

NEAR共同創設者Illia:なぜAIはWeb3を必要とするのか?
TechFlow厳選深潮セレクト
NEAR共同創設者Illia:なぜAIはWeb3を必要とするのか?
我々は今、分かれ道に立っている。その道の一方には、より多くの操作をもたらす閉鎖されたAIの世界がある。

先日、NEARの共同創業者であるイリア氏が「2024香港Web3フェスティバル」に出席し、AIとWeb3に関する重要な講演を行いました。以下はその講演内容を整理・要約したものです。
こんにちは、私はNEARの共同創業者のイリアです。今日は「なぜAIはWeb3を必要とするのか」というテーマでお話しします。実はNEARはAIから始まりました。起業する前、私はGoogle Researchで自然言語理解の研究をしており、GoogleのディープラーニングフレームワークであるTensorFlowの主要な貢献者の一人でもありました。当時、仲間たちと共に最初の「Transformers」モデルを開発しました。この技術革新が今日のAI進化の基盤となり、GPTの「T」にもつながっています。
その後、私はGoogleを離れてNEARを立ち上げました。当初はAIスタートアップとして、機械にプログラミングを教えることを目指していました。その方法の一つとして大量のデータアノテーションを行い、学生たちにデータ作成を依頼していました。しかし彼らは世界中にいて、中には銀行口座さえ持たない人もいたため、報酬支払いが大きな課題でした。そこで私たちはブロックチェーンを解決策として検討しましたが、スケーラビリティ、低コスト、使いやすさといった点で満足できるソリューションが存在しませんでした。そのため、私たち自身でNEARプロトコルを作ることになったのです。

