

ChatGPTの台頭:GPT-1からGPT-3へ、AIGC時代が目前に
TechFlow厳選深潮セレクト
ChatGPTの台頭:GPT-1からGPT-3へ、AIGC時代が目前に
ChatGPTの開発歴、背後にある技術原理、およびその限界について。

ChatGPTとは何か?
最近、OpenAIは対話形式でやり取りできるモデル「ChatGPT」を発表した。その高度な知能により、多くのユーザーから支持を得ている。
ChatGPTは、OpenAIが以前にリリースしたInstructGPTとも関係が深く、ChatGPTモデルの学習には、人間のフィードバックを用いた強化学習(RLHF: Reinforcement Learning with Human Feedback)が使われている。おそらくChatGPTの登場は、OpenAIによるGPT-4正式リリースへの前触れであるかもしれない。
GPTとは何か? GPT-1からGPT-3へ
Generative Pre-trained Transformer(GPT)とは、インターネット上の利用可能なデータを使って訓練された、テキスト生成のためのディープラーニングモデルである。質問応答、要約生成、機械翻訳、分類、コード生成、対話型AIなどに使用される。
2018年、GPT-1が登場した。この年は自然言語処理(NLP)における事前学習モデルの元年と呼ばれている。
性能面では、GPT-1はある程度の汎化能力を持ち、教師ありタスクに関係しないNLPタスクにも適用可能であった。
主な用途は以下の通り:
-
自然言語推論:2つの文の関係性(含意、矛盾、中立)を判断する;
-
質問応答と常識推論:文章といくつかの回答候補を与え、正しい回答を選ばせる;
-
意味類似性認識:2つの文が意味的に関連しているかを判断する;
-
分類:入力されたテキストが指定されたどのカテゴリに属するかを判定する;
GPT-1は調整されていないタスクでもある程度の効果を示したが、微調整された教師ありタスクに比べて汎化能力ははるかに低く、そのためGPT-1は優れた言語理解ツールという位置づけであり、対話型AIとは言い難かった。
2019年にはGPT-2が予定通り登場したが、ネットワーク構造に大きな革新はなく、より多くのパラメータと大規模なデータセットを使用しただけである。最大モデルは48層で、15億のパラメータを持つ。学習目的としては、非教師あり事前学習モデルを教師ありタスクに適用した。性能面では、理解力に加え、GPT-2は初めて生成能力において顕著な才能を見せた。要約作成、チャット、文章の続きを書く、物語を作る、偽ニュースやフィッシングメールの作成、オンラインでのロールプレイなども容易に行えた。「より大きくする」という戦略により、GPT-2は多方面で普遍的かつ強力な能力を発揮し、複数の特定言語モデリングタスクで当時の最高性能を達成した。
その後登場したGPT-3は、非教師ありモデル(現在は自教師ありモデルと呼ばれることが多い)でありながら、自然言語処理のほとんどすべてのタスクをこなすことができるようになった。問題指向検索、読解、意味推論、機械翻訳、文章生成、自動質問応答などが可能である。特に、フランス語-英語およびドイツ語-英語の機械翻訳タスクでは当時の最高水準に達し、自動生成された文章は人間が書いたものか機械が生成したものか見分けがつかないほど(正答率52%、ランダムな当て推量と同等)であった。さらに驚くべきことに、二桁の足し算・引き算タスクではほぼ100%の正答率を記録し、タスク説明に基づいてコードを自動生成することさえ可能になった。教師なしモデルでありながら多機能かつ高性能である点は、一般人工知能(AGI)への希望を見せたように思われ、これがGPT-3がこれほど大きな影響を与えた主な理由であろう。
GPT-3モデルとは一体何か?
