

에이전트를 깊이 있게 논해보자. 그것은 '동료'인가, 아니면 '도구'인가? 창업 기회와 그 본질적인 가치는 도대체 무엇인가?
정리: Moonshot
출처: GeekPark
2025년은 에이전트(Agent)가 가속 페달을 밟은 해였다.
초반 DeepSeek가 불러일으킨 탄성에서 시작해 GPT-4o와 Claude 3.5의 연이은 등장까지, 대규모 모델(Large Model)의 경계는 수차례 재정의되었다. 그러나 AI 산업 체인의 신경을 긴장하게 한 것은 모델 성능의 반복적 개선이 아니라, 바로 에이전트의 등장이었다.
Manus, Devin 등의 제품들이 폭발적인 인기를 끌며 하나의 공감대를 다시금 확인시켜 주고 있다. 즉 대규모 모델은 더 이상 단순한 도구가 아니라 스스로 작업을 스케줄링할 수 있는 지능형 실체가 되어야 한다는 것이다.
결과적으로 에이전트는 대규모 모델에 이어 전 세계 기술계에서 가장 빠르게 합의된 두 번째 트렌드가 되었다.
거대 기업들의 전략 재편부터 스타트업 시장의 빠른 추격까지, 에이전트는 다음 세대를 위한 베팅 방향으로 부상하고 있다. 하지만 소비자용(C단말) 제품들이 쏟아져 나오고 개발자들이 열광하는 와중에도 실제로 사용자 가치 사이클을 완성한 사례는 극소수에 그치며, 점점 더 많은 제품들이 '오래된 수요에 새로운 기술을 덧씌우는' 불안감 속에 갇히고 있다.
열기(熱浪)가 가라앉으며 시장도 차츰 냉정을 되찾고 있다. 과연 에이전트란 범식별적 재구성(范式重构)인가, 아니면 또 한 번의 포장술에 불과한가?所谓「범용」과 「특화」의 분기점은 진정한 지속 가능한 시장 공간을 만들어 낼 수 있을까? 그리고所谓「새로운 입구」라는 것이 과연 상호작용 방식의 진화인지, 혹은 구세계의 투영에 불과한 것인지?
이러한 의문들을 더 깊이 파고들다 보면, 에이전트의 진정한 장벽은 모델 능력에 있지 않고, 오히려 그것이 살아 움직이는 데 필요한 하부 인프라에 있다는 사실을 알 수 있다. 제어 가능한 실행 환경, 메모리 시스템, 컨텍스트 인지, 도구 호출 등 각각의 기초 모듈이 누락될 때마다, 에이전트는 데모 단계를 넘어 실용화되는 데 있어 가장 큰 저항을 맞닥뜨린다.
이러한 하부 엔지니어링 문제들은 에이전트가 '유행 장난감'에서 '생산성 도구'로 나아가는 데 있어 가장 큰 장애물이며, 동시에 현재 가장 명확하고 최고의 가치를 지닌 스타트업 블루오션(blue ocean)이기도 하다.
공급이 넘쳐나고 수요가 불분명한 이 시기에 우리는 이번 대담을 통해 점점 더 절박해지는 질문 하나에 답하고자 한다. 바로 에이전트의 진짜 문제와 진짜 기회가 어디에 숨어 있는가 하는 것이다.
본 심층 대담에서는 일선에서 활동 중인 쉬샹테크(XiXiang Tech) 창립자 리광밀(Li Guangmi)과 쉬샹테크 AI Research Lead 종개기(Zhong Kaiqi)를 초청한다. 두 현업자는 제품 형태, 기술 경로, 비즈니스 모델, 사용자 경험, Infra 구축 등 다양한 관점에서 현재 에이전트의 진짜 문제와 기회를 분석해 줄 것이다.
그들의 사고를 따라가 보며, 거대 플레이어들이 포진한 경기장 속에서 스타트업이 진짜 기회를 어디서 찾을 수 있는지, 어떻게 '코파일럿(Copilot)'에서 '에이전트'로의 현실적인 성장 경로를 검증해 나갈 수 있는지, 그리고 왜 코딩(Coding)이라는 겉보기에 특화된 영역이 AGI로 향하는 '가치 고지'이자 '핵심 지표'로 여겨지는지 살펴볼 것이다.
마지막으로 이 대화는 더 먼 미래를 조망하며 인간과 에이전트 간의 새로운 협업 관계와 차세대 지능형 인프라 구축의 핵심 도전과 무한한 기회를 조망할 것이다.
주요 요점 정리
-
범용 에이전트 분야에서 가장 우수한 접근법은 바로 "모델 자체가 에이전트"(Model as Agent)이다.
