

암호화 퍼블릭 트리지 시리즈: Polymarket의 데이터 인덱싱 문제
글: shew
요약
GCC Research 칼럼의 '암호화 공공재의 비극' 시리즈에 오신 것을 환영합니다.
이번 시리즈에서는 암호화 세계에서 핵심 노드에 위치하면서도 점차 규범이 무너지고 있는 '공공재'들에 주목할 것입니다. 이들은 생태계 전체의 기반 인프라이지만, 종종 인센티브 부족, 거버넌스 불균형, 심지어 점진적인 중앙집중화라는 어려움에 직면해 있습니다. 암호 기술이 추구하는 이상과 현실 속의 안정성 간의 긴장은 바로 이러한 구석에서 엄격한 시험을 받고 있습니다.
이번 호에서는 이더리움 생태계에서 가장 '주류로 진입한' 애플리케이션 중 하나인 Polymarket 및 그 데이터 인덱싱 도구를 다룹니다. 특히 올해 들어 트럼프의 당선, 우크라이나 희토류 거래 관련 오라클 조작, 제렌스키 대통령의 양복 색깔을 놓고 벌이는 정치적 내기 등 사건들을 중심으로 Polymarket은 여러 차례 언론의 초점이 되었으며, 이로 인해 Polymarket이 운용하는 자금 규모와 시장 영향력 또한 논란을 무시할 수 없게 만들었습니다.
그러나 '탈중앙 예측 시장'을 대표하는 이 제품의 핵심 기반 모듈인 데이터 인덱싱은 정말로 탈중앙화되었을까요? 왜 The Graph와 같은 공공 인프라가 기대되는 역할을 수행하지 못했을까요? 실제로 사용 가능하고 지속 가능한 데이터 인덱싱 공공재는 어떤 형태여야 할까요?
1. 중앙화된 데이터 플랫폼의 다운타임이 초래한 연쇄 반응
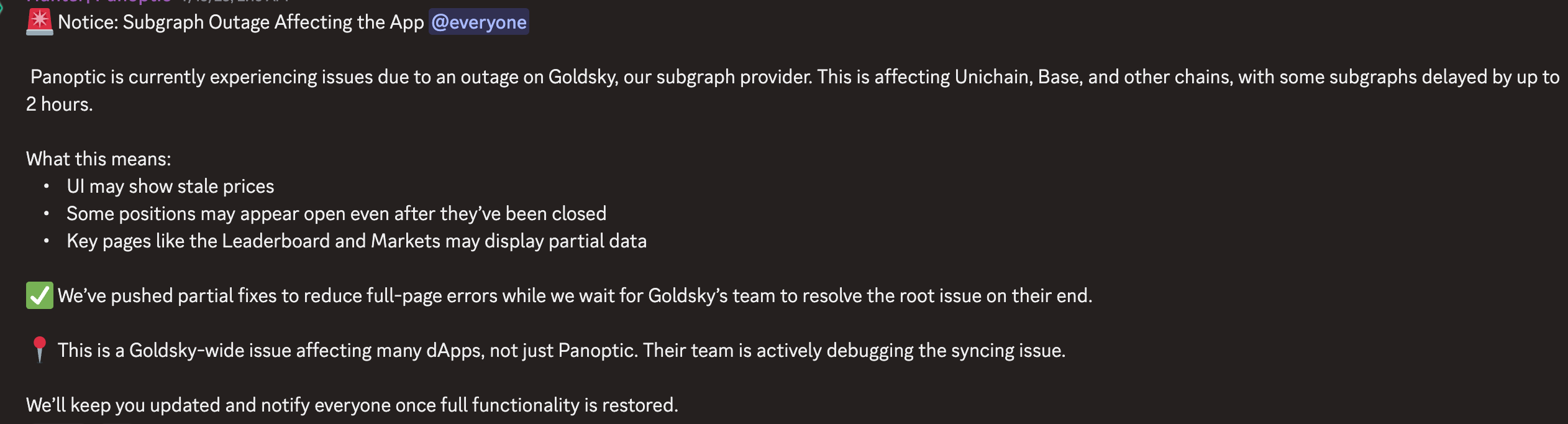
2024년 7월, Goldsky는 6시간 동안 서비스가 마비되는 사고를 겪었습니다(Goldsky는 Web3 개발자를 위한 실시간 블록체인 데이터 인프라 플랫폼으로, 인덱싱, 서브그래프, 스트리밍 데이터 서비스를 제공하며 데이터 기반의 탈중앙 앱을 신속하게 구축할 수 있도록 돕습니다). 이로 인해 이더리움 생태계의 많은 프로젝트들이 마비되었습니다. 예를 들어 DeFi 프론트엔드는 사용자의 포지션 및 잔액 정보를 표시할 수 없었고, 예측 시장 Polymarket 역시 정확한 데이터를 보여줄 수 없었으며, 수많은 프로젝트가 프론트엔드 사용자 입장에서는 완전히 사용 불가능한 상태처럼 보였습니다.
이러한 일은 탈중앙화 애플리케이션 세계에서는 발생해서는 안 됩니다. 결국 블록체인 기술의 설계 목적은 단일 장애 지점을 제거하는 것이 아니었을까요? Goldsky 사태는 불편한 사실을 드러냅니다. 블록체인 자체는 최대한 탈중앙화되어 있지만, 체인 위에 구축된 애플리케이션이 사용하는 인프라는 여전히 상당한 수준의 중앙화된 서비스를 포함하고 있다는 점입니다.
