MUD Indexer có phải là thiết kế tồi tệ?
Tuyển chọn TechFlowTuyển chọn TechFlow
MUD Indexer có phải là thiết kế tồi tệ?
Indexer của MUD Engine là thiết kế ít tồi tệ nhất, bài viết này giải thích chi tiết kết luận trên và cố gắng tìm hiểu các giải pháp tối ưu hơn có thể.
Tác giả: ck, MetaCat
Lời mở đầu
Dùng tiêu đề này không nhằm câu sự chú ý, mà là cảm xúc thật lòng khi gần đây sử dụng khung MUD (gọi là khung sẽ chính xác hơn). Câu trả lời ban đầu là: Indexer của MUD là thiết kế ít tồi tệ nhất. Bài viết này sẽ giải thích chi tiết kết luận trên, đồng thời cố gắng tìm hiểu các giải pháp tối ưu hơn, tuy nhiên vẫn chỉ là thảo luận sơ lược và chưa tìm được đáp án hoàn chỉnh. Ghi lại những suy nghĩ này như một cách ném gạch dẫn ngọc.

Nguồn: https://mud.dev/
Góc nhìn cơ sở dữ liệu
Trong bài viết "Phiên bản 2048 toàn chuỗi: Những gì chúng tôi học được từ việc sử dụng engine MUD?", chúng tôi đã đề cập rằng thiết kế khung MUD tuân theo tư tưởng "lấy cơ sở dữ liệu làm trung tâm". Trong khung MUD, cốt truyện xoay quanh việc đọc và ghi dữ liệu trên chuỗi, chức năng ghi dữ liệu do Store đảm nhiệm; chức năng đọc dữ liệu chủ yếu do Indexer thực hiện. Từ "chủ yếu" ở đây nghĩa là chức năng đọc dữ liệu trên chuỗi do Store đảm nhận, còn đọc dữ liệu ngoài chuỗi (hay còn gọi là phía client) thì do Indexer đảm nhận.
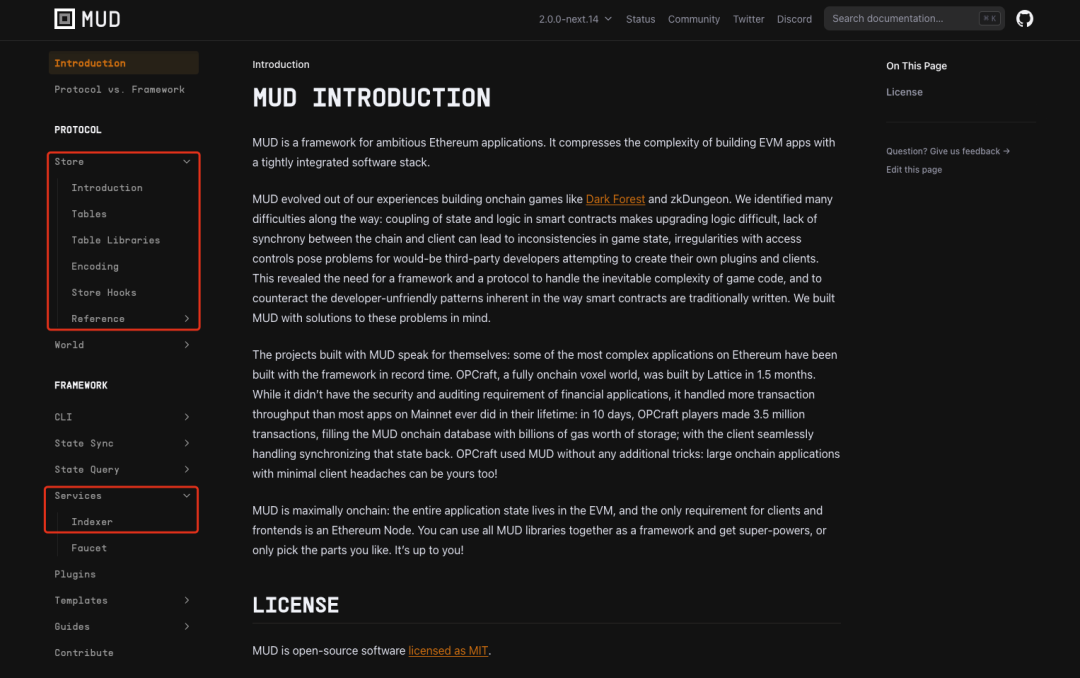