実際のところ、GPT-3は単なる統計的言語モデルにすぎない。機械学習の観点から言えば、言語モデルとは、ある語列の確率分布をモデル化したものであり、すでに述べられた文の一部を条件として、次に来る語の出現確率を予測するものである。言語モデルは、ある文が言語文法にどれだけ合っているかを評価する(例えば、対話システムが自動生成した返答が自然かどうかを測定する)一方で、新しい文の生成予測にも使える。たとえば、「昼の12時だ、一緒にレストランへ行こう」という文の続きとして、「レストラン」の後にどのような語が来るかを言語モデルは予測できる。一般的なモデルは「食べる」を予測するが、高性能なモデルは「昼の12時」という遠距離の文脈情報を捉え、「昼ご飯を食べる」を予測できる。
通常、言語モデルの強さは主に2つの要素に依存する:
-
まず、モデルが過去の全コンテキスト情報を活用できるか。上記の例で、「昼の12時」という遠い過去の情報を捉えられなければ、「昼ご飯を食べる」という次の語を予測するのは困難である。
-
次に、モデルが学習できる十分に豊かなコンテキスト情報を持っているか、つまり訓練用コーパスが十分に豊富か。言語モデルは自教師あり学習に分類され、最適化の目的は観測されたテキストの言語モデル確率を最大化することであるため、あらゆるテキストをラベル付けなしで学習データとして利用できる。
GPT-3はより強力な性能と明らかに多いパラメータを持ち、より多様なテーマのテキストを含んでおり、前の世代であるGPT-2を明確に上回っている。
現時点で最大の高密度ニューラルネットワークであるGPT-3は、ウェブページの説明を対応するコードに変換したり、人間のように物語を語ったり、カスタム詩を作成したり、ゲームシナリオを生成したり、亡くなった哲学者たちの口調を真似して生命の真髄を語らせたりすることさえ可能である。また、GPT-3はファインチューニングを必要とせず、文法的な難問に対してもわずかな出力サンプル(少数学習)があれば対応できる。
GPT-3は、私たちが言語の専門家に求めるすべての想像をほぼ満たしていると言ってよいだろう。
GPT-3にはどのような問題があるのか?
しかし、GTP-3は完璧ではない。現在、人々がAIに対して最も懸念している問題の一つとして、チャットボットやテキスト生成ツールがネット上のすべてのテキストを無差別かつ品質を問わず学習し、それによって誤った情報、悪意のある侮辱、さらには攻撃的な言語を出力する可能性があることが挙げられる。これは今後の応用に大きな影響を及ぼす。
OpenAIは、近い将来より強力なGPT-4を発表すると述べていた:

GPT-3とGPT-4、人間の脳との比較(画像出典:Lex Fridman @youtube)
噂によると、GPT-4は来年にリリースされ、チューリングテストを通過でき、人間と区別がつかないほど進化するという。それに加えて、企業がGPT-4を導入するコストも大幅に低下する見込みである。
ChatGPTとInstructGPT
ChatGPTについて語るなら、その「前身」であるInstructGPTにも触れる必要がある。
2022年初頭、OpenAIはInstructGPTを発表した。この研究では、GPT-3と比較して、アライメント研究(alignment research)を採用し、より真実的で、害が少なく、ユーザーの意図に従う言語モデルを訓練した。
InstructGPTは、有害で不正確かつ偏った出力を最小限に抑えるために、ファインチューニングされた新版のGPT-3である。
InstructGPTの仕組みは?
