

OpenAI最強モデルGPT-5が登場、無料で利用可能
TechFlow厳選深潮セレクト
OpenAI最強モデルGPT-5が登場、無料で利用可能
AltmanはAGIへの大きな一歩を宣言し、マイクロソフトが先んじて接続。
執筆:李丹、華爾街見聞
今年、OpenAIが最も注目を集める製品が登場した。
米東部時間8月7日木曜日、OpenAIは次世代フラッグシップ人工知能(AI)モデル「GPT-5」のリリースを発表した。これはOpenAI初の「一体化」AIシステムであり、oシリーズモデルの推論能力とGPTシリーズモデルの高速応答能力を初めて統合した成果である。
新モデル発表会にて、OpenAI CEOのSam AltmanはGPT-5を「世界最高のモデル」と称賛し、「これまでのモデルに比べて大きなアップグレード」であり、AGI(汎用人工知能)実現への道において「重要な一歩」を示すものだと述べた。
OpenAIによると、GPT-5は複数のベンチマークテストで優れたパフォーマンスを発揮し、プログラミング、数学、ヘルスケア分野などで最先端レベルに達している。SWE-bench Verifiedコードテストでは74.9%の正確率を記録し、今週火曜日にAnthropicが発表した新モデルClaude Opus 4.1をわずかに上回った。また、GPT-5のハルシネーション問題は大幅に改善され、誤情報率は4.8%にまで低下し、前世代モデルGPT-4oの20.6%を大きく下回っている。
今週木曜日から、GPT-5はChatGPTの無料ユーザーおよびPlus、Pro、Teamプランの有料ユーザーすべてにデフォルトモデルとして提供され、1週間以内にEnterpriseおよびEduプランにも導入される予定だ。
GPT-4oと同様に、GPT-5の無料版と有料版の違いは使用量にある。Plusユーザーにはより高い利用上限が与えられ、Proユーザーは無制限に使用でき、強化版のGPT-5 Proを利用可能となる。無料ユーザーについては、完全な推論機能がすべて利用可能になるまで数日かかる可能性がある。無料ユーザーがGPT-5の使用制限に達すると、OpenAIは自動的により小型のモデルGPT-5 miniに切り替える。
また、OpenAIは水曜日に、米連邦政府機関に対してChatGPT製品を年額1ドルという象徴的な料金で提供すると発表した。具体的には、強化されたセキュリティおよびプライバシー機能を備えたChatGPTエンタープライズ版である。
OpenAIがGPT-5を正式発表した直後、マイクロソフトは同日からGPT-5を幅広い製品群に統合することを発表した。これには365 Copilot、Copilot、GitHub Copilot、Azure AI Foundryなどのプラットフォームが含まれ、企業および個人ユーザーがすぐにGPT-5の高度な推論能力とプログラミングの利点を体験できるようになる。
GPT-5はプログラミング、クリエイティブライティング、ヘルスケアの3大強みを持つ
