Phía sau ánh trăng - Tự thuật của tác giả cốt lõi MoBA: Hành trình ba lần vào Thủy Quá Nhai của một "thực tập viên mới nổi trong huấn luyện mô hình lớn"
Tuyển chọn TechFlowTuyển chọn TechFlow
Phía sau ánh trăng - Tự thuật của tác giả cốt lõi MoBA: Hành trình ba lần vào Thủy Quá Nhai của một "thực tập viên mới nổi trong huấn luyện mô hình lớn"
"Từ luận văn mã nguồn mở, mã nguồn mở, hiện nay đã phát triển đến chuỗi tư duy mã nguồn mở rồi à!"
Tác giả: Andrew Lu, đội ngũ LatePost

Nguồn hình ảnh: Được tạo bởi Wujie AI
Ngày 18 tháng 2, Kimi và DeepSeek cùng ngày công bố tiến triển mới, lần lượt là MoBA và NSA, cả hai đều là cải tiến đối với "cơ chế chú ý" (Attention Mechanism).
Hôm nay, một trong những thành viên chính phát triển MoBA, Andrew Lu, đăng bài trên Zhihu tự thuật ba lần vấp ngã trong quá trình nghiên cứu, anh gọi đó là "ba lần vào Thủy Quá Nhai". Chữ ký của anh trên Zhihu là "người huấn luyện LLM mới nổi".
Một bình luận dưới bài viết này là: "Từ việc mở mã nguồn luận văn, mã nguồn, hiện nay đã tiến hóa đến mức mở luôn dây chuyền tư duy rồi."
Cơ chế chú ý quan trọng vì đây là cơ chế cốt lõi của các mô hình ngôn ngữ lớn (LLM) hiện tại. Trở lại bài báo Transformer tám tác giả ra đời vào tháng 6 năm 2017, khởi đầu cuộc cách mạng LLM, tiêu đề là: Attention Is All You Need (Chú ý là tất cả những gì bạn cần), bài báo này đến nay đã được trích dẫn tới 153.000 lần.
Cơ chế chú ý giúp mô hình AI giống con người, biết khi xử lý thông tin nên "tập trung chú ý" điều gì và "bỏ qua" điều gì, từ đó nắm bắt phần thông tin then chốt nhất.
Trong giai đoạn huấn luyện và sử dụng (suy luận) mô hình lớn, cơ chế chú ý đều phát huy tác dụng. Nguyên lý hoạt động cơ bản là khi đưa vào một đoạn dữ liệu, ví dụ như "Tôi thích ăn táo", mô hình lớn sẽ tính toán mối quan hệ giữa từng từ (Token) với các từ khác trong câu để hiểu ngữ nghĩa và các thông tin liên quan.
Khi mô hình lớn cần xử lý ngữ cảnh ngày càng dài, cơ chế Full Attention (chú ý toàn phần) mà Transformer ban đầu áp dụng khiến tài nguyên tính toán bị chiếm dụng quá mức, bởi quy trình ban đầu yêu cầu phải tính toàn bộ điểm quan trọng của mọi từ đầu vào, sau đó tính trọng số để xác định từ nào quan trọng nhất; độ phức tạp tính toán tăng theo cấp số bình phương (phi tuyến) khi văn bản dài ra. Như phần "tóm tắt" trong bài báo MoBA viết:
"Sự gia tăng bậc hai về độ phức tạp tính toán vốn có trong cơ chế chú ý truyền thống dẫn đến chi phí tính toán cao đến mức đáng sợ."
Đồng thời, các nhà nghiên cứu vẫn luôn mong muốn mô hình lớn có thể xử lý ngữ cảnh đủ dài —— hội thoại đa vòng, suy luận phức tạp, khả năng ghi nhớ... Những đặc tính mà AGI lý tưởng cần có đều đòi hỏi khả năng xử lý ngữ cảnh cực kỳ dài.
Vì vậy, việc tìm ra một phương pháp tối ưu hóa cơ chế chú ý vừa tiết kiệm tài nguyên tính toán và bộ nhớ, vừa không làm giảm hiệu suất mô hình, trở thành chủ đề quan trọng trong nghiên cứu mô hình lớn.
Đây là bối cảnh kỹ thuật khiến nhiều công ty đổ dồn sự chú ý vào "chú ý".
Bên cạnh DeepSeek NSA và Kimi MoBA, vào giữa tháng 1 năm nay, một công ty khởi nghiệp mô hình lớn Trung Quốc khác là MiniMax cũng đã triển khai quy mô lớn một cơ chế chú ý mới trong mô hình mã nguồn mở đầu tiên của họ MiniMax-01. Người sáng lập MiniMax, Yan Junjie, lúc đó cho chúng tôi biết đây là một trong những điểm đổi mới quan trọng nhất của MiniMax-01.