-
에이전트를 개발하는 데 있어서 꼭 '최종 목표를 먼저 정해두고' 완전 자동화된 에이전트를 처음부터 만들 필요는 없다. 코파일럿에서 시작해 사용자 데이터를 수집하고, UX를 개선하며 사용자 인식을 선점한 후 점진적으로 전환하는 것도 가능하다.
-
AGI는 코딩 환경에서 가장 먼저 실현될 가능성이 크다. 이 환경이 가장 단순하며 AI의 핵심 역량을 단련시킬 수 있기 때문이다. 코딩은 말하자면 '만능 기계'이며, 이를 통해 AI는 구축하고 창조할 수 있게 된다. 코딩은 단계적으로 대규모 모델 산업 전체 가치의 90%를 차지할 수도 있다.
-
AI 네이티브(AI Native) 제품은 인간만을 위한 것이 아니다. 반드시 AI에게도 서비스해야 한다. 진정한 AI 네이티브 제품은 인간과 AI 양쪽 모두를 위한 양방향 메커니즘을 내장해야 한다.
-
현재의 AI 제품은 '도구'에서 '관계'로 나아가고 있다. 사람은 도구와 관계를 맺지 않지만, 기억이 있고, 자신을 이해하며, '마음이 통하는' AI와는 관계를 맺는다.
다음은 당일 오늘밤 테크토크(Tech Talk) 생방송 내용을 정리한 글로, GeekPark에서 편집했다.
01 열풍 속에서 어떤 에이전트 제품이 두각을 나타내고 있나?
장펑: 지난一段时间 동안 모두가 에이전트에 대해 논의하며, 이것이 현재 중요한 이슈이자 스타트업에게 드물게 주어진 발전 기회라고 생각하고 있습니다.
쉬샹테크는 에이전트 체계에 대해 비교적 심도 깊은 연구를 수행했으며 관련 제품들을 체험하고 분석한 것으로 알고 있습니다. 우선 최근 어떤 에이전트 관련 제품이 두 분에게 강한 인상을 남겼는지, 그리고 이유는 무엇인지 듣고 싶습니다.
리광밀: 개인적으로 가장 인상 깊었던 것은 두 가지입니다. 하나는 Anthropic의 Claude가 보여준 프로그래밍 능력이고, 다른 하나는 OpenAI ChatGPT의 Deep Research 기능입니다.
Claude에 대해서는 주로 그들의 코딩 능력을 언급하고 싶습니다. 제가 한 가지 견해를 말씀드리자면, 코딩(Coding)은 AGI를 측정하는 가장 핵심적인 선행 지표입니다. AI가 규모화되고 엔드 투 엔드(end-to-end) 방식으로 소프트웨어 애플리케이션을 개발할 수 없다면, 다른 분야에서도 진전이 더딜 것입니다. 우선 코딩 환경에서 강력한 ASI(Artificial Superintelligence, 인공 초지능)를 실현해야 다른 분야도 가속화될 수 있습니다. 즉 디지털 환경에서 먼저 AGI를 달성한 후 확장하는 것이죠.

세계 최초의 AI 프로그래머 Devin|사진 출처: Cognition Labs
Deep Research는 제 개인적으로 매우 큰 도움이 됩니다. 거의 매일 사용하고 있는데, 본질적으로 정보 검색 에이전트로서 다양한 웹페이지와 자료를 검색해 주며, 체험이 좋고 제 연구 범위를 크게 확장시켜 줍니다.
장펑: 케이치, 당신의 관점에서 어떤 제품이 인상 깊었습니까?
종개기 (Cage): 제가 평소 에이전트를 관찰하고 사용하는 사고 모델을 소개한 후, 각 범주별로 대표적인 제품 몇 가지를 설명하겠습니다.
먼저 사람들이 자주 묻는 질문인데, 바로 '범용 에이전트 vs 특화 에이전트'입니다. 저희는 범용 에이전트 분야에서 가장 잘하고 있는 것이 '모델 자체가 에이전트'(Model as Agent)라고 생각합니다. 아까 광밀이 언급한 OpenAI의 Deep Research와 새롭게 발표된 o3 모델이 바로 표준적인 '모델 자체가 에이전트'의 예입니다. 여기서 에이전트의 모든 구성 요소—대규모 언어 모델(LLM), 컨텍스트(Context), 도구 사용(Tool Use), 환경(Environment)—가 통합되어 있으며, 엔드 투 엔드 강화 학습(Reinforcement Learning)을 통해 훈련됩니다. 그 결과 각종 정보 검색 작업을 원활히 수행할 수 있습니다.
제가 좀 논쟁적인 주장을 하자면, 범용 에이전트의 수요는 기본적으로 정보 검색과 경량 코딩 정도로 좁혀지며, 이미 GPT-4o가 이를 매우 잘 수행하고 있습니다. 따라서 범용 에이전트 시장은 기본적으로 대규모 모델 회사들의 전장이며, 스타트업이 범용 수요만으로 성장하기는 어렵습니다.
