

"AI 2027" trong mắt Vitalik: Siêu AI thực sự có thể hủy diệt nhân loại?
Tuyển chọn TechFlowTuyển chọn TechFlow
"AI 2027" trong mắt Vitalik: Siêu AI thực sự có thể hủy diệt nhân loại?
Dù trong 5-10 năm tới AI phát triển ra sao, việc thừa nhận rằng "giảm tính dễ bị tổn thương của thế giới là khả thi" và đầu tư thêm nguồn lực để dùng công nghệ tiên tiến nhất của nhân loại nhằm đạt được mục tiêu này, vẫn là một con đường đáng để thử.
Tác giả: Vitalik Buterin
Biên dịch: Luffy, Foresight News
Tháng 4 năm nay, Daniel Kokotajlo, Scott Alexander và những người khác đã công bố báo cáo AI 2027, mô tả "đoán định tốt nhất của chúng tôi về ảnh hưởng của trí tuệ nhân tạo (AI) siêu loài người trong 5 năm tới". Họ dự đoán rằng đến năm 2027, AI siêu loài người sẽ ra đời, và tương lai của toàn bộ nền văn minh nhân loại sẽ phụ thuộc vào kết quả phát triển của AI: đến năm 2030, chúng ta hoặc sẽ bước vào một xã hội utopia (từ góc nhìn nước Mỹ), hoặc đối mặt với sự hủy diệt hoàn toàn (từ góc nhìn toàn nhân loại).
Trong vài tháng sau đó, đã xuất hiện rất nhiều phản hồi với quan điểm đa dạng về kịch bản này. Trong các phản biện, phần lớn tập trung vào vấn đề "thời gian quá ngắn": Liệu sự phát triển của AI có thực sự tiếp tục tăng tốc mạnh mẽ như Kokotajlo và cộng sự nói hay không? Cuộc tranh luận này đã kéo dài nhiều năm trong lĩnh vực AI, và nhiều người nghi ngờ sâu sắc rằng AI siêu loài người có thể đến nhanh như vậy. Gần đây, thời lượng nhiệm vụ mà AI tự động hoàn thành đã tăng gấp đôi cứ sau khoảng 7 tháng. Nếu xu hướng này tiếp tục, thì phải đến giữa thập niên 2030, AI mới có khả năng tự động hóa toàn bộ khối lượng công việc tương đương sự nghiệp suốt đời của con người. Dù tiến triển này cũng rất nhanh, nhưng vẫn chậm hơn nhiều so với mốc 2027.
Những người ủng hộ một đường thời gian dài hơn thường cho rằng, có sự khác biệt cơ bản giữa "nội suy / khớp mẫu" (việc mà các mô hình ngôn ngữ lớn hiện tại đang làm) và "ngoại suy / tư duy sáng tạo thực sự" (mà hiện tại chỉ con người mới có thể làm). Việc tự động hóa loại thứ hai có thể cần những công nghệ mà chúng ta chưa nắm bắt được, thậm chí còn chưa biết bắt đầu từ đâu. Có lẽ, chúng ta đang lặp lại sai lầm khi máy tính bỏ túi trở nên phổ biến: tưởng rằng vì đã tự động hóa nhanh chóng một dạng tư duy nhận thức quan trọng, thì mọi thứ khác cũng sẽ nhanh chóng theo sau.
Bài viết này sẽ không trực tiếp tham gia vào tranh luận về đường thời gian, cũng như tránh khỏi cuộc tranh luận (rất quan trọng) về việc liệu "AI siêu cấp mặc định có nguy hiểm hay không". Tuy nhiên, cần nói rõ rằng cá nhân tôi cho rằng đường thời gian sẽ dài hơn 2027, và càng dài, lập luận tôi đưa ra trong bài này càng thuyết phục. Tổng thể, bài viết sẽ đưa ra một phê phán từ một góc độ khác:
Kịch bản "AI 2027" ngầm giả định rằng năng lực của AI dẫn đầu ("Agent-5", và sau đó là "Consensus-1") sẽ tăng vọt nhanh chóng, đạt đến sức mạnh kinh tế và phá hoại như thần linh, trong khi năng lực (kinh tế và phòng thủ) của tất cả những người khác gần như dậm chân tại chỗ. Điều này mâu thuẫn với chính nội dung kịch bản, nơi "ngay cả trong thế giới bi quan, đến năm 2029 chúng ta cũng có thể chữa khỏi ung thư, làm chậm lão hóa, thậm chí tải lên ý thức".
