

a16z : Lorsque les agents n’ont plus besoin d’interface, sur quoi se fonde encore la valorisation de plusieurs milliards de dollars des sociétés de logiciels ?
TechFlow SélectionTechFlow Sélection
a16z : Lorsque les agents n’ont plus besoin d’interface, sur quoi se fonde encore la valorisation de plusieurs milliards de dollars des sociétés de logiciels ?
Le logiciel perd-il sa « tête » ? a16z met en garde : à l’ère des agents IA, les bases de données sous simple habillage ne suffisent plus.
Auteur : Seema Amble
Traduction et adaptation : TechFlow
Introduction de TechFlow : Salesforce a annoncé le lancement de ses « produits headless », qui consistent essentiellement à reconditionner ses API. Mais cette initiative met en lumière une question plus fondamentale : lorsque les agents n’ont plus besoin d’interfaces utilisateur (UI) et peuvent appeler directement les API, que reste-t-il aux entreprises SaaS traditionnelles — outre une base de données et une couche logique métier ? Sur quoi reposent encore leur valorisation à plusieurs dizaines de milliards de dollars ? a16z analyse la refonte des « douves » des logiciels de systèmes d’enregistrement (SoR) à l’ère de l’IA : la fidélité liée à l’interface disparaît, les automatismes cognitifs deviennent obsolètes, tandis que la conformité réglementaire, la capacité de connecter différents systèmes et les logiques opérationnelles non formalisées prennent une importance accrue.
Les logiciels perdent-ils vraiment leur « tête » ?
Lorsqu’il a annoncé le mois dernier l’ouverture de ses API et le lancement de ses produits headless, Salesforce pariait sur un constat clair : à l’ère des agents, sa valeur réside dans sa couche de données, non dans son interface utilisateur. Il s’agit là d’un recentrage stratégique avisé. (Il convient toutefois de noter qu’au plan technique, peu de choses ont changé : les API commercialisées aujourd’hui sous l’appellation « produits headless » existent déjà depuis de nombreuses années. Autrement dit, il s’agit d’un lancement marketing classique à la Salesforce.) L’idée sous-jacente à ce nouveau produit est que les agents peuvent accéder directement aux données stockées dans les systèmes d’enregistrement, sans passer par une interface conçue pour les humains.
Cette annonce soulève une question encore plus intéressante : si l’on supprime l’interface et expose directement la base de données, que reste-t-il réellement ? En quoi cela diffère-t-il d’une base de données PostgreSQL, d’un schéma de données soigneusement conçu et d’une API ? Les facteurs historiques qui assuraient la robustesse des logiciels de systèmes d’enregistrement demeurent-ils pertinents, ou un nouvel ensemble de critères émerge-t-il ? À l’ère du SaaS, ces systèmes étaient défensifs parce que les humains vivaient dans l’interface. À l’ère des agents, cet avantage s’atténue. La résilience défensive descend désormais vers le modèle de données, les mécanismes de contrôle d’accès, la logique des flux de travail et la conformité réglementaire, et remonte vers le réseau, les données propriétaires générées et l’exécution dans le monde réel.
Lorsque les logiciels perdent leur « tête », où se déplace alors leur caractère défensif ?
L’interface était autrefois le produit lui-même
Un système d’enregistrement constitue la source autorisée de vérité dans un domaine précis de données métier. C’est là que résident les versions officielles des relations clients, des dossiers employés ou des transactions financières — c’est le système lu et écrit par d’autres outils. Le CRM est le système d’enregistrement des revenus. Le HRIS (système d’information des ressources humaines) est celui des effectifs. L’ERP est celui des flux financiers. Ce qui les rend puissants, ce n’est pas seulement le fait de stocker des données, mais le fait qu’ils constituent la réalité partagée sur laquelle repose toute l’organisation.
Pendant les deux dernières décennies, Salesforce vendait une méthode permettant aux responsables commerciaux de piloter leurs équipes. Ce que les utilisateurs achetaient réellement, ce sont les tableaux de bord, les vues des pipelines, les outils de prévision et les flux d’activités. Son modèle économique reposait sur la vente de licences (« sièges ») offrant l’accès à ces fonctionnalités. La base de données sous-jacente, bien que critique, n’était qu’un élément secondaire.
