

Foresight Ventures:分散型コンピューティングネットワークの分析と考察
TechFlow厳選深潮セレクト
Foresight Ventures:分散型コンピューティングネットワークの分析と考察
AI大規模モデルの発展トレンドの中で、計算リソースは次の10年間の大きな戦場となるだけでなく、将来の人間社会において最も重要な要素でもある。
執筆:Yihan@Foresight Ventures
概要
-
現在のAI+Cryptoの連携ポイントは主に2つの大きな方向がある:分散型コンピューティングリソースとZKML。ZKMLについては以前の私の記事を参照。本稿では分散型の分散コンピューティングネットワークについて分析と考察を行う。
-
AI大規模モデルの発展トレンドにおいて、コンピューティングリソースは次の10年間の大きな戦場であり、将来の人間社会で最も重要なものになる。これは商業競争にとどまらず、大国間の戦略的資源としても重要となる。今後、高性能計算インフラやコンピューティングリソースの投資は指数関数的に増加するだろう。
-
分散型コンピューティングネットワークは、AI大規模モデルの学習において最大の需要を持つ一方で、最大の課題と技術的ボトルネックにも直面している。複雑なデータ同期やネットワーク最適化の問題が含まれる。また、データのプライバシーとセキュリティも重要な制約要因である。既存の技術で初期的な解決策が提供されているが、大規模な分散学習タスクでは、計算および通信オーバーヘッドが大きいため、これらはまだ実用化されていない。
-
分散型コンピューティングネットワークはモデル推論においてより現実的な応用が期待でき、将来的な成長余地も十分にあると考えられる。しかし、通信遅延、データプライバシー、モデルセキュリティなどの課題も抱える。モデル学習と比較して、推論時の計算複雑度とデータ相互作用性は低く、分散環境での実行に適している。
-
スタートアップ企業TogetherとGensyn.aiの事例を通じて、それぞれ技術的最適化とインセンティブレイヤー設計の観点から、分散型コンピューティングネットワーク全体の研究方向と具体的なアプローチを説明する。
分散コンピューティング — 大規模モデル学習
分散コンピューティングの学習への応用を考える場合、通常は大規模言語モデルの学習に焦点を当てる。その主な理由は、小規模モデルの学習にはあまりコンピューティングリソースが必要ないため、データプライバシーや工学的問題を解決するために分散化を行うメリットが薄く、むしろ集中型で解決した方が効率的だからである。一方、大規模言語モデルは膨大なコンピューティングリソースを必要としており、現在は爆発的成長の初期段階にある。2012年~2018年の間、AIの計算需要は約4か月ごとに倍増しており、現在でもコンピューティング需要の集中点となっており、今後5~8年間は依然として大きな需要増が見込まれる。
大きな機会がある一方で、問題も明確に認識しておく必要がある。誰もが市場規模の大きさは理解しているが、具体的な課題はどこにあるのか?どのプロジェクトがこれらの課題に真正面から取り組み、盲目的に参入しないかが、この分野の優れたプロジェクトを見極める鍵となる。
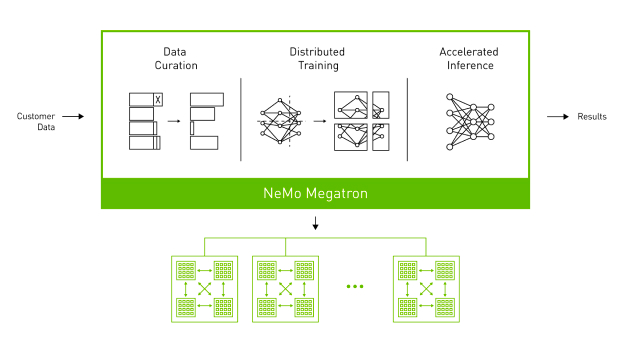
(NVIDIA NeMo Megatron Framework)
1. 全体の学習プロセス
1750億パラメータを持つ大規模モデルの学習を例に挙げる。モデル規模が巨大であるため、多数のGPUデバイス上で並列学習を行う必要がある。中心化されたデータセンターに100台のGPUがあり、各デバイスが32GBのメモリを持っていると仮定する。
-
データ準備:まず巨大なデータセットが必要であり、インターネット情報、ニュース、書籍など様々なデータを含む。学習前にこれらのデータを前処理する必要があり、テキストのクリーニング、トークン化(tokenization)、語彙構築などが含まれる。
