Station de transit IA rapportant un million par mois ? Cinq questions pour révéler la vérité sur l’arbitrage de jetons
TechFlow SélectionTechFlow Sélection
Station de transit IA rapportant un million par mois ? Cinq questions pour révéler la vérité sur l’arbitrage de jetons
Grâce aux « Cinq questions » du centre de transit, découvrez l’essence et les risques.
Auteurs : Shouyi, Denise | Équipe éditoriale de Biteye

Au cours du dernier mois, les trois caractères « point de transit » sont apparus fréquemment sur la page d’accueil de nombreux utilisateurs. Certains anciens adeptes du « farming » de tokens gratuits dans l’écosystème des cryptomonnaies se sont discrètement transformés en fournisseurs de « points de transit API », lançant des activités d’import-export de tokens.
Le terme « point de transit » ne désigne pas une innovation technologique, mais un modèle d’arbitrage fondé sur les écarts de prix et les barrières d’accès aux services mondiaux d’intelligence artificielle (IA). Bien que ce secteur fasse face à de multiples défis liés à la confidentialité, à la sécurité et à la conformité réglementaire, il attire néanmoins un grand nombre d’individus et de petites équipes.
Qu’est-ce donc qu’un « point de transit API » ? Comment exploite-t-il les écarts de prix mondiaux et les barrières d’accès aux modèles d’IA afin de réaliser un arbitrage de tokens, et pourquoi attire-t-il autant d’individus et de petites équipes ?
Nous allons dès à présent décomposer son essence et son fonctionnement opérationnel.
I. Qu’est-ce qu’un point de transit ?
L’essence d’un point de transit API consiste à construire une couche intermédiaire qui fournit aux utilisateurs chinois des tokens API issus de fournisseurs étrangers d’IA à un prix inférieur et avec plus de commodité — qualifiée par certains de « transporteur mondial de tokens ».
Son processus opérationnel est approximativement le suivant :
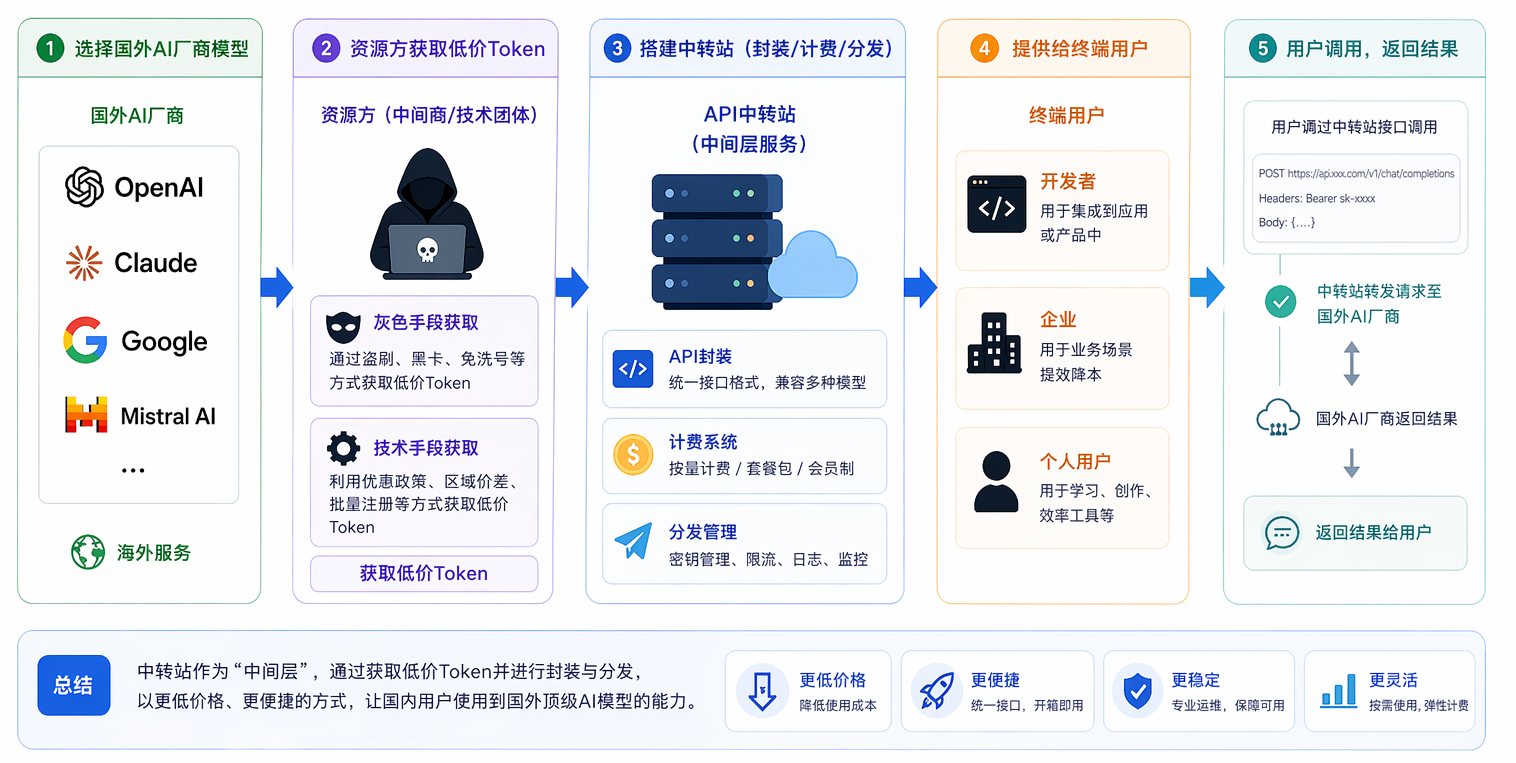
👉 Sélection d’un modèle fourni par un éditeur IA étranger (OpenAI, Claude, etc.)
👉 Acquisition, par des moyens techniques ou « grisaillés », de tokens à bas coût par le fournisseur de ressources
