

Sora의 컴퓨팅 파워 수학 문제
글: Matthias Plappert
번역: Siqi, Lavida, Tianyi
지난달 비디오 생성 모델 Sora를 출시한 OpenAI는 어제 또 다시 Sora를 활용해 창의적인 작업을 한 크리에이터들의 작품들을 공개하며 놀라운 효과를 보여주었다. 생성 품질 측면에서 Sora는 지금까지 나온 비디오 생성 모델 중 가장 강력하다고 단언할 수 있으며, 이는 창작 산업에 직접적인 충격을 줄 뿐 아니라 로봇공학 및 자율주행 분야의 핵심 문제 해결에도 영향을 미칠 것이다.
OpenAI는 Sora의 기술 보고서를 발표했지만, 기술 세부 사항은 극히 제한적이며 본문은 Factorial Fund의 Matthias Plappert가 작성한 리서치를 번역한 것이다. Matthias는 과거 OpenAI에서 근무하며 Codex 프로젝트에 참여한 바 있으며, 이 연구에서는 Sora의 핵심 기술적 세부사항과 혁신점, 그리고 그로 인한 주요 영향을 다루고 있다. 또한 Sora와 같은 비디오 생성 모델이 요구하는 컴퓨팅 파워에 대해서도 분석하고 있다. Matthias는 비디오 생성 기술의 활용이 점점 더 확대됨에 따라 추론(inference) 단계의 계산 수요가 훈련 단계를 급속히 초과할 것이라고 주장하며, 특히 diffusion 기반 모델인 Sora의 경우 더욱 그러하다고 강조한다.
Matthias의 추정에 따르면, Sora의 훈련 과정에서 필요한 컴퓨팅 자원은 대규모 언어 모델(LLM)보다 몇 배 이상 많으며, 약 4,200~10,500장의 Nvidia H100 GPU를 한 달간 사용해야 한다. 또한 모델이 1,530만~3,810만 분의 비디오를 생성한 후에는 추론 단계의 컴퓨팅 비용이 훈련 단계를 빠르게 넘어설 것으로 예상된다. 참고로 현재 매일 TikTok에 업로드되는 비디오는 약 1,700만 분이며 YouTube는 약 4,300만 분이다. 최근 OpenAI CTO인 Mira 역시 인터뷰를 통해 비디오 생성의 비용 문제가 Sora를 아직 일반에게 공개하지 못하는 이유라고 밝혔으며, DALL·E 수준의 이미지 생성 비용에 도달해야 공개를 고려하겠다고 말했다.
최근 OpenAI가 발표한 Sora는 매우 사실적인 비디오 장면 생성 능력으로 세계를 놀라게 했다. 본 글에서는 Sora의 기술적 세부사항, 이러한 비디오 모델의 잠재적 영향력, 그리고 우리가 가진 몇 가지 통찰을 깊이 있게 논의할 것이다. 마지막으로 Sora와 같은 모델을 훈련시키는 데 필요한 컴퓨팅 자원을 추정하고, 추론과 비교한 훈련 컴퓨팅 수요를 전망함으로써 미래 GPU 수요 예측에 중요한 시사점을 제공하고자 한다.
핵심 요약
본 보고서의 핵심 결론은 다음과 같다:
-
Sora는 DiT와 Latent Diffusion 기반의 diffusion 모델이며, 모델 규모와 훈련 데이터셋 모두 스케일링(scaling)을 적용하였다;
-
Sora는 비디오 모델에서도 scale up의 중요성을 입증하였으며, 지속적인 스케일링이 모델 성능 향상의 주요 동력이 될 것임을 보여준다. 이는 LLM과 유사하다;
-
Runway, Genmo, Pika 등의 기업들은 Sora와 같은 diffusion 기반 비디오 생성 모델 위에 직관적인 인터페이스와 워크플로우를 구축하려는 노력을 진행 중이며, 이는 모델의 보급성과 사용 편의성을 결정짓는 핵심 요소가 될 것이다;
-
Sora의 훈련은 막대한 컴퓨팅 규모를 요구하며, 우리는 약 4,200~10,500장의 Nvidia H100을 1개월간 사용해야 한다고 추정한다;
-
추론 단계에서는 각 H100당 시간당 최대 약 5분 정도의 비디오를 생성할 수 있을 것으로 예상되며, Sora와 같은 diffusion 기반 모델의 추론 비용은 LLM보다 여러 수준 이상 높다;
-
Sora와 같은 비디오 생성 모델이 널리 보급됨에 따라 추론 단계의 컴퓨팅 소비량이 훈련을 넘어설 것이며, 그 전환점은 1,530만~3,810만 분의 비디오 생성 후에 도달한다. 이 시점에서 추론에 소요된 컴퓨팅량이 원래 훈련량을 초과하게 된다. 참고로 매일 TikTok에 업로드되는 비디오는 1,700만 분이며 YouTube는 4,300만 분이다;
-
가정: AI가 이미 비디오 플랫폼에서 충분히 활용되고 있으며, TikTok의 50%, YouTube의 15% 비디오가 AI로 생성되었다고 가정할 때, 하드웨어 사용 효율과 방식을 고려하면 피크 수요 상황에서 추론에 약 72만 장의 Nvidia H100이 필요할 것으로 추정된다.
