

Soraの計算リソースに関する数学問題
TechFlow厳選深潮セレクト
Soraの計算リソースに関する数学問題
Soraは、動画生成の品質と機能において大きな進歩を示すだけでなく、将来的に推論プロセスにおけるGPU需要が大幅に増加する可能性を示唆している。
執筆:Matthias Plappert
翻訳:Siqi、Lavida、Tianyi
先月、OpenAIは動画生成モデル「Sora」をリリースしたが、昨日、同社はSoraを使ってクリエイティブワーカーが制作した作品群を公開し、その完成度の高さに大きな注目が集まっている。生成品質という観点から見ると、Soraは間違いなくこれまでで最も強力な動画生成モデルであり、この登場はクリエイティブ業界に直接的な衝撃を与えるだけでなく、ロボット工学や自動運転分野におけるいくつかの重要な課題の解決にも影響を及ぼすだろう。
OpenAIはSoraの技術報告書を公開しているものの、そこには技術的詳細が極めて限られており、本稿はFactorial FundのMatthias Plappertによる分析を編集したものである。MatthiasはかつてOpenAIに在籍し、Codexプロジェクトにも関与していた人物であり、今回の調査ではSoraの主要な技術的特徴や革新点、およびそれがもたらす可能性について詳述しているほか、Soraのような拡散(diffusion)ベースの動画生成モデルがどれだけの計算資源を必要とするかについても分析している。Matthiasによれば、動画生成の応用がますます広がるにつれ、推論(inference)フェーズの計算需要は訓練フェーズを急速に上回ると予測されている。
Matthiasの試算によると、Soraの訓練にはLLMよりも数段高い計算能力が必要で、おおよそ4200~10500枚のNvidia H100 GPUを1か月間使用して訓練される。また、モデルが1530万〜3810万分の動画を生成した時点で、推論フェーズの計算コストが訓練フェーズを超えることになる。比較として、現在ユーザーが毎日TikTokにアップロードする動画は1700万分、YouTubeでは4300万分に達している。OpenAIのCTOであるMiraも最近のインタビューで、動画生成のコスト問題がSoraを一般に公開できない理由の一つだと述べており、DALL·Eによる画像生成と同等のコスト効率を実現した上で公開を検討すると明言している。
OpenAIが最近発表したSoraは、非常にリアルな映像シーンの生成能力によって世界中を驚かせた。本稿では、Soraの背後にある技術的詳細、こうした動画モデルが持つ潜在的インパクト、そして私たちの現時点での考察について深掘りしていく。最後に、Soraクラスのモデルを訓練するために必要な計算資源の規模についても解説し、訓練計算と推論計算の比較を通じて、将来のGPU需要を予測する上での重要性を明らかにする。
主なポイント
本レポートの主な結論は以下の通り:
-
Soraは拡散モデル(diffusion model)であり、DiTおよびLatent Diffusionに基づいて構築されており、モデル規模とトレーニングデータセットのスケーリングを実施している;
-
Soraは、動画モデルにおいてもスケールアップが重要であることを示しており、今後も継続的なスケーリングが性能向上の主な原動力となることが期待される。これはLLMの場合と同様である;
-
Runway、Genmo、Pikaなどの企業は、Soraのような拡散ベースの動画生成モデルの上に直感的なインターフェースやワークフローを構築しようとしており、これがモデルの普及と使いやすさを左右する;