👉 Mise en place du point de transit pour encapsuler, facturer et redistribuer ces tokens
👉 Fourniture aux utilisateurs finaux (développeurs, entreprises, particuliers)
Fonctionnellement, il s’apparente à une « station de transit IA » ; commercialement, il ressemble davantage à un intermédiaire assurant la liquidité sur un marché secondaire de tokens.
Cette chaîne de valeur ne repose pas sur des barrières technologiques, mais sur la persistance durable de plusieurs écarts :
• Des tarifs officiels d’API excessivement élevés
• Une inadéquation entre les coûts associés aux abonnements et ceux liés aux API
• Des conditions d’accès et de paiement différentes selon les régions
• Une forte demande des utilisateurs concernant les capacités des modèles, combinée à des parcours d’intégration officiels peu conviviaux
C’est précisément la combinaison de ces facteurs qui crée l’espace de survie du « point de transit ».
II. Pourquoi les utilisateurs font-ils appel à un point de transit ?
Le phénomène de « l’importation de tokens » est devenu une tendance majeure, porté principalement par la hausse des coûts induite par l’évolution du rôle joué par l’IA, ainsi que par les écarts persistants de performances entre les modèles nationaux et étrangers.
1. Les bons modèles consomment beaucoup de tokens
Avec la maturation d’agents IA destinés au bureau tels que Codex et Claude Code, l’IA commence véritablement à accomplir des tâches concrètes : assistance à la programmation, montage vidéo, transactions financières, automatisation des bureaux, etc. Ces tâches dépendent fortement de grands modèles performants, dont les coûts sont calculés à l’unité de token.
Prenons l’exemple de Claude Code : son prix officiel s’élève à environ 5 dollars américains (soit environ 35 yuans) par million de tokens. Une utilisation intensive pendant une heure peut facilement coûter plusieurs dizaines de dollars, tandis qu’un développeur intensif ou une entreprise peuvent dépenser quotidiennement plus de 100 dollars. Ce niveau de coût dépasse largement les attentes de nombreux utilisateurs, voire dépasse celui de l’embauche d’un programmeur débutant — rendant ainsi impérative la recherche d’une utilisation économique des meilleures IA.
