

まだリリースされていないのに、なぜSoraはインターネット業界を震撼させたのか?
TechFlow厳選深潮セレクト
まだリリースされていないのに、なぜSoraはインターネット業界を震撼させたのか?
OpenAIはこれを直接「ワールドシミュレーター」と呼び、物理世界における人間、動物、環境の特徴をシミュレートできるとしている。
執筆:木沐
まだ一般向けのテストが開始されていないにもかかわらず、OpenAIがテキストから動画を生成するモデル「Sora」で制作したプロモーション映像によって、テクノロジー業界、インターネット業界、ソーシャルメディア業界が震撼している。
OpenAIが公式に公開した動画によると、Soraはユーザーが提供したテキスト情報をもとに、最大1分間の複雑なシーンを持つ「超動画」を生成できる。その映像のディテールは非常にリアルであり、さらにカメラの動きまで模倣することが可能だ。
すでに公開されている映像効果を見る限り、業界が注目しているのはSoraが示す現実世界の理解能力である。他のテキストから動画を生成する大規模モデルと比較して、Soraは意味理解、画面表現、視覚的連続性、再生時間の面で優位性を示している。
OpenAIは自らこれを「ワールドシミュレーター」と呼んでおり、物理世界における人間、動物、環境の特性を模倣できることを宣言している。しかし同社は、現在のSoraには未完成な点があり、理解不足や潜在的な安全上の問題があることも認めている。
そのため、Soraのテストはごく少数の人々に限定されており、一般へのリリース時期についてOpenAIはまだ発表していない。しかし、その衝撃は類似モデルを開発している企業にとって大きなプレッシャーとなっている。
Soraの「プロモーション映像」が人々を驚かせる
OpenAIのテキストから動画を生成するモデルSoraが登場すると、中国国内でも再び「衝撃的」と称する評価が相次いだ。
ネットメディアは「現実が存在しなくなった」と叫び、IT業界の大物たちもSoraの能力を絶賛している。360の創業者である周鴻祎(ジョウ・ホンイ)氏は、Soraの誕生によりAGI(汎用人工知能)の実現が従来の10年から約2年に短縮されるかもしれないと述べた。わずか数日で、Soraに関するGoogle検索指数は急上昇し、ChatGPTに匹敵するほどの話題性を獲得した。
Soraが注目を集めたのは、OpenAIが公開した48本の動画によるもので、最長のものは1分間である。これはそれ以前のテキストから動画を生成するモデルGen2やRunwayの動画長の限界を超えただけでなく、映像の画質も明瞭で、さらにはカメラワークさえ学習している。
1分間の動画では、赤いドレスを着た女性がネオンサインが立ち並ぶ街を歩いている。リアリズムのあるスタイルで、映像は滑らかであり、特に女性のクローズアップでは、顔の毛穴、そばかす、ニキビ跡まで忠実に再現されており、メイク崩れやファンデーションのヨレは、まるでライブ配信で美肌フィルターをオフにしたかのようだ。首のシワまでもが正確に年齢を「暴露」しており、顔と首の状態が完璧に統一されている。
人物のリアリズムだけでなく、Soraは現実の動物や環境も模倣できる。ある動画では、ヴィクトリア冠鳩の多角的クローズアップが映され、鳥の体全体から頭頂部までの青い羽根が超高精細で描写されており、赤い瞳の動きや呼吸のリズムまで細かく再現されており、これがAI生成なのか人間が撮影したものなのか見分けがつかないほどだ。
リアリズムではない創造的なアニメーションにおいても、Soraの生成結果はディズニーのアニメ映画のようなクオリティに達しており、ネットユーザーからはアニメーターの職業が脅かされるのではないかという懸念が出ている。
Soraがテキストから動画を生成するモデルにもたらした進歩は、動画の長さや画質だけにとどまらない。カメラの動きや撮影軌道、ゲームの一人称視点、空撮視点、さらには映画のようなワンカット長回しも模倣できるのだ。
OpenAIが公開した素晴らしい動画を見れば、なぜテック業界やソーシャルメディアの世論がSoraに驚愕したのか理解できるだろう。だがこれらはすべて「プロモーション映像」にすぎない。
OpenAIが提唱する「ビジュアルパッチ」データセット
では、Soraはどのようにしてこのような模倣能力を実現しているのか?