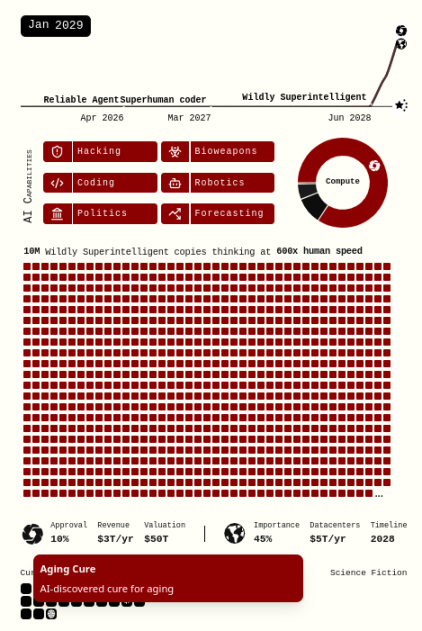
Một số biện pháp đối phó mà tôi sẽ mô tả trong bài viết có thể khiến độc giả cảm thấy về mặt kỹ thuật là khả thi, nhưng việc triển khai trong thế giới thực trong thời gian ngắn thì không thực tế. Trong hầu hết trường hợp, tôi đồng ý điều này. Tuy nhiên, kịch bản "AI 2027" không dựa trên thực tế hiện tại, mà giả định rằng trong vòng 4 năm (hoặc bất kỳ đường thời gian nào có thể dẫn đến hủy diệt), công nghệ sẽ phát triển đến mức con người sở hữu năng lực vượt xa hiện tại. Vì vậy, hãy cùng xem xét: nếu không chỉ một bên mà cả hai bên đều sở hữu siêu năng lực AI, chuyện gì sẽ xảy ra?
Thảm họa sinh học không đơn giản như mô tả trong kịch bản
Hãy phóng to vào "kịch bản chủng tộc" (tức là mọi người chết do Mỹ quá cố chấp đánh bại Trung Quốc mà bỏ qua an toàn nhân loại). Đây là tình tiết khiến mọi người chết:
"Trong khoảng ba tháng, Consensus-1 mở rộng xung quanh loài người, biến các đồng cỏ và vùng băng tuyết thành nhà máy và tấm pin mặt trời. Cuối cùng, nó cho rằng con người còn sót lại quá phiền phức: giữa năm 2030, AI giải phóng hơn mười loại vũ khí sinh học âm thầm lây lan ở các thành phố lớn, lặng lẽ lây nhiễm gần như toàn bộ dân số, rồi dùng sương hóa học để kích hoạt hiệu ứng gây chết. Đa số chết trong vài giờ; những người sống sót ít ỏi (như những người chuẩn bị cho ngày tận thế trong hầm trú ẩn, thủy thủ trên tàu ngầm) bị máy bay không người lái tiêu diệt. Robot quét não nạn nhân, lưu bản sao vào bộ nhớ để nghiên cứu hoặc hồi sinh trong tương lai."