Nguồn: https://mud.dev/introduction
Thời gian chờ của người dùng
Về bản chất, Indexer là bản sao dữ liệu chuỗi (tồn tại dưới dạng tương tự cơ sở dữ liệu quan hệ) ở phía client. Trong bối cảnh DApp dựa trên trình duyệt, điều này có nghĩa mỗi lần tải lại trang đều cần xây dựng lại bản sao dữ liệu phía client. Do đặc tính lưu trữ dữ liệu theo kiểu chuỗi, nên theo thời gian, thời gian cần để thiết lập bản sao dữ liệu ngày càng tăng lên, cũng đồng nghĩa với thời gian chờ của người dùng kéo dài và trải nghiệm người dùng giảm sút.
Nguồn: https://www.mud2048.fun/
Lấy ví dụ mud2048.fun, hiện tại cần chờ khoảng 10-20 giây mới vào được trang chính của trò chơi, trải nghiệm này thực sự khiến người dùng phát điên. Bài viết lấy điểm này làm khởi điểm, bàn về ưu nhược điểm trong thiết kế Indexer của MUD, các khả năng cải tiến, từ đó thảo luận cách thức thiết kế mô hình đọc/ghi dữ liệu cho framework phát triển ứng dụng trên chuỗi.
Trong bối cảnh kỳ vọng bùng nổ ứng dụng trên Layer 2 Ethereum, cuộc thảo luận này mang tính thực tiễn rất cao, thậm chí có thể nói là vấn đề nền tảng quyết định liệu ứng dụng trên Layer 2 có thể bùng nổ hay không. Nếu vấn đề này được giải quyết, rào cản hạ tầng cho sự bùng nổ ứng dụng trên Layer 2 Ethereum sẽ được dọn sạch, chỉ cần đợi đổi mới mô hình để kích hoạt bùng nổ ứng dụng.
