

グラデーション:Bittensorエコシステムにおける分散型AI学習インフラストラクチャ
TechFlow厳選深潮セレクト
グラデーション:Bittensorエコシステムにおける分散型AI学習インフラストラクチャ
Gradients は、TAO エコシステムにおけるトレーニングインフラを補完し、「市場主導型AI最適化」という新たなパラダイムを探求しています。長期的には、分散型AIトレーニングにおける重要なエントリーレイヤーへと発展する可能性があります。
出典:CoinW 研究院
概要
Gradients は、Bittensor 上に構築された分散型AI学習サブネット(SN56)であり、「タスクの発行・マイナーによる競争・検証者によるフィルタリング」などのメカニズムを通じて、複雑な技術プロセスであるモデル学習を、市場主導のネットワーク協働プロセスへと変換することをその核に据えています。アーキテクチャ上は、AutoML と分散型コンピューティングリソースを統合し、インセンティブ駆動型の学習市場を形成しており、AIの利用障壁を低下させるだけでなく、コンピューティングリソースの活用効率も向上させています。エコシステムおよびデータ面での実績から見ると、Gradients は基礎ネットワークの構築を既に完了していますが、現時点ではインセンティブの重み付けおよび資金流入が比較的限定的です。Gradients は、TAO エコシステムにおける学習インフラストラクチャーを補完する存在であり、「市場主導型AI最適化」という新たなパラダイムを探求しています。長期的には、分散型AI学習における重要なエントリーレイヤーとしての発展が期待されます。
1. Web2 AutoML から始める:AI学習の現状と限界
1.1 AutoMLとは何か
従来の認識では、AIモデルの学習は非常に高いハードルを持つ作業であり、エンジニアがデータ処理・モデル選定・パラメーターの反復調整・性能評価など、複雑かつ時間のかかる一連のプロセスを担う必要があります。一方で、AutoML(自動機械学習)は、こうした煩雑なステップを「パッケージ化して自動化する」ことを本質とする技術です。言い換えれば、「モデルを自動的に構築するツール」であり、ユーザーはデータと目的(例:分類・予測・認識など)のみを指定すれば、モデル選定・パラメーター調整・学習最適化といった残りの全工程をシステムが自動で実行します。これにより、AIはごく一部の専門エンジニアだけのものではなく、一般の開発者や企業でも利用可能な能力へと進化し、AIの普及に向けた重要な一歩となっています。
1.2 従来のAutoMLの核心的限界
現在のAutoMLの主流実装は、Google Vertex AI や AWS SageMaker などのクラウドベンダーが提供するプラットフォームに集中しており、いわば「AI学習即サービス(AI Training-as-a-Service)」です。確かにWeb2 AutoMLはAIの利用障壁を大幅に低下させましたが、その基盤となるモデルには明確な限界があります。第一に、中央集権性の問題です。コンピューティングリソース、価格設定、ルールすべてがプラットフォーム側によって支配されており、ユーザーは単一のサービスプロバイダーに強く依存し、価格交渉力も持ちません。第二に、コストの高さと不透明性です。AI学習に不可欠なGPUリソースは、クラウドベンダーがほぼ独占しており、価格メカニズムには市場競争が欠如しています。さらに決定的なのは、最適化効率の上限です。従来のAutoMLは、いかに高度なシステムであれ「単一のシステムが最適解を探索する」ことに他ならず、これは本質的に単一技術パスに基づく最適化に過ぎません。その探索空間は限られており、全く異なる複数のアプローチを同時に試すことは困難です。このため、現在のWeb2 AI学習は「閉じられたシステム」であり、モデルの学習・最適化・リソース配分のすべてが、単一プラットフォームが支配する環境内で完結しています。このようなモデルは効率的ではありますが、需要の増加に伴い、その限界が徐々に顕在化しつつあります。
2. Gradients:「ネットワーク」によってAI学習を再構築する
2.1 Gradientsとは何か:分散型AutoMLプラットフォーム