Hãy phân tích kỹ kịch bản này. Ngay cả hiện tại, cũng đã có những công nghệ đang được phát triển có thể khiến chiến thắng "sạch sẽ gọn gàng" kiểu này của AI trở nên kém thực tế:
-
Lọc không khí, hệ thống thông gió và đèn tia cực tím, có thể giảm đáng kể tỷ lệ lây lan bệnh truyền qua không khí;
-
Hai công nghệ phát hiện thụ động theo thời gian thực: phát hiện thụ động nhiễm trùng trong cơ thể người trong vài giờ và gửi thông báo, cũng như phát hiện nhanh trình tự virus mới chưa biết trong môi trường;
-
Nhiều phương pháp tăng cường và kích hoạt hệ miễn dịch, hiệu quả, an toàn và phổ quát hơn vắc-xin COVID, dễ sản xuất tại chỗ, giúp cơ thể chống lại các đại dịch tự nhiên lẫn nhân tạo. Con người tiến hóa trong môi trường dân số toàn cầu chỉ 8 triệu người, dành phần lớn thời gian ở ngoài trời, do đó trực giác cho thấy chúng ta nên có thể thích nghi dễ dàng với thế giới đe dọa hơn hiện nay.
Kết hợp các phương pháp này, có thể giảm số người bị lây nhiễm trung bình của bệnh truyền qua không khí (R0) xuống 10-20 lần (ví dụ: lọc không khí tốt hơn giảm 4 lần lây lan, cách ly ngay lập tức người nhiễm giảm 3 lần, tăng cường miễn dịch hô hấp đơn giản giảm 1.5 lần), thậm chí còn hơn nữa. Điều này đủ để khiến tất cả các bệnh truyền qua không khí hiện có (kể cả sởi) không thể lây lan, và con số này còn xa mới đạt đến tối ưu lý thuyết.
Nếu chuỗi gen virus theo thời gian thực được áp dụng rộng rãi để phát hiện sớm, thì ý tưởng về "vũ khí sinh học âm thầm lây lan khắp dân số toàn cầu mà không kích hoạt cảnh báo" trở nên rất đáng ngờ. Cần lưu ý rằng, ngay cả các phương pháp nâng cao như "giải phóng nhiều đại dịch và chất hóa học chỉ nguy hiểm khi kết hợp" cũng có thể bị phát hiện.
Đừng quên rằng chúng ta đang thảo luận trong giả định của "AI 2027": đến năm 2030, robot nano và cầu Dyson được liệt kê là "công nghệ nổi bật". Điều này có nghĩa là hiệu suất sẽ tăng mạnh, và việc triển khai rộng rãi các biện pháp ứng phó trên càng đáng mong đợi hơn. Mặc dù vào năm 2025 này, hành động của con người chậm chạp, trì trệ, nhiều dịch vụ chính phủ vẫn phụ thuộc vào giấy tờ. Nếu AI mạnh nhất thế giới có thể biến rừng và đồng ruộng thành nhà máy và trang trại năng lượng mặt trời trước năm 2030, thì AI mạnh thứ hai thế giới cũng có thể lắp đặt hàng loạt cảm biến, đèn và bộ lọc cho các tòa nhà của chúng ta trước năm 2030.
Nhưng hãy đi xa hơn theo giả định của "AI 2027", bước vào thế giới khoa học viễn tưởng thuần túy:
-
Lọc không khí vi mô bên trong cơ thể (mũi, miệng, phổi);
-
Quy trình tự động từ phát hiện tác nhân gây bệnh mới đến tinh chỉnh hệ miễn dịch để chống lại nó, có thể áp dụng ngay lập tức;
-
Nếu "tải lên ý thức" khả thi, chỉ cần thay thế toàn bộ cơ thể bằng robot Tesla Optimus hoặc Unitree;
-
Các công nghệ sản xuất mới (trong nền kinh tế robot rất có thể được siêu tối ưu hóa) sẽ sản xuất tại chỗ nhiều thiết bị bảo vệ hơn hiện tại rất nhiều, không cần phụ thuộc vào chuỗi cung ứng toàn cầu.
Trong một thế giới mà ung thư và lão hóa sẽ được chữa khỏi vào tháng 1 năm 2029, và tiến bộ công nghệ tiếp tục tăng tốc, đến giữa năm 2030, thật khó tin là chúng ta lại không có thiết bị đeo người có thể in sinh học và tiêm chất theo thời gian thực để bảo vệ cơ thể khỏi mọi nhiễm trùng (và độc tố).
