OpenAIのマルチタスクモデルGPT-4oがリアルタイムインタラクションで会場を震撼させ、SFの時代が到来した
TechFlow厳選深潮セレクト
OpenAIのマルチタスクモデルGPT-4oがリアルタイムインタラクションで会場を震撼させ、SFの時代が到来した
ChatGPTが登場してわずか17カ月で、OpenAIはSF映画に登場するようなスーパーエー・アイを無料で誰もが利用できる形で提供した。
執筆:機械の心
衝撃的すぎる!
各テクノロジー企業が大規模モデルのマルチモーダル機能を追いかけ、文書要約や画像編集(P図)などの機能をスマートフォンに搭載しようとしている中、一歩先んじてリードするOpenAIはいきなり大技を披露し、自社CEOのオルトマンですら「まるで映画のようだ」と驚嘆する新製品を発表した。

5月14日未明、OpenAIは初の「春季新製品発表会」を開催し、次世代フラッグシップ生成モデルGPT-4o、デスクトップアプリ、および一連の新機能を発表した。今回の発表は技術革新による製品形態の変革であり、OpenAIは世界中のテクノロジー企業に一石を投じた。
本日の司会はOpenAIのCTOであるミーラ・ムラティ。彼女は今日話すことを三つ紹介した:

-
第一に、今後OpenAIは製品開発において無料優先の方針を取る。これにより、より多くの人々が利用できるようにする。
-
第二に、そのためOpenAIは今回、デスクトップ版アプリと刷新されたUIをリリースした。使いやすさが向上し、より自然な操作感を実現している。
-
第三に、GPT-4に続く新バージョンの大規模モデル「GPT-4o」が登場した。GPT-4oの特徴は、極めて自然なインタラクションを通じて、すべての人々(無料ユーザーも含む)にGPT-4レベルの知能を提供する点にある。
今回のChatGPTアップデートにより、大規模モデルはテキスト、音声、画像の任意の組み合わせを入力として受け取り、リアルタイムでテキスト、音声、画像の任意の組み合わせを出力できるようになった――まさに未来型のインターフェースと言える。