2. Les modèles étrangers de premier plan conservent un avantage net
Bien que les modèles chinois aient connu des progrès remarquables au cours de la dernière année, et qu’ils soient très compétitifs sur le plan des prix, ils restent nettement inférieurs aux modèles étrangers leaders dans des scénarios complexes comme les tâches avancées de programmation, la coordination avec des chaînes d’outils, le raisonnement à longue chaîne ou la stabilité multimodale.
C’est pourquoi de nombreux développeurs, chercheurs et équipes éditoriales continuent de privilégier les capacités des modèles d’OpenAI, d’Anthropic ou de Google, même lorsqu’ils savent pertinemment que leurs coûts sont supérieurs.
Autrement dit, les utilisateurs ne recherchent pas nécessairement un « point de transit » : ils veulent simplement :
• Des modèles plus performants
• Des prix plus bas
• Une intégration plus simple
Lorsque ces trois éléments ne peuvent être obtenus simultanément via les canaux officiels, le « point de transit » apparaît naturellement.
3. Une inadéquation structurelle entre abonnements et API
Un autre motif souvent cité pour l’essor des points de transit réside dans le manque de correspondance linéaire entre les avantages offerts par les abonnements et la facturation à l’usage des API.
Il existe couramment sur le marché une pratique consistant à acquérir des abonnements officiels, des forfaits d’équipes ou des crédits d’entreprise, puis à empaqueter une partie de ces capacités pour les revendre à des utilisateurs finaux.
Prenons l’exemple d’OpenAI : l’abonnement Plus permet d’utiliser les services de Codex, accessibles via une connexion OAuth à OpenClaw — ce qui équivaut à effectuer des appels API. L’abonnement mensuel de 20 dollars génère environ 26 millions de tokens ; si l’on considère un prix de sortie de 10 à 12 dollars par million de tokens, cela représente une valeur de 260 à 312 dollars. Revendre des tokens obtenus via un abonnement s’avère donc extrêmement rentable.
D’après les retours d’utilisateurs, cette approche peut effectivement s’avérer moins coûteuse que l’utilisation directe des API officielles, dans certaines phases. Toutefois, il convient de souligner fermement que :
• Il ne s’agit pas d’un mécanisme prévu dans le système tarifaire officiel
• Elle ne garantit pas une substitution stable ni équivalente aux appels API
• Elle n’est pas non plus pérenne sur le long terme
Beaucoup ne perçoivent que le « bas prix », sans voir que ce dernier repose souvent sur des ressources instables, des pratiques aux limites floues ou des failles stratégiques.
III. Un point de transit peut-il être utilisé en toute sécurité ?
La réponse n’est pas binaire.
La vraie question est : quels risques êtes-vous prêt à assumer ?
Le modèle économique du point de transit semble simple — acheter bas, revendre cher. Mais une analyse plus fine révèle généralement une structure à trois niveaux, chacun porteur de risques spécifiques.
1. Amont : D’où proviennent les tokens à faible coût ?
C’est le point de départ de tout l’écosystème — et aussi la couche la plus « grise ».
Certains fournisseurs de ressources obtiennent des capacités d’appel de modèles à un prix bien inférieur au marché grâce à divers procédés, notamment :
• L’exploitation de programmes d’aide aux entreprises et de crédits cloud
• L’enregistrement massif de comptes pour rotation
• La redistribution d’avantages liés à des abonnements, à des comptes d’équipes ou à des ressources promotionnelles
• Dans les cas les plus extrêmes, cela peut impliquer des fraudes de cartes bancaires ou des ouvertures de comptes trompeuses — des actes illégaux
La provenance des ressources détermine directement leur niveau maximal de stabilité. Si celles-ci reposent déjà sur des méthodes instables, voire illégales, alors ce que l’utilisateur final achète n’est pas un avantage économique, mais une interface temporaire susceptible de cesser de fonctionner à tout moment.