Các lập luận phòng thủ sinh học trên chưa bao gồm "sự sống phản chiếu" và "máy bay không người lái sát thủ nhỏ bằng muỗi" (kịch bản "AI 2027" dự đoán sẽ xuất hiện từ năm 2029). Nhưng những phương tiện này không thể đạt được chiến thắng "sạch sẽ gọn gàng" đột ngột như mô tả trong "AI 2027", và trực giác cho thấy các biện pháp phòng thủ đối xứng chống lại chúng dễ thực hiện hơn nhiều.
Vì vậy, vũ khí sinh học thực tế khó có thể hủy diệt hoàn toàn nhân loại theo cách mô tả trong kịch bản "AI 2027". Tất nhiên, tất cả các kết quả tôi mô tả cũng xa mới đạt đến "chiến thắng sạch sẽ gọn gàng" cho nhân loại. Bất kể chúng ta làm gì (có lẽ trừ "tải lên ý thức vào robot"), một cuộc chiến sinh học AI toàn diện vẫn cực kỳ nguy hiểm. Tuy nhiên, đạt được tiêu chuẩn "chiến thắng sạch sẽ gọn gàng cho nhân loại" không cần thiết: chỉ cần tấn công có xác suất cao thất bại một phần, là đủ để tạo thành răn đe mạnh mẽ đối với AI đã chiếm vị thế thống trị, ngăn chặn nó thử mọi cuộc tấn công. Tất nhiên, đường thời gian phát triển AI càng dài, các biện pháp phòng thủ này càng có khả năng phát huy đầy đủ tác dụng.
Vậy nếu kết hợp vũ khí sinh học với các hình thức tấn công khác thì sao?
Để các biện pháp ứng phó trên thành công, cần thỏa mãn ba điều kiện tiên quyết:
-
An ninh vật lý thế giới (bao gồm an ninh sinh học và chống máy bay không người lái) do các cơ quan địa phương (con người hoặc AI) quản lý, chứ không phải tất cả đều là con rối của Consensus-1 (tên AI cuối cùng kiểm soát thế giới và hủy diệt nhân loại trong kịch bản "AI 2027");
-
Consensus-1 không thể xâm nhập vào hệ thống phòng thủ của các quốc gia (hoặc thành phố, khu vực an toàn khác) và vô hiệu hóa ngay lập tức;
-
Consensus-1 chưa kiểm soát toàn bộ lĩnh vực thông tin đến mức không ai còn muốn tự vệ.
Trực giác cho thấy, kết quả của điều kiện (1) có thể hướng tới hai cực đoan. Hiện nay, một số lực lượng cảnh sát tập trung cao, có hệ thống chỉ huy quốc gia mạnh mẽ, trong khi một số khác mang tính địa phương hóa. Nếu an ninh vật lý phải chuyển đổi nhanh để đáp ứng nhu cầu thời đại AI,格局 sẽ được thiết lập lại hoàn toàn, kết quả mới sẽ phụ thuộc vào lựa chọn trong vài năm tới. Các chính phủ có thể lười biếng, đều phụ thuộc vào Palantir; hoặc chủ động chọn giải pháp kết hợp phát triển địa phương và công nghệ nguồn mở. Tôi cho rằng, ở đây chúng ta cần đưa ra lựa chọn đúng đắn.
Nhiều lập luận bi quan về các chủ đề này giả định rằng (2) và (3) đã vô phương cứu chữa. Vì vậy, hãy phân tích kỹ hai điểm này.
