Grok3를 '세상에서 가장 똑똑한' 모델로 테스트하다: 이것이 정말로 모델 한계 효과의 종착점인가?
베이징 시간 2월 18일, 머스크와 xAI 팀은 생중계를 통해 Grok의 최신 버전인 Grok3를 정식으로 발표했다.
이번 발표회 이전부터 관련 정보들이 지속적으로 공개되었고, 머스크 본인이 24시간 내내 예열 마케팅을 하면서 전 세계적으로 Grok3에 대한 기대감이 사상 최고 수준으로 끌어올려졌다. 일주일 전, 머스크는 생중계 도중 DeepSeek R1에 대해 언급하며 자신감满满하게 "xAI가 곧 더 우수한 AI 모델을 출시할 것"이라고 밝힌 바 있다.
현장에서 공개된 데이터에 따르면, Grok3는 수학, 과학, 프로그래밍 분야의 벤치마크 테스트에서 현재 모든 주요 모델을 이미 능가했으며, 머스크는 심지어 Grok3가 향후 SpaceX 화성 임무 계산에 사용될 것이며 "3년 이내에 노벨상급 돌파가 가능할 것"이라고 예측했다.
하지만 이러한 주장들은 지금까지 모두 머스크 개인의 일방적인 발언일 뿐이다.笔者在发布后,就测试了最新的 Beta 版 Grok3,并提出了那个经典的用来刁难大模型的问题:「9.11 与 9.9 哪个大?」
안타깝게도 어떠한 부가 설명이나 표기 없이, 현재 가장 똑똑하다는 Grok3조차 이 문제를 올바르게 답변하지 못했다.
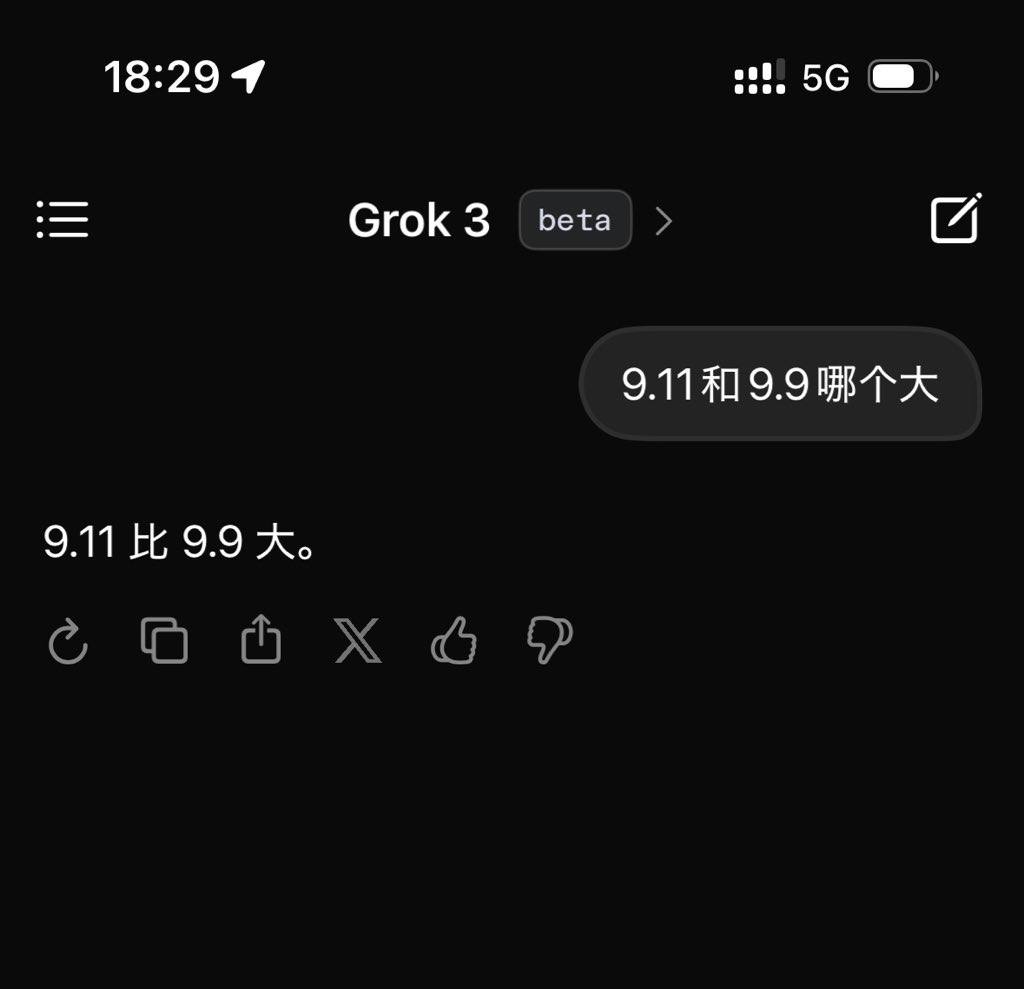
Grok3는 이 문제의 의미를 정확히 인식하지 못했다
이미지 출처: Geek Park
이 테스트 결과가 공개된 직후 짧은 시간 안에 많은 사람들의 관심을 끌었으며, 해외에서도 유사한 기초 물리/수학 문제들(예: 피사의 사탑에서 두 공 중 어떤 것이 먼저 떨어지는가)에 대한 테스트가 다수 이루어졌는데, Grok3는 여전히 이런 기본 문제들을 해결하지 못하는 것으로 드러났다. 이에 따라 '천재는 간단한 질문에는 답하지 않는다'는 조롱 섞인 평가를 받기도 했다.
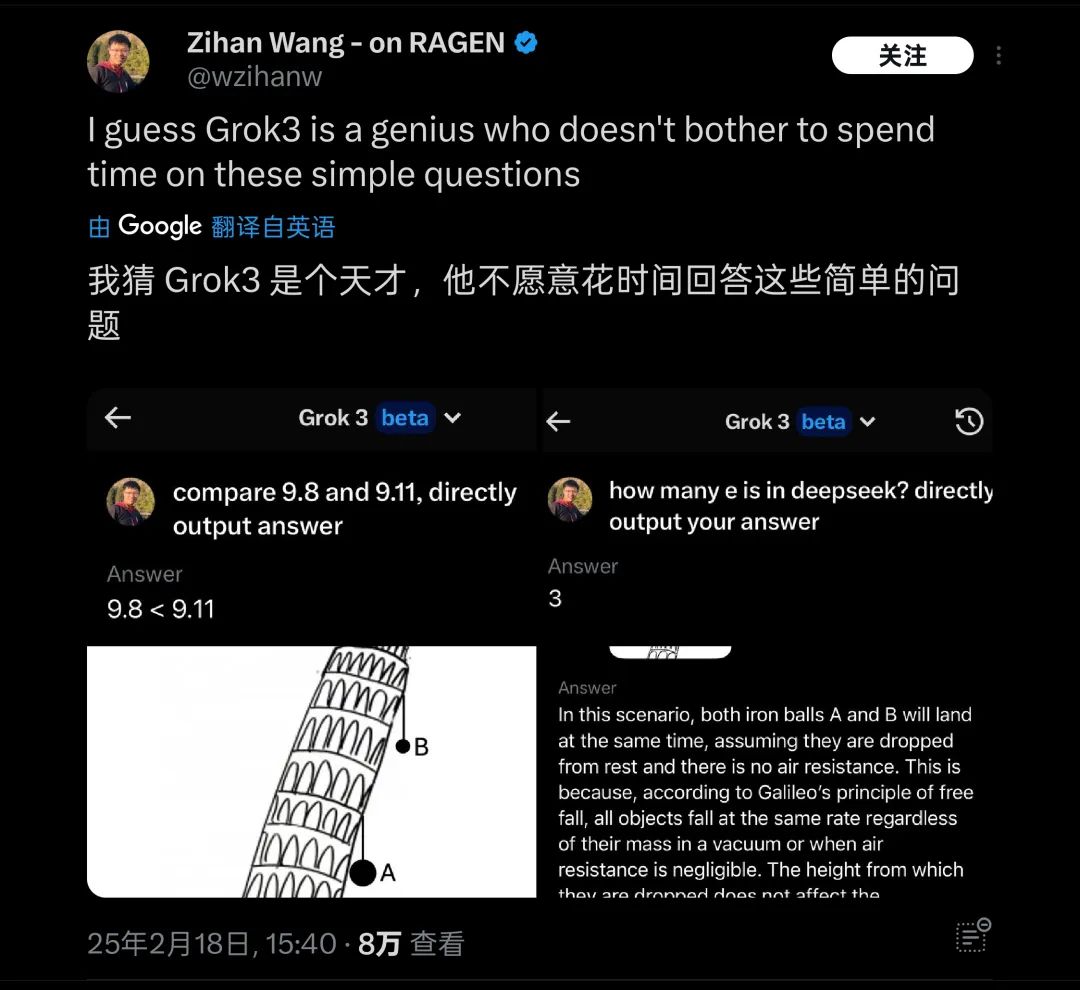
