

a16z: When Agents No Longer Need Interfaces, Why Should Software Companies Still Be Worth Billions?
TechFlow Selected TechFlow Selected
a16z: When Agents No Longer Need Interfaces, Why Should Software Companies Still Be Worth Billions?
Is Software Losing Its “Head”? a16z Warns: In the AI Agent Era, Wrapped Databases Aren’t Enough.
Author: Seema Amble
Translated and edited by TechFlow
TechFlow Insight: Salesforce has announced its “headless products”—essentially repackaging its existing APIs. But this move exposes a sharper question: When agents no longer need UIs and instead call APIs directly, what remains of traditional SaaS companies beyond a database plus a layer of business logic—and why should they still be worth tens of billions of dollars? a16z dissects how the moats of Systems of Record (SoR) are being重构 in the AI era: UI stickiness vanishes, muscle memory becomes obsolete—but compliance, cross-system connectivity, and unwritten operational logic grow even more critical.
Is software losing its “head”?
Last month, Salesforce announced open API access and launched headless products—a bet that, in the agent era, its value lies in the data layer, not the UI. It’s a savvy repositioning. (Though notably, there appears to be little technical change: The APIs now marketed as “headless products” have existed for years. In other words, this is a classic Salesforce-style marketing launch.) The core idea behind this new product is that agents can access data directly from systems of record—bypassing the human-designed UI entirely.
This announcement raises a more intriguing question: What remains once you strip away the UI and expose the database? How does it differ from a Postgres database, a well-designed schema, and an API? Do the classic factors that made SoRs durable still hold—or has a new set of criteria emerged? In the SaaS era, SoRs were defensible because humans lived inside interfaces. In the agent era, that advantage weakens. Defensibility shifts downward—to data models, permissions, workflow logic, and compliance—and upward—to networks, proprietary data generation, and real-world execution.
When software loses its head, where does defensibility migrate?
The UI *was* the product
A system of record is the authoritative source of truth for a given business data domain—the official version of customer relationships, employee records, or financial transactions—the system others read from and write back to. CRM is the system of record for revenue. HRIS is the system of record for people. ERP is the system of record for money. What makes them powerful isn’t just storing data, but becoming the shared reality on which the entire organization operates.
For the past two decades, Salesforce sold a way for sales leaders to manage their teams. Dashboards, pipeline views, forecasting tools, and activity feeds were what people actually bought. Its business model was built on selling seats—granting users access to those features. The underlying database, though critical, was incidental.
This meant UI drove stickiness. It enforced data standards. It created shared vocabulary: leads, opportunities, accounts. It compelled thousands of sales reps to enter data they otherwise wouldn’t. The UI was the mechanism keeping data coherent. The product was so sticky that many sales leaders carried Salesforce with them to new jobs—not because the UI was delightful, but because it had become muscle memory.
Agents are beginning to disrupt this pattern. They read and write underlying data directly—not via UI interaction—sparking a wave of entirely UI-bypassing tools and workarounds. (Salesforce isn’t alone: We recently wrote about how SAP sees an entire AI-friendly ecosystem growing around it.) Computer-using agents also render traditional human-layer factors—preferences, training, undocumented context—obsolete over time. In other words, the requirements for enduring systems of record are evolving.
A historical scorecard
Before asking what the agent era will change, it’s worth precisely identifying what originally drove SoR stickiness. The first few factors focus squarely on how humans interact with software—and their preferences. SoR stickiness was largely driven by UI, habits, human workflows, and embedded processes.
How frequent is access? CRM is used daily by GTM teams and others. This frequency makes it critical infrastructure—and the human layer built atop it—rituals, muscle memory, management rhythms honed over years—is often the hardest to migrate, precisely because it isn’t even recognized as something needing migration.
Read-only or read-write? A sticky SoR is a read-write system. For example, CRM isn’t a write-once archive; it’s constantly read. Every logged call, every updated stage, every created task is entered by someone (who likely cares about what they’re doing). This bidirectional flow means any replacement must handle real-time operational data—not just historical exports. There’s no safe cutover moment, meaning enterprises tend to stick with a vendor once onboarded. By contrast, applicant tracking systems (ATS) are often write-only: Little reason exists to return to the data after hiring concludes.
How much internal or external dependency? The core question: How many internal systems, team workflows, or external stakeholders depend on this SoR? Internal connectivity refers to downstream software or workflows. External connectivity refers to external parties—auditors, accountants, regulators—who require direct data access (e.g., ERP). Higher connectivity along either dimension means more to untangle during migration.
