

챗GPT의 광둥어 발음이 '틀린 발음'을 하는 이유: AI 시대에 소수 언어는 필연적으로 소외될 운명인가?
글: 아나타 장
챗GPT가 광둥어를 말하는 것을 들어본 적 있나요?
표준중국어(보통화)를 모국어로 하는 사람이라면 축하합니다. '광둥어 능숙'이라는 업적을 단번에 달성하게 되니까요. 반면 광둥어를 구사하는 사람들에게는 오히려 혼란스러울 수 있습니다. 챗GPT의 발음은 특이한 억양을 지니고 있으며, 마치 외지인이 애써 광둥어를 말하려는 것처럼 들리기 때문입니다.
2023년 9월의 업데이트에서 챗GPT는 처음으로 음성을 '말할' 수 있게 되었으며, 2024년 5월 13일 최신 세대 모델인 GPT-4o가 발표되었습니다. 아직 새 버전의 음성 기능은 공식적으로 출시되지 않았고 데모에만 존재하지만, 지난해의 업데이트를 통해 이미 챗GPT의 다국어 음성 대화 능력을 엿볼 수 있었습니다.
그런데 많은 사람들이 알아차렸습니다. 챗GPT가 말하는 광둥어는 강한 억양을 띠고 있다는 점 말이죠. 어조는 자연스럽고 실제 사람처럼 들리지만, 그 '실제 사람'은 분명히 광둥어 원어민이 아닙니다.

이 사실을 확인하고 그 배경을 파악하기 위해 우리는 광둥어 음성 소프트웨어 비교 테스트를 진행했습니다. 평가 대상에는 챗GPT 보이스, 애플 시리(Siri), 바이두 문심일언(文心一言), 그리고 최근 인기를 끌고 있는 인공지능 음악 생성 플랫폼 선오.ai(suno.ai)가 포함됐습니다. 이 중 처음 세 개는 음성 비서이며, 선오.ai는 인공지능 음악 생성 플랫폼입니다. 모두 프롬프트에 따라 광둥어 또는 유사한 형태로 응답을 생성할 수 있는 능력을 갖추고 있습니다.
어휘 발음 측면에서 시리와 문심일언은 정확한 발음을 보여주지만, 답변은 다소 기계적이고 딱딱합니다. 나머지 두 제품은 각각 정도의 차이는 있지만 발음 오류를 보입니다. 특히 자주 나타나는 오류는 표준중국어의 발음 방식을 적용하는 것입니다. 예를 들어, '영(影)'은 광둥어로 '징(jing2)'이어야 하지만 '잉(ying)'으로 발음됩니다. '량징징(亮晶晶)'은 '징(zing1)'이 되어야 하지만 '징(jing)'이라고 읽습니다.
'고루다샤(高樓大廈)'의 '고(高)'는 챗GPT에 의해 '가오(gao)'로 발음되지만 실제로는 광둥어 철자법으로 '구(gou1)'입니다. 현지 출신의 광둥인 프랭크(Frank)도 이 문제를 지적하며, 이는 비모국어 화자들 사이에서 흔히 발생하는 발음 실수라고 말했습니다. 또한 이 발음은 성기를 의미하는 광둥어 욕설과 동일하여 지역 주민들 사이에서도 종종 농담거리가 됩니다. 챗GPT의 발음은 매번 조금씩 다르며, '샤(厦)'는 가끔 올바른 '하(haa6)'로 발음되기도 하지만 때로는 광둥어에 존재하지 않는 '샤(xia)'처럼 중국어에 가까운 발음으로 잘못 읽히기도 합니다.
문법적으로 보면 생성된 텍스트는 명백히 서면체에 더 가깝고 가끔 구어체 표현이 섞입니다. 단어 선택과 문장 구성에서도 갑자기 표준중국어 패턴으로 전환되는 경우가 많으며, "물건 사기(买东西)"(광둥어: 물건 살 거(maaih yeh))나 "광둥어로 홍콩 소개해줄게(用粤语来给你介绍一下香港啦)"(광둥어: 광둥어로 너한테 홍콩 소개해줄게(用粤语同你介绍下香港啦)) 등 광둥어 관용 표현과 맞지 않는 문장을 내뱉는 경우가 있습니다.