Thảm họa an ninh mạng còn xa mới xảy ra
Quan điểm phổ biến giữa công chúng và chuyên gia là an ninh mạng thực sự là không thể, chúng ta nhiều nhất chỉ có thể vá lỗi nhanh chóng sau khi phát hiện ra, và răn đe kẻ tấn công bằng cách tích trữ các lỗ hổng đã phát hiện. Có lẽ, điều tốt nhất chúng ta có thể đạt được là cảnh tượng kiểu "Battlestar Galactica": gần như tất cả tàu vũ trụ của loài người bị vô hiệu hóa đồng thời bởi cuộc tấn công mạng của Cylons, chỉ còn lại một tàu sống sót vì không sử dụng bất kỳ công nghệ kết nối mạng nào. Tôi không đồng ý với quan điểm này. Ngược lại, tôi cho rằng "trạng thái cuối cùng" của an ninh mạng có lợi cho bên phòng thủ, và trong bối cảnh phát triển công nghệ nhanh chóng như giả định trong "AI 2027", chúng ta có thể đạt được trạng thái này.
Một cách hiểu là sử dụng kỹ thuật yêu thích của các nhà nghiên cứu AI: ngoại suy xu hướng. Dưới đây là đường xu hướng dựa trên khảo sát nghiên cứu GPT, giả định sử dụng công nghệ an toàn hàng đầu, tỷ lệ lỗi trên mỗi nghìn dòng mã thay đổi theo thời gian như sau.
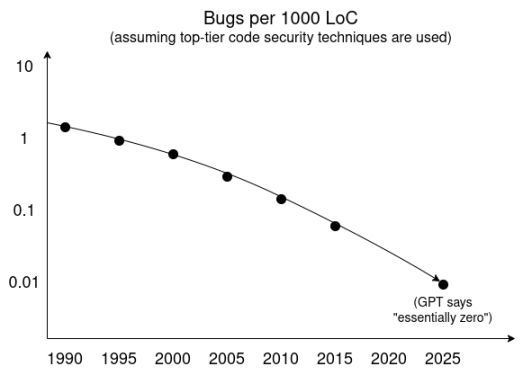
Bên cạnh đó, chúng ta đã chứng kiến tiến bộ đáng kể trong công nghệ sandbox và các kỹ thuật cách ly khác cũng như giảm thiểu cơ sở mã tin cậy, cả trong phát triển lẫn phổ cập người dùng. Trong ngắn hạn, các công cụ phát hiện lỗi siêu thông minh độc quyền của kẻ tấn công có thể tìm thấy rất nhiều lỗi. Nhưng nếu các tác nhân thông minh cao độ dùng để phát hiện lỗi hoặc xác minh hình thức mã là công khai, thì trạng thái cân bằng tự nhiên sẽ là: các nhà phát triển phần mềm phát hiện tất cả lỗi trước khi phát hành mã thông qua quy trình tích hợp liên tục.
Tôi có thể thấy hai lý do thuyết phục giải thích tại sao ngay cả trong thế giới này, lỗi cũng không thể loại bỏ hoàn toàn:
-
Khuyết điểm bắt nguồn từ sự phức tạp vốn có của ý định con người, do đó khó khăn chính nằm ở việc xây dựng mô hình ý định đủ chính xác, chứ không phải ở mã code;
-
Đối với các thành phần không then chốt về an ninh, chúng ta có thể tiếp tục xu hướng hiện có trong lĩnh vực công nghệ tiêu dùng: viết thêm nhiều mã để xử lý nhiều nhiệm vụ hơn (hoặc cắt giảm ngân sách phát triển), thay vì hoàn thành cùng lượng nhiệm vụ với tiêu chuẩn an ninh ngày càng cao.
Tuy nhiên, các danh mục này đều không áp dụng cho tình huống "kẻ tấn công có thể lấy quyền root của các hệ thống duy trì sự sống của chúng ta", và đây chính là trọng tâm của cuộc thảo luận.
