월의 어두운 면 MoBA 핵심 작가의 고백: '신진 대규모 모델 훈련사'의 세 번에 걸친 사과애 도전기
저자: 앤드류 루, 늦은 시점 팀

이미지 출처: 무계 AI 생성
2월 18일, Kimi와 DeepSeek가 각각 MoBA와 NSA라는 새로운 진전을 발표했는데, 이 둘 모두 "어텐션 메커니즘"(Attention Mechanism)의 개선안이다.
오늘날, MoBA의 주요 연구개발 담당자인 앤드류 루(Andrew Lu)가 징후상에서 포스팅을 통해 연구개발 과정에서 세 차례 실패했던 경험을 '삼입사과애'(세 번 사과애에 들어간 것)라 칭하며 설명했다. 그의 징후 프로필에는 "신진 LLM 트레이너"라고 적혀 있다.
이 답변 아래 달린 댓글 중 하나는 다음과 같다. "오픈소스 논문, 오픈소스 코드를 넘어 이제는 사고의 연쇄까지 오픈소스화하는 단계에 도달했구나."
어텐션 메커니즘이 중요한 이유는 현재의 대규모 언어 모델(LLM)의 핵심 메커니즘이기 때문이다. 2017년 6월 LLM 혁명의 서막을 알렸던 트랜스포머 8자 논문으로 돌아가보면, 제목은 바로 'Attention Is All You Need'(어텐션이 전부다)이며, 이 논문은 지금까지 15.3만 회 인용되었다.
어텐션 메커니즘은 AI 모델이 정보 처리 시 어떤 부분을 "중점적으로 주목"하고 어떤 부분을 "무시"할지를 인간처럼 판단하게 하여 정보 중 가장 핵심적인 부분을 파악할 수 있게 한다.
대규모 모델의 학습 단계와 사용(추론) 단계 모두에서 어텐션 메커니즘은 작동한다. 그 기본 원리는 입력 데이터 예를 들어 "나는 사과를 좋아해"라는 문장을 넣었을 때, 대형 모델이 문장 내 각 단어(Token) 간의 관계를 계산하여 의미 등의 정보를 이해하는 것이다.
그러나 대형 모델이 처리해야 하는 컨텍스트가 점점 길어질수록, 표준 트랜스포머가 처음 채택한 풀 어텐션(Full Attention) 방식은 계산 자원 소비가 감당할 수 없게 된다. 초기 프로세스에서는 모든 입력 단어들의 중요도 점수를 전부 계산한 후 가중치를 부여하여 가장 중요한 단어들을 추출하는데, 이 계산 복잡도는 텍스트 길이 증가에 따라 제곱급(비선형)으로 증가하기 때문이다. MoBA 논문의 "초록" 부분에 명시된 바와 같다.
"전통적 어텐션 메커니즘에 고유한 계산 복잡도의 제곱 증가는 엄청난 계산 비용을 초래한다."
동시에 연구자들은 AGI가 가져야 할 특성들—다중 대화, 복잡한 추론, 기억 능력 등—을 구현하기 위해 대형 모델이 매우 긴 컨텍스트를 처리할 수 있기를 기대한다.
따라서 계산 자원과 메모리 사용을 크게 줄이면서도 모델 성능을 손상시키지 않는 어텐션 메커니즘 최적화 방법을 찾는 것은 대형 모델 연구의 중요한 과제가 되었다.
이는 여러 기업들이 '어텐션' 기술에 주목하게 된 기술적 배경이다.
DeepSeek의 NSA와 Kimi의 MoBA 외에도 올해 1월 중순, 또 다른 중국의 대형 모델 스타트업 MiniMax도 첫 오픈소스 모델인 MiniMax-01에서 새로운 유형의 어텐션 메커니즘을 대규모로 구현했다. MiniMax 창립자 옌쥔제(Yan Junjie)는 당시 우리에게 이것이 MiniMax-01의 주요 혁신 포인트 중 하나라고 말했다.
또한 면벽지능 공동창립자이자 칭화대학 컴퓨터학과 부교수인 류즈위안(Liu Zhiyuan) 교수팀도 2024년 InfLLM을 발표했는데, 여기에서도 희소 어텐션(Sparse Attention) 개선이 포함되어 있으며, 이 논문은 NSA 논문에서 인용되었다.
