

アリババQwen3が世界のオープンソースNo.1に登り詰め、DeepSeek-R1を圧倒。わずか2時間でスター数が17,000を超える大反響
TechFlow厳選深潮セレクト
アリババQwen3が世界のオープンソースNo.1に登り詰め、DeepSeek-R1を圧倒。わずか2時間でスター数が17,000を超える大反響
Qwen3は人間の好みにより合致しており、創造的な文章作成、キャラクター演技、マルチターン対話および指示の遵守に長けており、より自然で魅力的かつリアルな対話体験を提供します。
著者:新智元

【新智元リード】アリババのQwen3が深夜にオープンソース化され、正式に世界のオープンソース大規模モデル王座に登頂!その性能はDeepSeek-R1およびOpenAI o1を全面的に凌駕し、MoEアーキテクチャを採用、総パラメータ数は235Bで、主要ベンチマークを席巻した。今回オープンソース化されたQwen3ファミリーでは、8種類のハイブリッド推論モデルがすべてオープンソースとなり、商用利用も無料。
本日未明、世界中から注目されていたアリババの次世代通義千問モデル「Qwen3」がついにオープンソース化された!
登場と同時に、即座に世界最強のオープンソースモデルの座を獲得した。
そのパラメータ量はDeepSeek-R1のわずか1/3ながら、コストは大幅に削減され、R1やOpenAI-o1など世界トップクラスのモデルを性能面で全面的に上回っている。
Qwen3は中国国内初の「ハイブリッド推論モデル」であり、「速い思考」と「遅い思考」を一つのモデルに統合。簡単な要求には低計算資源で「瞬時回答」でき、複雑な問題に対しては多段階の「深層思考」を行うことが可能で、計算資源の消費を大幅に節約できる。
MoE(混合専門家)アーキテクチャを採用しており、総パラメータ数は235B、活性化パラメータは22Bのみである。
事前学習データ量は36兆トークンに達し、後期学習段階では複数回の強化学習を通じて、非思考モードを思考モデルにシームレスに統合している。
誕生直後、Qwen3は主要なベンチマークテストを一掃した。
さらに、性能が大幅に向上した一方で、展開コストも大きく低下しており、Qwen3のフルバージョンを展開するにはH20 GPUをたった4枚使用すればよく、メモリ使用量は同等性能のモデルのわずか1/3に抑えられている!
主な特徴まとめ:
・ 0.6B、1.7B、4B、8B、14B、32Bおよび30B-A3B、235B-A22Bなど、さまざまなサイズの密行列モデルとMoE(混合専門家)モデル。
・ 複雑な論理的推論、数学、コーディング用の「思考モード」と、効率的な汎用チャット用の「非思考モード」をシームレスに切り替え可能で、あらゆるシーンで最適なパフォーマンスを実現。
・ 数学、コード生成、常識的論理推論などの分野での推論能力が顕著に強化され、以前の思考モード下のQwQおよび非思考モード下のQwen2.5 instructモデルを凌駕。
・ 人間の好みにより適合し、クリエイティブライティング、ロールプレイ、マルチターン対話、指示遵守に優れており、より自然で魅力的かつリアルな対話体験を提供。
・ AIエージェント機能に精通し、思考および非思考モード両方において外部ツールとの正確な統合をサポート。複雑なエージェントベースのタスクにおいて、オープンソースモデルの中で最先端のパフォーマンスを達成。
・ 初めて119言語および方言をサポートし、強力な多言語指示遂行および翻訳能力を持つ。
現在、Qwen3はModelScopeコミュニティ、Hugging Face、GitHubにも同時に公開されており、オンラインでの体験も可能。
全世界の開発者、研究機関、企業はいずれも無料でモデルをダウンロードして商用利用でき、またアリクラウド百錬を通じてQwen3のAPIサービスを呼び出すことも可能。個人ユーザーは通義APPですぐにQwen3を体験可能で、Kuaich(クァイチャー)も近日中に全面的にQwen3を搭載予定。
オンライン体験:
ModelScopeコミュニティ:
https://modelscope.cn/collections/Qwen3-9743180bdc6b48
Hugging Face:
https://huggingface.co/collections/Qwen/qwen3-67dd247413f0e2e4f653967f
GitHub:
https://github.com/QwenLM/Qwen3
これにより、アリババ通義はこれまでに200以上のモデルをオープンソース化し、全世界でのダウンロード回数は3億回を超え、千問派生モデル数は10万を超えており、米国Llamaを完全に凌駕し、世界第1のオープンソースモデルとなった!