-
データ分割:処理済みのデータは複数のバッチに分割され、複数のGPU上で並列処理される。バッチサイズを512とすると、各バッチは512のテキストシーケンスを含む。その後、全データセットを複数のバッチに分割し、バッチキューを形成する。
-
デバイス間データ転送:各学習ステップの開始時に、CPUがバッチキューから1つのバッチを取り出し、PCIeバスを通じてGPUにデータを送信する。各テキストシーケンスの平均長さが1024トークンと仮定し、各トークンが4バイトの単精度浮動小数点数で表現されるとすると、各バッチのデータサイズは約512 * 1024 * 4 B = 2 MBとなる。このデータ転送プロセスは通常数ミリ秒で完了する。
-
並列学習:各GPUデバイスがデータを受信した後、順伝播(forward pass)と逆伝播(backward pass)の計算を行い、各パラメータの勾配を計算する。モデル規模が非常に大きいため、単一のGPUのメモリではすべてのパラメータを保持できないため、モデル並列技術を使用して、パラメータを複数のGPUに分散させる。
-
勾配集約とパラメータ更新:逆伝播計算が完了した後、各GPUは一部のパラメータに関する勾配を得る。その後、これらの勾配はすべてのGPUデバイス間で集約され、グローバル勾配を算出する必要がある。これはネットワークを介したデータ転送を必要とする。25 Gbpsのネットワークを使用すると仮定し、700 GBのデータ(各パラメータが単精度浮動小数点数を使用すると仮定し、1750億パラメータは約700 GB)を転送するには約224秒かかる。その後、各GPUはグローバル勾配に基づいて自身が保持するパラメータを更新する。
-
同期:パラメータ更新後、すべてのGPUデバイスは同期を行い、次回の学習ステップで一貫したモデルパラメータを使用することを保証する。これもネットワークを介したデータ転送を必要とする。
-
学習ステップの繰り返し:上記のステップを繰り返し、すべてのバッチの学習が完了するか、予定されたエポック数に達するまで続ける。
このプロセスには大量のデータ転送と同期が伴い、学習効率のボトルネックとなる可能性がある。そのため、ネットワーク帯域幅と遅延の最適化、効率的な並列処理および同期戦略の使用は、大規模モデルの学習にとって非常に重要である。
2. 通信オーバーヘッドのボトルネック:
注意すべきは、通信のボトルネックが現在の分散コンピューティングネットワークが大規模言語モデルの学習に使えない原因となっていることである。
各ノードは協調作業のために頻繁に情報を交換する必要があり、これが通信オーバーヘッドを生む。大規模言語モデルの場合、パラメータ数が非常に多いため、この問題は特に深刻である。通信オーバーヘッドは以下の側面に分けられる:
-
データ転送:学習中にノードはモデルパラメータや勾配情報を頻繁に交換する必要がある。これは大量のデータをネットワーク上で転送することを意味し、大量のネットワーク帯域幅を消費する。ネットワーク状態が悪かったり、計算ノード間の距離が遠い場合、データ転送の遅延が非常に高くなり、さらに通信オーバーヘッドが増大する。
-
同期問題:学習中、ノードは学習の正確な進行を保証するために協調作業を行う必要がある。これには各ノード間での頻繁な同期操作が必要であり、例えばモデルパラメータの更新、グローバル勾配の計算などがある。これらの同期操作はネットワーク上で大量のデータを転送する必要があり、すべてのノードが操作を完了するのを待つ必要があるため、大量の通信オーバーヘッドと待ち時間が発生する。
-
勾配蓄積と更新:学習プロセス中、各ノードは自身の勾配を計算し、他のノードに送信して蓄積と更新を行う。これはネットワーク上で大量の勾配データを転送する必要があり、すべてのノードが勾配の計算と転送を完了するのを待つ必要があるため、大量の通信オーバーヘッドの原因となる。