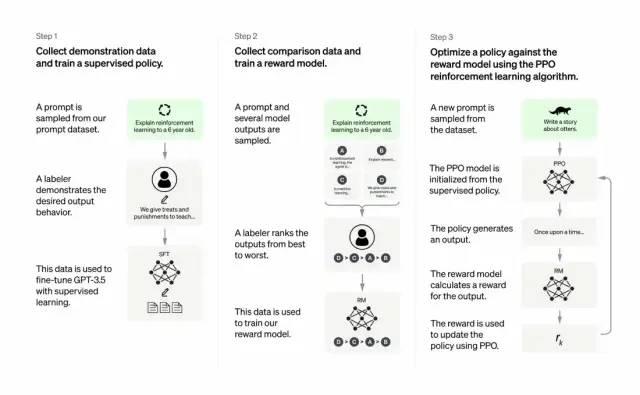
開発者は、教師あり学習と人間からのフィードバックに基づく強化学習を組み合わせることで、GPT-3の出力品質を向上させた。この学習プロセスでは、人間がモデルの潜在的な出力を順位付けし、強化学習アルゴリズムは高順位の出力に近い結果を出すモデルを報酬として強化していく。
訓練データセットの作成は、プロンプト(入力指示)から始まる。これらのプロンプトの一部は、GPT-3ユーザーの実際の入力に基づいている。例えば「カエルのお話を聞かせてください」や「6歳の子供向けに月面着陸を数文で説明してください」などである。
開発者は、プロンプトを3つのグループに分け、それぞれ異なる方法で応答を作成した:
-
第一グループのプロンプトに対しては、人間の作家が直接応答を作成した。その後、訓練済みのGPT-3をファインチューニングし、各プロンプトに対する既存の応答を生成できるようにしてInstructGPTとした。
-
次に、より良い応答に高い報酬を与えるモデルを訓練する。第二グループのプロンプトに対して、最適化されたモデルが複数の応答を生成する。人間の評価者がそれぞれの応答をランク付けする。あるプロンプトと2つの応答が与えられたとき、報酬モデル(別の事前学習済みGPT-3)は、高評価を受けた応答に高い報酬を、低評価の応答には低い報酬を計算するよう学習する。
-
第三グループのプロンプトと強化学習手法である近接方策最適化(Proximal Policy Optimization, PPO)を用いて、言語モデルをさらにファインチューニングした。プロンプトが与えられると、言語モデルが応答を生成し、報酬モデルがそれに応じた報酬を与える。PPOはこの報酬を使って言語モデルを更新する。
何が重要なのか?
核心は――責任ある人工知能が必要だということ。
OpenAIの言語モデルは、教育分野、バーチャルセラピスト、執筆支援ツール、ロールプレイングゲームなどで役立つ可能性がある。こうした領域では、社会的偏見、誤情報、有害なコンテンツの存在は深刻な問題であり、こうした欠陥を回避できるシステムこそが真に有用なのである。
ChatGPTとInstructGPTの学習プロセスの違いは?
全体として、ChatGPTも前述のInstructGPTと同様に、人間のフィードバックを用いた強化学習(RLHF)で訓練されている。
違いは、訓練(および収集)のためにデータがどのように設定されているかにある。(補足:以前のInstructGPTモデルでは、入力に対して1つの出力を出し、それを訓練データと照らし合わせて正解なら報酬、不正解ならペナルティを与える方式だった。一方、今のChatGPTは、1つの入力に対してモデルが複数の出力を生成し、人間がそれらの出力を「人間らしい」から「意味不明」まで順位付けすることで、モデルに人間の順位付けのスタイルを学習させる。この戦略を教師あり学習(supervised learning)という。本段落は張子兼博士に感謝。)
ChatGPTにはどのような制限があるのか?
以下の通り:
a) 強化学習(RL)の訓練段階では、質問に対する真実や正解となる基準が存在しないため、あなたの問いに正確に答えられない。
b) モデルの訓練はより慎重になっており、誤検出を避けるために回答を拒否することがある。
c) 教師あり訓練は、モデルに理想的な答えを知っているように誤導・偏りを生む可能性がある。本来であれば、モデルが一連のランダムな応答を生成し、人間のレビュアーが良い応答を選んで順位付けすべきである。
注意:ChatGPTは表現方法に敏感である。あるフレーズには反応しないが、わずかに言い換えるだけで正しく答えてしまうことがある。訓練者はより長い回答を好む傾向があり、それが冗長な回答を助長する原因となっている。また、特定のフレーズが過剰に使われる場合もあり、初期のプロンプトや質問が曖昧な場合、モデルは適切に追加の説明を求めない。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News