이러한 성과 중 NSA, MoBA, InfLLM의 어텐션 메커니즘은 모두 "희소 어텐션 메커니즘"(Sparse Attention)에 속한다. 반면 MiniMax-01의 시도는 주로 다른 방향인 "선형 어텐션 메커니즘"(Linear Attention)에 집중하고 있다.
SeerAttention 공동 저자이자 MSRA 고급 연구원인 차오스제(Cao Shijie)는 우리에게 말했다. 일반적으로 선형 어텐션 메커니즘은 표준 어텐션 메커니즘에 더 많은 수정과 극단적인 변화를 시도하며, 텍스트 길이 증가에 따른 계산 복잡도의 제곱 급증(즉 비선형 문제)을 직접 해결하려 한다. 그러나 그 대가로 장거리 컨텍스트의 복잡한 종속 관계를 포착하는 능력을 일부 잃을 수도 있다. 반면 희소 어텐션 메커니즘은 어텐션의 본질적인 희소성을 활용하여 비교적 안정적인 최적화 방법을 모색한다.
동시에 차오스제 교수가 징후에서 작성한 어텐션 메커니즘 관련 고득점 답변을 추천한다: https://www.zhihu.com/people/cao-shi-jie-67/answers
(그는 "량원펑이 참여하여 발표한 DeepSeek의 새로운 논문 NSA 어텐션 메커니즘은 어떤 정보가 주목할 만한가? 어떤 영향을 미칠 것인가?"라는 질문에 답변했다.)
희소 어텐션의 Mixture of Attention(MoA) 공동 제1저자이며 칭화대학 NICS-EFC 연구실 박사인 푸톈위(Fu Tianyu)는 희소 어텐션 메커니즘의 큰 방향성에 대해 말했다. "NSA와 MoBA는 모두 동적 어텐션 방법을 도입하여 세밀한 어텐션 계산이 필요한 KV 캐시 블록을 동적으로 선택할 수 있다. 정적 방법을 사용하는 일부 희소 어텐션 메커니즘과 비교하면 모델 성능을 향상시킬 수 있다. 또한 두 방법 모두 추론 시가 아니라 모델 학습 단계부터 희소 어텐션을 도입함으로써 모델 성능을 더욱 향상시켰다."
(참고: KV 캐시 블록은 이전에 계산된 Key 태그와 Value 값을 저장하는 캐시이다. Key 태그란 어텐션 계산 과정에서 데이터 특징이나 위치 정보 등을 식별하기 위한 태그이며, 어텐션 가중치 계산 시 다른 데이터와 매칭 및 연관될 수 있도록 한다. Value 값은 Key 태그에 대응하며, 일반적으로 단어 또는 어구의 의미 벡터 등 실제 처리할 데이터 내용을 포함한다.)
또한 이번에 Moonshot은 상세한 MoBA 기술 논문뿐 아니라 GitHub의 해당 프로젝트 페이지에 MoBA 엔지니어링 코드도 공개했다. 이 코드 세트는 Moonshot의 자체 제품 Kimi에서 이미 1년 이상 실서비스로 운영되고 있다.
* 다음은 앤드류 루(Andrew Lu)가 징후에 게시한 글이며, 저자로부터 허가를 받았다. 원문에는 다수의 AI 용어가 포함되어 있으며, 괄호 안의 회색 글자는 편집자의 주석이다. 원문 링크: https://www.zhihu.com/people/deer-andrew
앤드류 루의 연구개발 자술서
장밍싱(칭화대학교 조교수) 교수님의 초청에 응해 MoBA 개발 과정의 고충을 간략히 소개합니다. 저는 이를 희극적으로 "삼입사과애"라 부릅니다. (앤드류 루가 답한 질문: "Kimi가 오픈소스한 희소 어텐션 프레임워크 MoBA를 어떻게 평가할 수 있는가? DeepSeek의 NSA와 비교했을 때 각각의 강점은 무엇인가?")
