
Discours de Jensen Huang au CES 2026 : Trois sujets clés, une "bête de puce"
TechFlow SélectionTechFlow Sélection
Discours de Jensen Huang au CES 2026 : Trois sujets clés, une "bête de puce"
Quand l'IA physique doit réfléchir en continu, fonctionner sur le long terme et véritablement entrer dans le monde réel, la question n'est plus seulement de savoir si la puissance de calcul est suffisante, mais plutôt qui peut réellement mettre en place l'ensemble du système.
作者:李海伦 苏扬
北京时间 1月 6 日,英伟达 CEO 黄仁勋身着标志性皮衣再次站在 CES2026 的主舞台上。
2025年 CES,英伟达展示了量产的 Blackwell 芯片和完整的物理 AI 技术栈。在会上,黄仁勋强调,一个“物理 AI 时代”正在开启。他描绘了一个充满想象力的未来:自动驾驶汽车具备推理能力,机器人能够理解并思考,AIAgent(智能体)可以处理百万级 token 的长上下文任务。
转眼一年过去,AI 行业经历了巨大的变革演进。黄仁勋在发布会上回顾这一年的变化时,重点提到了开源模型。
他说,像 DeepSeek R1 这样的开源推理模型,让整个行业意识到:当开放、全球协作真正启动后,AI 的扩散速度会极快。尽管开源模型在整体能力上仍比最前沿模型慢大约半年,但每隔六个月就会追近一次,而且下载量和使用量已经呈爆发式增长。

相比 2025 年更多展示愿景与可能性,这一次英伟达开始系统性地希望解决“如何实现”的问题:围绕推理型 AI,补齐长期运行所需的算力、网络与存储基础设施,显著压低推理成本,并将这些能力直接嵌入自动驾驶和机器人等真实场景。
在本次黄仁勋在 CES 上的演讲,围绕三条主线展开:
●在系统与基础设施层面,英伟达围绕长期推理需求重构了算力、网络与存储架构。以 Rubin 平台、NVLink 6、Spectrum-X 以太网和推理上下文内存存储平台为核心,这些更新直指推理成本高、上下文难以持续和规模化受限等瓶颈,解决 AI 多想一会、算得起、跑得久的问题。
●在模型层面,英伟达将推理型 AI(Reasoning / Agentic AI)置于核心位置。通过 Alpamayo、Nemotron、Cosmos Reason 等模型与工具,推动 AI 从“生成内容”迈向能够持续思考、从“一次性响应的模型”转向“可以长期工作的智能体”。
●在应用与落地层面,这些能力被直接引入自动驾驶和机器人等物理 AI 场景。无论是 Alpamayo 驱动的自动驾驶体系,还是 GR00T 与 Jetson 的机器人生态,都在通过云厂商和企业级平台合作,推动规模化部署。

01 从路线图到量产:Rubin 首次完整披露性能数据
在本次 CES 上,英伟达首次完整披露了 Rubin 架构的技术细节。
演讲中,黄仁勋从 Test-time Scaling(推理时扩展)开始铺垫,这个概念可以理解为,想要 AI 变聪明,不再只是让它“多努力读书”,而是靠“遇到问题时多想一会儿”。
