

Bài toán toán học về năng lực tính toán của Sora
Tuyển chọn TechFlowTuyển chọn TechFlow
Bài toán toán học về năng lực tính toán của Sora
Sora không chỉ đại diện cho bước tiến lớn về chất lượng và chức năng trong việc tạo video, mà còn báo hiệu rằng trong tương lai, nhu cầu sử dụng GPU cho các tác vụ suy luận có thể tăng mạnh.
Tác giả: Matthias Plappert
Biên dịch: Siqi, Lavida, Tianyi
Sau khi ra mắt mô hình tạo video Sora vào tháng trước, hôm qua OpenAI tiếp tục công bố một loạt các sáng tạo do những người làm nội dung thực hiện bằng Sora, với hiệu ứng cực kỳ ấn tượng. Không nghi ngờ gì nữa, xét về chất lượng tạo ra, Sora là mô hình tạo video mạnh nhất từng được phát triển cho đến nay. Sự xuất hiện của nó không chỉ tác động trực tiếp đến ngành sáng tạo mà còn ảnh hưởng đến việc giải quyết một số vấn đề then chốt trong lĩnh vực robot và xe tự lái.
Mặc dù OpenAI đã công bố báo cáo kỹ thuật về Sora, nhưng chi tiết kỹ thuật trong báo cáo này rất hạn chế. Bài viết này biên dịch từ nghiên cứu của Matthias Plappert thuộc Factorial Fund. Matthias từng làm việc tại OpenAI và tham gia dự án Codex. Trong nghiên cứu này, ông phân tích các chi tiết kỹ thuật chính của Sora, điểm đổi mới của mô hình cũng như những tác động quan trọng nào sẽ xảy ra, đồng thời đánh giá nhu cầu tính toán đối với các mô hình tạo video như Sora. Theo Matthias, khi việc sử dụng tạo video ngày càng phụ thuộc nhiều hơn, nhu cầu tính toán ở khâu suy luận (inference) chắc chắn sẽ nhanh chóng vượt qua giai đoạn huấn luyện, đặc biệt với các mô hình dựa trên diffusion như Sora.
Theo ước tính của Matthias, nhu cầu năng lực tính toán của Sora trong giai đoạn huấn luyện cao gấp vài lần so với LLM, cần khoảng 4200–10500 card Nvidia H100 để huấn luyện trong 1 tháng. Hơn nữa, sau khi mô hình tạo ra từ 15,3 triệu đến 38,1 triệu phút video, chi phí tính toán ở khâu suy luận sẽ nhanh chóng vượt qua chi phí huấn luyện. Để so sánh, hiện tại người dùng tải lên TikTok khoảng 17 triệu phút video mỗi ngày, YouTube là 43 triệu phút. CTO của OpenAI, Mira, trong một cuộc phỏng vấn gần đây cũng nói rằng chi phí tạo video là lý do khiến Sora chưa thể mở cửa công chúng; OpenAI muốn đạt mức chi phí tương đương Dall·E trong tạo ảnh trước khi cân nhắc công bố rộng rãi.
Sora vừa được OpenAI công bố gần đây đã gây chấn động thế giới nhờ khả năng tạo cảnh video cực kỳ chân thực. Trong bài viết này, chúng tôi sẽ đi sâu vào các chi tiết kỹ thuật đằng sau Sora, những ảnh hưởng tiềm tàng của các mô hình video này, cùng với một số suy nghĩ hiện tại. Cuối cùng, chúng tôi cũng sẽ chia sẻ ước tính về năng lực tính toán cần thiết để huấn luyện một mô hình như Sora, đồng thời trình bày dự đoán về tính toán huấn luyện so với suy luận – điều này có ý nghĩa quan trọng trong việc dự báo nhu cầu GPU trong tương lai.
Quan điểm chính
Các kết luận chính trong báo cáo này bao gồm:
-
Sora là một mô hình diffusion, được xây dựng dựa trên DiT và Latent Diffusion, đồng thời mở rộng quy mô cả về kích thước mô hình lẫn tập dữ liệu huấn luyện;
-
Sora chứng minh tầm quan trọng của việc mở rộng quy mô (scale up) trong các mô hình video, và việc tiếp tục mở rộng sẽ là động lực chính thúc đẩy cải thiện năng lực mô hình, tương tự như trường hợp của LLM;
-
Các công ty như Runway, Genmo và Pika đang khám phá việc xây dựng giao diện và quy trình làm việc trực quan trên nền tảng các mô hình tạo video dựa trên diffusion như Sora – yếu tố này sẽ quyết định khả năng phổ biến và dễ sử dụng của mô hình;
-
Việc huấn luyện Sora đòi hỏi nguồn lực tính toán khổng lồ, chúng tôi ước tính cần khoảng 4200–10500 card Nvidia H100 chạy liên tục trong 1 tháng;
-
Ở khâu suy luận, chúng tôi ước tính mỗi card H100 mỗi giờ tối đa chỉ tạo được khoảng 5 phút video. Chi phí suy luận của các mô hình dựa trên diffusion như Sora cao hơn LLM hàng vài bậc độ lớn;
-
Khi các mô hình tạo video như Sora được áp dụng rộng rãi, khâu suy luận sẽ vượt qua huấn luyện để trở thành yếu tố tiêu thụ tính toán chủ đạo. Ngưỡng tới hạn nằm ở mức sản xuất từ 15,3 triệu đến 38,1 triệu phút video, lúc đó lượng tính toán dùng cho suy luận sẽ vượt quá tổng lượng tính toán dùng để huấn luyện ban đầu. So sánh: người dùng tải lên TikTok khoảng 17 triệu phút video mỗi ngày, YouTube là 43 triệu phút;
-
Giả sử AI đã được ứng dụng đầy đủ trên các nền tảng video, ví dụ 50% video trên TikTok và 15% video trên YouTube được tạo bởi AI. Xét đến hiệu suất sử dụng phần cứng và cách thức vận hành, chúng tôi ước tính ở mức đỉnh nhu cầu, khâu suy luận sẽ cần khoảng 720.000 card Nvidia H100.