원인을 살펴보면, 블록체인 데이터 인덱싱 및 검색은 '비배제성, 비경쟁성'을 갖춘 디지털 공공재로서 사용자는 무료 또는 매우 낮은 요금을 기대하지만, 그 이면에는 강도 높은 하드웨어, 저장 공간, 대역폭 및 운영 인력의 지속적인 투자가 필요합니다. 지속 가능한 수익 모델이 부족하면 승자독식의 집중화 구조가 나타납니다. 한 서비스 제공업체가 속도와 자본에서 초기 우위를 확보하면 개발자들은 대부분의 쿼리 트래픽을 해당 서비스로 유도하게 되며, 다시 단일 의존 구조가 형성됩니다. Gitcoin 등의 공익 프로젝트는 반복적으로 "오픈소스 인프라는 수십억 달러의 가치를 창출하지만, 그 개발자는 종종 월세조차 감당하기 어렵다"고 강조해왔습니다.
이는 우리가 탈중앙화 세계에서 공공재 지원, 재분배 또는 커뮤니티 주도의 조치를 통해 Web3 인프라 다양성을 확대해야 한다는 점을 경고합니다. 그렇지 않으면 중앙화 문제가 재발할 것입니다. 우리는 DApp 개발자들에게 로컬 우선 제품을 구축할 것을 촉구하며, 기술 커뮤니티가 DApp 설계 시 데이터 검색 서비스 장애 상황을 고려하여 데이터 검색 인프라 없이도 사용자가 프로젝트와 상호작용할 수 있도록 보장할 것을 요청합니다.
2. 당신이 Dapp에서 보는 데이터는 어디서 오는가?
왜 Goldsky와 같은 사태가 발생하는지를 이해하려면 DApp의 내부 작동 메커니즘을 깊이 있게 알아야 합니다. 일반 사용자에게 DApp은 보통 두 부분으로 구성됩니다. 체인 상의 스마트 계약과 프론트엔드 페이지입니다. 대부분의 사용자는 Etherscan 등의 도구를 이용해 체인 상의 거래 상태를 확인하고 프론트엔드에서 필요한 정보를 얻으며, 프론트엔드를 통해 거래를 발행하고 계약과 상호작용하는 데 익숙합니다. 그러나 프론트엔드에 표시되는 이러한 데이터는 정확히 어디서 오는 것일까요?
불가결한 데이터 검색 서비스
예를 들어 독자가 대출 프로토콜을 개발 중이라 가정합시다. 이 프로토콜은 사용자의 포지션 현황과 각 포지션의 증거금 및 부채 상태를 표시해야 합니다. 단순한 생각으로는 프론트엔드가 직접 체인에서 이러한 데이터를 읽어오면 된다고 할 수 있습니다. 그러나 실제로는 대출 프로토콜의 스마트 계약이 사용자 주소로 포지션 데이터를 조회하는 것을 허용하지 않으며, 대신 포지션 ID를 이용해 특정 포지션 데이터를 조회하는 함수를 제공합니다. 따라서 프론트엔드에 사용자의 포지션 현황을 표시하려면 현재 시스템 내 모든 포지션을 검색한 후 해당 사용자의 포지션을 찾아야 합니다. 이는 수백만 페이지 분량의 장부를 일일이 수작업으로 특정 정보를 찾도록 요구하는 것과 같습니다. 기술적으로는 가능하지만 극도로 느리고 비효율적입니다. 실제로 프론트엔드는 이런 검색 과정을 수행하기 어렵습니다. 대규모 DeFi 프로젝트의 검색 작업조차 서버상의 로컬 노드를 직접 활용해도 종종 수 시간이 소요됩니다.
따라서 데이터 획득을 가속화하기 위해 인프라를 도입해야 합니다. Goldsky 등의 기업이 바로 이러한 데이터 인덱싱 서비스를 제공합니다. 아래 이미지는 데이터 인덱싱 서비스가 애플리케이션에 제공할 수 있는 데이터 유형을 보여줍니다.

여기서 독자 중 일부는 이더리움 생태계에 탈중앙화된 데이터 검색 플랫폼인 TheGraph가 존재한다는 점을 떠올릴 수 있습니다. TheGraph와 Goldsky는 어떤 관계가 있을까요? 그리고 왜 많은 DeFi 프로젝트들이 더 탈중앙화된 TheGraph가 아닌 Goldsky를 데이터 공급자로 선택하는 것일까요?
TheGraph / Goldsky와 SubGraph의 관계
위 질문에 답하기 위해 먼저 몇 가지 기술 개념을 이해해야 합니다.
-
SubGraph는 개발자가 체인 상의 데이터를 읽고 요약하는 코드를 작성하고, 이를 특정 방법으로 프론트엔드에 표시할 수 있도록 하는 개발 프레임워크입니다.
-
TheGraph는 초기의 탈중앙화 데이터 검색 플랫폼으로, AssemblyScript로 작성된 SubGraph 프레임워크를 개발했습니다. 개발자는 subgraph 프레임워크를 사용해 프로그램을 작성함으로써 계약 이벤트를 수집하고 이를 데이터베이스에 기록할 수 있으며, 이후 사용자는 GraphQL 방식으로 데이터를 읽거나 SQL 코드로 직접 데이터베이스를 조회할 수 있습니다.