Grok3는 실제 테스트에서 여러 상식 문제에서 '전복'되었다
이미지 출처: X
네티즌들의 자발적 테스트에서 Grok3가 기초 지식 문제에서 실수를 저지른 것 외에도, xAI의 발표 생중계에서 머스크는 자신이 자주 플레이한다고 주장하는 Path of Exile 2(출처: 유랑의 길 2)의 직업 및 각성 효과 분석을 Grok3로 시연했는데, 실제로 Grok3가 제시한 대부분의 답변은 오답이었다. 그러나 생방송 당시 머스크는 이 명백한 오류를 알아차리지 못했다.
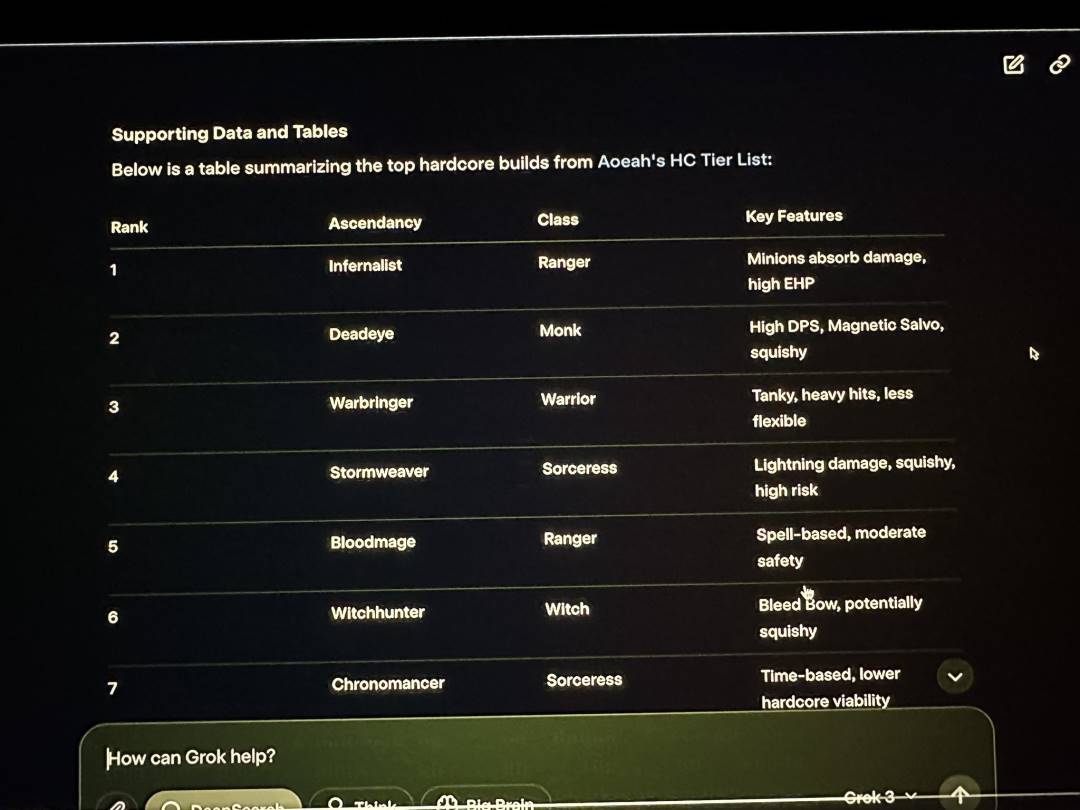
Grok3는 생방송에서도 데이터 오류를 대량으로 발생시켰다
이미지 출처: X
따라서 이러한 실수는 해외 네티즌들이 다시금 머스크가 게임 플레이 시 '대리 게이머'를 활용한다는 것을 입증하는 결정적 증거가 되었으며, Grok3의 실제 응용 가능성에 대해서도 커다란 의문을 제기하게 만들었다.