제가 인상 깊게 본 스타트업들은 대부분 특화(Vetical) 분야에 집중하고 있습니다.
ToB 특화 분야를 먼저 살펴보면, 사람의 업무를 프론트 오피스(Front Office)와 백 오피스(Back Office)로 나눌 수 있습니다.
백 오피스 업무는 반복성이 강하고 고도의 동시 처리(high concurrency)를 요구하며, 일반적으로 긴 SOP(Standard Operating Procedure)를 따릅니다. 여기에는 AI 에이전트가 일대일로 수행하기 적합한 많은 작업들이 포함되어 있으며, 비교적 넓은 탐색 공간에서 강화 학습을 수행하기에도 적합합니다. 이 분야의 대표적인 예로는 '과학을 위한 AI(AI for Science)'를 지향하는 스타트업들이 있는데, Multi-agent system(다중 에이전트 시스템)을 운영하고 있습니다.
이 시스템 안에는 문헌 검색, 실험 계획, 앞선 진전 예측, 데이터 분석 등 다양한 연구 과제들이 포함되어 있습니다. 특징은 Deep Research처럼 단일 에이전트가 아니라, 과학 시스템에 대해 더 높은 해상도를 제공하는 복잡한 시스템이라는 점입니다. 흥미로운 기능 중 하나는 '모순 발견(Contradiction Finding)'인데, 대립적인 작업을 처리할 수 있습니다. 예를 들어 두 편의 최고 권위 학술지 논문 사이의 모순점을 찾아낼 수 있습니다. 이는 연구 중심 에이전트의 매우 흥미로운 패러다임을 보여줍니다.
프론트 오피스 업무는 주로 사람과의 교류를 필요로 하며 외부 연결을 해야 합니다. 현재 가장 적합한 분야는 음성 에이전트로, 의료 분야의 간호사 전화 상담, 채용, 물류 커뮤니케이션 등이 있습니다.
여기서 제가 소개하고 싶은 회사는 HappyRobot입니다. 아주 작아 보이는 시나리오를 선택했는데, 물류 및 공급망 분야에서 전화 커뮤니케이션을 전담하고 있습니다. 예를 들어 트럭 운전사가 문제를 겪거나 화물이 도착하면, 에이전트가 즉시 전화를 걸 수 있습니다. 이 경우 AI 에이전트의 특별한 능력 하나가 발휘됩니다. 바로 7일 24시간 끊김 없는 응답과 신속한 반응입니다. 이는 대부분의 물류 수요를 충족시키기에 충분합니다.
위 두 가지 외에도 Coding Agent 같은 독특한 사례들이 있습니다.
02 코파일럿에서 에이전트로, 더 현실적인 성장 경로는 존재할까?
종개기: 코딩 개발 분야는 최근 스타트업 열기가 매우 뜨겁습니다. 좋은 예로 Cursor가 있습니다. Cursor 1.0의 출시는 원래 코파일럿(조수 운전)처럼 보였던 제품을 완전한 에이전트 제품으로 바꾸어 놓았습니다. 백그라운드에서 비동기적으로 작동하며 메모리 기능을 갖추고 있는데, 이는 우리가 에이전트에 대해 갖고 있던 상상 그 자체입니다.
Devin과의 비교도 흥미롭고, 중요한 교훈을 줍니다. 즉 에이전트를 만든다는 것은 꼭 '목표를 먼저 정하고' 완전 자동화된 에이전트를 처음부터 만들어야 하는 것은 아니며, 코파일럿 형태에서부터 시작할 수 있다는 것입니다. 이 과정에서 사용자 데이터를 수집하고, 사용자 경험을 개선하며, 사용자 인식을 선점한 후 점진적으로 전환할 수 있습니다. 국내에서도 Minus AI가 좋은 사례인데, 초기 제품 역시 코파일럿 형태에서 시작했습니다.
또한 저는 '환경(Environment)'이라는 사고 모델을 통해 다양한 에이전트를 구분합니다. Manus의 환경은 가상 머신(Virtual Machine)이고, Devin은 브라우저, flowith는 노트북, SheetZero는 스프레드시트, Lovart는 캔버스 등을 환경으로 삼고 있습니다. 이 '환경'은 강화 학습에서 말하는 환경 정의에 해당하며, 참고할 만한 분류 방식입니다.

국내 스타트업 팀이 개발한 flowith|사진 출처: flowith
장펑: Cursor 사례를 좀 더 깊이 다뤄보겠습니다. 그 뒷받침하는 기술 스택과 성장 경로는 어떤가요?