Cela signifie que l’interface créait la fidélité. Elle imposait la normalisation des données. Elle construisait un vocabulaire partagé : « piste », « opportunité », « client ». Elle incitait des milliers de commerciaux à saisir des données qu’ils n’auraient pas spontanément renseignées. L’interface était le mécanisme garantissant la cohérence des données. Ce produit était si captivant que de nombreux responsables commerciaux emportaient Salesforce avec eux lorsqu’ils changeaient d’entreprise — non pas parce que l’interface était particulièrement ergonomique, mais parce qu’elle était devenue un automatisme cognitif.
Les agents commencent à bouleverser ce modèle. En lisant et écrivant directement les données sous-jacentes, sans passer par l’interface, ils suscitent une vague d’outils et de solutions alternatives qui contournent totalement l’interface (Salesforce n’est pas le seul concerné : nous avons récemment analysé comment SAP voit croître tout un écosystème IA-compatible autour de lui). Les agents capables d’utiliser des ordinateurs rendent caduques, au fil du temps, les facteurs humains traditionnels — tels que les préférences, la formation ou les contextes non documentés. Autrement dit, les critères requis pour rester un système d’enregistrement durable évoluent.
Un bilan historique
Avant d’explorer ce que l’ère des agents va modifier, il convient de préciser exactement quels facteurs ont initialement conféré leur caractère fidélisant aux systèmes d’enregistrement. Les premiers critères portent principalement sur la manière dont les humains interagissent avec le logiciel et leurs préférences. La fidélité du logiciel dépendait largement de l’interface, des habitudes, des flux de travail humains et des processus intégrés.
Quelle est la fréquence d’accès ? Le CRM est utilisé quotidiennement par les équipes GTM (Go-To-Market) et d’autres départements. Cette fréquence en fait une infrastructure critique ; la couche humaine qui s’y est développée — rituels, automatismes cognitifs, rythmes managériaux bâtis sur des années — est souvent la plus difficile à migrer, car on ne perçoit même pas toujours qu’il s’agit d’un élément à migrer.
Le système est-il en lecture seule ou en lecture/écriture ? Un système d’enregistrement fidélisant est un système en lecture/écriture. Par exemple, le CRM n’est pas un simple dépôt d’archives en écriture unique ; il est continuellement lu. Chaque appel enregistré, chaque mise à jour d’étape, chaque tâche créée sont saisies par quelqu’un (qui, vraisemblablement, accorde de l’importance à ce qu’il fait). Ce flux bidirectionnel implique que tout substitut doit gérer des données opérationnelles en temps réel, et non simplement des exports historiques. Il n’existe aucun « moment sécurisé » pour basculer, ce qui explique pourquoi les entreprises, une fois installées, tendent à rester fidèles à un fournisseur donné. À l’inverse, un système de suivi des candidats (ATS) est souvent en écriture seule : une fois le recrutement terminé, il y a rarement lieu de revenir consulter les données.
Quelle est la dépendance interne ou externe ? La question centrale est la suivante : combien de systèmes internes, de processus métiers ou d’acteurs externes dépendent de ce système d’enregistrement ? La connectivité interne désigne les autres logiciels ou flux de travail situés en aval. La connectivité externe concerne les tiers extérieurs nécessitant un accès direct aux données, comme les auditeurs, les comptables ou les autorités de régulation (par exemple, dans le cas d’un ERP). Plus la connectivité est forte sur l’une ou l’autre de ces dimensions, plus la migration sera complexe.
Quelle est la criticité réglementaire des données ? Ici, la question centrale est simple : ce système est-il crucial pour la conformité ? Des systèmes critiques sur le plan réglementaire — paie, ERP, données RH — exigent une source de vérité juridiquement défendable, des contrôles stricts d’accès administrateur, ainsi qu’une implication directe des auditeurs et des autorités de régulation dans toute migration. Cela augmente considérablement leur caractère fidélisant. Les données commerciales ou les outils de support client comme Zendesk se trouvent à l’autre extrémité du spectre : vous accordez de l’importance à la continuité et au contexte, mais aucune conséquence réglementaire grave ne découlerait d’un transfert de données ou d’un accès non autorisé.