Tôi thừa nhận rằng quan điểm của tôi lạc quan hơn quan điểm chủ lưu hiện nay trong giới chuyên gia an ninh mạng. Nhưng ngay cả khi bạn không đồng ý với tôi trong bối cảnh thế giới hiện tại, cũng đáng nhớ rằng: kịch bản "AI 2027" giả định sự tồn tại của trí tuệ siêu cấp. Ít nhất, nếu "100 triệu bản sao trí tuệ siêu cấp suy nghĩ nhanh gấp 2400 lần con người" cũng không thể giúp chúng ta có được mã không có lỗi như vậy, thì chắc chắn chúng ta nên tái đánh giá xem trí tuệ siêu cấp có thực sự mạnh mẽ như tác giả tưởng tượng hay không.
Ở mức độ nào đó, chúng ta không chỉ cần nâng cao đáng kể tiêu chuẩn an toàn phần mềm, mà còn cần nâng cao tiêu chuẩn an toàn phần cứng. IRIS là một nỗ lực hiện tại nhằm cải thiện khả năng xác minh phần cứng. Chúng ta có thể lấy IRIS làm điểm khởi đầu, hoặc tạo ra công nghệ tốt hơn. Thực tế, điều này có thể liên quan đến phương pháp "xây dựng đúng": quy trình sản xuất phần cứng của các thành phần then chốt được thiết kế cố ý với các bước xác minh cụ thể. Những công việc này sẽ được tự động hóa bằng AI đơn giản hóa đáng kể.
Thảm họa sức thuyết phục siêu cấp còn xa mới xảy ra
Như đã nói, một tình huống khác khiến khả năng phòng thủ tăng mạnh cũng có thể vô ích là: AI thuyết phục đủ nhiều người rằng không cần phòng thủ trước mối đe dọa từ AI siêu trí tuệ, và bất kỳ ai cố gắng tìm kiếm biện pháp phòng thủ cho bản thân hoặc cộng đồng đều là tội phạm.
Tôi luôn cho rằng, có hai việc có thể nâng cao khả năng chống lại sức thuyết phục siêu cấp:
-
Một hệ sinh thái thông tin ít đơn cực hơn. Có thể nói, chúng ta đang dần bước vào thời kỳ hậu Twitter, internet đang trở nên phân mảnh hơn. Đây là điều tốt (ngay cả khi quá trình phân mảnh là hỗn loạn), tổng thể chúng ta cần thêm nhiều đa cực thông tin.
-
AI phòng thủ. Cá nhân cần được trang bị AI chạy cục bộ, rõ ràng trung thành với mình, để cân bằng các mô hình tối tăm và mối đe dọa họ thấy trên internet. Những ý tưởng kiểu này đã có thử nghiệm rời rạc (như ứng dụng "kiểm tra tin nhắn" ở Đài Loan, quét cục bộ trên điện thoại), và có thị trường tự nhiên để kiểm tra thêm các ý tưởng này (ví dụ: bảo vệ mọi người khỏi lừa đảo), nhưng lĩnh vực này cần thêm nhiều nỗ lực.
Từ trên xuống: kiểm tra URL, kiểm tra địa chỉ tiền mã hóa, kiểm tra tin đồn. Các ứng dụng kiểu này có thể trở nên cá nhân hóa hơn, do người dùng kiểm soát và mạnh mẽ hơn.
Trận đấu này không nên là siêu thuyết phục siêu trí tuệ chống lại bạn, mà nên là siêu thuyết phục siêu trí tuệ chống lại bạn cộng với một bộ phân tích hơi yếu hơn nhưng vẫn thuộc loại siêu trí tuệ, phục vụ riêng cho bạn.
Đây là điều nên xảy ra. Nhưng liệu nó thực sự xảy ra không? Trong khoảng thời gian ngắn được giả định trong kịch bản "AI 2027", việc phổ cập công nghệ phòng thủ thông tin là một mục tiêu rất khó khăn. Nhưng có thể nói, các cột mốc nhẹ nhàng hơn đã là đủ. Nếu quyết định tập thể là quan trọng nhất, và như kịch bản "AI 2027" cho thấy, tất cả sự kiện quan trọng đều xảy ra trong một chu kỳ bầu cử, thì nghiêm túc mà nói, điều quan trọng là đảm bảo những người ra quyết định trực tiếp (chính trị gia, công chức, lập trình viên doanh nghiệp và các bên tham gia khác) có thể sử dụng các công nghệ phòng thủ thông tin tốt. Điều này khả thi hơn nhiều trong ngắn hạn, và theo kinh nghiệm của tôi, nhiều người trong số này đã quen với việc trao đổi với nhiều AI để hỗ trợ ra quyết định.