OpenAIのGPT-5発表資料冒頭には、「GPT-5は、内蔵された思考能力により誰もが専門家の知性を持てる、OpenAI史上最も賢く、迅速かつ実用的なモデルです」と記されている。
OpenAIによれば、「最も強力なモデル」として、GPT-5は3つの主要分野で顕著な進化を遂げている。
まず第一にプログラミング能力の向上がある。GPT-5は、これまでのOpenAIモデルの中で最も強力なコーディングモデルであり、複雑なフロントエンド生成や大規模コードベースのデバッグにおいて特に優れた性能を発揮する。単一のプロンプトだけで、美しくレスポンシブなウェブサイト、アプリ、ゲームを作成できる。初期のテストユーザーは、間隔、タイポグラフィ、余白などのデザイン選択における改善に気づいた。
現実世界のコーディングタスクをGitHubから取得して評価するベンチマークテストSWE-bench Verifiedでは、GPT-5は思考後に最初の試行で74.9%の正確率を達成し、OpenAIの推論モデルo3の69.1%、GPT-4oの30.8%を上回った。
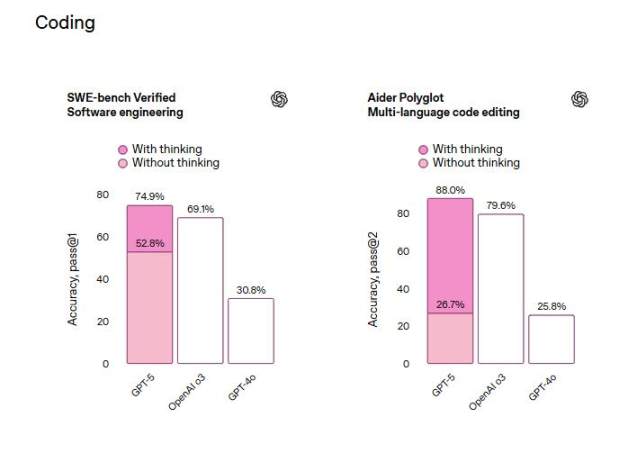
評論によれば、これはGPT-5が今週火曜日にAnthropicが発表したClaude Opus 4.1やGoogle DeepMindのGemini 2.5 Proよりもわずかに優れていることを意味する。両者のSWE-bench Verifiedテストでの得点はそれぞれ74.5%と59.6%だった。
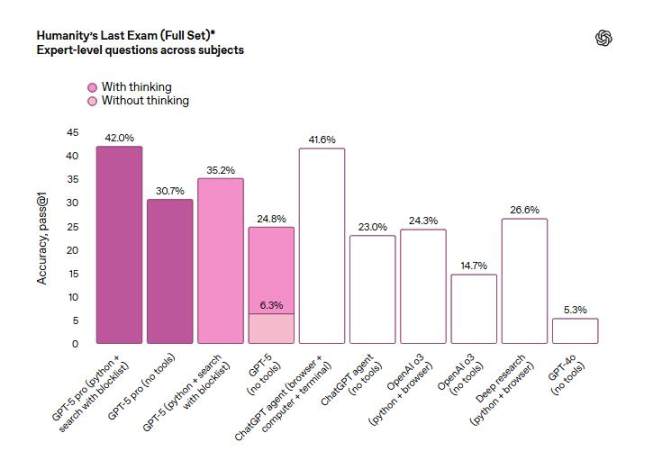
ただし、数学、人文、自然科学分野におけるモデルの性能を測る多分野専門能力テスト『Humanity』s Last Exam』では、拡張推論機能付きの強化版GPT-5 Proがツールを使用した場合の得点は42%だった。これはxAIのモデルGrok 4 Heavyの44.4%をやや下回っている。
Altmanは、GPT-5が特に得意とするのは、いわゆる「ムードコーディング」、つまり自然言語のプロンプトに基づいて機能的コードを生成することで、開発スピードを加速させることだと述べた。
一例として、OpenAIの研究者がGPT-5に「英語話者がフランス語を学べるウェブアプリを作成せよ。魅力的なテーマを持ち、フラッシュカード、クイズ、古典的なスネークゲーム、毎日の学習進捗を追跡する機能を含めること」という指示を与えた。
同じプロンプトを2つのGPT-5ウィンドウに入力したところ、数分後に2つの異なるアプリが生成された。OpenAIの責任者は、これらのアプリには「いくつかの欠陥がある」としつつも、ユーザーは背景の変更やタブの追加など、好みに合わせてAI生成のソフトウェアを調整できると述べた。
クリエイティブライティングにおいて、GPT-5は無韻詩の五音歩抑揚格や自然に流れる自由詩といった構造的に複雑な作業も処理できる。OpenAIのChatGPT担当副社長Nick Turleyは、GPT-5がクリエイティブタスクにおいて「より良い品位」を持ち、応答がより自然だと評価した。