Tous les systèmes d’enregistrement ne présentent pas le même coût de substitution. Si l’on applique ces mêmes critères pour comparer CRM et ATS, l’écart est flagrant. L’ATS est un outil de flux de travail circonscrit à un processus précis : le recrutement. Une fois le candidat recruté ou rejeté, cet enregistrement est essentiellement une écriture unique. Ses intégrations sont limitées. Sa communauté d’utilisateurs est petite et concentrée.
L’ERP se situe à l’opposé extrême : le grand livre est une trace d’audit ; vos comptables, vos auditeurs et les autorités de régulation deviennent des parties prenantes directes de toute migration. Remplacer un ATS est douloureux, mais envisageable. Remplacer un CRM revient à une chirurgie à cœur ouvert. Remplacer un ERP équivaut à pratiquer une chirurgie à cœur ouvert pendant que le patient court un marathon.
Historiquement, les systèmes d’enregistrement n’ont pas exploité de « douves » telles que les données propriétaires ou les effets de réseau ; le flux de travail lui-même constituait une douve suffisante. Si quelque chose caractérise l’approche historique, c’est que les entreprises grand public ont combiné outils et réseaux, tandis que les logiciels de systèmes d’enregistrement n’ont jamais adopté cette stratégie.
Données propriétaires — Bien que de nombreux systèmes d’enregistrement collectent des données clients, ils n’en exploitent guère (et, contractuellement, ne le peuvent souvent pas). Ainsi, même si un CRM dispose d’un jeu de données riche, pouvant être agrégé à travers les clients pour générer des insights transversaux, il ne l’a jamais fait de façon significative (malgré quelques tentatives, comme Einstein de Salesforce).
Effets de réseau — L’effet de réseau est considéré comme la « sainte graal ». Le CRM gagne en valeur parce que les vendeurs de logiciels peuvent y trouver des acheteurs. Comme les données, les effets de réseau sont, au mieux, faibles pour les systèmes d’enregistrement historiques.
Alors, que reste-t-il si l’interface disparaît — et que les agents arrivent ?
Les agents n’ont pas besoin d’un navigateur web. Ils ont besoin d’API, de contexte, d’instructions et de capacités d’action. Deux éléments rendent cela possible à grande échelle : d’abord, les modèles de langage (LLM) sont devenus suffisamment performants pour raisonner. Ainsi, les agents peuvent désormais lire un contexte, élaborer un plan, choisir des outils, exécuter des actions et vérifier les résultats, sans intervention humaine pour la plupart des tâches. Ensuite, le standard MCP (Model Context Protocol) a normalisé l’accès aux outils, offrant aux agents une interface universelle pour invoquer des capacités externes. Un agent disposant d’un accès MCP peut accomplir à grande échelle, en quelques millisecondes, les tâches d’un utilisateur humain, sans passer par un navigateur. Avec le bon contexte, un agent capable d’utiliser un ordinateur devrait même pouvoir naviguer dans les interfaces logicielles existantes sans avoir besoin d’API.
De façon simplifiée, les acheteurs de logiciels disposent aujourd’hui de trois voies possibles :
1) Système existant + agents. Utiliser les CLI et API du fournisseur actuel — soit via ses propres produits agents natifs (Agentforce de Salesforce, Joule de SAP), soit en construisant soi-même ses propres agents par-dessus cette infrastructure. (Nous laissons ici de côté la question de la disponibilité complète des API, ainsi que la complexité réelle des opérations « headless », qui n’est pas aussi simple qu’elle n’y paraît.)
2) Système d’enregistrement entièrement personnalisé (DIY). Construire soi-même son propre modèle de données, sa logique opérationnelle, ainsi que ses mécanismes de gestion des droits, de traçabilité d’audit, d’intégration, etc., et développer également ses propres agents (en s’appuyant potentiellement sur des outils tiers de construction d’agents et de gestion de bases de données).