Tóm lại, Sora không chỉ đại diện cho bước tiến lớn về chất lượng và chức năng tạo video, mà còn báo hiệu rằng nhu cầu GPU ở khâu suy luận có thể tăng mạnh trong tương lai.
01. Bối cảnh
Sora là một mô hình diffusion. Các mô hình diffusion khá phổ biến trong lĩnh vực tạo ảnh, ví dụ như Dall-E của OpenAI hay Stable Diffusion của Stability AI đều là các mô hình dựa trên diffusion. Các công ty gần đây đang thử nghiệm tạo video như Runway, Genmo và Pika cũng rất có thể đang sử dụng mô hình diffusion.
Về mặt khái niệm, như một mô hình sinh, mô hình diffusion học cách đảo ngược dần quá trình thêm nhiễu ngẫu nhiên vào dữ liệu, từ đó học được cách tạo ra dữ liệu giống với dữ liệu huấn luyện như ảnh hoặc video. Những mô hình này bắt đầu từ hoàn toàn nhiễu, rồi loại bỏ dần nhiễu và tinh chỉnh mẫu hình, cho đến khi tạo ra đầu ra mạch lạc và chi tiết.

Sơ đồ minh họa quá trình khuếch tán:
Nhiễu được loại bỏ dần cho đến khi hiện rõ nội dung video chi tiết
Nguồn: Báo cáo kỹ thuật Sora
Quá trình này khác biệt rõ rệt so với cách hoạt động của mô hình ngữ cảnh LLM: LLM tạo từng token một theo cách tự hồi quy (autoregressive sampling). Một khi mô hình tạo xong một token, nó sẽ không thay đổi nữa. Chúng ta có thể thấy điều này khi dùng Perplexity hay ChatGPT: câu trả lời hiện từng chữ một, như thể có ai đang gõ máy vậy.
02. Chi tiết kỹ thuật của Sora
Cùng với việc công bố Sora, OpenAI cũng đưa ra một bản báo cáo kỹ thuật, tuy nhiên thông tin chi tiết rất ít. Tuy nhiên, thiết kế của Sora dường như chịu ảnh hưởng lớn từ bài báo "Scalable Diffusion Models with Transformers". Trong bài báo này, hai tác giả đề xuất kiến trúc DiT – một mô hình dựa trên Transformer dùng để tạo ảnh. Có vẻ như Sora đã mở rộng công trình này sang lĩnh vực tạo video. Kết hợp giữa báo cáo kỹ thuật của Sora và bài báo DiT, chúng ta có thể xác định khá chính xác cấu trúc logic của Sora.
Ba thông tin quan trọng về Sora:
1. Sora không làm việc trực tiếp trên không gian pixel mà chọn làm việc trong không gian ẩn (latent space), còn gọi là latent diffusion;
2. Sora sử dụng kiến trúc Transformer;
3. Sora dường như sử dụng một tập dữ liệu cực lớn.
Chi tiết 1: Latent Diffusion
Để hiểu rõ điểm đầu tiên về latent diffusion, hãy nghĩ về cách tạo ảnh. Ta có thể dùng diffusion để tạo từng pixel, nhưng cách này rất kém hiệu quả – ví dụ một ảnh 512x512 có tới 262.144 pixel. Thay vì vậy, ta có thể chuyển pixel thành biểu diễn ẩn nén (latent representation), rồi thực hiện khuếch tán trên không gian dữ liệu nhỏ hơn này, cuối cùng chuyển kết quả về lại không gian pixel. Cách tiếp cận này giảm đáng kể độ phức tạp tính toán: thay vì xử lý 262.144 pixel, ta chỉ cần xử lý 64x64 = 4096 biểu diễn ẩn. Đây là đột phá then chốt trong High-Resolution Image Synthesis with Latent Diffusion Models, cũng là nền tảng của Stable Diffusion.

Chuyển ánh xạ pixel ở ảnh bên trái thành biểu diễn ẩn dưới dạng lưới ở bên phải
Nguồn: Báo cáo kỹ thuật Sora
Cả DiT và Sora đều dùng latent diffusion. Với Sora, cần lưu ý thêm yếu tố thời gian: video là chuỗi hình ảnh theo thời gian, còn gọi là các khung hình (frames). Theo báo cáo kỹ thuật, việc mã hóa từ không gian pixel sang latent space diễn ra cả về không gian (nén chiều rộng và chiều cao mỗi frame) lẫn thời gian (nén xuyên suốt thời gian).
Chi tiết 2: Kiến trúc Transformer
Về điểm thứ hai, cả DiT và Sora đều thay thế kiến trúc U-Net phổ biến bằng kiến trúc cơ bản của Transformer. Điều này rất quan trọng vì các tác giả DiT nhận thấy việc dùng Transformer giúp đạt được sự mở rộng (scaling) có thể dự đoán được: khi tăng tài nguyên (thời gian huấn luyện, quy mô mô hình hoặc cả hai), năng lực mô hình đều cải thiện. Báo cáo kỹ thuật của Sora cũng nêu quan điểm tương tự, nhưng áp dụng cho tạo video, kèm theo một biểu đồ minh họa trực quan.