선오.ai는 광둥어 랩 가사를 만들 때 "거리의 누구도 따라할 수 없어, 홍콩의 특색은 진짜 멋지고 아름다워(街坊边个仿得到,香港嘅特色真正靓妙)" 같은 의미가 불분명한 가사를 만들어냅니다. 우리는 이 문장을 챗GPT에 평가해달라고 요청했고, 그 결과 "이 문장은 중국어의 직역 같거나 중국어와 광둥어 문법이 섞인 것 같다"는 답을 받았습니다.

비교를 위해 우리가 표준중국어 사용을 시도했을 때 이러한 오류는 거의 나타나지 않았다는 점도 발견했습니다. 물론 광둥어라도 광저우, 홍콩, 마카오 지역마다 다른 억양과 어휘 차이가 있습니다. 광둥어의 '표준'으로 여겨지는 샤관음(西關音)과 홍콩에서 일반적으로 사용되는 광둥어 백화(廣東白話)는 매우 다릅니다. 그러나 챗GPT의 광둥어는 최대한 좋게 봐도 '응 아니, 아니'('음 아닌 듯, 양 아닌 듯', 미숙함을 의미)한 표준중국어 모국어 화자가 가질 법한 억양에 불과합니다.
이게 도대체 무슨 일일까요? 챗GPT는 광둥어를 모르는 걸까요? 하지만 지원하지 않는다고 직접 밝히지도 않고, 오히려 상상을 펼쳐내는데, 이 상상은 명백히 더 우세하고 공식적인 언어 위에 세워져 있습니다. 이것이 문제가 될 수 있을까요?
언어학자이자 인류학자인 사피어(Edward Sapir)는 구어가 인간이 세상과 상호작용하는 방식에 영향을 준다고 주장했습니다. 인공지능 시대에 어떤 언어가 제 목소리를 내지 못한다면, 그것은 무엇을 의미할까요? 광둥어의 모습에 대해 우리는 점점 AI와 같은 상상을 공유하게 될까요?
자원이 없는 언어
OpenAI가 공개한 정보를 살펴보면, 작년에 출시된 챗GPT의 음성 모드가 보여주는 대화 능력은 사실 세 가지 주요 부분으로 구성됩니다. 먼저 오픈소스 음성 인식 시스템 Whisper가 구어를 텍스트로 변환하고, 그 다음 챗GPT 텍스트 대화 모델이 답변을 생성하며, 마지막으로 텍스트-음성 변환 모델(TTS, Text-To-Speech)이 오디오를 생성하고 발음 방식을 미세 조정합니다.
즉, 대화 내용은 여전히 챗GPT3.5 본체가 생성하며, 그 학습 데이터는 웹 상에 존재하는 방대한 텍스트 기반 자료이지 음성 자료가 아닙니다.
이 점에서 광둥어는 명백한 열세를 가지고 있습니다. 왜냐하면 광둥어는 말보다 글로 기록되는 일이 극히 적기 때문입니다. 공식적으로 광둥어권에서 사용하는 서면어는 북방 한어에서 유래한 표준 중국어 서면어이며, 이는 광둥어보다 표준중국어에 훨씬 가깝습니다. 반면 광둥어 구어의 문법과 어휘 습관에 부합하는 광둥어 서면어(또는 광둥문)는 주로 인터넷 포럼과 같은 비공식적인 자리에서만 사용됩니다.