결론적으로 Sora는 비디오 생성 품질과 기능의 중대한 발전을 의미할 뿐 아니라, 미래에 추론 단계에서 GPU 수요가 크게 증가할 것임을 예고하고 있다.
01. 배경
Sora는 diffusion 모델이며, diffusion 모델은 이미지 생성 분야에서 널리 사용된다. 예를 들어 OpenAI의 DALL-E나 Stability AI의 Stable Diffusion 등 대표적인 이미지 생성 모델은 모두 diffusion 기반이며, 최근 비디오 생성을 탐색하는 Runway, Genmo, Pika 등의 기업들도 대부분 diffusion 모델을 사용하고 있다.
일반적으로 생성 모델로서 diffusion 모델은 데이터에 무작위 노이즈를 점진적으로 추가하는 과정을 역으로 학습함으로써, 훈련 데이터(예: 이미지 또는 비디오)와 유사한 새로운 데이터를 생성하는 능력을 습득한다. 이 모델은 완전한 노이즈 상태에서 시작하여 점차 노이즈를 제거하고 패턴을 세밀하게 다듬어 일관되고 정교한 출력물을 만들어낸다.

확산 과정의 개념도:
노이즈가 점차 제거되며 상세한 비디오 콘텐츠가 나타남
출처: Sora 기술 보고서
이 과정은 LLM의 작동 방식과 명백히 다르다. LLM은 하나의 토큰을 생성한 후 다음 토큰을 순차적으로 생성하는 반복적인 과정(자기회귀 샘플링, autoregressive sampling)을 따른다. 한 번 생성된 토큰은 변경되지 않으며, Perplexity나 ChatGPT와 같은 도구를 사용할 때 이를 확인할 수 있다. 답변이 마치 누군가 타이핑하듯 한 글자씩 나타나는 방식이다.
02. Sora의 기술적 세부사항
Sora를 발표하면서 OpenAI는 기술 보고서도 함께 공개했지만, 세부 정보는 거의 제공하지 않았다. 다만 Sora의 설계는 'Scalable Diffusion Models with Transformers'라는 논문의 영향을 크게 받은 것으로 보인다. 이 논문에서는 두 저자가 이미지 생성을 위한 Transformer 기반 아키텍처인 DiT를 제안했는데, Sora는 이 연구를 비디오 생성 분야로 확장한 것으로 보인다. Sora의 기술 보고서와 DiT 논문을 종합하면, Sora의 전체 구조를 어느 정도 정확히 파악할 수 있다.
Sora에 관한 세 가지 중요한 정보:
1. Sora는 픽셀 공간(pixel space)에서 작업하지 않고, latent space(잠재 공간, 즉 latent diffusion)에서 확산을 수행한다;
2. Sora는 Transformer 아키텍처를 채택했다;
3. Sora는 매우 대규모의 데이터셋을 사용한 것으로 보인다.
세부사항 1: Latent Diffusion
latent diffusion을 이해하기 위해 먼저 이미지 생성 과정을 생각해보자. 모든 픽셀을 diffusion 방식으로 생성할 수 있지만, 이는 매우 비효율적이다. 예를 들어 512x512 해상도의 이미지는 262,144개의 픽셀을 포함한다. 그러나 대신 픽셀을 압축된 잠재 표현(latent representation)으로 변환한 후, 이 작은 데이터 양의 latent space에서 확산을 수행하고, 마지막에 결과를 다시 픽셀로 복원하는 방법을 선택할 수 있다. 이 변환 과정은 계산 복잡도를 크게 낮춘다. 이제 262,144개의 픽셀을 처리할 필요 없이 64x64=4,096개의 latent representation만 처리하면 된다. 이것이 High-Resolution Image Synthesis with Latent Diffusion Models의 핵심 돌파구이며, Stable Diffusion의 기초이기도 하다.

좌측 이미지의 픽셀을 우측 격자로 표현된 잠재 표현으로 매핑
출처: Sora 기술 보고서
DiT와 Sora 모두 latent diffusion을 사용한다. Sora의 경우 추가적으로 고려해야 할 점은 비디오가 시간 차원을 갖는다는 것이다. 비디오는 연속된 이미지 프레임의 시퀀스이며, 이는 시간 축을 의미한다. Sora의 기술 보고서에 따르면, 픽셀에서 latent space로의 인코딩은 공간 차원(각 프레임의 너비와 높이 압축)뿐 아니라 시간 차원(시간 경과에 따른 압축)에서도 동시에 발생한다.