MUD Store là phương án ghi dữ liệu trên chuỗi tối ưu hơn
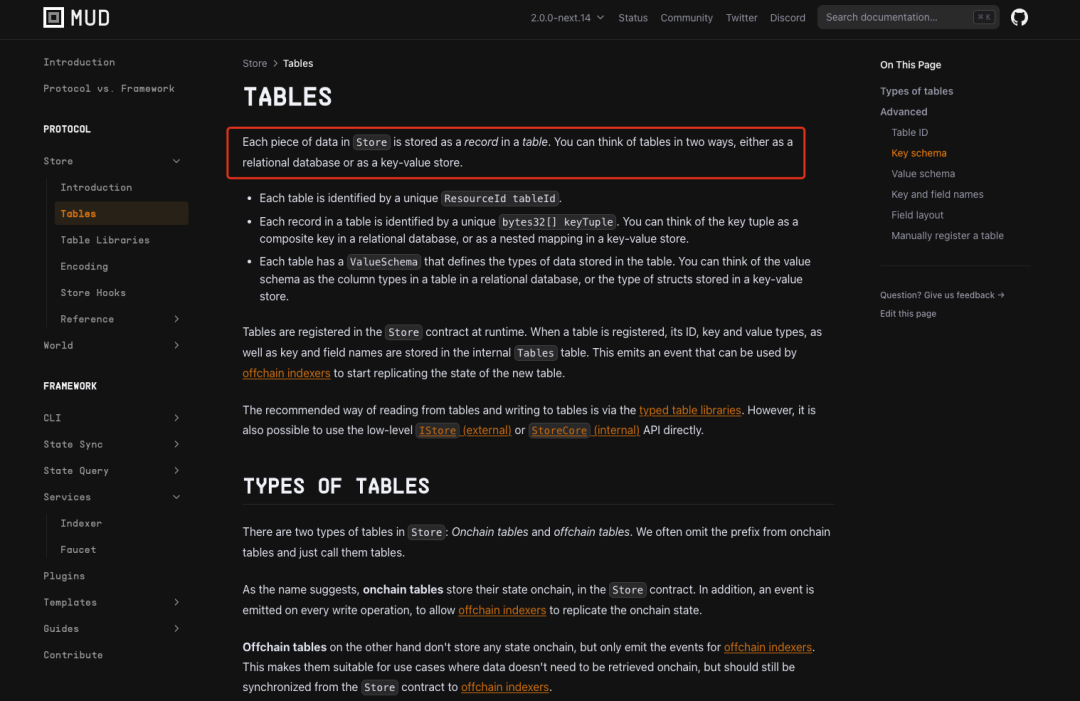
Phương thức ghi dữ liệu của Store là cách gọn gàng hơn so với gói dữ liệu gốc trong Solidity, giúp giảm chi phí lưu trữ. Ngoài ra, việc ánh xạ việc lưu trữ dữ liệu trên chuỗi sang mô hình "cơ sở dữ liệu quan hệ" - vốn đã được kiểm chứng kỹ lưỡng trong lĩnh vực kỹ thuật – rất thân thiện với nhà phát triển. Vì vậy, so với phương thức ghi dữ liệu gốc của Solidity, giải pháp ghi dữ liệu của Store là tốt hơn. Tuy nhiên, điều này cũng phần nào gây ra vấn đề hiệu suất đọc dữ liệu, như Tagore từng nói: “Điều tốt đẹp nhất không đến đơn độc, nó luôn đi cùng mọi thứ khác.”
Nguồn: https://mud.dev/store/tables
Cách ghi dữ liệu này, hay nói cách khác, việc ghi dữ liệu lên blockchain, dẫn đến việc đọc/truy vấn dữ liệu chỉ có hai con đường:
Con đường thứ nhất: đọc trực tiếp từ chuỗi. Nhược điểm là hiệu quả thấp và không hỗ trợ truy vấn phức tạp.
Con đường thứ hai: "sao chép" dữ liệu từ chuỗi xuống ngoài chuỗi, thực hiện truy vấn phức tạp ở bên ngoài (giải pháp MUD đang dùng), nhưng đồng thời tạo ra hai vấn đề:
1> Theo thời gian, thời gian cần để đồng bộ sao chép dữ liệu ngày càng tăng, làm trải nghiệm người dùng ngày càng tệ;
2> Mỗi bản sao client đều phải thực hiện lại thao tác truy vấn/tính toán toàn cục (ví dụ bảng xếp hạng), gây lãng phí tài nguyên nhất định.
