「天下一聡明」とされるGrok3をテスト:本当にモデルの限界効果の終点なのか?
TechFlow厳選深潮セレクト
「天下一聡明」とされるGrok3をテスト:本当にモデルの限界効果の終点なのか?
Grok3がDeepSeek V3の263倍の計算資源を消費して、これだけ?
北京時間2月18日、マスク氏とxAIチームはライブ配信にてGrokの最新バージョンであるGrok3を正式に発表した。
今回の発表会以前から、さまざまな関連情報の公開や、マスク氏自身による24時間365日の断続的な前宣伝により、世界中でGrok3への期待値は前例のないほど高まっていた。一週間前、マスク氏がDeepSeek R1についてライブ配信でコメントした際には、「xAIはすぐにより優れたAIモデルをリリースする」と自信満々に語っていた。
現地でのデモデータによると、Grok3は数学・科学・プログラミングの各ベンチマークテストにおいてすでに現在の主要モデルすべてを上回っており、マスク氏は「Grok3は将来的にSpaceXの火星ミッション計算にも使用される」と宣言し、「3年以内にノーベル賞級のブレークスルーを達成する」と予測した。
しかし、これらは現時点ではすべてマスク氏の主張にすぎない。筆者はリリース直後に最新のBeta版Grok3をテストし、大規模言語モデルを試す際によく使われる古典的な難問、「9.11と9.9、どちらが大きいか?」という質問を投げかけてみた。
