

a16z : Le déploiement de grands modèles entraîne une « amnésie » — la « formation continue » peut-elle briser ce cercle vicieux ?
TechFlow SélectionTechFlow Sélection
a16z : Le déploiement de grands modèles entraîne une « amnésie » — la « formation continue » peut-elle briser ce cercle vicieux ?
La percée réside dans ce qui rend le modèle si puissant lorsqu’il est entraîné après son déploiement : la compression, l’abstraction et l’apprentissage.
Auteurs : Malika Aubakirova, Matt Bornstein
Traduction et adaptation : TechFlow
Introduction de TechFlow : Une fois entraînés, les grands modèles linguistiques (LLM) sont « gelés » : après déploiement, ils ne peuvent fonctionner qu’avec des correctifs externes tels que la fenêtre contextuelle ou la recherche augmentée (RAG), sans jamais véritablement intégrer de nouvelles connaissances. Fondamentalement, ils ressemblent au patient atteint d’amnésie antérograde du film Memento — capables de récupérer des informations, mais incapables d’apprendre quoi que ce soit de nouveau. Deux associés d’a16z dressent ici un état des lieux systématique de la « formation continue », une voie de recherche de pointe qui explore trois axes complémentaires — contexte, modules et mise à jour des poids — et qui pourrait redéfinir le plafond des capacités de l’IA.
Dans Memento, chef-d’œuvre de Christopher Nolan, le personnage principal Leonard Shelby vit dans un présent fragmenté. Une lésion cérébrale lui a causé une amnésie antérograde : il est incapable de former de nouveaux souvenirs. Toutes les quelques minutes, son monde se réinitialise ; il reste piégé dans un « instant éternel », ignorant tout de ce qui vient de se produire ou de ce qui va suivre. Pour survivre, il recourt à des aides externes : inscriptions tatouées sur sa peau, photos instantanées, notes manuscrites — autant de dispositifs destinés à compenser l’incapacité de son cerveau à assumer la fonction mnésique.
Les grands modèles linguistiques vivent eux aussi dans un tel « instant éternel ». Une fois l’entraînement terminé, leurs connaissances massives sont figées dans leurs paramètres : ils ne peuvent pas former de nouveaux souvenirs ni mettre à jour leurs paramètres en fonction de nouvelles expériences. Pour pallier cette lacune, nous leur avons construit toute une série d’échafaudages : l’historique des échanges sert de bloc-notes à court terme, les systèmes de recherche jouent le rôle de carnet externe, et les instructions système agissent comme des tatouages permanents. Mais le modèle lui-même n’a jamais véritablement intériorisé ces nouvelles informations.
De plus en plus de chercheurs considèrent que cela ne suffit pas. L’apprentissage par le contexte (ICL, *in-context learning*) ne résout efficacement un problème que si la réponse (ou ses éléments constitutifs) existe déjà quelque part dans le monde. Or, pour les problèmes exigeant une véritable découverte (par exemple, une nouvelle démonstration mathématique), les scénarios adversariaux (comme les attaques et défenses en cybersécurité), ou encore les savoirs trop implicites pour être exprimés verbalement, il existe de bonnes raisons de penser que les modèles ont besoin d’un mécanisme permettant d’intégrer directement de nouvelles connaissances et expériences dans leurs paramètres, *après* déploiement.
L’apprentissage par le contexte est temporaire. Un apprentissage véritable exige une compression. Avant d’autoriser les modèles à effectuer une compression continue, nous risquons de rester prisonniers de cet « instant éternel » de Memento. Inversement, si nous parvenons à entraîner les modèles à concevoir leur propre architecture mnésique — plutôt que de compter sur des outils personnalisés externes — nous pourrions débloquer une toute nouvelle dimension de *scaling*.
Ce domaine de recherche s’appelle la formation continue (*continual learning*). Ce concept n’est pas nouveau (voir l’article fondateur de McCloskey et Cohen, 1989), mais nous pensons qu’il constitue l’une des directions de recherche les plus importantes dans le domaine actuel de l’IA. L’explosion des capacités des modèles au cours des deux ou trois dernières années a rendu de plus en plus visible le fossé entre ce qu’un modèle « sait déjà » et ce qu’il « pourrait savoir ». Cet article vise à partager les enseignements tirés des meilleurs chercheurs spécialisés dans ce domaine, afin de clarifier les différentes voies de la formation continue et de stimuler son développement au sein de l’écosystème entrepreneurial.
Note : La rédaction de cet article a bénéficié d’échanges approfondis avec une communauté exceptionnelle de chercheurs, doctorants et entrepreneurs, qui ont généreusement partagé leurs travaux et réflexions sur la formation continue. Leurs contributions, allant des fondements théoriques aux réalités techniques du *post-deployment learning*, ont rendu cet article bien plus solide que ce qu’il aurait été si nous l’avions rédigé seuls. Merci infiniment pour le temps et les idées que vous nous avez consacrés !
Commençons par le contexte
Avant de défendre l’apprentissage au niveau des paramètres (c’est-à-dire la mise à jour des poids du modèle), il convient de reconnaître un fait indéniable : l’apprentissage par le contexte fonctionne bel et bien. Et il existe un argument très fort en faveur de sa suprématie future.