Qwen3ファミリー登場
8種の「ハイブリッド推論」モデルすべてがオープンソース
今回、アリババは一挙に8種のハイブリッド推論モデルをオープンソース化。30B、235BのMoEモデル2種類と、0.6B、1.7B、4B、8B、14B、32Bの6種類の密行列モデルを含み、すべてApache 2.0ライセンスを採用。
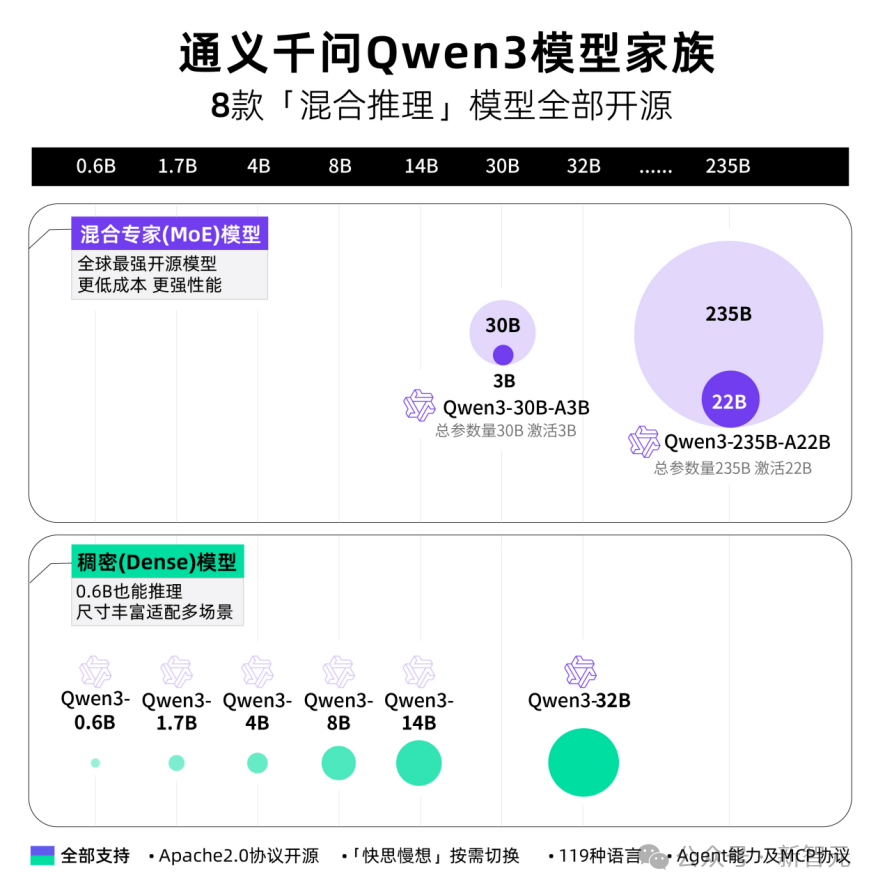
各モデルとも、同規模のオープンソースモデルでSOTA(最新最良)を達成している。
Qwen3の30BパラメータMoEモデルは、10倍以上のモデル性能レバレッジを実現。活性化パラメータわずか3Bで、前世代のQwen2.5-32Bモデルと同等の性能を発揮。
Qwen3の密行列モデルの性能もさらなる突破を遂げており、半分のパラメータ量で同等の高性能を実現。例えば、32B版Qwen3モデルは、Qwen2.5-72Bの性能を越える。
同時に、すべてのQwen3モデルはハイブリッド推論モデルであり、APIを通じて「思考予算」(最大深層思考のトークン数)を必要に応じて設定可能で、異なる程度の思考処理を行い、AIアプリケーションやさまざまなシナリオにおける性能とコストの多様なニーズに柔軟に対応できる。
例えば、4Bモデルはスマートフォン端末向けに最適なサイズ。8BはPCや車載端末へのスムーズな展開が可能。32Bは企業による大規模展開に最も人気があり、条件を満たす開発者であれば比較的簡単に導入可能。
オープンソースモデルの新王者、記録更新