-
データ一貫性:各ノードのモデルパラメータが一貫していることを保証する必要がある。これには各ノード間での頻繁なデータ検証と同期操作が必要であり、大量の通信オーバーヘッドを引き起こす。
通信オーバーヘッドを削減する方法もいくつか存在するが、例えばパラメータや勾配の圧縮、効率的な並列戦略などがある。しかし、これらの方法は追加の計算負荷をもたらしたり、モデルの学習効果に悪影響を及ぼす可能性がある。また、これらの方法は通信オーバーヘッド問題を完全に解決できるわけではなく、特にネットワーク状態が悪かったり、計算ノード間の距離が遠い場合には有効でない。
具体例:
分散型分散コンピューティングネットワーク
GPT-3モデルは1750億のパラメータを持ち、単精度浮動小数点数(各パラメータ4バイト)を使用してこれらのパラメータを表現すると、それらを保存するには約700 GBのメモリが必要である。分散学習では、これらのパラメータは各計算ノード間で頻繁に転送・更新される必要がある。
100の計算ノードがあり、各ノードが各ステップですべてのパラメータを更新する必要があると仮定すると、各ステップで約70 TB(700 GB × 100)のデータを転送する必要がある。1ステップに1秒かかると仮定(非常に楽観的な仮定)すると、毎秒70 TBのデータを転送する必要がある。この帯域幅の要求はすでにほとんどのネットワークを大きく超えており、実現可能性の問題でもある。
実際には、通信遅延やネットワーク混雑により、データ転送時間は1秒以上かかる可能性が高い。つまり、計算ノードは実際に計算を行うよりも多くの時間をデータ転送の待ちに費やすことになり、学習効率が大幅に低下する。この効率の低下は「待てばいい」というレベルではなく、「可能か不可能か」の違いとなり、学習プロセス全体を非現実的にする。
集中型データセンター
集中型データセンター環境であっても、大規模モデルの学習には依然として重い通信最適化が必要である。
集中型データセンター環境では、高性能計算デバイスがクラスタとして高速ネットワークで接続され、計算タスクを共有する。しかし、このような高速ネットワーク環境であっても、パラメータ数が非常に多いモデルの学習では、通信オーバーヘッドは依然としてボトルネックとなる。なぜなら、モデルのパラメータと勾配は各計算デバイス間で頻繁に転送・更新される必要があるからである。
前述のように、100の計算ノードがあり、各サーバーが25 Gbpsのネットワーク帯域幅を持つと仮定する。各サーバーが各学習ステップですべてのパラメータを更新する必要がある場合、各学習ステップで約700 GBのデータを転送するのに約224秒かかる。集中型データセンターの利点により、開発者はデータセンター内でネットワークトポロジーを最適化し、モデル並列などの技術を使用することで、この時間を大幅に短縮できる。
一方、同じ学習を分散環境で行う場合、依然として100の計算ノードが世界中に分散しており、各ノードのネットワーク帯域幅が平均1 Gbpsと仮定する。この場合、同じ700 GBのデータを転送するには約5600秒かかり、集中型データセンターに比べてはるかに長い。さらに、ネットワーク遅延や混雑により、実際の所要時間はさらに長くなる可能性がある。
比較すると、分散コンピューティングネットワークにおける通信オーバーヘッドの最適化は、集中型データセンターに比べてはるかに困難である。集中型データセンターでは、計算デバイスは通常同じ高速ネットワークに接続されており、ネットワークの帯域幅と遅延は比較的良好である。一方、分散コンピューティングネットワークでは、計算ノードは世界中に分散しており、ネットワーク状態が比較的悪くなる可能性があり、通信オーバーヘッドの問題がさらに深刻になる。