Đội nhóm của Liu Zhiyuan, phó giáo sư khoa Máy tính Đại học Thanh Hoa, đồng sáng lập công ty Bàn Bỉ Trí Năng, cũng từng công bố InfLLM vào năm 2024, trong đó cũng liên quan đến một cải tiến cơ chế chú ý thưa, bài báo này được trích dẫn trong bài báo NSA.
Trong các kết quả này, cơ chế chú ý trong NSA, MoBA, InfLLm đều thuộc loại "cơ chế chú ý thưa" (Sparse Attention); còn hướng thử nghiệm của MiniMax-01 chủ yếu là một hướng khác: "cơ chế chú ý tuyến tính" (Linear Attention).
Theo Cao Shijie, một trong các tác giả SeerAttention, nhà nghiên cứu cao cấp viện nghiên cứu Microsoft Asia, nói rằng nhìn chung, cơ chế chú ý tuyến tính thay đổi nhiều hơn, triệt để hơn so với cơ chế chú ý chuẩn, nhằm giải quyết trực tiếp vấn đề độ phức tạp tính toán tăng theo cấp số bình phương khi văn bản dài ra (do đó là phi tuyến), nhưng có thể đánh mất khả năng nắm bắt các mối phụ thuộc phức tạp trong ngữ cảnh dài; trong khi cơ chế chú ý thưa tận dụng tính thưa vốn có của chú ý, cố gắng tìm kiếm một cách tối ưu hóa ổn định hơn.
Đồng thời xin giới thiệu bài trả lời nổi tiếng của Cao Shijie trên Zhihu về cơ chế chú ý: https://www.zhihu.com/people/cao-shi-jie-67/answers
(Anh ấy trả lời câu hỏi: "Cơ chế chú ý NSA trong bài báo mới của DeepSeek do Liang Wenfeng tham gia công bố có những thông tin đáng chú ý nào? Sẽ gây ra ảnh hưởng gì?")
Fu Tianyu, tiến sĩ phòng thí nghiệm NICS-EFC Đại học Thanh Hoa, đồng tác giả chính MoA (Mixture of Sparse Attention), nói rằng trong định hướng lớn của cơ chế chú ý thưa: "NSA và MoBA đều đưa vào phương pháp chú ý động, tức có thể chọn động các khối KV Cache cần tính toán chú ý chi tiết, so với một số cơ chế chú ý thưa dùng phương pháp tĩnh, có thể nâng cao hiệu suất mô hình. Hai phương pháp này đều đưa cơ chế chú ý thưa vào ngay trong quá trình huấn luyện mô hình chứ không chỉ trong suy luận, điều này càng nâng cao thêm hiệu suất mô hình."
(Ghi chú: Khối KV Cache là vùng đệm lưu trữ Key và Value đã tính trước đó; trong đó Key là nhãn dùng trong tính toán cơ chế chú ý, để nhận diện đặc trưng dữ liệu hoặc vị trí, giúp khi tính trọng số chú ý có thể khớp và liên kết với dữ liệu khác, còn Value tương ứng với Key, thường chứa nội dung dữ liệu thực tế cần xử lý, ví dụ như vector ngữ nghĩa của từ hoặc cụm từ.)
Đồng thời, lần này Moonshot ngoài việc công bố chi tiết bài báo kỹ thuật MoBA, còn công bố mã nguồn kỹ thuật MoBA trên trang GitHub của dự án, bộ mã này đã được sử dụng trực tuyến trong sản phẩm Kimi của Moonshot hơn một năm.
* Dưới đây là tự thuật của Andrew Lu trên Zhihu, đã được tác giả cho phép. Trong nguyên bản có nhiều thuật ngữ AI, phần chữ xám trong () là chú thích của biên tập viên. Liên kết bài gốc: https://www.zhihu.com/people/deer-andrew
Tự thuật nghiên cứu của Andrew Lu
Theo lời mời của thầy Chương (giảng viên trợ lý Đại học Thanh Hoa Chương Minh Tinh), tôi xin trả lời về hành trình thăng trầm khi làm MoBA, tôi gọi vui là "ba lần vào Thủy Quá Nhai". (Andrew Lu đang trả lời câu hỏi: "Đánh giá thế nào về khung chú ý thưa MoBA do Kimi công bố mã nguồn? So với NSA của DeepSeek, mỗi bên có điểm nổi bật gì?")