종개기 (Cage): 자율주행의 예가 매우 흥미롭습니다. 지금까지도 테슬라조차 정말로 핸들과 브레이크, 액셀을 없애지는 못했습니다. 이는 많은 핵심 결정에서 아직 AI가 인간을 완전히 능가하지 못한다는 것을 의미합니다. AI의 능력이 인간과 비슷할 때까지만 해도 일부 핵심 결정은 반드시 인간이 개입해야 합니다. 이것이 바로 Cursor가 초기에 명확히 인지했던 부분입니다.
그래서 그들이 처음 집중한 기능은 인간이 가장 필요로 하는 '자동 완성(Autocompletion)'이었습니다. 이 기능을 Tab 키로 실행되도록 만들어, Claude 3.5와 같은 모델이 등장하면서 Cursor는 Tab 키의 정확도를 90% 이상으로 끌어올렸습니다. 이 수준의 정확도라면 한 작업 흐름에서 연속 5~10번 사용할 수 있어 '몰입 상태(flow)'가 형성됩니다. 이것이 Cursor의 코파일럿 1단계였습니다.
두 번째 단계는 코드 리팩토링(Code Refactoring) 기능입니다. Devin과 Cursor 모두 이 수요를 해결하고자 했지만, Cursor는 더 교묘한 방법을 선택했습니다. 사용자가 요구를 입력하면, 파일 외부에서 병렬 수정 모드를 열어 코드를 리팩토링하는 대화창을 띄웁니다.
이 기능이 처음 나왔을 때는 정확도가 그리 높지 않았지만, 사용자의 기대가 코파일럿 수준이었기 때문에 받아들여졌습니다. 또한 그들은 모델의 코딩 능력이 빠르게 향상될 것임을 정확히 예측했습니다. 그래서 제품 기능을 다듬으면서 동시에 모델 능력 향상을 기다렸고, 자연스럽게 에이전트로서의 능력이 드러났습니다.
세 번째 단계가 바로 오늘날의 Cursor 상태입니다. 상대적으로 엔드 투 엔드 방식으로 백그라운드에서 작동하는 에이전트입니다. 뒤에는 샌드박스와 같은 환경이 있으며, 제가 하고 싶지 않은 작업을 출근할 때 맡기면, 내 컴퓨팅 자원을 이용해 백그라운드에서 완료합니다. 그 사이 저는 가장 집중하고 싶은 핵심 작업에 몰입할 수 있습니다.
마지막으로 이메일이나 Feishu 메시지를 보내듯 비동기 방식으로 결과를 알려줍니다. 이렇게 코파일럿에서 오토파일럿(또는 에이전트)으로의 전환이 순조롭게 이루어진 것입니다.
핵심은 인간의 상호작용 인식을 잡는 것입니다. 처음에는 사용자가 동기식 상호작용을 더 선호하도록 유도함으로써 대량의 사용자 데이터와 피드백을 수집할 수 있습니다.
03 왜 코딩이 AGI로 가는 '핵심 시험장'인가?
장펑: 아까 광밀님이 "코딩은 AGI로 가는 핵심이며, 이 분야에서 ASI(초지능)를 실현하지 못하면 다른 분야도 어렵다"고 하셨는데, 그 이유는 무엇인가요?
리광밀: 몇 가지 논리를 들 수 있습니다. 첫째, 코드 데이터는 가장 깨끗하고 사이클을 쉽게 완성할 수 있으며 결과를 검증할 수 있습니다. 저의 추측으로는 챗봇은 데이터 플라이휠(피드백 루프 메커니즘으로 상호작용 또는 프로세스에서 데이터를 수집해 지속적으로 AI 모델을 최적화하고 더 나은 결과와 가치 있는 데이터를 생성하는 것)을 형성하지 못할지도 모릅니다. 그러나 코딩 분야는 데이터 플라이휠을 돌릴 수 있는 가능성이 있습니다. 왜냐하면 여러 차례의 강화 학습이 가능하며, 코드는 다중 라운드 강화 학습의 핵심 환경이기 때문입니다.
저는 코드를 프로그래밍 도구로 이해하기도 하지만, 더 중요하게는 AGI를 실현하는 환경으로 이해하고 싶습니다. AGI는 이 환경에서 가장 먼저 실현될 가능성이 큽니다. 이 환경이 가장 단순하며 AI의 핵심 역량을 단련시킬 수 있기 때문입니다. 만약 AI가 엔드 투 엔드 방식의 애플리케이션 개발을 할 수 없다면 다른 분야에서는 더욱 어려울 것입니다. 만약 향후 어느 정도 기간 동안 기초 소프트웨어 개발을 대규모로 대체하지 못한다면, 다른 분야에서도 어려울 것입니다.
