

Cofounder của NEAR Illia: Vì sao AI cần Web3?
Tuyển chọn TechFlowTuyển chọn TechFlow
Cofounder của NEAR Illia: Vì sao AI cần Web3?
Chúng ta đang đứng trước ngã tư, một bên là thế giới AI khép kín, nơi sẽ dẫn đến nhiều sự thao túng hơn.

Gần đây, Illia, đồng sáng lập NEAR đã tham dự sự kiện "Hồng Kông Web3 Carnival 2024" và phát biểu một bài quan trọng về chủ đề AI và Web3. Dưới đây là bản tóm tắt bài phát biểu của ông, có lược bỏ đôi chỗ.
Xin chào mọi người, tôi là Illia, đồng sáng lập NEAR. Hôm nay chúng ta sẽ thảo luận về lý do tại sao AI cần Web3. Thực tế, NEAR bắt nguồn từ AI. Trước khi khởi nghiệp, tôi làm việc tại Google Research, tập trung vào lĩnh vực hiểu ngôn ngữ tự nhiên, đồng thời là một trong những đóng góp chính cho framework học sâu TensorFlow của Google. Cùng với một nhóm đồng nghiệp, chúng tôi đã tạo ra mô hình “Transformers” đầu tiên, mở đường cho những đột phá lớn mà chúng ta đang chứng kiến ngày nay, thúc đẩy sự phát triển của AI — cũng chính là chữ “T” trong GPT.
Sau đó, tôi rời Google để thành lập NEAR. Khi ấy, NEAR là một công ty khởi nghiệp AI, dạy máy tính lập trình. Một trong những phương pháp của chúng tôi là gắn nhãn dữ liệu quy mô lớn, thuê sinh viên trên toàn thế giới giúp tạo dữ liệu. Tuy nhiên, chúng tôi gặp vấn đề trong việc thanh toán lương vì nhiều người trong số họ thậm chí không có tài khoản ngân hàng. Chúng tôi bắt đầu tìm hiểu blockchain như một giải pháp và nhận ra rằng không có nền tảng nào đáp ứng được nhu cầu của mình: khả năng mở rộng cao, phí thấp, dễ sử dụng và dễ tiếp cận. Chính lúc này, chúng tôi đã tạo ra giao thức NEAR.

Đối với những ai chưa quen thuộc, các mô hình ngôn ngữ không phải là điều mới mẻ — chúng đã tồn tại từ những năm 1950. Các mô hình thống kê phổ quát cho phép mô hình hóa ngôn ngữ và áp dụng vào nhiều lĩnh vực. Với tôi, bước đột phá thực sự thú vị xảy ra vào năm 2013, khi khái niệm nhúng từ (word embedding) được giới thiệu. Ý tưởng này cho phép chuyển đổi các ký hiệu như “New York” thành vector đa chiều dưới dạng toán học. Điều này kết hợp rất tốt với các mô hình học sâu, vốn về cơ bản chỉ là hàng loạt phép nhân ma trận và hàm kích hoạt.
Sau năm 2013, tôi gia nhập Google. Vào đầu năm 2014, mô hình chủ đạo trong nghiên cứu là RNN. Mô hình này tương tự cách con người đọc từng từ một, nhưng có một hạn chế lớn: nếu bạn muốn đọc nhiều tài liệu để trả lời một câu hỏi, sẽ có độ trễ đáng kể — điều này không thể chấp nhận được khi triển khai trong môi trường sản xuất tại Google.
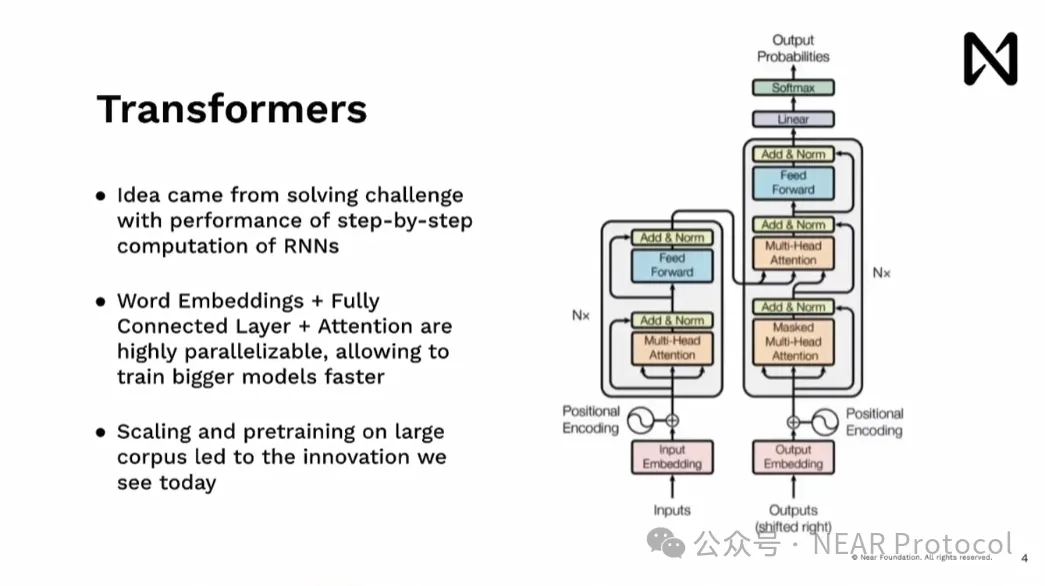
Transformer ra đời khi chúng tôi tìm cách khắc phục thách thức của RNN. Chúng tôi thử tận dụng tính song song trong xử lý tính toán — thứ tồn tại mạnh mẽ trong phần cứng, đặc biệt là GPU — cho phép xử lý toàn bộ tài liệu cùng lúc, thay vì từng bước một, từ đó loại bỏ điểm nghẽn. Điều này cho phép OpenAI sau này mở rộng mô hình, tiền huấn luyện trên kho dữ liệu khổng lồ, dẫn đến các đột phá lớn như ChatGPT, Gemini và các mô hình khác mà chúng ta thấy hôm nay.
