

Enhanced Sora image generation model released: now usable directly in ChatGPT and threatening meme creators' livelihoods
TechFlow Selected TechFlow Selected
Enhanced Sora image generation model released: now usable directly in ChatGPT and threatening meme creators' livelihoods
The official leads the way in creating meme images.
Just 24 hours after DeepSeek released an update for its V3 model on March 24, OpenAI seemed determined not to be outdone, announcing a new product launch in the early hours of March 26, Beijing time.

Although there had been rumors suggesting a possible GPT-5 release prior to the event, based on OpenAI's historical product rhythms, this was not expected to be a major update. Nevertheless, the integration of the new Sora into ChatGPT delivered an unexpectedly entertaining "show effect."
Currently, the version of Sora integrated into ChatGPT is temporarily limited to image generation compared to its standalone app counterpart. However, OpenAI stated during the livestream that this model represents a qualitative leap over previous versions.
According to the presentation, the development team built this version of Sora upon the "multimodal" capabilities of GPT-4o—a model capable of generating any type of data including text, images, audio, and video. This allows users to directly voice their requests or even upload or take a photo as a prompt.
For example, during the live demo, they took a selfie with Sam Altman and two others using a smartphone and asked Sora to generate an "anime-style version."
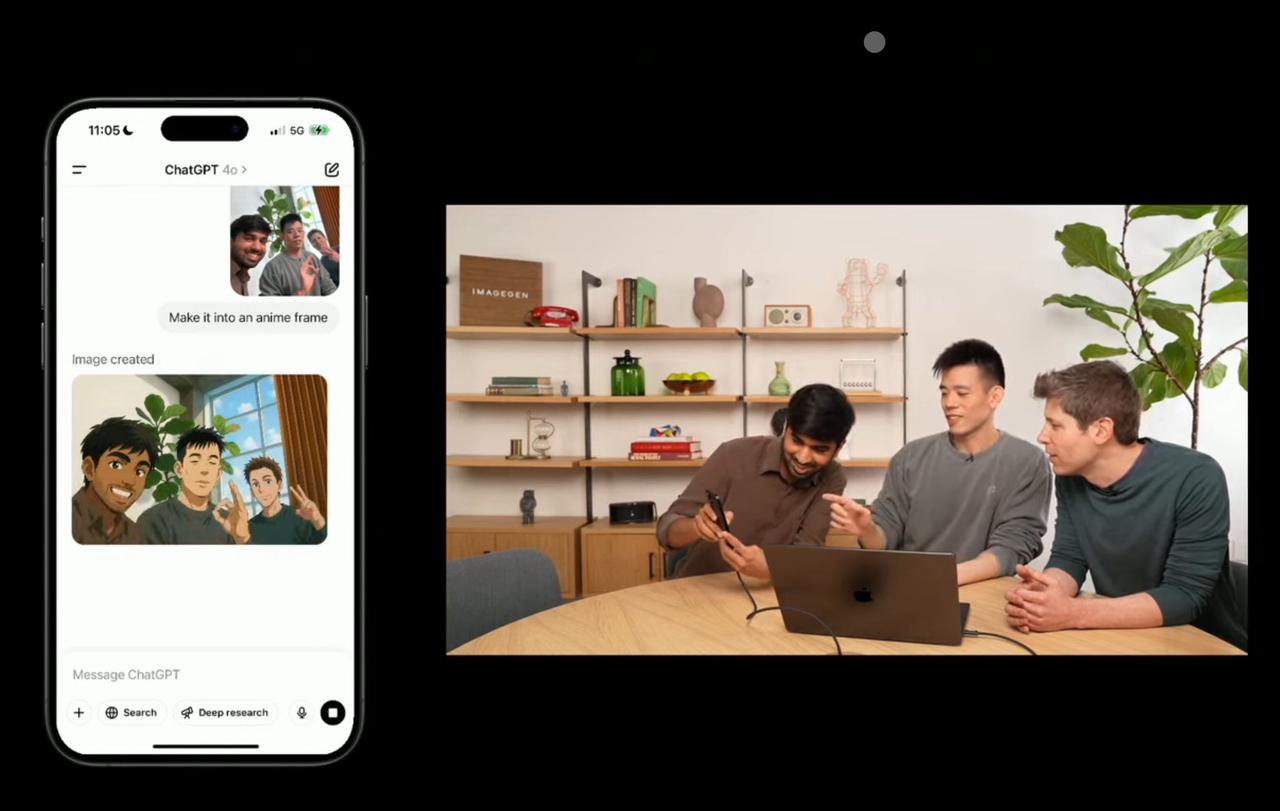
But it didn’t stop there—they proceeded to demonstrate adding the text “Feel The AGI” (Feel Artificial General Intelligence) onto the image live, creating the first meme featuring the new Sora.
The generated meme not only displayed accurate and clear text but also correctly understood essential elements of modern internet memes, such as bold fonts, making it immediately usable for sharing across various chat groups.