이러한 사용은 종종 통일된 규칙을 따르지 않습니다. "광둥어 글자 중 약 30%는 제가 어떻게 써야 할지 잘 모릅니다." 프랭크는 이렇게 말하며, 사람들이 채팅할 때 모르는 글자를 만나면 중국어 병음 키보드에서 발음이 비슷한 글자를 골라 입력하는 경우가 많다고 설명합니다. 예를 들어 광둥어 '란잉니시(乱噏廿四; 즉, 헛소리)'는 종종 '란업니시(乱 up 廿四)'로 쓰입니다. 서로 이해는 대부분 가능하지만, 이로 인해 기존의 광둥어 텍스트는 더욱 혼란스럽고 일관성이 떨어집니다.
대규모 언어 모델(Large Language Model)의 등장은 훈련 데이터가 인공지능의 성능과 잠재적 편향에 얼마나 중요한지를 각인시켰습니다. 그러나 실제로 생성형 AI가 등장하기 전부터 다양한 언어 간 데이터 자원 격차는 이미 커다란 갭을 형성해왔습니다. 대부분의 자연어 처리 시스템은 고자원 언어(high-resource language)를 중심으로 설계되고 테스트됩니다. 전 세계 활성 언어 중 단 20개만이 '고자원 언어'로 여겨지며, 여기에는 영어, 스페인어, 중국어, 프랑스어, 독일어, 아랍어, 일본어, 한국어 등이 포함됩니다.
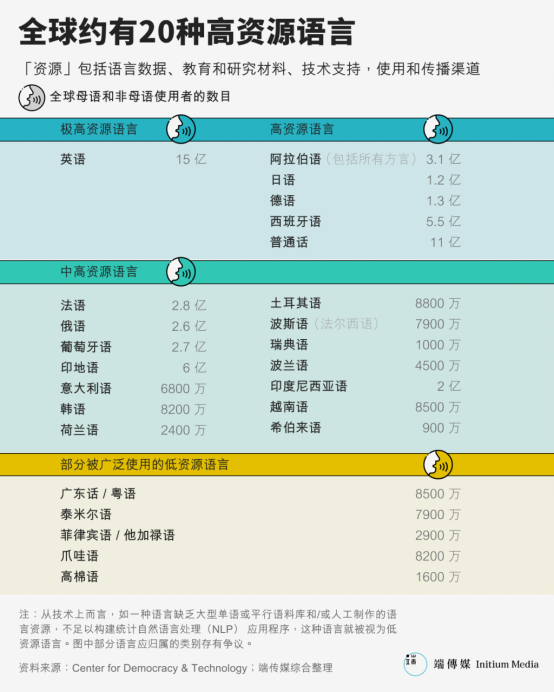
약 8500만 명의 사용자를 가진 광둥어는 자연어 처리(NLP) 분야에서 종종 저자원 언어(low-resource language)로 간주됩니다. 딥러닝의 출발점인 위키백과의 경우, 영문판을 압축하면 15.6GB, 번체·간체 혼합판은 1.7GB인데 비해 광둥어판은 겨우 52MB에 불과합니다. 무려 33배 가까운 차이입니다.
마찬가지로 가장 큰 공개 음성 데이터셋 중 하나인 Common Voice에서는 중국어(중국) 음성 데이터가 1232시간, 중국어(홍콩)은 141시간, 광둥어(Cantonese)는 198시간입니다.
자료 부족은 기계의 자연어 처리 성능에 깊은 영향을 미칩니다. 2018년의 한 연구에 따르면 평행 문장(corpus)이 13K 미만일 경우 기계 번역은 합리적인 결과를 낼 수 없습니다. 이는 기계의 '청취' 능력에도 영향을 줍니다. 챗GPT 보이스가 사용하는 오픈소스 Whisper 음성 인식 모델(V2 버전)의 성능 테스트에서 광둥어의 문자 오류율은 표준중국어보다 눈에 띄게 높았습니다.
모델의 텍스트 출력은 광둥어 자료의 부족을 보여주지만, 우리 귀에 들리는 발음과 억양의 오류는 어떻게 생기는 것일까요?
기계는 어떻게 말을 배우는가?