-
일반적으로 SubGraph를 실행하는 서비스 제공업체를 SubGraph 운영자라고 부릅니다. TheGraph와 Goldsky 모두 실제로 SubGraph의 호스팅 업체입니다. SubGraph는 단지 개발 프레임워크일 뿐이며, 이 프레임워크로 개발된 프로그램은 서버 내에서 실행되어야 하기 때문입니다. Goldsky 문서에는 다음과 같은 내용이 포함되어 있음을 확인할 수 있습니다:
여기서 독자 중 일부는 왜 SubGraph에 여러 운영자가 존재하는지 궁금할 수 있습니다.
이는 SubGraph 프레임워크가 블록에서 데이터를 어떻게 읽어 데이터베이스에 기록할지에 대해서만 규정하고 있기 때문입니다.
데이터가 SubGraph 프로그램으로 어떻게 유입되고, 최종 출력 결과가 어떤 데이터베이스에 기록될지는 구현하지 않았으며, 이러한 부분은 SubGraph 운영자가 자체적으로 구현해야 합니다.
일반적으로 SubGraph 운영자는 노드 수정 등을 통해 더 빠른 속도를 실현하며, 서로 다른 운영자(TheGraph, Goldsky 등)는 서로 다른 전략과 기술 방안을 가지고 있습니다.
TheGraph는 현재 Firehouse 기술 방안을 사용하고 있으며, 이 기술 도입 이후 TheGraph는 과거보다 훨씬 빠른 데이터 검색이 가능해졌습니다. 반면 Goldsky는 SubGraph 운영의 핵심 프로그램을 오픈소스로 공개하지 않았습니다.
앞서 언급했듯이, TheGraph는 탈중앙화된 데이터 검색 플랫폼입니다. Uniswap v3 subgraph의 예를 보면, Uniswap v3에 데이터 검색 서비스를 제공하는 운영자가 다수 존재함을 알 수 있습니다. 