MoBA의 시작
MoBA 프로젝트는 매우 일찍 시작되었는데, 2023년 5월 말 Moonshot 설립 직후 입사 첫날, Tim(Moonshot 공동창립자 저우신위)에게 작은 방으로 불려가 취제중 교수(저장대학교 / 지장실험실, MoBA 아이디어 제안자) 및 Dylan(Moonshot 연구원)과 함께 Long Context Training(장거리 컨텍스트 학습) 작업을 시작했다. 우선 Tim의 인내심과 지도에 감사드리며, LLM 초보자에게 신뢰를 주고 양성해주신 점에 깊이 감사드립니다. 다양한 실서비스 모델과 관련 기술을 개발하신 여러 전문가들 중 다수는 저와 마찬가지로 거의 LLM을 처음 접한 상태였습니다.
당시 업계 수준도 그리 높지 않았으며, 대부분은 4K 사전 학습(모델이 처리 가능한 입력/출력 길이가 약 4,000 토큰, 수천 개의 한자) 수준이었다. 프로젝트 초기 이름은 16K on 16B로, 16B(모델 파라미터 160억) 규모에서 16K 길이의 사전 학습을 수행하면 된다는 의미였다. 하지만 이후 곧바로 8월에는 128K에서 사전 학습을 지원해야 한다는 요구사항으로 변경되었다. 이것이 바로 MoBA 설계 시의 첫 번째 요구사항이었다. 즉 128K 길이를 지원하는 모델을 From Scratch(완전히 처음부터) 빠르게 학습시킬 수 있어야 하며, Continue Training(기존 학습된 모델 위에서 계속 학습)이 필요하지 않아야 했다.
여기서 흥미로운 문제가 하나 발생한다. 2023년 5~6월 당시 업계는 짧은 모델을 학습한 후 길이를 확장하는 것보다 장거리 텍스트를 직접 사용하여 단말간(end-to-end) 학습하는 것이 효과가 더 좋다고 보았다. 이러한 인식은 2023년 하반기에 Meta가 개발한 장거리 텍스트 처리 대형 모델 long Llama가 등장하면서 비로소 전환되었다. 우리 역시 엄격한 검증을 거쳤으며, 실제로는 짧은 텍스트 학습 + 길이 활성화가 더 높은 token efficiency(각 토큰이 기여하는 유효 정보량 향상, 즉 모델이 더 적은 토큰으로 더 고품질 작업을 수행할 수 있음)를 보였다. 따라서 MoBA 설계의 첫 번째 기능은 자연스럽게 시대의 희생물이 되었다.
이 시기 MoBA의 구조 설계도 현재의 "극도로 단순화된" 결과보다 훨씬 "급진적"이었다. 초기 제안된 MoBA는 cross attention(두 개의 서로 다른 텍스트 데이터 간 관계를 처리하는 어텐션 메커니즘)을 포함한 두 층의 어텐션 메커니즘을 직렬로 연결하는 방식이었으며, gate(입력 데이터가 각 전문가 네트워크 사이에서 어떻게 가중치를 분배할지를 제어하는 구조) 자체는 무파라미터 구조(파라미터 없음, 학습 불필요)였다. 그러나 이전 토큰의 학습을 더 잘하기 위해 우리는 각 Transformer 레이어마다 머신 간 cross attention과 해당 파라미터를 추가했다(역사 정보를 더 잘 기억 가능). 이때의 MoBA 설계는 나중에 널리 알려진 Context Parallel 개념(전체 컨텍스트 시퀀스를 여러 노드에 분산 저장하고 계산 시에만 집합)을 결합한 것이었다. 전체 컨텍스트 시퀀스를 데이터 병렬 노드들 사이에 분할하고, 각 데이터 병렬 노드 내 컨텍스트를 MoE(Mixture of Experts, 전문가 혼합 시스템)의 expert(전문가)로 간주하며, 어텐션이 필요한 토큰을 해당 expert로 보내 cross attention을 수행한 후 결과를 통신으로 반환하였다. 우리는 fastmoe(초기 MoE 학습 프레임워크)의 기능을 Megatron-LM(NVIDIA의 일반적인 대형 모델 학습 프레임워크)에 통합하여 expert 간 통신 기능을 지원했다.
이 아이디어를 우리는 MoBA v0.5라 명명했다.
(편집자 주: MoBA의 영감은 현재 주류인 대형 모델 MoE 구조에서 비롯된다. MoE란 대형 모델이 작동 시 모든 전문가의 파라미터를 활성화하는 대신 일부만 활성화함으로써 컴퓨팅 자원을 절약하는 것을 의미한다. MoBA의 핵심 아이디어는 "매번 전체 컨텍스트가 아니라 가장 관련 있는 컨텍스트만 보기 때문에 계산과 비용을 절약한다"는 것이다.)