세부사항 2: Transformer 아키텍처
두 번째 사항으로, DiT와 Sora는 일반적으로 사용되는 U-Net 아키텍처 대신 기본적인 Transformer 아키텍처를 채택했다. 이는 매우 중요한데, DiT의 저자들은 Transformer를 사용하면 예측 가능한 스케일링(scaling)이 가능하다는 것을 발견했기 때문이다. 즉, 모델 훈련 시간이나 모델 규모가 증가함에 따라 모델 성능이 일관되게 향상된다. Sora의 기술 보고서에서도 비디오 생성 맥락에서 동일한 관점을 언급하며 직관적인 그래프를 제공하고 있다.

훈련 컴퓨팅량 증가에 따라 모델 품질 향상: 좌에서 우로 기본, 4배, 32배 컴퓨팅량
이러한 스케일링 특성은 우리가 잘 아는 scaling law로 정량화할 수 있으며, 이는 중요한 속성이다. 비디오 생성 이전에도 LLM 또는 다른 모달리티의 autoregressive 모델에서 scaling law는 광범위하게 연구되어왔다. 스케일링을 통해 더 나은 모델을 만들 수 있다는 것은 LLM이 급속히 발전하는 데 핵심적인 동력이 되었다. 이미지 및 비디오 생성에서도 스케일링 속성이 존재하므로, 이 영역에서도 scaling law가 적용될 것으로 기대할 수 있다.
세부사항 3: 데이터셋
Sora와 같은 모델을 훈련하기 위해 마지막으로 고려해야 할 핵심 요소는 라벨링된 데이터이다. 우리는 데이터 부분이 Sora의 대부분의 비밀을 담고 있다고 생각한다. Sora처럼 text-to-video 모델을 훈련하려면 비디오와 해당 텍스트 설명이 쌍을 이루는 데이터가 필요하다. OpenAI는 데이터셋에 대해 자세히 설명하지 않았지만, 매우 대규모임을 암시하고 있다. 기술 보고서에서 OpenAI는 "인터넷 수준의 데이터에서 훈련함으로써 LLM이 범용 능력을 획득한 것에서 영감을 얻었다"고 언급했다.

출처: Sora 기술 보고서
OpenAI는 이미지를 상세한 텍스트 라벨로 주석 달기 위한 방법도 공개했는데, 이 방법은 DALL·E-3 데이터셋 수집에 사용되었다. 간단히 말해, 라벨이 붙은 데이터의 일부에 대해 주석 모델(captioner model)을 훈련한 후, 이 모델을 사용해 나머지 데이터에 자동으로 라벨을 부착하는 방식이다. Sora의 데이터셋도 유사한 기술을 사용했을 가능성이 높다.
03. Sora의 영향
비디오 모델의 실제 적용 시작
세부 묘사와 시간적 일관성 측면에서 Sora가 생성하는 비디오의 품질은 분명히 중요한 돌파구이며, 예를 들어 물체가 일시적으로 가려져도 위치를 유지하는 것을 정확히 처리하거나 수면의 반사 효과를 정확히 재현할 수 있다. 우리는 Sora의 현재 비디오 품질이 특정 유형의 장면에 대해 이미 충분히 좋다고 믿으며, 현실 세계의 응용(예: 비디오 스톡 라이브러리 수요 감소)에 사용될 수 있을 것이다.
