
スキルの正しい活用方法:Anthropicが内部メソドロジーを公開した後の5つの考察
TechFlow厳選深潮セレクト
スキルの正しい活用方法:Anthropicが内部メソドロジーを公開した後の5つの考察
多くの人が「Skill」を使用していますが、必ずしも「Skill」を正しく理解しているとは限りません。
著者:AIプロダクト担当・アイン
Anthropicチームが執筆したブログ『Lessons from building Claude Code: How we use skills』を読みました。現時点で、私が目にする中で最も深くSkillについて実践的に考察されたまとめです。
Skillという概念自体はそれほど複雑ではありませんが、実際に「良いSkill」を作り上げるのは、決して簡単ではないと私は感じています。
Skillが注目され始めた頃、多くの人が文風やライティングに関するSkillを次々と作成していました。「自分の文章スタイルをSkillに組み込めば、モデルがそのスタイルに従って安定して出力してくれる」と考えられていたのです。
しかし、その後私が実際にさまざまなSkillを試してみたところ、こうしたアプローチが多くの場合うまく機能しないことがわかりました。
なぜなら、ひとつの文風Skillには数千字から数万字もの内容が詰め込まれることがあり、Skillをロードするとコンテキストの大部分を占めてしまうからです。コンテキストが過剰になると、むしろモデルの推論能力が低下してしまうのです。
その結果、しばしば以下のような状況が生じます:確かにスタイルは再現できているものの、内容が浅くなり、分析力も弱まってしまうのです。
また、もう一つよくあるケースがあります。
多くの人がSkillを作成する際、手順書のように「ステップ1:これを行う」「ステップ2:これを実行する」「ステップ3:これを実施する」といった操作説明を大量に記述します。しかし、実際に実行してみると、モデルの動作は安定しません。
後にようやく理解しましたが、こうした反復的な作業は、長々としたInstructionsではなく、むしろScriptとして定着させるのが適しています。
Anthropicのこの記事を読んだ後、私が最も強く感じたのは、「多くの人が実はSkillを使っているが、必ずしもSkillの本質を本当に理解しているわけではない」という点です。
Skillとは、本質的にContext Engineering(コンテキスト設計)を行うものです。知識をSkillに埋め込むべきか、Reference(参照情報)として分割すべきか、Scriptとして実装すべきか、あるいはGotchas(注意点)を使ってモデルの振る舞いを制約すべきか——これらには、経験に基づく多くのノウハウが詰まっています。
Skillの動作原理を理解した上で、優れたSkillを見直すと、そこでは単なるプロンプトの問題ではなく、むしろコンテキストの最適化、経験の体系化、および能力の再利用という課題が解決されていることに気づきます。
もし皆さんがSkillを深く研究したいと考えているなら、ぜひ以下の2つの記事をおすすめします:
https://claude.com/blog/lessons-from-building-claude-code-how-we-use-skills
#01 無駄な説明は書かない
Skillは、組織内の「暗黙知」を体系化・蓄積することを目的としています。したがって、Skillにはモデルがすでに知っている常識を繰り返し記述する必要はありません。真に価値があるのは、モデルがそもそも知らない情報なのです。
Anthropic社内では、Skillに記載すべきは「Gotchas(よく陥る落とし穴)」であると繰り返し強調されています。
例えば:
1.このテーブルはcreated_atで並べ替えない
2.staging環境でHTTPステータス200が返されたからといって成功とは限らない
3.request_idとtrace_idは同一のものである
こうした情報は、しばしば現場のエンジニアの経験の中にしか存在しません。だからこそ、Skillの本質を常に意識しておく必要があります。
Skill = 貯金箱のないベテラン技術者の経験を言語化したもの
Skillを通じて、かつて個人の頭の中だけに分散していた貴重な経験を、組織全体で共有できる形に蓄積していくのです。
#02 Skillは本質的にContext Engineeringである
これは、Anthropicが提示した最も深い洞察のひとつかもしれません。
Skillは単なるMarkdownファイルではなく、むしろ「フォルダ」です。すでにSkillを使ったことのある人にとっては、この説明は当たり前のようですが、