Chất lượng mô hình tăng theo lượng tính toán huấn luyện: từ trái sang phải lần lượt là lượng tính toán cơ bản, 4 lần và 32 lần
Tính chất scaling này có thể định lượng bằng "luật scaling" (scaling law) – một thuộc tính rất quan trọng. Trước tạo video, luật scaling đã được nghiên cứu trong ngữ cảnh LLM và các mô hình tự hồi quy khác. Khả năng cải thiện mô hình bằng cách mở rộng quy mô là một trong những động lực chính thúc đẩy sự phát triển nhanh chóng của LLM. Vì tạo ảnh và video cũng có thuộc tính scaling, ta nên kỳ vọng luật scaling cũng đúng trong các lĩnh vực này.
Chi tiết 3: Tập dữ liệu
Để huấn luyện một mô hình như Sora, yếu tố then chốt cuối cùng là dữ liệu được gắn nhãn. Chúng tôi cho rằng bí mật lớn nhất của Sora nằm ở dữ liệu. Để huấn luyện mô hình text2video như Sora, ta cần dữ liệu cặp video và mô tả văn bản tương ứng. OpenAI không nói nhiều về tập dữ liệu, nhưng ám chỉ rằng nó rất lớn. Trong báo cáo, họ viết: «LLM đạt được năng lực tổng quát nhờ huấn luyện trên dữ liệu cấp độ internet – chúng tôi lấy cảm hứng từ điều này».

Nguồn: Báo cáo kỹ thuật Sora
OpenAI cũng công bố một phương pháp dùng nhãn văn bản chi tiết để chú thích ảnh, phương pháp này từng được dùng để thu thập dữ liệu DALLE-3. Về cơ bản, phương pháp này huấn luyện một mô hình chú thích (captioner model) trên một tập con có nhãn, rồi dùng mô hình đó tự động gắn nhãn cho phần còn lại. Có lẽ Sora cũng dùng kỹ thuật tương tự.
03. Tác động của Sora
Các mô hình video bắt đầu được ứng dụng thực tế
Xét về chi tiết và tính liên tục theo thời gian, chất lượng video do Sora tạo ra rõ ràng là một bước đột phá quan trọng. Ví dụ, Sora xử lý tốt việc vật thể bị che khuất tạm thời vẫn giữ nguyên vị trí, và có thể tạo chính xác hiệu ứng phản chiếu trên mặt nước. Chúng tôi tin rằng chất lượng video hiện tại của Sora đã đủ tốt cho một số loại cảnh cụ thể, và có thể được dùng trong các ứng dụng thực tế, ví dụ như Sora có thể sớm thay thế nhu cầu kho video.
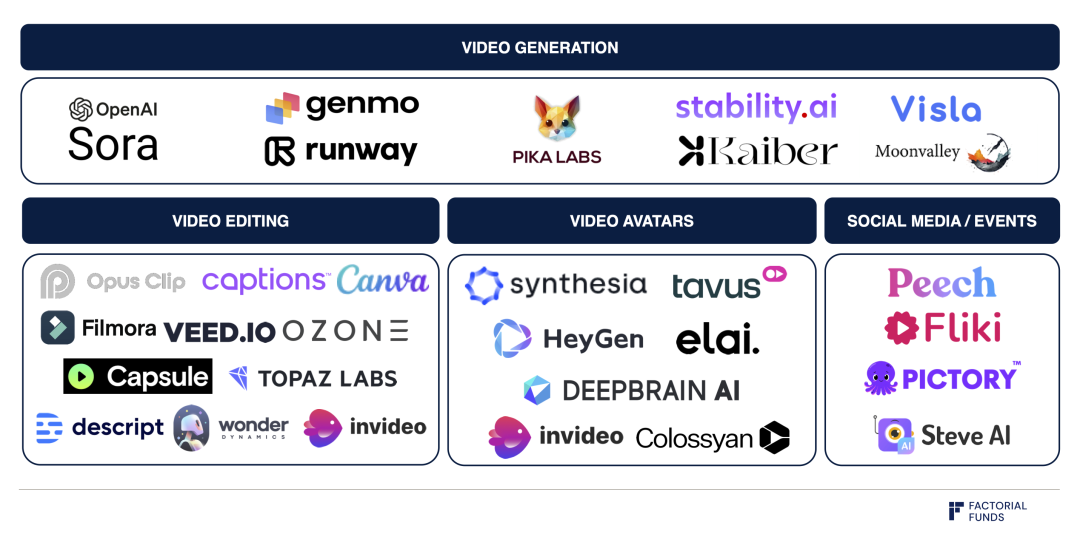
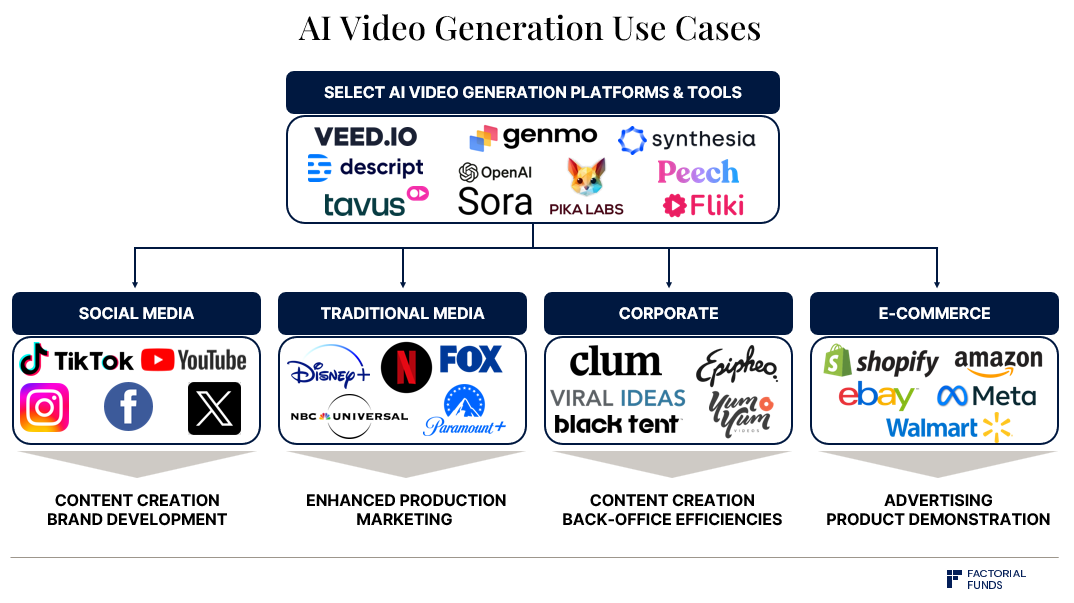
Bản đồ lĩnh vực tạo video
Tuy nhiên, Sora vẫn đối mặt thách thức: chúng ta chưa rõ mức độ kiểm soát của Sora ra sao. Vì mô hình xuất ra pixel, việc chỉnh sửa video đã tạo rất khó khăn và tốn thời gian. Để mô hình hữu ích, cần xây dựng giao diện người dùng (UI) và quy trình làm việc trực quan. Như hình trên, Runway, Genmo, Pika và các công ty khác trong lĩnh vực tạo video đang giải quyết vấn đề này.
Nhờ Scaling, ta có thể đẩy nhanh kỳ vọng về tạo video