-
Soraの訓練には膨大な計算資源が必要であり、我々の推定では4200~10500枚のNvidia H100を1か月間使用することが必要とされる;
-
推論フェーズでは、1枚のH100あたり1時間に約5分程度の動画生成が可能と考えられ、Soraのような拡散ベースモデルの推論コストはLLMに比べて数オーダー高い;
-
Soraのような動画生成モデルが広範に利用されるようになると、推論フェーズの計算量が訓練フェーズを上回り、支配的になる。この臨界点は、1530万〜3810万分の動画を生成した時点で到来する。比較として、TikTokへの日々の動画アップロード量は1700万分、YouTubeでは4300万分である;
-
仮にAI生成動画がTikTokで50%、YouTubeで15%の割合で使われていると仮定し、ハードウェアの使用効率などを考慮すると、ピーク需要時において推論フェーズには約72万枚のNvidia H100が必要になると試算される。
総じて、Soraは動画生成の品質と機能性における大きな進歩を象徴するだけでなく、将来的に推論フェーズにおけるGPU需要が大幅に増加することを予兆している。
01. 背景
Soraは拡散モデル(diffusion model)であり、画像生成分野では既に一般的に用いられている。たとえばOpenAIのDALL-EやStability AIのStable Diffusionなど、代表的な画像生成モデルはすべて拡散ベースである。また、近年登場した動画生成に取り組むRunway、Genmo、Pikaなどもおそらく拡散モデルを利用している。
一般的に、拡散モデルとは、データにランダムノイズを徐々に加える過程を逆方向に学習することで、訓練データ(画像や動画など)と類似した新しいデータを生成する生成モデルである。これらのモデルは完全なノイズ状態から始まり、徐々にノイズを除去しながらパターンを洗練させ、最終的に整合性があり詳細な出力を得る。

拡散プロセスの模式図:
ノイズが段階的に除去され、詳細な動画コンテンツが現れる
出典:Sora 技術報告書
このプロセスはLLMにおけるモデルの動作原理とは大きく異なる。LLMはトークンを逐次的に生成していく「自己回帰サンプリング(autoregressive sampling)」を行う。一度生成されたトークンは変更されず、PerplexityやChatGPTなどのツールを使用する際に、答えが一文字ずつ表示されていく様子がまさにそれである。
02. Soraの技術的詳細
Soraのリリースに合わせて、OpenAIは技術報告書も公開したが、そこにはあまり多くの詳細が記載されていない。しかし、Soraの設計は「Scalable Diffusion Models with Transformers」という論文に大きく影響を受けているように見える。この論文では、2人の著者が画像生成向けのTransformerベースアーキテクチャであるDiTを提案しており、Soraはその研究を動画生成へと拡張したものと考えられる。Soraの技術報告書とDiT論文を組み合わせることで、Soraの全体像をある程度正確に再構築できる。
Soraに関する3つの重要な情報:
1. Soraはピクセル空間(pixel space)ではなく、潜在空間(latent space、またはlatent diffusion)で処理を行っている;
2. SoraはTransformerアーキテクチャを採用している;
3. Soraは非常に大規模なデータセットを使用していると思われる。
