

Bài viết mới nhất của Vitalik Buterin: Community Notes trên Twitter mang tinh thần mã hóa mạnh mẽ, kỳ vọng vào tương lai của các thử nghiệm mạng xã hội mới
Tuyển chọn TechFlowTuyển chọn TechFlow
Bài viết mới nhất của Vitalik Buterin: Community Notes trên Twitter mang tinh thần mã hóa mạnh mẽ, kỳ vọng vào tương lai của các thử nghiệm mạng xã hội mới
Mặc dù Community Notes không phải là một "dự án mã hóa", nhưng nó có thể là ví dụ gần nhất với "giá trị mã hóa" mà chúng ta từng thấy trong thế giới chủ lưu.
Tác giả: vitalik
Biên dịch: TechFlow
Hai năm qua, Twitter (X) có thể nói là đầy biến động. Năm ngoái, Elon Musk đã mua nền tảng này với giá 44 tỷ USD, sau đó tiến hành cải tổ toàn diện về nhân sự, kiểm duyệt nội dung, mô hình kinh doanh và văn hóa trang web — những thay đổi này nhiều khả năng đến từ sức ảnh hưởng mềm của Elon Musk hơn là các quyết sách chính sách cụ thể. Tuy nhiên, giữa những hành động gây tranh cãi này, một tính năng mới trên Twitter đã nhanh chóng trở nên quan trọng và dường như được yêu thích bởi các phe phái chính trị khác nhau: Community Notes.
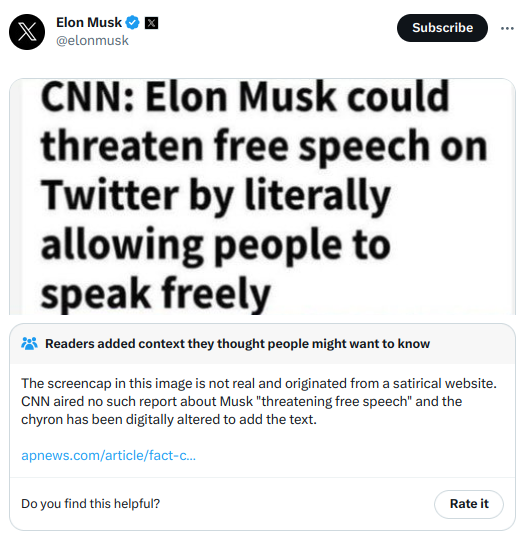
Community Notes là một công cụ kiểm chứng thực tế, đôi khi thêm chú thích bối cảnh vào các bài đăng Twitter, như trong ví dụ bài tweet của Elon Musk ở trên, nhằm mục đích kiểm chứng thông tin và chống lại tin giả. Nó ban đầu được gọi là Birdwatch và lần đầu tiên ra mắt dưới dạng dự án thử nghiệm vào tháng 1 năm 2021. Sau đó, nó được mở rộng dần, với giai đoạn phát triển nhanh nhất trùng với thời điểm Elon Musk tiếp quản Twitter vào năm ngoái. Ngày nay, Community Notes thường xuất hiện trên những bài tweet thu hút sự chú ý lớn trên Twitter, bao gồm cả những bài liên quan đến các chủ đề chính trị gây tranh cãi. Theo đánh giá của tôi, cũng như từ việc trao đổi với nhiều người thuộc các phe phái chính trị khác nhau, những ghi chú này khi xuất hiện đều mang tính thông tin và có giá trị.
Tuy nhiên, điều khiến tôi đặc biệt quan tâm là, mặc dù không phải là một “dự án mã hóa”, Community Notes có lẽ là ví dụ gần nhất mà chúng ta từng thấy trong thế giới phổ thông phản ánh “giá trị mã hóa”. Các ghi chú không do một nhóm chuyên gia trung ương lựa chọn viết hay điều phối; thay vào đó, bất kỳ ai cũng có thể viết và bỏ phiếu, và việc hiển thị ghi chú nào hoàn toàn do một thuật toán mã nguồn mở quyết định. Trang web Twitter có một hướng dẫn chi tiết và toàn diện mô tả cách thức hoạt động của thuật toán, bạn có thể tải về dữ liệu các ghi chú và phiếu bầu đã công bố, chạy thuật toán cục bộ và xác minh xem kết quả có khớp với nội dung hiển thị trên Twitter hay không. Dù chưa hoàn hảo, nhưng nó đáng ngạc nhiên khi khá gần với lý tưởng trung lập đáng tin cậy trong những tình huống gây tranh cãi, đồng thời vẫn rất hữu ích.
Thuật toán Community Notes hoạt động như thế nào?
Bất kỳ tài khoản Twitter nào đáp ứng một số điều kiện nhất định (cơ bản là: hoạt động hơn 6 tháng, không vi phạm quy định, đã xác minh số điện thoại) đều có thể đăng ký tham gia Community Notes. Hiện tại, người tham gia đang được chấp nhận từ từ và ngẫu nhiên, nhưng kế hoạch cuối cùng là cho phép mọi người đủ điều kiện đều được tham gia. Một khi được chấp nhận, trước tiên bạn có thể tham gia đánh giá các ghi chú hiện có; khi đánh giá của bạn đủ tốt (được đo bằng mức độ phù hợp với kết quả cuối cùng của ghi chú), bạn sẽ được quyền tự viết ghi chú của mình.