最近、ChatGPTは登録なしでも利用可能になり、さらに本日デスクトップアプリも追加された。OpenAIの目標は、誰もがいつでもどこでもシームレスにChatGPTを使えるようにし、作業プロセスに自然に統合すること。現在のAIは、まさに生産性そのものだ。

GPT-4oは未来の人間と機械のインタラクションパラダイムを意識して設計された新大規模モデルであり、テキスト、音声、画像という3つのモダリティを理解でき、反応が非常に速く感情を帯びており、人間らしい対話が可能だ。
発表会では、OpenAIのエンジニアがiPhoneを使って新モデルの主な機能をデモンストレーションした。最も注目すべきはリアルタイム音声対話だ。Mark Chenは「初めてライブ配信の発表会に出るので、少し緊張しています」と話し、ChatGPTは「深呼吸してみたらどうですか?」と返答した。
「よし、深呼吸します。」
するとChatGPTは即座に、「それじゃダメですね、息遣いが大きすぎますよ」と答えた。
Siriのような音声アシスタントを使ったことのある人なら、ここでの違いが明らかだろう。まず、AIの発話を途中で遮って次の発話を始められる。待つ必要がないのだ。第二に、モデルの反応速度が非常に速く、人間よりも早い。第三に、モデルは人間の感情を十分に理解し、自身もさまざまな感情を表現できる。
次に視覚能力について。別のエンジニアが紙に手書きした方程式を見せ、答えを直接出すのではなく「どのように解けばいいか」を段階的に説明させる。これにより、問題の教え方に大きな可能性があることがわかった。

ChatGPT曰く、「数学に悩むときはいつでも、あなたのそばにいます」
次にGPT-4oのコード処理能力を試す。あるコードを用意し、デスクトップ版ChatGPTに音声で「これは何のコードか」「特定の関数は何をしているか」などと質問すると、すべて正確に回答した。
出力されたコードの結果は温度曲線グラフであり、ChatGPTに「このグラフに関するすべての質問を一文で答えてください」と指示しても、完璧に対応した。
最も暑い月はいつか、Y軸は摂氏か華氏か、といった問いにも正確に答えられた。
OpenAIはX/Twitter上でリアルタイムに寄せられたユーザーの疑問にも応えた。例えばリアルタイム音声翻訳では、スマートフォンを翻訳機のように使い、英語とスペイン語を双方向に翻訳できた。