过去,AI 能力的提升主要靠训练阶段砸更多算力,把模型越做越大;而现在,新的变化是哪怕模型不再继续变大,只要在每次使用时给它多一点时间和算力去思考,结果也能明显变好。
如何让“AI 多思考一会儿”变得经济可行?Rubin 架构的新一代 AI 计算平台就是来解决这个问题。
黄仁勋介绍,这是一套完整的下一代 AI 计算系统,通过 Vera CPU、Rubin GPU、NVLink 6、ConnectX-9、BlueField-4、Spectrum-6 的协同设计,以此实现推理成本的革命性下降。

英伟达 Rubin GPU 是Rubin 架构中负责 AI 计算的核心芯片,目标是显著降低推理与训练的单位成本。
说白了,Rubin GPU 核心任务是“让 AI 用起来更省、更聪明”。
Rubin GPU 的核心能力在于:同一块 GPU 能干更多活。它一次能处理更多推理任务、记住更长的上下文,和其他 GPU 之间的沟通也更快,这意味着很多原本要靠“多卡硬堆”的场景,现在可以用更少的 GPU 完成。
结果就是,推理不但更快了,而且明显更便宜。
黄仁勋现场给大家复习了 Rubin 架构的 NVL72 硬件参数:包含 220 万亿晶体管,带宽 260 TB/秒,是业界首个支持机架规模机密计算的平台。

整体来看,相比 Blackwell,Rubin GPU 在关键指标上实现跨代跃升:NVFP4 推理性能提升至 50 PFLOPS(5 倍)、训练性能提升至 35 PFLOPS(3.5 倍),HBM4 内存带宽提升至 22 TB/s(2.8 倍),单 GPU 的 NVLink 互连带宽翻倍至 3.6 TB/s。
这些提升共同作用,使单个 GPU 能处理更多推理任务与更长上下文,从根本上减少对 GPU 数量的依赖。

Vera CPU 是专为数据移动和 Agentic 处理设计的核心组件,采用 88 个英伟达自研 Olympus 核心,配备 1.5 TB 系统内存(是上代 Grace CPU 的3 倍),通过 1.8 TB/s的 NVLink-C2C 技术实现 CPU与 GPU 之间的一致性内存访问。
与传统通用 CPU 不同,Vera 专注于 AI 推理场景中的数据调度和多步骤推理逻辑处理,本质上是让“AI 多想一会儿”得以高效运行的系统协调者。
NVLink 6 通过 3.6 TB/s 的带宽和网络内计算能力,让 Rubin 架构中的 72个 GPU 能像一个超级 GPU 一样协同工作,这是实现降低推理成本的关键基础设施。
这样一来,AI 在推理时需要的数据和中间结果可以迅速在 GPU 之间流转,不用反复等待、拷贝或重算。


在 Rubin 架构中,NVLink-6 负责 GPU 内部协同计算,BlueField-4 负责上下文与数据调度,而 ConnectX-9 则承担系统对外的高速网络连接。它确保 Rubin 系统能够与其他机架、数据中心和云平台高效通信,是大规模训练和推理任务顺利运行的前提条件。
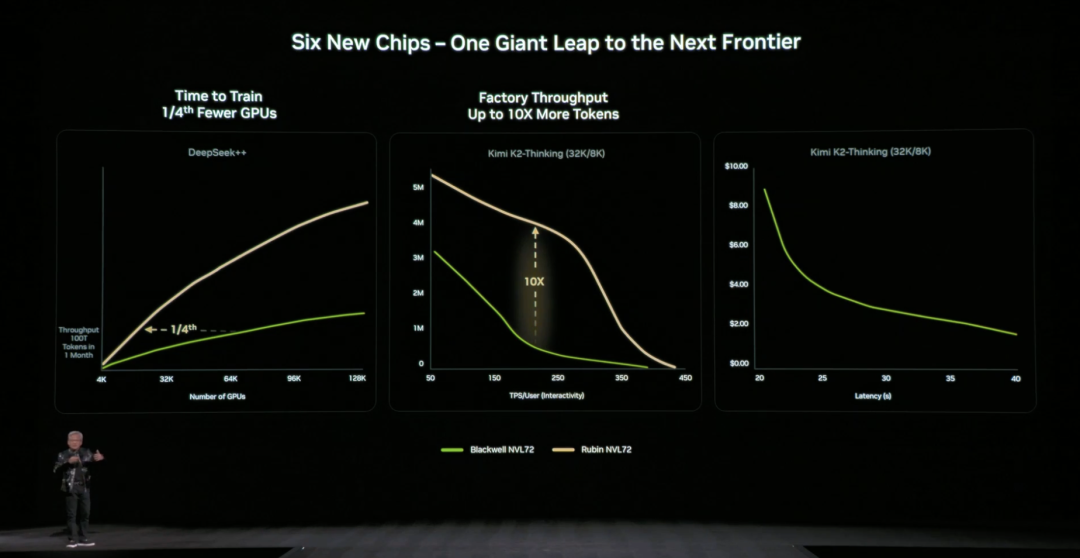
相比上一代架构,英伟达也给出具体直观的数据:相比 NVIDIA Blackwell 平台,可将推理阶段的 token 成本最高降低 10 倍,并将训练混合专家模型(MoE)所需的 GPU 数量减少至原来的 1/4。
英伟达官方表示,目前微软已承诺在下一代 Fairwater AI 超级工厂中部署数十万 Vera Rubin 芯片,CoreWeave 等云服务商将在 2026 年下半年提供 Rubin 实例,这套“让 AI 多想一会儿”的基础设施正在从技术演示走向规模化商用。

02 “存储瓶颈”如何解决?