3) Acheter une alternative native IA. Acquérir une nouvelle génération de logiciels conçus dès l’origine pour l’ère des agents, pensés pour être lisibles par les machines, et dont l’orchestration des agents constitue une fonctionnalité centrale — non une simple extension. Ces solutions peuvent être « headless ».
Que reste-t-il alors du précédent bilan ? Les éléments liés au comportement et aux préférences humaines disparaissent — notamment la fréquence d’accès ou la distinction entre lecture seule et lecture/écriture, tous deux ancrés dans les automatismes cognitifs. Les agents risquent de faire disparaître ces automatismes comme facteur de fidélisation, mais ils ne font pas disparaître la logique opérationnelle et le contexte comme facteurs défensifs. Au contraire, ils rendent cette logique encore plus cruciale, car les agents ont besoin de règles, de droits et de processus explicitement définis pour agir en toute sécurité.
Les procédures opérationnelles standard (SOP) non documentées conservent une importance à court terme. La logique institutionnelle codée dans vos règles de flux de travail est précisément ce dont les agents ont besoin pour agir correctement à votre place. C’est aussi ce qui est le plus difficile à reconstruire. Cela ne peut pas être exporté proprement, surtout lorsque certaines étapes du processus impliquent encore des intervenants humains. Toutefois, la capture du contexte devient plus aisée, et perd progressivement de son importance à mesure que les agents remplacent davantage de tâches humaines.
La connectivité reste difficile à défaire — et s’étend encore davantage. Les facteurs de connectivité évoluent. Il ne s’agit plus de suivre le rythme des humains, mais davantage de maintenir les liens entre des fonctions et des logiciels traditionnellement isolés. Un agent CRM doit agréger les données et le contexte relatifs aux ventes, à la facturation et à la réussite client. Si votre plateforme sert également de nœud transactionnel pour des agents provenant de multiples organisations externes — acheteurs, vendeurs, partenaires — les dépendances s’approfondissent encore. Un fournisseur existant doté d’agents éprouvera des difficultés accrues à travailler avec les primitives sous-jacentes de divers logiciels, tout comme une base de données personnalisée accompagnée d’un ensemble d’agents.
Les données critiques sur le plan réglementaire conservent leur importance. Les données destinées aux autorités de régulation, ou associées à des risques réglementaires ou juridiques, requièrent une source unique de vérité fiable. Si les clients font confiance à leur produit actuel, ils seront peu enclins à changer. Prenons l’exemple des données de paie et comptables : les agents peuvent vouloir y accéder, mais il est peu probable que vous les construisiez et les entreteniez en interne. Dans un monde entièrement piloté par les agents, l’un des problèmes les plus difficiles à résoudre est le suivant : quels agents sont autorisés à agir au nom de qui, dans quelles conditions, avec quelle traçabilité d’audit ? Un système d’enregistrement qui devient une couche d’identité et de gestion des droits pour les interactions entre agents joue un rôle structurel véritablement irremplaçable — non pas en raison des données qu’il détient, mais en raison de l’architecture de confiance qu’il met en œuvre.
À l’avenir, un ensemble croissant de facteurs devient déterminant pour assurer la résilience défensive des startups natives IA :
À quel point reconstruire un système d’enregistrement est-il difficile ? — Les données prendront plusieurs formes d’importance accrue. Premièrement, à court terme, la facilité avec laquelle on peut extraire et reconstruire les données sous-jacentes d’un système d’enregistrement. L’IA facilite cette tâche grâce à de nombreux outils. À court terme, les fournisseurs existants peuvent et vont rendre cette opération plus ardue — en rendant leurs API pénibles, limitées, incomplètes ou économiquement peu attractives, voire en ne les proposant pas du tout. Mais à mesure que les outils d’extraction s’améliorent, notamment avec le progrès des agents capables d’utiliser des ordinateurs, cette tâche deviendra de plus en plus aisée. Parallèlement, de nouvelles entreprises reconstruisent déjà des jeux de données plus riches à partir d’e-mails, d’appels téléphoniques, de voix et de documents internes. L’IA réduit de 80 % le coût de reconstruction d’un système d’enregistrement. Les 20 % restants — exceptions, validations, exigences de conformité et workflows de cas particuliers — demeurent ce qui distingue une solution utile d’une véritable alternative.