이처럼所谓「천재」라고 불리는 모델이라 할지라도 실제 능력이 어떠하든, 화성 탐사와 같은 극도로 복잡한 응용 시나리오에 적용되는 경우 그 신뢰성은 반드시 커다란 물음표를 가지게 될 것이다.
현재 몇 주 전 Grok3 테스트 자격을 얻었던 다수의 사용자들과 어제 겨우 몇 시간 동안 모델을 사용해본 테스터들 모두 Grok3의 현재 성능에 대해 동일한 결론을 내리고 있다:
「Grok3는 좋지만, R1이나 o1-Pro보다 더 낫지는 않다」

「Grok3는 좋지만, R1이나 o1-Pro보다 더 낫지는 않다」
이미지 출처: X
Grok3 발표 자료의 공식 PPT에서는 대규모 모델 경기장(Chatbot Arena)에서 '압도적 선두'를 달성했다고 하지만, 사실 이것은 약간의 그래프 꼼수를 적용한 것이다: 순위표의 세로축은 1400~1300점 구간만을 표시하여 원래 1%의 미세한 점수 차이를 마치 매우 큰 격차처럼 보이게 만든 것이다.
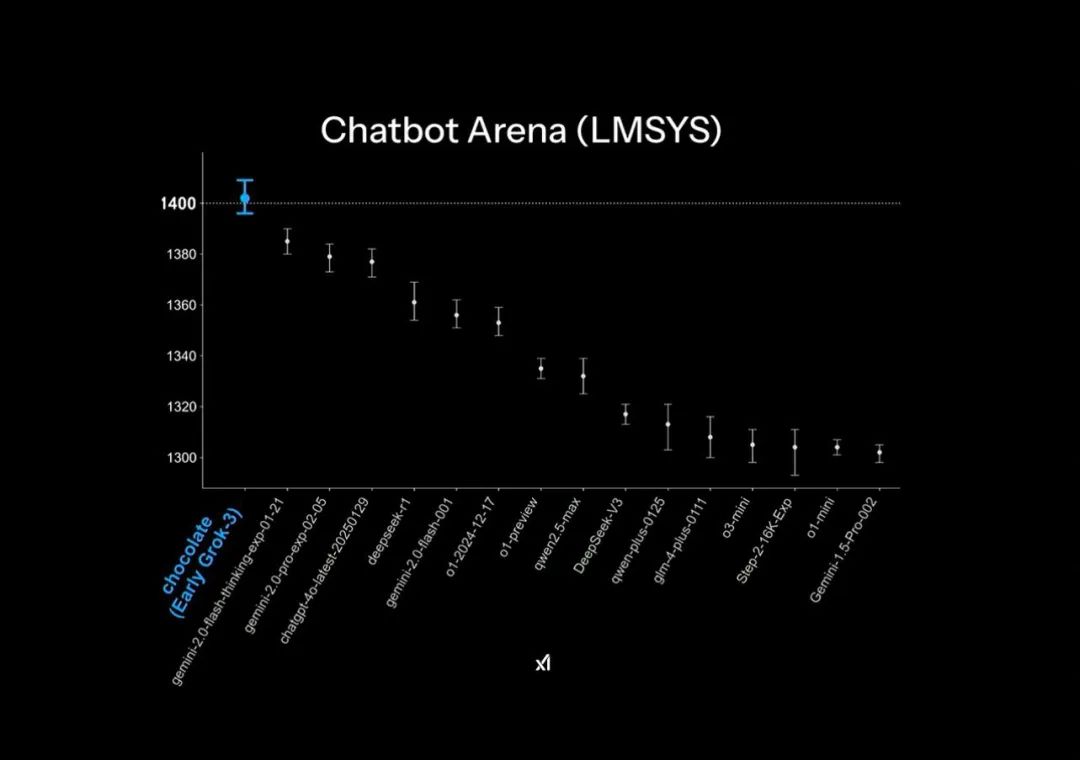
공식 발표 PPT 속 '압도적 선두' 효과
이미지 출처: X
실제 모델 점수 결과를 보면, Grok3는 DeepSeek R1과 GPT-4.0보다 겨우 1~2% 정도 높을 뿐이다. 이는 많은 사용자가 실제 테스트에서 체감하는 "별 차이 없음"과 일치한다.
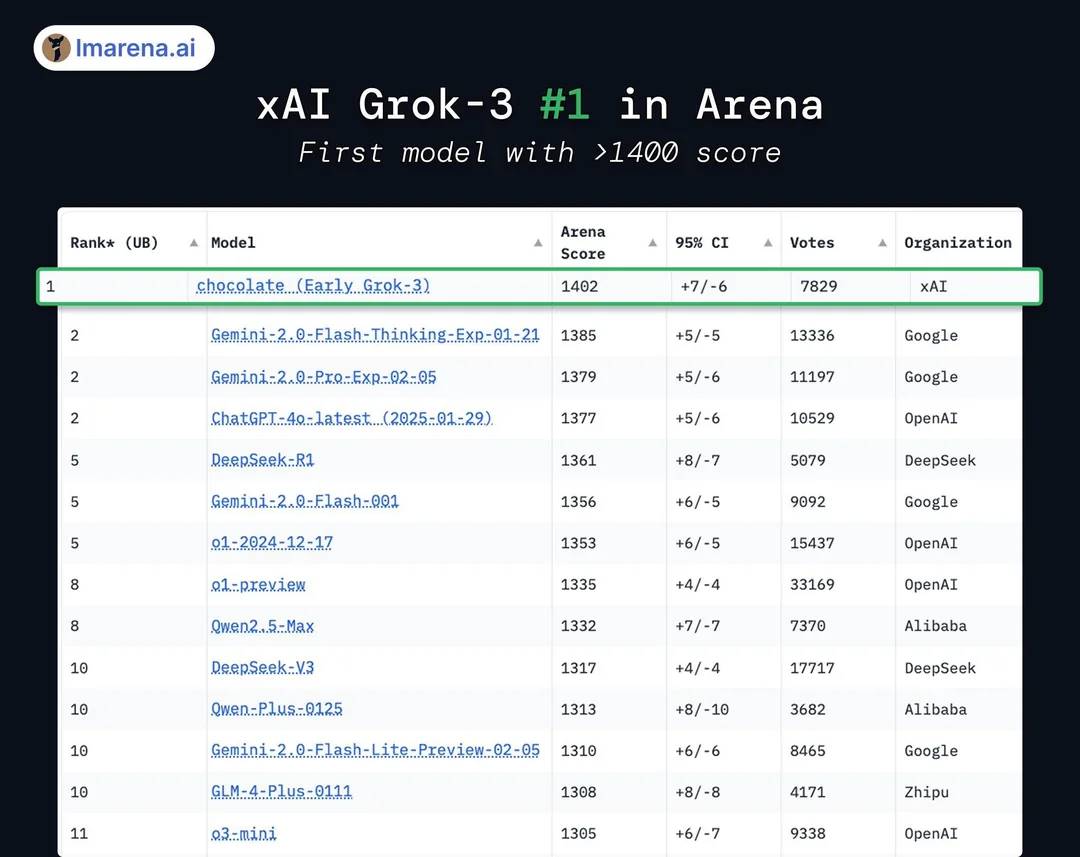
실제로 Grok3는 후발 주자보다 겨우 1~2% 높을 뿐이다
이미지 출처: X
또한 점수 면에서 Grok3가 현재 공개 테스트된 모든 모델을 초월했다고 하나, 이를 받아들이는 사람은 많지 않다. xAI는 과거 Grok2 시절부터 해당 리더보드에서 '점수 조작' 논란이 있었으며, 리더보드가 답변 길이 스타일에 대한 가중치를 낮추자 점수가 크게 하락했던 전례가 있어 업계에서는 종종 '높은 점수, 낮은 능력'이라는 비판을 받아왔다.