让 AI“多想一会儿”还面临一个关键技术挑战:上下文数据该放在哪里?
当 AI 处理需要多轮对话、多步推理的复杂任务时,会产生大量上下文数据(KV Cache)。传统架构要么把它们塞进昂贵且容量有限的 GPU 内存,要么放到普通存储里(访问太慢)。这个“存储瓶颈”如果不解决,再强的 GPU 也会被拖累。
针对这个问题,英伟达在本次 CES 上首次完整披露了由 BlueField-4 驱动的推理上下文内存存储平台(Inference Context Memory Storage Platform),核心目标是在 GPU 内存和传统存储之间创建一个“第三层”。既足够快,又有充足容量,还能支撑 AI 长期运行。
从技术实现上看,这个平台并不是单一组件在发挥作用,而是一套协同设计的结果:
- BlueField-4 负责在硬件层面加速上下文数据的管理与访问,减少数据搬移和系统开销;
- Spectrum-X 以太网提供高性能网络,支持基于 RDMA 的高速数据共享;
- DOCA、NIXL和 Dynamo 等软件组件,则负责在系统层面优化调度、降低延迟、提升整体吞吐。
我们可以理解为,这套平台的做法是,将原本只能放在 GPU 内存里的上下文数据,扩展到一个独立、高速、可共享的“记忆层”中。一方面释放 GPU 的压力,另一方面又能在多个节点、多个 AI 智能体之间快速共享这些上下文信息。
在实际效果方面,英伟达官方给出的数据是:在特定场景下,这种方式可以让每秒处理的 token 数提升最高达 5 倍,并实现同等水平的能效优化。
黄仁勋在发布中多次强调,AI 正在从“一次性对话的聊天机器人”,演进为真正的智能协作体:它们需要理解现实世界、持续推理、调用工具完成任务,并同时保留短期与长期记忆。这正是 Agentic AI 的核心特征。推理上下文内存存储平台,正是为这种长期运行、反复思考的 AI 形态而设计,通过扩大上下文容量、加快跨节点共享,让多轮对话和多智能体协作更加稳定,不再“越跑越慢”。

03 新一代 DGX SuperPOD :让 576个 GPU 协同工作
英伟达在本次 CES 上宣布推出基于 Rubin 架构的新一代 DGX SuperPOD(超节点),将 Rubin 从单机架扩展到整个数据中心的完整方案。
什么是 DGX SuperPOD?