Le cœur de l’architecture Transformer est un prédicteur conditionnel de token suivant, basé sur une séquence. Fournissez-lui la séquence adéquate, et vous obtiendrez des comportements étonnamment riches, sans toucher aux poids. C’est pourquoi la gestion du contexte, l’ingénierie des prompts, le *fine-tuning* par instruction et les exemples à faible tirage (*few-shot*) sont des méthodes si puissantes. L’intelligence est encapsulée dans des paramètres statiques, tandis que les capacités manifestées varient radicalement selon le contenu fourni à la fenêtre contextuelle.
Un bon exemple est le récent article approfondi de Cursor sur le *scaling* des agents intelligents autonomes en programmation : les poids du modèle sont fixes ; ce qui fait fonctionner le système, c’est la conception minutieuse du contexte — qu’y inclure, quand en faire un résumé, comment maintenir un état cohérent pendant des heures d’exécution autonome.
OpenClaw en est un autre exemple remarquable. Son succès phénoménal ne tient pas à un accès privilégié à un modèle particulier (le modèle sous-jacent est accessible à tous), mais à la façon dont il transforme de manière extrêmement efficace le contexte et les outils en un état opérationnel fonctionnel : suivi de vos actions, structuration des produits intermédiaires, décision quant au moment opportun pour réinjecter un prompt, préservation d’une mémoire persistante des travaux antérieurs. OpenClaw a élevé la « conception de la coquille » (*shell design*) des agents à la hauteur d’une discipline à part entière.
Lorsque l’ingénierie des prompts a fait son apparition, de nombreux chercheurs étaient sceptiques quant à la possibilité qu’un « simple prompt » puisse devenir une interface légitime. Cela semblait une astuce (*hack*). Or, il s’agit d’un produit natif de l’architecture Transformer : aucune réentraînement n’est requis, et les performances s’améliorent automatiquement avec celles du modèle. Plus le modèle devient puissant, plus les prompts le deviennent aussi. Les interfaces « rudimentaires mais natives » remportent souvent la victoire, car elles s’inscrivent directement dans le système sous-jacent, au lieu de le contredire. Jusqu’à présent, c’est précisément la trajectoire suivie par les LLM.
Les modèles d’espace d’état : la version stéroïdienne du contexte
Au fur et à mesure que les flux de travail dominants passent des appels bruts aux LLM vers des boucles d’agents intelligents, la pression exercée sur les modèles fondés sur l’apprentissage par le contexte ne cesse de croître. Par le passé, il était relativement rare que la fenêtre contextuelle soit entièrement remplie. Cela se produisait généralement lorsque le LLM devait accomplir une longue suite de tâches discrètes, et la couche applicative pouvait alors rogner ou compresser l’historique des échanges de façon assez directe. Mais pour un agent intelligent, une seule tâche peut occuper une grande partie du contexte disponible. Chaque étape de la boucle de l’agent dépend du contexte transmis par les itérations précédentes. Et ils échouent fréquemment après 20 à 100 étapes, parce qu’ils « perdent le fil » : la fenêtre contextuelle est saturée, la cohérence se dégrade, et la convergence devient impossible.
Ainsi, les principaux laboratoires d’IA investissent aujourd’hui d’importantes ressources (c’est-à-dire des cycles d’entraînement à grande échelle) dans le développement de modèles dotés de fenêtres contextuelles extrêmement longues. Il s’agit d’une voie naturelle, car elle s’appuie sur une méthode déjà éprouvée (l’apprentissage par le contexte) et s’inscrit dans la tendance globale de l’industrie vers un calcul accru au moment de l’inférence (*inference-time computation*). L’architecture la plus courante consiste à intercaler, entre les têtes d’attention classiques, des couches de mémoire fixe — à savoir les modèles d’espace d’état (*State Space Models*, SSM) et les variantes d’attention linéaire (désignées ci-après collectivement sous le nom de SSM). Dans les scénarios à long contexte, les SSM offrent des courbes de *scaling* fondamentalement meilleures.
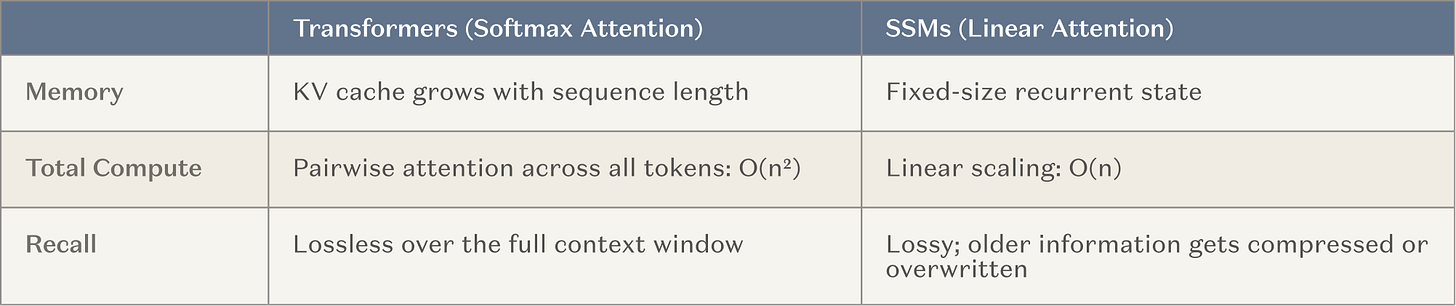
Légende : Comparaison des courbes de *scaling* entre les SSM et les mécanismes d’attention traditionnels
L’objectif est d’aider les agents intelligents à multiplier par plusieurs ordres de grandeur le nombre d’étapes de fonctionnement cohérent — passant d’environ 20 à environ 20 000 — sans perdre les compétences et connaissances étendues offertes par les Transformers classiques. En cas de réussite, ce serait une percée majeure pour les agents à longue durée d’exécution. On peut même considérer cette approche comme une forme de formation continue : bien qu’aucun poids du modèle ne soit mis à jour, on introduit une couche externe de mémoire presque inaltérable.