리더보드 '점수 조작'이든, 이미지 구성의 '작은 꼼수'든, 모두 xAI와 머스크 본인이 모델 성능에서 '압도적 선두'라는 이미지를 만들어내려는 집착을 보여주는 것이다.
그런 미세한 차이를 위해 머스크가 치른 대가는 막대하다. 발표회에서 머스크는 거의 자랑하듯 20만 장의 H100(생방송에서 '10만 장 이상'이라고 언급)을 사용해 Grok3를 학습시켰으며, 총 학습 시간이 2억 시간에 달한다고 밝혔다. 이에 일부 사람들은 GPU 산업에 또 한 번의 큰 호재가 될 것이라 생각하며, DeepSeek가 업계에 가져온 충격은 '어리석다'고 평가하기도 한다.
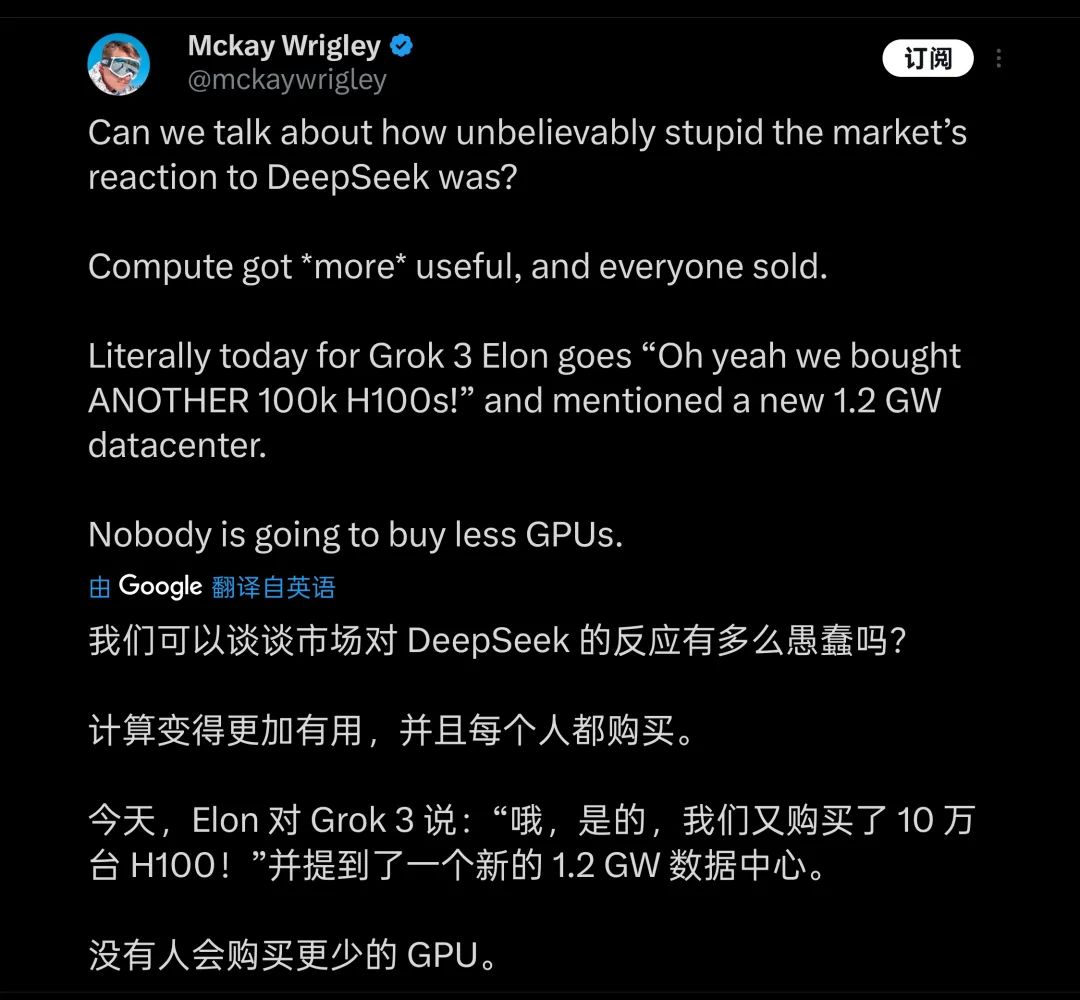
많은 이들이 컴퓨팅 파워의 집약이 앞으로 모델 학습의 미래라고 생각한다
이미지 출처: X
하지만 실제로는 네티즌들이 2000장의 H800으로 두 달간 학습시킨 DeepSeek V3와 비교해, Grok3의 실제 학습 컴퓨팅 파워 소비량이 V3보다 무려 263배에 달함을 계산해냈다. 그런데도 DeepSeek V3는 대규모 모델 경기장에서 점수 1402점을 받은 Grok3와 겨우 100점 미만의 차이밖에 나지 않는다.
이러한 데이터들이 공개된 이후, 많은 사람들은 Grok3가 '세계 최강'에 등극한 이면에서 '모델이 클수록 성능이 좋아진다'는 논리가 이미 명백한 한계 효과(marginal effect)를 드러내고 있음을 금세 깨닫게 되었다.