如果说 Rubin NVL72 是一个装有 72个 GPU 的“超级机架”,那么 DGX SuperPOD 就是把多个这样的机架连接起来,形成一个更大规模的 AI 计算集群。这次发布的版本由 8个 Vera Rubin NVL72 机架组成,相当于 576个 GPU 协同工作。
当 AI 任务规模继续扩大时,单个机架的 576个 GPU 可能还不够。比如训练超大规模模型、同时服务数千个 Agentic AI 智能体、或者处理需要数百万 token 上下文的复杂任务。这时就需要多个机架协同工作,而 DGX SuperPOD 就是为这种场景设计的标准化方案。
对于企业和云服务商来说,DGX SuperPOD 提供的是一个“开箱即用”的大规模 AI 基础设施方案。不需要自己研究如何把数百个 GPU 连接起来、如何配置网络、如何管理存储等问题。
新一代 DGX SuperPOD 五大核心组件:
○8个 Vera Rubin NVL72 机架 - 提供计算能力的核心,每个机架 72个 GPU,总共 576个 GPU;
○NVLink 6 扩展网络 - 让这 8 个机架内的 576个 GPU 能像一个超大 GPU 一样协同工作;
○Spectrum-X 以太网扩展网络 - 连接不同的 SuperPOD,以及连接到存储和外部网络;
○推理上下文内存存储平台 - 为长时间推理任务提供共享的上下文数据存储;
○英伟达 Mission Control 软件 - 管理整个系统的调度、监控和优化。
这一次的升级,SuperPOD 的基础以 DGX Vera Rubin NVL72 机架级系统为核心。每一台 NVL72 本身就是一台完整的 AI 超级计算机,内部通过 NVLink 6 将72块 Rubin GPU 连接在一起,能够在一个机架内完成大规模推理和训练任务。新的 DGX SuperPOD,则由多台 NVL72 组成,形成一个可以长期运行的系统级集群。
当计算规模从“单机架”扩展到“多机架”后,新的瓶颈随之出现:如何在机架之间稳定、高效地传输海量数据。围绕这一问题,英伟达在本次 CES 上同步发布了基于 Spectrum-6 芯片的新一代以太网交换机,并首次引入“共封装光学”(CPO)技术。
简单来看,就是将原本可插拔的光模块直接封装在交换芯片旁边,把信号传输距离从几米缩短到几毫米,从而显著降低功耗和延迟,也提升了系统整体的稳定性。
04 英伟达开源 AI“全家桶”:从数据到代码一应俱全
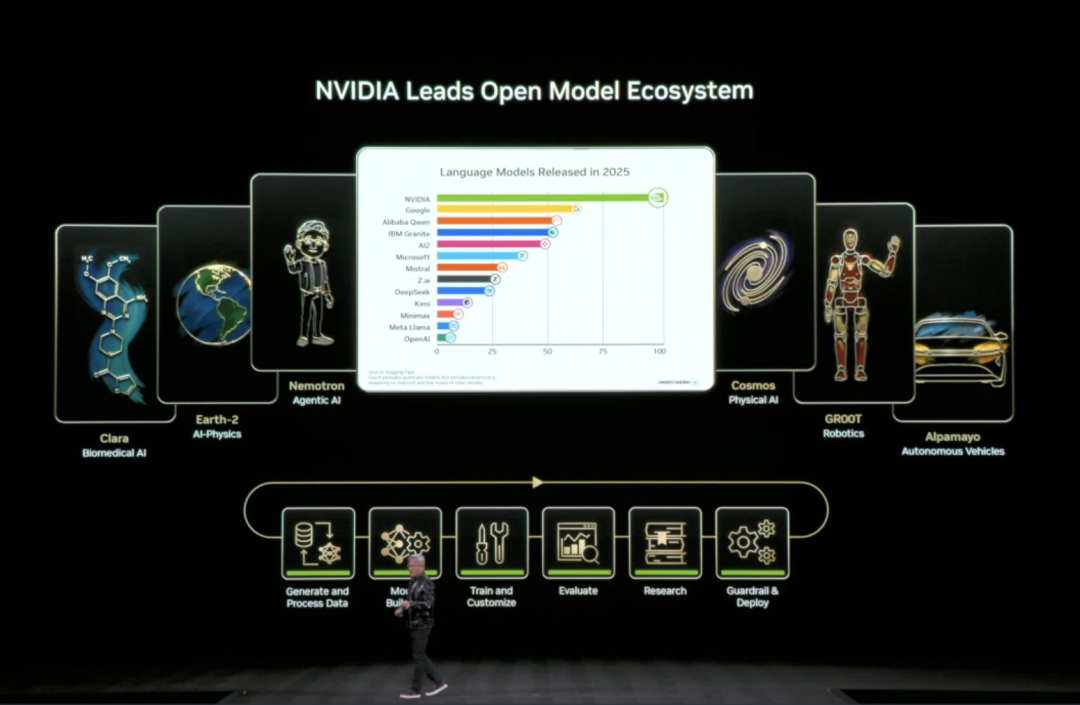