OpenAIがGPT-3を学習する過程で、Megatronというモデル並列フレームワークを使用して通信オーバーヘッドの問題を解決した。Megatronはモデルのパラメータを分割し、複数のGPUで並列処理することで、各デバイスが保持・更新するパラメータ量を減らし、通信オーバーヘッドを低減する。同時に、高速相互接続ネットワークを使用し、ネットワークトポロジーを最適化することで、通信経路の長さを短縮している。
(LLMモデル学習に使用されたデータ)
3. 分散コンピューティングネットワークがこれらの最適化を行えない理由
もちろん不可能ではないが、集中型データセンターと比較すると、これらの最適化の効果は限定的である。
1. ネットワークトポロジーの最適化:集中型データセンターでは、ネットワークハードウェアとレイアウトを直接制御できるため、必要に応じてネットワークトポロジーを設計・最適化できる。しかし、分散環境では、計算ノードが異なる地理的位置に分散しており、例えば中国とアメリカに一つずつある場合、それらの間のネットワーク接続を直接制御することはできない。ソフトウェアでデータ転送パスを最適化することはできるが、ハードウェアネットワークの直接最適化ほど効果的ではない。また、地理的差異により、ネットワーク遅延と帯域幅に大きな変動があり、ネットワークトポロジー最適化の効果がさらに制限される。
2. モデル並列:モデル並列はモデルのパラメータを複数の計算ノードに分割する技術であり、並列処理によって学習速度を向上させる。しかし、この方法は通常、ノード間でのデータ転送が頻繁に行われるため、ネットワーク帯域幅と遅延に対する要求が非常に高い。集中型データセンターではネットワーク帯域幅が高く、遅延が低いため、モデル並列は非常に効果的である。しかし、分散環境ではネットワーク状態が悪いため、モデル並列は大きな制約を受ける。
4. データセキュリティとプライバシーの課題
データ処理と転送に関わるほぼすべての環節がデータセキュリティとプライバシーに影響を与える可能性がある:
1. データ分配:学習データは各参加計算ノードに分配される必要がある。この環節で、データが分散ノードで悪意を持って使用・漏洩される可能性がある。
2. モデル学習:学習プロセス中、各ノードは割り当てられたデータを使用して計算を行い、その後モデルパラメータの更新または勾配を出力する。このプロセスで、ノードの計算プロセスが盗まれたり、結果が悪意を持って解析されたりすると、データが漏洩する可能性がある。
3. パラメータと勾配の集約:各ノードの出力はグローバルモデルを更新するために集約される必要があり、集約プロセス中の通信も学習データに関する情報を漏らす可能性がある。
データプライバシー問題に対する解決策は何か?
-
安全なマルチパーティ計算 (SMC):特定の小規模な計算タスクでは成功裏に適用されている。しかし、大規模な分散学習タスクでは、計算および通信オーバーヘッドが大きいため、まだ広く使用されていない。
-
差分プライバシー (DP):Chromeのユーザー統計など、一部のデータ収集・分析タスクで使用されている。しかし、大規模なディープラーニングタスクでは、モデルの正確性に影響を与える。また、適切なノイズ生成と追加メカニズムの設計も課題である。
-
フェデレーテッドラーニング (FL):Androidキーボードの語彙予測など、エッジデバイスのモデル学習タスクで使用されている。しかし、より大規模な分散学習タスクでは、通信オーバーヘッドが大きく、調整が複雑という問題がある。
-
準同型暗号 (HE):計算複雑度が小さいタスクで成功裏に適用されている。しかし、大規模な分散学習タスクでは、計算オーバーヘッドが大きいため、まだ広く使用されていない。
まとめ
上記の各方法にはそれぞれ適したシーンと限界があり、分散コンピューティングネットワークの大規模モデル学習でデータプライバシー問題を完全に解決する方法は存在しない。
期待されるZKは大規模モデル学習時のデータプライバシー問題を解決できるか?