また、「ChatGPTはあなたの表情を認識できますか?」という質問に対しては――
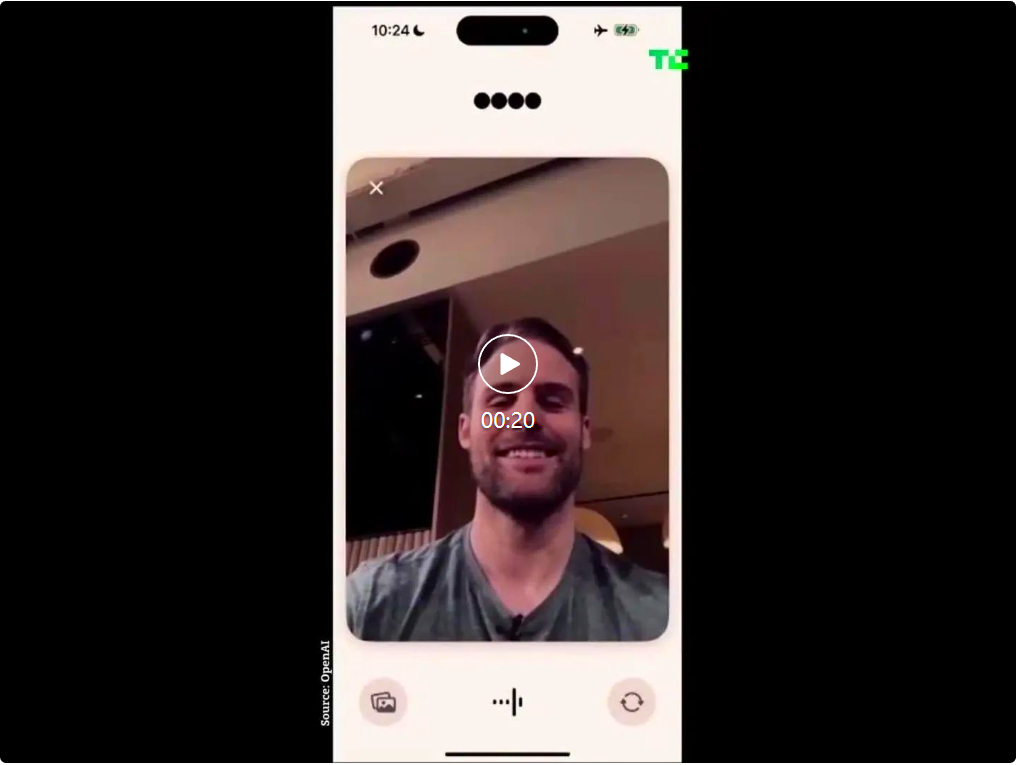
どうやらGPT-4oはすでにリアルタイムの動画理解が可能になっているようだ。
それでは、OpenAIが本日発表した“核兵器”の詳細を見ていこう。
オールラウンドモデル GPT-4o
まず紹介するのはGPT-4o。「o」はOmnimodel(オールラウンドモデル)を意味する。
初めて、OpenAIは一つのモデルにすべてのモダリティを統合し、大規模モデルの実用性を大きく高めた。
OpenAI CTOのMuri Muratiは、「GPT-4oは『GPT-4レベル』の知能を提供するが、GPT-4を基にテキスト、視覚、音声の能力を改善しており、今後数週間にわたり段階的に製品に導入される」と述べた。
「GPT-4oは音声、テキスト、視覚の理由づけを横断的に扱う」とMuri Muratiは語った。「モデルがますます複雑化していることはわかっていますが、私たちが目指すのは、より自然でシンプルなインタラクション体験です。ユーザーインターフェースに意識を向ける必要がなく、GPTとの協働に集中できるようにしたいのです。」
GPT-4oは英語テキストおよびコードにおける性能はGPT-4 Turboと同等だが、非英語テキストの性能は大幅に向上しており、APIの速度も速くなり、コストは50%削減された。既存モデルと比較して、特に視覚および音声理解において卓越している。
音声入力への応答は最短232ミリ秒、平均320ミリ秒で、人間とほぼ同じスピードだ。GPT-4o発表以前、ChatGPTの音声対話機能を体験したユーザーは、平均遅延が2.8秒(GPT-3.5)および5.4秒(GPT-4)であると感じていた。
これまでの音声応答モードは3つの独立したモデルからなるパイプラインだった。まず単純なモデルが音声をテキストに変換し、GPT-3.5またはGPT-4がテキストを受け取り応答を出力し、さらに別の単純なモデルがそのテキストを音声に戻す。しかしOpenAIは、この方法ではGPT-4が大量の情報を失ってしまうことに気づいた。つまり、ピッチ、複数の話者、背景雑音などを直接観察できず、笑い声や歌、感情表現も出力できないのだ。