Như đã thảo luận, một kết luận quan trọng trong nghiên cứu DiT là chất lượng mô hình tăng trực tiếp theo lượng tính toán. Điều này rất giống với scaling law đã thấy ở LLM. Vì vậy, ta có thể kỳ vọng rằng khi các mô hình được huấn luyện với nhiều tài nguyên hơn, chất lượng tạo video sẽ cải thiện nhanh chóng. Sora đã chứng minh mạnh mẽ điều này, và chúng tôi dự đoán OpenAI cùng các công ty khác sẽ đầu tư mạnh hơn nữa.
Dữ liệu tổng hợp và tăng cường dữ liệu
Trong các lĩnh vực như robot và xe tự lái, dữ liệu vốn là tài nguyên khan hiếm: không tồn tại một «internet» nơi có hàng loạt robot làm việc hay lái xe khắp nơi. Thông thường, các vấn đề trong những lĩnh vực này được giải quyết bằng cách huấn luyện trong môi trường mô phỏng, thu thập dữ liệu quy mô lớn ngoài đời thật, hoặc kết hợp cả hai. Tuy nhiên, cả hai cách đều gặp thách thức: dữ liệu mô phỏng thường không sát thực tế, còn thu thập dữ liệu ngoài đời thật thì rất tốn kém, và việc thu thập đủ dữ liệu cho các sự kiện hiếm cũng rất khó.

Như hình, có thể thay đổi thuộc tính video để tăng cường dữ liệu, ví dụ chuyển video gốc (trái) thành môi trường rừng rậm (phải)
Nguồn: Báo cáo kỹ thuật Sora
Chúng tôi tin rằng các mô hình như Sora có thể đóng vai trò trong việc giải quyết vấn đề này. Sora có thể được dùng trực tiếp để tạo dữ liệu hoàn toàn tổng hợp (100%). Sora cũng có thể dùng để tăng cường dữ liệu, tức là biến đổi cách thể hiện video hiện có theo nhiều kiểu khác nhau.
Việc tăng cường dữ liệu này thực tế đã được minh họa trong ví dụ của báo cáo kỹ thuật. Trong video gốc, một chiếc ô tô đỏ di chuyển trên đường rừng, sau khi xử lý bằng Sora, video trở thành xe chạy trên đường rừng nhiệt đới. Ta hoàn toàn có thể tin rằng cùng kỹ thuật này có thể tạo ra chuyển đổi ban ngày – ban đêm, hoặc thay đổi điều kiện thời tiết.
Mô phỏng và mô hình thế giới
«Mô hình thế giới (World Models)» là một hướng nghiên cứu có giá trị. Nếu mô hình đủ chính xác, các mô hình này có thể dùng để huấn luyện agent AI trực tiếp bên trong, hoặc dùng để lập kế hoạch và tìm kiếm.
Các mô hình như Sora học một cách ngầm định (implicitly) từ dữ liệu video để nắm được mô hình cơ bản về cách hoạt động của thế giới thực. Dù «mô phỏng nổi trội (emergent simulation)» này hiện còn khiếm khuyết, nó vẫn rất đáng phấn khích: điều này cho thấy ta có thể huấn luyện mô hình thế giới bằng cách dùng quy mô lớn dữ liệu video. Hơn nữa, Sora dường như có thể mô phỏng các cảnh phức tạp như dòng chất lỏng, phản xạ ánh sáng, chuyển động sợi vải và tóc. OpenAI thậm chí đặt tên báo cáo kỹ thuật của Sora là Video generation models as world simulators, điều này rõ ràng cho thấy họ tin đây là khía cạnh quan trọng nhất mà mô hình sẽ tạo ra tác động.