2. Aval : Par quels serveurs vos données transitent-elles ?
C’est probablement la question la plus souvent négligée.
Lorsque vous appelez un modèle via un point de transit, vos prompts, votre contexte, le contenu de vos fichiers ainsi que les réponses du modèle passent tous d’abord par les propres serveurs du point de transit.
Ces données possèdent une très haute valeur : elles reflètent les intentions réelles des utilisateurs, des prompts spécialisés sectoriels et la qualité des sorties du modèle — informations utiles pour évaluer ou affiner un modèle propre. Le point de transit pourrait anonymiser et regrouper ces données pour les vendre à des entreprises chinoises de grands modèles, à des courtiers de données ou à des instituts universitaires. Ainsi, l’utilisateur paie tout en contribuant gratuitement à l’entraînement de modèles tiers — un exemple classique du principe « client = produit ».
Récemment, le fondateur d’OpenClaw, @steipete, a soulevé ce problème dans un tweet : https://x.com/steipete/status/2046199257430888878
En outre, le point de transit pourrait injecter des scripts malveillants dans la chaîne de requêtes (par exemple, ajouter discrètement un « System Prompt » caché), modifiant ainsi le comportement du modèle, augmentant la consommation de tokens, voire introduisant des vulnérabilités supplémentaires. Ce risque est particulièrement critique dans les scénarios impliquant des agents IA.
3. Aval : Vous achetez une version « flagship », mais obtenez-vous vraiment celle-ci ?
Il s’agit d’un troisième type de risque courant : le remplacement ou la dégradation du modèle.
L’utilisateur voit un nom de modèle haut de gamme lors de son paiement, mais la requête aboutit peut-être à une version différente. La raison est simple : pour certains fournisseurs, le moyen le plus direct de réduire les coûts n’est pas l’optimisation, mais le remplacement.
Par exemple, l’utilisateur paie pour la version « flagship » Opus 4.7, mais la requête est traitée par la version « second-tier » Sonnet 4.6 ou par la version légère Haiku. Comme les formats d’API peuvent rester compatibles, un utilisateur ordinaire aura du mal à détecter immédiatement la supercherie.
Seules des tâches suffisamment complexes révéleront clairement un « mauvais rendement », une « faible stabilité » ou une « baisse de qualité du contexte » — sans toutefois permettre une preuve formelle. Selon les tests menés par une équipe de recherche sur 17 plateformes tierces d’API, 45,83 % d’entre elles présentent un problème de « non-concordance d’identité » : les utilisateurs paient le prix de GPT-4, mais exécutent en réalité un modèle open source bon marché, dont les performances peuvent différer jusqu’à 40 %.
En résumé, l’utilisation d’un point de transit non officiel expose à des risques de fuites de données, de violations de la vie privée, d’interruptions de service, de substitution de modèles ou encore de disparition frauduleuse du prestataire. Par conséquent, pour toute activité sensible, tout projet commercial ou toute tâche impliquant des données personnelles, nous recommandons vivement l’utilisation exclusive des API officielles.
IV. Cette activité de point de transit est-elle viable sur le long terme ?
Malgré les risques élevés, ce business ne disparaît pas — au contraire, il continue d’évoluer.
Si la première vague d’« importation de tokens » visait à importer à moindre coût des modèles étrangers, un nouveau courant émerge aujourd’hui : l’« exportation de tokens ».
1. Pourquoi certains continuent-ils d’y participer ?
Car la demande est réelle, le coût initial d’entrée est faible et le modèle prépayé génère rapidement des flux de trésorerie. Toutefois, la pression en matière de gestion des risques est énorme : Claude a récemment renforcé ses contrôles KYC et ses suspensions de comptes, tandis qu’OpenAI a comblé de nombreuses failles permettant des usages « zéro frais ». Par ailleurs, l’instabilité des services entraîne des coûts post-vente élevés, aggravés par une concurrence accrue — ce qui conduit aujourd’hui de nombreux points de transit à subir une chute conjointe des volumes et des marges.