詳細 1: 潜在拡散(Latent Diffusion)
まず、「潜在拡散」とは何かを理解するために、画像生成のプロセスを考えよう。各ピクセルに対して拡散処理を行うことも可能だが、これは非常に非効率的だ。例えば、512×512の画像には26万2144個のピクセルがある。代わりに、ピクセルを圧縮された潜在表現(latent representation)に変換し、このより小さなデータ量を持つ潜在空間上で拡散を行い、最後に再びピクセル空間に戻す方法がある。この手法により計算複雑度が大幅に削減され、26万2144個のピクセルを扱う代わりに、64×64=4096個の潜在表現のみを扱えばよい。この方法は「High-Resolution Image Synthesis with Latent Diffusion Models」の画期的な成果であり、Stable Diffusionの基盤でもある。

左側のピクセルを右側のグリッドで表される潜在表現にマッピング
出典:Sora 技術報告書
DiTとSoraはどちらも潜在拡散を採用しているが、Soraの場合はさらに時間次元を考慮する必要がある。動画は一連の画像(フレーム)の時系列であり、Soraの技術報告書によれば、ピクセル空間から潜在空間へのエンコードは空間的(フレームの幅・高さの圧縮)だけでなく、時間的(時間方向の圧縮)にも行われている。
詳細 2: Transformerアーキテクチャ
第二のポイントとして、DiTとSoraは一般的に使われるU-Netアーキテクチャの代わりに、基本的なTransformerアーキテクチャを採用している。これは極めて重要であり、DiTの著者らは、Transformerを使うことで予測可能なスケーリングが可能になることを発見した。つまり、モデルサイズや訓練時間の増加に伴い、モデル性能が安定して向上する。Soraの技術報告書でも同様の主張をしており、動画生成の文脈でそれを示す図も添付されている。

訓練計算量の増加に伴うモデル品質の向上:左から順に基礎計算量、4倍、32倍
このようなスケーリング特性は、よく知られる「スケーリング則(scaling law)」で定量化でき、非常に重要な性質である。LLMや他のモダリティにおける自己回帰モデルでは、スケーリング則が広く研究されてきた。スケーリングによって性能が向上することは、LLMの急速な発展を支えた原動力の一つである。画像・動画生成でも同様のスケーリングが確認された以上、今後もこの法則が適用されると期待できる。
詳細 3:データセット
Soraのようなモデルを訓練する際のもう一つの鍵となる要素は、ラベル付きデータである。データセットこそがSoraの大部分の秘密を含んでいると考えられる。text2videoモデルを訓練するには、動画と対応するテキスト説明のペアが必要である。OpenAIはデータセットについてはほとんど語っていないが、それが非常に大規模であることを示唆している。技術報告書では「インターネット規模のデータで訓練されたLLMが汎用的能力を得たことに着想を得た」と述べている。

出典:Sora 技術報告書
OpenAIはまた、画像に詳細なテキストタグを付ける方法を開発しており、これはDALL-E3のデータセット構築に使用された。具体的には、ラベル付きサブセットでキャプションモデル(captioner model)を訓練し、それを用いて残りのデータに自動でラベル付けを行う。Soraのデータセットも同様の技術を使っている可能性が高い。
03. Soraの影響
動画モデルの実用化が始まる