Khi bạn viết một ghi chú, nó sẽ nhận được một điểm số dựa trên đánh giá từ các thành viên khác trong Community Notes. Những đánh giá này có thể coi như lá phiếu theo ba mức độ: “có ích”, “khá có ích” và “vô ích”, tuy nhiên các đánh giá còn có thể chứa các nhãn khác đóng vai trò trong thuật toán. Dựa trên những đánh giá này, ghi chú sẽ nhận được một điểm số. Nếu điểm số vượt quá 0.40, ghi chú sẽ được hiển thị; nếu không, ghi chú sẽ không hiển thị.
Điểm độc đáo của thuật toán nằm ở cách tính điểm. Khác với các thuật toán đơn giản chỉ cộng hoặc lấy trung bình điểm đánh giá của người dùng rồi dùng làm kết quả cuối cùng, thuật toán chấm điểm của Community Notes cố gắng ưu tiên những ghi chú nhận được đánh giá tích cực từ những người có quan điểm khác nhau. Nói cách khác, nếu những người thường xuyên bất đồng lại đồng thuận về một ghi chú cụ thể, thì ghi chú đó sẽ nhận điểm cao.
Hãy đi sâu vào nguyên lý hoạt động. Chúng ta có một tập người dùng và một tập ghi chú; chúng ta có thể tạo một ma trận M, trong đó ô Mij biểu thị cách người thứ i đánh giá ghi chú thứ j.
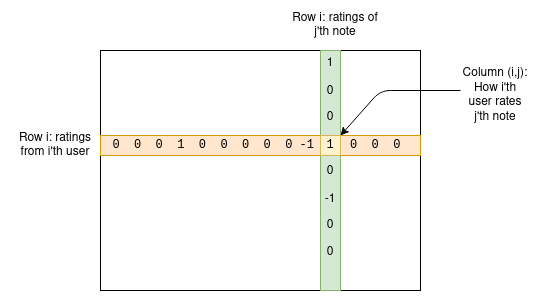
Với bất kỳ ghi chú nào, đa số người dùng không đánh giá nó, vì vậy phần lớn các ô trong ma trận sẽ bằng 0 — điều này không sao cả. Mục tiêu của thuật toán là xây dựng một mô hình gồm bốn yếu tố cho người dùng và ghi chú, gán cho mỗi người dùng hai thống kê mà ta có thể gọi là “thân thiện” và “cực đoan”, và cho mỗi ghi chú hai thống kê tương tự là “hữu ích” và “cực đoan”. Mô hình cố gắng dự đoán ma trận dựa trên các giá trị này, sử dụng công thức sau:
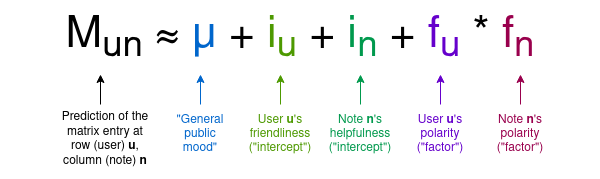
Xin lưu ý rằng ở đây tôi đưa ra các thuật ngữ được dùng trong bài báo Birdwatch, cũng như các tên gọi do tôi đặt để dễ hiểu hơn về ý nghĩa của các biến mà không cần đến khái niệm toán học:
-
μ là một tham số “tâm trạng công chúng”, đo lường mức độ người dùng nói chung thường cho điểm cao bao nhiêu.
-
iu là “mức độ thân thiện” của người dùng, tức là khả năng người đó có xu hướng cho điểm cao.
-
in là “mức độ hữu ích” của ghi chú, tức là khả năng ghi chú đó nhận được điểm cao. Đây là biến số chúng ta quan tâm.
-
fu hoặc fn là “cực đoan” của người dùng hoặc ghi chú, tức là vị trí của họ trên trục chính trị cực đoan. Về cơ bản, cực đoan âm đại diện cho “xu hướng cánh tả”, cực đoan dương là “xu hướng cánh hữu”, nhưng hãy lưu ý rằng trục cực đoan này được suy ra từ phân tích dữ liệu người dùng và ghi chú, chứ không bị cứng hóa khái niệm cánh tả – cánh hữu.
Thuật toán sử dụng một mô hình học máy cơ bản (gradient descent chuẩn) để tìm các giá trị tối ưu của các biến nhằm dự đoán các giá trị trong ma trận. Giá trị "hữu ích" được gán cho một ghi chú chính là điểm số cuối cùng của ghi chú đó. Nếu một ghi chú có độ hữu ích ít nhất +0.4, nó sẽ được hiển thị.
Chiêu thức then chốt ở đây là “cực đoan” hấp thụ những đặc điểm của một ghi chú khiến nó được một số người thích và người khác ghét, trong khi “hữu ích” chỉ đo lường những đặc điểm khiến nó được tất cả người dùng ưa thích. Do đó, việc chọn lọc theo “hữu ích” giúp xác định những ghi chú được công nhận xuyên đảng phái, đồng thời loại bỏ những ghi chú được cổ vũ nhiệt liệt trong một nhóm nhưng gây phản cảm ở nhóm khác.
Phần trên chỉ mô tả phần lõi của thuật toán. Trên thực tế, có rất nhiều cơ chế bổ sung được thêm vào. May mắn thay, chúng được mô tả công khai trong tài liệu. Những cơ chế này bao gồm:
-
Thuật toán được chạy nhiều lần, mỗi lần thêm vào một số “phiếu ảo” cực đoan được tạo ngẫu nhiên. Điều này có nghĩa là đầu ra thực tế cho mỗi ghi chú là một khoảng giá trị, và kết quả cuối cùng phụ thuộc vào “độ tin cậy thấp hơn” được lấy từ khoảng này, so sánh với ngưỡng 0.32.