私はこの数日間、この点を何度も考え直し、ようやく気づきました:彼らが「フォルダ」という形式を選んだのは、まさにContext Engineeringという考え方を表現しようとしていたからなのです。
では、典型的なSkill構造をもう一度見てみましょう:
skill/
├── SKILL.md
├── references/ 詳細な説明、APIリファレンス、境界条件など
├── scripts/ 実行可能なスクリプト
├── examples/ 使用例
├── assets/ テンプレート、画像、固定素材
あるSkillを呼び出す際、モデルはまずSKILL.mdを読み込みます。もしすべての情報をこのファイルに詰め込んでしまうと、すぐにコンテキストが膨張してしまいます。
仮にこれが「支払い障害対応Skill」だとしましょう。この中に、Stripeのエラーコード解説、過去の障害事例、トラブルシューティング用スクリプト、最終報告書のテンプレートなどがすべて含まれているとします。
これらの内容をすべてSKILL.mdに詰め込んでしまうと、ClaudeはSkillを呼び出すたびに、すべての情報を再読み込みしなければなりません。
ユーザーが単にエラーコードの意味を確認したいだけ、あるいは特定の支払いステータスが更新されない理由を調べたいだけだとしても、まったく不要な情報まで一括でコンテキストに読み込まれてしまいます。
一方、Anthropicのアプローチはまったく異なります。
SKILL.mdはあくまで「ナビゲーションページ」であり、Stripeのエラーが発生した場合にはreferencesディレクトリ内の該当説明を参照するよう、モデルに指示する役割を果たします。
過去の事例を参考にしたいときはexamplesディレクトリで類似事例を検索し、実際にトラブルシューティングを実行する際はscriptsディレクトリ内のスクリプトを実行し、最終報告書を作成する際にはassetsディレクトリ内のテンプレートを使用します。
このように、必要な情報は段階的に、必要なタイミングで展開されていくのです。
以下の図は、ぜひ保存しておいてください。
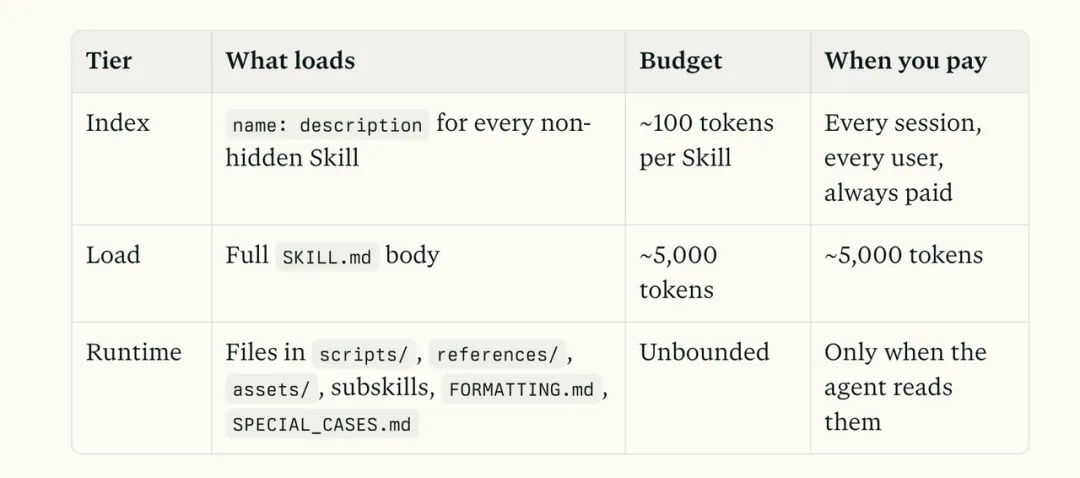
#03 可能な限りスクリプトを活用する
モデルの限られたコンテキスト容量と推論能力を、反復作業に浪費させないでください。こうした作業は、すべてスクリプトに任せるべきです。
例えば、多くの人がSkillを作成する際に以下のように記述することがあります:
1.登録データを照会する;2.課金データを照会する;3.コンバージョン率を算出する;4.異常原因を分析する。
この書き方自体は間違いではありませんし、モデルでも処理可能です。しかし、毎回実行されるたびに、モデルは分析フロー全体をゼロから再実行しなければなりません。
データの照会、整理、さまざまな境界条件への対応——これらすべてが反復的かつ定型的な作業です。
こうした能力は、すでに何度も検証済みです。ならば、なぜモデルに毎回「再発明」させなければならないのでしょうか?具体的なスクリプトを直接提供するのが最適です。
さらに、スクリプトを用いることで、Skillの実行精度も向上し、トークン消費量も削減できます。
この観点から見ると、Skill内のScriptsは、組織の能力を体系化・蓄積する役割を担っています。各スクリプトの背後には、チームがこれまで数多く経験してきた失敗と、そこから導き出されたベストプラクティスが詰まっているのです。
こうした能力を定着させれば、Claudeは今後、常にこうした経験の上に立って作業できるようになります。つまり、毎回ゼロから出発するのではなく、既存の知見を基盤として効率的に動けるのです。
そのため、私は次第に、SkillにおけるInstructionsとScriptsは、異なるレイヤーの課題をそれぞれ解決しているという認識を深めています。
Instructionsは「経験と判断」を提供し、Scriptsは「能力と実行」を提供します。
例えば、支払い障害対応Skillには次のような記述があるかもしれません:
「StripeがHTTPステータス200を返しても、直ちに支払い成功と判断してはならない。payment_eventsテーブルをさらに確認する必要がある。」
これはInstructionsに該当します。なぜなら、これは経験則であり、判断の根拠だからです。一方、「check_payment_events()」という関数はScriptに該当します。なぜなら、これは実行可能な能力だからです。
Scriptsのみがあれば、モデルは「どう調べるか」はわかりますが、「なぜ調べるのか」は理解できません。