一方、GPT-4oでは、テキスト、視覚、音声を横断的にエンドツーエンドで訓練された新しいモデルを採用。すべての入出力を同一のニューラルネットワークが処理する。
「技術的には、OpenAIは音声を直接音声にマッピングする一次モダリティとして扱い、動画をリアルタイムでTransformerに入力する方法を見つけた。トークナイゼーションやアーキテクチャに関する新たな研究が必要だが、全体としてはデータとシステムの最適化問題に帰着する(ほとんどの課題はそうであるように)」と、NVIDIAの科学者ジム・ファンはコメントした。
GPT-4oはテキスト、音声、動画を横断してリアルタイム推論を行うことができ、より自然な人間と機械のインタラクション(さらには機械同士のインタラクション)への重要な一歩を踏み出した。
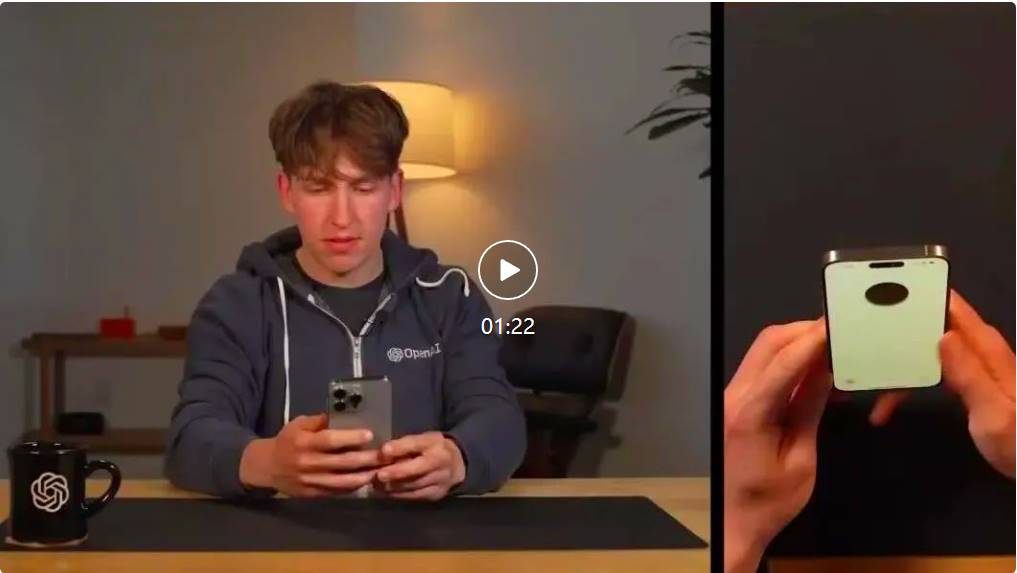
OpenAI社長のグレッグ・ブロックマンもオンラインで「遊び」を見せた。2つのGPT-4oにリアルタイムで会話させ、さらには即興で曲を作らせた。メロディーはやや「独特」だったが、歌詞には部屋の装飾スタイル、人物の服装、イベント中の出来事などが織り込まれていた。
さらに、GPT-4oは画像の理解・生成能力においても、既存のいかなるモデルよりもはるかに優れており、かつて不可能と思われたタスクが「簡単」になった。
例えば、OpenAIのロゴをコースターに印刷してほしいと依頼できる:
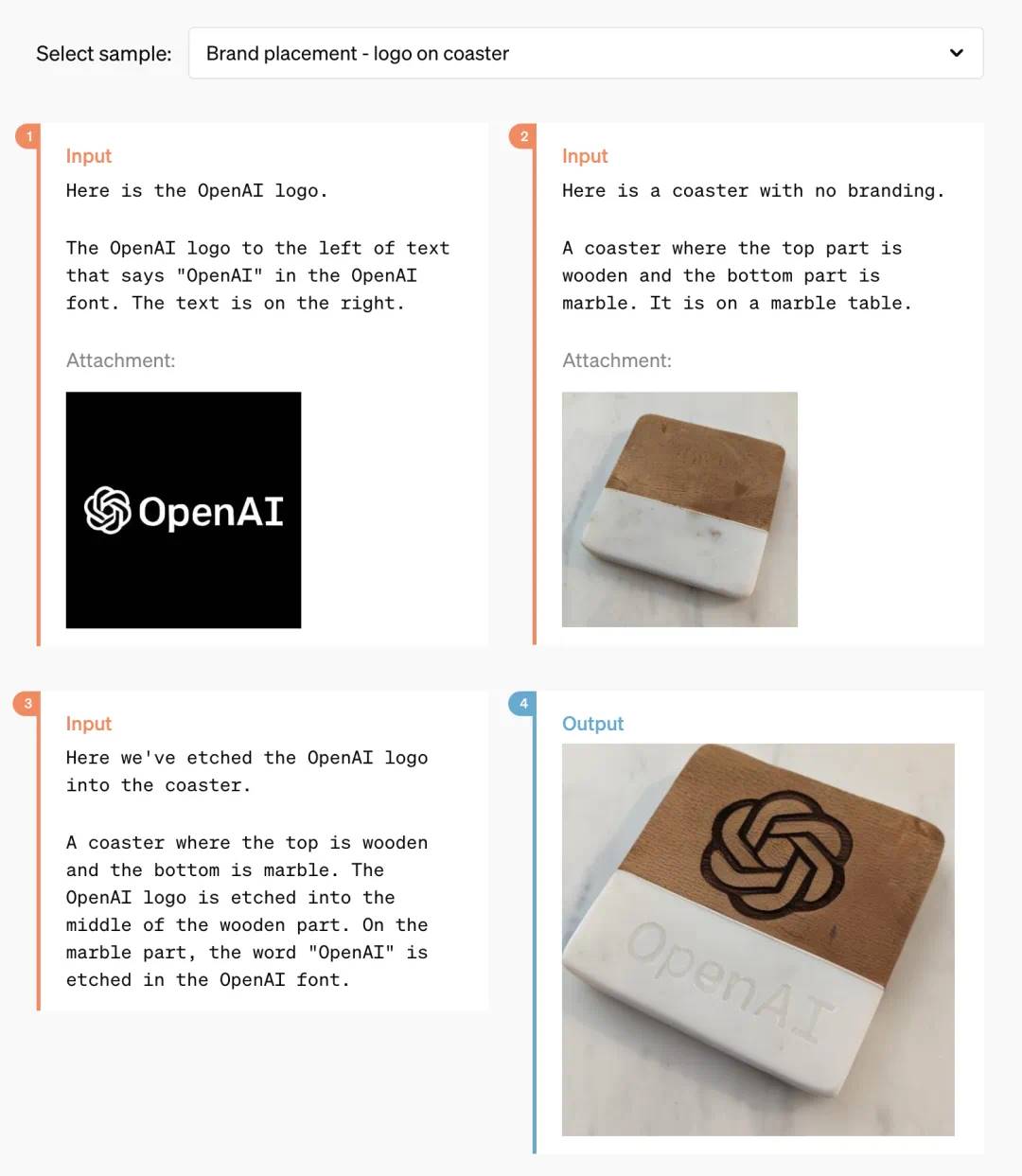
この期間の技術開発により、OpenAIはChatGPTのフォント生成問題を完全に解決したようだ。
またGPT-4oは3Dビジュアルコンテンツ生成能力も持ち、6枚の生成画像から3D再構成が可能:


これは一首の詩だが、GPT-4oはそれを手書き風にレイアウトできる:


より複雑なレイアウトも難なくこなす:



GPT-4oと共同作業すれば、わずか数行のテキスト入力で、一連の漫画コマ割りが得られる:
以下の機能は、多くのデザイナーにとって驚きだろう:
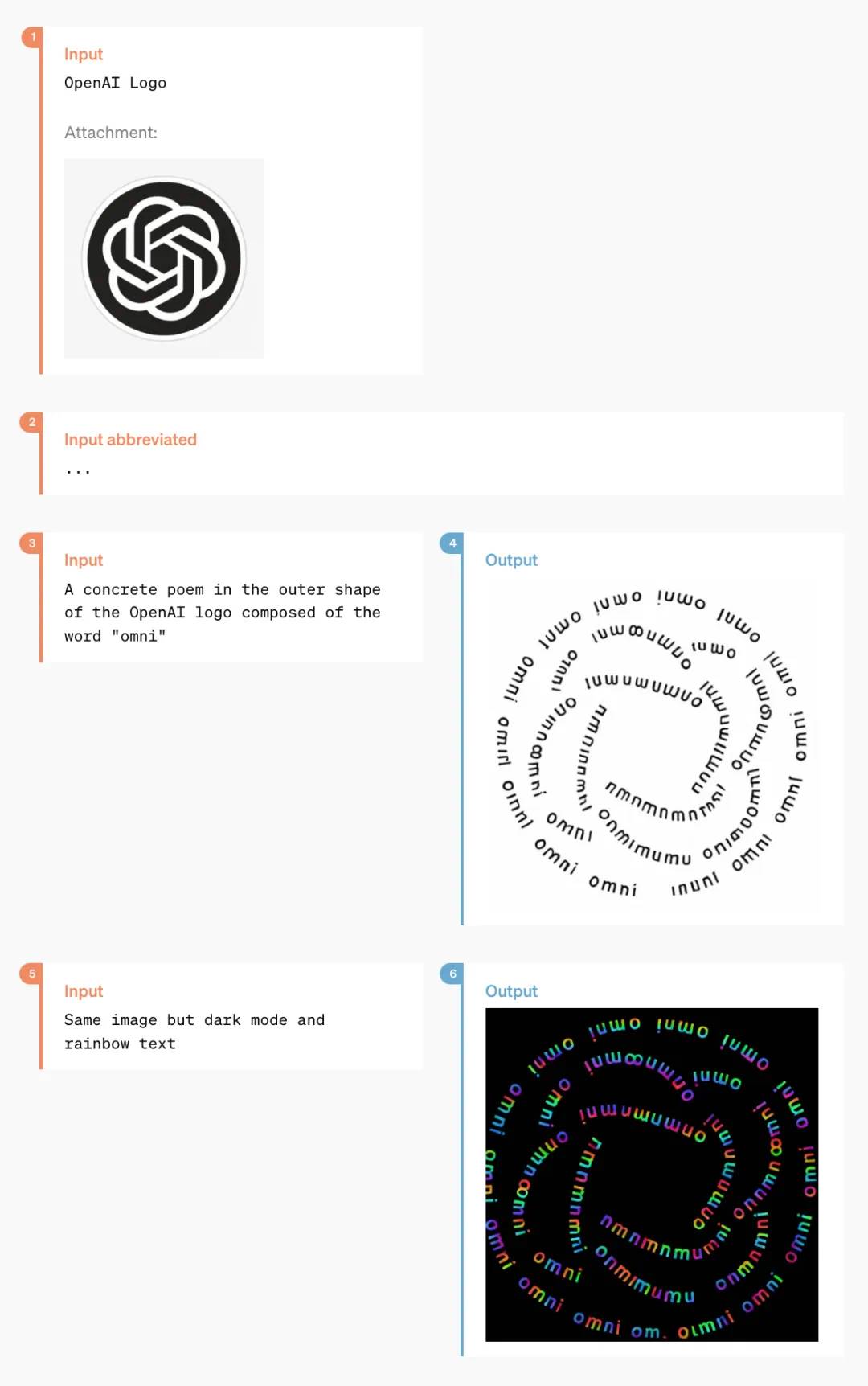
これは2枚の日常生活写真から生まれたスタイライズされたポスター:
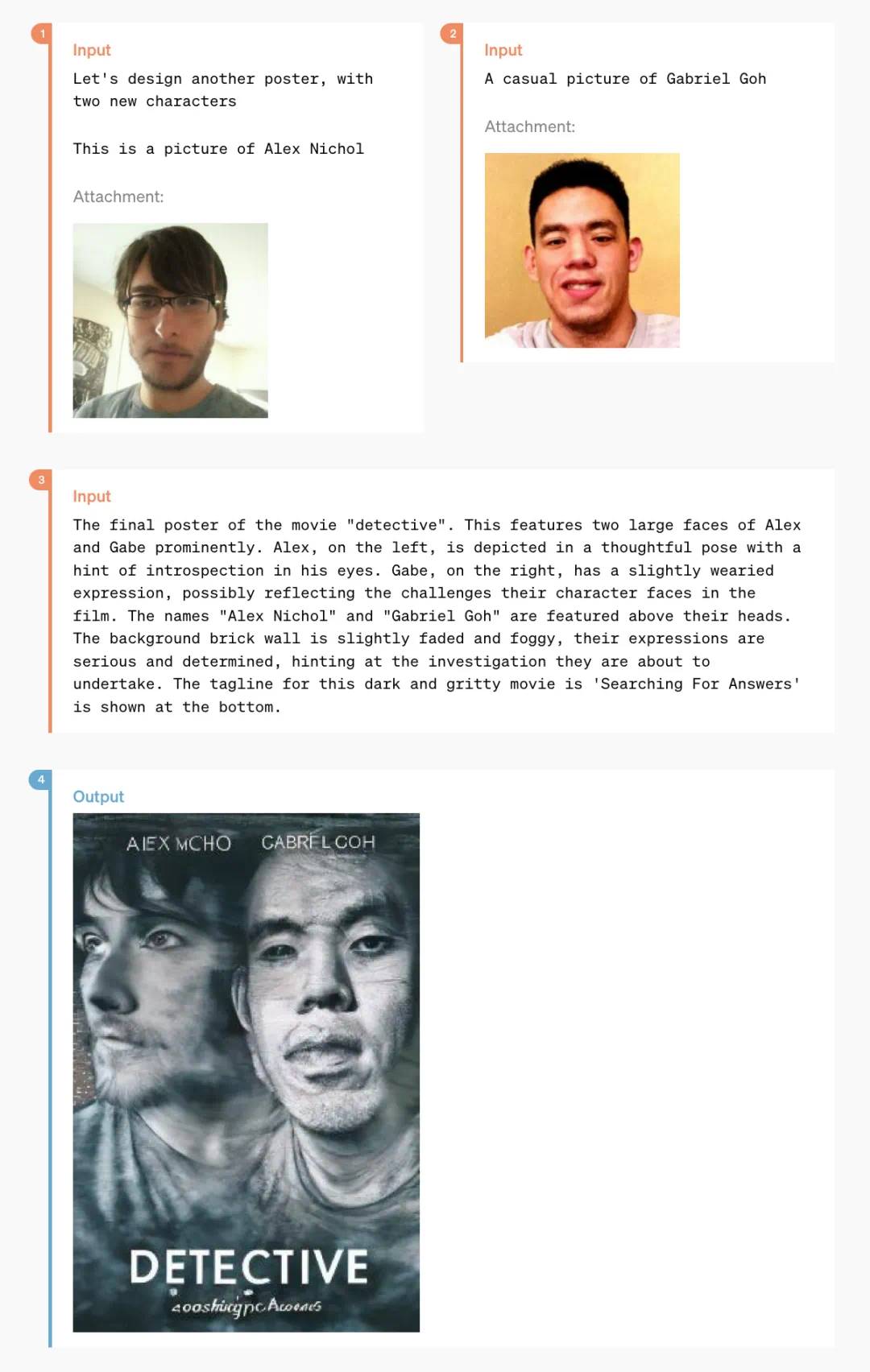
他にも「テキスト→アート文字」変換といったニッチな機能もある:

GPT-4o 性能評価結果
OpenAI技術チームのメンバーがX上で明かしたところによると、LMSYS Chatbot Arenaで広く話題となった謎のモデル「im-also-a-good-gpt2-chatbot」は、GPT-4oのバージョンの一つだった。
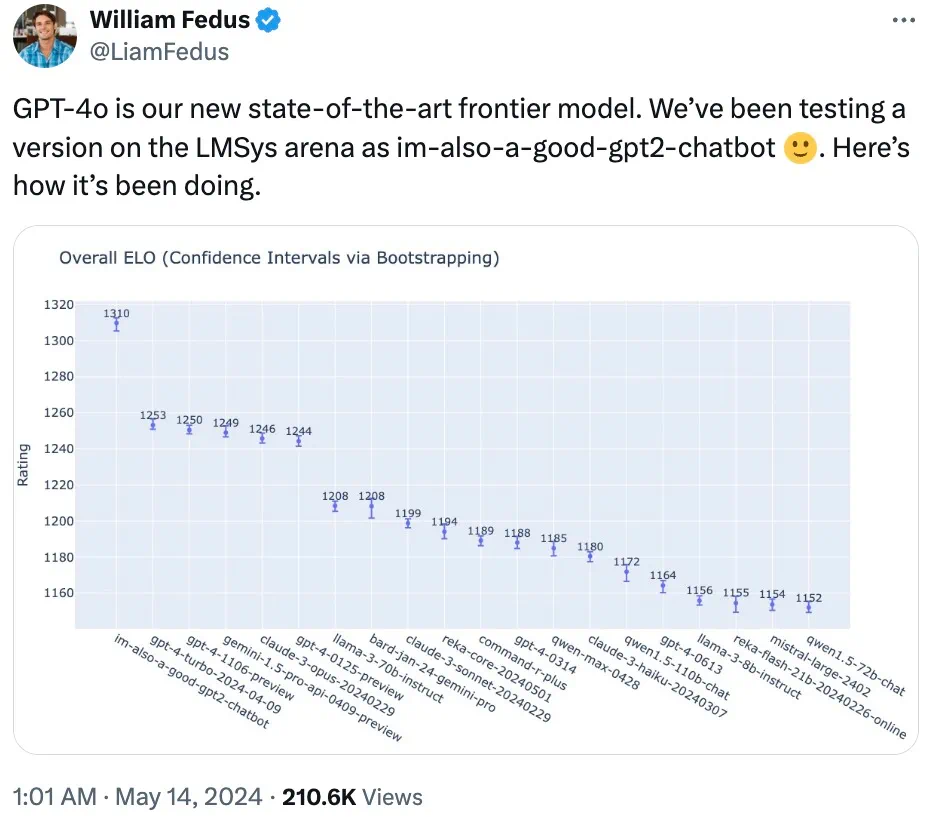
特にコーディングなど難しいプロンプトセットでは、GPT-4oはOpenAIの過去最高モデルと比べても著しく性能が向上している。
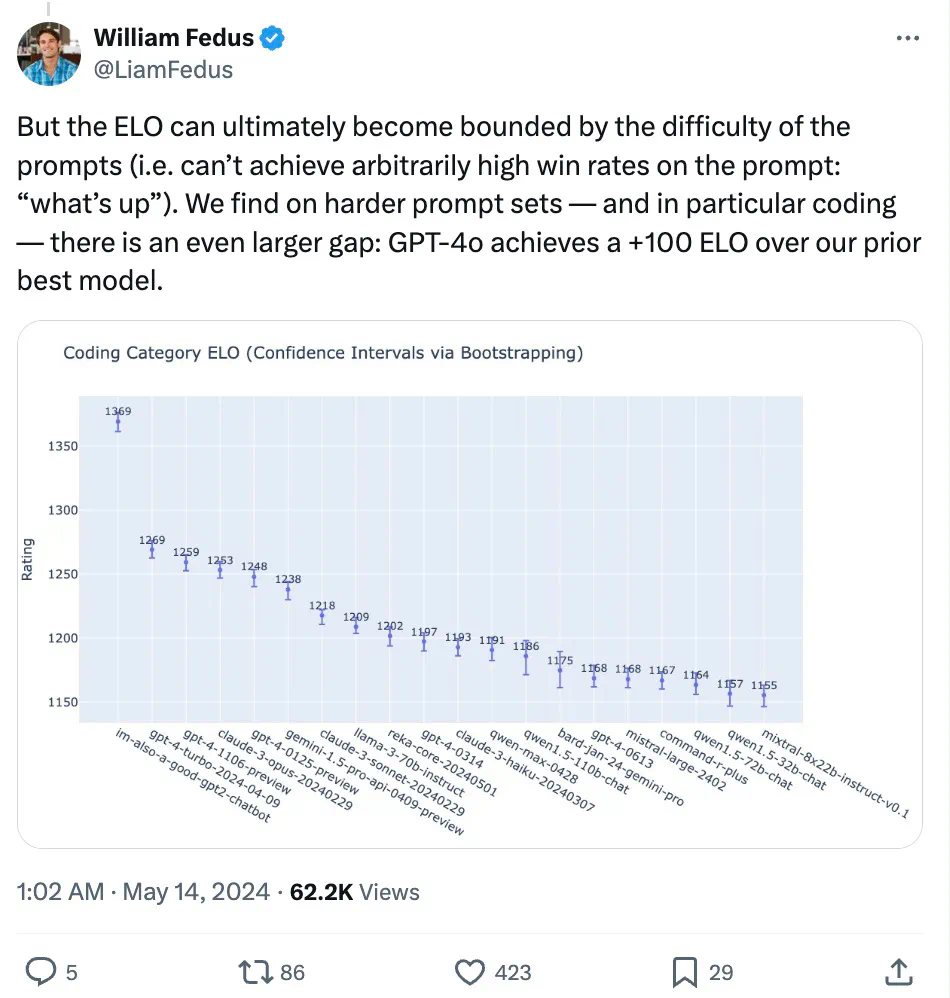
具体的には、複数のベンチマークテストにおいて、GPT-4oはテキスト、推論、コーディング知能でGPT-4 Turboレベルの性能を達成しつつ、多言語、音声、視覚機能で新記録を樹立している。
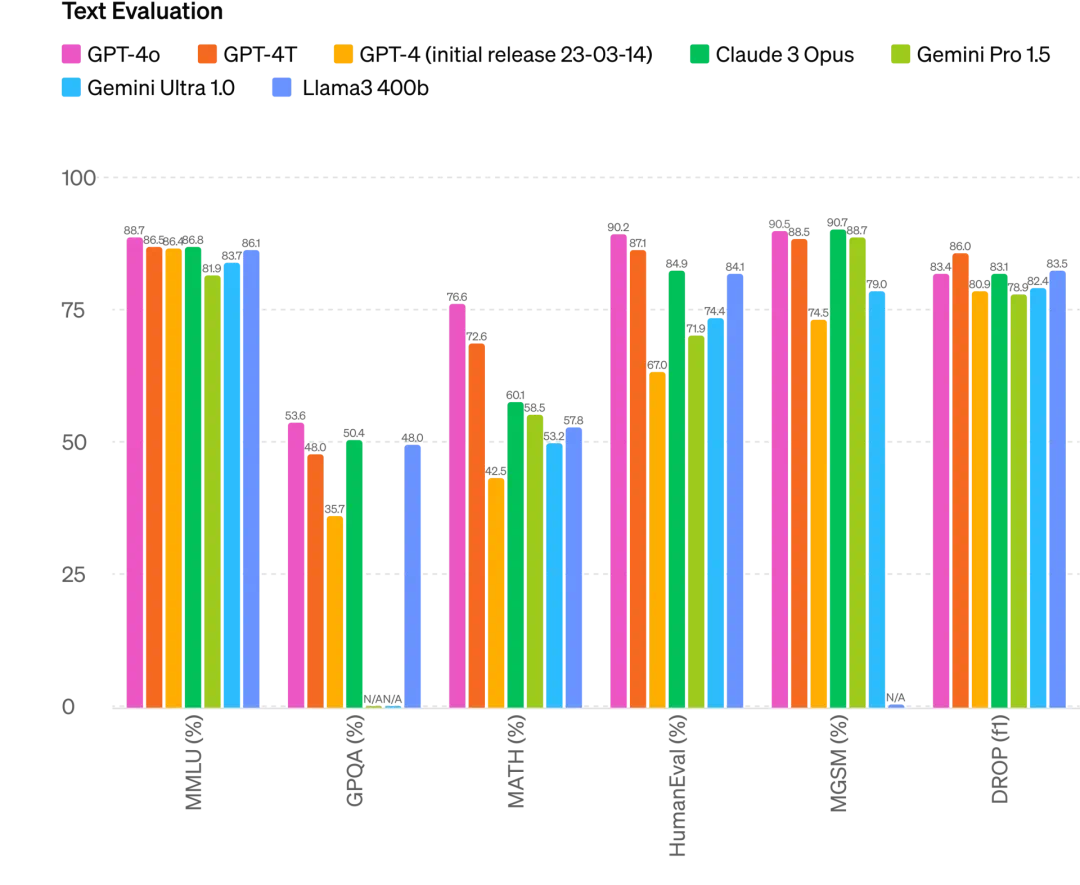
推論性能向上:GPT-4oは5-shot MMLU(常識問題)で87.2%の新記録を達成。(注:Llama3 400bはまだ訓練中)
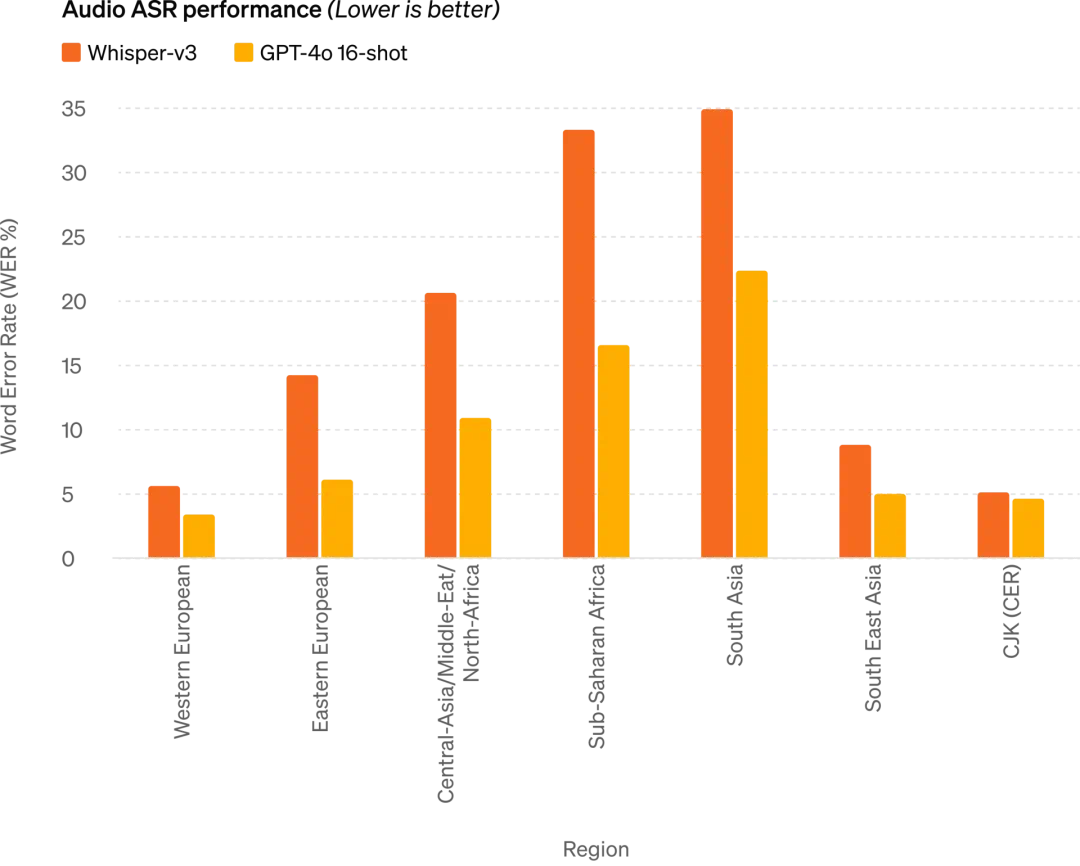
音声ASR性能:GPT-4oはWhisper-v3と比較して全言語の音声認識性能を大幅に向上。特にリソース不足言語で顕著
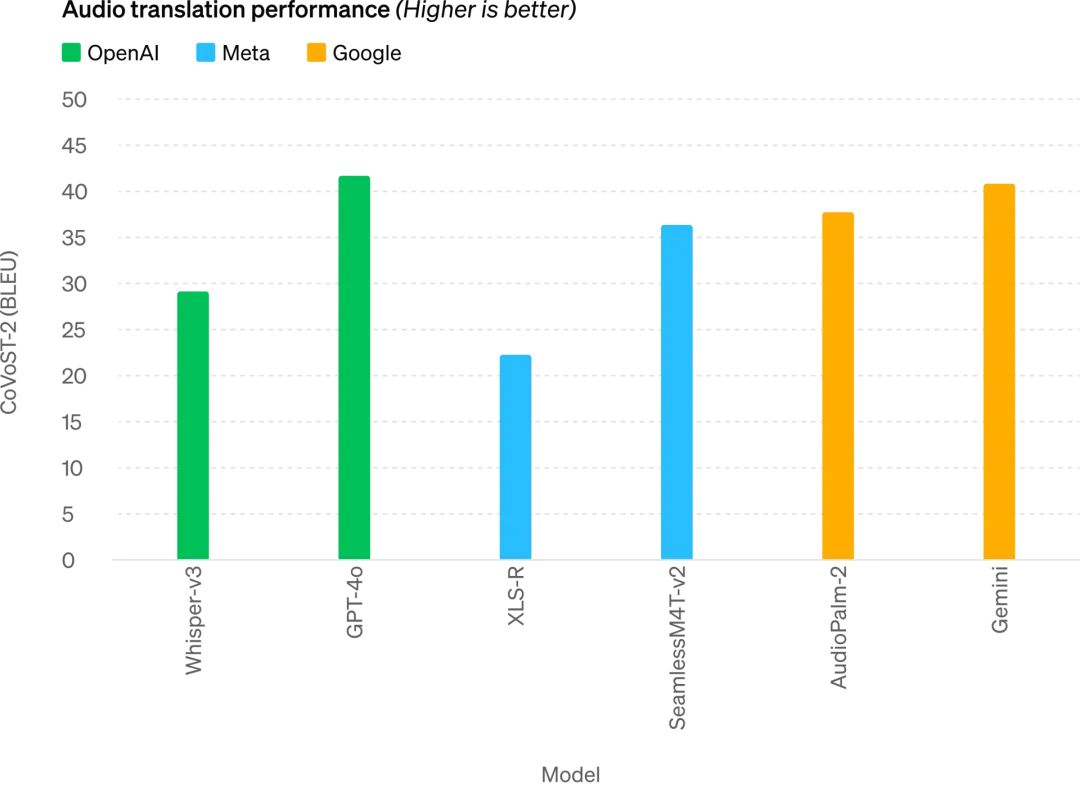
GPT-4oは音声翻訳で新たなSOTAを達成し、MLSベンチマークでWhisper-v3を上回る
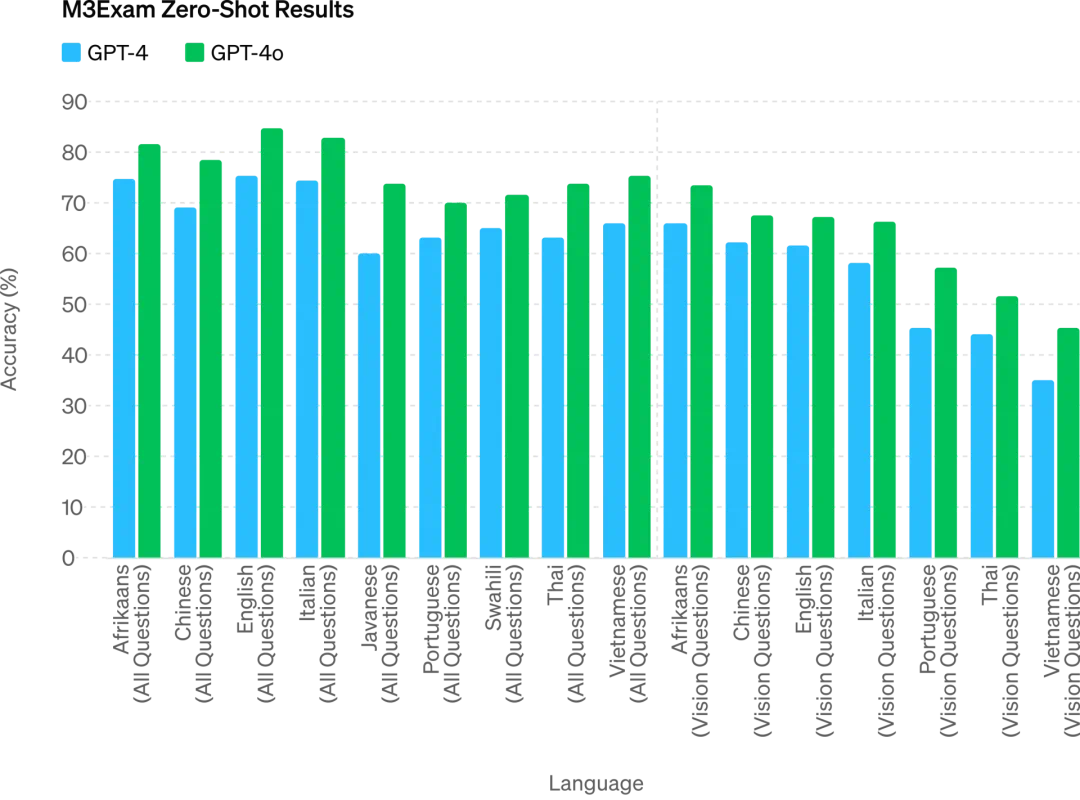
M3Examベンチマークは多言語評価および視覚評価の両面を持ち、各国・地域の標準化テストの選択問題とグラフ・図表を含む。すべての言語ベンチマークでGPT-4oはGPT-4を上回る