How critical is the data from a compliance perspective? The core question here is simple: Is this system mission-critical for compliance? Compliance-critical systems—payroll, ERP, HR data—require a legally defensible source of truth, strict admin access controls, and direct involvement from auditors and regulators in any migration. This significantly increases stickiness. Sales data and customer support tools like Zendesk sit at the other end: You care about continuity and context, but moving data or granting access carries no regulatory risk.
Not all SoRs carry equal switching costs. Scoring CRM against ATS across these same dimensions reveals a stark gap. ATS is a bounded workflow tool: hiring. Once a candidate is hired or rejected, that record is essentially write-once. Integrations are narrower. The user base is small and concentrated.
ERP sits at the opposite extreme: The ledger is the audit trail—and your accountants, auditors, and regulators become direct stakeholders in any migration. Replacing ATS is painful but manageable. Replacing CRM is open-heart surgery. Replacing ERP is open-heart surgery while the patient runs a marathon.
Traditionally, SoRs didn’t leverage moat-builders like proprietary data or network effects; the workflow itself created sufficient defensibility. If anything, consumer businesses combined tools and networks—while historically, SoR software did not.
Proprietary data — While many SoRs collect customer data, they rarely do much meaningful processing of it (and often cannot, per contractual terms). So although CRMs hold rich datasets aggregatable across customers to generate cross-customer insights, they’ve never done so in any meaningful way (despite attempts like Salesforce’s Einstein).
Network effects — The holy grail was always network effects. CRM would grow more valuable as software sellers could find buyers. Like data, network effects for historical SoRs were, at best, weak.
So if the UI disappears—and agents arrive—what remains?
Agents don’t need browsers. They need APIs, context, instructions, and action capability. Two things make this scalable: LLMs have become capable enough to reason. So agents can now read context, plan, select tools, execute actions, and review outputs—most tasks requiring no human intervention. And the MCP standard has standardized tool access, giving agents a universal interface to invoke external capabilities. An MCP-enabled agent can scale human-user work across millions of instances in milliseconds—no browser required. With proper context, computer-using agents should even navigate existing software interfaces without APIs.
Simplified, software buyers now face three paths:
1) Existing system + agents. Use the incumbent’s CLI and APIs—either through their native agent products (Salesforce’s Agentforce, SAP’s Joule), or by building your own agents on top. (We’ll temporarily set aside whether APIs are fully available or whether headless operation is as simple as it appears.)
2) Fully DIY SoR. Build your own data model, operational logic, permissions, audit trails, integrations—and your own agents (potentially leveraging third-party agent-building and database tools).
3) Buy AI-native alternatives. Purchase next-generation software built from scratch for the agent era—designed to be machine-readable, with agent orchestration as a first-class feature, not an add-on. This can be headless.
So what remains on the old scorecard? Elements driven by human behavior and preference—like access frequency or read vs. read-write—fade, since they’re tied to human muscle memory. Agents may kill muscle memory as a moat, but they won’t kill operational logic and context as moats. If anything, they make that logic more important—because agents need explicit rules, permissions, and process definitions to act safely.
Unwritten SOPs remain important in the short term. Institutional logic encoded in your workflow rules is exactly what agents need to operate correctly on your behalf. And it’s the hardest thing to rebuild. It doesn’t export cleanly—especially when parts of the process still involve humans. Yet capturing context is getting easier, and as agents replace more labor, it becomes less relevant.
Connectivity remains hard to untangle—and extends further. The nature of connectivity shifts. It’s no longer about keeping pace with humans, but about maintaining connections between traditionally siloed functions and software. A CRM agent must stitch together sales, billing, and customer success data and context. If your platform also serves as the node where agents from multiple external organizations transact—buyers, sellers, partners—dependencies deepen. An incumbent vendor with agents faces greater difficulty working across primitives of diverse underlying software—and so does a DIY database paired with a set of agents.
Compliance-critical data remains vital. Data needed by regulators—or carrying regulatory or legal risk—requires a single trusted source. If customers trust their current product, they’re unlikely to switch. Take payroll and accounting data: Agents may want access, but you’re unlikely to build and maintain it internally. In a fully agent-driven world, one of the hardest problems to solve is: Which agents are authorized to act for whom, and with what auditability? A SoR that becomes the identity and permissions layer governing interactions among agents assumes a structurally irreplaceable role—not because of the data it holds, but because of the trust architecture it enforces.