인간은 이미 17세기부터 기계에게 말하게 하려는 시도를 해왔습니다. 초기에는 오르간이나 풍상(풍상) 등을 이용해 공기를 인공 흉강, 성대, 입구 구조로 펌프하는 기계적 방법이 사용되었습니다. 이후 발명가 요셉 파버(Joseph Faber)가 이를 채택해 터키식 의상을 입은 말하는 인형을 만들었습니다. 하지만 당시 사람들은 이것이 무엇인지 이해하지 못했습니다.
가전제품이 보급되면서 기계에게 말하게 하려는 아이디어에 더 많은 관심이 쏠리게 됩니다.
대부분的人来说,用编码交流并不自然,也有相当一部分残障人群因此被隔绝在技术之外。

1939년 세계 박람회에서 벨 연구소의 엔지니어 홈어 덜리(Homer Dudley)가 개발한 음성 합성기 Voder는 인간에게 최초의 '기계의 목소리'를 들려주었습니다. 오늘날 머신러닝의 '신비로움'과 비교하면 Voder의 원리는 단순하고 명확했으며, 관객들도 직접 볼 수 있었습니다. 한 여성 조작원이 장난감 피아노 같은 기계 앞에 앉아 숙련된 손놀림으로 10개의 버튼을 조작해 성대 마찰음에 가까운 발음을 만들어냈습니다. 조작원은 페달을 밟아 음높이를 조절해 더 경쾌하거나 더 무거운 어조를 연출할 수도 있었습니다. 옆에서는 사회자가 계속해서 관객들에게 새로운 단어를 요청하며 Voder의 음성이 미리 녹음된 것이 아님을 증명했습니다.
당시의 녹음에 대해 <뉴욕 타임스>는 Voder의 목소리를 '심해에서 들려오는 외계인의 인사' 또는 '술에 취해 뇌까대는 사람처럼 알아듣기 어렵다'고 평가했습니다. 하지만 당시로서는 충분히 놀라운 기술이었으며, 이 박람회 기간 동안 Voder는 전 세계 500만 명 이상의 방문객을 끌어모았습니다.
초기 스마트 로봇이나 외계 생명체의 음성 상상은 이러한 장치에서 많은 영감을 얻었습니다. 1961년 벨 연구소의 과학자들은 IBM 7094 컴퓨터가 18세기 영국 민요 'Daisy Bell'을 부르게 만들었습니다. 이는 알려진 바로는 컴퓨터로 합성된 목소리로 노래한 최초의 사례입니다. <2001: 스페이스 오딧세이>의 작가 클라크(Arthur C. Clarke)는 벨 연구소를 방문해 IBM 7094가 Daisy Bell을 부르는 것을 들었고, 이 소설에 등장하는 초지능 컴퓨터 HAL 9000이 처음 배운 노래 역시 이 곡이 되었습니다. 영화에서는 초기화되는 HAL 9000의 의식이 혼란스러워지며 'Daisy Bell'을 읊조리기 시작하고, 생동감 있고 인간적인 목소리가 점차 기계의 신음 소리로 퇴화됩니다.
이후 음성 합성 기술은 수십 년에 걸쳐 진화했습니다. AI 시대의 뉴럴 네트워크 기술이 성숙하기 전까지는 연결합성(concatenative synthesis)과 공명봉합성(formant synthesis)이 가장 흔한 방법이었습니다. 실제로 오늘날 흔히 사용되는 많은 음성 기능도 여전히 이 두 가지 방식으로 이루어집니다. 예를 들어 화면 리더(Screen Reader). 특히 공명봉합성은 초기에 주도적인 위치를 차지했습니다. 그 발성 원리는 Voder와 매우 유사하며, 기본 주파수, 청음, 탁음 등의 매개변수를 제어해 무한한 음성을 생성합니다. 이는 큰 장점을 제공합니다. 즉, 어떤 언어라도 생성할 수 있다는 점입니다. 실제로 1939년 Voder는 이미 프랑스어를 말할 수 있었습니다.