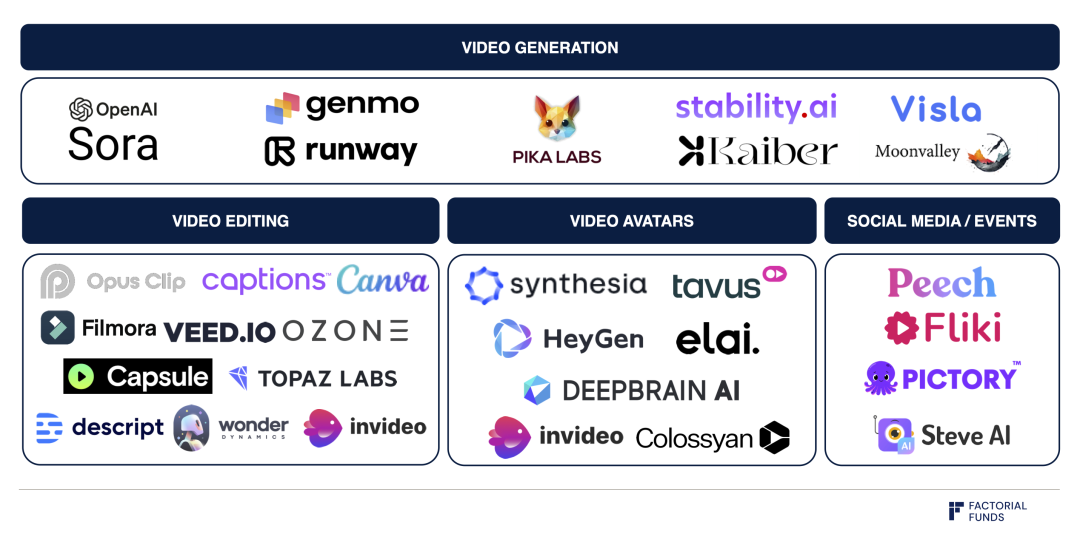
비디오 생성 분야의 생태계 지도
그러나 Sora는 여전히 몇 가지 과제를 안고 있다. 현재로서는 Sora의 조절 가능성(controlability)이 어떻게 되는지 불분명하다. 모델 출력이 픽셀 단위이기 때문에 생성된 비디오 내용을 수정하는 것은 매우 어렵고 시간이 오래 걸린다. 모델을 유용하게 만들기 위해서는 비디오 생성 모델 위에 직관적인 UI와 워크플로우를 구축하는 것이 필수적이다. 위의 지도에서 보듯, Runway, Genmo, Pika 등 비디오 생성 기업들이 이미 이러한 문제 해결에 나서고 있다.
스케일링 덕분에 비디오 생성 기대를 앞당길 수 있다
앞서 언급했듯이, DiT 연구의 핵심 결론 중 하나는 컴퓨팅량 증가에 따라 모델 품질이 직접적으로 향상된다는 점이다. 이는 우리가 LLM에서 관찰한 scaling law와 매우 유사하다. 따라서 더 많은 컴퓨팅 자원으로 훈련됨에 따라 비디오 생성 모델의 품질이 빠르게 향상될 것으로 기대할 수 있다. Sora는 이를 강력하게 검증했으며, OpenAI와 다른 기업들이 이 분야에 더욱 집중할 것으로 예상된다.
합성 데이터 생성 및 데이터 증강
로봇공학 및 자율주행 분야에서는 데이터 자체가 본질적으로 희소한 자원이다. 이 분야에는 로봇이 도와주거나 운전하는 일이 일상화된 '인터넷' 같은 환경이 존재하지 않는다. 일반적으로 이들 분야의 문제는 시뮬레이션 환경에서 훈련하거나, 현실 세계에서 대규모 데이터를 수집하거나, 두 가지를 병행하는 방식으로 해결한다. 그러나 시뮬레이션 데이터는 현실과 맞지 않을 수 있고, 현실 세계에서 대규모 데이터를 수집하는 것은 비용이 매우 높으며, 드문 사건(rare events)의 데이터를 충분히 수집하는 것도 어렵다.

위 그림에서 원본 비디오(좌)를 울창한 정글 환경(우)으로 렌더링하는 식으로 비디오를 증강할 수 있음
출처: Sora 기술 보고서
우리는 Sora와 같은 모델이 이러한 문제에 기여할 수 있다고 믿는다. Sora는 100% 합성 데이터를 직접 생성하는 데 사용될 수 있으며, 기존 비디오의 다양한 변형을 통해 데이터 증강(data augmentation)에도 활용될 수 있다.
기술 보고서의 예시를 보면, 원본 비디오에서 빨간 차가 숲길을 달리다가 Sora 처리 후에는 열대 정글 도로를 달리는 모습으로 변한다. 같은 기술을 사용하면 낮과 밤의 전환, 날씨 변화 등을 렌더링하는 것도 가능하다.
시뮬레이션 및 월드 모델
'월드 모델(World Models)'은 중요한 연구 방향이다. 모델이 충분히 정확하다면, AI 에이전트를 직접 훈련하거나, 계획 및 탐색 목적으로 활용할 수 있다.
Sora와 같은 모델은 비디오 데이터로부터 현실 세계의 작동 방식에 대한 기본 모델을 암묵적으로(implicitly) 학습한다. 현재 이 ' emergent simulation'(자발적 시뮬레이션)은 결함이 있지만 여전히 흥미롭다. 이는 대규모 비디오 데이터를 활용해 월드 모델을 훈련할 수 있음을 시사한다. 게다가 Sora는 액체 흐름, 빛의 반사, 섬유 및 머리카락의 움직임 등 매우 복잡한 현상도 시뮬레이션할 수 있는 것으로 보인다. OpenAI는 기술 보고서 제목을 Video generation models as world simulators로 지었는데, 이는 모델이 가장 중요한 영향을 미칠 분야라고 믿기 때문이다.