逆にInstructionsのみであれば、モデルは「調べるべきだ」とは理解できますが、毎回その実装をゼロから行わなければなりません。両者はどちらも不可欠なのです。
#04 Descriptionはルーティングルールに近い
多くの人がSkillのDescription(説明文)を書く方法が、そもそも誤っています。
なぜなら、多くの人が「機能紹介」のつもりで記述してしまうからです。例えば:「PR Management Skillは、PRのステータス監視、CI問題の処理、自動マージを支援します」などと記述します。
しかし問題は、モデルがSkillを検索する際に「機能」で探すわけではないという点にあります。Claude Codeが起動すると、まずすべてのSkillの名称とDescriptionをスキャンし、
ユーザーの現在の質問内容に基づいて、どのSkillを読み込むべきかを判断します。
したがって、Descriptionにおいて最も重要な情報は、「このSkillは何ができるか」ではなく、「どんな状況でこのSkillを読み込むべきか」です。
つまり、Descriptionは、そのSkill全体の「ルーティングルール」の役割を果たしているのです。
現実世界では、誰も「PR管理ツールを呼び出して」とは言いません。代わりに、「このPRを監視してくれ」「CIがまた落ちた」などと、ユーザーの意図を直接伝えることが多いのです。
したがって、優れたDescriptionとは、機能の一覧を羅列するのではなく、ユーザーの意図をできる限り正確に描写するものでなければなりません。
私自身、非常にシンプルなチェック方法を提案したいと思います。
Descriptionを書き終えた後、そのSkillの他のすべてのファイルを削除し、Descriptionの一行だけを残します。そして自分に問いかけます:「モデルがユーザーの質問を見たとき、このDescriptionだけで、いつこのSkillを読み込むべきかを正しく判断できるだろうか?」
もし答えが「否」であれば、おそらくまだ修正が必要です。
#05 Skillの管理と配布
最後に、Skillの管理について触れます。
個人でSkillを使う場合は、非常にシンプルです。自分でいくつか作成し、自分でメンテナンスし、自分でアップグレードすればよいだけです。しかし、ほとんどのチームが将来的に直面する共通の課題があります。
Skillの数が数個から数十個、さらには数百個へと増えていくと、これらのSkillをどう管理し、どうアップグレードし、どうチームメンバーに配布するかという問題が生じます。
この点に関して、Anthropicの経験は非常に参考になります。
チーム規模が小さいうちは、Skillをコードリポジトリにそのまま同梱するのが一般的です。プロジェクト内の.claude/skillsディレクトリに置けば、全員が同じSkillセットと作業手法を共有できます。
しかし、Skillの数が増えていくにつれ、新たな問題が浮上します。
Claude Codeが起動すると、すべてのSkillの名称とDescriptionをスキャンし、現在のタスクに応じてどのSkillを呼び出すかを判断します。Skillの数が増えれば増えるほど、このルーティング処理のコストも高くなります。
だからこそ、Anthropicは後にMarketplaceを立ち上げたのです。もっと興味深いのは、彼らがMarketplaceをどのように管理しているかです。
多くの企業がこうした課題に直面した際、最初に思いつくのは「審査フローの構築」です。誰かがSkillを作成したら、まず申請し、審査を経て公式Skillライブラリに登録するという流れです。私たちの内部でもかつて同様の仕組みを導入しましたが、非常に重厚で、管理のために管理するような状態になってしまいました。
ところが、Anthropicの組織運営はとても軽やかです。
新しいSkillはまず小規模な範囲で広め、同僚が自らインストールし、自ら試用するように促します。
そして、徐々に利用者が増え始めたら、それはそのSkillが実際に何らかのリアルな課題を解決しているという確かな証左です。この段階になって初めて、作者が正式なMarketplaceへと提出するのです。
つまり、彼らは「このSkillに価値があるかどうか」を事前に議論するのではなく、まずは実際の利用シーンで検証させ、自然と利用者が増えてきたものを、段階的に公式システムへと取り込んでいくのです。こうして残ったSkillは、ほぼすべてチームが本当に必要としていたものばかりです。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News