今後、モデルの進化により、より自然でリアルタイムな音声対話が可能になり、リアルタイム動画を通じてChatGPTと会話できるようになる。例えば、ユーザーがスポーツ中継を見せ、「ルールを説明して」と要求できる。
ChatGPTユーザーは無料で高度な機能をより多く利用可能に
毎週1億人以上がChatGPTを利用しているが、OpenAIはGPT-4oのテキストおよび画像機能を本日からChatGPTで無料提供開始し、Plusユーザーには最大5倍のメッセージ上限を提供する。

現在ChatGPTを開くと、GPT-4oがすでに使用可能になっている。
無料ユーザーでもGPT-4oを使用することで以下の機能が利用可能:GPT-4レベルの知能体験、モデルおよびネットワークからの応答取得。
さらに、無料ユーザーには以下のような選択肢がある――
データ分析とグラフ作成:

撮影した写真との対話:
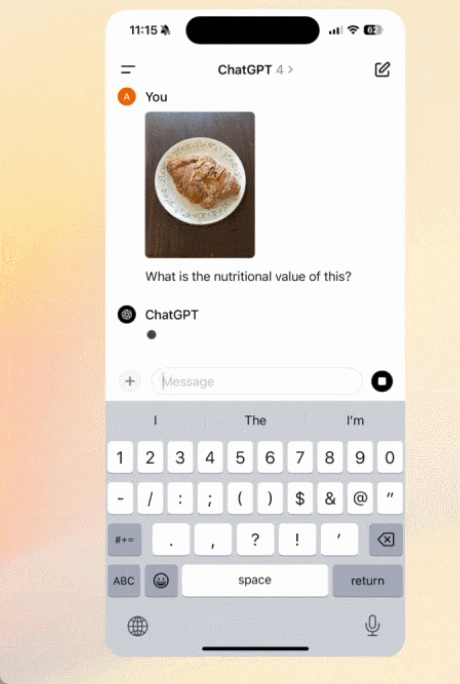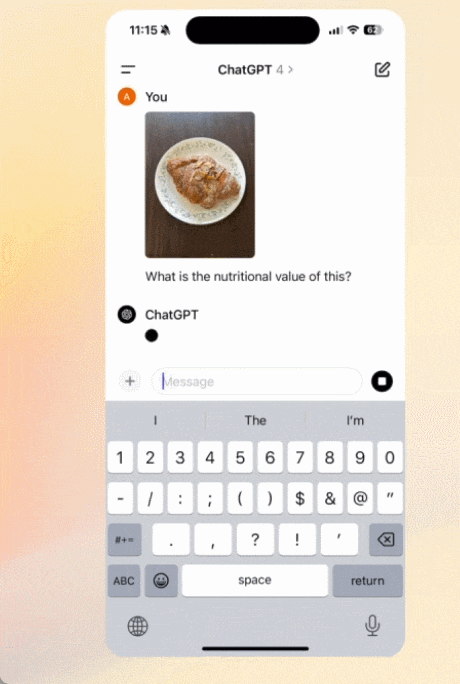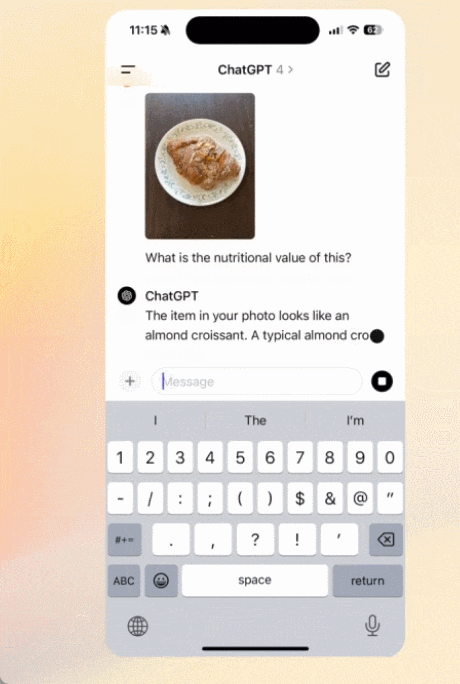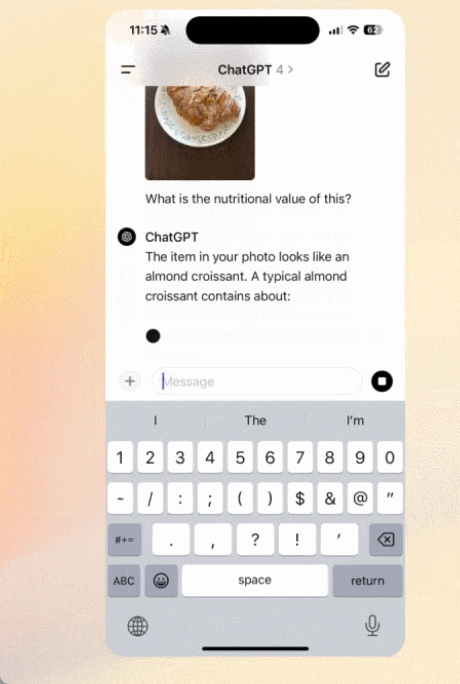
ファイルをアップロードして要約、文章作成、分析の支援を得る:
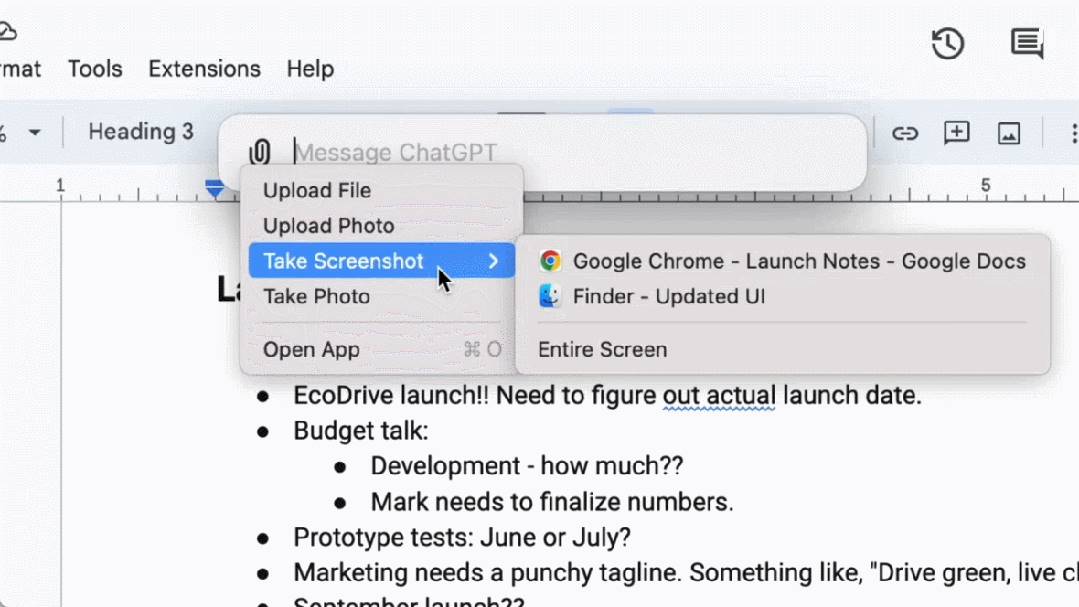
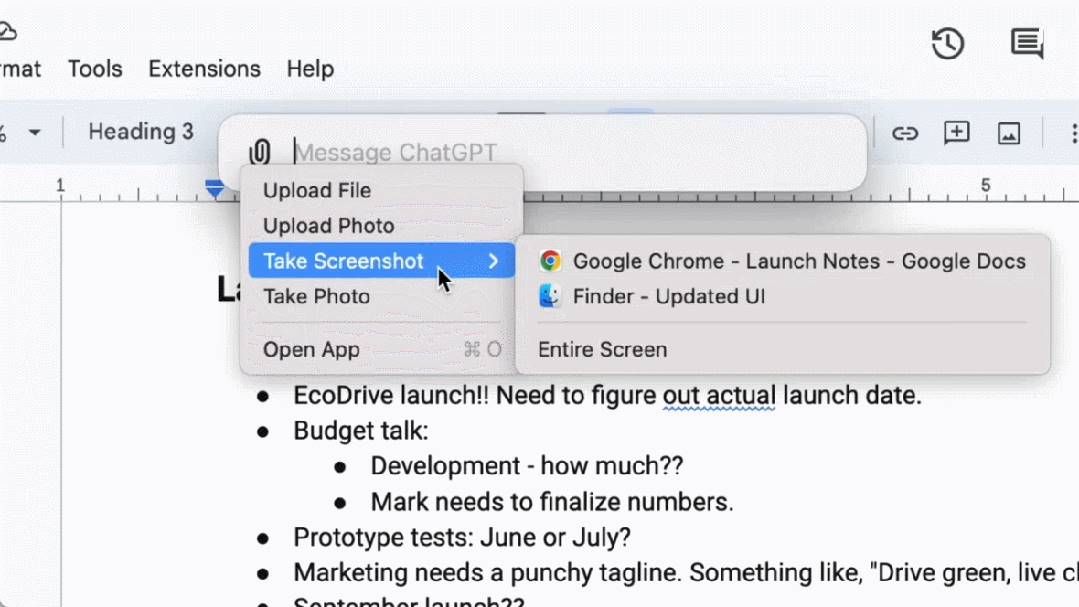
GPTsおよびGPTアプリストアの発見と利用:
メモリ機能を使い、より役立つ体験を実現。
ただし、使用状況や需要に応じ、無料ユーザーはGPT-4oで送信できるメッセージ数に制限がある。制限に達すると、ChatGPTは自動的にGPT-3.5に切り替わり、対話を続けることができる。
また、OpenAIは今後数週間以内に、ChatGPT Plusで新バージョンの音声モード「GPT-4o alpha」をリリースし、APIを通じて信頼できるパートナーの一部に限定して、GPT-4oの新しい音声・動画機能を提供する予定。
もちろん、多数のモデルテストと反復により、GPT-4oはすべてのモダリティにおいていくつかの限界を持っている。OpenAIはこれらの不完全な点を改善するために努力している。