細部の描写や時間的連続性という観点から見ると、Soraが生成する動画の品質は確かに重要なブレークスルーである。例えば、物体が一時的に遮られた場合でもその位置を正しく保持したり、水面の反射を正確に描いたりすることができる。我々は、Soraの現時点での動画品質は特定のシナリオにおいてすでに十分実用レベルに達しており、現実世界のアプリケーションに使えると考えている。たとえば、Soraは近い将来、一部のストック動画ライブラリの需要を代替する可能性がある。
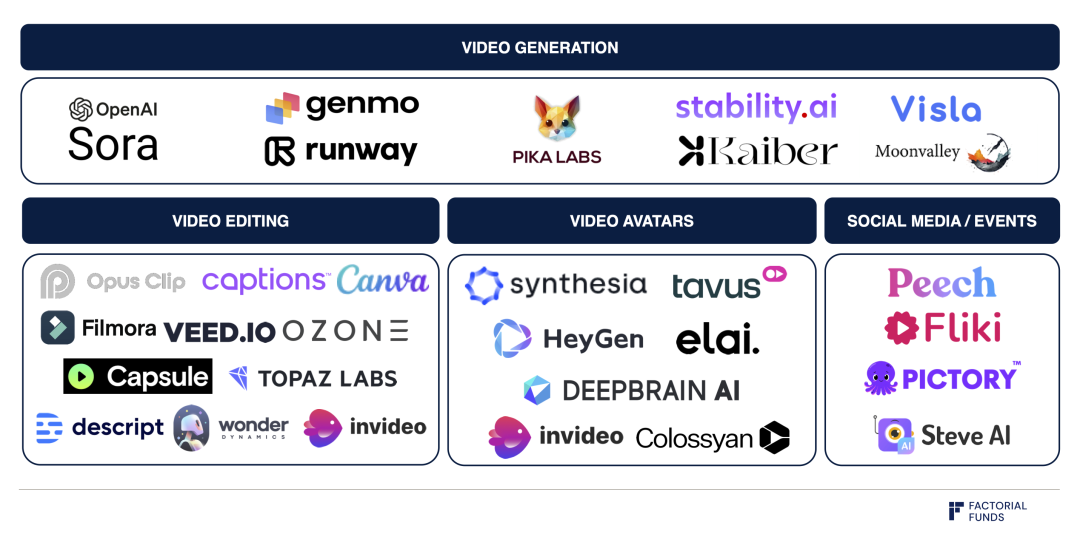
動画生成分野のエコシステム
ただし、Soraはまだいくつかの課題を抱えている。現時点ではSoraの制御性(controllability)がどの程度なのか不明である。モデルが出力するのはピクセル単位のデータであるため、生成された動画を編集するのは困難で時間がかかる。モデルを実際に有用なものにするには、直感的なUIやワークフローの構築が不可欠である。上図のように、Runway、Genmo、Pikaなどの企業がすでにこの課題に取り組んでいる。
スケーリングのおかげで、動画生成の進展が加速する
前述したように、DiTの研究では計算量の増加に伴ってモデル品質が直接向上することが示されている。これはLLMで観察されたスケーリング則と非常に似ており、より多くの計算資源で訓練すれば、動画生成モデルの品質も急速に向上すると期待できる。Soraはこれを強く裏付けている。今後、OpenAIをはじめとする企業がこの分野にさらに投資を重ねることは間違いない。
合成データ生成とデータ拡張
ロボティクスや自動運転の分野では、データ自体が本質的に希少である。これらの領域には、ロボットが日常的に作業を行う「インターネット」のような環境は存在しない。通常、これらの問題はシミュレーション環境での訓練や、現実世界での大量データ収集、あるいは両方を組み合わせることで解決される。しかし、シミュレーションデータは現実と乖離しやすく、現実でのデータ収集はコストが高く、まれな事象のデータを集めるのも難しい。

上図:元の動画(左)を濃密なジャングル環境(右)にレンダリングすることで動画を拡張
出典:Sora 技術報告書
我々は、Soraのようなモデルがこれらの課題に対処できると考えている。Soraは100%合成データの生成に直接使える可能性がある。また、既存の動画をさまざまな方法で変換することでデータ拡張(data augmentation)にも活用できる。
ここで言うデータ拡張は、技術報告書の例ですでに示されている。元の動画では赤い車が森の中の道を走っているが、Soraの処理により、熱帯雨林の中の道を走るシーンに変換されている。同じ技術を使えば、昼夜の切り替えや天候の変化も再現できるだろう。
シミュレーションとワールドモデル
「ワールドモデル(World Models)」は価値ある研究テーマである。モデルが十分に正確であれば、AIエージェントをその中で直接訓練したり、プランニングや探索に利用したりできる。
Soraのようなモデルは、動画データから現実世界の動き方を暗黙的に学習している。このような「出現的シミュレーション(emergent simulation)」は現時点では不完全だが、非常に興味深い。これは、大規模な動画データを用いてワールドモデルを訓練できる可能性を示している。さらに、Soraは液体の流れ、光の反射、繊維や髪の毛の動きといった非常に複雑な現象も模倣できるように見える。OpenAIは技術報告書のタイトルを『Video generation models as world simulators』としており、これがモデルが与える最も重要なインパクトであると信じていることを明確に示している。