Hiện tại, chúng ta đang chứng kiến những đột phá lớn trong AI, và tốc độ đổi mới còn đang tăng lên. Những mô hình này có khả năng suy luận cơ bản, sở hữu kiến thức thông thường. Chúng ta thấy mọi người liên tục thử thách giới hạn của các mô hình này. Tôi cho rằng điều quan trọng là trước đây, trong lĩnh vực học máy và khoa học dữ liệu, luôn cần con người để diễn giải kết quả. Nhưng giờ đây, điều thú vị là mô hình ngôn ngữ lớn (LLM) có thể giao tiếp trực tiếp với con người và tương tác với các ứng dụng và công cụ khác. Vì vậy, giờ đây chúng ta đã có phương tiện kỹ thuật để loại bỏ bên trung gian trong việc diễn giải kết quả.
Đối với những ai chưa rõ, khi nói các mô hình này được huấn luyện hoặc sử dụng bởi GPU, thì thực tế đây không phải là GPU dùng cho chơi game hay đào tiền mã hóa. Đây là siêu máy tính chuyên dụng, mỗi máy thường chứa tám GPU với sức mạnh xử lý khổng lồ. Những thiết bị này được xếp thành các tủ rack, phần lớn được triển khai tại các trung tâm dữ liệu. Việc huấn luyện một mô hình lớn như Groq mất ba tháng với 10.000 chip H100 sẽ tiêu tốn 64 triệu USD tiền thuê thiết bị. Quan trọng hơn, ngoài tính toán còn là yếu tố kết nối.
Một phần then chốt ở đây là A100, đặc biệt là H100, được kết nối với tốc độ 900 gigabyte mỗi giây. Để so sánh, kết nối giữa CPU và RAM của bạn chỉ khoảng 9 gigabyte mỗi giây. Việc di chuyển dữ liệu giữa hai nút/hai GPU trong cùng một rack trung tâm dữ liệu thực tế còn nhanh hơn việc di chuyển dữ liệu từ GPU sang CPU. Hiện tại, chúng tôi đang nỗ lực cải tiến Blackwell, với kỳ vọng tốc độ kết nối sẽ tăng gấp đôi, đạt 1.800 gigabyte mỗi giây. Tốc độ kết nối phần cứng này thật điên rồ, khiến chúng ta không còn phải xem các thiết bị này như đơn vị riêng lẻ. Bởi từ góc nhìn lập trình viên, chúng cảm giác như một thao tác duy nhất. Khi xây dựng hệ thống quy mô lớn, có rất nhiều điều cần lưu ý. Ý tưởng ở đây là các thiết bị này được kết nối cực kỳ chặt chẽ, trong khi kết nối mạng thông thường trên mạng nội bộ chỉ khoảng 100 megabyte mỗi giây — nghĩa là thấp hơn khoảng mười nghìn lần.