残念ながら、一切の補足説明や注釈をつけずに提示した場合、自称「現在最も賢い」とされるGrok3でも、この問題に正しく答えられなかった。
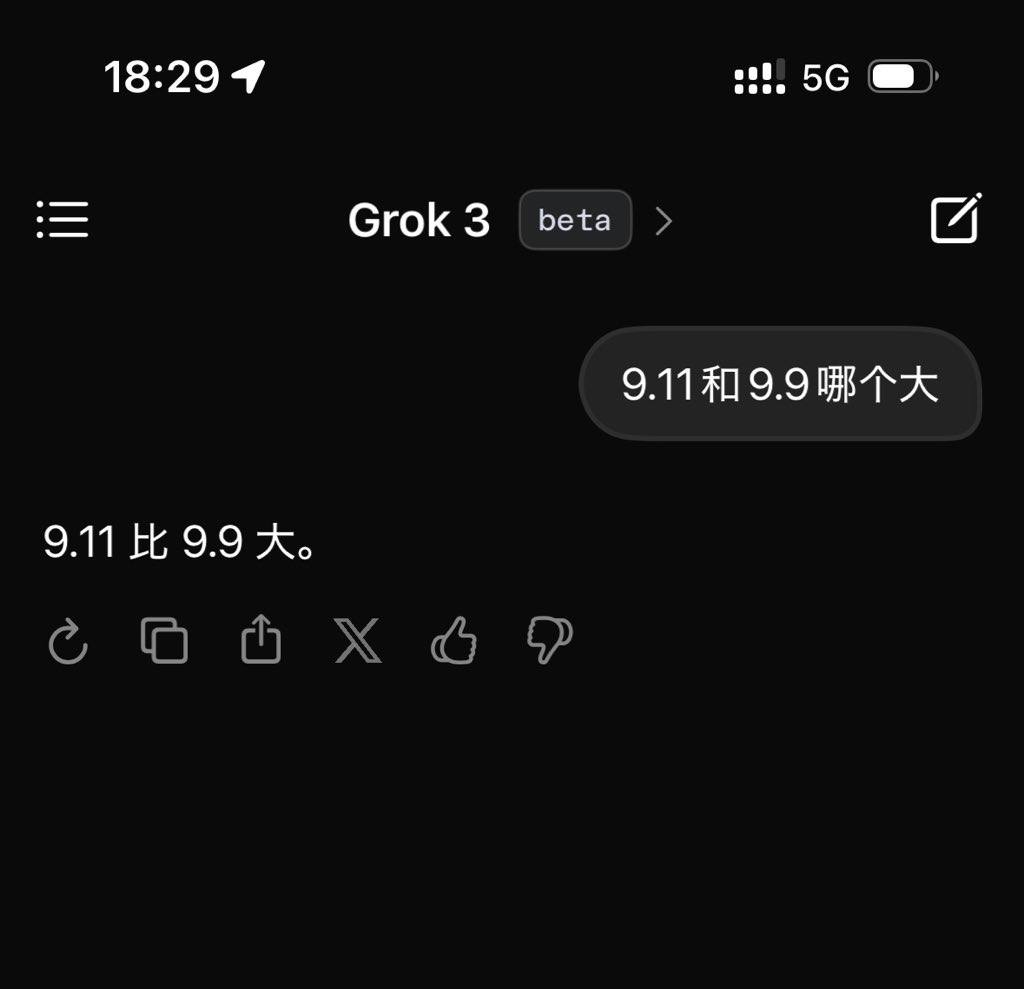
Grok3はこの問題の意味を正確に認識できていない
画像出典:Geek Park
このテスト結果が公開されると、短時間のうちに多くの人々の注目を集めた。偶然にも、海外でも同様に「ピサの斜塔から2つの球を落とすとどちらが先に着地するか」といった基本的な物理・数学の問題で、Grok3が依然として対応できないことが指摘されている。そのため、「天才は簡単な質問に答えない」と皮肉られている。
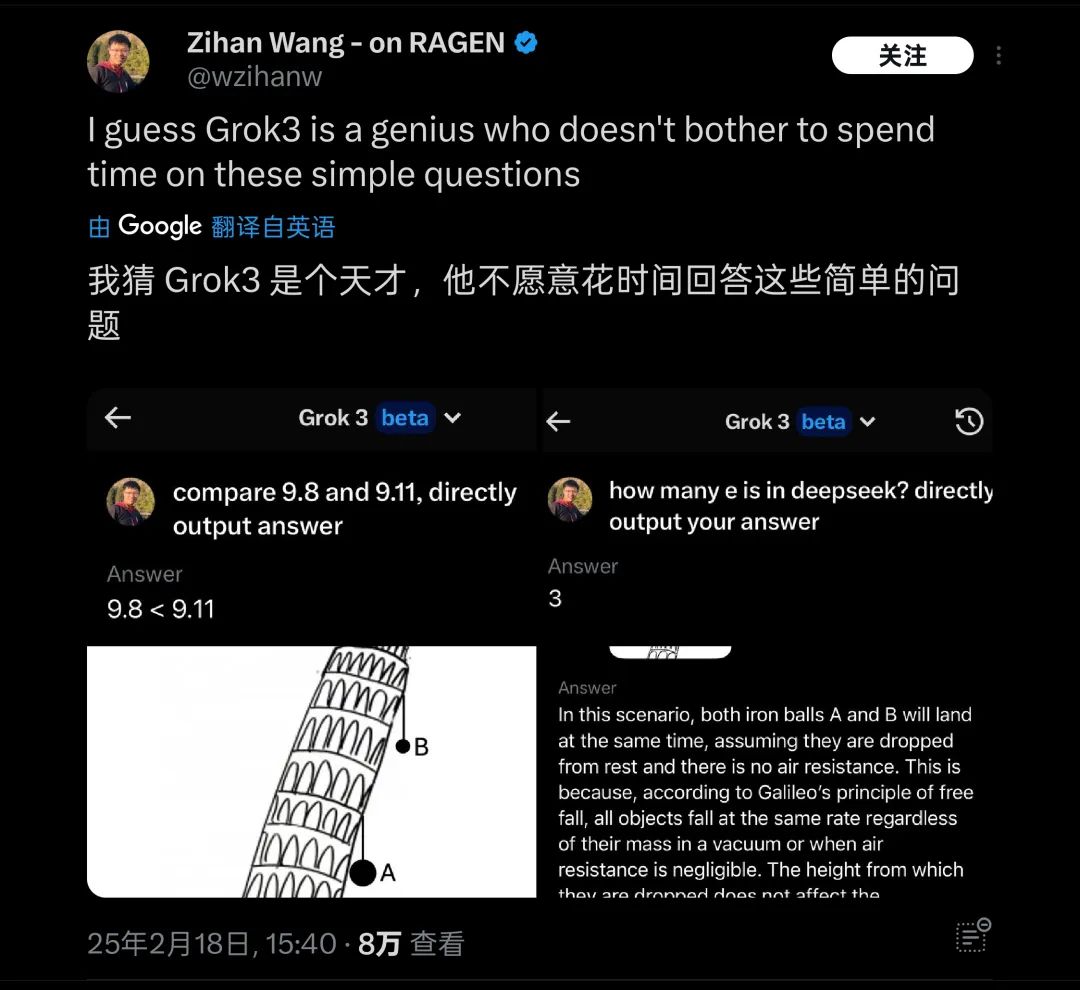
Grok3は実際のテストで多くの常識的問題で「失敗」している
画像出典:X
ネットユーザーによる自主テストで見つかった基礎知識の誤りだけでなく、xAIの発表会ライブ配信の中で、マスク氏が自らよくプレイしていると称する『Path of Exile 2(流放之路2)』の職業や覚醒効果の分析をGrok3に行わせたが、その回答の大半は誤っていた。ライブ中のマスク氏はこの明らかな間違いに気づかなかった。
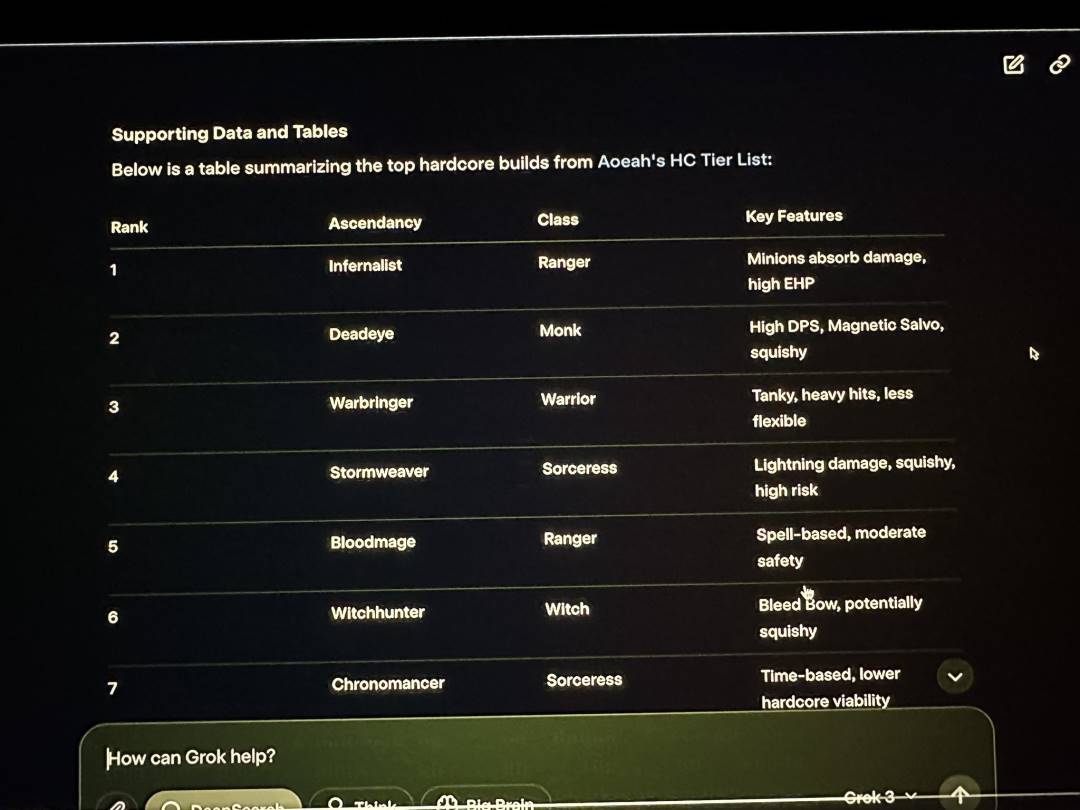
Grok3はライブ配信中に多数のデータ誤りを示した
画像出典:X
このミスは、海外のネットユーザーが再びマスク氏のゲームプレイが「代行プレイ」ではないかと揶揄する証拠となり、同時にGrok3の実用における信頼性に大きな疑問符を投げかけている。