With OpenAI leading the way in meme creation, many users in the comments were inspired to try feeding the same prompts into Grok, using identical photos and instructions to generate similarly styled content—but the results clearly fell far short of the new Sora, producing even more comedic outcomes.

Beyond meme-making, OpenAI also showcased improvements in Sora’s text rendering capabilities, significantly increasing the success rate of generating coherent, error-free text within images.
In another demonstration scenario, the OpenAI team tasked Sora with generating a comic card explaining the theory of relativity.
Unlike earlier image-generation models where text often became chaotic or resulted in “AI-invented characters,” the native image generation of the new Sora produced text with no noticeable errors, even generating natural and fluent Japanese in the comic—unexpectedly thrilling many Japanese users in the Japanese-speaking community.
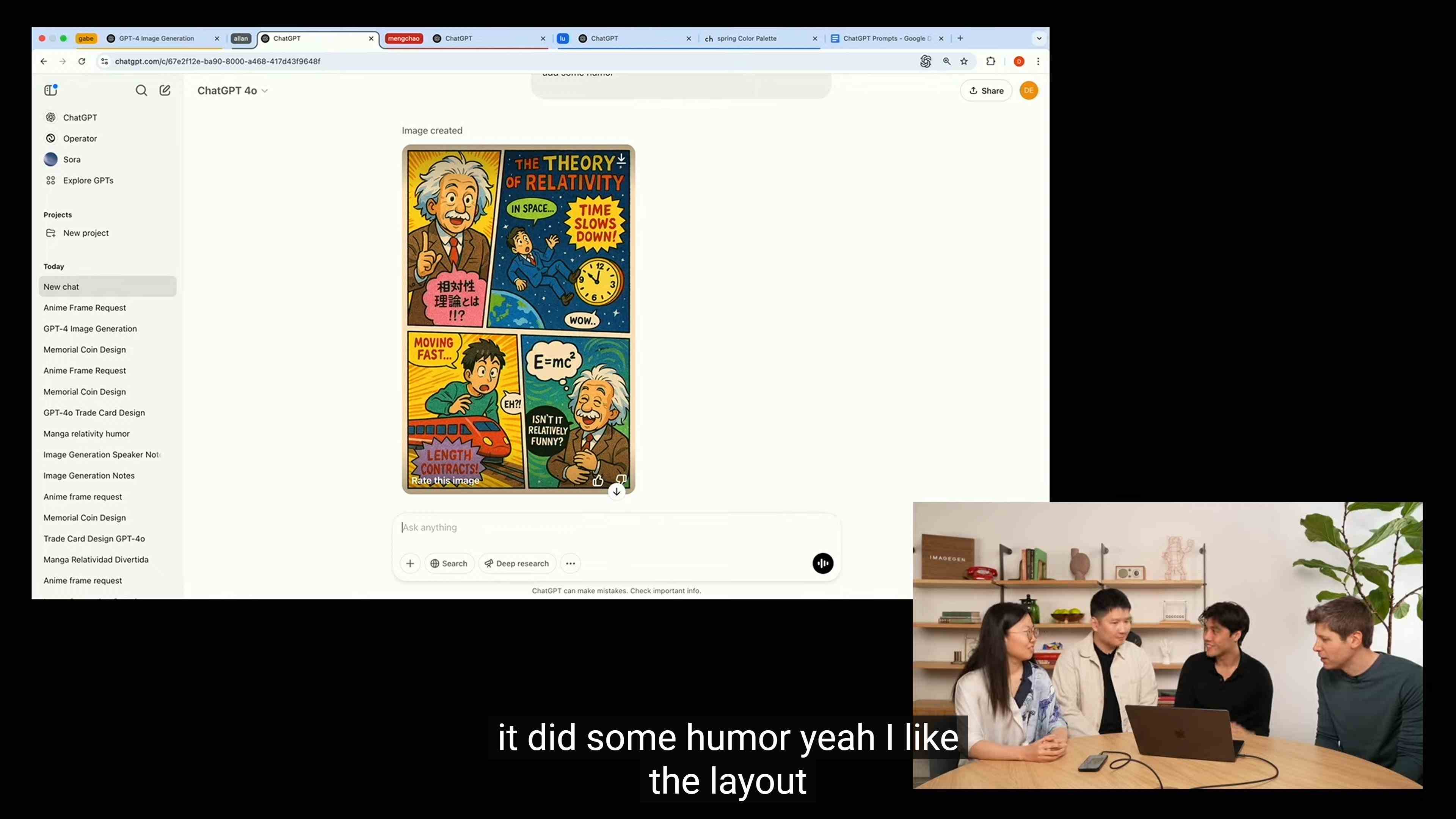
For image-generation models, accurately rendering text has historically been a significant challenge. If headlines or textual elements contain spelling mistakes or inaccuracies, the entire image can become unusable.
Additionally, in this case, OpenAI demonstrated proper referencing of existing world knowledge, such as concepts related to relativity.