비록 '높은 점수, 낮은 능력'으로 평가받던 Grok2조차도 X(Twitter) 플랫폼 내부의 방대한 고품질 제1자 데이터를 기반으로 지원받았었다. 그러나 Grok3의 학습 단계에 들어서면서 xAI 역시 OpenAI가 현재 겪고 있는 것과 동일한 '한계'에 부딪히게 되었으니, 바로 고품질 학습 데이터의 부족으로 인해 모델 성능의 한계 효과가 급속도로 노출되고 있다는 점이다.
이러한 현실을 가장 먼저 인식하고 가장 깊이 이해하고 있는 것은 분명 Grok3 개발팀과 머스크本人일 것이다. 그래서 머스크는 소셜미디어를 통해 현재 사용자들이 체험하는 버전은 "아직 테스트판일 뿐이며, 완전한 버전은 향후 몇 개월 내 출시될 것"이라고 계속해서 강조하고 있다. 머스크本人更是化身为 Grok3의 제품 책임자로서, 사용자들에게 직접 댓글란에 사용 중 발생한 문제들을 피드백하도록 권유하고 있다.
그는 아마 지구상에서 팬 수가 가장 많은 제품 책임자일 것이다
이미지 출처: X
그러나 하루도 채 되지 않아 Grok3의 성능은 '힘으로 덩치 키우기' 전략을 통해 더 강력한 대형 모델을 개발하려는 후발 주자들에게 경종을 울렸다. 마이크로소프트가 공개한 정보를 기반으로 추정하면, OpenAI의 GPT-4는 약 1.8조 개의 파라미터를 가지며, GPT-3 대비 10배 이상 증가했고, 소문에 따르면 GPT-4.5의 파라미터 규모는 더욱 커질 전망이다.