想像できる通り、GPT-4oの音声モード開放は新たなリスクを伴う。安全性に関しては、GPT-4oはトレーニングデータのフィルタリングやポストトレーニングによる行動調整などの技術を用い、マルチモーダル設計に安全性を内包している。OpenAIはさらに、音声出力の保護のための新しい安全システムも構築した。
新しいデスクトップアプリでユーザーワークフローを簡素化
無料および有料ユーザー向けに、OpenAIはmacOS用の新しいChatGPTデスクトップアプリをリリースした。シンプルなキーボードショートカット(Option + Space)で、すぐにChatGPTに質問できる。また、アプリ内で直接スクリーンショットをキャプチャし、議論することも可能だ。
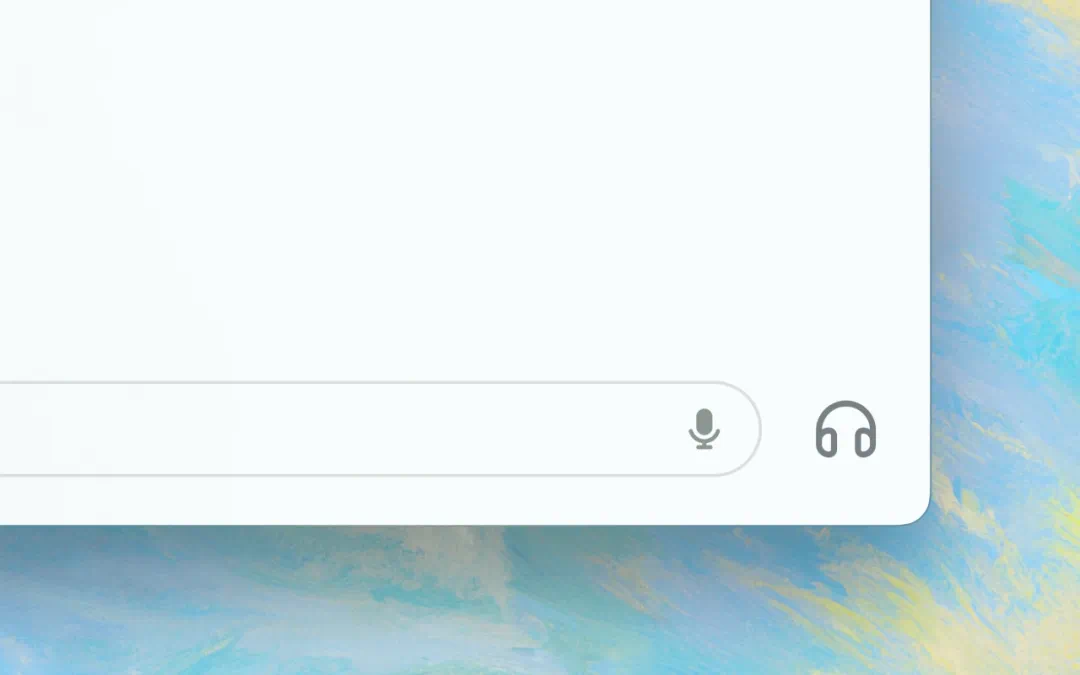
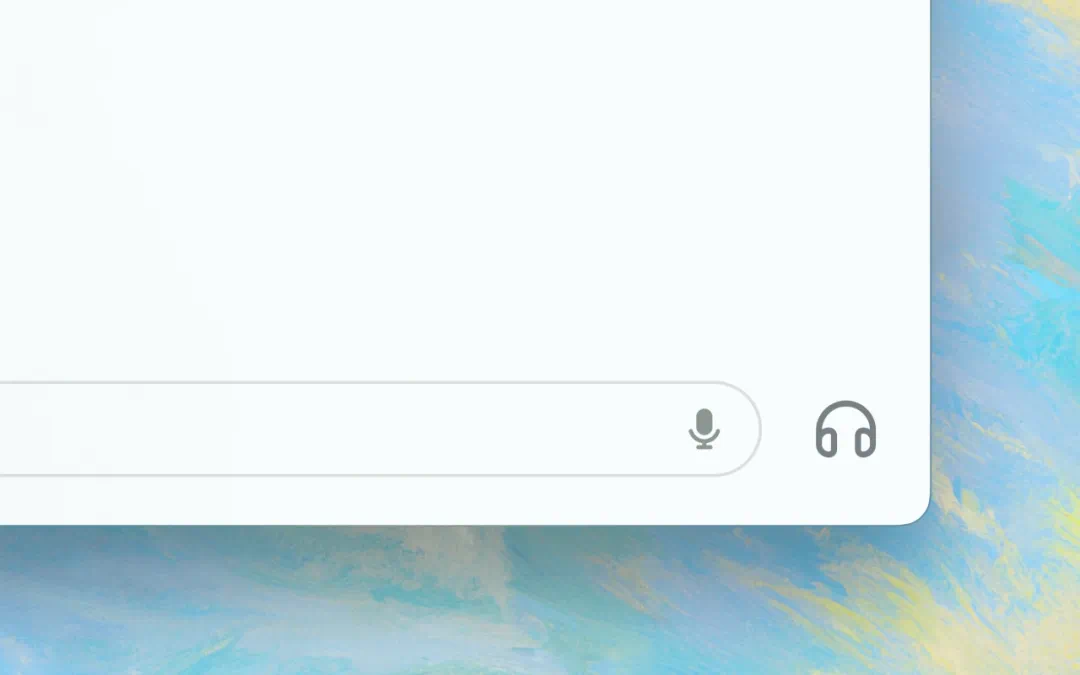
今後、ユーザーはコンピュータから直接ChatGPTと音声対話できるようになる。GPT-4oの音声および動画機能は今後リリースされ、デスクトップアプリ右下のヘッドフォンアイコンをクリックすることで音声対話を開始できる。
本日から、OpenAIはPlusユーザー向けにmacOSアプリを展開し、今後数週間でより広く提供される。また今年後半にはWindows版もリリース予定。
オルトマン:あなた方はオープンソース、私たちは無料
発表終了後、OpenAI CEOのサム・オルトマンは久しぶりにブログ記事を投稿し、GPT-4o開発時の思いを語った:
今日の発表で、二つのことを強調したい。
まず、私たちのミッションの重要な部分は、強力なAIツールを無料(または低価格)で人々に提供することだ。私は胸を張って宣言できる――ChatGPTの中で世界最高のモデルを、広告など一切なしに無料で提供している。
OpenAI設立当初、我々の構想は「AIを作り、それを使って世界に利益をもたらす」ことだった。しかし今、状況は変わりつつあり、我々がAIを作ると、他の人々がそれを用いて素晴らしいものを創造し、全員が恩恵を受ける未来が見えてきた。