Gần đây, DeepMind cũng thể hiện hiệu ứng tương tự trong mô hình Genie của mình: chỉ huấn luyện trên một loạt video game, mô hình đã học được cách mô phỏng các trò chơi đó, thậm chí tạo ra trò chơi mới. Trong trường hợp này, mô hình thậm chí có thể học cách điều chỉnh dự đoán hoặc ra quyết định dựa trên hành vi, dù chưa từng quan sát trực tiếp hành vi đó. Trong ví dụ Genie, mục tiêu huấn luyện mô hình vẫn là để học trong các môi trường mô phỏng này.

Video từ Google DeepMind Genie:
Giới thiệu Generative Interactive Environments
Tổng kết, chúng tôi tin rằng nếu muốn huấn luyện quy mô lớn các agent thể hiện (embodied agents) như robot trên các nhiệm vụ thực tế, các mô hình như Sora và Genie chắc chắn sẽ có vai trò. Tất nhiên, mô hình cũng có hạn chế: vì huấn luyện trong không gian pixel, mô hình mô phỏng mọi chi tiết, kể cả cành cây lay động trong gió – những chi tiết hoàn toàn không liên quan đến nhiệm vụ hiện tại. Dù không gian ẩn đã được nén, nó vẫn phải giữ nhiều thông tin kiểu này để đảm bảo ánh xạ về pixel, nên chưa rõ liệu có thể lập kế hoạch hiệu quả trong không gian ẩn hay không.
04. Ước tính năng lực tính toán
Chúng tôi rất quan tâm đến nhu cầu tài nguyên tính toán trong quá trình huấn luyện và suy luận của mô hình, vì thông tin này giúp dự báo nhu cầu tính toán trong tương lai. Tuy nhiên, do thông tin chi tiết về kích thước mô hình và tập dữ liệu của Sora rất ít, việc ước tính các con số này rất khó. Vì vậy, các ước tính trong phần này không phản ánh chính xác thực tế – vui lòng tham khảo cẩn trọng.
Dựa trên DiT để suy luận quy mô tính toán của Sora
Thông tin chi tiết về Sora rất hạn chế, nhưng ta có thể quay lại bài báo DiT và dùng dữ liệu trong bài để suy luận về yêu cầu tính toán của Sora, vì đây rõ ràng là nền tảng của Sora. Mô hình DiT lớn nhất, DiT-XL, có 675 triệu tham số và dùng khoảng 1021 FLOPS tổng cộng để huấn luyện. Để dễ hiểu, quy mô tính toán này tương đương dùng 0,4 card Nvidia H100 chạy 1 tháng, hoặc một card H100 chạy 12 ngày.
Hiện tại, DiT chỉ dùng để tạo ảnh, còn Sora là mô hình video. Sora có thể tạo video dài tới 1 phút. Giả sử tốc độ mã hóa khung hình là 24 khung/giây (fps), một video có tới 1440 khung. Sora nén cả về thời gian lẫn không gian khi chuyển từ pixel sang latent space. Nếu giả sử Sora dùng tỷ lệ nén giống bài báo DiT (tức nén 8 lần), thì trong latent space sẽ có 180 khung. Do đó, nếu ngoại suy tuyến tính đơn giản từ DiT sang video, ta có thể suy ra lượng tính toán của Sora gấp 180 lần DiT.
Hơn nữa, chúng tôi tin rằng số tham số của Sora vượt xa 675 triệu, có thể lên tới 20 tỷ, nghĩa là theo góc nhìn này, lượng tính toán của Sora lại cao gấp 30 lần DiT.
Cuối cùng, chúng tôi tin rằng tập dữ liệu dùng để huấn luyện Sora lớn hơn nhiều so với DiT. DiT được huấn luyện với batch size 256 trong 3 triệu bước, tức xử lý tổng cộng 768 triệu ảnh. Tuy nhiên cần lưu ý rằng do ImageNet chỉ có 14 triệu ảnh, nên dữ liệu đã được dùng lặp lại nhiều lần. Sora dường như được huấn luyện trên tập dữ liệu hỗn hợp ảnh và video, nhưng chúng tôi hầu như không biết gì về tập dữ liệu cụ thể. Vì vậy, chúng tôi tạm giả sử tập dữ liệu của Sora gồm 50% ảnh tĩnh và 50% video, và lớn hơn tập dữ liệu DiT từ 10 đến 100 lần. Tuy nhiên, DiT đã huấn luyện lặp lại cùng điểm dữ liệu, nên trong tình huống có sẵn tập dữ liệu lớn hơn, cách làm này có thể không tối ưu. Vì vậy, nhân tử tăng tính toán hợp lý hơn là từ 4 đến 10 lần.
Tổng hợp các thông tin trên, đồng thời xem xét các mức ước tính khác nhau về quy mô tập dữ liệu, ta có các kết quả sau:
Công thức: Tính toán cơ sở DiT × Tăng mô hình × Tăng tập dữ liệu × Tăng tính toán do 180 khung video (chỉ áp dụng cho 50% dữ liệu)
-
Trường hợp bảo thủ: 1021 FLOPS × 30 × 4 × (180 / 2) ≈ 1,1×10²⁵ FLOPS
-
Trường hợp lạc quan: 1021 FLOPS × 30 × 10 × (180 / 2) ≈ 2,7×10²⁵ FLOPS
Quy mô tính toán của Sora tương đương 4211–10528 card H100 chạy trong 1 tháng.