최근 DeepMind는 Genie 모델을 통해 유사한 효과를 보여주었다. 일련의 게임 비디오만으로 훈련한 모델이 해당 게임을 시뮬레이션하고 새로운 게임까지 창조하는 능력을 습득한 것이다. 이 경우 모델은 직접 행동을 관찰하지 못했음에도 불구하고, 행동에 따라 예측이나 결정을 조정하는 법을 배웠다. Genie의 경우, 모델 훈련의 목표는 이러한 시뮬레이션 환경에서 학습하는 것이었다.

Google DeepMind Genie에서 제공한 비디오:
Generative Interactive Environments 소개
종합적으로, 현실 세계 과제 기반으로 로봇과 같은 구체적 에이전트(embodied agents)를 대규모로 훈련할 때 Sora 및 Genie와 같은 모델이 반드시 기여할 것이라 믿는다. 물론 이러한 모델에도 한계가 있다. 픽셀 공간에서 훈련되기 때문에 바람에 흔들리는 풀잎까지 모든 디테일을 시뮬레이션하지만, 이는 현재 과제와 무관할 수 있다. latent space는 압축되었지만 pixel로 복원해야 하므로 많은 정보를 유지해야 하며, latent space 내에서 얼마나 효과적으로 계획(planning)을 수행할 수 있을지는 여전히 불확실하다.
04. 컴퓨팅 자원 추정
우리는 모델 훈련과 추론 과정에서 각각 필요한 컴퓨팅 자원에 관심을 갖고 있으며, 이러한 정보는 미래 컴퓨팅 수요 예측에 도움이 된다. 그러나 Sora의 모델 크기 및 데이터셋에 대한 구체적인 정보가 매우 적어 정확한 추정은 어렵다. 따라서 본 섹션의 추정치는 실제 상황을 진정으로 반영하지 못할 수 있으니 신중히 참고하기 바란다.
DiT를 기반으로 Sora의 컴퓨팅 규모 추론
Sora에 관한 자세한 정보는 매우 제한적이지만, DiT 논문을 다시 살펴보고 이를 기준으로 Sora의 컴퓨팅 수요를 추론할 수 있다. 이 연구가 분명히 Sora의 기반이기 때문이다. 가장 큰 DiT 모델인 DiT-XL은 6.75억 개의 파라미터를 가지며, 훈련에 총 1,021 FLOPS의 컴퓨팅 자원을 사용했다. 이 수치를 이해하기 쉽게 말하면, 0.4장의 Nvidia H100을 1개월간 돌리거나, 단일 H100으로 12일간 돌리는 것과 같다.
현재 DiT는 이미지 생성에만 사용되지만, Sora는 비디오 모델이다. Sora는 최대 1분 길이의 비디오를 생성할 수 있다. 비디오 인코딩 프레임률을 초당 24프레임(fps)로 가정하면, 하나의 비디오는 최대 1,440프레임을 포함한다. Sora는 픽셀에서 latent space로의 매핑에서 시간 및 공간 차원 모두를 압축하는데, DiT 논문의 8배 압축률과 동일하다고 가정하면 latent space에서는 180프레임이 남는다. 따라서 DiT의 수치를 비디오에 단순 선형 외삽하면, Sora의 컴퓨팅량은 DiT의 180배가 된다.
또한 우리는 Sora의 파라미터 수가 6.75억을 훨씬 초과한다고 믿으며, 200억 수준도 가능하다고 추정한다. 이는 다시 모델 측면에서 DiT보다 30배 많은 컴퓨팅량을 필요로 함을 의미한다.
마지막으로, Sora의 훈련 데이터셋은 DiT보다 훨씬 클 것으로 생각한다. DiT는 256의 배치 크기로 300만 스텝 훈련하여 총 7.68억 장의 이미지를 처리했다. 다만 ImageNet은 1,400만 장밖에 없으므로 동일 데이터를 반복 사용했음을 유의해야 한다. Sora는 이미지와 비디오가 혼합된 데이터셋으로 훈련된 것으로 보이나, 데이터셋에 대해 거의 알지 못한다. 우선 Sora의 데이터셋이 정지 이미지 50%와 비디오 50%로 구성되며, DiT보다 10~100배 크다고 가정하자. 그러나 DiT는 동일 데이터포인트를 반복 훈련했고, 더 큰 데이터셋이 사용 가능할 경우 이러한 방식은 비효율적일 수 있다. 따라서 컴퓨팅량 증가 배율을 4~10배로 보는 것이 더 합리적이다.