Bắt đầu với MoBA
Dự án MoBA bắt đầu rất sớm, vào cuối tháng 5 năm 2023, ngay ngày đầu gia nhập Moonshot, tôi bị Tim (đồng sáng lập Moonshot Chu Tinh Vũ) kéo vào phòng nhỏ cùng thầy Cầu (Cầu Tiết Trung, Đại học Chiết Giang / Phòng thí nghiệm Chi Giang, người đề xuất ý tưởng MoBA) và Dylan (nhà nghiên cứu Moonshot) bắt đầu làm Long Context Training (huấn luyện ngữ cảnh dài). Trước tiên xin cảm ơn Tim vì sự kiên nhẫn và hướng dẫn, đã đặt niềm tin lớn vào một tay mơ LLM và sẵn sàng đào tạo, trong số các chuyên gia phát triển mô hình上线 và các công nghệ liên quan, nhiều người như tôi gần như bắt đầu từ con số 0 với LLM.
Lúc đó trình độ ngành nói chung chưa cao, mọi người đều đang ở mức tiền huấn luyện 4K (chiều dài đầu vào/ra mô hình khoảng 4000 Token, vài nghìn chữ Hán), dự án ban đầu tên là 16K on 16B, ý là trên mô hình 16B (16 tỷ tham số) thực hiện Pre-train (tiền huấn luyện) độ dài 16K là được, tuy nhiên sau đó nhu cầu này nhanh chóng thay đổi vào tháng 8, cần hỗ trợ Pre-train ở độ dài 128K. Đây cũng là yêu cầu đầu tiên khi thiết kế MoBA, có thể From Scratch (từ đầu) huấn luyện nhanh một mô hình hỗ trợ độ dài 128K, lúc này chưa cần Continue Training (tiếp tục huấn luyện trên mô hình đã huấn luyện).
Điều này cũng dẫn đến một câu hỏi thú vị, vào tháng 5/6 năm 23, ngành nói chung cho rằng huấn luyện dài, huấn luyện văn bản dài end-to-end (dùng trực tiếp văn bản dài để huấn luyện mô hình) tốt hơn huấn luyện mô hình ngắn rồi tìm cách kéo dài nó. Nhận thức này chỉ thay đổi khi vào nửa cuối năm 23 xuất hiện long Llama (mô hình lớn xử lý văn bản dài do Meta phát triển). Chúng tôi cũng đã kiểm chứng nghiêm ngặt, thực tế huấn luyện văn bản ngắn + kích hoạt độ dài mang lại hiệu quả token tốt hơn (mỗi token đóng góp lượng thông tin hiệu quả cao hơn, nghĩa là mô hình hoàn thành nhiệm vụ chất lượng cao hơn với ít token hơn). Do đó chức năng đầu tiên trong thiết kế MoBA trở thành nước mắt của thời đại.
Giai đoạn này, thiết kế cấu trúc MoBA cũng "cách mạng" hơn, so với kết quả "cực giản" hiện tại, MoBA ban đầu là một giải pháp nối tiếp hai tầng chú ý có cross attention (cơ chế chú ý xử lý mối quan hệ giữa hai đoạn dữ liệu khác nhau), bản thân gate (kiểm soát cách dữ liệu đầu vào phân bổ trọng số giữa các mạng chuyên gia) là cấu trúc không tham số (không có tham số, không cần dữ liệu huấn luyện), nhưng để học tốt hơn các token lịch sử, chúng tôi thêm vào mỗi tầng Transformer một cross attention liên máy và tham số tương ứng (có thể ghi nhớ thông tin lịch sử tốt hơn). Thiết kế MoBA lúc này đã kết hợp tư tưởng Context Parallel (toàn bộ chuỗi ngữ cảnh được lưu trên các nút khác nhau, chỉ tập trung lại khi cần tính toán), chúng tôi trải đều toàn bộ chuỗi ngữ cảnh lên các nút song song dữ liệu, coi mỗi ngữ cảnh trong mỗi nút song song dữ liệu là một expert (chuyên gia) trong MoE (Mixture of Experts, hệ thống chuyên gia hỗn hợp), gửi token cần attention đến expert tương ứng để thực hiện cross attention rồi gửi kết quả về. Chúng tôi tích hợp công việc fastmoe (một khung huấn luyện MoE sơ kỳ) vào Megatron-LM (khung huấn luyện mô hình lớn phổ biến hiện nay từ Nvidia) để hỗ trợ khả năng truyền thông giữa các expert.
Chúng tôi gọi ý tưởng này là MoBA v0.5.