理論的にはZKPは分散計算におけるデータプライバシーを保証するために使用でき、あるノードが規定通りに計算を行ったことを証明しつつ、実際の入力・出力データを明らかにせずに済む。
しかし、実際にはZKPを大規模分散コンピューティングネットワークでの大規模モデル学習に適用するには以下のボトルネックがある:
-
計算・通信オーバーヘッドの増加:ゼロ知識証明の構築と検証には大量の計算リソースが必要。また、ZKPの通信オーバーヘッドも大きく、証明自体の転送が必要である。大規模モデル学習の場合、これらのオーバーヘッドは特に顕著になる可能性がある。例えば、各ミニバッチの計算ごとに証明を生成する必要がある場合、学習の総時間とコストが大幅に増加する。
-
ZKプロトコルの複雑さ:大規模モデル学習に適したZKPプロトコルの設計と実装は非常に複雑である。このプロトコルは大規模なデータと複雑な計算を扱え、発生する可能性のある例外エラーも処理できる必要がある。
-
ハードウェアとソフトウェアの互換性:ZKPの使用には特定のハードウェアとソフトウェアサポートが必要であり、すべての分散計算デバイスで利用可能なわけではない。
まとめ
ZKPを大規模分散コンピューティングネットワークでの大規模モデル学習に適用するには、数年にわたる研究と開発が必要であり、学術界もこの方向にさらに多くの精力とリソースを注ぐ必要がある。
分散コンピューティング — モデル推論
分散コンピューティングのもう一つの大きな応用分野はモデル推論である。大規模モデルの発展経路を判断すると、モデル学習の需要はピーク後に大規模モデルの成熟とともに徐々に減少する一方で、モデル推論の需要は大規模モデルとAIGCの成熟に伴い指数関数的に増加すると考えられる。
推論タスクは学習タスクと比較して、通常計算複雑度が低く、データ相互作用性も弱いため、分散環境での実行に適している。
(Power LLM inference with NVIDIA Triton)
1. 課題
通信遅延:
分散環境では、ノード間の通信は不可欠である。去中心化された分散コンピューティングネットワークでは、ノードが世界中に分散している可能性があるため、ネットワーク遅延が問題となる。特にリアルタイム応答が必要な推論タスクでは顕著である。
モデルの展開と更新:
モデルは各ノードに展開される必要がある。モデルが更新された場合、各ノードは自身のモデルを更新する必要があり、大量のネットワーク帯域幅と時間が消費される。
データプライバシー:
推論タスクは通常入力データとモデルのみを必要とし、大量の中間データやパラメータを返す必要はないが、入力データには依然としてユーザーの個人情報などの機微情報が含まれる可能性がある。
モデルセキュリティ:
去中心化ネットワークでは、モデルは信頼できないノードに展開される必要があり、モデルの漏洩による知的財産権侵害や悪用の問題が生じる可能性がある。また、モデルが機微データを処理する場合、ノードはモデルの挙動を分析することで機微情報を推測する可能性があり、セキュリティとプライバシーの問題を引き起こす。
品質管理:
去中心化分散コンピューティングネットワーク内の各ノードは異なる計算能力とリソースを持つ可能性があり、推論タスクの性能と品質の保証が難しくなる。
2. 実現可能性
計算複雑度:
学習段階では、モデルは繰り返し反復する必要があり、各層で順伝播と逆伝播の計算(活性化関数の計算、損失関数の計算、勾配の計算、重みの更新)を行うため、計算複雑度が高い。
推論段階では、予測結果を得るために一度だけ順伝播計算を行うだけでよい。例えばGPT-3では、入力テキストをベクトルに変換し、モデルの各層(通常はTransformer層)を順伝播させ、最終的に出力確率分布を得て、次の単語を生成する。GANsでは、入力ノイズベクトルに基づいて画像を生成する。これらの操作はモデルの順伝播のみを含み、勾配の計算やパラメータの更新は不要であり、計算複雑度は低い。