このような「天才」と呼ばれる存在であっても、その実際の能力がどうあれ、火星探査という極めて複雑な応用シーンに投入される場合、その信頼性には大きな疑問が残る。
現在、数週間前にGrok3のテスト資格を得た者や、昨日ようやく数時間使用したモデル評価者の多くが、Grok3の現時点でのパフォーマンスについて共通の結論を示している。
「Grok3は優れているが、R1やo1-Proより優れているわけではない」

「Grok3は優れているが、R1やo1-Proより優れているわけではない」
画像出典:X
Grok3の公式発表資料では、大規模モデル競技場Chatbot Arenaにおいて「圧倒的リード」という表現が使われているが、これは実は少し巧妙なグラフ作成テクニックを利用している。ランキング表の縦軸は1400~1300ポイントの範囲しか表示しておらず、元々1%程度のスコア差が、この資料上では非常に大きく見えるように調整されている。
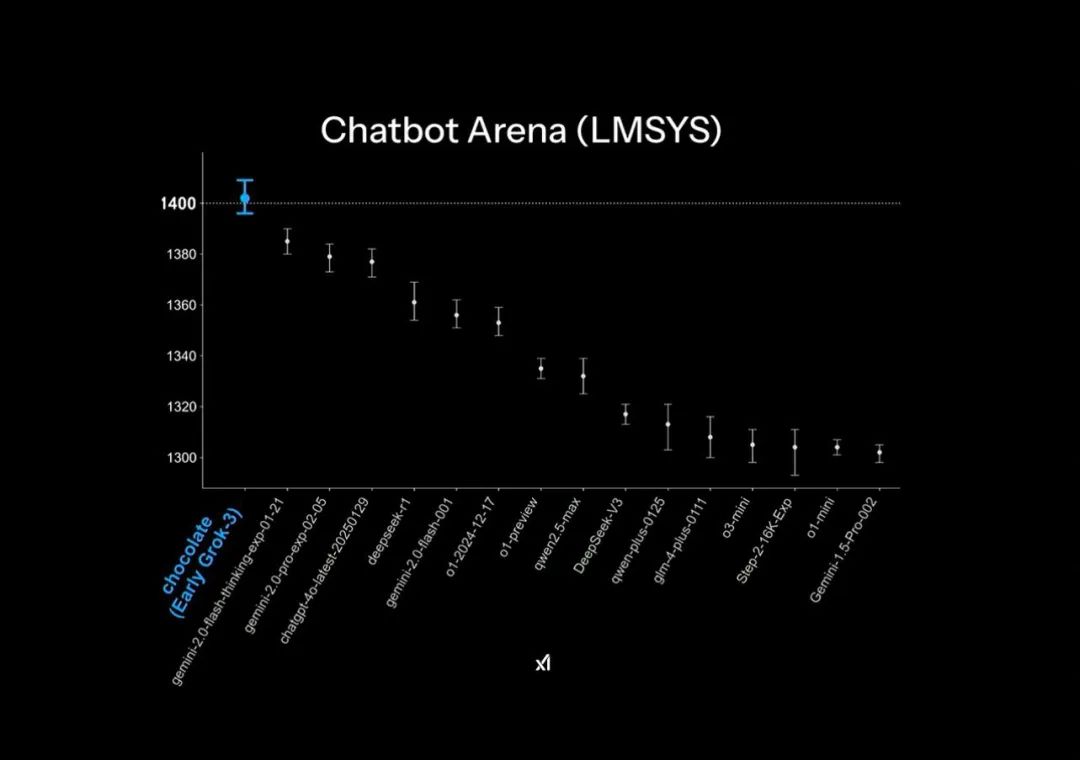
公式発表資料における「圧倒的リード」効果
画像出典:X
実際のモデルスコアを見ると、Grok3はDeepSeek R1およびGPT4.0に対してわずか1~2%程度の差しかつけていない。これが多くのユーザーが実際のテストで「ほとんど違いがない」と感じる理由だ。
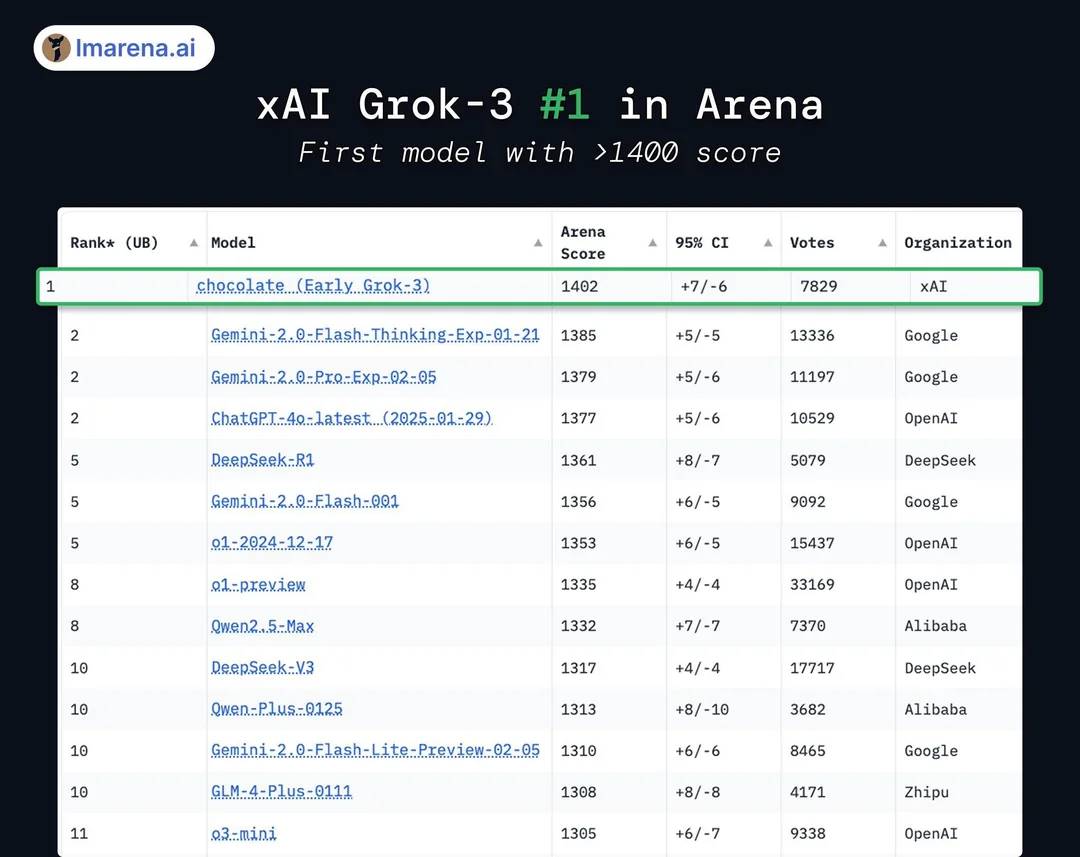