또한 코딩 능력이 향상되면 모델의 지시사항 준수 능력도 함께 향상됩니다. 예를 들어 긴 프롬프트 처리의 경우 Claude가 명백히 우수한데, 이는 코딩 능력과 논리적 관계가 있다고 추측됩니다.
또 다른 점은, 미래의 AGI는 먼저 디지털 세계에서 실현될 것이라고 생각합니다. 향후 2년 이내에 에이전트는 사람이 스마트폰과 컴퓨터에서 수행하는 거의 모든 작업을 할 수 있게 될 것입니다. 간단한 코딩으로 해결하거나, 그렇지 않으면 다른 가상 도구를 호출할 수 있습니다. 따라서 먼저 디지털 세계에서 AGI를 실현하여 빠르게 달리게 하는 것이 큰 논리입니다.
04 좋은 에이전트를 판단하는 기준은 무엇인가?
장펑: 코딩은 말하자면 '만능 기계'이며, 이를 통해 AI는 구축하고 창조할 수 있습니다. 게다가 코딩 분야는 상대적으로 구조화되어 있어 AI가 능력을 발휘하기에 적합합니다. 에이전트의 우열을 평가할 때 사용자 경험 외에 어떤 관점에서 에이전트의 잠재력을 평가하십니까?
종개기 (Cage): 좋은 에이전트는 먼저 데이터 플라이휠을 구축할 수 있는 환경을 가져야 하며, 이 데이터 자체가 검증 가능해야 합니다.
최근 Anthropic의 연구원들이 자주 언급하는 용어가 RLVR(검증 가능한 보상으로부터의 강화 학습, Reinforcement Learning from Verifiable Reward)인데, 여기서 'V'는 검증 가능한 보상을 의미합니다. 코드와 수학은 매우 표준적인 검증 가능한 분야이며, 작업 완료 후 즉시 정답 여부를 검증할 수 있으므로 데이터 플라이휠이 자연스럽게 형성됩니다.
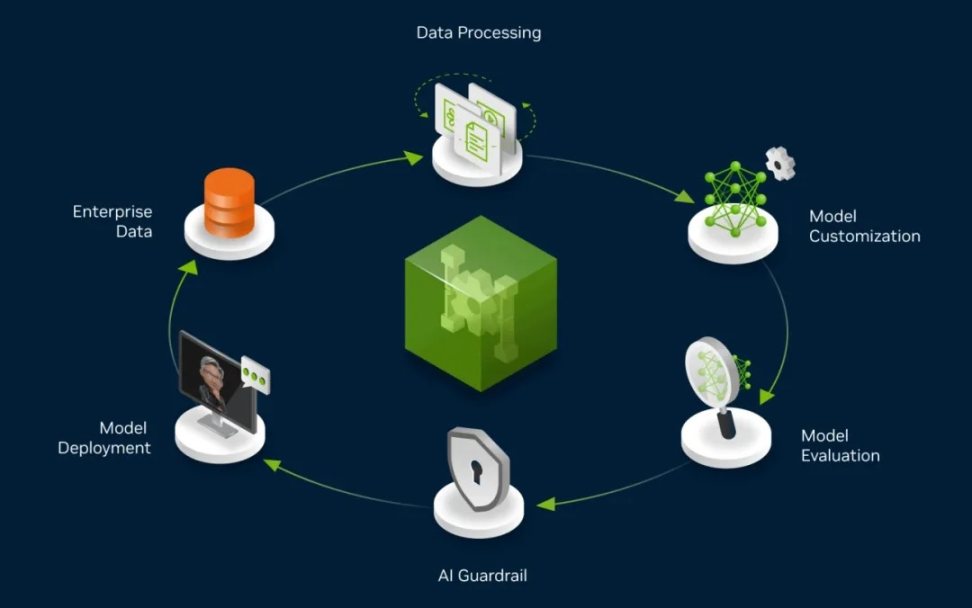
데이터 플라이휠의 작동 메커니즘|사진 출처: NVIDIA
따라서 에이전트 제품을 설계한다는 것은 바로 그러한 환경을 구축하는 것입니다. 이 환경 안에서 사용자가 작업을 성공하거나 실패하는 것은 중요하지 않습니다. 왜냐하면 현재의 에이전트는 반드시 실패하기 때문입니다. 중요한 것은 실패할 때 잡음을 아닌 신호를 담은 데이터를 수집해 제품 자체의 최적화를 이끌어낼 수 있어야 한다는 점입니다. 이러한 데이터는 강화 학습 환경의 콜드 스타트(cold start) 데이터로 활용될 수도 있습니다.