本次 CES 上,黄仁勋宣布扩展其开源模型生态(Open Model Universe),新增和更新了一系列模型、数据集、代码库和工具。这个生态覆盖六大领域:生物医学 AI(Clara)、AI 物理模拟(Earth-2)、Agentic AI(Nemotron)、物理 AI(Cosmos)、机器人(GR00T)和自动驾驶(Alpamayo)。
训练一个 AI 模型需要的不只是算力,还需要高质量数据集、预训练模型、训练代码、评估工具等一整套基础设施。对大多数企业和研究机构来说,从零开始搭建这些太耗时间。
具体来说,英伟达开源了六个层次的内容:算力平台(DGX、HGX 等)、各领域的训练数据集、预训练的基础模型、推理和训练代码库、完整的训练流程脚本,以及端到端的解决方案模板。
Nemotron 系列是此次更新的重点,覆盖了四个应用方向。
在推理方向,包括 Nemotron 3 Nano、Nemotron 2 Nano VL 等小型化推理模型,以及 NeMo RL、NeMo Gym 等强化学习训练工具。在 RAG(检索增强生成)方向,提供了 Nemotron Embed VL(向量嵌入模型)、Nemotron Rerank VL(重排序模型)、相关数据集和 NeMo Retriever Library(检索库)。在安全方向,有 Nemotron Content Safety 内容安全模型及配套数据集、NeMo Guardrails 护栏库。
在语音方向,则包含 Nemotron ASR 自动语音识别、Granary Dataset 语音数据集和 NeMo Library 语音处理库。这意味着企业想做一个带 RAG的 AI 客服系统,不需要自己训练嵌入模型和重排序模型,可以直接使用英伟达已经训练好并开源的代码。
05 物理 AI 领域,走向商业化落地
物理 AI 领域同样有模型更新——用于理解和生成物理世界视频的 Cosmos,机器人通用基础模型 Isaac GR00T、自动驾驶视觉-语言-行动模型 Alpamayo。

黄仁勋在 CES 上声称,物理 AI 的“ChatGPT 时刻”快要来了,但面对挑战也很多:物理世界太复杂多变,采集真实数据又慢又贵,永远不够用。
怎么办呢?合成数据是条路。于是英伟达推出了 Cosmos。
这是一个开源的物理 AI 世界基础模型,目前已经用海量视频、真实驾驶与机器人数据,以及 3D 模拟做过预训练。它能理解世界是怎么运行的,可以把语言、图像、3D 和动作联系起来。