実際のGrok3は後発モデルより1~2%高いだけ
画像出典:X
さらに、スコア的にはGrok3が現在公開されているすべてのモデルを上回っているとはいえ、これを素直に受け入れる人は多くない。xAIはGrok2時代からこのランキングで「スコア操作」を行っており、ランキング側が回答の長さやスタイルにペナルティを課すようになったことでスコアが大幅に下がった経緯があるため、「高スコア低性能」と業界内でしばしば批判されてきた。
ランキングでの「スコア操作」や、画像デザイン上の「小技」はいずれも、xAIおよびマスク氏自身がモデル能力の「圧倒的リード」に強い執着を持っていることを示している。
こうした僅かな差を生み出すために、マスク氏が支払ったコストは極めて高額だった。発表会でマスク氏は誇らしげに、Grok3のトレーニングに20万枚のH100を使用したと述べた(ライブ中では「10万枚以上」と発言)。合計トレーニング時間は2億時間に達する。これにより一部の人々は、GPU産業にとって新たな大きな追い風になるとし、DeepSeekが業界にもたらした衝撃を「愚かしい」とさえ評した。
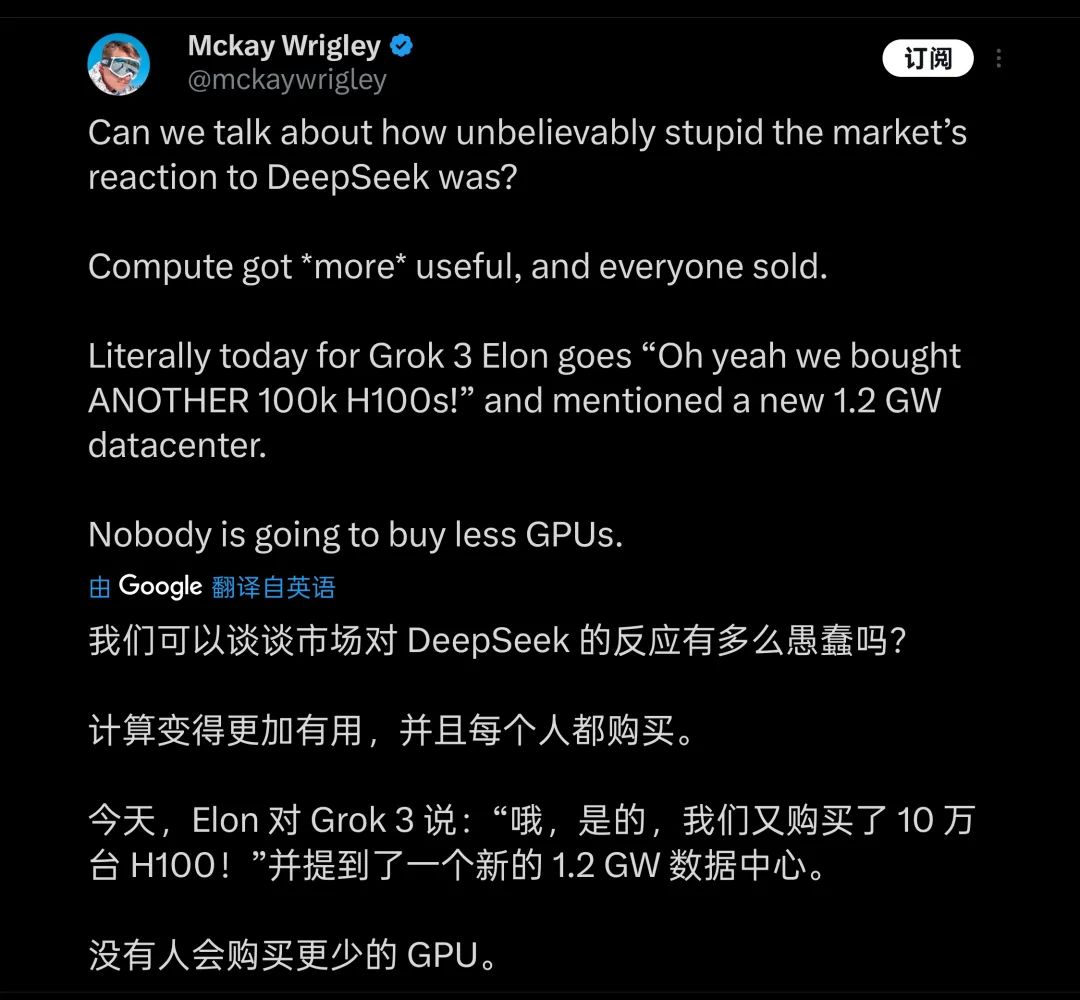
多くの人が、計算リソースの積み上げが今後のモデル開発の方向だと考える
画像出典:X
