

Why Web3 Needs a Dedicated Data Availability Layer?
TechFlow Selected TechFlow Selected
Why Web3 Needs a Dedicated Data Availability Layer?
Data is the core asset of the Web3 era, and user ownership of data is a key feature of Web3.
When the data economy develops to a certain stage and people widely and deeply participate in it, everyone inevitably becomes involved in various data storage activities.
In addition, with the arrival of the Web3 era, most technology sectors will gradually upgrade or transform over the next few years. Decentralized storage, as a key infrastructure of Web3, will see increasing real-world applications. For instance, data storage networks behind familiar services such as social media, short videos, live streaming, and smart vehicles are expected to adopt decentralized storage models in the future.
Data is the core asset of the Web3 era, and user ownership of data is a defining feature of Web3. Enabling users to securely own their data and associated assets, while alleviating common concerns about asset security, will help onboard the next billion users to the Web. An independent data availability layer will be an indispensable component of Web3.
From Decentralized Storage to Data Availability Layer
Historically, data has been stored via traditional centralized cloud storage, where data is fully stored on centralized servers.
Amazon Web Services (AWS) pioneered cloud storage and remains the world's largest cloud storage provider today.
-
Over time, user demands for personal data security and storage reliability have steadily increased. Following major data breaches at large-scale data operators, the drawbacks of centralized storage have become increasingly evident, making traditional storage methods inadequate for current market needs.
-
Coupled with the ongoing advancement of the Web3 era and the expansion of blockchain applications, data has become more diverse and voluminous. Personal network data now spans broader dimensions and holds greater value, making data security and privacy more critical than ever, and raising the bar for data storage requirements.
Decentralized data storage has thus emerged as a solution.
Decentralized storage is one of the earliest and most prominent infrastructures in the Web3 space, with Filecoin—launched in 2017—being the first major project.
Compared to AWS, decentralized and centralized storage differ fundamentally. AWS owns and maintains its own data centers composed of multiple servers, and users pay AWS directly for storage services. In contrast, decentralized storage follows the sharing economy model, leveraging vast numbers of edge storage devices to provide storage capacity, with data actually stored on storage provided by Provider nodes. As such, project operators cannot control the stored data. The fundamental difference between decentralized and AWS-style storage lies in whether users can control their own data. In a system without centralized control, data security is significantly higher.
Decentralized storage primarily operates as a business model that uses distributed storage to split files or file sets across a distributed storage network. Its importance stems from solving numerous pain points of Web2 centralized cloud storage, better aligning with the demands of the big data era by enabling lower-cost, higher-efficiency storage of unstructured edge data, thereby empowering emerging technologies. Thus, decentralized storage can be considered a foundational pillar of Web3 development.
Currently, there are two common types of decentralized storage projects:
-
One type focuses on block production through storage-based mining. A key issue with this model is that storing and downloading data on-chain slows down actual usage speed—downloading a single photo can take hours;
-
The other relies on one or several centralized nodes; storage and downloads can only proceed after verification by these central nodes. If these nodes are attacked or fail, data loss may occur.
Compared to the first model, MEMO’s layered storage mechanism effectively resolves slow download speeds, achieving sub-second retrieval times.
Compared to the second model, MEMO introduces the role of Keeper, which enables random selection of validator nodes, avoiding centralization while maintaining security. Moreover, MEMO has pioneered RAFI technology, which multiplies repair capabilities and greatly enhances storage security, reliability, and availability.
Data Availability (DA) essentially allows light nodes to verify data availability and correctness without participating in consensus, storing all data, or maintaining full network state in real time. For such nodes, efficient mechanisms are required to ensure data availability and accuracy. Since blockchain's core lies in immutable data, it guarantees consistency across the network. Consensus nodes, aiming for performance, tend toward centralization. Other nodes rely on DA to access verified, available data. An independent data availability layer effectively eliminates single points of failure and maximizes data security.
Furthermore, Layer2 scaling solutions like zkRollup also require a data availability layer. As execution layers, Layer2s leverage Layer1 as the consensus layer. While they post batched transaction results to Layer1, they must also ensure the availability of raw transaction data—so that even if no prover is available to generate proofs, the Layer2 state can still be recovered, preventing user assets from being permanently locked in Layer2 under extreme conditions. However, directly posting raw data to Layer1 contradicts the modular design principle where Layer1 serves solely as a consensus layer. Therefore, storing data in a dedicated data availability layer while only recording the Merkle root of that data on the consensus layer is a more rational and sustainable architectural approach.