(Chú thích biên tập viên: Cảm hứng MoBA đến từ cấu trúc MoE mô hình lớn chủ lưu hiện nay. MoE nghĩa là khi mô hình lớn hoạt động, chỉ kích hoạt tham số một phần chuyên gia, không phải toàn bộ, từ đó tiết kiệm năng lực tính toán; tư tưởng cốt lõi MoBA là "chỉ xem ngữ cảnh liên quan nhất mỗi lần, không phải toàn bộ ngữ cảnh, từ đó tiết kiệm tính toán và chi phí".)
Theo thời gian đến đầu tháng 8 năm 23, mô hình chính Pre-Train đã huấn luyện rất nhiều token, làm lại tốn kém. MoBA với cấu trúc thay đổi rõ rệt và thêm tham số phụ至此 lần đầu tiên bước vào Thủy Quá Nhai.
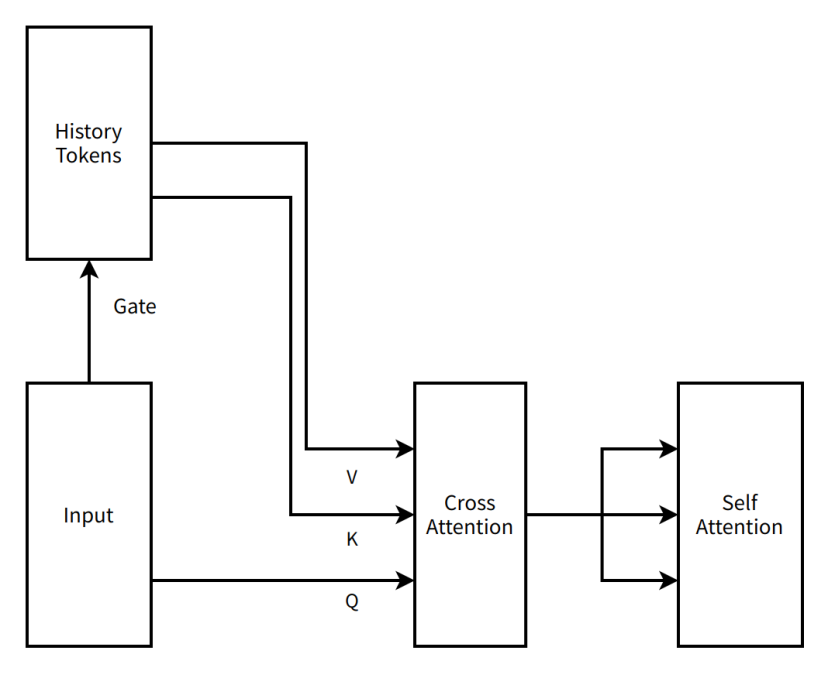
Sơ đồ minh họa rất đơn giản của MoBA v0.5
Chú thích biên tập viên:
History Tokens (token lịch sử) —— trong các tình huống xử lý ngôn ngữ tự nhiên, đại diện cho tập hợp các đơn vị văn bản đã xử lý trước đó.
Gate (cổng) —— trong mạng thần kinh, cấu trúc dùng để kiểm soát luồng thông tin
Input (đầu vào) —— dữ liệu hoặc thông tin mô hình nhận được
V (Value) —— trong cơ chế chú ý, chứa nội dung dữ liệu thực tế cần xử lý hoặc chú ý, ví dụ như vector ngữ nghĩa
K (Key - nhãn) —— trong cơ chế chú ý, nhãn dùng để nhận diện đặc trưng dữ liệu hoặc vị trí, để khớp và liên kết với dữ liệu khác
Q (Querry - truy vấn) —— trong cơ chế chú ý, vector dùng để truy xuất thông tin liên quan từ cặp khóa-giá trị
Cross Attention (chú ý chéo) —— một loại cơ chế chú ý, tập trung vào đầu vào từ nguồn khác nhau, ví dụ liên kết đầu vào với thông tin lịch sử
Self Attention (chú ý tự thân) —— một loại cơ chế chú ý, mô hình chú ý đến đầu vào của chính mình, nắm bắt phụ thuộc bên trong đầu vào
Lần thứ nhất vào Thủy Quá Nhai
"Vào Thủy Quá Nhai" đương nhiên là cách nói đùa, là thời gian dừng lại tìm giải pháp cải tiến, cũng là thời gian hiểu sâu cấu trúc mới. Lần đầu vào Thủy Quá Nhai tu luyện, vào nhanh, ra cũng nhanh. Tim với tư cách là "thiên tài ý tưởng" của Moonshot đưa ra ý tưởng cải tiến mới, thay đổi MoBA từ giải pháp nối tiếp hai tầng chú ý thành giải pháp song song một tầng chú ý. MoBA không còn thêm tham số mô hình phụ, mà dùng tham số cơ chế chú ý hiện có, đồng thời học tất cả thông tin trong chuỗi, từ đó có thể tận dụng tối đa cấu trúc hiện tại để Continue Training.