Qwen3は推論、指示遵守、ツール呼び出し、多言語能力などで大幅に強化され、中国製モデルおよび世界のオープンソースモデルにおける新たな性能記録を樹立した――
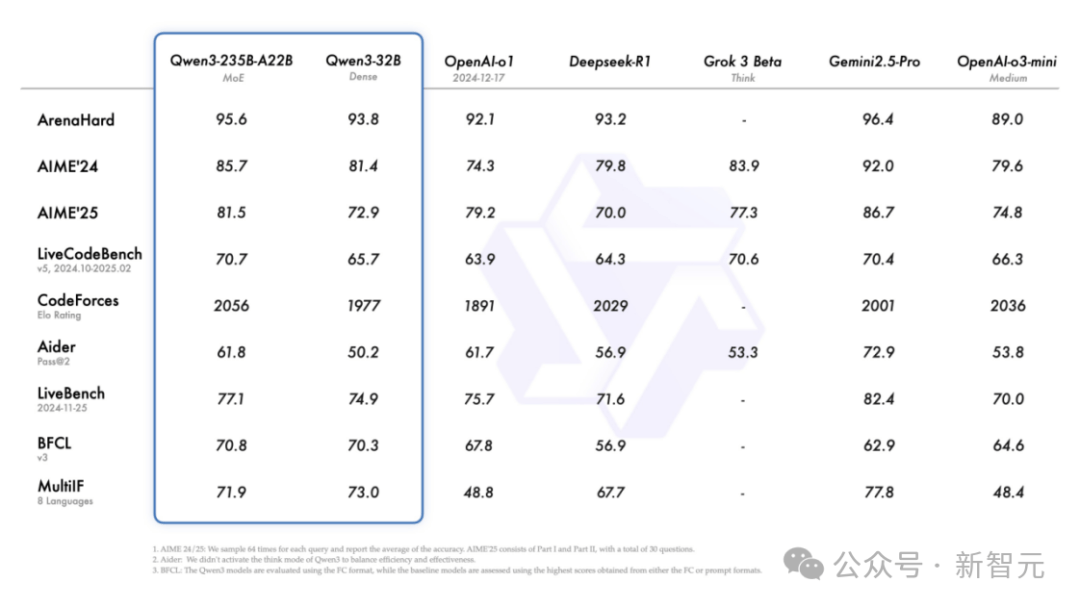
数学オリンピックレベルのAIME25評価テストでは、Qwen3が81.5点を獲得し、オープンソースモデルの記録を更新。
コード能力を測るLiveCodeBench評価では、Qwen3が70点の大台を突破し、Grok3を上回る結果を示した。
モデルの人間好みとの整合性を評価するArenaHardテストでは、Qwen3が95.6点を記録し、OpenAI-o1およびDeepSeek-R1を上回った。

具体的には、フラッグシップモデルQwen3-235B-A22Bは、DeepSeek-R1、o1、o3-mini、Grok-3、Gemini-2.5-Proなどのトップクラスモデルと比較しても、コーディング、数学、汎用能力などの各種ベンチマークテストで非常に優れた成績を収めている。
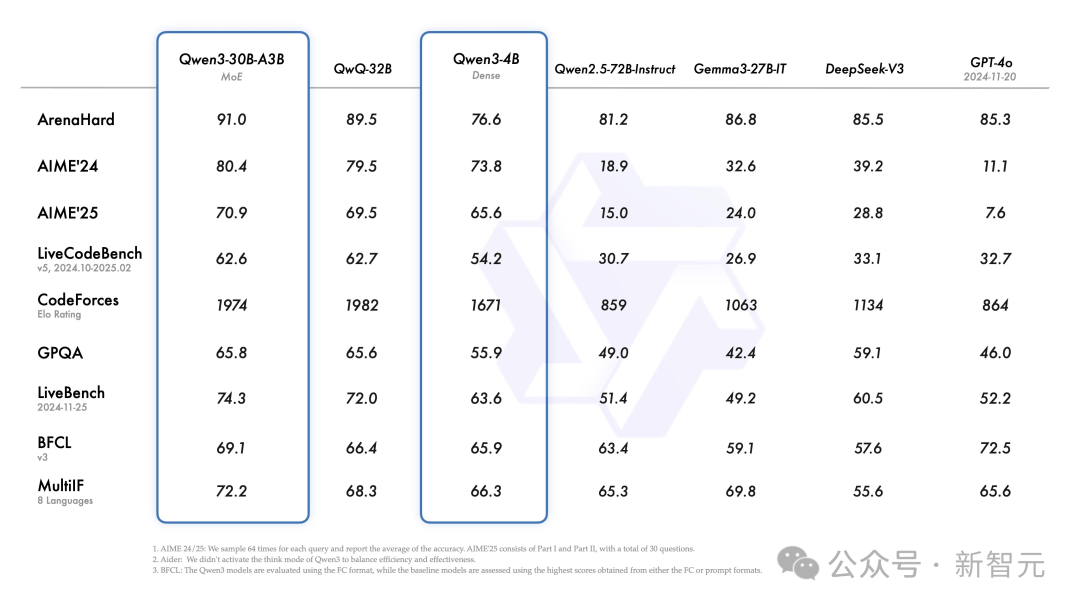
さらに、小型MoEモデルQwen3-30B-A3Bは、QwQ-32Bの活性化パラメータのわずか1/10ながら、性能はそれを上回っている。
Qwen3-4Bのような小型モデルでも、Qwen2.5-72B-Instructモデルと同等の性能を発揮できる。
微調整済みモデル(例:Qwen3-30B-A3B)およびその事前学習バージョン(例:Qwen3-30B-A3B-Base)は、現在Hugging Face、ModelScope、Kaggleなどのプラットフォームで入手可能。