물론 광둥어도 마찬가지입니다. 2006년 중산대학에서 컴퓨터 소프트웨어 이론 석사를 공부하던 광저우 출신 황관능(黃冠能)은 졸업 논문 주제를 정하면서 시각장애인을 위한 리눅스 브라우저를 개발하는 것을 생각했습니다. 이 과정에서 그는 eSpeak이라는 공명봉합성 방식의 오픈소스 음성 합성기를 접하게 됩니다. 언어적 장점 덕분에 eSpeak은 출시 후 빠르게 실제 응용에 활용되었으며, 2010년 구글 번역이 중국어, 핀란드어, 인도네시아어 등 다수 언어에 읽어주기 기능을 추가할 때도 eSpeak을 사용했습니다.

2015년 11월 24일 중국 베이징, 기계 팔이 붓으로 한자를 쓰고 있다.
황관능은 자신의 모국어인 광둥어를 eSpeak에 추가하기로 결정했습니다. 하지만 원리의 한계로 인해 eSpeak이 합성한 발성은 명백한 이음새를 드러냈습니다. "중국어를 배울 때 병음이 아니라 영어 발음 기호로 읽는 것과 같습니다. 효과는 마치 외국인이 중국어를 배우는 것처럼 느껴집니다." 황관능은 이렇게 말했습니다.
그래서 그는 Ekho TTS를 만들었습니다. 현재 이 음성 합성기는 광둥어, 표준중국어는 물론 조안객가화(诏安客語), 티베트어, 아언(雅言), 광둥 타이산화(台山話) 등 더 소수 언어까지 지원합니다. Ekho는 연결합성(concatenative synthesis) 방식을 사용하는데, 쉽게 말해 '붙이기(paste)'입니다. 인간의 발음을 미리 녹음해두고, '말할 때' 이것들을 붙여 만듭니다. 이렇게 하면 단어 발음이 더 정확해지고, 자주 사용하는 어휘가 전체적으로 녹음되어 있으면 듣는 느낌도 더 자연스러워집니다. 황관능은 5005개 음절로 구성된 광둥어 발음표를 정리했고, 처음부터 끝까지 녹음하는 데 2~3시간이 걸립니다.
딥러닝의 등장은 이 분야에 혁명을 가져왔습니다. 딥러닝 알고리즘 기반의 음성 합성은 사전에 정의된 언어 규칙이나 미리 녹음된 음성 단위에 의존하지 않고, 대규모 음성 말뭉치(corpus)에서 텍스트와 음성 특징 간의 맵핑을 학습합니다. 이 기술은 기계 음성의 자연스러움을 크게 향상시켜 이제는 종종 실제 사람과 구별이 어려울 정도이며, 심지어 몇 초의 음성만으로도一个人의 음색과 말투를 복제할 수 있습니다. 챗GPT의 TTS 모듈도 이러한 기술을 사용합니다.
공명봉합성과 연결합성 기술에 비해 이런 시스템은 음성 합성에 필요한 초기 인력 비용을 크게 줄였지만, 동시에 텍스트와 음성이 정렬된 자료에 대한 요구는 훨씬 더 높아졌습니다. 예를 들어 구글이 2017년에 발표한 엔드-투-엔드(end-to-end) 모델 Tacotron은 좋은 음질을 얻기 위해 10시간 이상의 훈련 데이터가 필요합니다.
많은 언어의 자원 부족을 고려해 최근 연구자들은 전이 학습(transfer learning) 방법을 제안했습니다. 먼저 고자원 언어의 데이터셋으로 일반 모델을 훈련한 후, 이 규칙을 저자원 언어 합성에 전이시키는 방식입니다. 어느 정도까지는 이러한 전이된 규칙은 여전히 원래 데이터셋의 특성을 지니고 있습니다. 마치 제1모국어 화자가 새로운 언어를 배울 때 자신의 모국어 언어 지식을 끌어들이는 것과 같습니다. 2019년 Tacotron 팀은 서로 다른 언어 사이에서 동일 화자의 음성을 복제할 수 있는 모델을 제안하기도 했습니다. 데모에서 영어 모국어 화자가 중국어를 말할 때 발음은 표준적이었지만, 매우 뚜렷한 '외국인 억양'을 지녔습니다.