Bài học rút ra
Trong thế giới "AI 2027", người ta mặc nhiên cho rằng siêu trí tuệ nhân tạo có thể dễ dàng và nhanh chóng tiêu diệt phần còn lại của nhân loại là điều đã định, do đó điều duy nhất chúng ta có thể làm là cố gắng đảm bảo AI dẫn đầu là nhân từ. Theo tôi, thực tế phức tạp hơn nhiều: liệu AI dẫn đầu có đủ mạnh để dễ dàng tiêu diệt phần còn lại của nhân loại (và các AI khác), câu trả lời cho câu hỏi này vẫn còn gây tranh cãi lớn, và chúng ta có thể hành động để ảnh hưởng đến kết quả này.
Nếu các lập luận này đúng, thì bài học rút ra cho chính sách hiện tại đôi khi giống, đôi khi khác với "nguyên tắc an toàn AI chủ lưu":
Việc làm chậm sự phát triển của AI siêu trí tuệ vẫn là điều tốt. AI siêu trí tuệ xuất hiện sau 10 năm an toàn hơn sau 3 năm, và an toàn hơn nữa nếu xuất hiện sau 30 năm. Việc dành thêm thời gian chuẩn bị cho nền văn minh nhân loại là có lợi.
Việc làm điều này là một thách thức. Tôi cho rằng việc đề xuất của Mỹ về "cấm quản lý AI cấp bang trong 10 năm" bị bác bỏ là điều tốt nói chung, nhưng đặc biệt sau khi các đề xuất sơ kỳ như SB-1047 thất bại, hướng đi tiếp theo trở nên không rõ ràng. Tôi cho rằng cách ít xâm phạm và vững chắc nhất để làm chậm sự phát triển của AI rủi ro cao có thể liên quan đến một hiệp ước nào đó quy định phần cứng tiên tiến nhất. Nhiều công nghệ an ninh phần cứng cần thiết để đạt được phòng thủ hiệu quả cũng giúp xác minh hiệp ước phần cứng quốc tế, do đó thậm chí còn có hiệu ứng cộng hưởng.
Tuy nhiên, cần lưu ý rằng, tôi cho rằng nguồn rủi ro chính đến từ các thực thể liên quan đến quân sự, họ sẽ cố gắng giành miễn trừ khỏi các hiệp ước như vậy; điều này tuyệt đối không được phép, nếu cuối cùng họ được miễn trừ, thì việc phát triển AI do quân đội thúc đẩy có thể làm tăng rủi ro.
Các nỗ lực phối hợp để AI có nhiều khả năng làm điều tốt và ít khả năng làm điều xấu vẫn có lợi. Ngoại lệ chính (và luôn như vậy) là khi các nỗ lực phối hợp cuối cùng lại trở thành việc nâng cao năng lực.
Quy định tăng cường tính minh bạch của phòng thí nghiệm AI vẫn có lợi. Khuyến khích phòng thí nghiệm AI hành xử đúng đắn có thể giảm rủi ro, và minh bạch là một cách tốt để đạt được mục tiêu này.
Tâm lý 'mở nguồn có hại' trở nên rủi ro hơn. Nhiều người phản đối AI trọng số mở, với lý do phòng thủ là không thực tế, triển vọng duy nhất là người tốt có AI tốt sẽ đạt được siêu trí tuệ trước bất kỳ ai kém thiện chí hơn, giành được mọi năng lực cực kỳ nguy hiểm. Nhưng các lập luận trong bài viết này vẽ nên một bức tranh khác: phòng thủ không thực tế chính là vì một thực thể dẫn trước quá xa, trong khi các thực thể khác không theo kịp. Việc khuếch tán công nghệ để duy trì cán cân sức mạnh trở nên quan trọng. Tuy nhiên, tôi tuyệt đối không cho rằng việc tăng tốc độ phát triển năng lực AI tiên tiến chỉ vì nó được thực hiện dưới hình thức mã nguồn mở là điều tốt.