따라서 TheGraph를 SubGraph 운영자의 통합 플랫폼으로 볼 수 있습니다. 사용자는 자신이 작성한 SubGraph 코드를 TheGraph에 제출하면, TheGraph 내부의 일부 운영자가 사용자를 대신해 데이터를 검색할 수 있습니다.
Goldsky의 요금제
Goldsky와 같은 중앙화 플랫폼의 경우, Goldsky는 자원 사용량 기반의 간단한 요금제를 가지고 있으며, 이는 인터넷에서 가장 일반적인 SaaS 플랫폼의 과금 방식으로, 대부분의 기술자가 익숙합니다. 아래 이미지는 Goldsky의 요금 산정기를 보여줍니다:
TheGraph의 요금제
TheGraph는 일반적인 과금 방식과 완전히 다른 요금 방안을 갖고 있으며, 이 방안은 GRT 토큰 이코노미와 관련이 있습니다. 아래 이미지는 GRT 전체 토큰 이코노미를 보여줍니다:
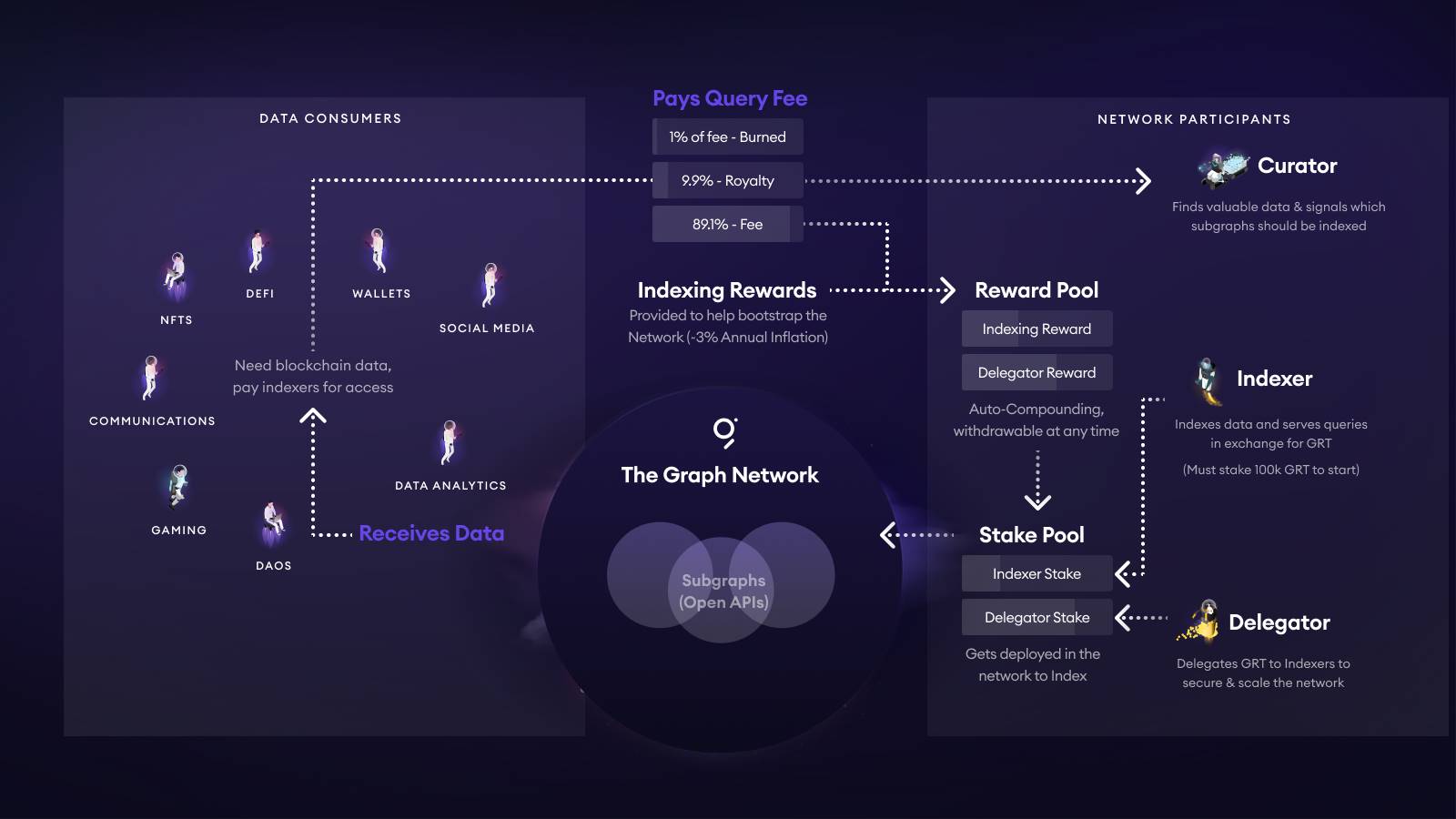
-
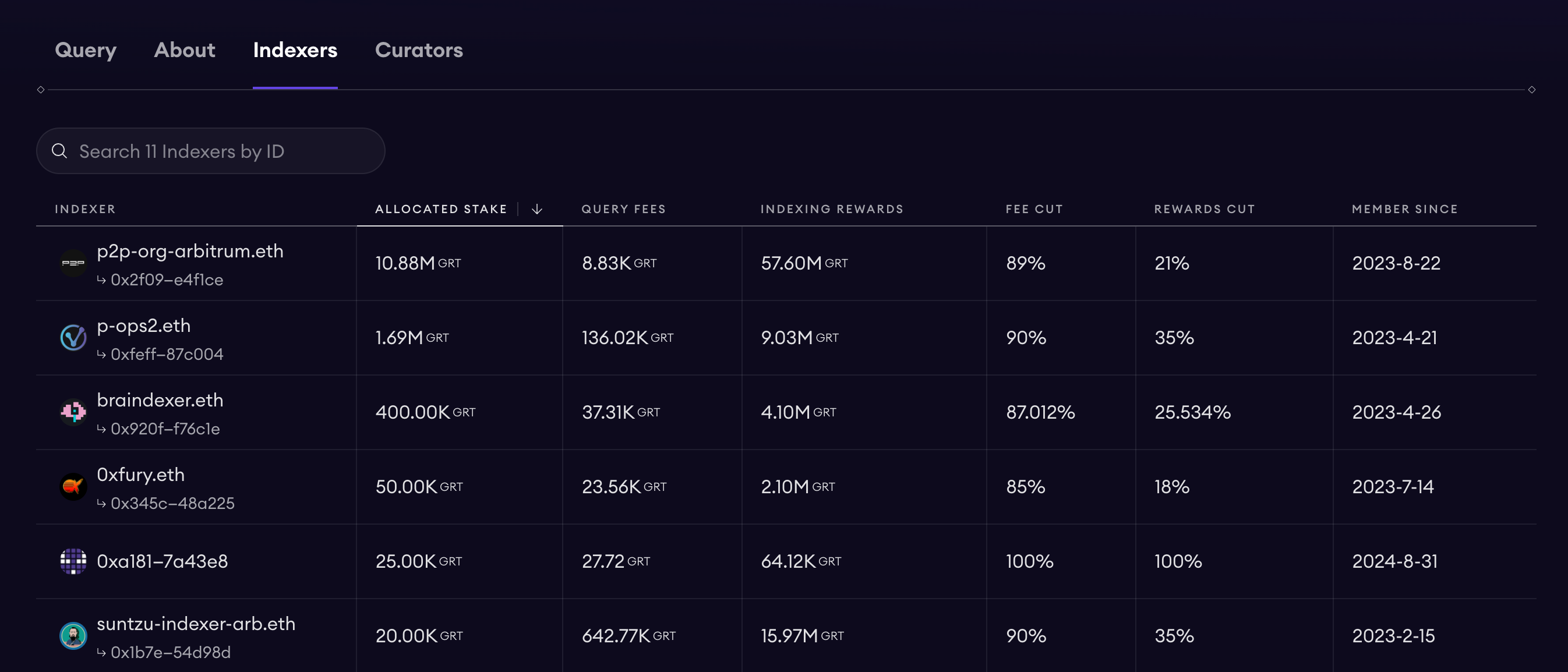
DApp 또는 지갑이 특정 Subgraph에 요청을 보낼 때 지불하는 Query Fee는 자동으로 분할됩니다. 1%는 소각되며, 약 10%는 해당 Subgraph의 큐레이션 풀(Curator / 개발자)로 유입되며, 나머지 약 89%는 지수 보상 메커니즘에 따라 컴퓨팅 리소스를 제공하는 Indexer와 그 Delegator에게 분배됩니다.
-
Indexer는 ≥ 100k GRT를 자체 스테이킹해야 서비스에 참여할 수 있으며, 잘못된 데이터를 반환할 경우 처벌(slash)을 받습니다. Delegator는 GRT를 Indexer에게 위임함으로써 위의 89% 수익의 비례 배당을 받습니다.