시간이 흘러 2023년 8월 초, 주 모델 사전 학습이 이미 많은 토큰을 학습한 상태에서 다시 처음부터 시작하는 것은 비용이 너무 크다. 따라서 구조를 크게 변경하고 추가 파라미터를 포함한 MoBA는 처음으로 '사과애'에 들어갔다.
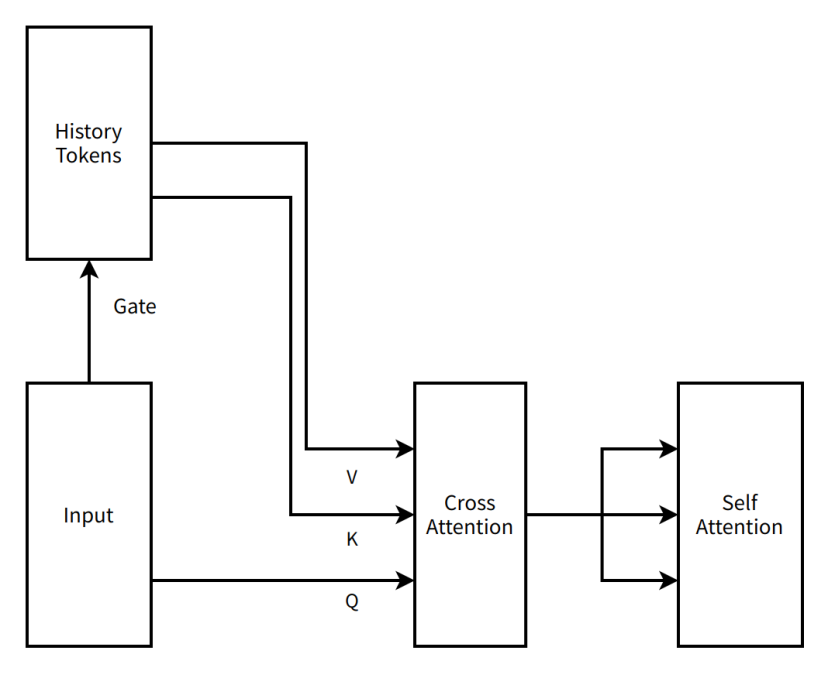
매우 간단한 MoBA v0.5의 개략도
편집자 주:
History Tokens(역사 토큰)—자연어 처리 등의 시나리오에서 이전에 처리된 텍스트 단위의 집합을 나타냄
Gate(게이트)—신경망에서 정보 흐름을 제어하는 구조
Input(입력)—모델이 수신하는 데이터 또는 정보
V(Value, 값)—어텐션 메커니즘에서 실제로 처리하거나 주목해야 할 데이터 내용을 포함하며, 의미 벡터 등을 포함함
K(Key, 키 태그)—어텐션 메커니즘에서 데이터 특징이나 위치 정보 등을 식별하기 위한 태그로, 다른 데이터와 매칭 및 연관 가능하도록 함
Q(Query, 쿼리)—어텐션 메커니즘에서 키-값 쌍에서 관련 정보를 검색하기 위한 벡터
Cross Attention(크로스 어텐션)—입력을 역사 정보와 연결하는 등 서로 다른 소스의 입력에 주목하는 어텐션 메커니즘
Self Attention(셀프 어텐션)—모델이 자신의 입력에 주목하여 내부 의존 관계를 포착하는 어텐션 메커니즘
일입사과애
'사과애'에 들어가는 것은 물론 희극적인 표현으로, 개선 방안을 모색하고 새 구조를 깊이 이해하는 시간을 의미한다. 첫 번째 사고애 진입은 빠르게 들어가 빠르게 나왔다. Moonshot의 아이디어 장인 Tim은 새로운 개선 아이디어를 제시하여 MoBA를 직렬 2층 어텐션에서 병렬 단일 어텐션 구조로 변경했다. MoBA는 더 이상 추가 모델 파라미터를 추가하지 않고 기존 어텐션 메커니즘 파라미터를 활용하여 시퀀스 내 모든 정보를 동시에 학습함으로써 현재 구조를 최대한 유지하며 Continue Training을 수행할 수 있도록 했다.
