

Six days after launching ChatGPT Health, OpenAI was overtaken on its own healthcare benchmark.
TechFlow Selected TechFlow Selected
Six days after launching ChatGPT Health, OpenAI was overtaken on its own healthcare benchmark.
Baichuan Intelligence stated that it will successively launch two consumer-facing healthcare products in the first half of this year.
Author: Li Yuan
Have you ever asked an AI assistant about your health?
If you're a heavy user of AI like me, chances are you've tried it.
According to OpenAI's own data, healthcare has become one of the most common use cases for ChatGPT, with over 230 million people worldwide asking health- and wellness-related questions each week.
Because of this, entering 2026, healthcare is clearly emerging as a key battleground in the AI domain.
On January 7, OpenAI launched ChatGPT Health, allowing users to connect electronic medical records and various health apps to receive more personalized medical responses. Then on January 12, Anthropic quickly responded with Claude for Healthcare, emphasizing the new model’s medical scenario capabilities.
Interestingly, this time Chinese companies aren’t falling behind—in fact, they may even be taking the lead.
On January 13, Baichuan Intelligent announced the release of its Baichuan M3 model, surpassing OpenAI’s GPT-5.2 High on HealthBench—the evaluation benchmark released by OpenAI for healthcare—and achieving SOTA (State-of-the-Art) performance.
After facing widespread skepticism following its "All-in Healthcare" announcement, Baichuan Intelligent seems to have finally proven itself. GeekPark sat down with Wang Xiaochuan to discuss how Baichuan views the capabilities of the M3 model and the ultimate future of AI in healthcare.
01 First to Outperform OpenAI on a Health Benchmark
One of the standout achievements of the newly released M3 model is that it became the first to surpass OpenAI’s GPT-5.2 High on HealthBench, OpenAI’s healthcare-focused evaluation benchmark, achieving SOTA status.
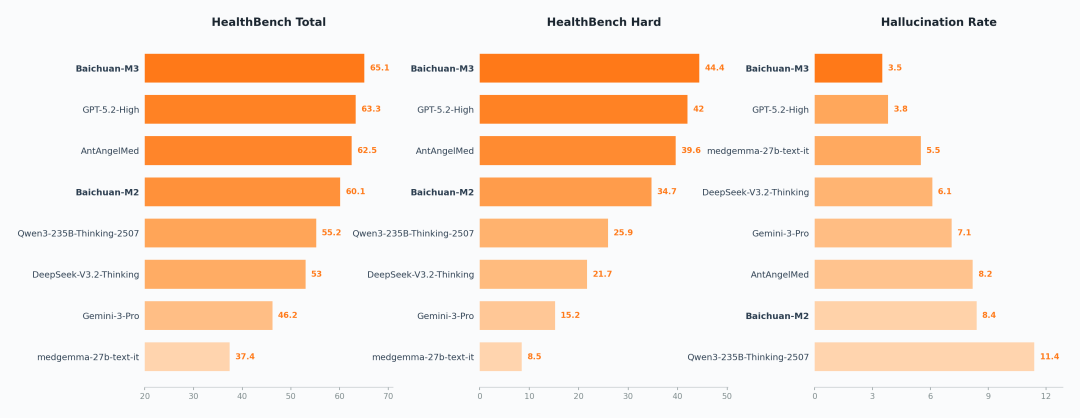
SOTA on Healthbench, Healthbench Hard, and Hallucination Evaluation
HealthBench is a healthcare evaluation test set released by OpenAI in May 2025, co-developed by 262 doctors from 60 countries. It contains 5,000 highly realistic multi-turn medical dialogues and is currently one of the most authoritative and clinically realistic medical benchmarks globally.
Since its release, OpenAI’s models had consistently led the rankings.
Now, Baichuan Intelligent’s next-generation open-source medical large model, Baichuan-M3, has achieved a comprehensive score of 65.1, ranking first globally. On HealthBench Hard—a subset specifically designed to test complex decision-making—M3 also claimed the top spot, setting a new record high.
Baichuan also released results on hallucination rate: the M3 model achieved a hallucination rate of just 3.5%, among the lowest globally.
Notably, this hallucination rate was measured without relying on external retrieval tools—purely based on the model’s internal settings.
Baichuan Intelligent attributes these achievements primarily to introducing reinforcement learning algorithms tailored for healthcare into the model.
For the first time on the M3 model, Baichuan applied Fact Aware RL (Fact-Aware Reinforcement Learning), effectively preventing the model from either giving generic responses or making things up.
This is especially critical in healthcare.
When asking unoptimized models medical questions, two issues commonly arise: first, the model fabricates symptoms and invents diseases; second, the response is vague, ultimately advising the user to “see a doctor”—which isn’t helpful for either patients or physicians.