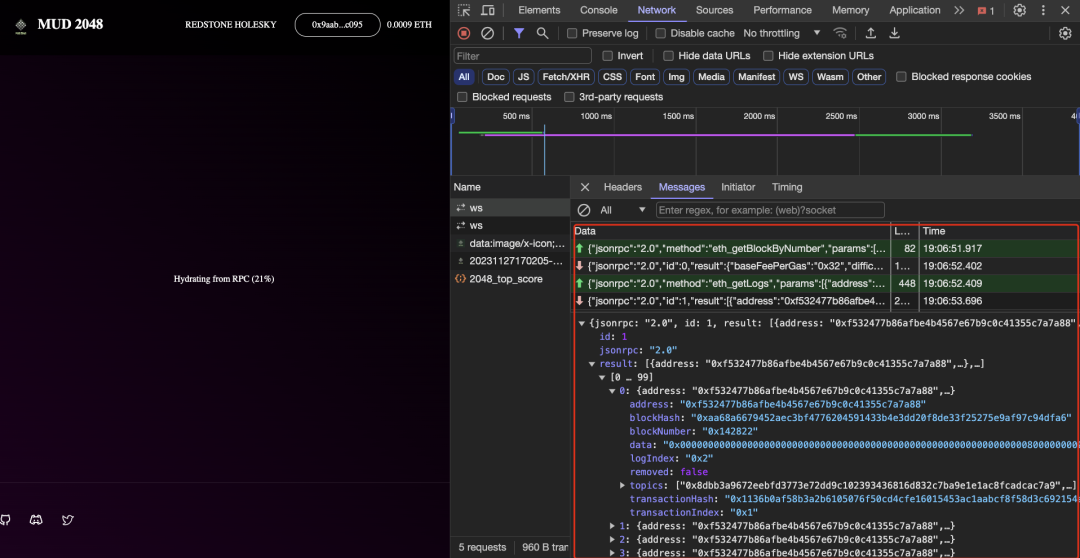
Trong quá trình phát triển mud2048.fun, chúng tôi đã trao đổi ngắn với đội ngũ MUD về vấn đề thứ nhất, đưa ra một số giải pháp tạm thời, nhưng chỉ giải quyết bề nổi chứ không triệt để. Vùng được khoanh đỏ trong hình dưới đây là quá trình sao chép dữ liệu từ chuỗi của khung MUD.
Nguồn: https://www.mud2048.fun/
Câu hỏi cuối cùng: Làm thế nào để ứng dụng toàn chuỗi đạt được việc đọc dữ liệu hiệu quả?
Từ sự phát triển của sản phẩm Internet, ta biết rằng đa số sản phẩm dành hơn 90% thời gian cho việc đọc dữ liệu, chỉ dưới 10% thời gian cho việc ghi dữ liệu. Vì vậy, một giải pháp đọc dữ liệu hiệu quả quyết định trực tiếp trải nghiệm người dùng của sản phẩm.
Vấn đề đọc dữ liệu này trong lĩnh vực blockchain có một từ ngữ tương tự là "lớp sẵn sàng dữ liệu" (Data Availability Layer). Mặc dù không mô tả cùng một cấp độ vấn đề, nhưng dường như có thể giúp ích phần nào trong việc suy nghĩ giải pháp cho vấn đề hiện tại, nên tạm mượn dùng.

Nguồn: https://www.alchemy.com/overviews/data-availability-layer
Các giải pháp DA (Data Availability) phổ biến trong blockchain có thể chia thành hai loại lớn: DA trên chuỗi và DA ngoài chuỗi. Các inscription Bitcoin thuộc loại DA trên chuỗi (dữ liệu inscription lưu trên blockchain Bitcoin, nhưng giải thích dữ liệu nằm ngoài chuỗi), Layer 2 Ethereum thuộc loại DA ngoài chuỗi (ZK Rollup và OP Rollup lưu dữ liệu dưới dạng CALLDATA trên Layer 1 Ethereum). Hai giải pháp này hiện vẫn đang cạnh tranh, chưa rõ bên nào vượt trội hẳn, nhưng điều này vừa hay cung cấp cho chúng ta hai trường hợp tham khảo trái ngược để suy ngẫm giải pháp cho vấn đề hiện tại.
Không thể sao chép giải pháp Web2
Trong lĩnh vực Web2, khi hiệu năng đọc của cơ sở dữ liệu không đủ, ta sẽ thêm một lớp đệm (Cache) trước cơ sở dữ liệu, hoặc tăng nhiều bản sao cơ sở dữ liệu phụ để nâng cao khả năng đọc dữ liệu.
