

The Rise of ChatGPT: From GPT-1 to GPT-3, the Era of AIGC is Approaching
TechFlow Selected TechFlow Selected
The Rise of ChatGPT: From GPT-1 to GPT-3, the Era of AIGC is Approaching
The development history of ChatGPT, the technical principles behind it, and its limitations.

What is ChatGPT?
Recently, OpenAI released ChatGPT, a model that interacts through conversational dialogue and has gained widespread popularity due to its intelligence.
ChatGPT is also a relative of InstructGPT, previously released by OpenAI. The ChatGPT model was trained using RLHF (Reinforcement Learning with Human Feedback). Perhaps the arrival of ChatGPT marks the prelude to OpenAI's official launch of GPT-4.
What is GPT? From GPT-1 to GPT-3
Generative Pre-trained Transformer (GPT) is a deep learning model for text generation trained on publicly available internet data. It is used for question answering, text summarization, machine translation, classification, code generation, and conversational AI.
In 2018, GPT-1 was introduced—the same year considered the inaugural year of pre-trained models in NLP (Natural Language Processing).
In terms of performance, GPT-1 demonstrated certain generalization capabilities and could be applied to NLP tasks unrelated to supervised training.
Its common applications include:
-
Natural language inference: determining the relationship between two sentences (entailment, contradiction, neutrality);
-
Question answering and commonsense reasoning: given a passage and several possible answers, output the correct one;
-
Semantic similarity recognition: judging whether two sentences are semantically related;
-
Classification: identifying which category a given text belongs to;
Although GPT-1 showed some effectiveness on tasks without fine-tuning, its generalization ability was far inferior to supervised tasks that had undergone fine-tuning. Therefore, GPT-1 could only be regarded as a decent language understanding tool rather than a conversational AI.
GPT-2 arrived as expected in 2019. However, GPT-2 did not introduce significant structural innovations to the original network but simply used more parameters and a larger dataset: the largest version had 48 layers and 1.5 billion parameters, with an objective to use unsupervised pre-training for supervised tasks. In terms of performance, beyond comprehension, GPT-2 demonstrated remarkable talent in generation for the first time: reading summaries, chatting, continuing stories, writing fiction, generating fake news, phishing emails, or role-playing online—all were within its capabilities. By simply "scaling up," GPT-2 indeed exhibited broad and powerful abilities, achieving state-of-the-art performance across multiple specific language modeling tasks at the time.
Then came GPT-3, an unsupervised model (now often referred to as self-supervised), capable of handling nearly all major natural language processing tasks, such as question-oriented search, reading comprehension, semantic inference, machine translation, article generation, and automated question answering. Moreover, the model performed exceptionally well in many areas—for instance, achieving state-of-the-art results in French-to-English and German-to-English machine translation, producing articles so realistic that humans could barely distinguish them from human-written ones (with only 52% accuracy—equivalent to random guessing). Even more astonishingly, it achieved near-perfect accuracy on two-digit arithmetic operations and could even generate code based on task descriptions. A single unsupervised model exhibiting such diverse and strong capabilities seemed to offer a glimpse of hope toward artificial general intelligence—likely the main reason behind GPT-3’s immense impact.
What Exactly Is the GPT-3 Model?
In essence, GPT-3 is a simple statistical language model. From a machine learning perspective, a language model predicts the probability distribution of the next word given a sequence of previous words. A language model can assess how grammatically correct a sentence is (e.g., evaluating whether responses generated by a chatbot sound natural and fluent), while also being able to predict and generate new sentences. For example, given the phrase “It’s 12 noon, let’s go to the restaurant together,” a language model can predict what might follow after “restaurant.” A typical model might suggest “eat,” whereas a more advanced one could capture temporal context and generate the more appropriate “have lunch.”
Typically, the strength of a language model depends on two key factors:
-
First, whether the model can effectively utilize all historical contextual information. In the above example, if the model fails to capture the distant contextual clue “12 noon,” it would struggle to predict the next word as “have lunch.”
-
Second, whether there is sufficiently rich historical context available for the model to learn from—that is, whether the training corpus is rich enough. Since language models fall under self-supervised learning, their optimization goal is to maximize the likelihood of observed text sequences, meaning any unannotated text can serve as training data.
Due to its superior performance and significantly greater number of parameters, GPT-3 encompasses a broader range of topics and clearly outperforms its predecessor, GPT-2.
As the largest dense neural network currently available, GPT-3 can convert webpage descriptions into corresponding code, mimic human narratives, compose custom poetry, generate game scripts, and even emulate deceased philosophers—predicting the meaning of life. Notably, GPT-3 requires no fine-tuning and can handle grammatical challenges with only a few examples of the desired output type (few-shot learning).
One could say GPT-3 seems to fulfill every expectation we have of a linguistic expert.
What Are the Problems With GPT-3?
However, GPT-3 is not perfect. One of the primary concerns people have about current AI systems is that chatbots and text generation tools may indiscriminately learn from all online texts regardless of quality, potentially producing incorrect, offensive, or even malicious outputs—significantly affecting their future applicability.
OpenAI has also indicated that a more powerful GPT-4 will be released in the near future:

Comparison of GPT-3, GPT-4, and the human brain (Image source: Lex Fridman @youtube)
Reportedly, GPT-4 will be launched next year, capable of passing the Turing test and being so advanced as to beindistinguishable from humans. Additionally, the cost for enterprises to adopt GPT-4 is expected to drop significantly.
ChatGPT and InstructGPT
When discussing ChatGPT, we must mention its "predecessor," InstructGPT.
In early 2022, OpenAI released InstructGPT. In this research, compared to GPT-3, OpenAI employed alignment research to train a language model—InstructGPT—that is more truthful, less harmful, and better aligned with user intentions.
InstructGPT is a fine-tuned new version of GPT-3 designed to minimize harmful, false, and biased outputs.
How Does InstructGPT Work?
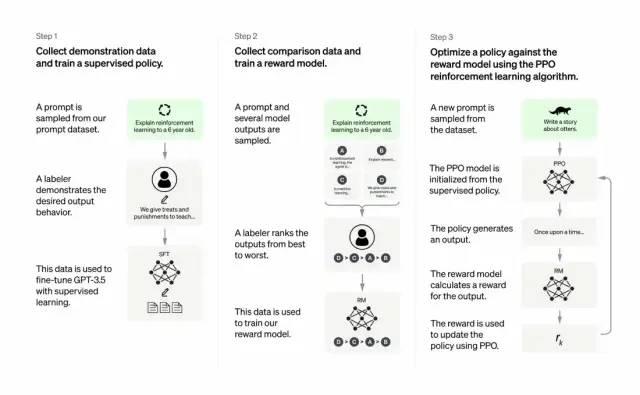
Developers improve GPT-3's output quality by combining supervised learning with reinforcement learning from human feedback. In this approach, humans rank potential model outputs; reinforcement learning algorithms then reward the model for generating outputs similar to those ranked highly.
The training dataset begins with prompts, some derived from actual GPT-3 user inputs, such as "Tell me a story about a frog" or "Explain moon landing to a 6-year-old in a few sentences".
Developers divide these prompts into three parts and create responses for each part differently:
-
Human writers respond to the first set of prompts. Developers fine-tune a pretrained GPT-3 model to replicate these existing responses, transforming it into InstructGPT.
-
Next, a model is trained to assign higher rewards to better responses. For the second set of prompts, the optimized model generates multiple responses. Human raters rank each response. Given a prompt and two responses, a reward model (another pretrained GPT-3) learns to assign higher scores to highly rated responses and lower scores to poorly rated ones.
-
Using the third set of prompts and the reinforcement learning method Proximal Policy Optimization (PPO), developers further fine-tune the language model. Given a prompt, the language model generates a response, and the reward model assigns a score. PPO uses this reward signal to update the language model.
Why Is This Important?
The core idea is this—artificial intelligence must be responsible artificial intelligence.
OpenAI's language models can support education, virtual therapists, writing assistants, role-playing games, and more.In these domains, societal biases, misinformation, and toxic content pose significant challenges. Systems capable of avoiding such flaws will be far more useful.
How Do ChatGPT and InstructGPT Differ in Training Process?
Overall, ChatGPT, like InstructGPT described above, is trained using RLHF (Reinforcement Learning from Human Feedback).
The difference lies in how the data is configured for training (and collected). (Here’s an explanation: the earlier InstructGPT model took one input and produced one output, comparing it against training data for reward or penalty. Now, ChatGPT takes one input and the model produces multiple outputs, which humans then rank—from “sounds natural” to “nonsensical”—teaching the model to learn human preferences in ranking. This strategy is known as supervised learning. Thanks to Dr. Zhang Zijian for this clarification.)
What Are the Limitations of ChatGPT?
They are as follows:
a) During the reinforcement learning (RL) training phase, there is no concrete source of truth or standard answers to your questions.
b) The trained model tends to be overly cautious and may refuse to answer (to avoid false positives in prompts).
c) Supervised training may mislead/bias the model toward knowing ideal answers, rather than generating a random set of responses where only human evaluators select and rank the good ones.
Note: ChatGPT is sensitive to phrasing. Sometimes the model fails to respond to a phrase, but with slight rewording of the question or prompt, it eventually provides the correct answer. Trainers tend to favor longer answers because they appear more comprehensive, leading the model to produce unnecessarily verbose responses and overuse certain phrases. If the initial prompt or question is ambiguous, the model does not appropriately ask for clarification.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News