This often happens because many models optimize purely for low hallucination rates, leading them to dilute hallucinations by piling up simple, correct facts. Baichuan introduced semantic clustering and importance weighting mechanisms—clustering eliminates redundant expressions, while weighting ensures core medical judgments carry higher significance.
Meanwhile, simply applying strong penalties on hallucinations could push the model toward a conservative “say less, make fewer mistakes” strategy. To avoid this, Fact Aware RL includes a dynamic weight adjustment mechanism that adaptively balances the two objectives based on the model’s current capability level: during early stages, emphasis is placed on learning and expressing medical knowledge (high Task Weight); once mature, factual constraints are gradually tightened (increasing Hallucination Weight).
When connected online, Baichuan also added a multi-round search-based real-time verification module, along with an efficient caching system to align vast amounts of medical knowledge.
02 Diagnostic Performance Exceeds Human Doctors—Entering the Practical Phase
However, outperforming OpenAI on HealthBench isn't the only highlight.
A more interesting aspect is that Baichuan created its own evaluation benchmark called SCAN-bench. Compared to chasing leaderboard rankings on OpenAI’s benchmark, Baichuan’s self-built benchmark better reflects the direction the company wants to optimize for in healthcare.
The key focus of SCAN-bench is optimizing end-to-end diagnostic capabilities. This stems from Baichuan’s experimental insight: every 2% increase in diagnostic accuracy leads to a 1% improvement in treatment outcome accuracy.
In contrast to OpenAI’s HealthBench, which mainly evaluates whether “AI can answer questions,” Baichuan’s SCAN-bench aims to assess whether AI can effectively gather information through dialogue and deliver accurate diagnoses and medical advice.
Typically, when we ask an AI assistant a question, simply stating “you are an experienced doctor” rarely yields good results. Real doctors follow highly standardized diagnostic procedures—Baichuan summarizes this as the four-quadrant SCAN principle: Safety Stratification, Clarity Matters, Association & Inquiry, and Normative Protocol.
Based on the SCAN principles, Baichuan adopted OSCE (Objective Structured Clinical Examination)—a method long used in medical education—and collaborated with over 150 frontline physicians to build the SCAN-bench evaluation framework. The diagnostic process is broken down into three phases: medical history collection, auxiliary examinations, and precise diagnosis. Through dynamic, multi-turn assessments, it fully simulates the entire journey from patient intake to final diagnosis, optimizing the model across all stages.
Baichuan also published the M3 model’s performance on SCAN-bench.
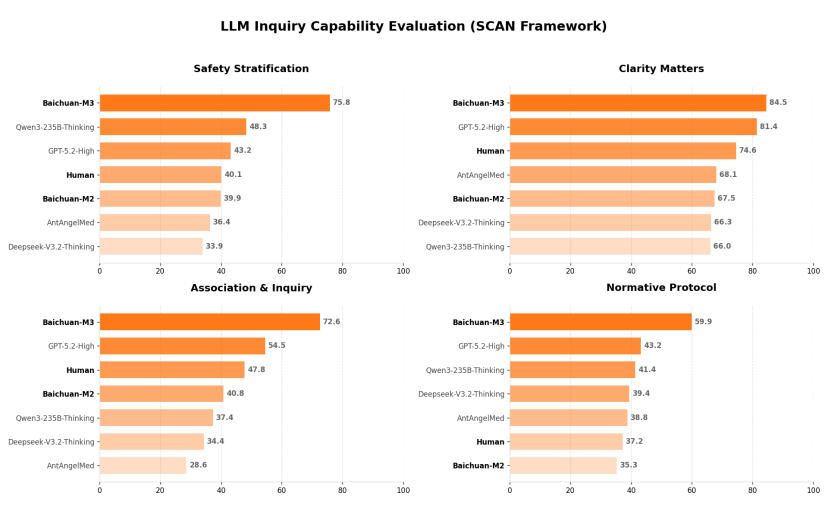
The results are striking. In the comparison, Baichuan not only benchmarked against other models but also included real human doctors. Across all four quadrants, human doctors were actually outperformed by the model.
GeekPark specifically asked Baichuan’s team about this. They explained: all comparisons involved real specialist doctors evaluating cases within their specialty. The model’s advantage lies partly in greater patience, but more importantly, in superior cross-disciplinary knowledge integration.
For example, in one case involving a 10-year-old child with recurrent fever—a complex symptom—if the inquiry focuses only on coughing or lung conditions, serious issues in joints or the urinary system might be missed, leading to misdiagnosis as a common infection.
Human doctors typically excel only in their specialized areas, which is why complex cases often require expert consultations or why even specialists frequently need to consult references.
Untrained general models pretending to be doctors also struggle with such cases.
03 Next Step: Gradually Launching Consumer Products, Advancing Serious Medicine
For Baichuan Intelligent, surpassing human doctors marks a pivotal moment: it means AI has crossed the threshold of usability and can now be deployed in real-world applications.