이 접근법을 우리는 MoBA v1이라 명명했다.
MoBA v1은 사실상 희소 어텐션(Sparse Attention)과 Context Parallel의 산물로서, 당시 Context Parallel이 대세가 아니었던 시기에 MoBA v1은 매우 높은 end-to-end 가속 능력을 보여주었다. 우리는 3B, 7B 규모에서 효과를 검증한 후 더 큰 모델로 확장하려 했으나 벽에 부딪혔다. 학습 중 매우 큰 loss spike(모델 학습 시 발생하는 비정상 현상)가 나타났다. 우리가 초기에 block attention output(어텐션 모듈이 데이터 처리 후 출력 결과)을 통합하는 방식이 너무 단순하여 단순 누산만 했기 때문에 Full Attention과 정확히 비교하여 디버깅이 불가능했다. ground truth(표준 답안, 여기서는 Full Attention 결과) 없는 디버깅은 극도로 어렵다. 당시의 모든 안정성 기법을 동원해도 해결되지 않았다. 더 큰 모델 학습에서 문제가 발생함에 따라 MoBA는 두 번째로 사고애에 들어갔다.
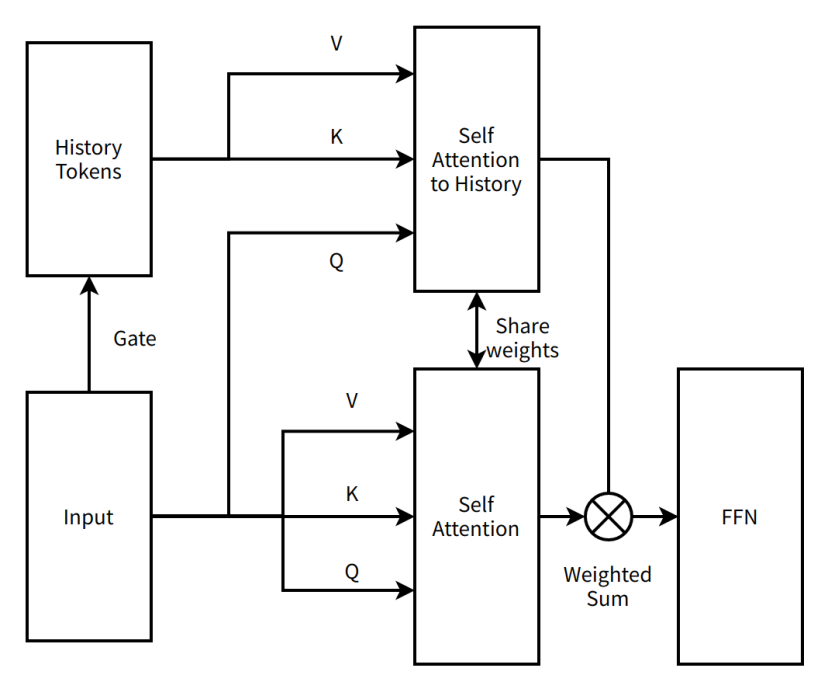
매우 간단한 MoBA v1의 개략도
편집자 주:
Self Attention to History(역사에 대한 셀프 어텐션)—모델이 역사 토큰에 주목하여 현재 입력과 역사 정보 간 의존 관계를 포착하는 어텐션 메커니즘
Share weights(가중치 공유)—신경망의 서로 다른 부분이 동일한 가중치 파라미터를 사용하여 파라미터 수를 줄이고 모델 일반화 능력을 향상
FFN(Feed-Forward Neural Network, 전방향 신경망)—데이터가 입력층에서 은닉층을 거쳐 출력층으로 단일 방향으로 흐르는 기본 신경망 구조
Weighted Sum(가중합)—여러 값을 각각의 가중치에 따라 합산하는 연산
이입사과애
두 번째 사고애 체류 기간은 비교적 길었으며, 2023년 9월부터 시작하여 사고애를 나올 때는 이미 2024년 초였다. 그러나 사고애 안에 있다는 것이 버림받았다는 의미는 아니다. 나는 Moonshot에서 일하는 두 번째 특징인 '포화 구조(saturation rescue)'를 체험할 수 있었다.