Chúng tôi gọi ý tưởng này là MoBA v1.
Thực tế MoBA v1 là sản phẩm của Sparse Attention (chú ý thưa) và Context Parallel, lúc đó Context Parallel chưa phổ biến, MoBA v1 thể hiện khả năng tăng tốc end-to-end rất cao. Sau khi kiểm chứng hiệu quả trên mô hình 3B, 7B, chúng tôi gặp tường khi mở rộng lên mô hình lớn hơn, xuất hiện hiện tượng loss spike (hiện tượng bất thường khi huấn luyện mô hình) rất lớn trong quá trình huấn luyện. Cách hợp nhất block attention output (kết quả đầu ra sau khi mô-đun chú ý xử lý xong dữ liệu) phiên bản đầu quá sơ sài, chỉ đơn giản cộng dồn, dẫn đến hoàn toàn không thể debug song song với Full Attention, việc debug không có ground truth (câu trả lời chuẩn, ở đây là kết quả Full Attention) cực kỳ khó khăn, chúng tôi dùng mọi biện pháp ổn định lúc đó cũng không giải quyết được. Vì huấn luyện trên mô hình lớn gặp vấn đề, MoBA至此 lần thứ hai bước vào Thủy Quá Nhai.
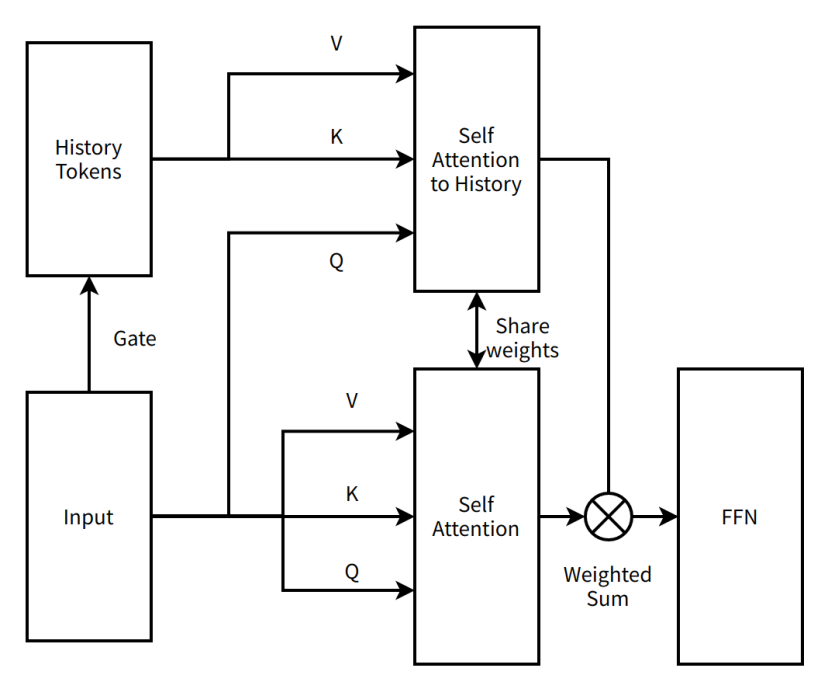
Sơ đồ minh họa rất đơn giản của MoBA v1
Chú thích biên tập viên:
Self Attention to History (chú ý tự thân với lịch sử) —— một loại cơ chế chú ý, mô hình chú ý đến token lịch sử, nắm bắt phụ thuộc giữa đầu vào hiện tại và thông tin lịch sử
Share weights (chia sẻ trọng số) —— các phần khác nhau trong mạng thần kinh dùng cùng trọng số tham số, nhằm giảm số lượng tham số và nâng cao khả năng tổng quát mô hình
FFN (Feed - Forward Neural Network, mạng thần kinh truyền thẳng) —— một cấu trúc mạng thần kinh cơ bản, dữ liệu chảy theo một hướng từ tầng đầu vào qua tầng ẩn đến tầng đầu ra
Weighted Sum (tổng trọng số) —— thao tác cộng dồn nhiều giá trị theo trọng số riêng của từng giá trị
Lần thứ hai vào Thủy Quá Nhai
Lần thứ hai ở lại Thủy Quá Nhai khá lâu, bắt đầu từ tháng 9 năm 23, đến khi ra khỏi Thủy Quá Nhai thì đã sang đầu năm 24. Nhưng ở trong Thủy Quá Nhai không có nghĩa là bị bỏ rơi, tôi được trải nghiệm đặc điểm làm việc thứ hai tại Moonshot: cứu trợ bão hòa.