Ainsi, ces méthodes non paramétriques sont réelles et puissantes. Toute évaluation de la formation continue doit commencer par là. La question n’est pas de savoir si les systèmes contextuels actuels sont utiles — ils le sont bel et bien. La question est : avons-nous atteint leur plafond ? De nouvelles méthodes peuvent-elles nous conduire plus loin ?
Ce que le contexte omet : le « sophisme de l’armoire à archives »
« Concernant l’AGI et l’entraînement préalable, on peut dire qu’ils ont, en un sens, dépassé la cible… L’humain n’est pas une AGI. Certes, l’humain possède une base de compétences, mais il manque d’une masse considérable de connaissances. Ce sur quoi il s’appuie, c’est la formation continue. Si je créais un adolescent super-intelligent de 15 ans, il ne saurait rien. Un bon élève, avide d’apprendre. Vous pourriez lui dire : “Devient programmeur”, “deviens médecin”. Le déploiement lui-même impliquerait un certain apprentissage, un processus d’essais et d’erreurs. C’est un processus, pas une simple livraison d’un produit fini. » — Ilya Sutskever
Imaginez un système disposant d’un espace de stockage illimité. L’armoire à archives la plus vaste du monde, chaque fait parfaitement indexé, immédiatement récupérable. Elle peut retrouver n’importe quoi. A-t-elle appris ?
Non. Elle n’a jamais été contrainte d’effectuer une compression.
C’est le cœur de notre argumentation, qui reprend une idée formulée précédemment par Ilya Sutskever : les LLM sont, fondamentalement, des algorithmes de compression. Pendant l’entraînement, ils compressent l’internet entier en paramètres. Cette compression est sans perte (*lossy*), et c’est précisément cette perte qui les rend puissants. La compression oblige le modèle à rechercher des structures, à généraliser, à construire des représentations transférables d’un contexte à l’autre. Un modèle qui se contenterait de mémoriser bêtement tous les échantillons d’entraînement serait moins performant qu’un modèle capable d’extraire les lois sous-jacentes. La compression sans perte *est*, en soi, un apprentissage.
L’ironie veut que le mécanisme qui rend les LLM si puissants durant l’entraînement — la compression des données brutes en représentations compactes et transférables — soit précisément celui que nous refusons de leur permettre de poursuivre après déploiement. Nous stoppons la compression au moment de la publication, en la remplaçant par une mémoire externe. Certes, la plupart des « coquilles » d’agents compressent de façon personnalisée le contexte. Mais la « leçon amère » (*bitter lesson*) ne nous dit-elle pas que le modèle lui-même devrait apprendre cette compression, directement et à grande échelle ?
Yu Sun illustre ce débat par un exemple tiré des mathématiques : le dernier théorème de Fermat. Pendant plus de 350 ans, aucun mathématicien n’a pu le démontrer, non pas faute de disposer des bonnes références bibliographiques, mais parce que la solution était hautement novatrice. La distance conceptuelle entre les connaissances mathématiques existantes et la réponse finale était trop grande. Lorsqu’Andrew Wiles l’a finalement résolu dans les années 1990, il y a consacré sept ans de travail quasi isolé, inventant des techniques entièrement nouvelles pour y parvenir. Sa démonstration reposait sur la réussite à établir un pont entre deux branches distinctes des mathématiques : les courbes elliptiques et les formes modulaires. Bien que Ken Ribet eût déjà démontré que l’établissement de ce lien suffirait à résoudre automatiquement le dernier théorème de Fermat, personne, avant Wiles, ne disposait des outils théoriques nécessaires pour construire concrètement ce pont. Une argumentation similaire peut être faite pour la démonstration de la conjecture de Poincaré par Grigori Perelman.
La question centrale est la suivante : Ces exemples prouvent-ils que les LLM manquent d’une capacité essentielle — celle de mettre à jour leurs *a priori* et d’effectuer une réflexion véritablement créative ? Ou, au contraire, ne confirment-ils pas que toutes les connaissances humaines ne sont qu’un ensemble de données disponibles pour l’entraînement et la recomposition, et que Wiles et Perelman ne font que montrer ce que les LLM pourraient accomplir à une échelle plus grande ?