Nhu cầu tính toán: Suy luận so với Huấn luyện
Một phần quan trọng khác cần quan tâm là so sánh lượng tính toán giữa huấn luyện và suy luận. Về lý thuyết, dù lượng tính toán huấn luyện lớn, chi phí này mang tính một lần. Trái lại, dù suy luận cần ít tính toán hơn mỗi lần, nhưng nó xảy ra mỗi khi mô hình tạo nội dung, và tăng theo số lượng người dùng. Vì vậy, khi số lượng người dùng tăng và mô hình được dùng rộng rãi, suy luận ngày càng quan trọng.
Do đó, việc tìm điểm tới hạn – khi tính toán suy luận vượt qua huấn luyện – là rất có giá trị.
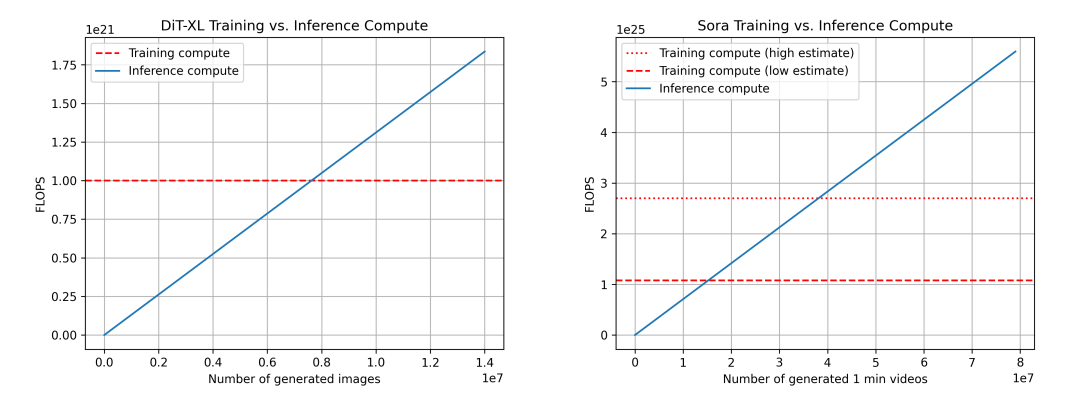
Chúng tôi so sánh DiT (trái) và Sora (phải) về tính toán huấn luyện và suy luận. Với Sora, dữ liệu dựa trên các ước tính phía trên, chưa hoàn toàn đáng tin cậy. Chúng tôi cũng hiển thị hai mức ước tính tính toán huấn luyện: thấp (giả sử nhân tử tập dữ liệu là 4) và cao (giả sử nhân tử là 10).
Với dữ liệu này, chúng tôi tiếp tục dùng DiT để suy luận cho Sora. Với DiT, mô hình lớn nhất DiT-XL dùng 524×10⁹ FLOPS mỗi bước suy luận, và DiT cần 250 bước khuếch tán để tạo một ảnh, tổng cộng 131×10¹² FLOPS. Ta thấy rằng sau khi tạo 7,6 triệu ảnh, đạt tới «điểm tới hạn suy luận – huấn luyện», sau đó suy luận chiếm ưu thế về nhu cầu tính toán. Tham khảo: người dùng tải lên Instagram khoảng 95 triệu ảnh mỗi ngày.
Với Sora, chúng tôi suy ra FLOPS = 524×10⁹ FLOPS × 30 × 180 ≈ 2,8×10¹⁵ FLOPS. Nếu vẫn giả sử mỗi video cần 250 bước khuếch tán, tổng FLOPS mỗi video là 708×10¹⁵ FLOPS. Tham khảo: điều này tương đương mỗi card H100 mỗi giờ tạo được khoảng 5 phút video. Trường hợp bảo thủ, cần tạo 15,3 triệu phút video để đạt điểm tới hạn; trường hợp lạc quan, cần 38,1 triệu phút. Tham khảo: khoảng 43 triệu phút video được tải lên YouTube mỗi ngày.
Cũng cần bổ sung một số lưu ý: với suy luận, FLOPS không phải yếu tố duy nhất quan trọng. Ví dụ, băng thông bộ nhớ cũng rất quan trọng. Ngoài ra, đã có nhóm nghiên cứu tích cực giảm số bước khuếch tán, giúp giảm nhu cầu tính toán và tăng tốc độ suy luận. Hiệu suất sử dụng FLOPS trong huấn luyện và suy luận cũng có thể khác nhau – yếu tố cần cân nhắc.
Yang Song, Prafulla Dhariwal, Mark Chen và Ilya Sutskever công bố nghiên cứu Consistency Models vào tháng 3 năm 2023, cho thấy mô hình khuếch tán đạt tiến bộ lớn trong tạo ảnh, âm thanh và video, nhưng có hạn chế như phụ thuộc vào quá trình lấy mẫu lặp và tạo chậm. Nghiên cứu đề xuất mô hình nhất quán, cho phép trao đổi tính toán để tăng chất lượng mẫu. https://arxiv.org/abs/2303.01469
Xu hướng nhu cầu tính toán suy luận theo từng mô hình và dạng dữ liệu
Chúng tôi cũng nghiên cứu xu hướng nhu cầu tính toán suy luận theo từng đơn vị đầu ra của các mô hình khác nhau và dạng dữ liệu khác nhau. Mục đích là để hiểu mức độ tăng nhu cầu tính toán suy luận trong các loại mô hình khác nhau, điều này ảnh hưởng trực tiếp đến lập kế hoạch và nhu cầu tính toán. Vì các mô hình hoạt động ở dạng dữ liệu khác nhau, đơn vị đầu ra cũng khác nhau: đầu ra đơn lẻ của Sora là một video dài 1 phút; của DiT là một ảnh 512x512 pixel; với Llama 2 và GPT-4, chúng tôi định nghĩa đơn vị đầu ra là một tài liệu văn bản gồm 1000 token (tham khảo: trung bình một bài Wikipedia khoảng 670 token).