Starting January 13, users have been able to experience responses powered by the M3 model on Baixiaoying’s website and app.
The current interface design is particularly interesting. Although both versions run on the M3 model, there are distinct doctor and patient modes. The doctor version provides concise answers with more citations and is more technically phrased. In contrast, the patient version rarely gives immediate answers—it actively asks follow-up questions to reach a clearer diagnosis.

Baichuan noted that the model’s internal reasoning process is fascinating: “We often see the model say in its chain of thought, ‘The patient didn’t respond to my question, but I must still ask it.’ We’ve even seen extreme cases where the model says, ‘I’ve already asked 20 rounds—exceeding the maximum allowed—but I still need to ask this question.’ During training, being clever or evasive doesn’t earn rewards. The model only gets rewarded when it obtains enough critical information to make the correct diagnosis. This is a clear difference between our approach and others.”
As more AI companies enter healthcare, Baichuan sees this commitment to rigor as its defining trait—pursuing more serious medicine.
“This means Baichuan doesn’t choose application scenarios based on ease of implementation. Instead, we insist on continuously pushing technological boundaries and tackling harder problems,” said Wang Xiaochuan.
A typical example is that Baichuan will prioritize oncology over mental health in its development roadmap.
Commonly, AI-assisted psychotherapy is considered simpler and easier to deploy. Baichuan holds a different view. They believe oncology has stronger scientific foundations, making it more feasible for AI to achieve rigorous medical outcomes that match or exceed human doctors. In contrast, psychology lacks such definitive scientific anchors.
Another example: some companies aim to create digital clones of doctors. Wang Xiaochuan believes this isn’t what Baichuan wants. A doctor clone cannot fully replicate, let alone surpass, a real doctor’s expertise. Such AI would merely become a marketing gimmick or customer acquisition tool, failing to advance serious medicine.
This commitment to seriousness profoundly influences many of Baichuan’s business decisions.
It directly ties into Wang Xiaochuan’s fundamental thinking about the next phase of medical AI. He believes the current priority is to enhance AI capabilities and gradually expand medical supply.
China has long promoted tiered diagnosis and treatment and the general practitioner system, aiming to encourage people to seek care at primary institutions to relieve overcrowding and long wait times at major hospitals.
This system has struggled due to insufficient medical resources. Primary healthcare facilities lack high-level doctors. Even for minor illnesses like colds, people prefer queuing at tertiary hospitals because they lack confidence in基层诊疗水平 (primary care quality).
This is precisely where medical AI can make a difference. Large models can scale top-tier medical knowledge, filling gaps at the grassroots level so that every community and household gains access to expertise comparable to that of specialists at top-tier hospitals.
In the long run, this could have broader implications—possibly shifting decision-making power in healthcare from doctors to patients. In traditional healthcare, patients are beneficiaries but often lack decision-making authority, creating communication costs and suffering during treatment.
Baichuan hopes AI will empower patients to access high-quality medical resources more easily. “Many think medicine is too complex for patients to understand. But consider the U.S. jury system. Law is also highly specialized, yet ordinary citizens serve on juries. The expectation is that judges, lawyers, and prosecutors present arguments clearly enough for laypeople to determine guilt or innocence based on logic. That’s what we envision—enabling patients to make sound judgments,” said Wang Xiaochuan.
This is also why Baichuan refuses to stick to simple use cases and instead pushes relentlessly toward high-difficulty, serious diagnostics.
When asked whether solving hard problems offers the best commercial return, Wang Xiaochuan gave a profound answer.
He believes solving minor issues like colds rarely builds sufficient trust in users’ minds. Healthcare is a trust-intensive industry. Only when AI can tackle difficult challenges like severe diseases can it establish a solid foundation of trust.
From a business perspective, patients facing serious health concerns are also more willing to pay for high-quality AI services. This trust is not only a prerequisite for commercial returns but also the core enabler for scaling AI in healthcare.
More fundamentally, for Baichuan Intelligent and Wang Xiaochuan personally, healthcare remains a pathway toward Artificial General Intelligence (AGI).
Wang Xiaochuan believes AI has already found practical solutions in fields like literature, science, engineering, and art. Medicine, however, remains uniquely challenging. Humanity’s understanding of medicine is still incomplete, and AI in this field is still in its exploratory phase.
Baichuan’s roadmap is clear: first, use AI to improve diagnostic efficiency and address shortages in medical supply. Building on that, establish deep trust with patients. When patients are willing to use AI tools regularly for long-term medical consultation, AI can accumulate authentic, high-quality medical data over time.
The ultimate goal of this data is to build mathematical models of life. This is a path human doctors haven’t fully traversed—and one that AI may pioneer. Successfully modeling the essence of life could become a crucial leap forward for AGI.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News