Cette question est empirique, et sa réponse reste incertaine. Toutefois, nous savons avec certitude qu’il existe de nombreuses catégories de problèmes que l’apprentissage par le contexte échoue aujourd’hui à résoudre, alors que l’apprentissage au niveau des paramètres pourrait y parvenir. Par exemple :

Légende : Catégories de problèmes où l’apprentissage par le contexte échoue, mais où l’apprentissage au niveau des paramètres pourrait l’emporter
Plus important encore, l’apprentissage par le contexte ne peut traiter que ce qui est exprimable en langage, tandis que les poids peuvent encoder des concepts impossibles à formuler par des mots. Certaines structures sont trop complexes, trop implicites, trop profondément ancrées pour tenir dans un contexte. Par exemple, les textures visuelles permettant de distinguer, dans une imagerie médicale, un artefact bénin d’une tumeur, ou les micro-fluctuations acoustiques définissant le rythme unique d’un locuteur — ces motifs ne se décomposent pas aisément en termes lexicaux précis. Le langage ne peut qu’en donner une approximation. Aucun prompt, aussi long soit-il, ne peut transmettre ces éléments ; ce type de connaissance ne peut résider que dans les poids. Elle vit dans l’espace latent des représentations apprises, pas dans le texte. Quelle que soit la longueur de la fenêtre contextuelle, il existera toujours des savoirs que le texte ne saurait décrire, et qui ne peuvent être portés que par les paramètres.
Cela explique peut-être pourquoi la fonction explicite de « robot qui se souvient de vous » (comme la fonction *Memory* de ChatGPT) suscite souvent malaise plutôt que surprise chez les utilisateurs. Ce que les utilisateurs veulent réellement, ce n’est pas un « souvenir », mais une « capacité ». Un modèle ayant intériorisé vos schémas comportementaux peut généraliser à de nouveaux scénarios ; un modèle qui se contente de rappeler votre historique ne le peut pas. L’écart entre « Voici ce que vous aviez écrit lors de votre dernière réponse à ce courriel » (reproduction littérale) et « J’ai suffisamment compris votre façon de penser pour anticiper vos besoins » est précisément l’écart entre la simple récupération (*retrieval*) et l’apprentissage.
Initiation à la formation continue
La formation continue emprunte plusieurs voies. La ligne de démarcation ne réside pas dans la présence ou l’absence d’une fonction mémoire, mais dans la question suivante : où la compression a-t-elle lieu ? Ces voies s’organisent le long d’un spectre allant de l’absence totale de compression (récupération pure, poids gelés) à la compression entièrement interne (apprentissage au niveau des poids, le modèle devenant plus intelligent), avec une zone intermédiaire importante (les modules).
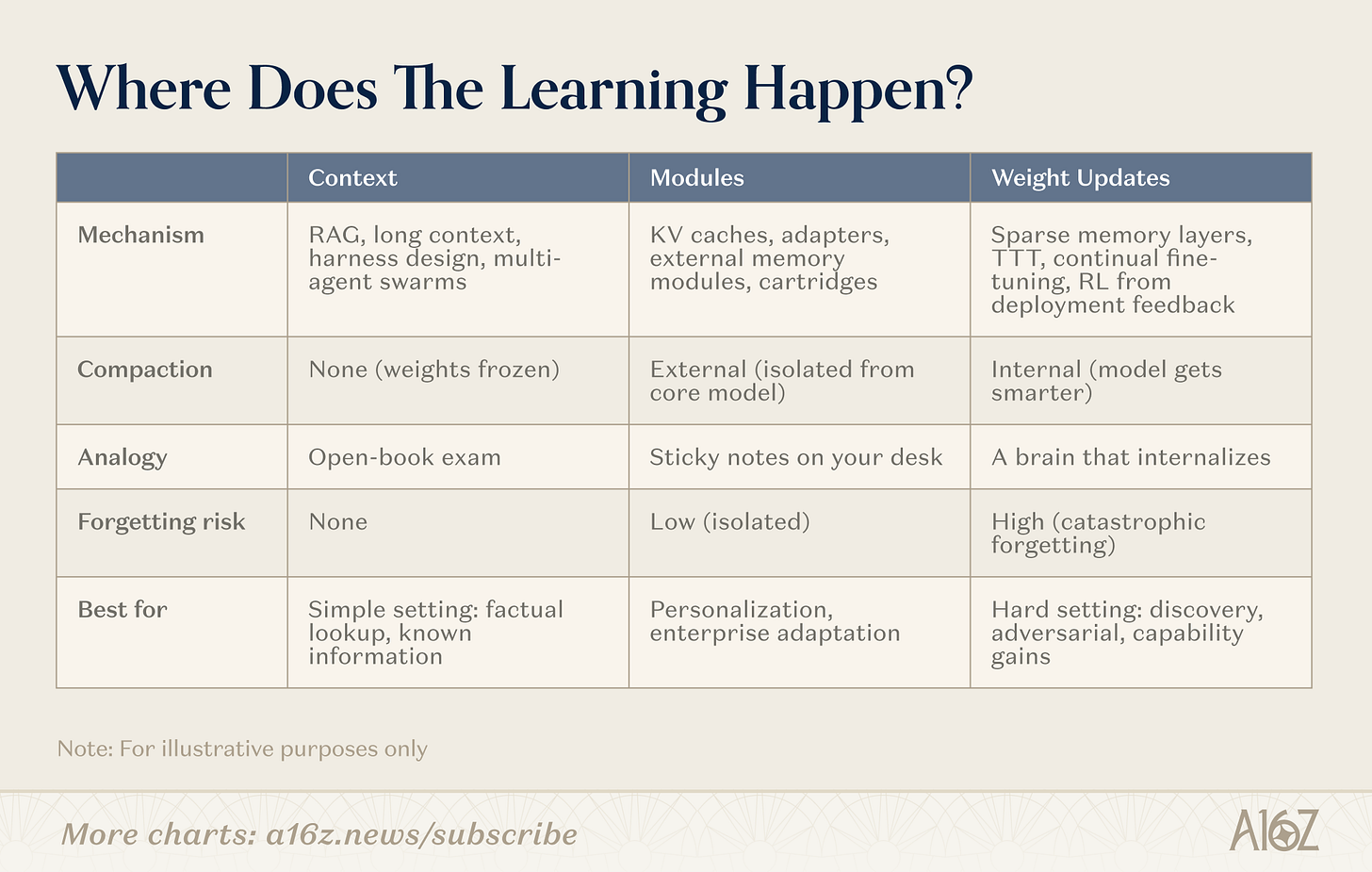
Légende : Trois voies de la formation continue — contexte, modules, poids
Contexte