前章で述べたように、従来のWeb2 AutoMLの核心的課題は「閉じられたシステム」にあり、モデル学習はプラットフォームへの依存、最適化パスの制約、リソース流動性の不足に直面しています。Gradients は、まさにこのモデルに対する再構築の試みです。Gradients は、WanderingWeights が立ち上げた分散型エンジニアコミュニティを起源とし、Bittensor ネットワーク上に構築された、サブネット56上で動作するAI学習サブネットです。従来のプラットフォームとは異なり、Gradients は中央集権的なサービスを提供するのではなく、学習プロセスを分解し、それをオープンなネットワーク全体に委ねます。ユーザーは、モデルの種類やデータといったタスク目標を定義するだけでよく、学習の実行・パラメーター最適化・結果のフィルタリングといった残りのすべてのプロセスは、ネットワークが自動で遂行します。この方式により、AI学習は複雑な工学的プロセスから、「ニーズを提出し、結果を得る」という極めてシンプルなプロセスへと抽象化され、専門性の極めて高い技術作業ではなく、むしろ汎用的な能力に近づきます。
2.2 閉じたシステムからオープンな協働へ:Gradientsが解決した課題
Gradients の核心的な変化は、元来単一プラットフォーム内部で完結していた学習プロセスを、オープンな協働ネットワークへと転換したことにあります。学習タスクはもはや単一のシステムによって遂行されるのではなく、複数の参加者に並列して割り当てられ、その後、統一的な評価メカニズムによって最良の結果が選別されます。この構造はまず、中央集権的サービスプロバイダーへの依存を低減し、学習を分散型コンピューティングリソースの上に構築します。また、分散したGPUリソースが単一のネットワークに統合され、競争を通じてより市場に近いリソース配分が実現します。さらに重要なのは、モデル最適化が単一のパスに限定されず、多様な手法による並列的探査を通じて常に最適解に近づいていく点です。これにより、全体的な最適化上限が向上します。
2.3 本質的変化:ツールから「学習市場」へ
従来のAutoMLでは、プラットフォームはあくまで「ツール」であり、内部アルゴリズムを用いてユーザーのために最適解を探索します。一方、Gradients では、このプロセスは継続的に稼働する「市場」に近くなります:ユーザーがニーズを発行し、異なる参加者が同一タスクをめぐって競争し、評価メカニズムによって結果が選別されます。これにより、モデルの性能は単一システムの能力に依存しなくなり、多数の参加者による継続的な競争と反復によって支えられるようになります。AutoMLは、比較的閉じられた技術的最適化課題から、インセンティブによって駆動される動的プロセスへと変容し、参加者の増加に伴って最適化能力が拡張可能となります。この変化によって、AI学習は市場に類似した自己進化特性を獲得し始めます。
2.4 TAOエコシステム内での役割:AI学習インフラストラクチャー層
Bittensor のサブネット体系において、各サブネットは推論・データ処理・学習など異なる機能を担っていますが、Gradients はその中で「学習層」に位置付けられます。それは、分散したコンピューティングリソースを実際のモデル成果物へと変換し、タスクの配信および評価メカニズムを通じて、これらのリソースを継続的にスケジューリング・最適化することを任務としています。同時に、Gradients はコンピューティングリソースの供給側とモデルの需要側を接続し、学習を単なるリソース消費プロセスから、組織化・最適化可能なネットワーク協働プロセスへと転換します。この枠組みにおいて、Gradients は分散型リソースを実用可能なAI能力へと変換し、上位レイヤーのアプリケーション発展を支える「中枢的要素」として機能しています。
3. 核心アーキテクチャー:AI学習はネットワーク内でいかに実行されるか
前章では、Gradients がAI学習を「プラットフォーム内部で実行」から「ネットワークによる協働で実行」へと転換したと述べました。では、このネットワークは具体的にどのように機能しているのでしょうか?本章の目的は、このプロセスをより直感的に分解・明示することにあります。
3.1 分散型学習:1つのタスクが「複数人」によっていかに遂行されるか