データ相互作用性:
推論段階では、モデルは通常単一の入力を処理し、学習時のような大規模バッチデータではなく、各推論の結果は現在の入力にのみ依存し、他の入力や出力に依存しないため、大量のデータ相互作用は不要であり、通信負荷も小さい。
生成的画像モデルを例に取ると、GANsで画像を生成する場合、ノイズベクトルをモデルに入力するだけで、対応する画像が生成される。このプロセスでは、各入力は一つの出力のみを生成し、出力間に依存関係がないため、データ相互作用は不要である。
GPT-3を例に取ると、次の単語を生成するには現在のテキスト入力とモデルの状態があればよく、他の入力や出力との相互作用は不要であり、データ相互作用性の要求も低い。
まとめ
大規模言語モデルでも生成的画像モデルでも、推論タスクの計算複雑度とデータ相互作用性は比較的低く、去中心化分散コンピューティングネットワークでの実行に適しており、現在大多数のプロジェクトが注力している方向でもある。
プロジェクト
去中心化分散コンピューティングネットワークは技術的ハードルと技術的幅が非常に高く、ハードウェアリソースの支援も必要であるため、現時点ではあまり多くの試みを見ていない。TogetherとGensyn.aiを例に挙げる:
1. Together

(TogetherのRedPajama)
Togetherは大規模モデルのオープンソース化と去中心化AIコンピューティングソリューションに特化した企業であり、誰もがどこからでもAIにアクセス・利用できるようにすることを目指している。TogetherはLux Capitalが主導する2000万ドルのシード資金調達を最近完了した。
TogetherはChris、Percy、Ceが共同設立し、大規模モデルの学習には大量の高性能GPUクラスタと高額な支出が必要であり、これらのリソースとモデル学習能力が少数の大手企業に集中していることに起因している。
私の視点から見ると、分散コンピューティングの起業計画として妥当なのは以下の通り:
ステップ1. オープンソースモデル
去中心化分散コンピューティングネットワークでモデル推論を実現するには、まずノードが低コストでモデルを取得できる必要がある。つまり、去中心化コンピューティングネットワークで使用されるモデルはオープンソースである必要がある(モデルの使用にライセンスが必要な場合、実装の複雑性とコストが増加する)。例えばchatgptのような非オープンソースモデルは、去中心化コンピューティングネットワーク上で実行するのに適していない。
したがって、去中心化コンピューティングネットワークを提供する企業の隠れた壁は、強力な大規模モデルの開発・維持能力を持つ必要があると推測できる。独自に開発し、オープンソース化した強力なベースモデルは、第三者のモデルオープンソースへの依存をある程度解消し、去中心化コンピューティングネットワークの基本問題を解決できる。また、コンピューティングネットワークが大規模モデルの学習・推論を効果的に行えることを証明するのにも有利である。
Togetherもまさにそれを実行している。最近発表されたLLaMAベースのRedPajamaは、Together、Ontocord.ai、ETH DS 3 Lab、Stanford CRFM、Hazy Researchなどのチームが共同で立ち上げたもので、完全にオープンソースの大規模言語モデルシリーズの開発を目指している。
ステップ2. 分散コンピューティングのモデル推論への適用
前述の2セクションで述べたように、モデル学習と比較して、モデル推論の計算複雑度とデータ相互作用性は低く、去中心化分散環境での実行に適している。