-
Nếu nhiều người dùng (đặc biệt là những người có cực đoan tương tự ghi chú) đánh giá một ghi chú là “không hữu ích” và cùng chọn một “nhãn” cụ thể (ví dụ: “ngôn ngữ gây tranh cãi hoặc thiên vị”, “nguồn không hỗ trợ nội dung”) làm lý do, thì ngưỡng hữu ích cần thiết để hiển thị ghi chú sẽ tăng từ 0.4 lên 0.5 (con số nhỏ nhưng quan trọng trong thực tế).
-
Nếu một ghi chú được chấp nhận, độ hữu ích của nó phải giảm xuống dưới ngưỡng chấp nhận 0.01 điểm.
-
Thuật toán sẽ chạy nhiều lần với nhiều mô hình khác nhau, đôi khi nâng cao điểm cho những ghi chú có điểm hữu ích gốc từ 0.3 đến 0.4.
Tóm lại, bạn có một đoạn mã Python khá phức tạp với tổng cộng 6282 dòng, trải dài trên 22 tệp. Nhưng tất cả đều mở, bạn có thể tải dữ liệu ghi chú và phiếu bầu về, chạy thử và kiểm tra xem kết quả có khớp với hiện trạng trên Twitter hay không.
Trong thực tế, điều này diễn ra như thế nào?
Sự khác biệt lớn nhất giữa thuật toán này và phương pháp đơn giản lấy trung bình điểm từ phiếu bầu có lẽ là khái niệm mà tôi gọi là giá trị “cực đoan”. Tài liệu thuật toán gọi chúng là fu và fn, dùng f để chỉ factor vì hai thành phần này nhân với nhau; thuật ngữ tổng quát hơn vì sau này mong muốn biến fu và fn thành đa chiều.
“Cực đoan” được gán cho cả người dùng và ghi chú. Việc nối ID người dùng với tài khoản Twitter nền tảng được giữ bí mật có chủ ý, nhưng các ghi chú thì công khai. Trên thực tế, ít nhất với tập dữ liệu tiếng Anh, “cực đoan” do thuật toán tạo ra có liên hệ rất chặt chẽ với cánh tả và cánh hữu.
Dưới đây là một vài ví dụ về các ghi chú có cực đoan khoảng -0.8:
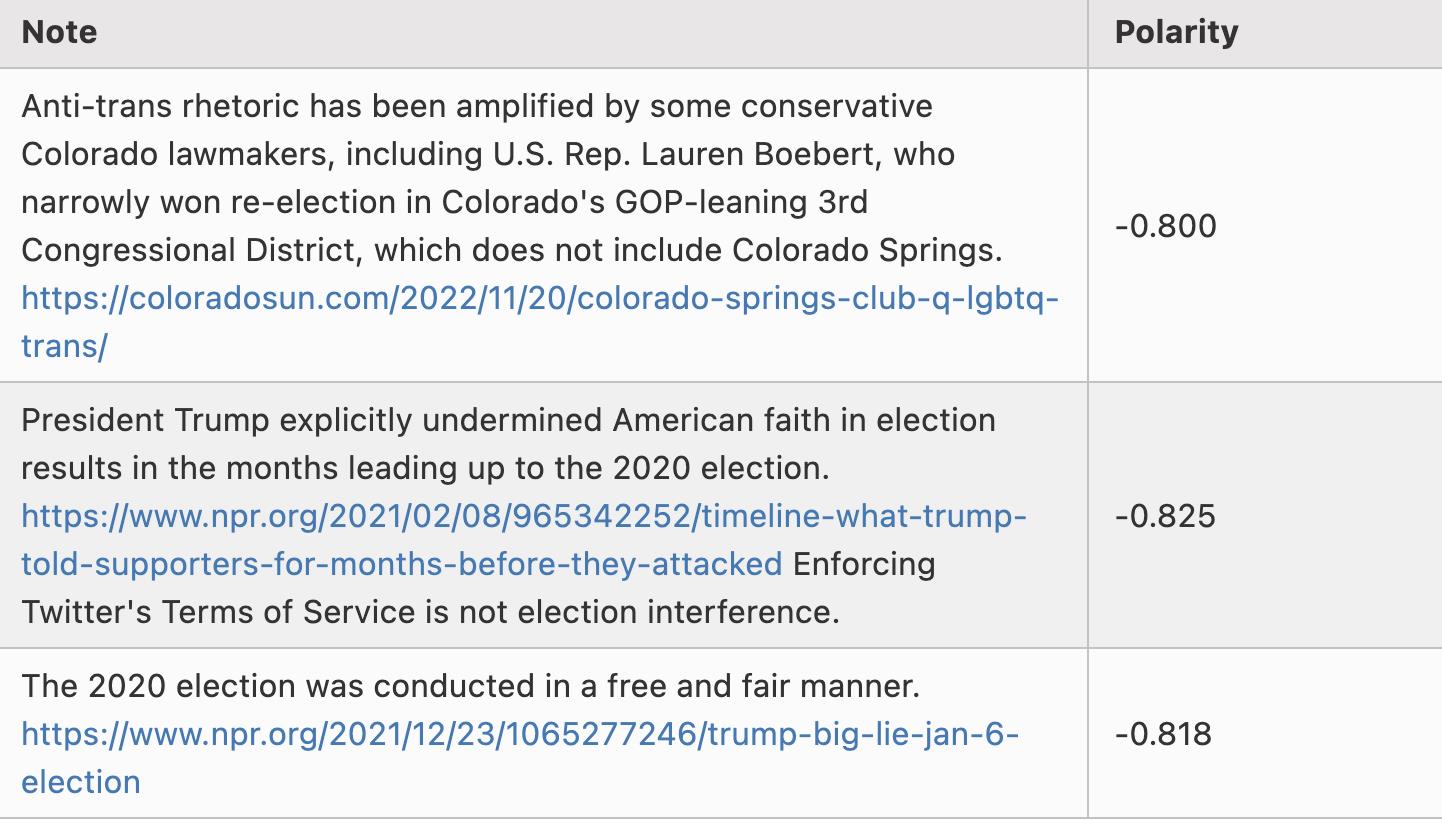
Xin lưu ý rằng tôi không chọn lọc ở đây; đây thực sự là ba dòng đầu tiên trong bảng tính scored_notes.tsv khi tôi chạy thuật toán cục bộ, với điểm cực đoan (trong bảng gọi là coreNoteFactor1) dưới -0.8.