이러한 정보를 종합하고 데이터셋 규모에 따른 다양한 추정을 고려하면 다음과 같은 결과를 얻을 수 있다:
공식: DiT 기준 컴퓨팅량 × 모델 증가 × 데이터셋 증가 × 180프레임 비디오 데이터로 인한 증가 (데이터셋 중 50%에만 해당)
-
데이터셋 규모 보수적 추정: 1,021 FLOPS × 30 × 4 × (180 / 2) ≈ 1.1×10²⁵ FLOPS
-
데이터셋 규모 낙관적 추정: 1,021 FLOPS × 30 × 10 × (180 / 2) ≈ 2.7×10²⁵ FLOPS
Sora의 컴퓨팅 규모는 4,211~10,528장의 H100을 1개월간 사용하는 것과 동등하다.
컴퓨팅 수요: 추론 vs 훈련
컴퓨팅 수요를 평가할 때 중요한 또 다른 부분은 훈련과 추론 단계의 컴퓨팅량 비교이다. 이론적으로 훈련은 막대한 컴퓨팅량이 필요하지만 일회성 비용이며, 한 번만 지불하면 된다. 반면 추론은 훈련보다 적은 컴퓨팅을 필요로 하지만, 콘텐츠 생성 시마다 발생하며 사용자 수가 증가함에 따라 계속해서 누적된다. 따라서 사용자 수와 모델 보급이 증가함에 따라 추론이 점점 더 중요해진다.
따라서 추론 컴퓨팅이 훈련 컴퓨팅을 초과하는 전환점(critical point)을 찾는 것도 매우 가치 있다.
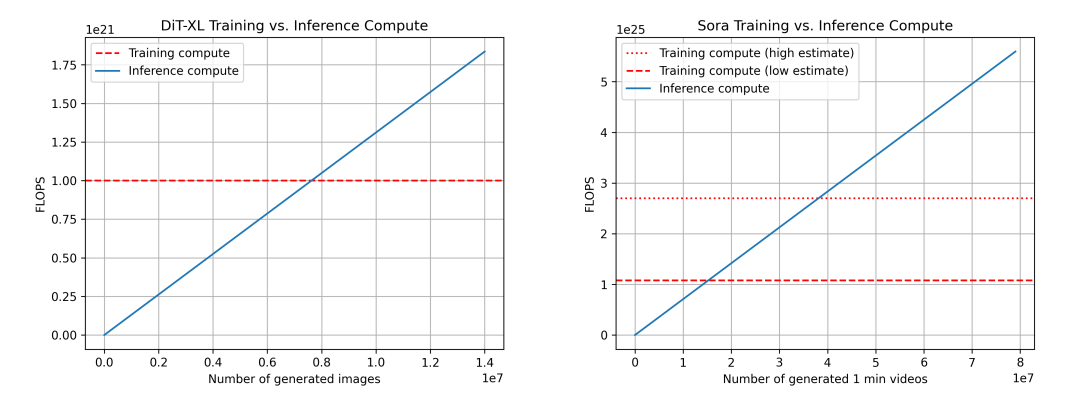
DiT(좌)와 Sora(우)의 훈련 및 추론 컴퓨팅 비교. Sora의 경우 위 추정치를 기반으로 하며, 신뢰도는 다소 낮다. 우리는 훈련 컴퓨팅에 대해 두 가지 추정치를 제시한다: 낮은 추정(데이터셋 크기 4배), 높은 추정(데이터셋 크기 10배).
위 데이터를 기반으로 다시 DiT를 이용해 Sora 상황을 추론한다. DiT의 경우, 가장 큰 모델인 DiT-XL은 추론 한 단계당 524×10⁹ FLOPS를 사용하며, 이미지 생성에는 250단계의 diffusion이 필요하므로 총 131×10¹² FLOPS가 소요된다. 760만 장의 이미지를 생성한 후 '추론-훈련 전환점'에 도달하며, 이후부터는 추론이 컴퓨팅 수요를 주도하게 된다. 참고로 매일 Instagram에 약 9,500만 장의 이미지가 업로드된다.
Sora의 경우, FLOPS를 524×10⁹ FLOPS × 30 × 180 ≈ 2.8×10¹⁵ FLOPS로 추산한다. 여전히 각 비디오에 250단계의 diffusion을 가정하면, 비디오 당 총 FLOPS는 708×10¹⁵ FLOPS가 된다. 참고로 이는 H100 한 장당 시간당 약 5분의 비디오를 생성하는 데 해당한다. 데이터셋 보수적 추정 시 '추론-훈련 전환점' 도달을 위해 1,530만 분의 비디오 생성이 필요하며, 낙관적 추정 시에는 3,810만 분이 필요하다. 참고로 매일 YouTube에 약 4,300만 분의 비디오가 업로드된다.
추가로 주의할 점이 있다. 추론에서 FLOPS만 중요한 것은 아니다. 메모리 대역폭(memory bandwidth)도 중요한 요소이며, diffusion 단계를 줄이기 위한 연구도 활발히 진행 중이며, 이는 컴퓨팅 수요 감소와 추론 속도 향상으로 이어진다. 훈련과 추론에서 FLOPS 활용률이 다를 수도 있어 이 역시 중요한 고려 사항이다.