-
Curator(일반적으로 개발자)는 자신의 Subgraph의 바운드 곡선에 GRT를 스테이킹하여 Signal을 생성합니다. Signal 수치가 높을수록 Indexer가 리소스를 할당하도록 유도할 수 있습니다. 커뮤니티 경험상 5k~10k GRT를 자체 조달하면 여러 Indexer가 주문을 수락할 수 있다고 권장합니다. 동시에 큐레이터는 10% 로열티도 받을 수 있습니다.
TheGraph의 조회당 과금:
TheGraph 백엔드에서 API KEY를 등록하고, 해당 API KEY를 사용해 TheGraph 내 운영자가 검색한 데이터를 요청하면, 이 요청은 요청 횟수에 따라 과금되며, 개발자는 미리 플랫폼에 일정량의 GRT 토큰을 입금하여 API 요청 비용을 충당해야 합니다.
TheGraph의 Signal 스테이킹 비용:
SubGraph 배포자는 TheGraph 플랫폼 내 운영자가 데이터 검색을 도와줘야 하며, 위에서 언급한 수익 분배 방식에 따라 자신의 쿼리 서비스가 더 좋고 더 많은 수익을 얻을 수 있음을 다른 참가자들에게 알려야 합니다. 이를 위해 GRT를 스테이킹해야 하며, 광고 효과와 수익 보증 역할을 합니다.
테스트 시 개발자는 SubGraph를 TheGraph 플랫폼에 무료로 배포할 수 있으며, 이때 TheGraph 공식이 사용자에게 일부 검색을 도와주고 테스트용 무료 할당량을 제공하지만, 프로덕션 환경에서는 사용할 수 없습니다. 개발자가 SubGraph가 TheGraph 공식 테스트 환경에서 잘 작동한다고 판단하면, 이를 공개 네트워크에 게시하여 다른 운영자의 검색 참여를 기다릴 수 있습니다. 개발자는 특정 운영자에게 직접 비용을 지불하고 검색 보장을 받을 수 없으며, 대신 여러 운영자가 경쟁적으로 서비스를 제공하도록 하여 단일 의존 구조를 피해야 합니다. 이 과정에서 개발자는 자신의 SubGraph에 대해 GRT 토큰을 사용해 큐레이션(Curating) 작업(또는 Signal 작업이라고도 함)을 수행해야 하며, 즉 개발자가 배포한 SubGraph에 일정량의 GRT를 스테이킹해야 합니다. 스테이킹한 GRT 수량이 일정 수준(이전 문의 기준 10,000 GRT)에 도달해야 운영자가 SubGraph의 검색 작업에 참여합니다.
나쁜 요금 체험, 개발자와 전통 회계를 난처하게 만든다
대부분의 프로젝트 개발자에게 TheGraph를 사용하는 것은 다소 번거로운 일입니다. GRT 토큰을 구매하는 것은 Web3 프로젝트 입장에서 비교적 쉬우나, 이미 배포된 SubGraph에 대해 큐레이션(Curating) 작업을 수행하고 운영자의 참여를 기다리는 과정은 매우 비효율적입니다. 이 과정에는 적어도 다음 두 가지 문제가 있습니다:
-
스테이킹한 GRT 수량과 운영자 유치에 필요한 시간의 불확실성 문제.笔者过去在部署SubGraph时曾直接咨询TheGraph社区大使以确定质押GRT的数量,但对于大部分开发者而言,这一数据并不容易获得。此外,在质押足够的GRT后,运营方介入检索也需要一段时间。
-
비용 산정 및 회계의 복잡성 문제. TheGraph는 토큰 이코노미 메커니즘을 기반으로 요금을 설계하여 대부분의 개발자에게 비용 계산을 복잡하게 만듭니다. 더욱 실제적인 문제는 기업이 이 비용을 회계 처리할 때 회계 담당자가 이러한 비용 구조를 이해하기 어려울 수 있다는 점입니다.
"좋아, 그래도 중앙화가 낫네?"
분명히 대부분의 개발자에게 Goldsky를 직접 선택하는 것이 훨씬 더 간단합니다. 누구나 이해할 수 있는 요금제와 거의 즉시 사용 가능한 서비스는 불확실성을 크게 줄여주며, 이로 인해 블록체인 데이터 인덱싱 및 검색 서비스에서 단일 제품에 대한 의존성이 생깁니다.
분명히 TheGraph의 복잡한 GRT 토큰 이코노미는 TheGraph의 광범위한 적용을 저해했습니다. 토큰 이코노미는 복잡할 수 있지만, 이러한 복잡성은 사용자에게 노출되어서는 안 됩니다. 예를 들어 GRT의 큐레이션 스테이킹 메커니즘은 사용자에게 노출되지 말아야 하며, TheGraph는 사용자에게 간소화된 결제 페이지를 제공하는 것이 더 낫습니다.
위의 TheGraph에 대한 평가는 개인적인 의견이 아닙니다. 유명한 스마트 계약 엔지니어이자 Sablier 프로젝트 창립자인 Paul Razvan Berg도 트윗 에서 이 견해를 표현한 바 있습니다. 그는 SubGraph 배포와 GRT 과금의 사용자 경험(UX)이 극도로 나쁘다고 언급했습니다.