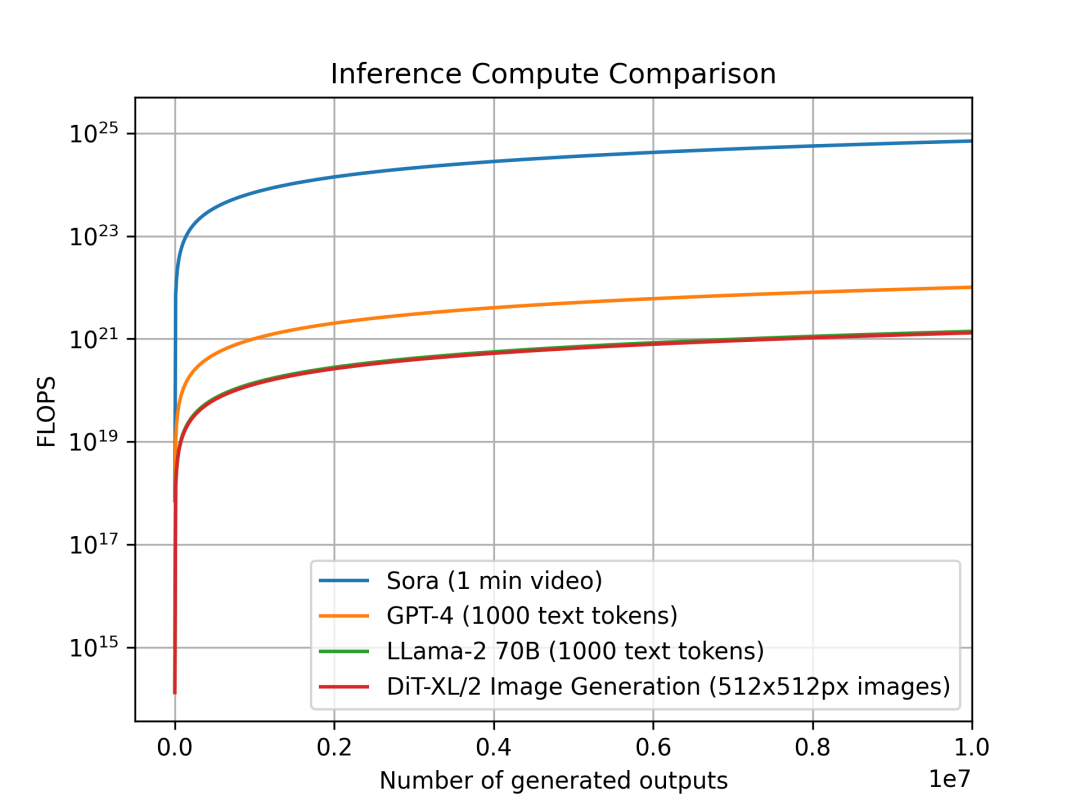
So sánh tính toán suy luận theo từng đơn vị đầu ra: Sora mỗi đơn vị tạo 1 phút video, GPT-4 và LLama 2 mỗi đơn vị tạo văn bản 1000 token, DiT mỗi đơn vị tạo một ảnh 512x512px. Biểu đồ cho thấy ước tính suy luận của Sora tốn nhiều tính toán hơn hàng bậc độ lớn.
Chúng tôi so sánh Sora, DiT-XL, LLama2-70B và GPT-4, dùng thang log để vẽ biểu đồ FLOPS. Với Sora và DiT, dùng ước tính suy luận ở trên. Với Llama 2 và GPT-4, chúng tôi dùng công thức «FLOPS = 2 × số tham số × số token tạo ra» để ước tính nhanh. Với GPT-4, chúng tôi giả sử mô hình là MoE, mỗi chuyên gia có 220 tỷ tham số, và mỗi lần lan truyền về trước kích hoạt 2 chuyên gia. Cần nhấn mạnh rằng dữ liệu về GPT-4 không phải là thông tin chính thức từ OpenAI, chỉ để tham khảo.