둘째, 제품이 얼마나 '에이전트 네이티브(Agent Native)'인지 여부입니다. 즉 제품 설계 시 인간과 에이전트의 수요를 동시에 고려해야 한다는 것입니다. 대표적인 예로 The Browser Company가 있습니다. 왜 새로운 브라우저를 만들까요? 기존의 Arc 브라우저는 오직 인간 사용자의 효율 향상을 위해 설계되었기 때문입니다. 그러나 그들의 새로운 브라우저는 설계 단계에서 많은 신기능을 AI 에이전트가 스스로 사용할 수 있도록 고려했습니다. 제품의 근본 설계 로직이 변화하는 순간, 이것이 매우 중요해집니다.
결과적으로 객관적 평가도 중요합니다.
1. 작업 완료율 + 성공률: 우선 작업이 끝까지 수행되어야 하며, 그래야 사용자가 최소한 피드백을 받을 수 있습니다. 다음은 성공률입니다. 10단계의 작업에서 각 단계의 정확도가 90%라면 최종 성공률은 35%에 불과합니다. 따라서 각 단계 사이의 연결을 최적화해야 합니다. 현재 업계의 기준선은 50% 이상의 성공률일 수 있습니다.
2. 비용과 효율: 계산 비용(token cost)과 사용자의 시간 비용을 포함합니다. GPT-4o가 작업을 3분 만에 완료한다면, 다른 에이전트가 30분이 걸린다면 이는 사용자에게 큰 부담입니다. 게다가 이 30분 동안 컴퓨팅 파워 소모가 막대하여 규모 효과에 영향을 미칩니다.
3. 사용자 지표: 가장 대표적인 것은 사용자 접착력입니다. 체험 후 반복 사용하고자 하는가? 예를 들어 일일 활성 사용자(DAU)/월간 활성 사용자(MAU) 비율, 익월 유지율, 유료 전환율 등이 있으며, 이는 회사가 '허황된 번영(five minutes of fame)'에 머무르지 않도록 하는 근본 지표입니다.
리광밀: 한 가지 더 보완하자면, 에이전트와 현재 모델 능력의 적합도입니다. 오늘날 에이전트의 80% 능력은 모델이라는 엔진에 의존하고 있습니다. 예를 들어 GPT가 3.5 버전에 이르러 다중 라운드 대화의 범용 패턴이 등장했고, 챗봇이라는 제품 형태가 성공할 수 있었습니다. Cursor의 부상도 모델이 Claude 3.5 수준에 이르러야 비로소 코드 자동 완성 기능이 가능해졌기 때문입니다.
Devin은 사실 너무 일찍 출시된 감이 있습니다. 따라서 창립팀이 모델 능력의 한계를 얼마나 잘 이해하고 있는지가 매우 중요합니다. 오늘날 그리고 향후 6개월 이내에 모델이 어디까지 도달할 수 있을지 명확히 파악해야 하며, 이는 에이전트가 달성할 수 있는 목표와 밀접하게 연결되어 있습니다.
장펑: 'AI 네이티브' 제품이란 무엇입니까? 저는 AI 네이티브 제품은 인간만을 위한 것이 아니라고 생각합니다. 반드시 AI에게도 서비스해야 합니다.
즉, 제품 안에 AI의 작업 환경을 구축하고 디버깅할 수 있는 합리적인 데이터가 없다면, AI를 단지 비용 절감과 효율 향상의 도구로만 사용하는 것이며, 이런 제품의 생명력은 제한적이며 기술 물결에 쉽게 휩쓸릴 수 있습니다. 진정한 AI 네이티브 제품은 인간과 AI를 위한 양방향 메커니즘을 내장해야 합니다. 간단히 말해, AI가 사용자를 서비스할 때 사용자도 동시에 AI를 서비스하고 있는가 하는 것입니다.
종개기 (Cage): 저는 이 개념이 매우 마음에 듭니다. 현실 세계에는 에이전트를 위한 데이터가 존재하지 않습니다. 아무도 작업을 수행할 때 사고 과정을 단계별로 분해하지 않습니다. 그렇다면 어떻게 해야 할까요? 한 가지 방법은 전문 어노테이션 회사를 고용하는 것이고, 다른 한 가지 방법은 사용자를 활용(leverage)해 사용자의 실제 사용 방식과 에이전트 자체의 실행 과정을 포착하는 것입니다.
장펑: 그렇다면 에이전트를 통해 인간이 AI에게 데이터를 '공급'하게 하려면 어떤 종류의 작업이 가장 가치 있는가요?