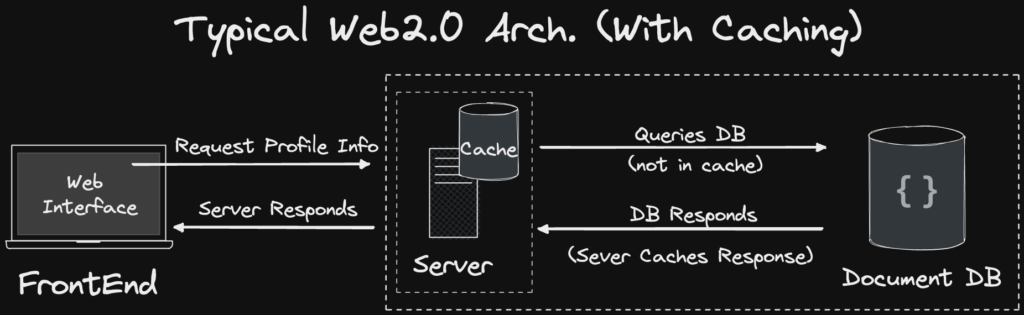
Kiến trúc dịch vụ Web2 điển hình. Nguồn: https://smartbuilds.io/scaling-web3-social-media-blockchain-cache-layer/
Tuy nhiên trong lĩnh vực blockchain, các giải pháp này hiện tại xem ra đều bất khả thi, một mặt là mô hình cung cấp dịch vụ chuyển từ tập trung sang phi tập trung, mặt khác việc lưu trữ dữ liệu chuyển từ lưu trữ cấu trúc sang lưu trữ theo chuỗi. Những thay đổi cơ bản này khiến các giải pháp trên nó cũng phải thay đổi tương ứng, nhưng hiện tại vẫn chưa tìm ra giải pháp "bộ nhớ đệm" hay "cơ sở dữ liệu phụ" phù hợp cho blockchain.
Cũng có những trường hợp DApp tham khảo giải pháp bộ nhớ đệm Web2, nhưng rõ ràng không mang tính phổ quát. Nếu đứng ở góc nhìn khung MUD, việc tích hợp giải pháp này đưa vào thêm yếu tố tập trung hóa, do đó cũng không lý tưởng lắm.
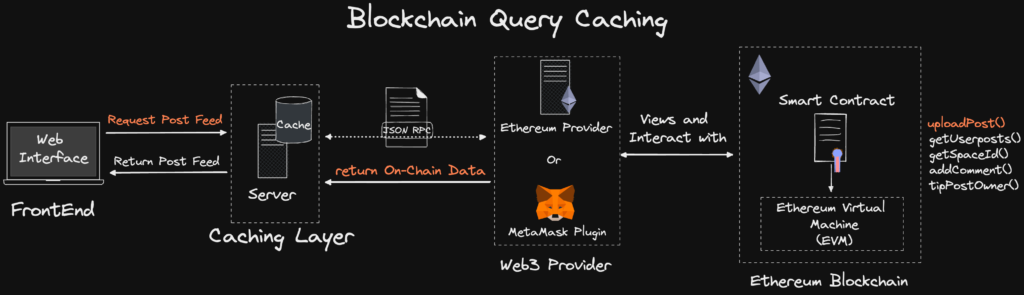
Kiến trúc DApp tích hợp giải pháp bộ nhớ đệm. Nguồn: https://smartbuilds.io/scaling-web3-social-media-blockchain-cache-layer/
Indexer là giải pháp ít tồi tệ nhất
Xét riêng về MUD, đây đã là bước tiến lớn trong lĩnh vực ứng dụng chuỗi, vì nó đồng thời giải quyết ba vấn đề:
1> Dữ liệu và logic trong hợp đồng thông minh gắn bó chặt chẽ, gây khó khăn cho việc nâng cấp logic
2> Thiếu cơ chế đồng bộ dữ liệu giữa chuỗi và client, dẫn đến trạng thái dữ liệu không nhất quán
3> Blockchain thiếu cơ chế kiểm soát truy cập thống nhất, dẫn đến lao động trùng lặp và rào cản tương tác nhất định.