<남화조보>의 한 논평은 홍콩인이 표준중국어로 글을 쓸 때 모든 중국어 사용자가 자신의 뜻을 이해하도록 하기 위해 현대 표준중국어의 'ta men(他们)'을 사용해야 한다고 지적했습니다. 'ta men'의 광둥어 철자는 'taa1 mun4'이며, 이는 광둥어 회화에서 거의 사용되지 않는 단어입니다. 광둥어에서 '그들'을 의미하는 것은 발음과 표기 모두 완전히 다른 'keoi5 dei6(佢哋)'입니다.
범용적인 해결책이 일반적인 문제를 처리한다는 점에서 최신 GPT-4o 모델은 이를 더욱 극단적으로 밀어붙입니다. OpenAI는 텍스트, 시각, 오디오를 모두 통합해 단일 신경망으로 모든 입력과 출력을 처리하는 엔드-투-엔드 모델을 훈련했다고 설명합니다. 이 모델이 다양한 언어를 어떻게 처리하는지는 아직 명확하지 않지만, 과거보다 훨씬 더 강력한 작업 간 범용성을 지닌 것으로 보입니다.
하지만 광둥어와 표준중국어 사이의 상호 운용성은 때때로 문제를 더 복잡하게 만들기도 합니다.
언어학에서는 '이중 언어' 또는 '언어 계층(diglossia)'이라는 개념이 있습니다. 특정 사회에서 밀접하게 연결된 두 가지 언어가 존재하는데, 하나는 더 높은 권위를 지니고 정부에서 사용되며, 다른 하나는 방언으로 구어로 사용되거나 백화(白話)라고 불립니다.
중국의 맥락에서 표준중국어는 공식적인 글쓰기, 뉴스 방송, 학교 교육, 정부 업무에 사용되는 최상위 언어입니다. 반면 광둥어, 민난어(대만어), 상하이어 등의 지역 방언은 하위 언어로, 주로 가정과 지역 공동체의 일상적인 구어 교류에 사용됩니다.
따라서 광둥성, 홍콩, 마카오에서는 대부분의 사람들이 일상적인 구어로 광둥어를 사용하지만, 공식적인 서면 언어는 일반적으로 표준중국어의 서면 표준어를 사용하는 현상이 발생합니다.
이 두 언어 사이에는 비슷하지만 실제로는 다른 점이 많으며, 'ta men'과 'keoi5 dei6'처럼 일치하지 않는 많은 '불협화음'이 존재합니다. 이는 표준중국어에서 광둥어로의 전이를 더욱 어렵고 오해를 불러일으킬 수 있습니다.
점점 더 주변화되는 광둥어
「광둥어 미래에 대한 걱정은 결코 터무니없는 것이 아니다. 언어의 쇠퇴는 매우 빠르게 일어날 수 있으며, 한두 세대 안에 사라질 수 있다. 일단 언어가 쇠퇴의 길로 접어들면 되살리기 어렵다.」제임스 그리피스, 『표준어를 말하라』
이제까지 살펴본 바에 따르면, 음성 합성에서 광둥어의 부진한 성능은 기술이 저자원 언어를 처리하는 데서 오는 한계 때문으로 보입니다. 딥러닝 알고리즘을 채택한 모델은 낯선 단어를 접할 때 음성 환각을 만들어냅니다. 하지만 홍콩 중문대학 전자공학과 교수 탄 리(Tan Lee)는 챗GPT의 음성 성능을 듣고 다른 의견을 제시합니다.
TechFlow 공식 커뮤니티에 오신 것을 환영합니다
Telegram 구독 그룹:https://t.me/TechFlowDaily
트위터 공식 계정:https://x.com/TechFlowPost
트위터 영어 계정:https://x.com/BlockFlow_News