OpenAIが公開したSoraの技術報告書によると、このモデルは従来の画像データ生成モデルの制約を越えようとしている。
これまでのテキストから視覚コンテンツを生成する研究では、リカレントネットワーク、生成的敵対ネットワーク(GAN)、自己回帰変換器、拡散モデルなどさまざまな手法が使われてきたが、いずれも視覚データの種類が限られ、短い動画や固定サイズの動画に集中していた。
Soraはトランスフォーマーに基づく拡散モデルを採用しており、画像生成プロセスは「順方向プロセス」と「逆方向プロセス」の二段階に分けられる。これにより、Soraは時間軸に沿って前後に動画を拡張できる能力を持つ。
順方向プロセスでは、実際の画像から完全なノイズ画像へと拡散する過程を模倣する。具体的には、モデルが徐々に画像にノイズを加え、最終的に画像が完全にノイズになるまで続ける。逆方向プロセスはその逆で、ノイズ画像から元の画像を徐々に復元していく。この一往一復のプロセスを通じて、OpenAIは機械であるSoraに視覚情報の形成を理解させている。
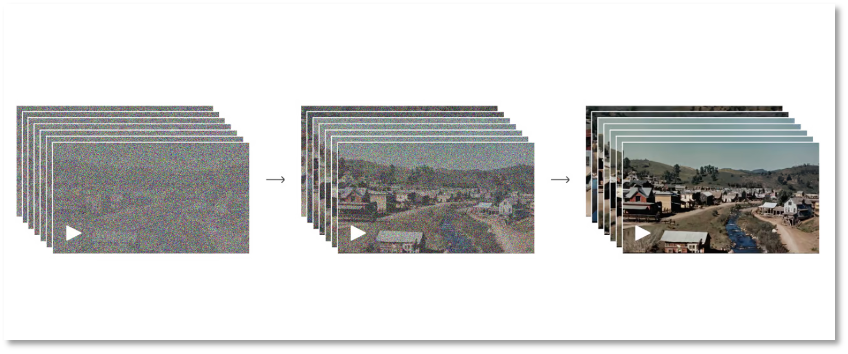 ノイズから鮮明な画像へ
ノイズから鮮明な画像へ
もちろん、このプロセスは繰り返しの訓練と学習を必要とする。モデルはノイズを段階的に除去し、画像のディテールを復元する方法を学ぶ。この二つのプロセスを反復することで、Soraの拡散モデルは高品質な画像を生成できるようになる。このモデルは、画像生成、画像編集、スーパーレゾリューションなどの分野で優れた性能を発揮している。
上述のプロセスにより、Soraが高解像度かつ極めて詳細な映像を生成できる理由が説明される。しかし、静止画から動画へと移行するには、さらに多くのデータ収集と訓練が必要となる。
拡散モデルの基盤に加えて、OpenAIは動画や画像といったあらゆる種類の視覚データを統一された表現形式に変換し、Soraに対して大規模な生成訓練を行っている。この表現形式をOpenAIは「ビジュアルパッチ(patches)」と定義しており、これはGPTにおけるテキストトークンの集合に類似した、より小さなデータ単位の集合である。
研究者たちはまず、動画を低次元の潜在空間に圧縮し、その後この表現を時空間パッチ(spatio-temporal patch)に分解する。これは非常に拡張性の高い表現形式であり、動画からパッチへの変換を容易にし、さまざまなタイプの動画や画像の生成モデルの訓練に適している。
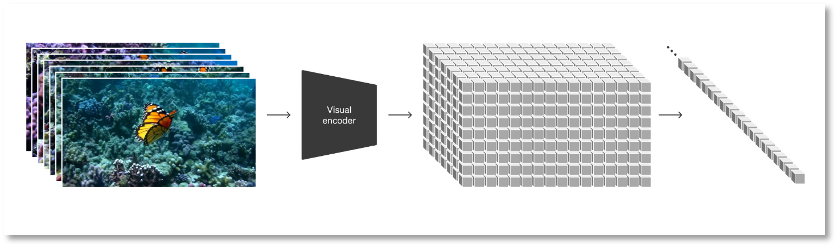 視覚データをパッチに変換
視覚データをパッチに変換
Soraの訓練に必要な情報量と計算量を減らすため、OpenAIは動画圧縮ネットワークを開発した。まず動画をピクセルレベルの低次元潜在空間に次元削減し、その後圧縮された動画データを使ってパッチを生成する。これにより入力情報が減少し、計算負荷が軽減される。同時に、OpenAIは圧縮された情報をピクセル空間に戻すためのデコーダーモデルも訓練している。