言語モデルが新しいものだと思われている方もいるかもしれませんが、実際には1950年代から存在しています。統計的モデルを使って言語をモデリングし、さまざまな用途に応用されてきました。私にとって真に革新的だったのは2013年、ワードエンベディング(単語のベクトル化)が導入されたときです。これにより、「ニューヨーク」といった記号を多次元の数学的ベクトルとして扱えるようになりました。これは行列乗算と活性化関数を中心とするディープラーニングモデルと非常に相性が良かったのです。
2013年に私はGoogleに入社しました。2014年初頭、主流だったのはRNN(再帰型ニューラルネットワーク)です。人間が単語を一つずつ読むように処理するこの方式には大きな制限がありました。例えば複数の文書を読んで質問に答える場合、非常に大きな遅延が生じます。これはGoogleの本番環境では現実的ではありませんでした。
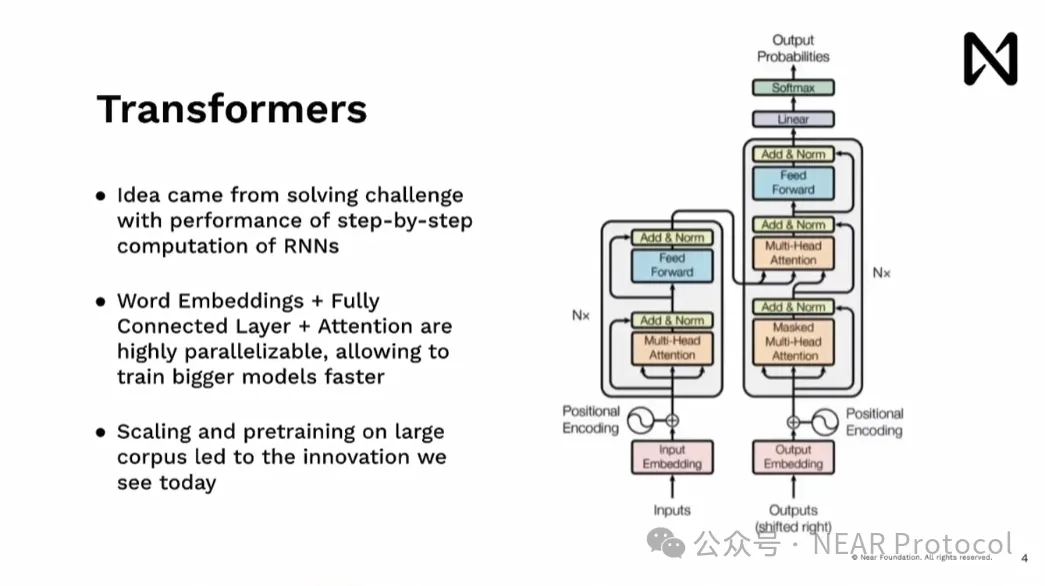
こうしたRNNの課題を解決するために生まれたのがTransformerです。ハードウェア、特にGPUに備わる並列処理能力を活かし、ドキュメント全体をほぼ同時に処理できるようにしました。1ステップずつ順番に処理するというボトルネックがなくなり、OpenAIチームが開発したモデルを大規模に拡張し、巨大なコーパスで事前学習することが可能になりました。これがChatGPTやGeminiなど、今日見られる画期的なAIモデルの礎となったのです。
現在、AIの革新は加速しており、これらのモデルは基本的な推論能力を持ち、常識的理解も可能になっています。人々は今なおモデルの限界に挑戦し続けています。かつては機械学習やデータ科学の専門家が結果を解釈する必要がありましたが、今や大規模言語モデル自体が人間と直接対話でき、他のアプリケーションやツールとも連携できるようになりました。つまり、中間者を介さずに結果を解釈する技術的手段がすでに手に入っているのです。
ここで注意してほしいのは、これらのモデルを訓練または使用するGPUは、ゲーム機や暗号通貨マイニングに使われるものとは異なります。これらは専用のスーパーコンピュータであり、1台のマシンに通常8つのGPUが搭載されています。このようなマシンがラックに積み重ねられ、データセンターに設置されています。例えばGroqのような大規模モデルを3か月間訓練するには、1万個のH100 GPUが必要で、レンタル費用だけで6400万ドルかかるでしょう。さらに重要なのは、計算能力だけでなく接続性も極めて重要だということです。
特にA100、そしてH100では、GPU間の接続速度が毎秒900ギガバイトに達します。比較として、CPUとRAMの接続速度は毎秒9ギガバイト程度です。つまり、データセンター内の2つのノード/GPU間でデータを転送する方が、GPUからCPUにデータを移動するよりも高速なのです。現在開発中のBlackwellでは、この速度がさらに倍の毎秒1800ギガバイトになると予想されています。この驚異的なハードウェア接続速度により、プログラマーの視点ではこれら複数のデバイスをまるで1つのユニットのように扱えるようになります。通常のローカルネットワークの接続速度が毎秒100メガバイト程度であることを考えると、その差は実に約1万倍にも及びます。
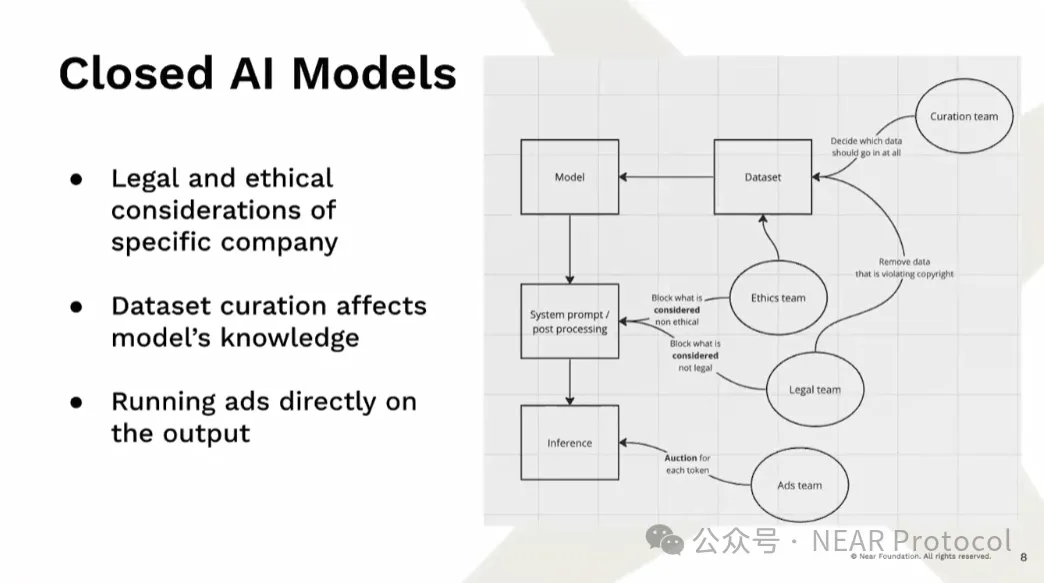
このような訓練インフラへの要求から、現在、閉鎖的なAIモデルが台頭しています。たとえモデルの重み(weights)がオープンソースであっても、実際には何がモデルに組み込まれているかは不明です。これは重大な問題です。なぜなら、モデルはデータから偏り(bias)を学習してしまうからです。ある人は冗談めかして「モデルとは重みと偏りにすぎない」と言いますが、まさにそれがモデルの本質です。現在ではエンジニアだけでなく、多くのチームがデータセットを改変することで、意図的に特定の情報をモデルに含めたり除外したりしています。さらにモデル生成後にはポストプロセッシングやシステムプロンプトの調整を通じて、モデルの推論内容を操作しています。最も危険なのは、そのような過程が全く透明でないことなのです。
また、AIに対して大規模な抗議活動や訴訟も起きています。データ利用のあり方から、モデルが出力する結果、さらには企業による配信プラットフォームの支配権に至るまで、多くの点で論争の的となっています。モデル自体が配信プラットフォームになりつつある以上、我々は非常に大きなリスクに直面しています。明らかに規制当局はこれを管理しようとしており、悪意ある行為者へのアクセスを制限しようとします。しかしその結果、オープンモデルや分散型アプローチの存在がより困難になっています。オープンソースには十分な経済的インセンティブがなく、企業は一時的にオープンソース化しても、収益化を目指す段階でモデルの公開を制限する傾向があります。より多くの資金を得て計算資源を購入し、より大きなモデルを訓練するためです。
生成AIは人々を大規模に操る道具になりつつあります。大企業の経済構造は常にインセンティブを歪めてしまいます。一旦目標の市場シェアを獲得したら、次は収益成長を示さなければなりません。そのためには一人当たりの平均収益(ARPU)を増やす必要があり、つまりユーザーからより多くの価値を搾取しなければならないのです。これが現在のオープンソースAIを取り巻く状況です。一方で、Web3をツールとして活用すれば、人々にインセンティブを与え、競争力のあるモデルを構築するための十分な計算資源やデータを創出することが可能になります。