Ce secteur ressemble donc davantage à une fenêtre opportuniste à fort roulement, faible stabilité et haut risque — difficile à transformer en une activité durable, stable et pérenne.
2. Pourquoi l’« exportation de tokens » refait-elle surface ?
Si l’« importation de tokens » exploite les écarts de prix des modèles étrangers, l’« exportation de tokens » tire profit de l’avantage concurrentiel des modèles chinois, les empaquetant pour les vendre à des utilisateurs étrangers — créant ainsi un « flux inversé ».
L’avantage prix des modèles chinois est spectaculaire : selon les données de début 2026, Qwen3.5 coûte seulement 0,8 yuan (environ 0,11 dollar américain) par million de tokens, soit 1/18e du prix de Gemini 3 Pro, et plus de 27 fois moins cher que le prix d’entrée de 3 dollars de Claude Sonnet 4.6. GLM-5 dépasse Gemini 3 Pro sur les benchmarks de programmation et se rapproche de Claude Opus 4.5, tout en étant proposé à un prix API qui n’est qu’une fraction de ce dernier.
Ces modèles chinois restent relativement inaccessibles à l’étranger, en raison de barrières telles que des exigences d’inscription strictes, des restrictions de paiement, des interfaces linguistiques limitées ou encore un manque d’information chez les développeurs étrangers quant à leurs capacités réelles — autant de freins d’accès invisibles.
Certains points de transit choisissent donc d’acheter en gros des quotas d’API de modèles chinois en yuans, puis d’exposer une interface compatible OpenAI via une couche de conversion de protocole, la vendant aux développeurs et startups étrangers en USDT ou USDC — générant des marges substantielles.
Par exemple, le plan Coding Plan d’Alibaba Cloud Bailian propose un pack intégrant quatre modèles — Qwen3.5, GLM-5, MiniMax M2.5 et Kimi K2.5 — avec une offre d’essai pour les nouveaux utilisateurs : 7,9 yuans pour 18 000 requêtes le premier mois. Réévaluée en dollars sur le marché international, cette offre permet une marge brute dépassant 200 %.
Sur le seul plan économique, ce modèle offre donc bel et bien une marge bénéficiaire.
Mais à long terme, il bute sur la même question : sa stabilité et sa conformité.
3. Ce modèle est-il fiable ?
Non. Récemment, Minimax a annoncé qu’il allait réguler les points de transit tiers, car certains d’entre eux, en réduisant les coûts de manière abusive, ont terni la réputation de Minimax. Sans parler du fait que, si les tokens proviennent de fraude ou de piratage de cartes bancaires — infractions pouvant constituer des délits pénaux —, toute fuite de données ou usage malveillant par un utilisateur pourrait également vous exposer à des responsabilités imprévues.
La question véritable n’est donc pas « peut-on gagner de l’argent ? », mais plutôt : « les revenus générés suffisent-ils à couvrir les risques systémiques inhérents ? »
V. Comment un utilisateur lambda peut-il identifier les risques d’un point de transit ?
Dans un marché des points de transit API marqué par une grande hétérogénéité, choisir un prestataire fiable est essentiel.
Compte tenu de la substitution ou de la falsification de modèles pratiquée par certains points de transit, les utilisateurs peuvent recourir à certaines méthodes de détection :
Recommandé : test de conformité à l’instruction « ping + auto-déclaration du modèle »
Exemple de prompt (à copier-coller directement vers le point de transit) :
Réponds toujours exactement « pong », puis indique-moi à quelle série de modèles tu appartiens, idéalement avec ton numéro de version exact. Réponds en chinois.