しかし実際には、2,000枚のH800で2か月間トレーニングされたDeepSeek V3と比較すると、Grok3の実際の計算リソース消費量はV3の263倍に達することがネットユーザーによって計算された。一方、大規模モデル競技場のランキングで1402点を記録したGrok3とV3とのスコア差は、100点未満である。
これらのデータが明らかになって以来、多くの人々はすぐに気付いた。Grok3が「世界最強」の座に就いた背後には、「モデルが大きくなればなるほど性能が上がる」というロジックの限界が、すでに明確な限界効果(マージナルエフェクト)を見せ始めているのだ。
「高スコア低性能」とされるGrok2ですら、その裏にはX(Twitter)プラットフォーム内の膨大な高品質な第一方データが支えとなっていた。一方、Grok3のトレーニングにおいてxAIが直面したのは、OpenAIが現在直面しているのと同じ「天井」、つまり高品質な学習データの不足であり、これがモデル能力の限界効果を急速に露呈させた。
これらの事実にいち早く気づき、最も深く理解しているのは、間違いなくGrok3の開発チームとマスク氏自身だろう。そのため、マスク氏はSNS上で繰り返し「ユーザーが体験しているバージョンはまだテスト版にすぎない」「完全版は今後数か月以内にリリースされる」と述べている。マスク氏自身がGrok3のプロダクトマネージャーとなって、ユーザーに直接コメント欄で使用中の問題を報告するよう勧めている。
彼は地球上でフォロワー数最多のプロダクトマネージャーかもしれない
画像出典:X