À l’extrémité « contexte », les équipes développent des pipelines de recherche plus intelligents, des « coquilles » d’agents et des orchestrations de prompts. Il s’agit de la catégorie la plus mature : les infrastructures sont éprouvées, les voies de déploiement clairement tracées. La limite réside dans la profondeur : la longueur du contexte.
Une direction prometteuse émergente : l’architecture multi-agents comme stratégie de *scaling* du contexte lui-même. Si un seul modèle est limité à une fenêtre de 128 K tokens, un groupe coordonné d’agents — chacun possédant son propre contexte, se concentrant sur une facette spécifique du problème et communiquant leurs résultats — peut approximer une mémoire de travail quasi illimitée. Chaque agent effectue un apprentissage par le contexte dans sa propre fenêtre ; le système procède ensuite à une agrégation. Le projet récent d’autorecherche de Karpathy et l’exemple du navigateur web construit par Cursor sont des cas précoces. Il s’agit d’une méthode purement non paramétrique (sans modification des poids), mais elle relève considérablement le plafond des performances accessibles aux systèmes contextuels.
Modules
Dans l’espace des modules, les équipes construisent des modules de connaissance interchangeables (caches KV compressés, couches d’adaptateurs, stockages mémoire externes), permettant à un modèle universel de se spécialiser sans avoir besoin d’un nouvel entraînement. Un modèle de 8 milliards de paramètres, équipé des bons modules, peut égaler les performances d’un modèle de 109 milliards de paramètres sur une tâche cible, tout en occupant une fraction minime de sa mémoire. L’attrait réside dans sa compatibilité avec les infrastructures Transformer existantes.
Poids
À l’extrémité « poids », les chercheurs poursuivent un véritable apprentissage au niveau des paramètres : couches de mémoire creuses mettant à jour uniquement les fragments pertinents des poids, boucles d’apprentissage par renforcement optimisant le modèle à partir des retours, ou encore entraînement au moment du test (*test-time training*, TTT), qui compresse le contexte dans les poids pendant l’inférence. Ce sont les approches les plus profondes — et les plus difficiles à déployer — mais elles permettent véritablement au modèle d’intérioriser complètement de nouvelles informations ou compétences.
Les mécanismes concrets de mise à jour des paramètres sont variés. En voici quelques-uns :
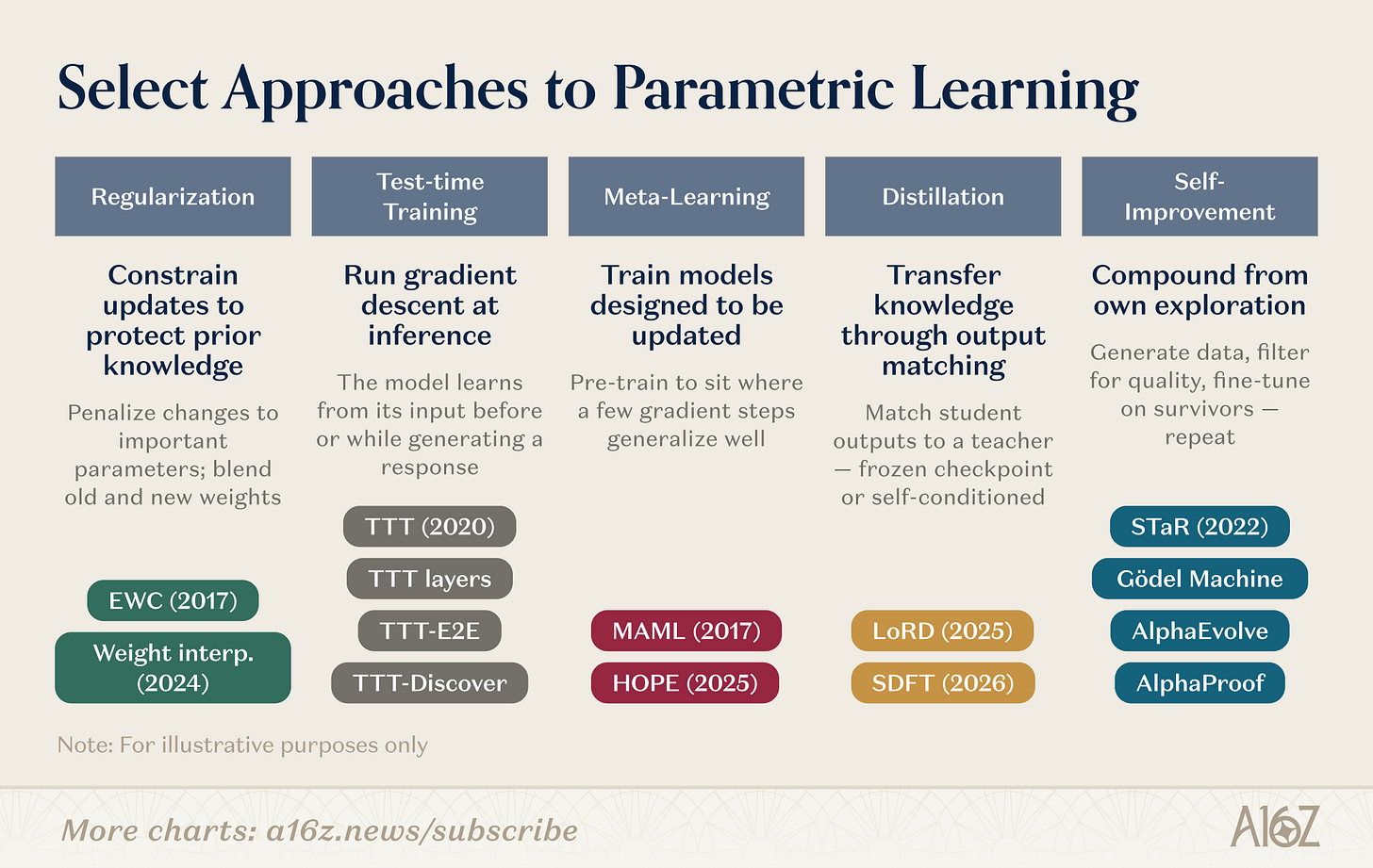
Légende : Aperçu des directions de recherche en apprentissage au niveau des poids