オープンソースモデルの基礎の上、Togetherの研究開発チームはRedPajama-INCITE-3Bモデルに対してLoRAを利用した低コストファインチューニングなど一連のアップデートを行い、モデルをCPU(特にM2 Proプロセッサ搭載MacBook Pro)上でよりスムーズに動作させるようにしている。また、このモデルの規模は小さいものの、同規模の他のモデルを上回る能力を持っており、法律、ソーシャルなどのシーンで実際の応用が進んでいる。
ステップ3. 分散コンピューティングのモデル学習への適用
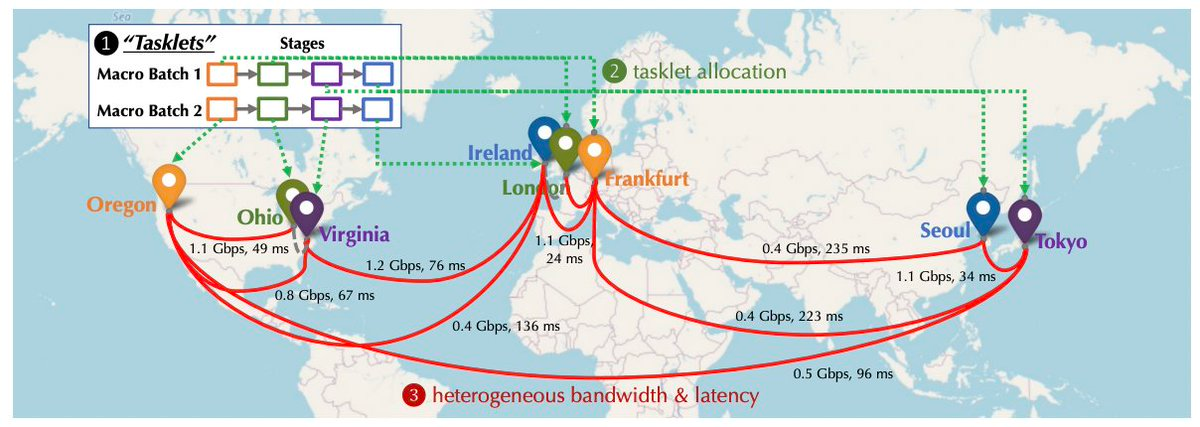
(分散学習の通信ボトルネックを克服するためのコンピューティングネットワーク図)
中長期的には、大きな課題と技術的ボトルネックがあるものの、AI大規模モデル学習のコンピューティング需要に対応することが最も魅力的である。Togetherは設立当初から、分散学習における通信ボトルネックを克服する取り組みを始めている。NeurIPS 2022でも関連論文「Overcoming Communication Bottlenecks for Decentralized Training」を発表している。以下のような方向に要約できる:
スケジューリング最適化
分散環境で学習を行う場合、各ノード間の接続には異なる遅延と帯域幅があるため、重度の通信を必要とするタスクを高速接続を持つデバイスに割り当てることが重要である。Togetherは特定のスケジューリング戦略のコストを記述するモデルを構築し、通信コストを最小化し、学習スループットを最大化するスケジューリング戦略の最適化をより良く行っている。Togetherチームは、ネットワークが100倍遅くても、エンドツーエンドの学習スループットは1.7~2.3倍しか遅くならないことも発見した。したがって、スケジューリング最適化により、分散ネットワークと集中型クラスタの差を埋めることが可能である。
通信圧縮最適化
Togetherは、順伝播アクティベーションと逆伝播勾配の通信圧縮を提案し、AQ-SGDアルゴリズムを導入した。このアルゴリズムは確率的勾配降下法の収束について厳密な保証を提供する。AQ-SGDは低速ネットワーク(例えば500 Mbps)上で大規模ベースモデルのファインチューニングが可能で、集中型コンピューティングネットワーク(例えば10 Gbps)で圧縮なしのエンドツーエンド学習性能と比較して、31%しか遅くならない。さらに、AQ-SGDは最先端の勾配圧縮技術(QuantizedAdamなど)と組み合わせることで、エンドツーエンド速度を10%向上させることができる。
プロジェクトまとめ
Togetherチームは非常に包括的な構成であり、メンバーは非常に強い学術的背景を持ち、大規模モデル開発からクラウドコンピューティング、ハードウェア最適化まで各分野の専門家が支えている。また、Togetherは戦略立案において本当に長期的かつ忍耐強い姿勢を示しており、大規模オープンソースモデルの開発から、アイドルコンピューティングリソース(例えばmac)のテスト、分散コンピューティングネットワークでのモデル推論への応用、そして大規模モデル学習への取り組みまで。— 厚積薄発の感がある:)
しかし、現時点ではTogetherがインセンティブレイヤーに関して多くの研究成果を出していない。私はこれが技術開発と同等の重要性を持ち、去中心化コンピューティングネットワークの発展を保証する鍵となる要素だと考える。
2. Gensyn.ai

(Gensyn.ai)
Togetherの技術的アプローチから、去中心化コンピューティングネットワークがモデル学習・推論に応用される
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News