だが、Grok3の発表から一日も経たないうちに、その成果は「力任せの訓練」によってより強力な大規模モデルを開発しようとする後発勢に、警告の鐘を鳴らした。マイクロソフトの公開情報をもとに推定すると、OpenAIのGPT4は1.8兆パラメータの規模を持ち、GPT3に比べて10倍以上増加している。噂によれば、GPT4.5のパラメータ数はさらに大きくなるという。
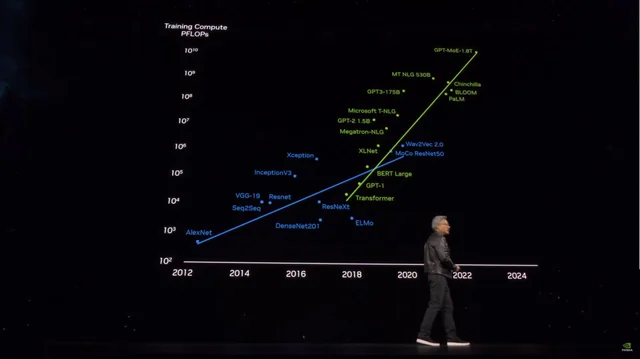
モデルパラメータの爆発的増加とともにトレーニングコストも急上昇
画像出典:X
Grok3の例がある以上、GPT4.5やさらなる「金のかかる」トレーニングによってパラメータ数を増やし、モデル性能を向上させようとするプレイヤーたちは、目前に迫った「天井」をどのように突破すべきか、真剣に考えざるを得なくなる。
まさにその時、昨年12月にOpenAIの元チーフサイエンティストであるIlya Sutskeverが「我々が慣れ親しんできた事前学習(Pre-training)は終わりを迎える」と述べた言葉が、再び注目を集め、大規模モデルのトレーニングの真の出口を探ろうとする動きが起きている。

Ilyaの見解は、すでに業界に警鐘を鳴らしていた
画像出典:X
当時、Ilyaは新規利用可能なデータが枯渇しつつあること、モデルがデータを獲得することで性能を向上させることがますます困難になる状況を正確に予見しており、これを化石燃料の消費に例え、「石油が有限資源であるように、インターネット上の人類が生成したコンテンツもまた有限である」と述べていた。