Ngoài Tim và thầy Cầu luôn mạnh mẽ hỗ trợ, Tô Thần (Tô Kiến Lâm, nhà nghiên cứu Moonshot), Viễn Ca (Jingyuan Liu, nhà nghiên cứu Moonshot) cùng các cao thủ khác đều tham gia thảo luận sôi nổi, bắt đầu tháo gỡ và sửa chữa MoBA, điều đầu tiên được sửa là thao tác chồng Weighted Sum (tổng trọng số) đơn giản đó. Sau khi thử nhiều cách chồng ghép nhân cộng ma trận Gate, Tim lục trong đống tài liệu cũ tìm ra Online Softmax (không cần thấy hết dữ liệu mới tính được, mà đến một dữ liệu xử lý một), nói cái này chắc được. Lợi ích lớn nhất là sau khi dùng Online Softmax, chúng tôi có thể giảm độ thưa xuống 0 (chọn toàn bộ các khối), để đối chiếu debug nghiêm ngặt với Full Attention tương đương toán học, điều này giải quyết phần lớn khó khăn gặp phải trong thực hiện. Nhưng thiết kế chia ngữ cảnh trên các nút song song dữ liệu vẫn gây ra vấn đề mất cân bằng, sau khi trải đều một mẫu dữ liệu trên các nút song song dữ liệu, vài token đầu ở nút đầu tiên sẽ bị hàng loạt Q phía sau gửi đến tính attend (quá trình tính toán chú ý), gây mất cân bằng nghiêm trọng, từ đó làm chậm hiệu suất tăng tốc. Hiện tượng này còn có tên phổ biến hơn —— Attention Sink (điểm tụ chú ý).
Lúc này thầy Chương đến thăm, sau khi nghe ý tưởng của chúng tôi đã đưa ra ý tưởng mới, tách riêng khả năng Context Parallel và MoBA. Context Parallel là Context Parallel, MoBA là MoBA, MoBA trở về bản chất là một Sparse Attention chứ không phải khung huấn luyện Sparse Attention phân tán. Chỉ cần bộ nhớ GPU chứa được, hoàn toàn có thể xử lý toàn bộ ngữ cảnh trên một máy, dùng MoBA để tăng tốc tính toán, tổ chức và truyền ngữ cảnh giữa các máy theo cách Context Parallel. Vì vậy chúng tôi tái triển khai MoBA v2, về cơ bản đã là dạng MoBA hiện tại mọi người thấy.
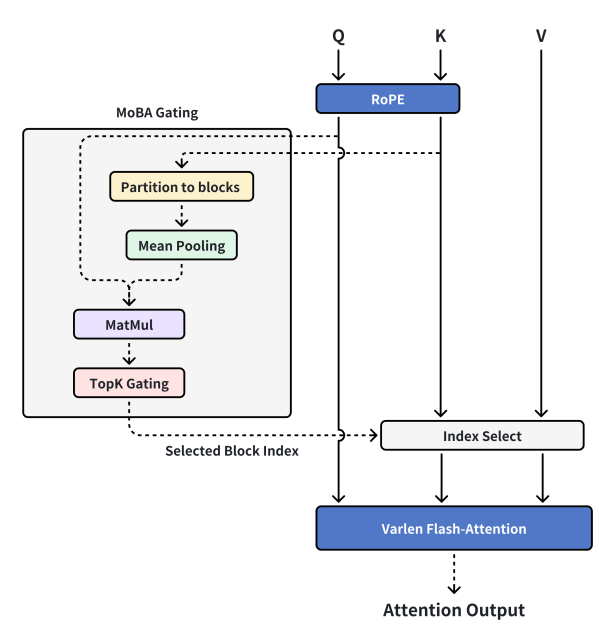
Thiết kế MoBA hiện tại
Chú thích biên tập viên:
MoBA Gating (điều khiển cổng MoBA) —— cơ chế điều khiển cổng đặc biệt trong MoBA
RoPE (Rotary Position Embedding - Nhúng vị trí xoay) —— kỹ thuật thêm thông tin vị trí cho chuỗi
Partition to blocks (phân chia thành khối) —— chia dữ liệu thành các khối khác nhau
Mean Pooling (trung bình hóa) —— thao tác giảm mẫu dữ liệu trong học sâu, tính giá trị trung bình của dữ liệu trong vùng
MatMul (Matrix - Multiply - Nhân ma trận) —— phép toán toán học dùng để tính tích hai ma trận
TopK Gating (điều khiển Top-K) —— cơ chế điều khiển cổng, chọn K phần tử quan trọng hàng đầu
Selected Block Index (chỉ số khối được chọn) —— biểu thị số hiệu khối được chọn
Index Select (chọn theo chỉ số) —— chọn phần tử tương ứng từ dữ liệu theo chỉ số
Varlen Flash-Attention (chú ý nhanh độ dài thay đổi) —— cơ chế chú ý phù hợp với chuỗi độ dài thay đổi và hiệu quả tính toán cao
Attention Output (đầu ra chú ý) —— kết quả đầu ra sau khi tính toán cơ chế chú ý
MoBA v2 ổn định, huấn luyện được, văn bản ngắn và Full Attention có thể hoàn toàn căn chỉnh, Scaling Law trông rất đáng tin cậy, và khá mượt mà khi áp dụng lên mô hình online. Vì vậy chúng tôi thêm nhiều tài nguyên hơn, sau một loạt debug và tiêu hao n đ把 tóc của đồng đội nhóm infra, chúng tôi có thể đưa mô hình Pretrain sau khi kích hoạt MoBA đạt điểm xanh toàn bộ trong bài test tìm kim (đạt tiêu chuẩn trong kiểm tra khả năng xử lý văn bản dài mô hình lớn), ở bước này chúng tôi cảm thấy rất tốt, bắt đầu上线.