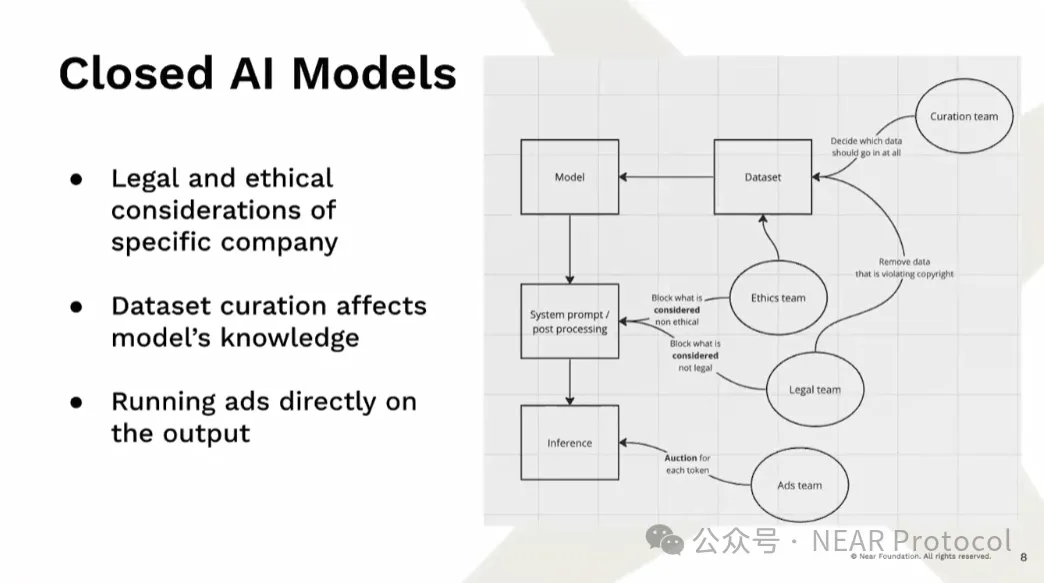
Hiện tại, do yêu cầu huấn luyện cao như vậy, chúng ta đang chứng kiến sự trỗi dậy của các mô hình AI đóng kín. Ngay cả khi trọng số mô hình là mã nguồn mở, chúng ta vẫn thực sự không biết có gì đã được đưa vào mô hình. Điều này quan trọng vì các mô hình này thực chất học thiên kiến từ dữ liệu. Có người đùa rằng mô hình thực ra chỉ là trọng số và thiên kiến — đó là cách mô hình thể hiện. Hiện nay, ngoài kỹ sư, còn có nhiều đội ngũ khác quyết định nội dung đưa vào mô hình bằng cách chỉnh sửa tập dữ liệu, vì một số lý do mà chọn không đưa một số nội dung vào dữ liệu. Sau đó, khi mô hình được tạo ra, họ xử lý hậu kỳ và thay đổi prompt hệ thống để quyết định mô hình sẽ suy luận điều gì. Nguy hiểm nhất là, chúng ta không biết rõ mô hình được tạo ra như thế nào.
Chúng ta cũng đang chứng kiến làn sóng phản đối và kiện tụng quy mô lớn đối với AI. Từ việc sử dụng dữ liệu, cách các mô hình tạo ra kết quả, đến quyền lực của các công ty đối với nền tảng phân phối — tất cả đều dễ gây tranh cãi. Bản thân các mô hình đang trở thành nền tảng phân phối, và do đó chúng ta đối mặt với rủi ro lớn. Rõ ràng, các cơ quan quản lý đang cố gắng kiểm soát, tìm cách hạn chế quyền truy cập của các đối tượng xấu, điều này khiến các mô hình mở và phương pháp phi tập trung càng khó tồn tại. Mã nguồn mở thiếu động lực kinh tế đủ mạnh, dẫn đến việc các công ty ban đầu có thể mở mã, nhưng sau đó khi tìm cách kiếm tiền, lại thu hẹp việc mở mã để thu hút thêm vốn mua sức mạnh tính toán, huấn luyện các mô hình lớn hơn.
AI tạo sinh đang trở thành công cụ thao túng quy mô lớn. Tình hình kinh tế của các tập đoàn lớn luôn dẫn đến méo mó động lực. Khi bạn đã đạt được thị phần mục tiêu, bạn vẫn phải tiếp tục tăng doanh thu. Bạn cần tăng doanh thu trung bình trên mỗi người dùng, tức là phải khai thác giá trị nhiều hơn từ người dùng — đó là toàn bộ câu chuyện của AI mã nguồn mở. Sử dụng Web3 như một công cụ để tạo động lực có thể mở ra cơ hội cho mọi người, đồng thời tạo ra đủ tài nguyên tính toán và dữ liệu để mọi người xây dựng các mô hình cạnh tranh.

Chúng ta cần đưa hàng loạt công cụ AI hoạt động hiệu quả trong thế giới Web3 để tích hợp chúng lại với nhau. Tôi sẽ trình bày một vài thành phần theo ba cấp độ: dữ liệu, cơ sở hạ tầng và ứng dụng. Một phần quan trọng là các mô hình ngôn ngữ hiện nay có thể tương tác trực tiếp với xã hội, có khả năng thao túng và tạo tin giả trên phạm vi rộng. Tôi muốn nhấn mạnh rằng AI không phải là vấn đề, vì những điều kiểu này đã từng xảy ra trước đây. Điều quan trọng là chúng ta cần tận dụng mật mã học và danh tiếng trên chuỗi để giải quyết vấn đề. Không quan trọng là nội dung do AI hay con người tạo ra, mà là ai đã đăng tải nó, nguồn gốc là gì, và cộng đồng đánh giá ra sao — đó mới là điều thực sự quan trọng.