Yang Song, Prafulla Dhariwal, Mark Chen, Ilya Sutskever는 2023년 3월 Consistency Models 연구를 발표하며, diffusion 모델이 이미지, 오디오, 비디오 생성 분야에서 중대한 진전을 이루었지만 반복적 샘플링 과정에 의존하고 생성 속도가 느리다는 한계가 있다고 지적했다. 연구팀은 일관성 모델(consistency model)을 제안하여 계산 교환을 통해 샘플 품질을 향상시켰다. https://arxiv.org/abs/2303.01469
다양한 모달리티 모델의 추론 컴퓨팅 수요
우리는 서로 다른 모달리티에서 모델의 추론 컴퓨팅 수요를 단위 출력당 비교했다. 이 연구는 다양한 모델에서 추론의 계산 집약도가 얼마나 증가하는지를 분석하여 컴퓨팅 계획 및 수요에 직접적인 영향을 준다. 각 모델의 출력 단위는 모달리티에 따라 다르다: Sora는 최대 1분 길이의 비디오, DiT는 512x512 픽셀의 이미지, Llama 2 및 GPT-4는 1,000토큰짜리 문서를 단위 출력으로 정의했다(참고: 평균 위키백과 문서는 약 670토큰).
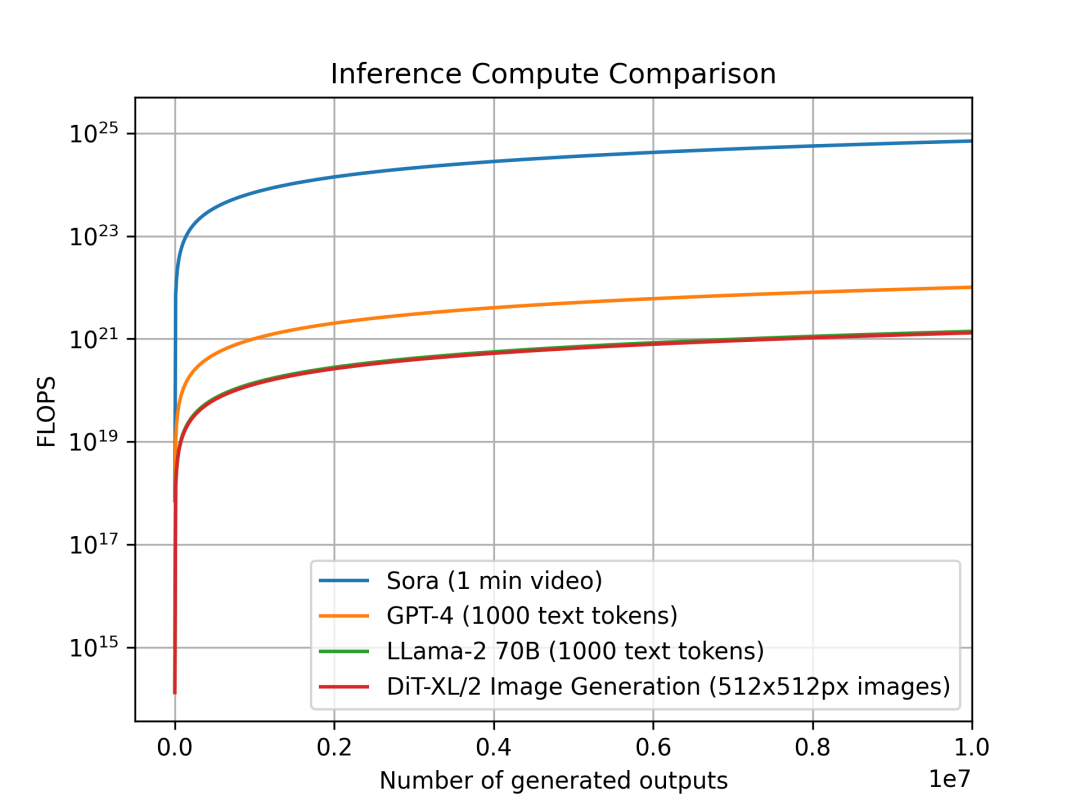
단위 출력당 추론 컴퓨팅 비교: Sora는 1분 비디오, GPT-4와 LLaMA 2는 1,000토큰 텍스트, DiT는 512x512픽셀 이미지. Sora의 추론이 계산상 몇 수준 이상 더 비용이 많이 든다는 것을 보여준다.