Nhưng điều không bất ngờ nhất, chính là bất ngờ. Giai đoạn SFT (tinh chỉnh giám sát, trên cơ sở mô hình tiền huấn luyện, huấn luyện thêm mô hình cho nhiệm vụ cụ thể để nâng cao hiệu suất trên nhiệm vụ đó) một phần dữ liệu đi kèm mask loss rất thưa (chỉ 1% hoặc ít hơn token có gradient dùng để huấn luyện) (mask loss là kỹ thuật chọn phần nào tham gia đo lường kết quả dự đoán mô hình với câu trả lời chuẩn), điều này khiến MoBA biểu hiện tốt trên phần lớn nhiệm vụ SFT, nhưng càng là nhiệm vụ tóm tắt văn bản dài, mask loss càng thưa, phản ánh hiệu quả học tập càng thấp. MoBA bị nhấn nút tạm dừng trong quy trình上线, lần thứ ba bước vào Thủy Quá Nhai.
Lần thứ ba vào Thủy Quá Nhai
Lần thứ ba vào Thủy Quá Nhai thực sự căng thẳng nhất, lúc này toàn bộ dự án đã có chi phí chìm khổng lồ, công ty bỏ ra lượng lớn tài nguyên tính toán và nhân lực, nếu cuối cùng ứng dụng xử lý văn bản dài end-to-end gặp vấn đề, nghiên cứu trước đó gần như đổ sông đổ biển. May mắn thay, nhờ tính chất toán học tuyệt vời vốn có của MoBA, trong loạt thí nghiệm ablation (thí nghiệm loại trừ, nghiên cứu ảnh hưởng đến hiệu suất mô hình bằng cách loại bỏ một phần mô hình hoặc thay đổi thiết lập) cứu trợ bão hòa mới, chúng tôi phát hiện bỏ mask loss biểu hiện rất tốt, có mask loss biểu hiện không như ý, từ đó nhận ra token có gradient trong giai đoạn SFT quá thưa, dẫn đến vấn đề hiệu quả học tập thấp, do đó bằng cách sửa đổi vài tầng cuối thành Full Attention, nâng mật độ token có gradient trong lan truyền ngược, cải thiện hiệu quả học tập nhiệm vụ cụ thể. Các thí nghiệm sau đó chứng minh việc chuyển đổi này không ảnh hưởng đáng kể đến hiệu quả chú ý thưa khi chuyển lại, trên độ dài 1M (1 triệu) các chỉ số bằng với Full attention cấu trúc tương tự. MoBA một lần nữa trở về từ Thủy Quá Nhai, và thành công上线 phục vụ người dùng.
Cuối cùng, cảm ơn các cao thủ đã ra tay tương trợ, cảm ơn sự hỗ trợ mạnh mẽ của công ty và lượng lớn card đồ họa. Bây giờ chúng tôi công bố mã nguồn đang dùng online, là mã đã được kiểm chứng lâu dài, vì nhu cầu thực tế đã cắt bỏ mọi thiết kế phụ, giữ cấu trúc cực giản nhưng đồng thời đủ hiệu quả, cấu trúc Sparse Attention. Mong rằng MoBA cùng dây chuyền tư duy (CoT - Chain of Thought) sinh ra nó có thể mang lại chút giúp đỡ và giá trị cho mọi người.
