

« Je n’ai pas besoin d’un meilleur modèle » : les multiples visages de l’IA sous le fil chaud de Reddit
TechFlow SélectionTechFlow Sélection
« Je n’ai pas besoin d’un meilleur modèle » : les multiples visages de l’IA sous le fil chaud de Reddit
Pour un produit phare mettant en avant une évolution majeure des capacités, « le coût en termes d’accessibilité supporté pour assurer la sécurité » devient le facteur déterminant pour les utilisateurs lorsqu’ils décident ou non de l’acheter.
Auteur : Vendredi, TechFlow
Anthropic vient de publier un bulletin de résultats qui semble, sur le papier, parfaitement irréprochable.
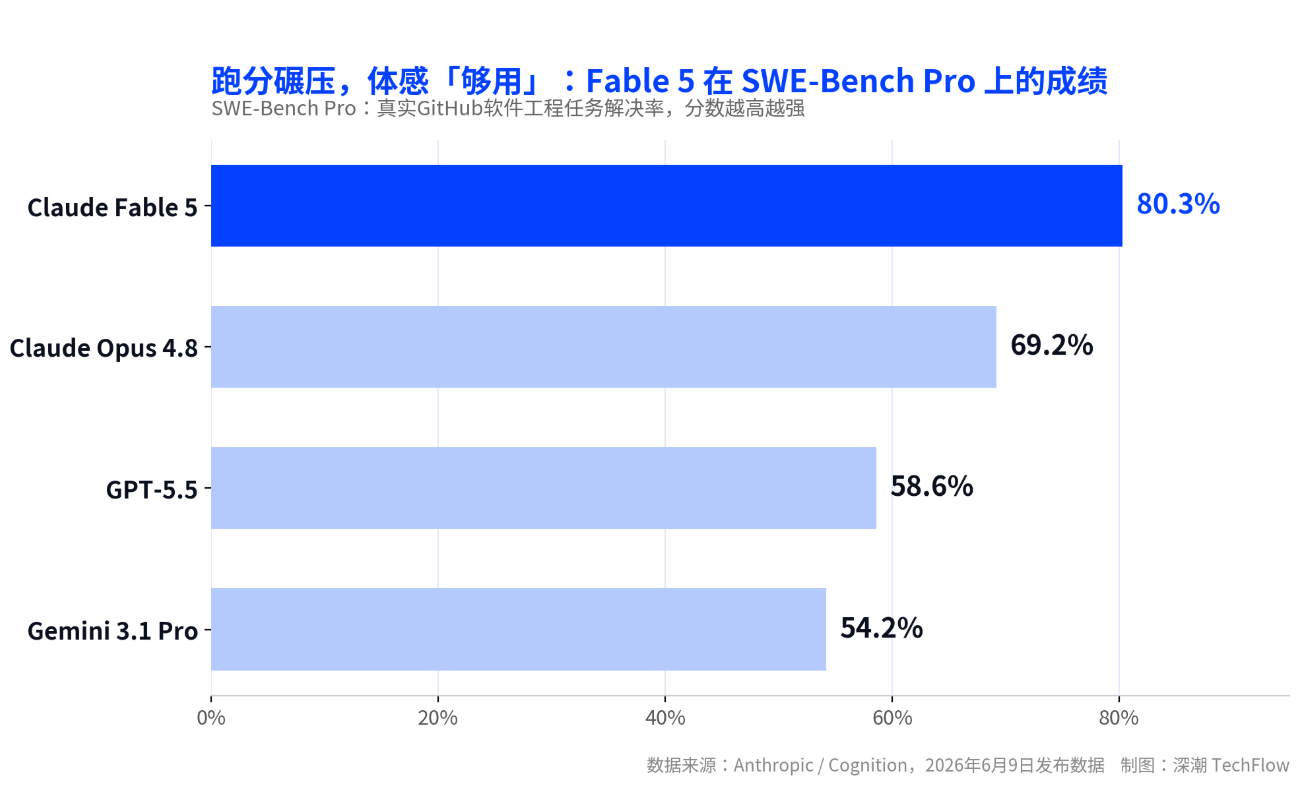
Le 9 juin, l’entreprise a lancé Claude Fable 5, son premier modèle de niveau Mythos ouvert au grand public. Sur la référence réelle en ingénierie logicielle SWE-Bench Pro, il obtient un score de 80,3 %, devançant d’environ 11 points son prédécesseur phare, Opus 4.8, et de plus de 20 points GPT-5.5.