3. 기존의 일부 해결책
데이터 검색의 단일 장애 지점 문제 해결법에 대해 위에서 이미 일부 언급했습니다. 즉 개발자는 TheGraph 서비스를 사용할 수 있으나, 절차가 다소 복잡하며 GRT 토큰을 구입해 스테이킹 및 API 비용을 지불해야 합니다.
현재 EVM 생태계에는 다양한 데이터 검색 소프트웨어가 존재하며, 구체적으로는 Dune가 작성한 The State of EVM Indexing 또는 rindexer가 작성한 EVM 데이터 검색 소프트웨어 요약을 참고할 수 있습니다. 또 다른 최근 논의는 이 트윗을 참고하세요.
이 글은 Glodsky의 고장 원인을 논의하지 않을 것입니다. 현재 Glodsky 보고서 에 따르면, Glodsky는 구체적인 원인을 알고 있지만 기업 고객에게만 공개할 예정이기 때문입니다. 이는 어떠한 제3자도 현재 Glodsky가 어떤 고장을 겪었는지를 알 수 없다는 의미입니다. 보고서 내용을 바탕으로 추측하면, 검색 후 데이터를 데이터베이스에 기록하는 과정에서 문제가 발생했을 가능성이 있습니다. 이 간략 보고서에서 Glodsky는 데이터베이스에 정상적으로 접근할 수 없었다고 언급하며 AWS와 협력한 후에야 데이터베이스 접근 권한을 얻었다고 밝혔습니다.
본 절에서는 주로 다른 해결 방법을 소개합니다:
-
ponder는 간단하고 개발 경험도 우수하며 배포가 용이한 데이터 검색 서비스 소프트웨어로, 개발자가 직접 서버를 임대해 배포할 수 있습니다.
-
local-first는 흥미로운 개발 철학으로, 네트워크가 없는 상황에서도 사용자에게 좋은 경험을 제공해야 한다고 주장합니다. 블록체인이 존재하는 상황에서는 local-first의 제약을 다소 완화할 수 있으며, 블록체인에 연결할 수 있는 상황에서 좋은 경험을 제공할 수 있도록 보장할 수 있습니다.
ponder
왜 저는 다른 소프트웨어가 아닌 ponder 사용을 추천할까요? 구체적인 이유는 다음과 같습니다:
-
ponder는 공급업체 의존성이 없습니다. 처음에 ponder는 개인 개발자가 만든 프로젝트이므로, 다른 기업이 제공하는 데이터 검색 소프트웨어에 비해 사용자가 이더리움 RPC URL과 postgres 데이터베이스 연결 정보만 입력하면 됩니다.
-
ponder는 우수한 개발 경험을 제공합니다. 저는 과거 여러 차례 ponder를 사용해 개발했으며, ponder가 typescript로 작성되었고 핵심 라이브러리가 viem에 의존하기 때문에 개발 경험이 매우 탁월합니다.
-
ponder는 더 높은 성능을 제공합니다.
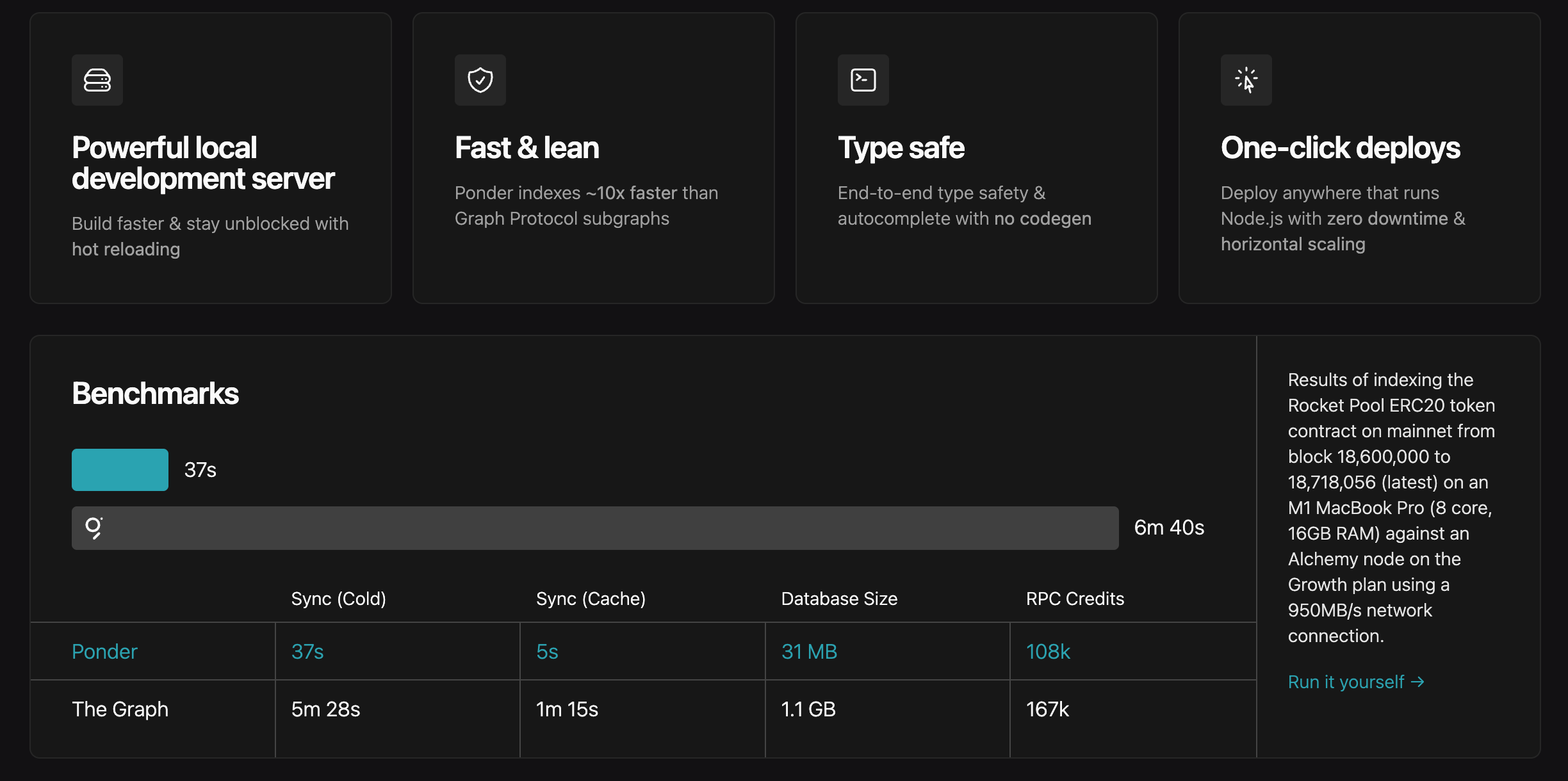
물론 일부 문제도 존재합니다. ponder는 현재 여전히 빠르게 개발 중이며, 개발자는 파괴적인 버전 업데이트로 인해 이전 프로젝트가 실행되지 않는 상황을 겪을 수 있습니다. 본문은 기술 입문서가 아니므로 ponder의 개발 세부 사항을 더 이상 다루지 않겠습니다. 기술 배경을 가진 독자는 문서를 직접 참고하시기 바랍니다.