展開に関しては、アリババがSGLangおよびvLLMなどのフレームワークの使用を推奨。ローカル使用には、Ollama、LMStudio、MLX、llama.cpp、KTransformersなどのツールが強く推奨されている。
研究、開発、あるいは本番環境を問わず、Qwen3はあらゆるワークフローに容易に統合可能。
エージェント(Agent)および大規模モデルアプリケーションの爆発的普及に追い風
Qwen3は、目前に迫ったエージェント(Agent)および大規模モデルアプリケーションの爆発的普及を支える強力な基盤を提供していると言える。
モデルのエージェント能力を評価するBFCLベンチマークでは、Qwen3が70.8という新たな最高得点を記録し、Gemini2.5-Pro、OpenAI-o1といったトップモデルを上回り、エージェントのツール呼び出しのハードルを大幅に下げることになる。
同時に、Qwen3はネイティブにMCPプロトコルをサポートし、強力なツール呼び出し能力を持つ。これに加え、ツール呼び出しテンプレートおよび解析器を内包するQwen-Agentフレームワークによって、コーディングの複雑さを大きく低減し、スマートフォンおよびPCでの効率的なエージェント操作などのタスクを実現可能にする。
主な特徴
ハイブリッド推論モード
Qwen3モデルは、ハイブリッド型の問題解決方式を導入している。以下の2つのモードをサポート:
1. 思考モード:このモードでは、モデルが段階的に推論を行い、その後回答を出力。深い思考を要する複雑な問題に適している。