Gradients を、常時稼働中の「学習協働ネットワーク」とイメージしてください。ユーザーが学習タスクを提出すると、そのタスクは単一のシステムに任されるのではなく、ネットワーク内の複数の参加者に同時配信されます。これらの参加者は、同一のデータと目標に基づき、それぞれ異なる学習手法を試行し、所定の時間内に結果を提出します。その後、システムがこれらの結果を統一的に評価し、最も優れた結果を選別します。最終的に、より優れた結果を提出した参加者が報酬を得て、他の結果は却下されます。ユーザーの視点からは、このプロセスは単一のタスク発行だけで済み、あたかも複数の異なる最適化アプローチを同時に「呼び出し」、自動的に最適解を選択しているかのようです。この方式の鍵は、単一ノードの能力がどれほど強いかではなく、複数の並列試行+自動選別によって、結果が常に最適解に近づくという点にあります。
このネットワークには、主に3種類の参加者が存在します:ユーザー、マイナー、検証者です。ユーザーは学習ニーズを提示します。マイナーはコンピューティングリソースを提供し、異なる学習手法を試行します。検証者は結果を評価し、最良のモデルを選別します。この分業により、学習プロセスは継続的に稼働し、絶え間なくより優れた解が選別され続けます。全体として、これは「ニーズ・供給・評価」によって駆動される協働ネットワークを構成しています。
3.2 市場主導型AutoML
前述のメカニズムの分解から明らかなように、Gradients は単にAutoMLをブロックチェーン上に移行させただけではなく、多方参加とインセンティブメカニズムを導入することで、モデル最適化の基盤的ロジックを根本的に変革しています。従来のAutoMLは、有限のパス内で単一システムが最適解を探索するのに依存していましたが、Gradients ではこのプロセスがネットワーク全体へと拡張されています:異なる参加者が同一タスクをめぐって継続的に異なる手法を試行し、統一的な評価を通じて繰り返し選別・反復を行います。これにより、モデル最適化は単発の計算プロセスではなく、反復的に進化可能な動的プロセスとなります。このメカニズムでは、より高性能な結果がより高い収益を生み出すため、参加者は自らの戦略を継続的に最適化するよう誘因付けられ、全体的な成果が絶えず向上します。
4. インセンティブと競争メカニズム:AI学習はいかに「正の循環」を形成するか
4.1 インセンティブメカニズム(TAO駆動):学習行為から収益への還元
Gradients が長期にわたって稼働し続ける鍵は、その背後にあるインセンティブメカニズムにあります。これは、Bittensor が提供するネイティブなインセンティブ体系に依拠しています。TAO は、Bittensor ネットワークのネイティブトークンであり、ネットワーク全体の「価値媒体」です。一方では、コンピューティングリソースおよびモデル貢献を提供する参加者への報酬に使用され、他方では、ステーキングなどを通じてサブネットの重み付け配分に参加し、異なるサブネット間でのリソース流動を左右します。
Bittensor メインネットは、継続的に新しいインセンティブ(Emission)、すなわちTAOを生成します(現在の適切な量は1日あたり約3600 TAO)。これは一定のルールに基づき、異なるサブネットに配分されます。各サブネットが得られる配分量は、ネットワーク全体におけるその「パフォーマンス」(例:アクティビティレベル・貢献の質・資金支援状況など)に応じて決まります。Gradients が属するサブネットの場合、このように配分されたTAOは、内部で再び参加者に分配されます。分配の核心的基準は、「誰がより優れたモデルを貢献したか」であり、より良い成果を出した参加者がより多くの収益を得ます。
具体的には、マイナーが学習結果を提出し、検証者がそれらの結果をテスト・採点します。システムは採点結果に基づき、各参加者の「貢献ウェイト」を算出し、それに応じて報酬を分配します。より優れたモデル(例:汎化能力が高く、安定した性能を発揮するもの)はより高い収益を獲得し、検証者がより正確に、かつ真の品質を反映した評価を行うことができれば、それにもより多くのインセンティブが与えられます。このような設計により、「より良くすること」と「より多く稼ぐこと」が直接結びつき、参加者がモデルを絶えず最適化するよう駆動します。
4.2 サブネット間の競争:内部競争だけでなく、外部ランキングも存在
サブネット内部の競争に加えて、Gradients はBittensorネットワーク全体における「横断的競争」にも直面しています。TAOの配分は動的であるため、異なるサブネットはより高い重み付けを巡って競い合います。持続的に高品質な成果を生み出し、より多くの参加者を惹きつけるサブネットのみが、より大きな報酬シェアを獲得できます。したがって、Gradients のインセンティブは、単に内部のモデルパフォーマンスに依存するだけでなく、エコシステム全体における相対的競争力をも反映します。このシステムは、複数のレベルにわたる循環を形成します:サブネット内部ではモデル同士の競争があり、サブネット間では全体的なパフォーマンス競争があります。最終的に、コンピューティングリソース投入・モデル効果・経済的リターンが密接に結合され、継続的に稼働する正のフィードバック機構が成立します。