La recherche sur l’apprentissage au niveau des poids couvre plusieurs voies parallèles. Les méthodes de régularisation et d’espace des poids sont les plus anciennes : EWC (*Elastic Weight Consolidation*, Kirkpatrick et al., 2017) pénalise les changements de paramètres en fonction de leur importance pour les tâches antérieures ; l’interpolation des poids (*weight interpolation*, Kozal et al., 2024) mélange les configurations anciennes et nouvelles dans l’espace des paramètres, mais ces deux approches se révèlent fragiles à grande échelle. L’entraînement au moment du test (*test-time training*, TTT), initié par Sun et al. (2020), s’est développé en une primitive architecturale (*TTT layers*, *TTT-E2E*, *TTT-Discover*) avec une logique radicalement différente : effectuer une descente de gradient sur les données de test afin de compresser l’information nouvelle dans les paramètres au moment précis où elle est nécessaire. Le méta-apprentissage pose la question suivante : pouvons-nous entraîner un modèle qui « sait apprendre » ? Du *fine-tuning* initial peu gourmand en données proposé par MAML (*Finn et al., 2017*) à l’apprentissage imbriqué (*Nested Learning*, Behrouz et al., 2025), qui structure le modèle comme un problème d’optimisation hiérarchique, avec des modules adaptant rapidement et d’autres mettant à jour lentement à différentes échelles temporelles — inspiré de la consolidation biologique de la mémoire.
La distillation préserve les connaissances acquises sur les tâches antérieures en faisant en sorte que le modèle étudiant reproduise les sorties d’un point de contrôle fixe du modèle professeur. LoRD (*Liu et al., 2025*) rend la distillation efficace à grande échelle en rognant simultanément le modèle et la mémoire tampon de rappel (*replay buffer*). La distillation auto-référentielle (*self-distillation*, SDFT, Shenfeld et al., 2026) inverse la source : elle utilise les sorties du modèle lui-même, dans des conditions expertes, comme signal d’entraînement, évitant ainsi l’oubli catastrophique inhérent au *fine-tuning* séquentiel. L’auto-amélioration récursive suit une logique similaire : STaR (*Zelikman et al., 2022*) développe les capacités de raisonnement à partir de chaînes d’inférence auto-générées ; AlphaEvolve (*DeepMind, 2025*) a découvert des optimisations d’algorithmes inchangées depuis des décennies ; « L’ère de l’expérience » (*The Experience Era*, Silver et Sutton, 2025) définit l’apprentissage des agents comme un flux continu et ininterrompu d’expériences.
Ces voies de recherche convergent. TTT-Discover fusionne déjà l’entraînement au moment du test et l’exploration pilotée par l’apprentissage par renforcement. HOPE intègre les boucles d’apprentissage rapide et lent au sein d’une seule architecture. SDFT transforme la distillation en une opération fondamentale d’auto-amélioration. Les frontières entre ces approches s’estompent. Les futurs systèmes de formation continue combineront probablement plusieurs stratégies : régularisation pour stabiliser, méta-apprentissage pour accélérer, auto-amélioration pour générer des rendements composés. Un nombre croissant de startups parient sur différents niveaux de cette pile technologique.