FAQ
Nhân tiện trả lời một số câu hỏi thường xuyên bị hỏi mấy ngày nay, mấy ngày nay hầu như làm phiền thầy Chương và Tô Thần làm nhân viên chăm sóc khách hàng trả lời câu hỏi, thật sự quá áy náy, ở đây tôi tổng hợp vài câu hỏi thường gặp trả lời luôn.
1. MoBA vô hiệu với Decoding (quá trình tạo văn bản giai đoạn suy luận mô hình) sao?
MoBA có hiệu lực với Decoding, rất hiệu quả với MHA (Multi-Head Attention, chú ý đa đầu), hiệu quả giảm với GQA (Grouped Query Attention, chú ý truy vấn nhóm), hiệu quả kém nhất với MQA (Multi-Query Attention, chú ý truy vấn đa). Nguyên lý rất đơn giản, trong trường hợp MHA, mỗi Q có KV cache tương ứng riêng, thì gate MoBA trong điều kiện lý tưởng có thể tính toán và lưu trữ token đại diện cho mỗi block (khối dữ liệu) trong prefill (giai đoạn tính toán khi xử lý đầu vào lần đầu), token này sau đó sẽ không thay đổi, do đó mọi thao tác IO (nhập/xuất) cơ bản có thể chỉ đến từ KV cache sau index select (thao tác chọn dữ liệu theo chỉ số), trong trường hợp này mức độ thưa của MoBA quyết định mức độ giảm IO.
Nhưng với GQA và MQA, do một nhóm Q Head thực tế đang chia sẻ cùng một KV cache, thì trong điều kiện mỗi Q Head có thể tự do chọn Block quan tâm, rất có thể lấp đầy ưu thế tối ưu IO do tính thưa mang lại. Ví dụ ta xét tình huống này: 16 Q Head MQA, MoBA vừa hay chia toàn bộ chuỗi thành 16 phần, điều này có nghĩa là trong trường hợp xấu nhất mỗi Q head quan tâm lần lượt đến các khối ngữ cảnh thứ tự từ 1 đến 16, lợi thế tiết kiệm IO sẽ bị xóa sạch. Số lượng Q Head có thể tự do chọn KV Block càng nhiều, hiệu quả càng kém.
Do hiện tượng "Q Head tự do chọn KV Block" tồn tại, ý tưởng cải tiến tự nhiên là hợp nhất, giả sử mọi người đều chọn cùng Block, chẳng phải thu lợi thuần túy từ tối ưu IO sao. Đúng vậy, nhưng trong thử nghiệm thực tế của chúng tôi, đặc biệt với mô hình tiền huấn luyện đã trả chi phí lớn, mỗi Q head đều có "gu" riêng biệt, ép hợp nhất không bằng huấn luyện lại từ đầu.
2. Mặc định MoBA bắt buộc chọn self attention(cơ chế chú ý tự thân), vậy láng giềng self có bắt buộc chọn không?
Không bắt buộc, đây là điểm dễ gây nhầm lẫn, cuối cùng chúng tôi chọn tin SGD (Stochastic Gradient Descent - giảm dần gradient ngẫu nhiên). Việc thực hiện gate MoBA hiện tại rất trực tiếp, bạn bè quan tâm có thể đơn giản sửa đổi gate để bắt buộc chọn chunk (khối dữ liệu) trước đó, nhưng tự thử nghiệm chúng tôi thấy lợi ích từ thay đổi này khá margin (lợi ích nhỏ).
3. MoBA có triển khai Triton (khung viết mã GPU hiệu suất cao, do OpenAI phát triển) không?
Chúng tôi đã triển khai một phiên bản, hiệu suất end-to-end tăng hơn 10%, nhưng chi phí duy trì và cập nhật thường xuyên với phiên bản chính của triển khai Triton khá cao, do đó sau nhiều lần lặp lại chúng tôi tạm hoãn tối ưu hóa thêm.
*Địa chỉ dự án của các thành quả nhắc đến đầu bài viết (trang GitHub đều chứa liên kết paper kỹ thuật, DeepSeek tạm thời chưa上线 trang GitHub NSA):
Trang GitHub MoBA: https://github.com/MoonshotAI/MoBA
Bài báo kỹ thuật NSA: https://arxiv.org/abs/2502.11089
Trang GitHub MiniMax-01: https://github.com/MiniMax-AI/MiniMax-01
Trang GitHub InfLLM: https://github.com/thunlp/InfLLM?tab=readme-ov-file
Trang GitHub SeerAttention: https://github.com/microsoft/SeerAttention
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News