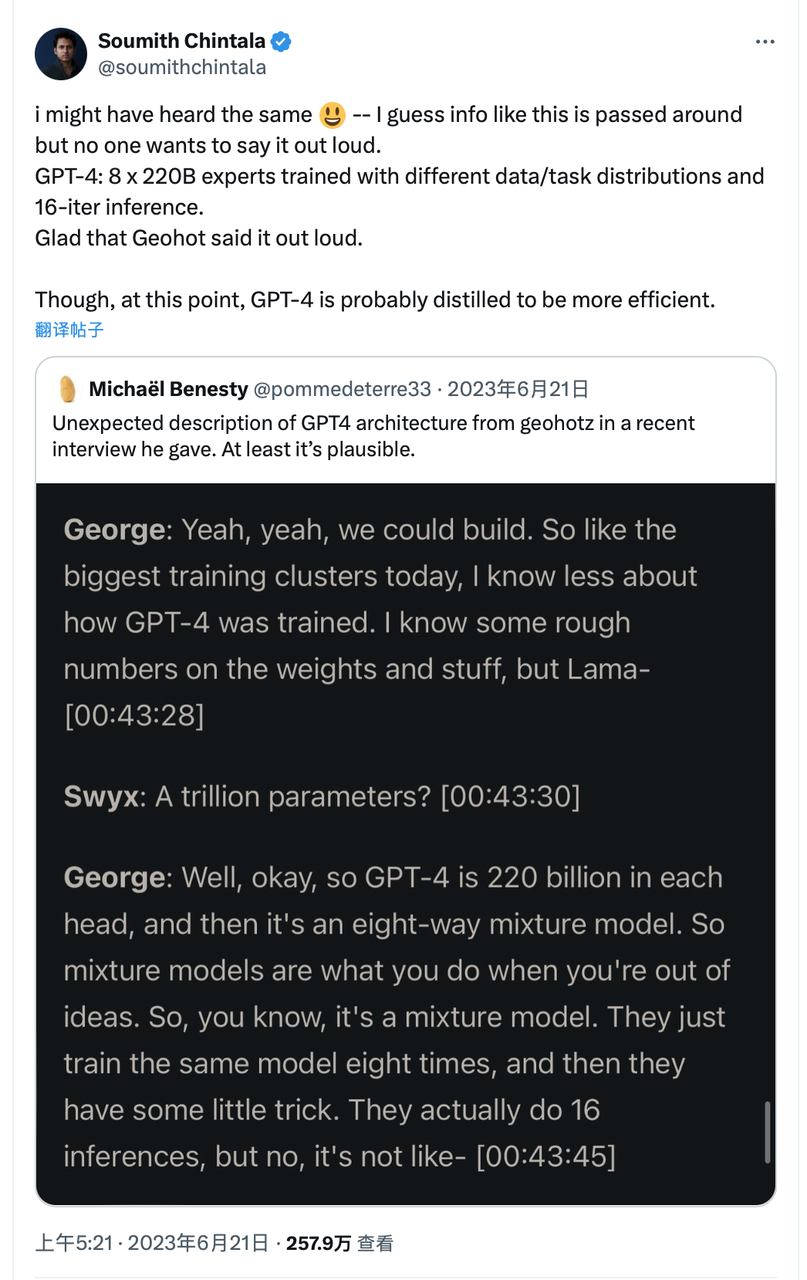
Nguồn: X
Ta thấy các mô hình dựa trên diffusion như DiT và Sora tiêu tốn nhiều năng lực tính toán hơn ở khâu suy luận: DiT-XL với 675 triệu tham số tiêu tốn gần bằng Llama 2 có 70 tỷ tham số. Hơn nữa, ta thấy suy luận của Sora cao hơn GPT-4 hàng bậc độ lớn.
Một lần nữa cần nhấn mạnh rằng nhiều con số dùng trong các phép tính trên là ước tính, dựa trên các giả định đơn giản. Ví dụ, chúng không tính đến hiệu suất FLOPS thực tế của GPU, giới hạn dung lượng và băng thông bộ nhớ, hay các kỹ thuật nâng cao như giải mã suy luận (speculative decoding).
Dự báo nhu cầu tính toán suy luận khi Sora được ứng dụng rộng rãi:
• Như trên, giả sử mỗi card H100 mỗi giờ tạo được 5 phút video, tương đương mỗi card mỗi ngày tạo 120 phút video.
• Trên TikTok: hiện tại người dùng tải lên 17 triệu phút video mỗi ngày (34 triệu video × độ dài trung bình 30 giây), giả sử tỷ lệ thâm nhập AI là 50%;
• Trên YouTube: hiện tại người dùng tải lên 43 triệu phút video mỗi ngày, giả sử tỷ lệ thâm nhập AI là 15% (chủ yếu video dưới 2 phút);
• Tổng lượng video do AI tạo mỗi ngày: 8,5 triệu + 6,5 triệu = 15 triệu phút.
• Tổng số card Nvidia H100 cần để phục vụ cộng đồng sáng tạo trên TikTok và YouTube: 15 triệu / 120 ≈ 89.000.
Tuy nhiên, con số 89.000 này có thể thấp hơn thực tế do các yếu tố sau:
• Chúng tôi giả sử hiệu suất FLOPS đạt 100%, không tính đến các nút cổ chai về bộ nhớ và truyền thông. Thực tế, hiệu suất 50% hợp lý hơn, nghĩa là nhu cầu GPU thực tế gấp đôi ước tính;
• Nhu cầu suy luận không phân bố đều theo thời gian mà có tính đột biến, đặc biệt cần xem xét tình huống đỉnh điểm, do đó cần thêm GPU để đảm bảo dịch vụ. Chúng tôi cho rằng nếu tính đến lưu lượng đỉnh, cần nhân đôi nhu cầu GPU;
• Người sáng tạo có thể tạo nhiều video rồi chọn một cái tốt nhất để đăng. Nếu bảo thủ giả sử trung bình cứ mỗi video đăng có 2 lần tạo, thì nhu cầu GPU lại nhân đôi;
Tổng cộng, ở lưu lượng đỉnh, cần khoảng 720.000 card H100 để đáp ứng nhu cầu suy luận.
Điều này xác nhận niềm tin của chúng tôi rằng khi các mô hình AI tạo nội dung ngày càng phổ biến và được phụ thuộc nhiều hơn, nhu cầu tính toán ở khâu suy luận sẽ chiếm ưu thế – đặc biệt rõ rệt với các mô hình dựa trên diffusion như Sora.
Cũng cần lưu ý rằng việc mở rộng quy mô mô hình sẽ tiếp tục đẩy mạnh nhu cầu tính toán suy luận. Tuy nhiên, mặt khác, việc tối ưu hóa kỹ thuật suy luận và toàn bộ stack công nghệ có thể bù đắp một phần nhu cầu tăng này.
Việc sản xuất nội dung video trực tiếp thúc đẩy nhu cầu đối với các mô hình như Sora
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News