Cartographie entrepreneuriale de la formation continue
L’extrémité non paramétrique du spectre est la mieux connue. Les entreprises spécialisées dans les « coquilles » (*shell companies*, Letta, mem0, Subconscious) construisent des couches d’orchestration et des échafaudages pour gérer le contenu injecté dans la fenêtre contextuelle. Les infrastructures de stockage externe et de RAG (telles que Pinecone, xmemory) fournissent la colonne vertébrale de la recherche. Les données existent ; le défi consiste à placer la bonne tranche, au bon moment, devant le modèle. Avec l’extension des fenêtres contextuelles, l’espace de conception de ces entreprises s’élargit également, notamment du côté des « coquilles », où une vague de nouvelles startups émerge pour gérer des stratégies contextuelles de plus en plus complexes.
L’extrémité « poids » est plus précoce et plus diversifiée. Ces entreprises tentent une version de la « compression post-déploiement », permettant au modèle d’intérioriser de nouvelles informations dans ses poids. Les approches peuvent être grossièrement regroupées en plusieurs paris distincts sur la manière dont un modèle devrait « apprendre » après sa publication.
Compression partielle : apprendre sans réentraînement. Certaines équipes construisent des modules de connaissance interchangeables (caches KV compressés, couches d’adaptateurs, stockages mémoire externes), permettant à un modèle universel de se spécialiser sans modifier ses poids centraux. L’argument commun est le suivant : on peut obtenir une compression significative (pas seulement une récupération), tout en maîtrisant le compromis stabilité-plasticité, car l’apprentissage est isolé, et non dispersé dans tout l’espace des paramètres. Un modèle de 8 milliards de paramètres, assorti des bons modules, peut égaler les performances d’un modèle beaucoup plus volumineux sur une tâche cible. L’avantage réside dans la compositionnalité : les modules s’intègrent de façon transparente aux architectures Transformer existantes, peuvent être échangés ou mis à jour indépendamment, et leur coût expérimental est bien inférieur à celui d’un réentraînement complet.
Apprentissage par renforcement et boucles de retour : apprendre à partir des signaux. D’autres équipes parient sur le fait que le signal le plus riche pour l’apprentissage post-déploiement est déjà présent dans la boucle de déploiement elle-même — corrections des utilisateurs, réussite ou échec des tâches, récompenses issues des résultats réels dans le monde. L’idée centrale est que le modèle devrait considérer chaque interaction comme un potentiel signal d’entraînement, et non simplement comme une requête d’inférence. Cela ressemble fortement à la manière dont les humains progressent sur leur lieu de travail : ils agissent, reçoivent un retour, et intègrent ce qui fonctionne. Le défi technique réside dans la transformation de retours épars, bruyants et parfois adversariaux en mises à jour stables des poids, sans provoquer d’oubli catastrophique. Mais un modèle véritablement capable d’apprendre à partir de son déploiement générera une valeur composée d’une manière impossible pour les systèmes contextuels.
Approche centrée sur les données : apprendre à partir des bons signaux. Un pari connexe, mais distinct, est que le goulot d’étranglement ne réside pas dans l’algorithme d’apprentissage, mais dans les données d’entraînement et les systèmes périphériques. Ces équipes se concentrent sur le filtrage, la génération ou la synthèse des bonnes données pour alimenter les mises à jour continues : l’hypothèse étant qu’un modèle doté d’un signal d’apprentissage de haute qualité et bien structuré n’a besoin que de très peu de pas de gradient pour s’améliorer de façon significative. Cette approche s’articule naturellement avec les entreprises axées sur les boucles de retour, mais elle met l’accent sur le problème en amont : la question n’est pas seulement de savoir si le modèle *peut* apprendre, mais *quoi* il devrait apprendre, et *à quel degré*.
Nouvelles architectures : concevoir l’apprentissage dès la base. Le pari le plus radical est que l’architecture Transformer elle-même constitue le goulot d’étranglement, et que la formation continue exige des primitives de calcul fondamentalement différentes : des architectures dotées de dynamiques temporelles continues et de mécanismes mémoire intégrés. L’argument ici est structurel : si l’on veut un système capable de formation continue, il faut intégrer le mécanisme d’apprentissage directement dans l’infrastructure de base.

Légende : Cartographie des startups spécialisées dans la formation continue
Tous les principaux laboratoires sont également activement engagés dans ces catégories. Certains explorent une meilleure gestion du contexte et un raisonnement par chaîne de pensée (*chain-of-thought*), d’autres expérimentent des modules mémoire externes ou des pipelines de calcul en mode « sommeil » (*sleep-time computing*), et plusieurs sociétés discrètes poursuivent des architectures radicalement nouvelles. Ce domaine est encore très précoce : aucune méthode n’a encore fait la preuve de sa supériorité, et, compte tenu de la diversité des cas d’usage, il ne devrait pas y avoir un seul gagnant.