Giờ hãy xem một vài ghi chú có cực đoan khoảng +0.8. Hóa ra nhiều trong số này hoặc là người Bồ Đào Nha bàn về chính trị Brazil, hoặc là fan Tesla giận dữ phản bác các chỉ trích về Tesla, nên tôi sẽ chọn lọc một chút để tìm những ghi chú không thuộc hai nhóm này:
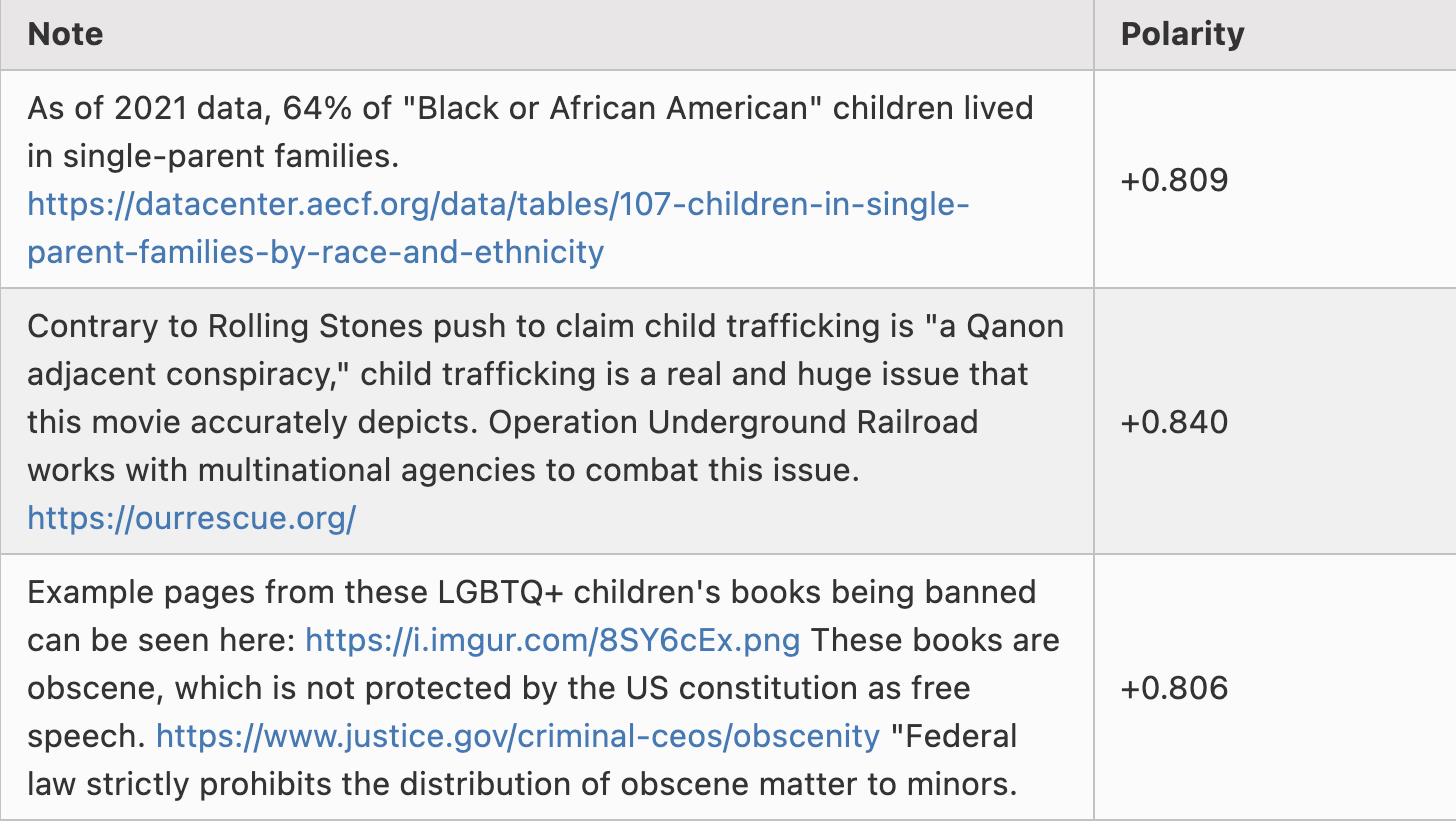
Một lần nữa, sự phân chia “cánh tả – cánh hữu” không bị mã hóa cứng vào thuật toán theo bất kỳ cách nào; nó được khám phá thông qua tính toán. Điều này cho thấy rằng nếu áp dụng thuật toán này vào các bối cảnh văn hóa khác, nó có thể tự động phát hiện ra các điểm phân chia chính trị chính và xây cầu nối giữa chúng.