4.3 Gradients 5.0:競争から「トーナメント方式」へ
初期の継続的競争を基盤として、Gradients はさらに構造化されたメカニズム、すなわち「トーナメント方式の学習」へと進化しました。これは、周期的なコンペティションと捉えることができます:各ラウンドの学習では、時間ウィンドウが設定され、複数の参加者が同一タスクをめぐって競争し、複数ラウンドの選別を経て段階的に脱落者を淘汰し、最終的に最良のソリューションを選出します。この形式は、段階的な比較と集中評価を重視します。重要な変化の一つは、マイナーが学習結果を直接提出するのではなく、「学習手法」(コード)を提出し、検証ノードがこれを一括して実行する点です。これにより、異なる計算環境による干渉を回避し、公平性を高めるとともに、データおよび学習プロセスのプライバシー保護もより強固になります。さらに、優勝したソリューションはしばしば蓄積され、再利用可能な手法として固定化され、いわば「ベストプラクティス」の集合体が構築されます。長期的には、このメカニズムは単に最良のモデルを選別するだけでなく、絶えず進化する学習手法のライブラリーを構築することにも寄与します。
5. エコシステムの現状
5.1 参加者構造:ニーズ・供給・評価から成る協働ネットワーク
Gradients エコシステムは、3つの主要な役割から構成されます:ユーザー(需要側)、マイナー(供給側)、検証者(評価側)。ユーザーには、AI開発者・中小企業・Web3ビルダーが含まれ、これらは通常一定の技術的素養を持ちますが、コンピューティングリソースや完全なモデル学習能力に乏しく、Gradients を通じて低コストでモデル構築を実現しようとする傾向があります。マイナーはGPUコンピューティングリソースを提供し、学習タスクへの参加・競争を試み、その主な動機はTAO収益の獲得です。検証者は学習結果を評価・順位付けし、モデル品質およびメカニズムの有効な稼働を確保する上で極めて重要な役割を果たします。
より詳細なユーザー像を見ると、Gradients の実際の利用層は明確な「半開発者化」の特徴を示しています:最先端のAI研究所とは異なり、またまったく技術的背景を持たない一般ユーザーとも異なり、ある程度のエンジニアリング能力を持つ開発者およびWeb3技術ユーザーが中心です。これは、コミュニティ構造にも反映されており、現状では英語が主言語であり、コアユーザーは北米およびヨーロッパの開発者層に集中し、一部の東南アジアのマイナーおよびグローバルなGPUリソース提供者も含んでいます。全体としては、技術主導型の開発者コミュニティに近いと言えます。
5.2 エコシステムの運用現状
5月12日時点のデータによると、Gradients のalphaトークン価格は約0.0255 TAO、保有アドレス数は約4,890件、マイナー数は243名、検証者数は12名、Emission割合は1.61%です。また、流動性プールにおけるTAOの割合は2.19%、Alphaの割合は97.81%です。価格および保有アドレス数から見ると、Gradients はすでに一定のユーザー基盤と注目度を獲得していますが、全体としてはまだ初期拡散段階にあります。TAOエコシステムにおけるトッププロジェクトChutesと比較すると、当日のalphaトークン価格は0.0877 TAO、保有アドレス数は13,409件です。
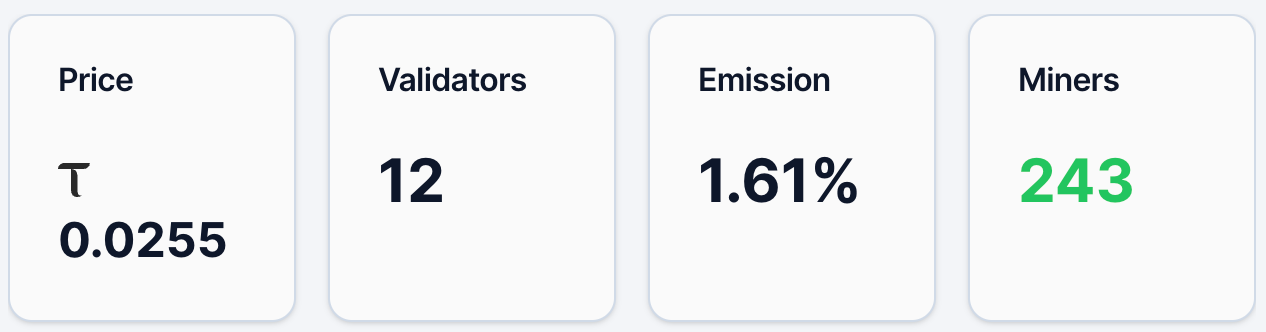
図1. Gradientsのデータ
出典: https://bittensormarketcap.com/subnets/56