Existe-t-il des données propriétaires significatives ?
Deuxièmement, les données elles-mêmes deviennent plus intéressantes. Les données défensives ne sont pas celles que vous importez, mais celles que votre produit génère de façon unique. Nous parlons ici des « jardins clos » de données — celles qui sont propriétaires, réglementées ou nécessitent une mise à jour continue. Les éditeurs de logiciels qui investissent dans la collecte de données fiables et complètes détiennent un avantage face aux fournisseurs généralistes ou à leurs concurrents dépourvus de telles données. Une autre dimension des données concerne les cas où celles-ci dépendent de comportements générés en interne. Les meilleures applications ne se contentent pas de stocker des données saisies ailleurs. Elles produisent de nouvelles données secondaires via leur participation aux processus — comportements observés, taux de réponse, motifs temporels, résultats des processus, référentiels, modèles d’anomalies et trajectoires de performance des agents. L’essentiel est que les données sont désormais synonymes de contexte.
Dispose-t-il d’une couche d’action ?
Dans l’ancien monde, il suffisait de stocker les enregistrements. Dans le nouveau monde, les agents agissent, et la résilience défensive pourrait se déplacer vers les produits capables de fonctionner en boucle fermée — passer à l’action, capturer le résultat, puis utiliser ce retour pour améliorer les décisions futures. Pour un ERP, cela pourrait inclure l’approbation des dépenses, le déclenchement des salaires, la vérification des factures ou l’envoi de notifications. Les produits qui ferment la boucle sont plus défensifs, car ils sont intégrés à l’exécution même — et non seulement à l’observation : ils génèrent des données uniques, s’améliorent avec l’usage et deviennent plus difficiles à remplacer sans rompre le flux de travail. Bien entendu, la valeur augmente avec la richesse du contexte collecté et la variété des cas particuliers traités.
Comporte-t-il un élément d’exécution dans le monde réel ?
Le modèle économique est lié à des opérations réelles qui ne peuvent pas être entièrement automatisées. L’exemple le plus évident est celui des entreprises ayant construit un réseau opérationnel, comme DoorDash — qui, historiquement, n’était pas un système d’enregistrement, mais offre ici une illustration éclairante. Plus largement, tout logiciel dont l’activité s’étend aux services, à l’exécution, à la logistique, aux opérations sur site ou aux paiements possède une résilience différente de celle d’un SaaS pur. Ces entreprises ne se contentent pas de stocker des enregistrements ou de recommander des actions ; elles déploient du personnel, expédient des marchandises ou livrent des services.
Pour les développeurs, cela signifie qu’il existe des opportunités sur les marchés où le logiciel peut de plus en plus prendre des décisions, où les agents peuvent de plus en plus coordonner les activités, mais où la dernière étape — le « dernier kilomètre » — exige encore une exécution dans le monde réel. Par exemple, les logiciels verticaux liés aux services sur site.
Présente-t-il des effets de réseau ?
Historiquement, les effets de réseau étaient faibles pour la plupart des systèmes d’enregistrement, car les logiciels étaient principalement utilisés en interne. Dans le monde des agents, toutefois, les effets de réseau pourraient devenir plus importants si le système est intégré dans des flux de travail impliquant plusieurs parties. Si le système orchestre les interactions répétées entre acheteurs et vendeurs, employeurs et employés, entreprises et auditeurs, fournisseurs et clients, ou encore payeurs et prestataires, chaque nouvel acteur ajouté rend le réseau plus utile pour le suivant.