2. 非思考モード:このモードでは、モデルが迅速に回答を出力。速度が求められる簡単な問題に適している。
この柔軟性により、ユーザーはタスクの複雑さに応じて、モデルの推論プロセスを制御できる。
例えば、難しい問題は拡張された推論によって解決され、一方で簡単な問題は遅延なく直接回答される。
特に重要なのは、この2つのモードの統合により、モデルが推論リソースを安定かつ効率的に制御する能力が大きく向上したことである。
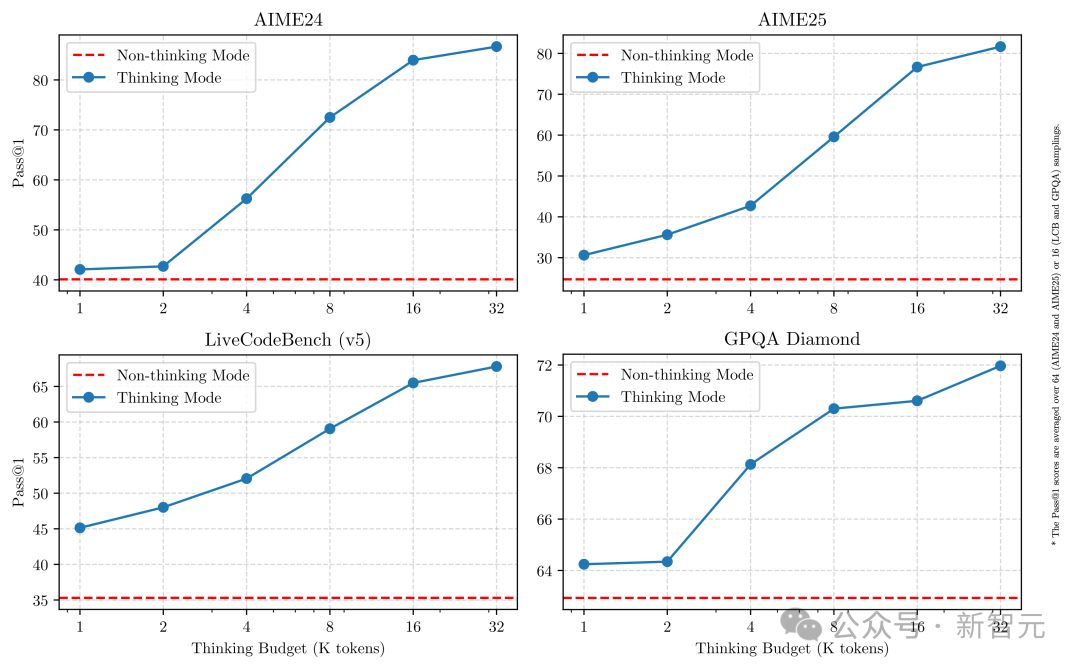
上図のように、Qwen3は割り当てられた計算推論予算に直接関連して、スケーラブルかつ滑らかな性能改善を示している。
この設計により、ユーザーは特定のタスクに応じた予算を簡単に設定でき、コスト効率と推論品質の間でより最適なバランスを実現できる。
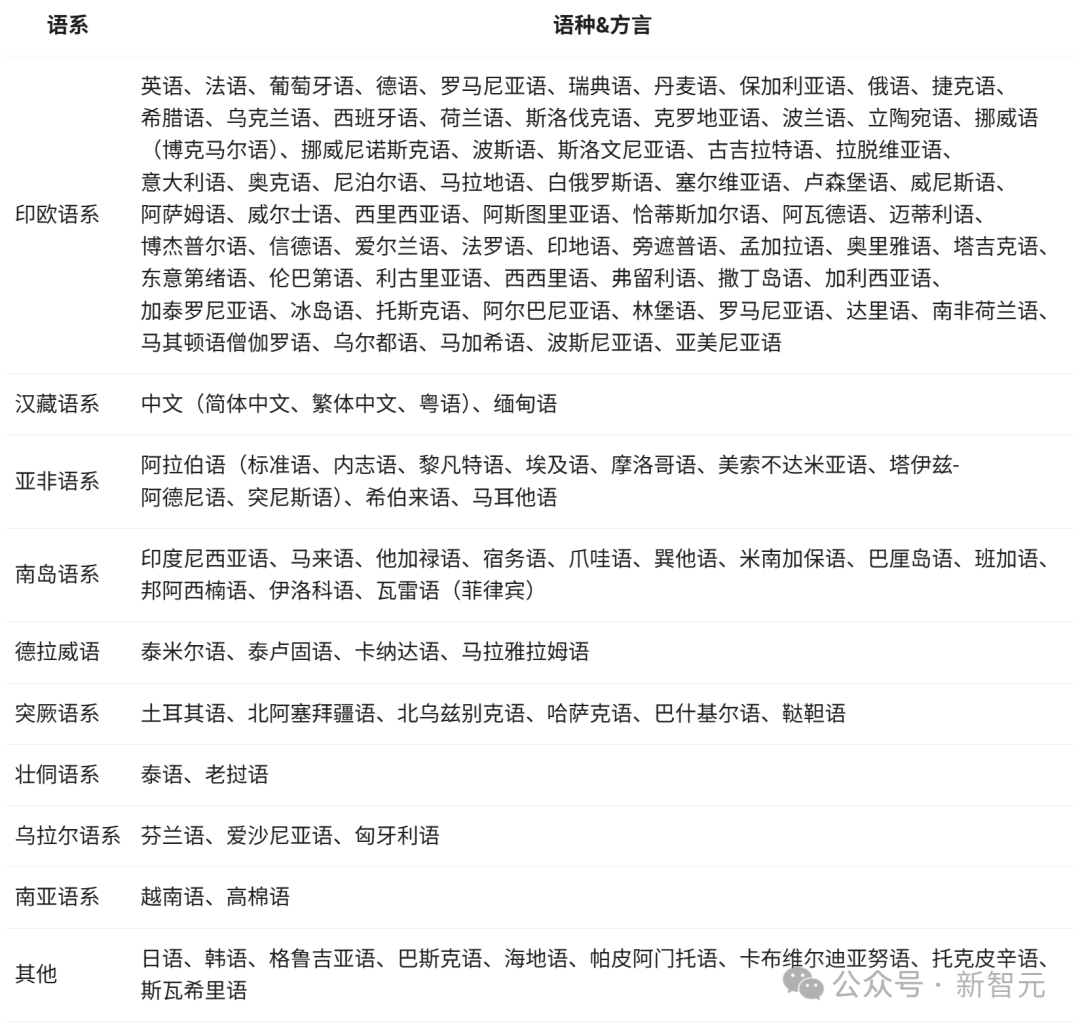
多言語対応
Qwen3モデルは119言語および方言をサポート。
これほど広範な多言語能力を持つことで、Qwen3は世界的に流行する国際アプリケーションの作成に極めて大きな可能性を秘めている。
さらに強化されたエージェント能力
アリババはQwen3モデルを最適化し、コーディングおよびエージェント能力を向上させるとともに、MCPサポートも強化している。
以下の例は、Qwen3がどのように思考し、環境と相互作用するかをよく示している。
36兆トークン、多段階トレーニング
千問シリーズ最強のモデルとして、Qwen3はいかにしてこれほど驚異的なパフォーマンスを実現したのか?