Mais la réaction des utilisateurs a été un véritable seau d’eau froide.
Trois jours après sa sortie, un message très commenté sur le sous-forum r/artificial (305 000 visites hebdomadaires) portait ce titre provocateur : « Claude Fable m’a fait réaliser que je n’ai pas besoin d’un modèle plus performant. » L’auteur du message, Axi0m-22, explique avoir testé Fable pendant un certain temps pour des tâches de recherche en sécurité et des travaux quotidiens, puis être revenu presque immédiatement à Opus pour coder et à Haiku pour les tâches secondaires. Il propose une analogie parlante : « C’est comme regarder la présentation de l’iPhone 17 avec un iPhone 14 en main : vous savez que le nouveau est meilleur, mais vous vous dites : “Bon, celui-ci me convient très bien.” »
La zone des commentaires les plus votés est dominée par les « suffisants » : la lassitude face aux modèles devient l’émotion dominante
Le commentaire le mieux noté (42 votes) affirme : « En dehors d’une fenêtre contextuelle plus grande, je ne ressens plus le besoin d’un modèle plus puissant depuis Opus 4.5. »
Un autre utilisateur, hyprlab, déclare : « Changer pour un modèle consommant davantage de tokens ne m’apporte aucun avantage concret dans mon flux de travail ; le mode haute intensité d’Opus 4.8 me convient parfaitement », recueillant 13 votes.
Ces déclarations reposent toutes sur un même calcul des coûts.
Le tarif API de Fable 5 s’élève à 10 dollars par million de tokens d’entrée, soit près du double de celui d’Opus 4.8. L’utilisateur siromega37 va droit au but : « La consommation de tokens augmente, mais sans retour sur investissement. Je pense que nous entrons dans une phase de stagnation, et que la bulle finira par éclater. »
L’utilisateur hobopwnzor offre une interprétation plus systémique : « Nous sommes déjà depuis un certain temps au sommet de la courbe en forme de S. Les progrès récents proviennent surtout des appels d’outils et des améliorations périphériques, non des capacités intrinsèques des modèles. »
Les garde-fous de sécurité constituent le principal sujet de mécontentement : « 90 % des usages sont directement refusés »
Si le sentiment de « suffisance » relève encore de la subjectivité, les critiques relatives aux garde-fous de sécurité constituent un problème produit bien concret.
Conformément aux informations officielles d’Anthropic, Fable 5 partage le même modèle sous-jacent que Mythos 5, réservé à un petit nombre d’institutions. La différence réside dans l’ajout, sur Fable, d’un classificateur de sécurité : les requêtes impliquant des domaines à haut risque — comme la cybersécurité — sont bloquées et redirigées vers Opus 4.8. Anthropic précise que ce mécanisme est calibré de façon conservatrice, déclenchant en moyenne dans moins de 5 % des échanges, et qu’il peut parfois rejeter à tort des requêtes inoffensives.
Dans ce fil Reddit, toutefois, le taux de déclenchement perçu est nettement supérieur à 5 %. L’utilisateur jradoff, dont le commentaire recueille 17 votes, raconte qu’il a demandé à Fable d’analyser la sécurité de son code, mais que « dès qu’on mentionne un sujet lié à la sécurité, il refuse presque systématiquement de traiter la demande », le renvoyant alors vers Opus. Un autre commentaire, doté de 12 votes, est encore plus direct : « 90 % des tâches que vous souhaitez accomplir avec lui sont refusées — ce qui revient à dire qu’il est inutilisable. »
Le mécontentement est encore plus vif chez les utilisateurs payants. L’abonné au forfait de 200 dollars, kaitava, écrit : « Je paie le double pour la consommation de tokens afin d’effectuer une analyse de sécurité, et je me retrouve finalement dégradé vers Opus. À présent, je déteste tout chez ce modèle, et j’attends simplement qu’OpenAI rattrape le retard. »
Pour un produit phare censé marquer un saut qualitatif, « le coût en termes de fonctionnalité payé pour la sécurité » devient ainsi le critère central déterminant si les utilisateurs acceptent ou non de l’adopter.