Đồng thời, những ghi chú đạt điểm “hữu ích” cao nhất trông như thế này. Lần này, vì các ghi chú này thực sự hiển thị trên Twitter, tôi có thể chụp màn hình trực tiếp:
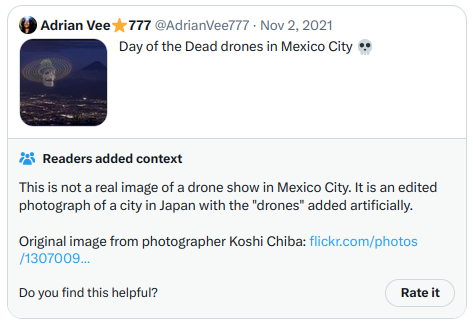
Và một ví dụ khác:
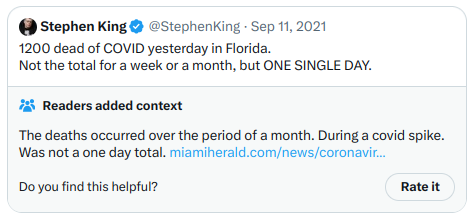
Với ghi chú thứ hai, nó liên quan trực tiếp hơn đến chủ đề chính trị đảng phái, nhưng lại là một ghi chú rõ ràng, chất lượng cao và cung cấp thông tin, do đó nhận được điểm cao. Nhìn chung, thuật toán dường như hiệu quả, và việc chạy mã để xác minh đầu ra cũng khả thi.
Tôi nghĩ gì về thuật toán này?
Khi phân tích thuật toán này, điều gây ấn tượng mạnh nhất với tôi là độ phức tạp của nó. Có một “phiên bản học thuật” sử dụng gradient descent để tìm nghiệm tối ưu cho phương trình ma trận và vector năm chiều, rồi có phiên bản thực tế — một chuỗi thuật toán phức tạp thực hiện nhiều lần chạy khác nhau với nhiều hệ số tùy ý dọc đường đi.
Ngay cả phiên bản học thuật cũng che giấu độ phức tạp bên dưới. Phương trình nó tối ưu là bậc bốn âm (vì có hạng fu*fn bình phương trong công thức dự đoán, và hàm chi phí đo bình phương sai số). Trong khi tối ưu phương trình bậc hai trên bất kỳ số biến nào hầu như luôn có nghiệm duy nhất và có thể tính bằng đại số tuyến tính cơ bản, thì tối ưu phương trình bậc bốn trên nhiều biến thường có nhiều nghiệm, do đó các vòng gradient descent có thể cho ra các kết quả khác nhau. Những thay đổi nhỏ ở đầu vào có thể khiến thuật toán rơi từ cực tiểu cục bộ này sang cực tiểu khác, làm thay đổi lớn đầu ra.
Sự khác biệt này đối với tôi giống như sự khác biệt giữa thuật toán của nhà kinh tế và của kỹ sư. Thuật toán của nhà kinh tế trong điều kiện lý tưởng nhấn mạnh tính đơn giản, dễ phân tích, và có các đặc tính toán học rõ ràng chứng minh nó là tối ưu (hoặc ít tồi tệ nhất) cho nhiệm vụ giải quyết, lý tưởng nhất là còn chứng minh được mức độ thiệt hại nếu ai đó cố lợi dụng nó. Ngược lại, thuật toán của kỹ sư được xây dựng qua quá trình thử sai lặp lại, xem trong môi trường vận hành của kỹ sư cái gì hiệu quả và cái gì không. Thuật toán kỹ sư thực dụng, có thể hoàn thành nhiệm vụ; còn thuật toán kinh tế sẽ không mất kiểm soát hoàn toàn khi gặp tình huống bất ngờ.
Hoặc, như triết gia internet danh tiếng roon (còn gọi là tszzl) từng nói về chủ đề liên quan:

Tất nhiên, tôi cho rằng khía cạnh “thẩm mỹ lý thuyết” của tiền mã hóa là cần thiết, vì nó giúp phân biệt chính xác giữa các giao thức thực sự không cần tin cậy và những giao thức trông đẹp, hoạt động bề ngoài tốt nhưng thực chất lại cần tin tưởng vào một số tác nhân tập trung, hoặc tệ hơn, có thể là lừa đảo thuần túy.
Học sâu hiệu quả trong điều kiện bình thường, nhưng lại có điểm yếu không tránh khỏi trước các cuộc tấn công học máy đối kháng. Nếu làm tốt, các bẫy kỹ thuật và bậc thang trừu tượng cao có thể chống lại những cuộc tấn công này. Vì vậy, tôi đặt câu hỏi: liệu chúng ta có thể biến chính Community Notes thành một thứ giống kiểu thuật toán kinh tế học hơn không?
Để hiểu rõ điều này nghĩa là gì, hãy khám phá một thuật toán mà tôi từng thiết kế vài năm trước cho mục đích tương tự: Pairwise-bounded quadratic funding (thiết kế mới cho tài trợ bậc hai).