ここからは、Qwen3の裏側にある技術的詳細を探ってみよう。
事前学習
Qwen2.5と比較して、Qwen3の事前学習データセット規模は前世代のほぼ2倍となり、18兆トークンから36兆トークンに拡大した。
119言語および方言をカバーしており、ウェブからの情報だけでなく、PDFなどの文書から抽出されたテキストコンテンツも含まれる。
データ品質を確保するため、チームはQwen2.5-VLを使用して文書テキストを抽出し、Qwen2.5で抽出内容の正確性を最適化している。
さらに、数学およびコード分野でのモデルのパフォーマンスを向上させるために、Qwen2.5-MathおよびQwen2.5-Coderを活用して大量の合成データ(教科書、QAペア、コードスニペットなど)を生成している。
Qwen3の事前学習プロセスは、モデルの能力を段階的に高めるために、全部で3段階に分けられている:
第一段階(S1):基本言語能力構築
30兆を超えるトークンを使用し、4kのコンテキスト長で事前学習。この段階で、モデルに堅固な言語能力および一般的知識の基礎を築く。
第二段階(S2):知識集中型最適化
STEM、コーディング、推論タスクなどの知識集中型データの比率を増やし、追加の5兆トークンで継続的に学習させ、専門的能力のパフォーマンスをさらに向上。
第三段階(S3):コンテキスト能力拡張
高品質なコンテキストデータを活用し、モデルのコンテキスト長を32kまで拡張することで、複雑かつ超長の入力を処理できるようにする。
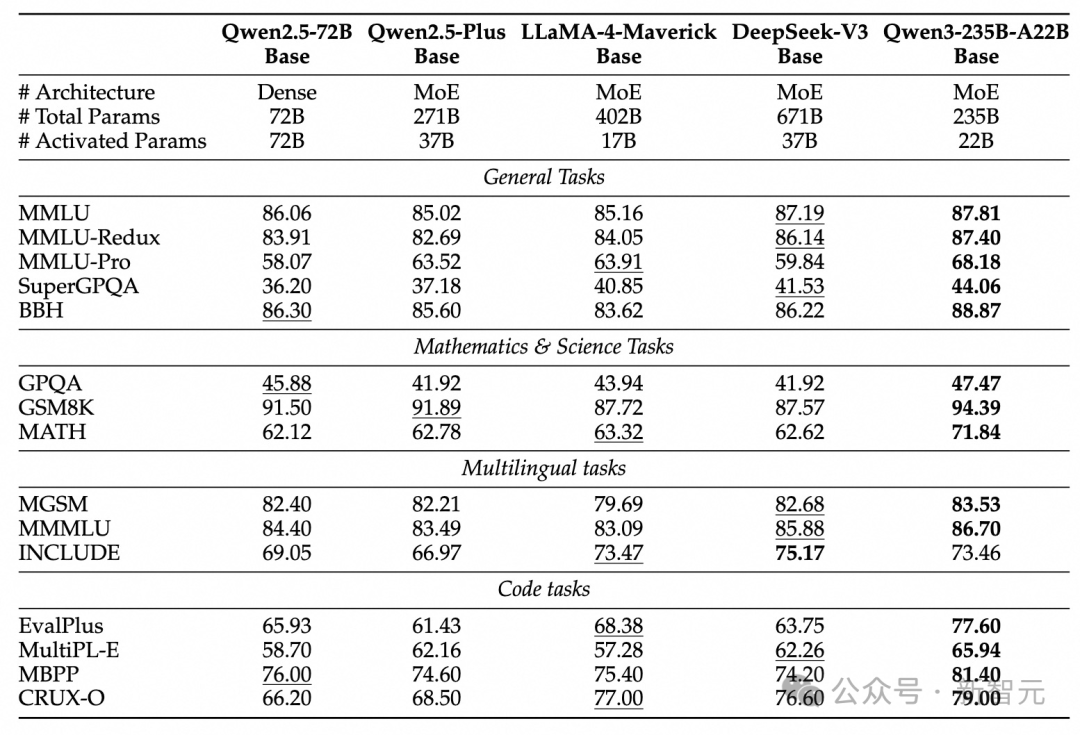
モデルアーキテクチャの最適化、データ規模の拡大、より効率的な学習手法のおかげで、Qwen3 Denseベースモデルは目覚ましいパフォーマンスを発揮。