最近、DeepMindも自社のGenieモデルで同様の効果を示している。一連のゲーム映像のみで訓練されたモデルが、それらのゲームを模倣し、新たなゲームさえ創造できるようになった。この場合、モデルは行動を直接観測しなくても、その行動に基づいて予測や意思決定を調整する方法を学べる。Genieのケースでは、モデルの訓練目的はこうしたシミュレーション環境での学習にある。

動画出典:Google DeepMind Genie –
Generative Interactive Environments 紹介
総合的に見て、我々は、ロボットのような具身エージェントを現実世界のタスクに基づいて大規模に訓練するには、SoraやGenieのようなモデルが必ず役立つと考えている。もちろん、こうしたモデルにも限界はある。モデルはピクセル空間で訓練されるため、風に揺れる草などタスクに関係ない細部まで模倣してしまう。潜在空間は圧縮されているとはいえ、ピクセル空間に戻す必要があるため、多くの情報を保持せざるを得ず、潜在空間内で効率的にプランニングできるかどうかは不明である。
04. 計算資源の見積もり
我々はモデルの訓練と推論それぞれがどれだけの計算資源を必要とするかに注目しており、これらは将来の計算需要を予測する上で重要である。しかし、Soraのモデルサイズやデータセットに関する詳細情報が少ないため、正確な見積もりは困難である。そのため、以下の試算は現実を正確に反映していない可能性があるため、慎重に参照されたい。
DiTに基づくSoraの計算規模の推定
Soraの詳細情報は非常に限られているが、DiT論文を参考にすれば、Soraの計算量を推定できる。なぜなら、Soraは明らかにDiTの研究に基づいているからである。最大のDiTモデルであるDiT-XLは6.75億のパラメータを持ち、訓練には約1021FLOPSの総計算量が必要だった。この規模を理解するために、これは0.4枚のNvidia H100を1か月間使う、あるいは1枚のH100を12日間使うことに相当する。
現在、DiTは画像生成に限定されているが、Soraは動画モデルである。Soraは最長1分間の動画を生成できる。仮にエンコードフレームレートを24fpsとすると、1本の動画には最大1440フレーム含まれる。Soraはピクセル空間から潜在空間へのマッピングにおいて、時間方向と空間方向の両方で圧縮を行っている。もしDiT論文と同じ8倍の圧縮率を採用していると仮定すれば、潜在空間では180フレームになる。したがって、DiTの数値を動画に線形外挿すると、Soraの計算量はDiTの180倍と見積もられる。
さらに、Soraのパラメータ数は6.75億を大きく超えており、200億程度である可能性もある。これにより、パラメータ数の面からはDiTの約30倍の計算量が必要になる。
最後に、Soraの訓練データセットはDiTよりもはるかに大きいと考えられる。DiTはバッチサイズ256で300万ステップ訓練され、合計7.68億枚の画像が処理された。ただし、ImageNetが1400万枚しかないため、同じデータが繰り返し使用されている。Soraは画像と動画の混合データセットで訓練されていると思われるが、詳細は不明である。ここでは、データセットの50%が静止画、50%が動画で構成され、DiTのデータセットより10~100倍大きいと仮定する。ただし、DiTでは同じデータポイントを繰り返し訓練しており、より大規模なデータセットが利用可能な場合、これは非最適である可能性がある。そのため、データセットの増加による計算量の乗数は4~10倍が妥当だと考える。