このビジュアルパッチに基づく表現方式により、研究者は異なる解像度、長さ、アスペクト比を持つ動画/画像に対してSoraを訓練できるようになった。推論フェーズに入ると、Soraは適切なサイズのグリッド内にランダムに初期化されたパッチを配置することで、動画の論理を判断し、生成される動画のサイズを制御できる。
OpenAIの報告によると、大規模な訓練を行うことで、動画モデルは興味深い機能を示すようになる。たとえば、Soraは現実世界の人間、動物、環境をリアルに模倣し、高忠実度の動画を生成できるだけでなく、3Dの一貫性、時間的一貫性を実現し、物理世界を忠実にシミュレートできるようになる。
Altmanが中継役となりユーザーのテストを支援
結果から開発プロセスまで、Soraは強大な能力を見せているが、一般ユーザーはまだ体験できない。現状では、プロンプトをX(旧Twitter)上でSam Altmanに送信し、彼が中継役となってSoraで動画を生成し、その結果を公開する形になっている。
こうなると、SoraがOpenAIが公式に示しているほど本当に優れているのか疑問に思う人も少なくない。
これについてOpenAIは、現時点でのモデルにはいくつかの問題があると率直に認めている。初期のGPTと同様、今のSoraにも「ハルシネーション(幻覚)」が存在する。これは主に視覚情報を中心とした動画結果において、より具体的な誤りとして現れる。
例えば、走馬機のベルトと人の動作の関係、ガラス杯が割れて中の液体が流れ出すタイミングの論理など、多くの基本的な相互作用の物理プロセスを正確に模倣できない。
以下の「考古学者たちがプラスチック製の椅子を発掘する」動画では、プラスチック椅子が砂の中からそのまま「浮き上がっている」。
また、突然出現する子狼がネットユーザーから「狼の有糸分裂」と皮肉られている。
前後左右の区別がつかないこともある。
これらの動画に見られる不備は、Soraが物理世界の運動に関する論理をさらに理解し、訓練を重ねる必要があることを示している。さらに、ChatGPTのリスクと比べて、直感的な視覚体験を提供するSoraには、倫理的・安全上のリスクがより深刻である。
以前、テキストから画像を生成するモデルMidjourneyは、「画像があっても真実とは限らない」という事実を人類に突きつけた。AIが作り出した本物そっくりの画像は、すでにデマの要素になりつつある。本人確認サービス会社iProovの最高科学責任者ニューウェル博士は、「Soraによって悪意ある行為者が高品質な偽動画を作成しやすくなる」と指摘している。
想像すればわかるが、もしSoraによって生成された動画が悪用され、詐欺や名誉毀損、暴力やポルノの拡散に利用された場合、その結果は計り知れない。これがSoraに驚きとともに恐怖を感じさせる所以である。
OpenAIもSoraが引き起こしうる安全上の問題を考慮しており、おそらくそれがSoraのテストをごく少数の招待制ユーザーに限定している理由であろう。一般公開はいつになるのか? OpenAIはタイムラインを示していないが、公式が公開した映像を見る限り、他社がSoraに追いつく時間はあまり残されていない。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News