大量のAIツールをWeb3の世界で機能させることが必要です。ここではデータ、インフラ、アプリケーションの各レイヤーからその一部を紹介します。特に重要なのは、言語モデルが社会と直接やり取りできるようになったことで、広範囲にわたって情報操作や誤情報の生成が可能になっている点です。ここで強調したいのは、AI自体が問題なのではなく、こうしたことは過去にも存在していたということです。大切なのは、暗号技術やオンチェーンでの評判システムを活用して、誰が情報を発信したか、その情報源は何か、コミュニティの反応はどうか、といった点を可視化することです。それが人間によって生成されたかAIによって生成されたかよりも、はるかに重要なのです。
もう一つの側面は「エージェント」です。私たちはすべてをエージェントと呼んでいますが、実際には多様性があります。ツールとしてのエージェントもあれば自律的なエージェントもあり、それらは中央集権的でもあれば非中央集権的でもあります。たとえばChatGPTは中央集権的なツールですが、Llamaモデルはオープンソースです。そのため、同じモデルでも中央集権的・非中央集権的に利用できます。非中央集権モデルはユーザーの端末上でだけ動作させることも可能で、ブロックチェーンなどを必要としないケースもあります。自分のデバイス上でモデルを実行すれば、それが完全に自分の期待通りに動作することを保証できるからです。資金の分配や重要な意思決定を行う場合には、検証を伴う完全に自律的な非中央集権AIガバナンスが必要になるでしょう。

さらに専門化の種類もあります。たとえばプロンプトではzero-shotでLlamaに特定の応答方法を指示できます。特定のデータでファインチューニングすることで、モデルに知識を追加することも可能です。あるいはリトリーバル拡張(RAG)を使い、ユーザーのリクエスト時にコンテキスト情報を付加することもできます。出力はテキストに限りません。豊かなUIコンポーネントや、ブロックチェーン上で何かを実行する直接的なアクションにもなり得るのです。
次に「自律性」についてです。これは単なるツールとして使うこともできますが、自分で計画を立てて実行することもできます。継続的なタスクとして、ゴールだけ指定すればよいこともあります。強化学習の最適化であれば、評価指標と制約条件を設定するだけで、モデルが継続的に探索し、改善方法を見つけることができます。

最後にインフラです。OpenAIやGroqのような中央集権的インフラを使うこともできますし、分散されたローカルモデルや、確率的な非中央集権的推論も可能です。非常に興味深いユースケースとして、プログラム可能な通貨からスマート資産へと進化する流れがあります。これは自然言語で資産の振る舞いを定義し、現実世界や他のユーザーと相互作用できる仕組みです。例えばニュースを読み取る自然言語オラクルを使えば、発生している出来事に基づいて自動的に戦略を最適化できます。ただし最大の懸念点は、現在の言語モデルは敵対的攻撃に対して脆弱であり、さまざまな手段で簡単に説得されてしまうことです。
我々は今、岐路に立っています。一方の道は閉鎖されたAIの世界であり、そこではより多くの操作が行われます。規制当局の決定はしばしばこの方向に進みます。監督強化、KYCの拡大、要求事項の増加など、大企業にしか満たせない条件が積み重なります。スタートアップ、特にオープンソースを目指す企業は、実際に対抗するリソースを持たず、最終的に倒産または大企業に買収される運命を迎えます。すでにその兆候は見え始めています。
もう一方の道は、開放されたモデルの世界です。非営利的・オープンソースの精神で実行するという約束と能力を持ち、暗号経済インセンティブを通じて機会と資源を創造します。これは競争力を持つオープンソースAIモデルにとって不可欠です。NEARは、エコシステム全体でこの実現に向けて努力しています。「AI is NEAR」。今後数週間以内にさらなるアップデートを発表する予定ですので、私のTwitterやNEARのソーシャルメディアをぜひフォローしてください。ありがとうございました!
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News