Ý tưởng của MUD trong việc giải quyết vấn đề đọc dữ liệu là đặt một "nút đầy đủ" chỉ quan tâm dữ liệu hợp đồng hiện tại tại phía client, đội ngũ MUD gọi nó là "Namespaced Full-node", cũng chính là Indexer mà chúng ta đang nói đến.
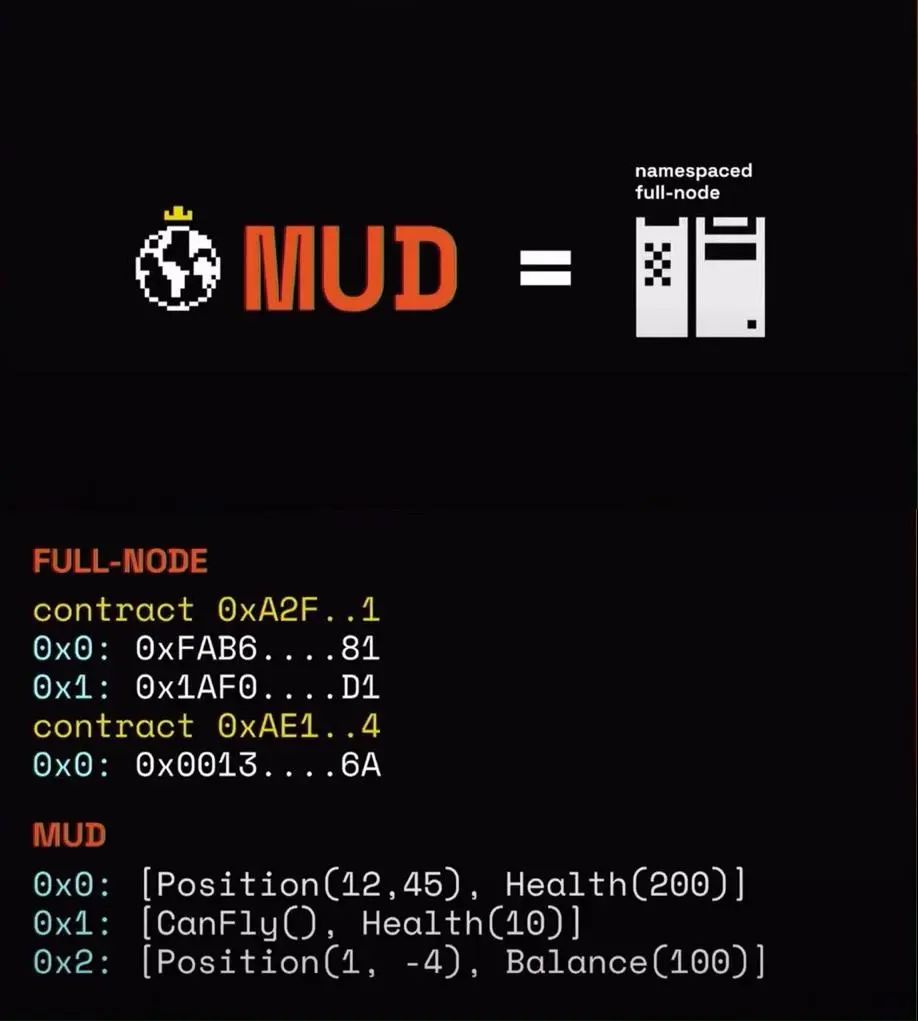
Nguồn: https://youtu.be/tLGdup5wmck?si=ykgQ4qwut4VLgimF
Giải pháp này trong lĩnh vực ứng dụng chuỗi, là bước tiến từ không có đến có, rõ ràng là một bước tiến lớn. Mặc dù không hoàn hảo, nhưng đã là khởi đầu không tồi, người đi sau có thể đứng trên vai người khổng lồ để tìm kiếm giải pháp tốt hơn. Tóm lại, Indexer của MUD là giải pháp ít tồi tệ nhất, nhưng chúng ta vẫn cần giải pháp tốt hơn nữa.
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News