끊임없이 강력한 아이디어를 제공하는 Tim과 취 교수 외에도, 소선린(蘇神, Moonshot 연구원), 위안거(Jingyuan Liu, Moonshot 연구원) 및 다양한 전문가들이 격렬한 토론에 참여하여 MoBA를 분해하고 수정하기 시작했다. 먼저 수정된 것은 단순한 Weighted Sum(가중합) 중첩이었다. 다양한 Gate Matrix와의 곱셈 및 덧셈 방식을 시도한 후, Tim은 오래된 문서에서 Online Softmax(모든 데이터를 본 후 계산하는 것이 아니라 데이터가 올 때마다 처리)를 찾아내어 이것이 효과가 있을 것이라고 주장했다. 가장 큰 장점은 Online Softmax 사용 후 희소도를 0으로 낮춰(모든 블록 선택) 수학적으로 동등한 Full Attention과 정밀하게 비교 디버깅할 수 있다는 점이었다. 이는 대부분의 구현 문제를 해결했다. 그러나 여전히 데이터 병렬 노드 사이에 컨텍스트를 분할하는 설계는 불균형 문제를 초래했다. 하나의 데이터 샘플이 데이터 병렬로 분할된 후, 첫 번째 데이터 병렬 rank의 앞부분 몇 토큰이 후속 수많은 Q에 의해 attend(어텐션 계산 과정)되면서 극도로 나쁜 균형을 이루었고, 이로 인해 가속 효율성이 저하되었다. 이 현상은 더 잘 알려진 이름인 "Attention Sink(어텐션 집결점)"으로도 불린다.
이때 장 교수님이 방문하여 우리의 아이디어를 듣고 새로운 접근법을 제안했다. Context Parallel 기능과 MoBA를 분리하자는 것이었다. Context Parallel은 Context Parallel이고, MoBA는 MoBA다. MoBA는 분산형 희소 어텐션 학습 프레임워크가 아닌 순수한 희소 어텐션으로 회귀해야 한다는 것이다. GPU 메모리에 담을 수 있다면 단일 머신에서 전체 컨텍스트를 처리하고 MoBA로 계산을 가속화하며, Context Parallel 방식으로 머신 간 컨텍스트를 조직하고 전달하는 것이다. 따라서 우리는 MoBA v2를 재구현하였으며, 이는 현재 모두가 보는 MoBA의 모습과 거의 같다.
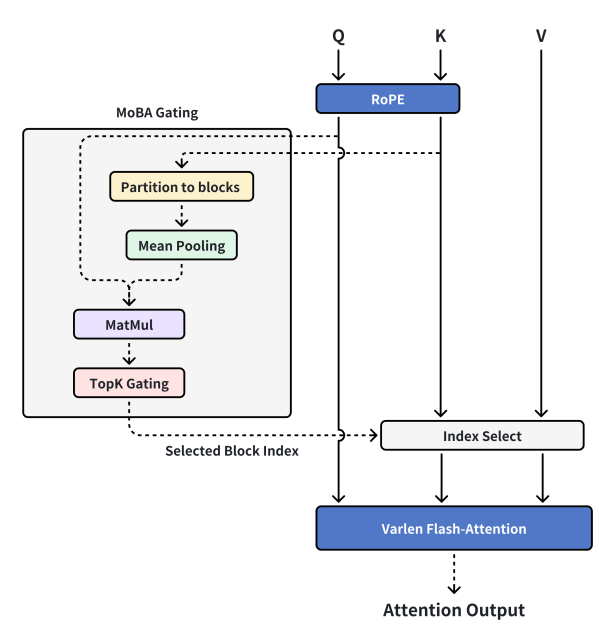
현재의 MoBA 설계
편집자 주:
MoBA Gating(MoBA 게이팅)—MoBA의 특정 게이트 메커니즘
RoPE(Rotary Position Embedding, 회전 위치 임베딩)—시퀀스에 위치 정보를 추가하는 기술
Partition to blocks(블록으로 분할)—데이터를 서로 다른 블록으로 나누기
Mean Pooling(평균 풀링)—딥러닝에서 데이터 다운샘플링을 위한 연산으로, 특정 영역 내 데이터의 평균값을 계산
MatMul(Matrix-Multiply, 행렬 곱셈)—두 행렬의 곱을 계산하는 수학 연산
TopK Gating(Top-K 게이팅)—상위 K개의 중요한 요소를 선택하는 게이트 메커니즘
Selected Block Index(선택된 블록 인덱스)—선택된 블록의 번호를 나타냄
Index Select(인덱스 선택)—인덱스에 따라 데이터에서 해당 요소를 선택
Varlen Flash-Attention(가변 길이 플래시 어텐션)—가변 길이 시퀀스에 적합하고 계산 효율이 높은 어텐션 메커니즘
Attention Output(어텐션 출력)—어텐션 메커니즘 계산 후의 출력 결과
MoBA v2는 안정적이고 학습 가능하며, 짧은 텍스트와 Full Attention이 완전히 일치했고 Scaling Law도 매우 신뢰할 수 있었으며, 온라인 모델에 비교적 부드럽게 적용할 수 있었다. 따라서 더 많은 자원을 투입했고, 일련의 디버깅을 거쳐 infra 팀 동료들의 머리카락 n줄기를 소모한 후, MoBA로 활성화된 사전 학습 모델이 '바늘찾기 테스트'에서 전 항목 녹색(대형 모델의 장거리 텍스트 처리 능력 테스트 기준 충족)을 달성할 수 있었다. 이 단계에서 우리는 매우 만족했고 상용화를 시작했다.