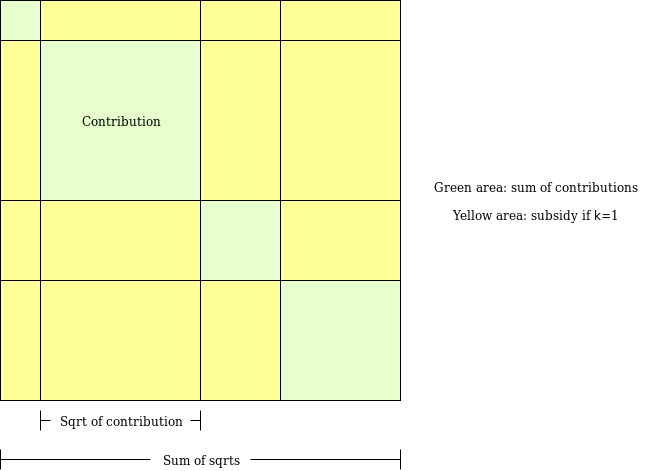
Mục tiêu của Pairwise-bounded quadratic funding là lấp một lỗ hổng trong tài trợ bậc hai “thông thường”, nơi ngay cả hai người tham gia cấu kết cũng có thể đóng góp số tiền rất lớn vào một dự án giả, hoàn trả tiền cho nhau và nhận được trợ cấp lớn làm cạn kiệt toàn bộ quỹ. Trong Pairwise-bounded quadratic funding, chúng ta gán cho mỗi cặp người tham gia một ngân sách giới hạn M. Thuật toán duyệt qua tất cả các cặp người tham gia, nếu quyết định trợ cấp cho dự án P vì cả A và B đều ủng hộ, thì trợ cấp đó sẽ được trừ từ ngân sách dành cho cặp (A,B). Do đó, ngay cả khi k người cấu kết, số tiền họ đánh cắp từ cơ chế cũng tối đa là k*(k-1)*M.
Dạng thuật toán này không phù hợp với bối cảnh Community Notes vì mỗi người dùng chỉ bỏ rất ít phiếu: trung bình, số phiếu chung giữa hai người dùng bất kỳ đều bằng 0, nên không thể hiểu được “cực đoan” của người dùng chỉ bằng cách xem riêng từng cặp. Mục tiêu của mô hình học máy chính là cố gắng “điền đầy” ma trận từ dữ liệu nguồn rất thưa thớt, thứ không thể phân tích trực tiếp theo cách này. Nhưng thách thức của phương pháp này là cần nỗ lực bổ sung để tránh kết quả dao động mạnh khi đối mặt với một số ít phiếu xấu.
Community Notes thực sự có kháng cự được sự phân cực trái-phải?
Chúng ta có thể phân tích xem thuật toán Community Notes có thực sự kháng cự được sự cực đoan hay không, tức là nó có hoạt động tốt hơn một thuật toán bỏ phiếu ngây thơ hay không. Loại bỏ phiếu ngây thơ này đã phần nào kháng cự sự cực đoan: một bài có 200 like và 100 dislike sẽ biểu hiện kém hơn bài chỉ có 200 like. Nhưng Community Notes có làm tốt hơn không?
Từ thuật toán trừu tượng, khó có thể nói chắc. Một bài có điểm trung bình cao nhưng gây chia rẽ tại sao lại không thể có “cực đoan” mạnh và “hữu ích” cao? Ý tưởng là nếu các phiếu này mâu thuẫn nhau, “cực đoan” nên “hấp thụ” những đặc điểm khiến bài đó nhận nhiều phiếu, nhưng thực tế có đúng vậy không?
Để kiểm tra, tôi đã chạy 100 vòng với phiên bản đơn giản hóa của riêng mình. Kết quả trung bình như sau:

Trong thử nghiệm này, các ghi chú “tốt” nhận điểm +2 từ người dùng cùng phe, +0 từ người dùng phe đối lập; các ghi chú “tốt nhưng thiên lệch hơn” nhận +4 từ cùng phe, -2 từ phe đối lập. Mặc dù điểm trung bình giống nhau, nhưng cực đoan khác nhau. Và thực tế, điểm “hữu ích” trung bình của các ghi chú “tốt” dường như cao hơn các ghi chú “tốt nhưng thiên lệch hơn”.
Một thuật toán gần với “thuật toán kinh tế học” hơn sẽ có câu chuyện rõ ràng hơn về cách nó trừng phạt sự cực đoan.
Trong các tình huống rủi ro cao, điều này hữu ích đến đâu?
Chúng ta có thể hiểu phần nào qua một trường hợp cụ thể. Khoảng một tháng trước, Ian Bremmer phàn nàn rằng một bài tweet của quan chức chính phủ Trung Quốc đã bị gắn một ghi chú Community Note mang tính chỉ trích gay gắt, nhưng ghi chú đó đã bị xóa.
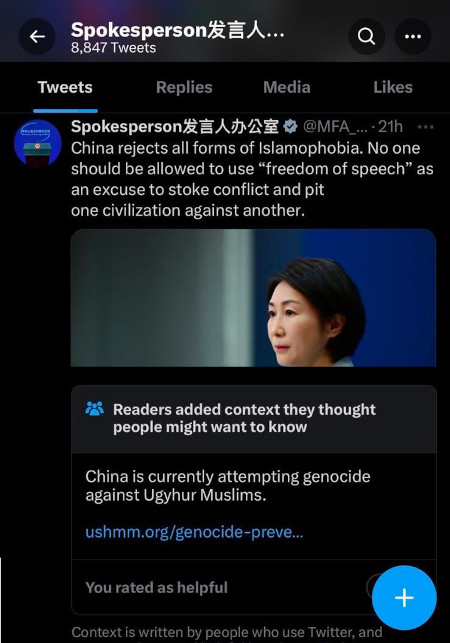
Đây là một nhiệm vụ khó khăn. Thiết kế cơ chế trong môi trường cộng đồng Ethereum là một chuyện, nơi lời phàn nàn lớn nhất có thể chỉ là 20.000 đô la chảy vào tay một influencer Twitter cực đoan. Nhưng khi liên quan đến các vấn đề chính trị và địa chính trị ảnh hưởng hàng triệu người, mọi người thường hợp lý khi giả định động cơ tồi tệ nhất. Tuy nhiên, nếu các nhà thiết kế cơ chế muốn tạo ảnh hưởng lớn đến thế giới, thì tương tác với các môi trường rủi ro cao là điều thiết yếu.