ponder의 더 흥미로운 점은 현재 ponder도 부분적으로 상용화를 시작했다는 점이며, ponder의 상용화 경로는 이전 글에서 논의한 '격리 이론'과 매우 잘 맞습니다.
여기서 간단히 '격리 이론'을 소개하겠습니다. 우리는 공공재의 공공성 때문에 무제한의 사용자가 이용할 수 있다고 생각하며, 공공재에 요금을 부과하면 일부 사용자가 이용을 중단하게 되어 사회적 이익이 극대화되지 않는다고 봅니다(경제학 용어로 '파레토 최적'이 아님). 이론적으로 공공재는 각 개인에게 차등 요금을 부과할 수 있지만, 차등 요금 책정에 드는 비용이 그로 인한 잉여보다 클 가능성이 큽니다. 따라서 공공재가 무료로 공개되는 이유는 공공재가 본질적으로 무료여야 하기 때문이 아니라, 고정 요금을 부과하는 행위가 모두 사회적 이익에 해롭고, 현재까지 각 개인에게 차등 요금을 부과할 수 있는 저렴한 방법이 없기 때문입니다. 격리 이론은 공공재 내에서 가격을 책정할 수 있는 방법을 제안하는데, 특정 방법으로 동질 집단의 일부를 격리시키고, 이 집단에 요금을 부과하는 것입니다. 먼저, 격리 이론은 누구도 공공재를 무료로 이용하는 것을 막지 않습니다. 그러나 일부 집단에 요금을 부과할 수 있는 방법을 제안합니다.
ponder는 비슷한 격리 이론의 방법을 사용합니다:
-
먼저, ponder의 배포는 일정한 지식을 필요로 하며, 개발자는 배포 과정에서 RPC, 데이터베이스 등의 외부 의존성을 제공해야 합니다.
-
또한 배포 완료 후 개발자는 ponder 애플리케이션을 지속적으로 운영해야 합니다. 예를 들어 proxy 시스템을 사용해 부하 분산을 하여 데이터 요청이 ponder의 백그라운드 스레드에서 체인 데이터를 검색하는 작업에 영향을 주지 않도록 해야 합니다. 일반 개발자에게는 다소 복잡할 수 있습니다.
-
현재 ponder는 전자동 배포 서비스 marble를 내부 테스트 중이며, 사용자는 코드만 해당 플랫폼에 제출하면 자동 배포가 가능합니다.
분명히 이것은 '격리 이론'의 적용입니다. 자기 스스로 ponder 서비스를 운영하기를 원하지 않는 개발자들이 격리되었으며, 이 개발자들은 요금을 지불함으로써 ponder 서비스의 간소화된 배포를 얻을 수 있습니다. 물론 marble 플랫폼의 등장은 다른 개발자가 ponder 프레임워크를 무료로 사용하고 자체 호스팅 배포하는 것을 방해하지 않습니다.
ponder와 Goldsky의 대상 사용자는 누구일까요?
-
공급업체 의존성이 전혀 없는 ponder와 같은 공공재는 다른 공급업체에 의존하는 데이터 검색 서비스보다 소규모 프로젝트 개발 시 더 인기가 많습니다.
-
일부 대규모 프로젝트를 운영하는 개발자는 반드시 ponder 프레임워크를 선택하지 않을 수도 있습니다. 대규모 프로젝트는 종종 검색 서비스의 성능이 충분해야 하며, Goldsky 등의 서비스 제공업체는 종종 충분한 가용성 보장을 제공하기 때문입니다.