Sora, DiT-XL, LLama2-70B, GPT-4를 비교하고 log-scale로 FLOPS를 그래프화했다. Sora와 DiT는 위의 추론 추정치를 사용했으며, Llama 2와 GPT-4는 경험적으로 'FLOPS = 2 × 파라미터 수 × 생성된 토큰 수' 공식을 사용해 빠르게 추정했다. GPT-4의 경우 MoE 모델로 가정하고, 각 전문가(expert) 모델은 2,200억 파라미터를 가지며, 각 포워드 패스에서 2개의 전문가를 활성화한다고 가정했다. 참고로 GPT-4 관련 데이터는 OpenAI의 공식 입장이 아니며 참고용이다.
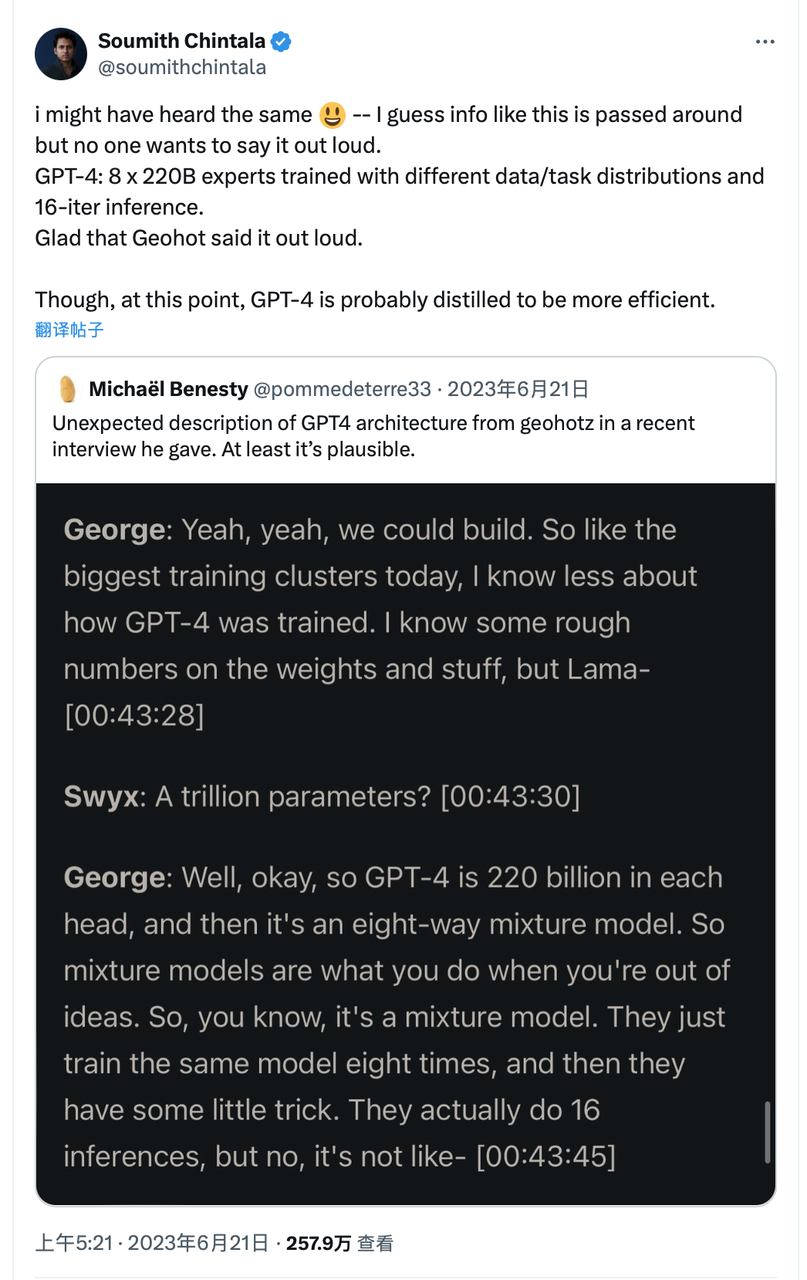
출처: X
DiT와 Sora와 같은 diffusion 기반 모델은 추론 단계에서 더 많은 컴퓨팅을 소비한다는 것을 알 수 있다. 6.75억 파라미터의 DiT-XL은 추론에서 약 700억 파라미터의 LLaMA 2와 비슷한 수준을 소비한다. 더 나아가 Sora의 추론 소비는 GPT-4보다 여러 수준 이상 높다.
다시 한번 강조하지만, 위 계산에 사용된 수치는 대부분 추정치이며 단순화된 가정에 기반한다. 예를 들어 GPU의 실제 FLOPS 활용률, 메모리 용량
TechFlow 공식 커뮤니티에 오신 것을 환영합니다
Telegram 구독 그룹:https://t.me/TechFlowDaily
트위터 공식 계정:https://x.com/TechFlowPost
트위터 영어 계정:https://x.com/BlockFlow_News