以上の情報を統合し、データセット規模の異なる前提を考慮すると、以下のように計算される:
式:DiTの基本計算量 × モデル規模増加 × データセット増加 × 180フレームによる計算量増加(データセットの50%にのみ適用)
-
データセット規模の控えめな推定:1021 FLOPS × 30 × 4 × (180 / 2) ≒ 1.1×10²⁵ FLOPS
-
データセット規模の楽観的な推定:1021 FLOPS × 30 × 10 × (180 / 2) ≒ 2.7×10²⁵ FLOPS
Soraの計算規模は、4211〜10528枚のH100を1か月間使用する計算量に相当する。
計算需要:推論 vs 訓練
計算需要を考える上で重要なもう一つの視点は、訓練と推論の計算量の比較である。理論的には、訓練の計算量が巨大であっても、それは一回限りのコストである。一方、推論の計算量は一回あたりは小さいが、生成ごとに発生し、ユーザー数の増加とともに累積していく。したがって、ユーザーが増え、モデルが広く使われるようになればなるほど、推論の重要性は高まっていく。
そのため、推論計算が訓練計算を上回る「臨界点」を見つけることは極めて意義深い。
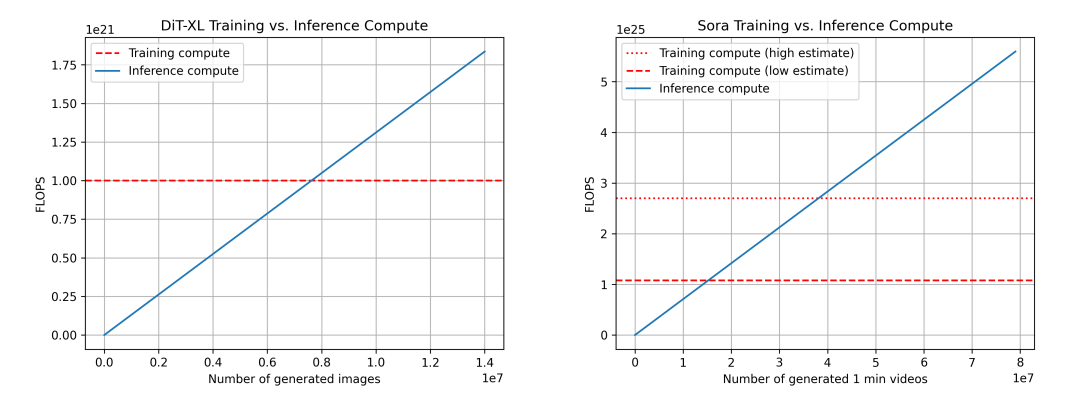
DiT(左)とSora(右)の訓練・推論計算量の比較。Soraについては前述の推定に基づき、信頼性は低い。また、データセット規模の乗数を4倍(低推定)と10倍(高推定)の二通りで示している。
ここで再びDiTを用いてSoraを推定する。DiT-XLの最大モデルでは、1回の推論に524×10⁹ FLOPSを使用し、250ステップの拡散処理を経るため、1枚の画像生成に要する総FLOPSは131×10¹²である。760万枚の画像生成後に「推論=訓練」の臨界点に達し、以降は推論が計算需要の主体となる。参考までに、Instagramには毎日約9500万枚の画像がアップロードされている。
Soraの場合、FLOPSは524×10⁹ × 30 × 180 ≒ 2.8×10¹⁵ FLOPSと推定される。各動画に250ステップの拡散を仮定すると、1本の動画あたりの総FLOPSは708×10¹⁵ FLOPSとなる。これは、1枚のH100で1時間に約5分の動画を生成できることに相当する。データセット規模を控えめに見積もった場合、1530万分の動画生成で臨界点に達し、楽観的に見積もった場合は3810万分で到達する。参考までに、YouTubeには毎日約4300万分の動画がアップロードされている。
補足として、推論においてFLOPS以外の要素も重要である。たとえば、メモリ帯域幅も重要であり、拡散ステップを削減する研究も進行中であり、これにより計算需要の削減と推論速度の向上が期待される。また、訓練と推論におけるFLOPS利用率も異なる可能性があり、これは重要な考慮事項である。
Yang Song、Prafulla Dhariwal、Mark Chen、Ilya Sutskeverは2023年3月に『Consistency Models』を発表し、拡散モデルが画像・音声・動画生成で大きな進展を遂げた一方で、反復的サンプリングに依存し生成が遅いという課題を指摘。一貫性モデルを提案し、計算を交換することでサンプル品質を向上させることを示した。https://arxiv.org/abs/2303.01469