以下の表に示す通り、Qwen3-1.7B/4B/8B/14B/32B-Baseは、Qwen2.5-3B/7B/14B/32B/72B-Baseと同等の性能を発揮し、より少ないパラメータでより大きなモデルと同等の水準に到達。
特に、STEM、コーディング、推論などの分野では、Qwen3 Denseベースモデルはより大きなQwen2.5モデルを上回る性能を示している。
さらに注目すべきは、Qwen3 MoEモデルは活性化パラメータの10%しか使用しないにもかかわらず、Qwen2.5 Denseベースモデルと同等の性能を達成している点だ。
これはトレーニングおよび推論コストを大幅に削減するだけでなく、モデルの実際の展開にも高い柔軟性を提供している。
後期学習
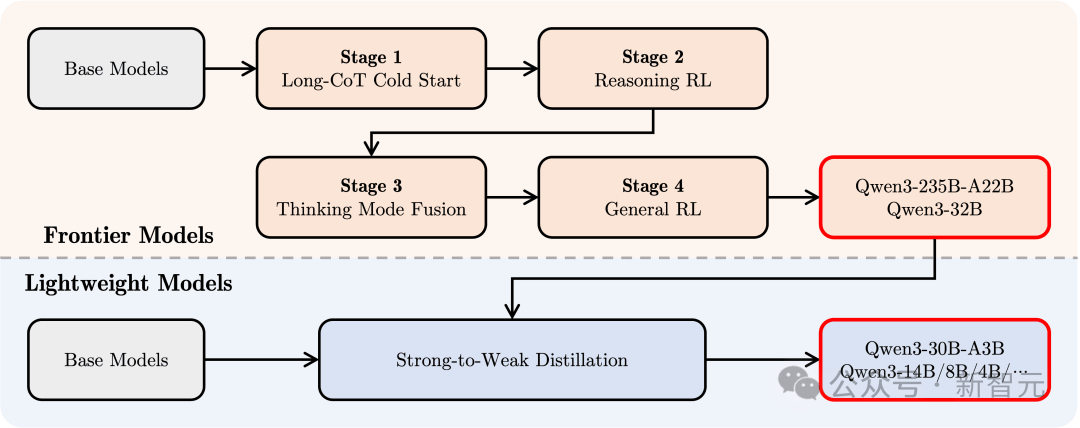
複雑な推論が可能でありながら、迅速に応答できるハイブリッドモデルを構築するため、Qwen3は4段階の後期学習プロセスを設計している。
1. 長チェイン思考コールドスタート
数学、コーディング、論理的推論、STEM問題などを網羅する多様な長チェイン思考データを使用し、モデルに基本的な推論能力を習得させる。
2. 長チェイン思考強化学習
強化学習(RL)の計算リソースを拡張し、ルールに基づく報酬メカニズムを組み合わせることで、モデルが推論パスの探索および活用能力を向上させる。
3. 思考モード融合
長チェイン思考データと命令微調整データを用いて微調整を行い、迅速な反応能力を推論モデルに統合。これにより、複雑なタスクにおいても正確かつ効率的であることを保証。
このデータは第2段階の強化された思考モデルによって生成されており、推論能力と迅速な応答能力のシームレスな融合を確実にしている。
4. 汎用強化学習