黄仁勋表示,Cosmos 能实现不少物理 AI 技能,比如生成内容、做推理、预测轨迹(哪怕只给它一张图)。它可以依据 3D 场景生成逼真的视频,根据驾驶数据生成符合物理规律的运动,还能从模拟器、多摄像头画面或文字描述生成全景视频。就连罕见场景,也能还原出来。
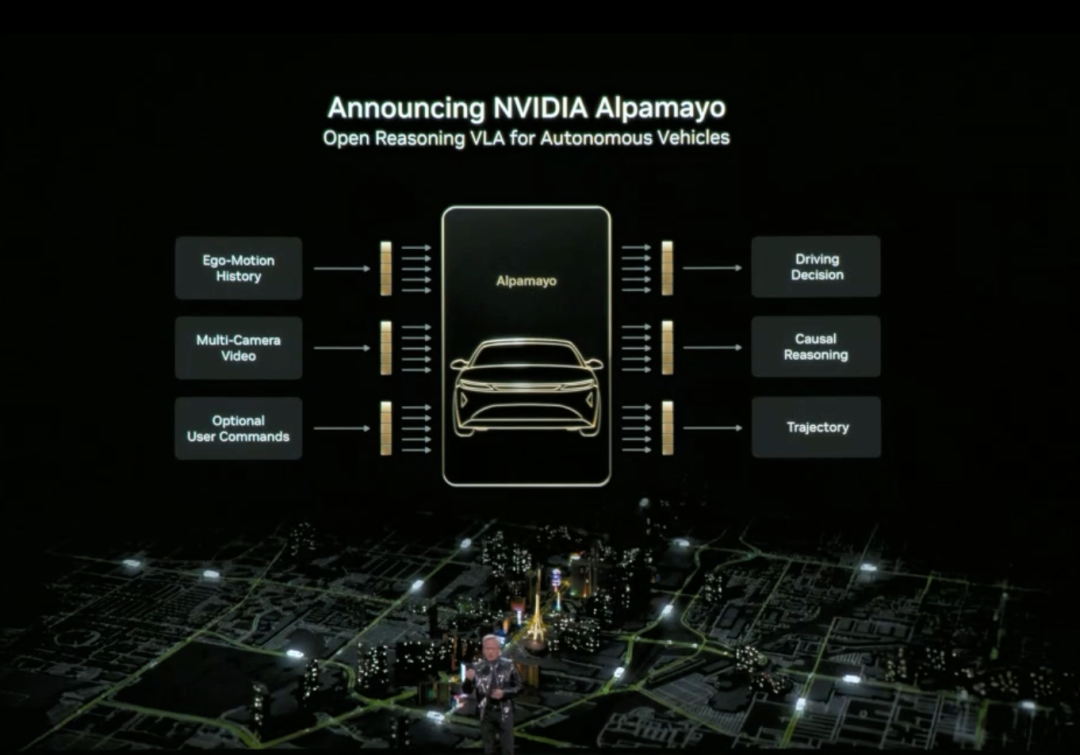
黄仁勋还正式发布了 Alpamayo。Alpamayo 是一个面向自动驾驶领域的开源工具链,也是首个开源的视觉-语言-行动(VLA)推理模型。与之前仅开源代码不同,英伟达这次开源了从数据到部署的完整开发资源。
Alpamayo 最大的突破在于它是“推理型”自动驾驶模型。传统自动驾驶系统是“感知-规划-控制”的流水线架构,看到红灯就刹车,看到行人就减速,遵循预设规则。而 Alpamayo 引入了“推理”能力,理解复杂场景中的因果关系,预测其他车辆和行人的意图,甚至能处理需要多步思考的决策。
比如在十字路口,它不只是识别出“前方有车”,而是能推理”那辆车可能要左转,所以我应该等它先过”。这种能力让自动驾驶从“按规则行驶”升级到“像人一样思考”。
黄仁勋宣布英伟达 DRIVE 系统正式进入量产阶段,首个应用是全新的梅赛德斯-奔驰 CLA,计划 2026 年在美国上路。这款车将搭载 L2++级自动驾驶系统,采用“端到端 AI 模型+传统流水线”的混合架构。
机器人领域同样有实质性进展。
黄仁勋表示包括 Boston Dynamics、Franka Robotics、LEM Surgical、LG Electronics、Neura Robotics和 XRlabs 在内的全球机器人领军企业,正在基于英伟达 Isaac 平台和 GR00T 基础模型开发产品,覆盖了从工业机器人、手术机器人到人形机器人、消费级机器人的多个领域。

在发布会现场,黄仁勋背后站满了不同形态、不同用途的机器人,它们被集中展示在分层舞台上:从人形机器人、双足与轮式服务机器人,到工业机械臂、工程机械、无人机与手术辅助设备,展现出一版“机器人生态图景”。
从物理 AI 应用到 RubinAI 计算平台,再到推理上下文内存存储平台和开源 AI“全家桶”。
英伟达在 CES 上展示的这些动作,构成了英伟达对于推理时代 AI 基础设施的叙事。正如黄仁勋反复强调的那样,当物理 AI 需要持续思考、长期运行,并真正进入现实世界,问题已经不再只是算力够不够,而是谁能把整套系统真正搭起来。
CES 2026 上,英伟达已经给出了一份答卷。
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News