"If I draw an image myself, I'm limited by my own skills—and by all the world knowledge I've accumulated," explained Jackie Shannon, ChatGPT's multimodal product lead, in an interview with media, highlighting the necessity of this feature.
"The model brings in world knowledge, so when you ask it to generate an image of Newton's prism experiment, you don't need to explain what the 'Newton's prism experiment' actually is—you just get the correct image."

Besides these demonstrated enhancements, OpenAI noted that the new Sora greatly improved its ability to maintain correct relationships between attributes and objects. For instance, weaker models might misinterpret a prompt asking for blue stars and red triangles by generating red stars without any triangles.
According to OpenAI, most current image models are prone to such "errors," especially when asked to render multiple items (typically around 5 to 8), frequently confusing colors and shapes. The new Sora, however, can correctly bind attributes for 15 to 20 objects, accurately understanding complex requirements while avoiding confusion, thereby substantially increasing success rates.

In addition to user experience improvements, one detail worth noting is that OpenAI confirmed the new Sora takes longer to generate images than before, though the company believes this trade-off is worthwhile.
"While we certainly have room for improvement in latency... we believe the quality, functionality, and world knowledge embedded in these generated images truly compensate for those extra few seconds of waiting," said Shannon.
Regarding safety concerns in image generation—such as the repeated incidents from last year to this year involving fabricated celebrity indecent images, fake viral event images, and Google Gemini removing original photo watermarks—OpenAI emphasized that the new Sora can remove photo watermarks while actively preventing generative deepfake imagery and rejecting related content requests. Moreover, all generated images will include standard C2PA metadata to indicate they were created by OpenAI.
Currently, the new Sora image-generation feature integrated into ChatGPT is available to Pro and Plus subscribers. OpenAI also pledged that the new Sora will soon be made available to free-tier users and via API.
Right now, the first thing I want to do is immediately ask it to create a meme of me.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News