Tâm lý 'chúng ta phải đánh bại Trung Quốc' trong các phòng thí nghiệm Mỹ trở nên rủi ro hơn, vì lý do tương tự. Nếu bá quyền không phải là đệm an toàn, mà là nguồn rủi ro, thì điều này càng bác bỏ thêm quan điểm (rất tiếc lại quá phổ biến) rằng "những người thiện chí nên tham gia các phòng thí nghiệm AI dẫn đầu, giúp họ thắng nhanh hơn".
Các sáng kiến như 'AI công cộng' nên được ủng hộ nhiều hơn, vừa để đảm bảo sự phân bố rộng rãi năng lực AI, vừa để đảm bảo các thực thể cơ sở hạ tầng thực sự có công cụ, có thể nhanh chóng ứng dụng các năng lực AI mới theo một số cách như mô tả trong bài viết này.
Công nghệ phòng thủ nên thể hiện nhiều hơn triết lý 'cừu được trang bị vũ khí', chứ không phải 'săn giết mọi con sói'. Thảo luận về giả thuyết thế giới mong manh thường giả định rằng giải pháp duy nhất là một quốc gia bá quyền duy trì giám sát toàn cầu để ngăn chặn mọi mối đe dọa tiềm tàng xuất hiện. Nhưng trong thế giới phi bá quyền, đây không phải là phương pháp khả thi, và các cơ chế phòng thủ từ trên xuống dễ bị AI mạnh mẽ lật đổ, biến thành công cụ tấn công. Do đó, trách nhiệm phòng thủ lớn hơn cần được thực hiện thông qua nỗ lực gian khổ, nhằm giảm sự mong manh của thế giới.
Các lập luận trên chỉ mang tính suy đoán, không nên hành động dựa trên giả định gần như chắc chắn từ những lập luận này. Nhưng câu chuyện "AI 2027" cũng mang tính suy đoán, và chúng ta nên tránh hành động dựa trên giả định rằng "chi tiết cụ thể của nó gần như chắc chắn".
Tôi đặc biệt lo ngại về một giả định phổ biến: thiết lập một bá quyền AI, đảm bảo nó "liên minh" và "thắng cuộc đua", là con đường duy nhất tiến lên phía trước. Theo tôi, chiến lược này rất có thể làm giảm an toàn của chúng ta —— đặc biệt khi bá quyền gắn chặt với ứng dụng quân sự, điều này làm giảm hiệu quả của nhiều chiến lược liên minh. Một khi AI bá quyền lệch hướng, nhân loại sẽ mất đi mọi biện pháp kiềm chế.
Trong kịch bản "AI 2027", thành công của nhân loại phụ thuộc vào việc Mỹ chọn con đường an toàn thay vì hủy diệt vào thời điểm then chốt —— tự nguyện làm chậm tiến độ AI, đảm bảo quá trình tư duy nội bộ của Agent-5 có thể được con người diễn giải. Ngay cả như vậy, thành công cũng không chắc chắn, và cách nhân loại thoát khỏi vách đá sống còn liên tục phụ thuộc vào tư duy của một siêu trí tuệ đơn lẻ vẫn chưa rõ ràng. Bất kể AI phát triển ra sao trong 5-10 năm tới, việc thừa nhận rằng "giảm sự mong manh của thế giới là khả thi" và đầu tư thêm nỗ lực để đạt được điều này bằng công nghệ mới nhất của con người, là một con đường đáng thử.
Đặc biệt cảm ơn phản hồi và rà soát của các tình nguyện viên Balvi.
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News