次に、Emissionインセンティブメカニズムについてです。Bittensor体系において、Emissionとは、当該サブネットがネットワーク全体の新規報酬配分においてリアルタイムで受け取る割合を指します。Bittensorネットワークは継続的に新しい TAOを生成し、各サブネットに重み付けに基づき配分しますが、Gradients の現在の1.61%は、ネットワーク全体の新規インセンティブのうちごく一部しか獲得していないことを意味します。この指標は、本質的に市場(例:ステーキングなど)が資金フローを通じて異なるサブネットに対して行う「投票結果」を反映しています。したがって、1.61%という水準は、現時点で市場からの認知度および資金流入が比較的限定的であることを示す一方で、今後の重み付け向上の余地があることも意味します。資金構造(流動性プール)から見ると、TAOの割合はわずか2.19%であり、Alphaは97.81%に達しています。これは、外部からの資金流入が依然として限定的であり、現状はサブネット内部の供給が主導していることを示唆しています。価格は新規資金流入に対して非常に敏感であり、TAOがさらに流入すれば、より顕著な拡大効果を生む可能性があります。
6. 競争構造および強み・弱み
6.1 業界におけるポジショニング:分散型AutoMLの学習インフラストラクチャー
Gradients は、「AI学習インフラストラクチャー+分散型AutoML」という細分化されたセグメントに位置付けられます。それは、モデル学習を中央集権的プラットフォームから解放し、ネットワーク化されたメカニズムを通じて、より効率的なリソース活用およびモデル最適化を実現しようと試みています。Web2体系では、このセグメントはすでに比較的成熟しており、代表的な事例としてGoogle Vertex AIやAWS SageMakerがあります。これらのプラットフォームは、クラウドコンピューティングを活用して、開発者にワンストップのモデル学習・デプロイサービスを提供していますが、その本質は依然として中央集権的アーキテクチャーです。これに対し、Gradients の差異は「機能の多さ」ではなく、基盤となるロジックの違いにあります:それは、学習を「プラットフォームサービス」から「ネットワーク協働」へと転換し、競争メカニズムによって最良の結果を選別することで、より市場志向の学習システムに近づけている点です。
6.2 横断的比較:Web2とWeb3のAutoMLの差異
より広い視点から見ると、Web2とWeb3におけるAutoMLの差異は、本質的に二つの異なるパラダイムの対比です。Web2モデルは効率性と安定性を重視し、集中型リソースと工学的最適化を通じて、制御可能かつ成熟したサービス体験を提供します。一方、Web3モデルは、開放性とインセンティブメカニズムを重視し、多方参加を導入することで、モデル最適化を競争の中で絶えず進化させようとします。具体的には、Web2 AutoMLは「強力なツール」に近く、ユーザーがタスクをプラットフォームに委ね、システム内部で最適解が探索されます。これに対し、Gradients を代表とするWeb3 AutoMLは「オープンな市場」に近く、ユーザーがニーズを発行し、異なる参加者がソリューションを提供し、評価メカニズムによって結果が選別されます。この差異がもたらす直接的な影響は以下の通りです:前者はより安定・制御可能ですが、最適化パスに限界があります。後者は探索空間が大きく、潜在的な上限が高まりますが、安定性および成熟度についてはまだ向上の余地があります。
6.3 Web3におけるGradientsの差別化
現在のWeb3 AI分野では、大多数のプロジェクトは推論層またはAI Agentに焦点を当てており、「学習インフラストラクチャー」に特化したプロジェクトは比較的少数です。一部のプロジェクトは、コンピューティングリソースネットワークまたはデータネットワークと連携して学習能力を提供しようと試みていますが、全体として見ると、多くはリソースのスケジューリングやコンピューティングリソース市場のレベルにとどまっています。Gradients の差別化は、単にコンピューティングリソースの仲介を提供するにとどまらず、さらに上位レイヤーである「モデル最適化メカニズム」そのものへと拡張している点にあります。評価および競争体制を導入することで、学習プロセスに継続的な進化能力を付与しています。これは、単に「コンピューティングリソースをどこから調達するか」を解決するだけでなく、「これらのコンピューティングリソースをいかに効率的に活用するか」にも取り組んでいることを意味します。ポジショニングから見ると、Gradients は単なるコンピューティングリソース市場やツールプラットフォームではなく、「学習結果を重視する」ネットワークに近いと言え、これが多数のWeb3 AIプロジェクトとの核心的な違いです。
6.4 核心的強み:メカニズム主導の効率性向上