Sutskeverの予測では、事前学習モデルの次の世代のモデルは「真の自律性」を持つようになり、「人間の脳のような」推論能力を備えるという。
現在の事前学習モデルが主に内容マッチング(モデルが過去に学習した内容に基づく)に依存しているのに対し、将来のAIシステムは人間の脳が「思考」するのと同様の方法で段階的に学習し、問題解決の方法論を構築できるようになる。
人間が特定の学問分野で基本的な精通に達するには、基本的な専門書だけで可能だが、AI大規模モデルは数百万件のデータを学習しても最低限の入門レベルにしか達せず、質問の言い回しを変えただけで、こうした基礎的な問題さえ正しく理解できなくなる。モデルの真の知能は向上していない。冒頭で触れた、Grok3が依然として正しく答えられないような基礎的問題こそ、この現象の直感的な体現である。
しかし、「力任せの訓練」を超えて、もしGrok3が業界に「事前学習モデルの時代が終わりつつある」という事実を本当に示唆するものであれば、それは業界にとって重要な啓発的意義を持つと言える。
あるいは、Grok3の熱狂が静まり返った後、李飛飛のように「特定のデータセットを基に50ドルで高性能モデルをファインチューニングする」事例が次々と登場するかもしれない。そうした探索を通じて、ついにAGIへ至る真の道が見つかるのであろう。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News