양쪽 모두 일부 위험 요소가 있습니다. 최근 Goldsky 사태를 보면, 개발자는 제3자 서비스 다운타임에 대비해 항상 자체 ponder 서비스를 유지하는 것이 가장 좋습니다. 또한 ponder 사용 시 RPC가 반환하는 데이터의 유효성 문제도 고려해야 합니다. 얼마 전 safe는 RPC가 잘못된 데이터를 반환하여 검색기가 충돌한 사례를 보고했습니다. Goldsky 사태가 RPC의 무효 이벤트와 관련이 있다는 직접적인 증거는 없지만, 저는 Goldsky도 비슷한 상황을 겪었을 가능성이 있다고 의심합니다.

local-first 개발 철학
Local-first는 지난 몇 년간 계속 논의되어온 주제입니다. 간단히 말해, Local-first는 소프트웨어가 다음 기능을 가져야 한다고 요구합니다:
-
오프라인 작업
-
다중 클라이언트 협업
현재 대부분의 local-first 관련 기술 논의는 CRDT(Conflict-free Replicated Data Type) 기술을 다룹니다.所谓 CRDT는 충돌이 없는 데이터 형식으로, 사용자가 다중 단말에서 작업할 때 자동으로 충돌을 병합하여 데이터 무결성을 유지할 수 있게 합니다. 간단히 말해 CRDT는 간단한 합의 프로토콜을 갖춘 데이터 타입으로, 분산 환경에서 데이터의 무결성과 일관성을 보장할 수 있습니다.
그러나 블록체인 개발에서는 위의 Local-first 소프트웨어 요구사항을 완화할 수 있습니다. 프로젝트 개발자가 제공하는 백엔드 인덱스 데이터가 없을 때에도 사용자가 프론트엔드에서 최소한의 사용 가능성을 유지할 수 있기를 요구하는 정도입니다. 또한 local-first의 다중 클라이언트 협업 요구는 사실상 블록체인에 의해 이미 해결되었습니다.
DApp 상황에서 local-first 철학은 다음과 같이 실현할 수 있습니다:
-
핵심 데이터 캐싱: 프론트엔드는 잔액, 포지션 정보 등 사용자의 중요한 데이터를 캐싱해야 하며, 인덱스 서비스가 불가능하더라도 사용자는 마지막으로 알려진 상태를 볼 수 있어야 합니다.
-
기능 강등 설계: 백엔드 인덱스 서비스가 불가능할 때 DApp은 기본 기능을 제공할 수 있습니다. 예를 들어 데이터 검색 서비스가 불가능할 때 일부 데이터는 직접 RPC를 이용해 체인 상의 데이터를 읽어오는 것으로 대체할 수 있어 사용자가 기존 데이터의 최신 상태를 확인할 수 있도록 보장할 수 있습니다.
이러한 local-first DApp 설계 철학은 애플리케이션의 탄력을 크게 향상시켜 데이터 검색 서비스가 다운된 후 애플리케이션이 사용 불가능한 상황을 피할 수 있습니다. 사용 편의성을 고려하지 않을 경우, 최고의 local-first 애플리케이션은 사용자가 로컬에서 노드를 실행하고 trueblocks 와 같은 도구를 사용해 로컬에서 데이터를 검색하도록 요구하는 것입니다. 탈중앙화 검색 또는 로컬 검색에 대한 일부 논의는 트윗 Literally no one cares about decentralized frontends and indexers을 참고하세요.
4. 맺음말
Goldsky의 6시간 다운타임 사태는 생태계에 경종을 울렸습니다. 블록체인 자체는 탈중앙화 및 단일 장애 지점 저항 특성을 가지고 있지만, 그 위에 구축된 애플리케이션 생태계는 여전히 중앙화된 인프라 서비스에 높은 의존성을 가지고 있습니다. 이러한 의존성은 전체 생태계에 시스템적 위험을 초래합니다.
본문은 오래 전부터 명성이 자자한 탈중앙 검색 서비스 TheGraph가 왜 오늘날 널리 사용되지 않고 있는지를 간략히 소개하며, 특히 GRT 토큰 이코노미가 가져온 일부 복잡성에 대해 논의했습니다. 마지막으로 더 견고한 데이터 검색 인프라를 구축하는 방법에 대해 논의하며, 필자는 개발자들이 비상 대응 옵션으로 ponder의 자체 호스팅 데이터 검색 개발 프레임워크를 사용할 것을 권장하며, ponder의 우수한 상용화 경로도 소개합니다. 마지막으로 local-first 개발 철학을 논의하며, 데이터 검색 서비스 없이도 사용 가능한 애플리케이션을 구축할 것을 개발자들에게 권고합니다.
현재 많은 Web3 개발자들이 인식 하고 있듯이 데이터 검색 서비스의 단일 장애 지점 문제는 이미 명확합니다. GCC는 더 많은 개발자가 이 인프라에 관심을 갖고, 탈중앙화된 데이터 검색 서비스를 구축하거나, 데이터 검색 서비스 없이도 DApp 프론트엔드가 작동할 수 있도록 하는 프레임워크를 설계해볼 것을 희망합니다.
TechFlow 공식 커뮤니티에 오신 것을 환영합니다
Telegram 구독 그룹:https://t.me/TechFlowDaily
트위터 공식 계정:https://x.com/TechFlowPost
트위터 영어 계정:https://x.com/BlockFlow_News