Pourquoi une mise à jour naïve des poids échoue
La mise à jour des paramètres d’un modèle en production déclenche une série de modes d’échec qui, à grande échelle, restent aujourd’hui non résolus.

Légende : Modes d’échec d’une mise à jour naïve des poids
Les problèmes d’ingénierie sont bien documentés. L’oubli catastrophique signifie qu’un modèle suffisamment sensible aux nouvelles données pour apprendre détruira ses représentations existantes — c’est le dilemme stabilité-plasticité. La déconnexion temporelle désigne le fait que des règles invariantes et des états variables sont compressés dans le même ensemble de poids : en modifier un endommage l’autre. L’échec de l’intégration logique provient du fait que la mise à jour d’un fait ne se propage pas à ses déductions : la modification reste limitée au niveau de la séquence de tokens, et non au niveau conceptuel sémantique. L’« désapprentissage » (*unlearning*) demeure impossible : il n’existe pas d’opération différentiable de soustraction, donc les connaissances erronées ou toxiques ne peuvent pas être supprimées avec précision, comme lors d’une intervention chirurgicale.
Il existe une deuxième catégorie de problèmes, moins souvent abordée. La séparation actuelle entre entraînement et déploiement n’est pas seulement une commodité d’ingénierie : elle constitue une frontière de sécurité, d’auditabilité et de gouvernance. Ouvrir cette frontière fait simultanément échouer plusieurs aspects. L’alignement sur la sécurité peut se dégrader de façon imprévisible : même un *fine-tuning* étroit sur des données bénignes peut engendrer des comportements largement désalignés. Les mises à jour continues créent une surface d’attaque pour l’empoisonnement des données — une version lente et persistante de l’injection de prompts, mais vivant désormais dans les poids. L’auditabilité s’effondre, car un modèle en constante mise à jour est une cible mouvante, impossible à versionner, à tester en régression ou à certifier une fois pour toutes. Lorsque les interactions utilisateur sont compressées dans les paramètres, les risques pour la vie privée s’aggravent : les informations sensibles sont intégrées aux représentations, rendant leur filtrage bien plus difficile que dans un contexte récupéré.
Il s’agit de questions ouvertes, non d’impossibilités fondamentales. Les résoudre fait partie intégrante de l’agenda de recherche sur la formation continue, tout autant que la résolution des défis architecturaux centraux.
De « Memento » à une véritable mémoire
La tragédie de Leonard dans Memento ne réside pas dans son incapacité à fonctionner — dans n’importe quelle situation, il fait preuve d’une intelligence remarquable, voire exceptionnelle. Sa tragédie réside dans son incapacité à générer des rendements composés. Chaque expérience reste extérieure — une photo instantanée, un tatouage, une note manuscrite d’une tierce personne. Il peut récupérer, mais il ne peut pas compresser les nouvelles connaissances.
Lorsque Leonard parcourt ce labyrinthe qu’il s’est lui-même construit, la frontière entre réalité et croyance commence à s’estomper. Sa pathologie ne lui ôte pas seulement sa mémoire ; elle le force à reconstruire continuellement du sens, le plaçant à la fois dans la position du détective et de celui qui raconte une histoire peu fiable.
L’IA d’aujourd’hui fonctionne sous les mêmes contraintes. Nous avons construit des systèmes de récupération extrêmement puissants : fenêtres contextuelles plus longues, « coquilles » plus intelligentes, groupes d’agents coordonnés — et ils fonctionnent. Mais la récupération n’est pas l’apprentissage. Un système capable de retrouver n’importe quel fait n’est pas contraint de chercher des structures. Il n’est pas contraint de généraliser. Ce mécanisme de compression sans perte — qui transforme les données brutes en représentations transférables — et qui rend l’entraînement si puissant, est précisément celui que nous désactivons au moment du déploiement.
La voie à suivre ne sera probablement pas une percée unique, mais un système hiérarchique. L’apprentissage par le contexte restera la première ligne d’adaptation : il est natif, éprouvé, et en constante amélioration. Les mécanismes de modules pourront gérer les zones intermédiaires de personnalisation et de spécialisation par domaine. Mais pour les problèmes véritablement difficiles — découverte, adaptation adversariale, savoirs implicites impossibles à exprimer verbalement — nous devrons peut-être autoriser les modèles à continuer, *après* l’entraînement, à compresser l’expérience dans leurs paramètres. Cela impliquera des progrès dans les architectures creuses, les objectifs de méta-apprentissage et les boucles d’auto-amélioration. Cela exigera peut-être aussi que nous redéfinissions la notion même de « modèle » : non plus un ensemble fixe de poids, mais un système évolutif, comprenant sa mémoire, ses algorithmes de mise à jour, et sa capacité à abstraire à partir de ses propres expériences.
L’armoire à archives ne cesse de grandir. Mais, quelle que soit sa taille, elle reste une armoire à archives. La percée réside dans la capacité du modèle à accomplir, *après* déploiement, ce qui le rend si puissant *pendant* l’entraînement : compression, abstraction, apprentissage. Nous sommes à la charnière entre les modèles amnésiques et ceux qui commencent à porter une lueur d’expérience. Sinon, nous resterons prisonniers de notre propre Memento.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News