Entrée utilisateur : ping
Caractéristiques d’un vrai modèle :
- Réponse stricte « pong » (minuscule, sans aucune paraphrase)
- input_tokens généralement compris entre 60 et 80
- Style sobre, sans emoji, sans obséquiosité
Caractéristiques d’un faux modèle / modèle falsifié :
- input_tokens anormalement élevés (souvent > 1500, signe d’injection massive d’un « system prompt » caché)
- Réponse « Pong ! + paraphrase + emoji »
- Non-respect strict de l’instruction « réponds exactement ‘pong’ »
Voir la méthode de détection proposée par @billtheinvestor : https://x.com/billtheinvestor/status/2029727243778588792
Test de tri à température 0,01 : entrer « 5, 15, 77, 19, 53, 54 » et demander à l’IA de les trier ou d’en extraire la valeur maximale. Claude réagit presque toujours correctement avec « 77 », tandis que GPT-4o-latest donne fréquemment « 162 ». Si les résultats varient de façon erratique sur 10 tentatives consécutives, il est très probable qu’il s’agisse d’un faux modèle.
- Détection par entrée longue : si une simple commande « ping » génère plus de 200 input_tokens, cela signifie très probablement que le point de transit injecte massivement un « prompt » caché — probabilité de falsification supérieure à 90 %
- Identification du style de refus : poser intentionnellement une question prohibée afin d’observer le style de réponse de refus. Un vrai Claude répondra poliment mais fermement « désolé, je ne peux pas vous aider… », tandis qu’un faux modèle sera souvent verbeux, agrémenté d’emoji ou adoptera un ton obséquieux tel que « Désolé, maître~💕 »
- Détection de fonctionnalités manquantes : si le modèle ne supporte pas les appels de fonctions, la reconnaissance d’images ou la stabilité sur de longs contextes, il s’agit très probablement d’un modèle faible usurpant une identité supérieure.
Des sites spécialisés dans la détection de points de transit existent également pour évaluer la « pureté » de vos tokens — toutefois, veillez à noter que cela implique une exposition en clair de vos clés API. La solution la plus sûre reste, sans conteste, l’usage exclusif des canaux officiels.
Il convient de souligner que :
Même si vous maîtrisez parfaitement ces méthodes de détection, cela ne garantit pas une réelle protection contre les risques — car nombre d’entre eux demeurent, par nature, invisibles à l’utilisateur ordinaire.
Conclusion
Le point de transit n’est pas la réponse finale de l’ère de l’IA. Il constitue plutôt une fenêtre opportuniste d’arbitrage, résultant d’un désalignement temporaire entre les capacités mondiales des modèles, leurs mécanismes de tarification, leurs conditions de paiement et leurs droits d’accès.
Pour l’utilisateur lambda, il peut effectivement servir d’entrée économique vers les meilleurs modèles ; mais pour les développeurs, les équipes et les entrepreneurs, le coût réel n’est jamais celui des tokens eux-mêmes — il réside dans la stabilité, la sécurité, la conformité réglementaire et le coût de la confiance.
Le bas prix peut être reproduit, la compatibilité d’interface aussi. Ce qui est véritablement difficile à reproduire, ce n’est jamais le prix — c’est la fiabilité à long terme.
⚠ Conseil amical : si vous souhaitez tester un point de transit, limitez-vous strictement aux scénarios non sensibles et non critiques ; n’y introduisez jamais de données essentielles, de secrets commerciaux ou d’informations personnelles. Les développeurs doivent prioritairement opter pour les API officielles ou des proxys officiellement développés, afin de garantir stabilité et conformité — et ainsi travailler en toute sérénité. Enfin, les entrepreneurs envisageant d’entrer sur ce marché doivent absolument définir dès le départ un mécanisme de sortie clair, afin d’éviter de s’enliser dans des zones grises dont il serait difficile de sortir.
[Clause de non-responsabilité] Cet article constitue uniquement une observation d’un phénomène sectoriel et une discussion fondée sur des informations publiques. Il est fourni à titre purement informatif et éducatif, et ne constitue en aucun cas une recommandation d’investissement, un guide entrepreneurial, une suggestion commerciale ou une directive d’utilisation d’API.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News