Une première voie consiste à coordonner des flux de travail partagés : le produit devient le lieu où les deux parties d’un processus échangent, échangent du contexte et résolvent les anomalies. Une deuxième voie passe par les benchmarks et l’intelligence : le système peut présenter des normes, des anomalies et des recommandations fondées sur les motifs observés au sein du réseau — ce qui s’articule naturellement avec le point précédent sur les données. Une troisième voie repose sur la confiance et la standardisation : dès lors que les parties prenantes commencent à s’appuyer sur le même canal pour les approbations, les transmissions, la conformité ou les paiements, le produit devient plus difficile à remplacer, car il n’est plus seulement une base de données — il fait partie intégrante de l’infrastructure de coordination du marché lui-même.
Quel est le niveau de compétence technique des acheteurs ?
Dans un monde théorique où chacun pourrait construire ses propres agents, l’écart entre les capacités réelles des acheteurs demeure considérable. En particulier, dans les marchés verticaux spécialisés et chez les acheteurs fonctionnels qui, historiquement, ne disposent pas de solides ressources internes en ingénierie, la probabilité qu’ils construisent, maintiennent et améliorent continuellement leur propre base de données, leur logique de flux de travail, leur pile d’agents et leur couche de gouvernance reste très faible. Le coût joue également un rôle important : théoriquement, la solution DIY pourrait réduire les frais de licence logicielle, mais elle déplace généralement les dépenses vers la mise en œuvre, la maintenance et la complexité interne. Cela crée de réelles opportunités dans les catégories où l’opération est complexe mais les services technologiques insuffisants — comme la fabrication, les back-offices de la construction, les industries lourdes, les workflows de services sur site ou la comptabilité.
D’autres facteurs importants entreront également dans les exigences fondamentales des logiciels. Par exemple, l’ontologie devra évoluer. Beaucoup de raisonnements autour des « bases de données DIY » sous-estiment la valeur intrinsèque du modèle d’objets lui-même. Les logiciels existants sont conçus pour les tableaux de bord, les rapports et les humains, et capturent les flux de travail — opportunités, tickets, candidats, etc. Les modèles d’agents doivent capturer le raisonnement, l’action, le suivi d’état, la gestion des anomalies, la délégation et la coordination entre systèmes. Le modèle d’objets natif pourrait ainsi évoluer vers des tâches, des intentions, des fils de discussion, des stratégies ou des résultats.
De même, la gestion des droits doit être actualisée pour gérer non seulement les humains, mais aussi les agents. Cela comprend : qui peut faire quoi, via quel agent, selon quelle politique, avec quels niveaux d’approbation requis, quelle traçabilité d’audit, et quelles procédures de restauration ou de gestion des anomalies.
Bien entendu, tout ceci s’inscrit dans un cadre de coûts (par exemple, les coûts de construction et de maintenance des agents ou des bases de données, les coûts d’accès aux API), ce qui ramène inévitablement aux questions de la difficulté de recréer les données et du nombre de dépendances.
Où cela nous mène-t-il ?