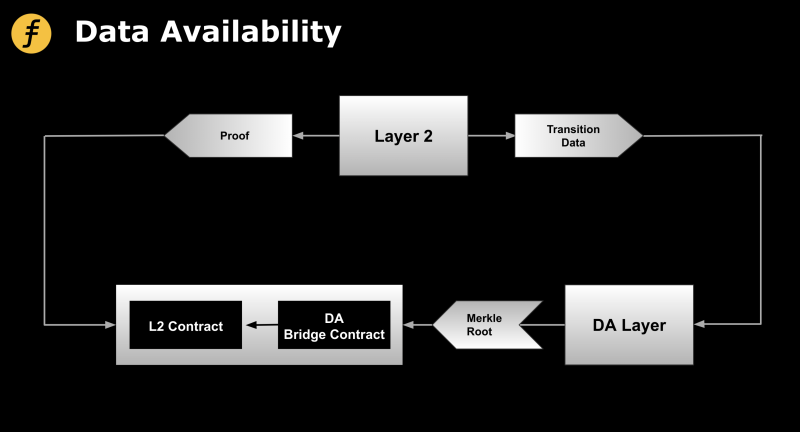
Figure 1: Generic Layer2 Independent Data Availability Layer Model
Analysis of Independent Data Availability Layer: Celestia
An independent data availability layer functions as a public blockchain, superior to a committee of subjective individuals responsible for data availability. If enough private keys of committee members are compromised (as occurred in Ronin Bridge and Harmony Horizon Bridge), off-chain data availability could be held hostage—threatening users into paying ransoms to withdraw funds from Layer2.
Given that off-chain data availability committees are inherently insecure, what if blockchain itself were used as a trust anchor to guarantee off-chain data availability?
This is exactly what Celestia achieves—making the data availability layer more decentralized by providing a standalone DA blockchain equipped with its own set of validators, block producers, and consensus mechanisms, thereby enhancing overall security.
Layer2 platforms publish transaction data to the Celestia mainchain. Celestia validators sign the Merkle Root of the DA Attestation and send it to the DA Bridge Contract on Ethereum for verification and storage. Effectively, the Merkle Root attests to the availability of all underlying data, allowing the Ethereum contract to verify and store just this root, drastically reducing overhead.
Celestia employs optimistic fraud proofs: as long as no errors occur in the network, efficiency remains high. In normal operation, no fraud proof is generated. Light nodes need not perform extra work—they simply receive data, reconstruct it via erasure coding, and proceed efficiently under optimistic assumptions.
Analysis of Independent Data Availability Layer: MEMO
MEMO is a next-generation, high-capacity, highly available enterprise-grade storage network built by algorithmically aggregating global edge storage devices. Founded in September 2017, the team specializes in decentralized storage research. MEMO is a large-scale, decentralized data storage protocol based on blockchain peer-to-peer technology, offering high security and reliability for massive data storage.
Unlike the one-to-many model of centralized storage, MEMO enables decentered, many-to-many storage operations.
On MEMO’s mainchain, smart contracts govern critical operations including data uploads, matching of storage nodes, system functionality, and penalty enforcement.
Technically, existing decentralized storage systems like Filecoin, Arweave, and Storj allow computer users to connect and rent out unused hard drive space in exchange for fees or tokens. While all are decentralized, each has distinct features. MEMO differentiates itself by using erasure coding and data repair technologies to enhance storage functionality, improving both data security and the efficiency of storage and retrieval. Creating a more practical and purely decentralized storage system is MEMO’s ultimate goal.
While enhancing usability, MEMO also optimizes incentives for Providers. Beyond Users and Providers, MEMO introduces the Keeper role to protect against malicious node attacks. Through mutual checks among multiple roles, the system maintains economic balance and supports high-capacity, highly available enterprise-grade commercial storage. It delivers secure and reliable cloud storage services for NFTs, GameFi, DeFi, SocialFi, and more, while remaining compatible with Web2—making it a perfect fusion of blockchain and cloud storage.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News