그러나 가장 예상치 못한 일이 발생했다. SFT(감독 미세 조정, 사전 학습 모델 기반 특정 작업에 맞춰 추가 학습하여 모델 성능 향상) 단계에서 일부 데이터는 매우 희소한 loss mask(오직 1% 또는 그 이하의 토큰만 학습용 그래디언트를 가지도록 함)(loss mask란 모델 예측 결과와 정답 간 계산에 참여할 부분을 선택하는 기술)를 포함하고 있었다. 이로 인해 MoBA는 대부분의 SFT 작업에서는 우수한 성능을 보였지만, 특히 장문 요약 유형 작업에서 loss mask가 더 희소해질수록 학습 효율이 현저히 낮아졌다. MoBA는 상용화 직전 프로세스에서 일시 중단되었고, 세 번째로 사고애에 들어갔다.
삼입사과애
세 번째 사고애 진입 시 가장 긴장됐다. 이미 이 프로젝트는 막대한 잠식 비용(sunk cost)을 지녔고, 회사는 많은 컴퓨팅 자원과 인적 자원을 투입했다. 만약 최종적으로 장문 시나리오에서 문제가 발생한다면 초기 연구는 거의 물거품이 될 수 있었다. 다행히도 MoBA 자체의 우수한 수학적 특성 덕분에 새로운 라운드의 포화 구조 실험(ablation, 모델의 일부를 제거하거나 설정을 변경하여 성능에 미치는 영향을 연구)에서 loss mask를 제거하면 성능이 매우 우수했지만, loss mask를 포함하면 성능이 만족스럽지 않음을 발견했다. 결국 SFT 단계에서 그래디언트를 가진 토큰이 지나치게 희소하여 학습 효율이 낮아졌음을 인지했다. 따라서 마지막 몇 층을 Full Attention으로 수정하여 역전파 시 그래디언트 토큰의 밀도를 높이고 특정 작업의 학습 효율을 개선했다. 이후 다른 실험에서 이러한 전환이 전환 후 희소 어텐션 효과에 크게 영향을 주지 않음을 확인했으며, 1M(백만) 길이에서도 동일 구조의 Full Attention과 모든 지표가 동일했다. MoBA는 다시 사고애를 벗어나 성공적으로 상용 서비스에 투입되었다.
마지막으로, 여러 전문가들의 도움과 회사의 강력한 지원, 그리고 방대한 GPU 자원에 감사드립니다. 이제 우리가 공개하는 것은 실서비스에서 사용 중인 코드이며, 오랜 기간 검증되었고 실제 요구에 따라 다양한 추가 설계를 제거하여 극도로 단순하면서도 충분한 효과를 갖춘 희소 어텐션 구조이다. MoBA와 그 탄생 과정의 CoT(Chain of Thought, 사고의 연쇄)가 여러분께 도움과 가치를 제공하기를 바랍니다.
FAQ
덧붙여 최근 자주 받는 질문들을 몇 가지 답변하겠습니다. 지난 며칠간 장 교수님과 소신님께 고객 응대를 부탁드려 정말 죄송해서, 자주 묻는 질문을 몇 가지 정리해 답변드립니다.