종개기 (Cage): 데이터를 통해 AI를 서비스하려는 것보다는, AI의 강점을 무엇으로 삼아야 할지 고민하는 것이 낫습니다. 예를 들어 과학 연구 분야에서, AlphaGo 이전까지 인간은 바둑과 수학이 가장 어렵다고 생각했습니다. 그러나 강화 학습을 적용한 후 이 분야가 오히려 AI에게는 가장 쉬운 것으로 밝혀졌습니다. 과학 분야도 마찬가지입니다. 인류 역사상 오랫동안 어느 학자도 모든 학문의 사각지대를 모두 꿰뚫을 수 없었습니다. 그러나 AI는 가능합니다. 따라서 과학 연구와 같은 작업은 인간에게는 어렵지만 AI에게는 그렇지 않을 수 있습니다. 그래서 오히려 그러한 작업을 위해 더 많은 데이터와 서비스를 찾아야 합니다. 이러한 작업의 보상은 대부분의 작업보다 더 검증 가능하며, 미래에는 인간이 AI를 위해 '시험관을 흔들며' 결과가 맞는지 틀리는지 알려주고, AI와 함께 기술 트리를 밝혀 나가는 상황이 올 수 있습니다.
리광밀: 초기 데이터 콜드 스타트는 필수적입니다. 에이전트를 만든다는 것은 스타트업을 창업하는 것과 같습니다. 창립자는 반드시 콜드 스타트를 해야 하며 직접 참여해야 합니다. 다음으로 환경 구축이 매우 중요하며, 이는 에이전트가 어떤 방향으로 나아갈지를 결정합니다. 이후 더 중요한 것은 보상(Reward) 시스템을 구축하는 것입니다. 저는 환경과 보상이라는 두 요소가 매우 중요하다고 생각합니다. 이 기반 위에서 에이전트 창업자는 자신의 에이전트를 위한 'CEO' 역할을 잘하면 됩니다. 오늘날 AI는 인간이 이해할 수 없지만 실행 가능한 코드를 작성할 수 있습니다. 우리는 반드시 강화 학습의 엔드 투 엔드 논리를 이해할 필요는 없습니다. 환경을 잘 구축하고 보상을 잘 설정하기만 하면 됩니다.
05 에이전트의 비즈니스 모델은 어디로 나아갈 것인가?
장펑: 최근 ToB 분야에서 많은 에이전트를 보고 있는데, 특히 미국에서 이들의 비즈니스 모델과 성장 모델에 변화가 있었습니까? 아니면 새로운 모델이 등장했습니까?
종개기 (Cage): 현재 가장 큰 특징은 점점 더 많은 제품이 C단말 측면에서 시작해 조직 내에서 아래에서 위로(bottom-up) 사용되고 있다는 점입니다. 가장 대표적인 것이 Cursor입니다. 이것 외에도 많은 AI 에이전트나 코파일럿 제품들이 있으며, 사용자들이 먼저 자발적으로 사용하려는 경향이 있습니다. 이는 더 이상 전통적인 SaaS처럼 CIO를 설득하고 일대일 계약을 체결해야 하는 모델이 아니며, 적어도 첫 번째 단계는 아닙니다.
또 다른 흥미로운 제품은 OpenEvidence입니다. 그들은 의사 그룹을 먼저 공략한 후 점차 의료기기 및 의약품 광고를 삽입하고 있습니다. 이러한 사업은 병원과의 협의 없이도 가능하며, 왜냐하면 병원과의 협의는 매우 느리기 때문입니다. AI 스타트업의 가장 중요한 것은 속도이며, 기술적 보호벽만으로는 부족합니다. 이러한 아래에서 위로의 방식을 통해 성장해야 합니다.

AI 의료 유니콘 OpenEvidence|사진 출처: OpenEvidence
비즈니스 모델 측면에서 현재 하나의 추세는 점차 '비용 기반(cost-based)' 가격 책정에서 '가치 기반(value-based)' 가격 책정으로 나아가고 있다는 점입니다.
1. 비용 기반: 전통적인 클라우드 서비스처럼 CPU/GPU 비용 위에 소프트웨어 가치를 추가하는 방식입니다.
2. 건당 과금: 에이전트 분야에서는 '행위(action)' 당 과금하는 방식이 있습니다. 앞서 언급한 물류 에이전트의 경우, 트럭 운전자에게 전화 한 통을 걸 때마다 수십 전(센트)을 받는 식입니다.
3. 워크플로 기반 과금: 더 높은 수준의 추상화는 '워크플로(workflow)' 기반 과금입니다. 예를 들어 물류 주문 전체를 완료하는 데 대한 과금입니다. 이는 비용 측면에서 멀어지고 가치 측면에 더 가까워집니다. 왜냐하면 실제로 작업에 참여했기 때문입니다. 하지만 이는 상대적으로 수렴된 시나리오가 필요합니다.
4. 결과 기반 과금: 그 위에는 '결과(result)' 기반 과금이 있습니다. 에이전트의 성공률이 높지 않기 때문에 사용자는 성공한 결과에 대해서만 비용을 지불하고자 합니다. 이는 에이전트 회사가 제품에 대해 매우 높은 수준의 다듬기를 요구합니다.