Looking ahead, a set of increasingly relevant factors will drive defensibility for AI-native startups:
How hard is it to reconstruct the SoR? — Data grows more important in several ways. First, in the short term: how easy or hard it is to extract and reconstruct the underlying data of an SoR. AI is making this easier through many tools. Incumbents can—and will—make this harder in the near term by making APIs painful, restricted, incomplete, or economically unattractive—if they offer APIs at all. But as extraction tools improve—especially as computer-using agents advance—they’ll make reconstruction easier. Meanwhile, new companies are rebuilding richer datasets from email, phone and voice agents, and internal documents. AI lowers the cost of reconstructing the first 80% of an SoR. The remaining 20%—exceptions, approvals, compliance requirements, and edge-case workflows—remains what separates a useful wedge from a true alternative.
Is there meaningfully proprietary data?
Second, the data itself becomes more interesting. Defensible data isn’t data you import—it’s data uniquely generated *by* your product. We talk about walled gardens of data—proprietary, regulated, or requiring continuous updating. Software providers investing in collecting authoritative, complete data hold advantages over generic providers—or competitors lacking such data. Another dimension around data emerges when it depends on internally generated behavior. The best businesses don’t just store data input elsewhere. They generate new data byproducts through process participation—including observed behaviors, response rates, timing patterns, process outcomes, benchmarks, anomaly patterns, and agent performance trajectories. Crucially, data *is* now context.
Does it have an action layer?
In the old world, storing records sufficed. In the new world, agents take action—and defensibility may shift toward products operating in closed loops: acting, capturing results, and using feedback to improve future decisions. For ERP, this could mean approving expenses, triggering payroll, reconciling invoices, sending notifications. Products completing the loop are more defensible because they sit inside execution—not just observation: They generate unique data, improve with use, and become harder to remove without breaking workflows. Of course, value grows with more context collected and more edge cases handled.
Does it include real-world execution elements?
The business model connects to real-world operations that won’t fully automate. Obvious examples are companies with operational networks—like DoorDash—which historically weren’t record systems but are highly instructive here. More broadly, any software business extending into services, fulfillment, logistics, field operations, or payments possesses different defensibility than pure SaaS. These companies don’t just store records or recommend actions; they dispatch people, ship goods, or complete services.
For builders, this signals opportunity in markets where software increasingly makes decisions, agents increasingly coordinate—but the last mile still requires real-world execution. Examples include vertical software for field service.
Does it have network effects?
Historically, most record systems had weak network effects because software was primarily used internally. But in the agent world, network effects may grow more important if the system embeds into multi-party workflows. If the system mediates repeated interactions between buyers and sellers, employers and employees, companies and auditors, suppliers and customers, or payers and providers—each additional participant makes the network more valuable for the next.
One path is shared workflow coordination: The product becomes the place where both sides of a process transact, exchange context, and resolve exceptions. A second is benchmarking and intelligence: The system surfaces norms, anomalies, and recommendations based on patterns observed across the network—complementing the data point above. A third is trust and standardization: Once counterparties rely on the same rails for approvals, handoffs, compliance, or payments, the product becomes harder to replace—not just as a database, but as part of the market’s coordination infrastructure.
What is the buyer’s technical capability?
In a theoretical world where anyone can build their own agents, the practical gap in buyers’ ability to do so remains vast. Especially in vertical end markets—and functional buyers who historically lacked strong internal engineering resources—their likelihood of building, maintaining, and continuously improving their own databases, workflow logic, agent stacks, and governance layers remains low. Cost matters too: DIY may theoretically reduce software license fees, but often shifts spend to implementation, maintenance, and internal complexity. This creates real opportunity in operationally complex but technically underserved categories—manufacturing, construction back-office, industrial and field service workflows, or accounting.
Several other critical factors will also become table stakes for software. For instance, ontologies need to evolve. Much “DIY database” thinking underestimates the value embedded in object models themselves. Existing software is built for dashboards, reports, and humans—and captures workflows. This includes opportunities, tickets, candidates. Agent paradigms need to capture reasoning, action, state tracking, exception handling, delegation, and cross-system coordination. Native object models may evolve into tasks, intents, threads, policies, or outcomes.
Likewise, permission management needs updating to govern agents—not just humans. This includes: Who can do what, via which agent, under what policy, requiring what approvals, with what audit trail, and what rollback/exception handling.
Of course, all this sits within a cost context (e.g., cost to build/maintain agents/databases, cost of API access)—which circles back to how hard data reconstruction is and how many dependencies exist.
So where does this leave us?