1. MoBA는 Decoding (모델 추론 단계의 텍스트 생성 과정)에는 무효인가?
MoBA는 Decoding에 유효하다. MHA(Multi-Head Attention, 다중 헤드 어텐션)에는 매우 효과적이며, GQA(Grouped Query Attention, 그룹 쿼리 어텐션)에는 효과가 감소하고, MQA(Multi-Query Attention, 다중 쿼리 어텐션)에는 효과가 가장 낮다. 원리는 간단하다. MHA의 경우 각 Q는 자신만의 KV 캐시를 가지므로, 이상적인 경우 MoBA의 게이트는 prefill(입력 처리 초기 단계)에서 각 블록(block, 데이터 블록)의 대표 토큰을 미리 계산하여 저장할 수 있으며, 이 토큰은 이후 변하지 않는다. 따라서 모든 IO(입출력 작업)는 기본적으로 index select(인덱스 선택 후) KV 캐시에서 오게 된다. 이 경우 MoBA의 희소 정도가 IO 감소 정도를 결정한다.
그러나 GQA와 MQA의 경우, 여러 Q Head가 동일한 KV 캐시를 공유하기 때문에 각 Q Head가 자유롭게 관심 있는 블록을 선택할 경우 희소성에서 오는 IO 최적화가 상쇄될 수 있다. 예를 들어 다음과 같은 상황을 생각해보자. 16개 Q Head의 MQA에서 MoBA가 전체 시퀀스를 정확히 16개로 분할했다면, 최악의 경우 각 Q Head가 각각 1~16번 컨텍스트 블록에 관심을 가지면 IO 절감 효과가 상쇄된다. KV 블록을 자유롭게 선택할 수 있는 Q Head가 많을수록 효과는 더 나빠진다.
"KV 블록을 자유롭게 선택하는 Q Head"라는 현상이 존재하기 때문에 자연스러운 개선 아이디어는 통합이다. 모두 같은 블록을 선택한다면 IO 최적화를 그대로 얻을 수 있지 않을까? 맞다. 그러나 실제 테스트에서 특히 많은 비용을 들여 사전 학습된 모델의 경우 각 Q Head는 고유한 "취향"을 가지고 있으며, 강제로 통합하는 것보다 처음부터 다시 학습하는 것이 낫다.
2. MoBA는 기본적으로 self attention(셀프 어텐션 메커니즘)을 반드시 선택하는데, 그러면 자기 이웃도 반드시 선택되는가?
아니다. 이는 일부 혼동을 초래할 수 있는 지점인데, 우리는 결국 SGD(Stochastic Gradient Descent, 확률적 경사하강법)를 믿기로 했다. 현재 MoBA 게이트 구현은 매우 직접적이며, 관심 있는 연구자는 게이트를 간단히 수정하여 이전 청크(chunk, 데이터 블록)를 반드시 선택하도록 할 수 있지만, 우리 자체 테스트에서 이 수정의 수익은 매우 미미했다.
3. MoBA는 Triton (OpenAI가 개발한 고성능 GPU 코드 작성 프레임워크) 구현이 있나요?
버전을 하나 구현해봤으며, end-to-end 성능이 10% 이상 향상되었지만, Triton 구현은 주 라인(mainline)을 따라가며 지속적으로 유지 관리하는 비용이 매우 높아 여러 차례 반복 후 추가 최적화를 보류했다.
* 본문 시작 부분에서 언급된 몇 가지 성과의 프로젝트 주소(GitHub 페이지에는 모두 기술 논문 링크 포함, DeepSeek는 아직 NSA의 GitHub 페이지를 공개하지 않음):
MoBA GitHub 페이지: https://github.com/MoonshotAI/MoBA
NSA 기술 논문: https://arxiv.org/abs/2502.11089
MiniMax-01 GitHub 페이지: https://github.com/MiniMax-AI/MiniMax-01
InfLLM GitHub 페이지: https://github.com/thunlp/InfLLM?tab=readme-ov-file
SeerAttention GitHub 페이지: https://github.com/microsoft/SeerAttention
TechFlow 공식 커뮤니티에 오신 것을 환영합니다
Telegram 구독 그룹:https://t.me/TechFlowDaily
트위터 공식 계정:https://x.com/TechFlowPost
트위터 영어 계정:https://x.com/BlockFlow_News