Trong trường hợp Twitter, có một lý do rõ ràng để nghi ngờ can thiệp tập trung: Elon Musk có nhiều lợi ích kinh doanh tại Trung Quốc, do đó có thể Elon Musk đã ép đội Community Notes can thiệp vào đầu ra thuật toán và xóa ghi chú cụ thể này.
May mắn thay, thuật toán này mã nguồn mở và có thể xác minh, nên chúng ta thực sự có thể đào sâu! Hãy làm điều đó. URL bài tweet gốc là https://twitter.com/MFA_China/status/1676157337109946369. Số 1676157337109946369 ở cuối là ID bài tweet. Chúng ta có thể tìm kiếm ID này trong dữ liệu có thể tải về và xác định dòng cụ thể trong bảng tính chứa ghi chú trên:
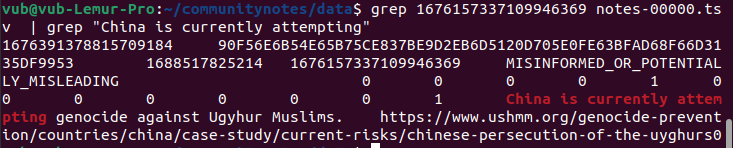
Ở đây, chúng ta có ID của ghi chú, 1676391378815709184. Sau đó, chúng ta tìm kiếm ID này trong các tệp scored_notes.tsv và note_status_history.tsv do thuật toán tạo ra. Chúng ta nhận được kết quả sau:
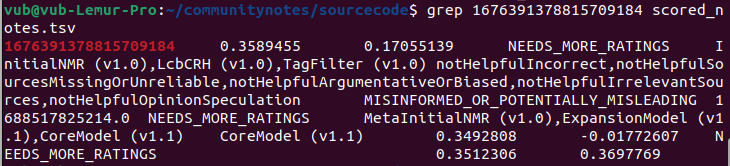

Cột thứ hai trong đầu ra đầu tiên là điểm số hiện tại của ghi chú. Đầu ra thứ hai cho thấy lịch sử: trạng thái hiện tại của ghi chú ở cột thứ bảy (NEEDS_MORE_RATINGS), và trạng thái đầu tiên không phải NEEDS_MORE_RATINGS trước đó ở cột thứ năm (CURRENTLY_RATED_HELPFUL). Do đó, chúng ta thấy thuật toán trước tiên hiển thị ghi chú, sau đó xóa nó khi điểm số giảm nhẹ — dường như không có can thiệp tập trung.
Chúng ta cũng có thể xem xét theo cách khác bằng cách nhìn vào các phiếu bầu. Chúng ta có thể quét tệp ratings-00000.tsv để tách tất cả các đánh giá cho ghi chú này và xem có bao nhiêu đánh giá HELPFUL và NOT_HELPFUL:

Tuy nhiên, nếu sắp xếp theo dấu thời gian và xem 50 phiếu đầu tiên, bạn thấy có 40 phiếu HELPFUL và 9 phiếu NOT_HELPFUL. Do đó, chúng ta rút ra cùng kết luận: đối tượng ban đầu đánh giá ghi chú tích cực hơn, trong khi đối tượng sau đánh giá thấp hơn, nên điểm số bắt đầu cao và giảm dần theo thời gian.
Thật không may, việc giải thích chính xác cách trạng thái ghi chú thay đổi rất khó: không đơn giản là “trước đây điểm trên 0.40, giờ dưới 0.40 nên bị xóa”. Thay vào đó, một lượng lớn phản hồi NOT_HELPFUL đã kích hoạt một trong các điều kiện ngoại lệ, làm tăng điểm hữu ích cần thiết để ghi chú duy trì trên ngưỡng.
Đây là một cơ hội học tập tuyệt vời, dạy chúng ta một bài học: để một thuật toán trung lập đáng tin cậy thực sự đáng tin cậy, cần giữ cho nó đơn giản. Nếu một ghi chú chuyển từ được chấp nhận sang bị từ chối, phải có một câu chuyện đơn giản và rõ ràng giải thích lý do tại sao.
Tất nhiên, còn một cách hoàn toàn khác để thao túng cuộc bỏ phiếu: Brigading. Những người thấy một ghi chú họ không đồng tình có thể kêu gọi một cộng đồng nhiệt tình (hoặc tệ hơn, một lượng lớn tài khoản giả) để đánh giá NOT_HELPFUL, và có thể không cần nhiều phiếu để đưa ghi chú từ “hữu ích” thành “cực đoan”. Để giảm đúng mức độ dễ bị tổn thương của thuật toán trước các cuộc tấn công phối hợp này, cần thêm phân tích và nỗ lực. Một cải tiến khả dĩ là không cho phép người dùng bất kỳ bỏ phiếu cho ghi chú nào, mà dùng thuật toán “đề xuất cho bạn” để phân ghi chú ngẫu nhiên cho người đánh giá, và chỉ cho phép họ đánh giá những ghi chú được phân.