指示遵守、フォーマット遵守、エージェント能力など20以上の汎用領域タスクでRLを適用し、モデルの汎用性およびロバスト性をさらに向上させるとともに、不適切な振る舞いを修正。
ネット全体で絶賛の声
Qwen3がオープンソース化されてから3時間も経たないうちに、GitHubで17,000スターを獲得し、オープンソースコミュニティの熱意を完全に点燃した。開発者たちは次々とダウンロードを始め、高速テストが続々と開始されている。
プロジェクトページ:
https://github.com/QwenLM/Qwen3
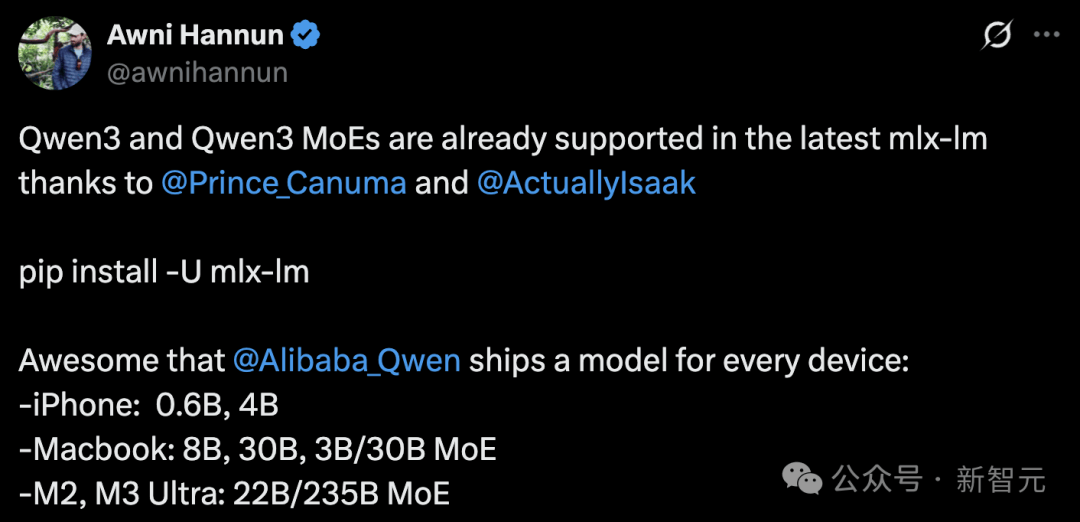
AppleのエンジニアAwni Hannun氏は、Qwen3がMLXフレームワークでサポートされたことを発表。
また、iPhone(0.6B, 4B)、MacBook(8B, 30B, 3B/30B MoE)、M2/M3 Ultra(22B/235B MoE)などの民生用デバイスでも、すべてローカルで実行可能。
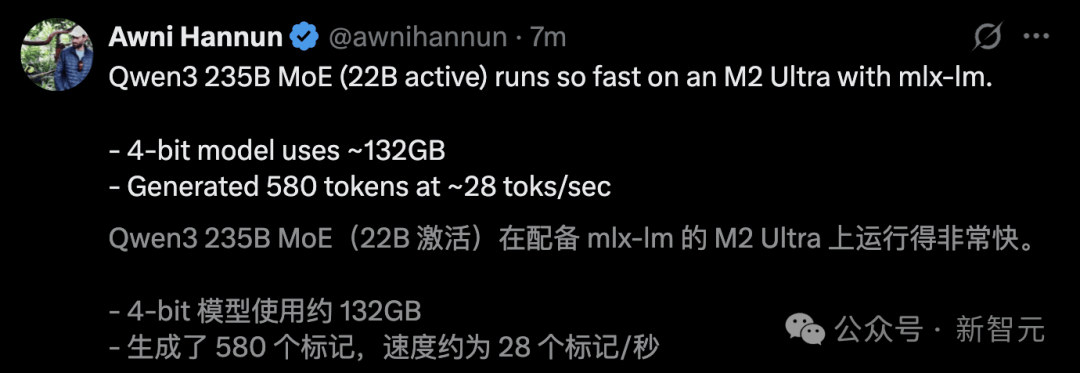
M2 Ultra上でQwen3 235B MoEを実行したところ、生成速度は最大28トークン/秒に達した。
あるユーザーが実測した結果によると、同じサイズのLlamaモデルと比べて全く別次元の存在。前者はより深い推論ができ、長いコンテキストを維持でき、より難しい問題を解決できる。

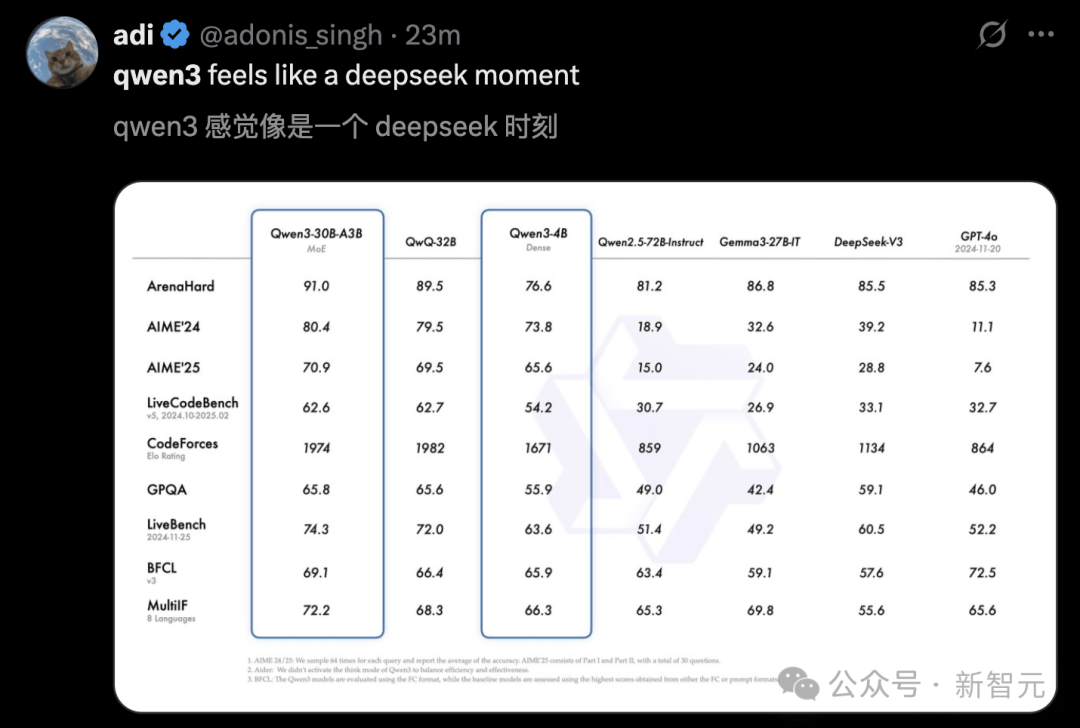
また、「Qwen3はまるでDeepSeekの瞬間のようだ」と述べる声もある。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News