モダリティ別のモデル推論計算需要
我々は、異なるモダリティにおけるモデルの単位出力あたりの推論計算量の傾向も調査した。これは、計算計画や需要予測に直接影響を与える。各モデルの出力単位は異なり、Soraは1分間の動画、DiTは512×512ピクセルの画像、Llama 2およびGPT-4は1000トークンのテキスト(参考:平均的なWikipedia記事は約670トークン)を1単位としている。
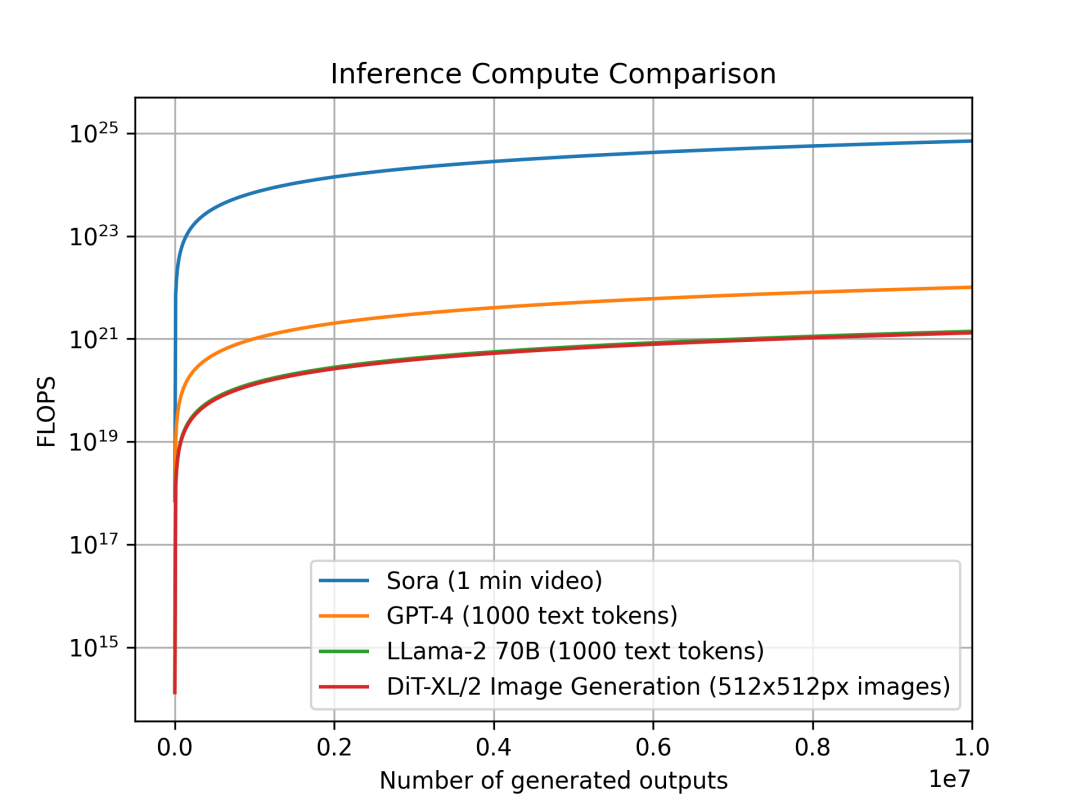
単位出力あたりの推論計算比較:Soraは1分間の動画、GPT-4とLLama 2は1000トークンのテキスト、DiTは512×512pxの画像。Soraの推論計算は数オーダー高い。
Sora、DiT-XL、LLama2-70B、GPT-4を比較し、log-scaleでFLOPSをプロットした。SoraとDiTには前述の推定値を、LLama 2とGPT-4には「FLOPS = 2 × パラメータ数 × 生成トークン数」で簡易推定を用いた。GPT-4についてはMoEモデルと仮定し、各エキスパートが2200億パラメータを持ち、前向伝播時に2エキスパートが活性化するとした。なお、GPT-4のデータはOpenAI公式ではないため、参考値である。
出典:X
DiTやSoraのような拡散ベースモデルは、推論フェーズでより多くの計算資源を消費することがわかる。6.75億パラメータのDiT-XLは、700億パラメータのLLama 2とほぼ同等の推論コストを要する。さらに、Soraの推論コストはGPT-4よりも数オーダー高い。
繰り返すが、上記の計算には多くの推定値が含まれ、単純化された仮定に依存している。実際のGPUのFLOPS利用率、メモリ容量・帯域幅の制限、推測デコーディング(speculative decoding)などの高度な技術は考慮されていない。
Soraが広く使われた場合の推論計算需要の予測:
ここでは、Soraの計算需要から、TikTokやYouTubeでAI生成動画が大規模に使われた場合に必要なNvidia H100の台数を試算する。
• 上述の通り、1枚のH100で1時間に5分の動画が生成可能。つまり、1日あたり120分の動画を生成できる。
• TikTok:現在、ユーザーは毎日1700万分の動画をアップロード(3400万本×平均30秒)。AI浸透率を50%と仮定。
• YouTube:現在、毎日4300万分の動画がアップロード。AI浸透率を15%と仮定(主に2分未満の動画)。
• AIが1日に生成する動画総量:850万 + 650万 = 1500万分。
• TikTokおよびYouTubeのクリエイターコミュニティを支えるために必要なH100総数:1500万 ÷ 120 ≒ 8.9万枚。
ただし、この8.9万枚という数字は低めの可能性がある。以下の要因を考慮する必要がある:
• 試算ではFLOPS利用率100%を仮定しているが、メモリや通信のボトルネックを考慮すると、実際の利用率は50%程度が現実的。つまり、必要なGPU台数は2倍となる。
• 推論需要は時間的に均等ではなく、ピーク時に集中する。サービスを保証するため、さらに2倍のGPUが必要と考えられる。
TechFlow公式コミュニティへようこそ Telegram購読グループ:https://t.me/TechFlowDaily Twitter公式アカウント:https://x.com/TechFlowPost Twitter英語アカウント:https://x.com/BlockFlow_News