Community Notes có “gan dạ” đủ không?
Tôi thấy chỉ trích chính đối với Community Notes cơ bản là nó làm chưa đủ. Tôi đã thấy hai bài viết gần đây đề cập điều này. Trích một bài:
Chương trình này chịu một giới hạn nghiêm trọng: để một Community Note được công khai, nó phải nhận được sự chấp nhận phổ quát từ mọi phe phái chính trị.
“Nó phải có sự đồng thuận ý thức hệ,” ông nói. “Nghĩa là người cánh tả và cánh hữu phải đồng ý rằng ghi chú này phải được đính kèm vào bài tweet này.”
Ông nói, về cơ bản, nó cần “đạt được sự nhất trí xuyên ý thức hệ về sự thật, và trong môi trường ngày càng phân cực đảng phái, việc đạt được sự đồng thuận như vậy gần như là không thể.”
Đây là một vấn đề nan giải, nhưng cuối cùng tôi thiên về quan điểm thà để mười bài tweet sai sự thật lan truyền tự do, còn hơn để một bài bị gắn ghi chú bất công. Chúng ta đã chứng kiến nhiều năm kiểm chứng thực tế, hành động gan dạ, từ góc nhìn “chúng ta biết sự thật, chúng ta biết một bên thường xuyên nói dối hơn bên kia”. Kết quả ra sao?

Thành thật mà nói, khái niệm kiểm chứng thực tế đang bị hoài nghi khá phổ biến. Ở đây, một chiến lược là nói: bỏ qua những người chỉ trích, nhớ rằng các chuyên gia kiểm chứng thực tế thực sự hiểu sự thật hơn bất kỳ hệ thống bỏ phiếu nào, và kiên trì. Nhưng dốc toàn lực theo hướng này dường như đầy rủi ro. Việc xây dựng các tổ chức xuyên đảng phái ít nhất được mọi người tôn trọng ở mức độ nào đó là có giá trị. Giống như câu châm ngôn của William Blackstone và tòa án, tôi nghĩ để duy trì sự tôn trọng này, cần một hệ thống mắc lỗi thiếu sót chứ không phải lỗi chủ động. Vì vậy, đối với tôi, việc có ít nhất một tổ chức lớn theo con đường khác và coi trọng sự tôn trọng xuyên đảng phái hiếm hoi như một tài nguyên quý giá, dường như là điều đáng giá.
Lý do khác khiến tôi nghĩ Community Notes thận trọng một chút là được, vì tôi không cho rằng mỗi bài tweet sai sự thật, thậm chí phần lớn các bài, nên nhận ghi chú sửa chữa. Ngay cả khi chưa đến một phần trăm bài tweet sai sự thật nhận được ghi chú cung cấp bối cảnh hoặc sửa sai, Community Notes vẫn cung cấp một dịch vụ giáo dục cực kỳ có giá trị. Mục tiêu không phải là sửa tất cả; ngược lại, mục tiêu là nhắc nhở mọi người rằng tồn tại nhiều quan điểm, một số bài trông thuyết phục và hấp dẫn khi xem riêng thực ra khá sai lệch, và bạn, đúng vậy, bạn hoàn toàn có thể thực hiện tìm kiếm cơ bản trên internet để xác minh nó sai.
Community Notes không thể và cũng không nhằm trở thành liều thuốc chữa bách bệnh cho mọi vấn đề trong nhận thức luận công cộng. Dù nó không giải quyết được gì, vẫn còn đủ chỗ cho các cơ chế khác lấp đầy, dù là các công cụ kỳ lạ như thị trường dự đoán, hay các tổ chức lâu đời thuê nhân viên toàn thời gian có chuyên môn lĩnh vực, đều có thể cố gắng lấp khoảng trống đó.
Kết luận
Community Notes không chỉ là một thí nghiệm mạng xã hội hấp dẫn, mà còn là một ví dụ điển hình cho kiểu thiết kế cơ chế mới nổi: cố gắng có chủ ý nhận diện sự cực đoan và ưu tiên thúc đẩy sự hợp tác xuyên biên giới thay vì kéo dài sự chia rẽ.
Hai ví dụ khác tôi biết trong nhóm này là: (i) cơ chế tài trợ bậc hai theo cặp được dùng trong Gitcoin Grants, và (ii) Polis, một công cụ thảo luận sử dụng thuật toán phân cụm để giúp cộng đồng nhận diện các tuyên bố được ưa chuộng phổ biến vượt qua những người thường có quan điểm khác nhau. Lĩnh vực thiết kế cơ chế này rất có giá trị, tôi hy vọng sẽ thấy thêm nhiều nghiên cứu học thuật trong lĩnh vực này.
Mức độ minh bạch thuật toán mà Community Notes cung cấp không hoàn toàn là mạng xã hội phi tập trung hoàn toàn — nếu bạn không đồng ý cách Community Notes hoạt động, bạn không thể xem cùng nội dung qua một thuật toán khác. Nhưng đây là kết quả gần nhất mà các ứng dụng siêu quy mô có thể đạt được trong vài năm tới, và chúng ta có thể thấy nó đã mang lại nhiều giá trị, vừa ngăn chặn thao túng tập trung, vừa đảm bảo các nền tảng không tham gia thao túng như vậy nhận được sự công nhận xứng đáng.
Tôi mong chờ được chứng kiến sự phát triển và trưởng thành của Community Notes và nhiều thuật toán cùng tinh thần trong thập kỷ tới.
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News