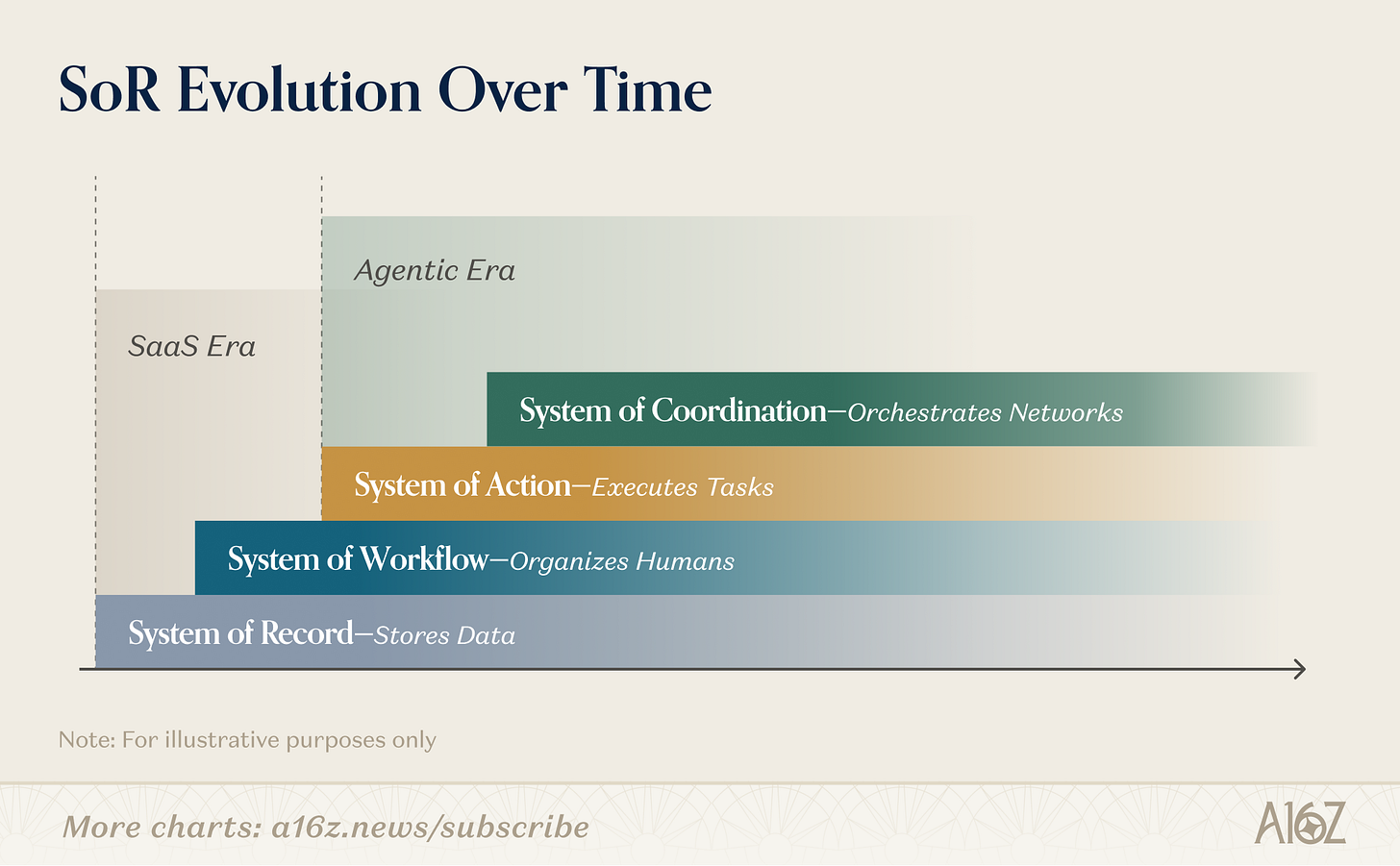
As incumbents go headless, they’re implicitly betting the data layer will continue to be the source of value. In certain categories—especially those heavily constrained by compliance, like financial services—this bet may hold for some time, and headless adoption may remain distant. For software builders, the opportunity to compete with incumbents going headless—and build durable software—is shifting. Next-generation record systems are already looking different: Not just repositories collecting data to log human work, but agentive systems that capture context, initiate work, and log data byproducts. Moreover, the most compelling businesses will extend into real-world execution—coordinating field workers, logistics providers, service teams, and physical assets—or sit between multiple parties. They’ll blend old-world business models, while the core of traditional record systems—data—fades into the background.
Huge thanks to @astrange for thought partnership on this!
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News