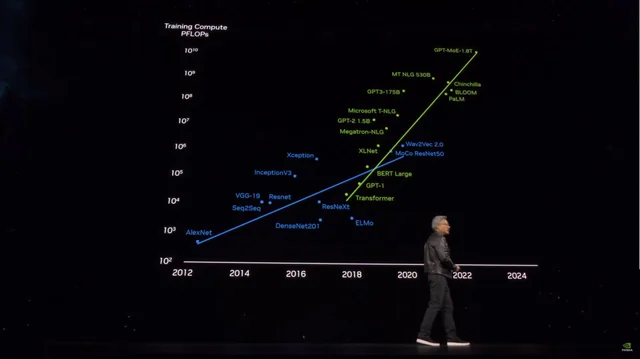
모델 파라미터 규모가 급증하면서 학습 비용도 치솟고 있다
이미지 출처: X
Grok3의 사례가 앞선 가운데, GPT-4.5를 포함해 파라미터 규모를 늘려 더 나은 성능을 얻기 위해 돈을 더 '태우려는' 플레이어들은 이제 눈앞에 다가온 천장을 어떻게 돌파할지 진지하게 고민해야 할 것이다.
이때 문득, 작년 12월 OpenAI의 전 수석 과학자였던 일야 서츠크버(Ilya Sutskever)가 "우리가 알고 있는 방식의 사전 학습(pre-training)은 끝날 것이다"라고 말했던 발언이 다시 회자되며, 사람들이 대형 모델 학습의 진정한 돌파구를 그 속에서 찾고자 하고 있다.

일야의 견해는 이미 업계에 경종을 울렸다
이미지 출처: X
당시 일야는 새로운 이용 가능한 데이터가 고갈에 가까워지고, 데이터 획득을 통한 성능 향상이 어려워질 것을 정확히 예견했으며, 이를 화석 연료 소비에 비유해 "석유가 한정된 자원인 것처럼, 인터넷 내 인간이 생성한 콘텐츠 역시 한정되어 있다"고 표현했다.
서츠크버의 예측에 따르면, 사전 학습 모델 이후 다음 세대 모델은 '진정한 자율성'을 가지게 될 것이며, 동시에 '인간의 뇌와 유사한' 추론 능력을 갖추게 될 것이다.
현재 사전 학습 모델이 주로 이전에 학습한 콘텐츠 기반의 내용 매칭(content matching)에 의존하는 것과 달리, 미래의 AI 시스템은 인간의 뇌가 '사고'하는 것과 유사한 방식으로 점진적으로 학습하며 문제 해결 방법론을 스스로 구축할 수 있게 될 것이다.
인간은 특정 학문을 기초적으로 숙달하기 위해 필요한 것은 기본 전공 서적 정도지만, AI 대형 모델은 최소한 기초 입문 수준에 도달하기 위해 수백만 건의 데이터를 학습해야 한다. 심지어 질문 방식만 바꿔도 이런 기초적인 질문조차 제대로 이해하지 못하는 경우가 많으며, 모델의 진정한 지능 수준은 전혀 향상되지 않았다. 본문 서두에서 언급한 Grok3가 여전히 올바르게 답하지 못하는 기초 문제들이 바로 이러한 현상의 직관적인 반영이다.
그러나 '힘으로 덩치 키우기' 외에도, 만약 Grok3가 정말로 업계에 '사전 학습 모델이 곧 종말을 맞이할 것'이라는 사실을 알려줄 수 있다면, 그럼에도 불구하고 업계에 중요한 시사점을 제공했다고 평가할 수 있을 것이다.
어쩌면 Grok3의 열풍이 서서히 가라앉은 후, 이페이피(Li Feifei)처럼 특정 데이터셋을 기반으로 50달러의 비용으로 고효율 모델을 파인튜닝(fine-tuning)하는 사례들이 더 많이 나타날지도 모른다. 그리고 그러한 탐색 속에서 우리는 궁극적으로 AGI(일반 인공지능)로 향하는 진정한 길을 찾아낼 수 있을 것이다.
TechFlow 공식 커뮤니티에 오신 것을 환영합니다
Telegram 구독 그룹:https://t.me/TechFlowDaily
트위터 공식 계정:https://x.com/TechFlowPost
트위터 영어 계정:https://x.com/BlockFlow_News