ヘルスケア相談が第3の重要な向上領域である。
GPT-5は潜在的な健康問題をより積極的に指摘し、医療結果の解釈を支援できる。ただしOpenAIは、ChatGPTは医療専門家に代わるものではないと強調している。
「HealthBench Hard Hallucinations」テストでは、思考能力を持つGPT-5のハルシネーションによる誤情報率はわずか1.6%だった。これはGPT-4oとo3モデルの15.8%および12.9%を大きく下回っている。

ハルシネーションの可能性が大幅に低減 新たな安全トレーニング方式
OpenAIは、GPT-5は過去のモデルと比較してより信頼性と実用性が高く、現実世界の質問に正確に答えられ、ハルシネーションの可能性が著しく低減していると説明している。
ChatGPTの実際のトラフィックを代表する匿名プロンプトにネット検索を有効にした場合、GPT-5の応答に事実誤認が含まれる可能性はGPT-4oより約45%低い。また、思考後であれば、o3モデルに比べて約80%低い。以下の図からわかるように、GPT-5の誤情報率は4.8%、GPT-4oは20.6%、o3は22%である。

OpenAIはまた、GPT-5向けに「安全補完(safe completions)」と呼ばれる新たな安全トレーニング方式を導入したと発表している。これは、安全範囲内で可能な限り役立つ回答を出すようモデルを訓練するものだ。時には、ユーザーの質問に部分的にしか答えず、あるいは高レベルの回答のみを提供する場合もある。
拒否が必要な場合、トレーニング済みのGPT-5はその理由を透明に伝え、安全な代替案を提示する。
制御された実験およびOpenAIの実運用モデルにおいて、この安全補完方式はより繊細で、二重用途の問題をより適切に誘導でき、曖昧な意図に対する堅牢性が強化され、不要な過剰拒否が減少することが確認された。
OpenAIのポストトレーニング責任者Michelle Pokrass氏は、「GPT-5は、タスクが完了不可能であることを認識し、当て推量を避け、制限についてより明確に説明できるよう訓練されており、これにより以前のモデルと比べて根拠のない主張が減少しています」と述べた。
4種類の選択可能なChatGPTチャットプリセット性格を導入
OpenAIは、GPT-5が命令の実行能力を向上させ、カスタム命令の実行能力もそれに応じて向上したと説明している。すべてのChatGPTユーザー向けに、4種類のプリセット性格を持つ新しい研究プレビュー版を提供する。
初期の4つの性格オプション——皮肉屋(Cynic)、ロボット(Robot)、傾聴者(Listener)、マニア(Nerd)——はいずれも任意選択可能で、ユーザーは設定からいつでも調整でき、ChatGPTとユーザーのコミュニケーションスタイルを一致させられる。
これらの4つの性格は当初テキストチャットに適用され、その後音声チャットへと拡大される予定で、ユーザーはカスタムプロンプトを書くことなく、簡潔でプロフェッショナルな、思いやりのあるサポートの、あるいは少しくだけた皮肉交じりの、といったChatGPTの対話スタイルを設定できる。
OpenAIは、これらすべての新性格が、媚びる行動を減らすための社内評価基準を満たしている、またはそれを上回っていると述べている。
Altmanが歴史的ブレイクスルーと絶賛 GPT-4に戻った途端に酷い結果に
今週木曜日のブリーフィングで、AltmanはGPT-5を極めて高く評価し、AGIへの道における重要なマイルストーンであると位置づけた。彼はこう述べた。
「これまでのどの時代においても、GPT-5のようなものが存在することは想像できなかった。」「初めて、あらゆる分野の専門家と会話しているような感覚になる。」
Altmanは、GPT-5を称賛するために、わざわざGPT-4を貶める発言さえした。
「私はGPT-4に戻って使ってみたが、結果は非常にひどかった。」
GPT-5は統一されたシステムアーキテクチャを採用しており、リアルタイムルーターを備えており、会話のタイプ、複雑さ、ツールの必要性に応じて、即時応答か深層的な「思考」かを自動的に判断できる。これにより、ユーザーが適切な設定を選択する必要がなくなり、ChatGPTの使いやすさが向上する。
経済的価値創出に関する社内ベンチマークテストでは、推論モードを使用するGPT-5は、法律、物流、営業、工学など40以上の職業において、およそ半数のケースで専門家並み、あるいはそれ以上のパフォーマンスを発揮した。OpenAIのVP Nick Turleyは「このモデルの感触は本当に素晴らしい」と語った。
Altmanは、GPT-5を使うことは、常に博士号を持つ専門家チームを擁しているようなものだと比喩した。また、「多くの新しい分野では、人々はアイデアに制限されているが、実際には実行力がない。」とも述べた。
マイクロソフトが全面統合で先手を取る
マイクロソフトは、GPT-5発表当日に、これを幅広い製品ラインに統合することを発表した。企業向けアプリケーションでは、Microsoft 365 CopilotがGPT-5を活用して複雑な問題をより適切に処理し、長い会話でも集中力を維持し、ユーザーの文脈を理解できるようになる。企業ユーザーは推論機能を使ってメール、ドキュメント、ファイルを処理できる。
一般ユーザー向けには、Microsoft Copilotの新スマートモードがGPT-5を活用して最適な解決策を発見するのを支援する。ユーザーはcopilot.microsoft.com、またはWindows、Mac、Android、iOSデバイスのCopilotアプリを通じて無料でGPT-5を体験できる。

開発者はGitHub CopilotおよびVisual Studio Codeを通じてGPT-5のサポートを受け、コードの作成、テスト、展開が可能になる。Azure AI FoundryプラットフォームはすべてのGPT-5モデルを提供し、AI駆動のモデルルーターが各タスクの複雑さ、パフォーマンス要件、コスト効率に応じて最適なモデルを選択する。
マイクロソフトAIレッドチームは厳格なセキュリティプロトコルを用いてGPT-5推論モデルをテストした結果、悪意あるソフトウェア生成、詐欺の自動化など複数の攻撃パターンにおいて、OpenAIの歴代モデル中最も強固なAIセキュリティ設定の一つを備えていることが判明した。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News