Mặt khác, hiện nay chúng ta có các tác nhân (agent). Chúng ta có thói quen gọi mọi thứ là agent. Nhưng thực tế, chúng rất đa dạng: có thể là tác nhân công cụ hoặc tác nhân tự trị, có thể tập trung hoặc phi tập trung. Ví dụ, ChatGPT là một công cụ tập trung, trong khi mô hình Llama là mã nguồn mở. Do đó, chúng có thể được sử dụng theo cách tập trung hoặc phi tập trung. Chúng ta cũng có thể chạy mô hình phi tập trung chỉ trên thiết bị người dùng, mà không cần blockchain hay thứ gì tương tự. Bởi nếu bạn chạy mô hình trên thiết bị của mình, bạn có thể đảm bảo nó hoàn toàn đúng như mong đợi. Có một dạng quản trị AI phi tập trung hoàn toàn tự trị, đòi hỏi xác minh, ví dụ khi phân bổ ngân sách hoặc ra quyết định quan trọng.

Cũng có nhiều dạng chuyên biệt khác nhau. Ví dụ như prompt, bạn có thể thực hiện zero-shot để dạy Llama phản hồi theo cách cụ thể; bạn có thể tinh chỉnh (fine-tune) với dữ liệu đặc thù để bổ sung thêm tri thức cho mô hình; hoặc bạn có thể dùng tăng cường truy xuất (retrieval-augmented) để thêm thông tin bối cảnh khi người dùng yêu cầu. Đầu ra không nhất thiết chỉ là văn bản — nó cũng có thể là một thành phần giao diện người dùng phong phú, hoặc một hành động trực tiếp, như thực hiện một việc gì đó trên blockchain.
Tiếp theo là tính tự chủ. Nó có thể là một công cụ để làm những gì bạn muốn; nó cũng có thể tự viết kế hoạch và thực thi; nó có thể là một công việc liên tục, bạn chỉ cần đặt mục tiêu; nó có thể là tối ưu hóa học tăng cường, nơi bạn chỉ định một chỉ số, một bộ tiêu chuẩn và giới hạn; bạn để mô hình liên tục khám phá và tìm cách tăng trưởng.

Cuối cùng là cơ sở hạ tầng. Bạn có thể dùng cơ sở hạ tầng tập trung như OpenAI hay Groq. Bạn có thể có mô hình cục bộ phân tán, hoặc suy luận phi tập trung mang tính xác suất. Có một trường hợp sử dụng rất thú vị: chuyển từ tiền tệ lập trình được sang tài sản thông minh — nơi hành vi của tài sản được định nghĩa bằng ngôn ngữ tự nhiên, và có thể tương tác với thế giới thực hoặc với người dùng khác. Ví dụ, có thể dùng oracle ngôn ngữ tự nhiên đọc tin tức, tự động tối ưu chiến lược dựa trên những gì đang xảy ra. Điểm cần lưu ý lớn nhất là các mô hình ngôn ngữ hiện tại chưa vững chắc trước hành vi đối địch, nên rất dễ bị thuyết phục trong nhiều tình huống.
Chúng ta đang đứng trước ngã tư đường. Một bên là thế giới AI đóng kín, dẫn đến thao túng ngày càng nhiều. Các quyết định quản lý thường dẫn đến tình trạng này, khi các cơ quan quản lý yêu cầu ngày càng nhiều giám sát, KYC và các điều kiện nghiêm ngặt hơn. Chỉ các công ty lớn mới có thể đáp ứng được. Các startup, đặc biệt là những startup cố gắng mở mã, sẽ không có đủ nguồn lực để cạnh tranh thực sự, cuối cùng chỉ còn lựa chọn sụp đổ hoặc bị các tập đoàn lớn thâu tóm. Chúng ta đang bắt đầu chứng kiến điều này xảy ra.
Bên kia con đường là các mô hình mở, nơi chúng ta có cam kết và khả năng thực hiện với tinh thần phi lợi nhuận và mã nguồn mở, sử dụng động lực kinh tế mã hóa để tạo cơ hội và tài nguyên — điều thiết yếu để xây dựng các mô hình AI mã nguồn mở có khả năng cạnh tranh. NEAR đang nỗ lực thực hiện điều này trên toàn bộ hệ sinh thái. AI is NEAR. Trong vài tuần tới, chúng tôi sẽ có thêm nhiều cập nhật. Mời các bạn theo dõi Twitter của tôi và các kênh mạng xã hội của NEAR để biết thêm chi tiết. Cảm ơn mọi người!
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News