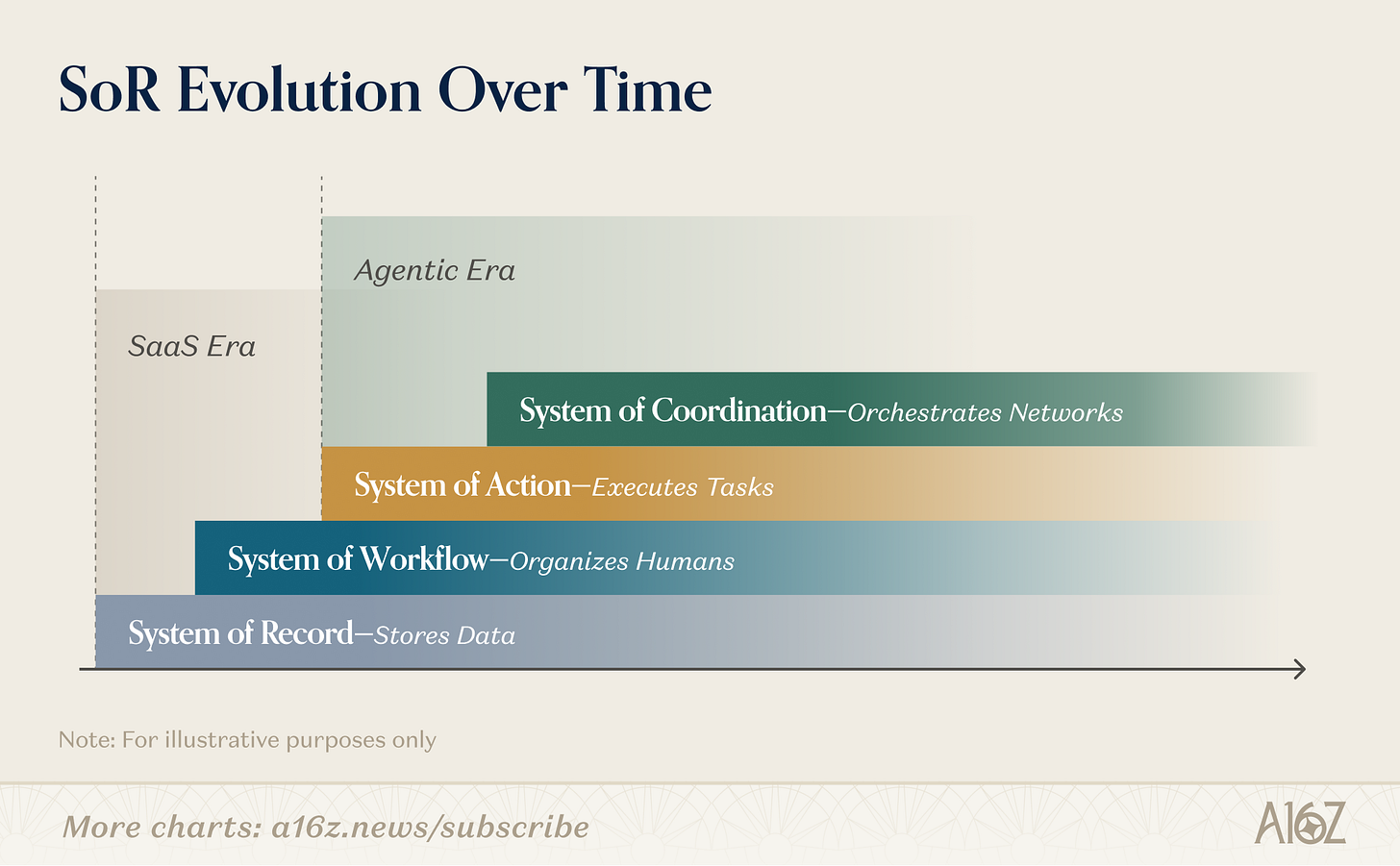
À mesure que les acteurs établis se tournent vers l’architecture « headless », ils parient implicitement sur le fait que la couche de données continuera d’être la source de valeur. Dans certaines catégories — notamment celles fortement encadrées par la réglementation, comme les services financiers — ce pari pourrait rester valable pendant un certain temps, tandis que la transition vers une architecture headless resterait lointaine. Pour les concepteurs de logiciels, les opportunités de concurrencer ces acteurs établis et de construire des logiciels durables évoluent. Les systèmes d’enregistrement de nouvelle génération commencent à prendre une forme différente : ils ne sont plus simplement des entrepôts de données destinés à documenter le travail humain, mais des systèmes dotés d’agentivité, capables de capturer le contexte, de déclencher des workflows et d’enregistrer les données secondaires qu’ils génèrent. En outre, les affaires les plus prometteuses s’étendent jusqu’à l’exécution dans le monde réel — coordonnant des travailleurs sur site, des prestataires logistiques, des équipes de service et des actifs physiques, ou occupant une position intermédiaire entre plusieurs parties. Elles mêlent les modèles économiques du monde ancien, tandis que la donnée — cœur traditionnel des systèmes d’enregistrement — devient un élément du décor.
Merci chaleureusement à @astrange pour sa contribution intellectuelle sur ce sujet !
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News