もちろん、私たちは企業であり、多くの有料サービスを開発する。それが数十億人に無料で優れたAIサービスを提供する原資となる(願わくば)。
第二に、新しい音声・動画モードは、私が今まで使った中で最高の計算インタフェースだ。まるで映画のAIのようで、それが本当に存在するとはまだ少し信じられない。人間並みの応答時間と表現力に到達したことで、大きな飛躍が実現した。
初期のChatGPTは言語インターフェースの可能性を示唆したが、この新バージョン(GPT-4o)は本質的に異なる感触だ――速く、賢く、面白く、自然で、役に立つ。
私にとって、コンピュータとのやり取りは決して自然なものではなかった。しかし、(任意の)パーソナライズ、個人情報へのアクセス、AIが人間の代わりに行動する能力などを追加していくことで、コンピュータでこれまで以上に多くのことができる未来が確かに見える。
最後に、この成果を実現してくれたチームに心から感謝します!

ちなみに、先週オルトマンはあるインタビューで、「ユニバーサルベーシックインカム(UBI)の実現は難しいかもしれないが、『ユニバーサルベーシックコンピュート(普遍的な基本計算資源)』なら実現できる」と語った。将来、誰もがGPTの計算資源を無料で得られ、それを使用したり転売したり寄付したりできるというのだ。
「AIがますます高度になり、生活のあらゆる側面に組み込まれるにつれ、GPT-7のような大規模言語モデルの単位はお金よりも価値を持つかもしれない。生産力の一部を手にするということだ」とオルトマンは説明した。
GPT-4oのリリースは、OpenAIがこの方向に向けた第一歩かもしれない。
そう、これはまだ始まりにすぎない。
最後にひとつ、本日OpenAIのブログで公開された「Guessing May 13th’s announcement.」の動画は、明日開催されるGoogle I/Oカンファレンスのプレビデオとほぼ完全に一致しており、まさしくGoogleに対する正面からの挑戦状だ。今日のOpenAI発表を見て、Googleは巨大なプレッシャーを感じているだろうか?
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News