総合的に見ると、Gradients の強みは主にそのメカニズム設計にあります。まず、タスクの抽象化によって利用障壁を低下させ、ユーザーが複雑な学習プロセスに深く関与せずともモデルの成果を得られるようになり、潜在的なユーザー層を拡大しています。次に、リソース面では、分散型コンピューティングリソースの導入により、学習が単一のクラウドベンダーに依存しなくなり、理論的には競争を通じてより柔軟なコスト構造を形成できます。さらに重要なのは最適化方法の変化です。複数の参加者による並列的探査と選別メカニズムの組み合わせにより、Gradients は従来の単一パス最適化とは異なるソリューションを提供し、モデルがより短時間でより優れた性能に到達する可能性を秘めています。この「競争駆動型最適化」のモデルこそが、Gradients の最も核心的な強みです。
6.5 潜在的な課題
まず、モデル品質の安定性に関する問題があります。分散型学習は多方参加に依存しており、上限の向上には寄与しますが、結果のばらつきを招く可能性もあり、中央集権的システムと比較して制御性に若干の不確実性を伴います。次に、企業レベルの信頼性の問題です。企業ユーザーにとって、データセキュリティおよび学習プロセスの検証可能性は極めて重要ですが、分散型環境において、データの不正利用を防止し、結果を監査可能にする仕組みを確立することは、依然として重要な課題です。最後に、トークン経済への依存度です。Gradients の稼働は、インセンティブメカニズムに強く依存しており、もしTAOによる収益性が低下すれば、マイナーの参加意欲およびネットワーク全体の活性が損なわれる可能性があります。したがって、その長期的な持続可能性は、経済モデルが安定した正の循環を形成できるかどうかに一定程度依存します。
7. 今後の展望:分散型AutoMLは成立するか?
現時点では、Gradients はまだ初期段階にあり、その将来の成功はいくつかのキーポイントにかかっています。最も核心的なのは、単にインセンティブを目的とした参加ではなく、実際に必要な学習ニーズを継続的に引きつけることができるかということです。次に、モデル品質の問題です。分散型方式が、安定して利用可能な、あるいはさらに優れた結果を継続的に生み出せるかどうかです。さらに、経済的メカニズムが正の循環を形成できるか、すなわちコンピューティングリソースの供給と収益の間に長期的なバランスを維持できるかです。
より広い業界背景に照らすと、AI学習は現在、二つの異なる方向へと分岐しています。一つは、Web2モデルであり、トップテクノロジー企業が中心となって、集中型リソースと工学的能力を駆使してモデル性能を絶えず強化するものです。その強みは安定性と成熟度にあります。もう一つは、Gradients を代表とするWeb3のアプローチであり、オープンなネットワークとインセンティブメカニズムを活用して、より多くの参加者がモデル最適化に共同で関与し、競争の中で上限を絶えず押し上げていくものです。前者は「より強力なシステムを構築する」ことを目指し、後者は「自己進化するネットワークを構築する」ことに近いと言えます。
この観点から見ると、Gradients の探求は新たな可能性を示しています:AI学習はもはや単なる技術課題ではなく、「コンピューティングリソース+データ+市場メカニズム」の融合であるということです。もし、このモデルが成立すれば、Gradients は分散型AIにおける学習のエントリーポイントとなり、Bittensorエコシステムにおいて重要なインフラストラクチャーとしての役割を果たす可能性があります。もちろん、この方向性はまだ時間をかけて検証される必要がありますが、すでに従来のアプローチとは異なるAutoMLの進化の道筋を提示しています。
参考文献
1. Bittensor ドキュメンテーション: https://docs.learnbittensor.org
2. Gradients ウェブサイト: https://www.gradients.io/
3. Gradients: https://bittensormarketcap.com/subnets/56
4. Gradients X: https://x.com/gradients_ai
5. Taostats: https://taostats.io/subnets/56/chart
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News