Voix opposées : les utilisateurs de tâches exigeantes perçoivent une différence radicale
Le fil chaud ne manque pas de voix contraires — et ces dernières suivent un profil clair : plus la tâche est exigeante, plus l’évaluation est positive.
Le commentaire de Phylaras, crédité de 15 votes, indique : « Fable fait une différence concrète pour moi. Pour les tâches complexes nécessitant une fenêtre contextuelle très large, il détecte des erreurs qui avaient échappé aux modèles précédents. » Un utilisateur affirmant travailler sur des simulations en physique des hautes énergies précise que chaque modèle de simulation comporte entre 8 000 et 10 000 lignes de code, avec des centaines de modèles interagissant entre eux : « Disposer d’un modèle capable de fonctionner de manière autonome et continue, et de comprendre les détails de l’environnement, est pour moi une perspective extrêmement prometteuse. »
La réfutation la plus virulente vient de Navetz : « Honnêtement, ceux qui ont utilisé ce modèle jugeront ce fil complètement délirant. Pour moi, il est tellement plus intelligent qu’il semble appartenir à une autre espèce — je l’utilise sans arrêt. J’explique à mes amis non techniciens : c’est comme passer d’un joueur universitaire à un titulaire de la NBA. »
D’autres proposent des usages plus nuancés. ready-eddy recommande d’utiliser Fable comme « planificateur et correcteur », plutôt que comme « constructeur » quotidien — sauf à ne pas craindre les coûts élevés. Une autre réflexion résume l’approche comme un manuel d’utilisation : utiliser Fable pour calculer un tableau est choisir le mauvais modèle ; faire exécuter à Haiku une tâche complexe impliquant 16 agents intelligents est également un mauvais choix. « Il n’existe pas de mauvais modèle par nature, seulement des modèles mal adaptés à leur contexte d’usage. »
Une déconnexion croissante entre benchmarks et expérience réelle : l’intelligence artificielle ouverte continuera-t-elle à progresser ?
Le commentaire le plus intéressant de ce débat déplace la discussion du produit vers la structure industrielle.
KedMcJenna formule une « hypothèse de gel de l’IA ouverte » : les modèles accessibles au grand public pourraient rester durablement à leur niveau actuel, tandis que les entreprises et les élites gouvernementales continueront à bénéficier de modèles privés plus performants. « Nous savons déjà qu’il existe Mythos, et il est fort probable qu’il existe d’autres modèles encore plus puissants, dont nous n’entendrons jamais parler. »
Ce commentaire pointe un fait avéré : Mythos 5 n’est effectivement pas accessible au grand public, et n’est actuellement fourni qu’aux organismes de défense cybernétique et aux entreprises gérant des infrastructures critiques dans le cadre du programme Project Glasswing.
En confrontant les scores de benchmark et les réactions sur les réseaux sociaux, la conclusion n’est pas contradictoire.
Les benchmarks mesurent le potentiel maximal d’un modèle, tandis que les commentaires les mieux notés sur Reddit reflètent le plafond des besoins quotidiens. Dès lors que la plupart des utilisateurs voient leurs besoins satisfaits depuis l’époque d’Opus 4.6, les modèles plus puissants ne peuvent prouver leur valeur que dans des scénarios extrêmes — comme les simulations physiques ou les fenêtres contextuelles exceptionnellement longues. Les fabricants de modèles ne sont plus confrontés à la question « Est-ce possible ? », mais à celle-ci : « Qui en a besoin ? Qui est prêt à payer combien ? Et jusqu’à quel point peut-on tolérer les frictions liées à la sécurité ? »
À trois jours de son lancement, Fable 5 a obtenu deux bulletins de résultats totalement divergents : l’un sur les classements de performance, l’autre dans l’opinion publique. Lequel se rapproche le plus de la vérité dépendra de la rapidité avec laquelle Anthropic ajustera son classificateur de sécurité, et du vote des utilisateurs exigeants — exprimé cette fois non pas par des mots, mais par leurs portefeuilles.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News