5. 에이전트 자체 기반 과금: 미래에는 진정으로 '에이전트' 자체에 대해 과금할 수 있습니다. 예를 들어 Hippocratic AI라는 회사는 AI 간호사를 개발하고 있는데, 미국에서 인간 간호사를 고용하면 시간당 약 40달러지만, 그들의 AI 간호사는 시간당 9~10달러에 불과하여 비용을 4분의 3 줄였습니다. 미국처럼 인건비가 비싼 시장에서는 매우 합리적입니다. 앞으로 에이전트가 더 잘하게 되면, 성과급이나 연말 보너스를 줄 수도 있습니다. 이 모두가 비즈니스 모델의 혁신입니다.
리광밀: 저희가 가장 기대하는 것은 가치 기반(value-based) 요금 체계입니다. 예를 들어 Manus AI가 웹사이트 하나를 만들었을 때 그 가치가 300달러인지, 애플리케이션 하나를 만들었을 때 5만 달러인지 말입니다. 하지만 현재 작업의 가치는 아직 잘 평가되지 않습니다. 어떻게 좋은 측정 및 요금 체계를 구축할 수 있을지, 이것은 스타트업들이 탐색해볼 만한 가치가 있습니다.
또한 아까 케이치가 언급한 에이전트 자체에 대한 과금은 기업이 직원과 계약을 맺는 것과 같습니다. 미래에 우리가 에이전트를 고용하게 되면, 그에게 '신분증'을 발급해야 할까요? '근로계약서'를 체결해야 할까요? 이는 바로 스마트 계약(smart contract)입니다. 저는 미래에 크립토 분야의 스마트 계약이 디지털 세계의 에이전트에 어떻게 적용될지 매우 기대됩니다. 작업 완료 후 좋은 측정 및 요금 수단을 통해 경제적 이익을 배분하는 것이 가능할 것입니다. 이것이 바로 에이전트와 크립토 스마트 계약의 융합 기회일 수 있습니다.
06 인간과 에이전트의 협업 관계는 어떤 형태가 될 것인가?
장펑: 최근 코딩 에이전트 분야에서 두 가지 용어가 자주 논의되고 있습니다. 'Human in the loop'와 'Human on the loop'인데, 이는 무엇을 다루고 있습니까?
종개기 (Cage): 'Human on the loop'란 인간이 루프 내에서의 결정을 최소화하고, 핵심 순간에만 개입하는 것을 의미합니다. 테슬라 FSD처럼 시스템이 위험한 결정을 마주했을 때 인간에게 경고하고 핸들과 브레이크를 넘겨받는 것과 비슷합니다. 가상 세계에서는 일반적으로 즉각적이지 않고 비동기적인 인간-기계 협업을 의미합니다. 인간은 AI가 확신이 없는 핵심 결정에 대해 개입할 수 있습니다.
'Human in the loop'는 AI가 가끔씩 'ping'을 보내며 어떤 일을 확인하는 방식에 더 가깝습니다. 예를 들어 Minus AI는 오른쪽 반쪽에 가상 머신을 두어, 브라우저에서 무엇을 하고 있는지 실시간으로 볼 수 있습니다. 이는 열린 백지상태처럼, 에이전트가 무엇을 하려는지 대략적으로 알 수 있습니다.
이 두 개념은 흑백논리가 아니며 하나의 스펙트럼입니다. 현재는 대부분 'in the loop'이며, 인간은 많은 핵심 지점에서 승인을 해야 합니다. 그 이유는 간단합니다. 소프트웨어가 아직 그 단계에 도달하지 못했고 문제가 발생하면 결국 책임을 질 사람이 있어야 하기 때문입니다. 핸들과 브레이크는 반드시 제거되지 않습니다.
예상할 수 있는 것은, 미래에 반복적인 작업에서는 결국 인간이 요약만 확인하게 되며, 자동화 정도가 매우 높아질 것입니다. 어려운 문제의 경우, 예를 들어 AI에게 병리 보고서를 분석하게 할 때, 우리는 에이전트의 '위양성률(false positive rate)'을 조금 더 높게 설정하여 '문제가 있다'고 더 쉽게 판단하게 할 수 있습니다. 그런 다음 'on the loop' 방식으로 이러한 사례들을 이메일로 인간 의사에게 보내면 됩니다. 이렇게 하면 인간 의사가 재검토해야 할 사례는 많아지지만, 에이전트가 '음성'으로 판단한 모든 사례는 무사히
TechFlow 공식 커뮤니티에 오신 것을 환영합니다
Telegram 구독 그룹:https://t.me/TechFlowDaily
트위터 공식 계정:https://x.com/TechFlowPost
트위터 영어 계정:https://x.com/BlockFlow_News












