

Série sur le drame des biens communs cryptographiques : Le malaise de l'indexation des données de Polymarket
TechFlow SélectionTechFlow Sélection
Série sur le drame des biens communs cryptographiques : Le malaise de l'indexation des données de Polymarket
Cet article se concentre sur l'une des applications les plus populaires de l'écosystème Ethereum : Polymarket et son outil d'indexation des données.
Rédaction : shew
Résumé
Bienvenue dans la série « Tragédie des biens communs » de la rubrique GCC Research.
Dans cette série, nous allons nous concentrer sur les « biens publics » clés du monde cryptographique qui, bien qu'essentiels, perdent progressivement leur bon fonctionnement. Ces biens constituent l'infrastructure fondamentale de tout l'écosystème, mais souffrent souvent d’incitations insuffisantes, de déséquilibres de gouvernance, voire d’un processus croissant de centralisation. Les idéaux poursuivis par la technologie blockchain et la stabilité redondante attendue en pratique sont mis à rude épreuve dans ces domaines.
Cette fois, nous examinons l'une des applications les plus médiatisées de l'écosystème Ethereum : Polymarket et ses outils d'indexation de données. Depuis le début de l'année, Polymarket a été au centre de l'attention médiatique à propos notamment de manipulations d'oracles liées à la victoire présumée de Trump, aux transactions de terres rares ukrainiennes ou encore aux paris politiques sur la couleur du costume de Zelensky. L'ampleur des fonds gérés et l'influence de ce marché rendent ces controverses impossibles à ignorer.
Pourtant, ce produit emblématique des « marchés prévisionnels décentralisés », son module fondamental — l'indexation des données — est-il vraiment décentralisé ? Pourquoi un service public comme The Graph n’a-t-il pas pu assumer le rôle escompté ? Quelle devrait être la forme d’un bien public d’indexation réellement utilisable et durable ?
I. Une panne de plateforme centralisée déclenche une réaction en chaîne
En juillet 2024, Goldsky a subi une panne prolongée de six heures (Goldsky est une plateforme d’infrastructure de données blockchain en temps réel destinée aux développeurs Web3, offrant des services d’indexation, de sous-graphes et de flux de données pour permettre la construction rapide d’applications décentralisées pilotées par les données), entraînant l’immobilisation d’une grande partie des projets de l’écosystème Ethereum. Par exemple, les interfaces DeFi ne pouvaient plus afficher les positions ni les soldes des utilisateurs, et le marché prévisionnel Polymarket ne montrait plus les données correctes. De nombreux projets semblaient totalement inutilisables aux yeux des utilisateurs finaux.
Ce type d’incident ne devrait pas se produire dans un monde d’applications décentralisées. Après tout, l’un des objectifs initiaux de la technologie blockchain est précisément d’éliminer les points de défaillance unique. L’incident Goldsky révèle une réalité troublante : bien que la blockchain elle-même soit aussi décentralisée que possible, les infrastructures utilisées par les applications construites dessus contiennent fréquemment de nombreux composants centralisés.
La raison en est que l’indexation et la recherche de données blockchain relèvent du bien public numérique « non exclusif et non rival ». Les utilisateurs s’attendent généralement à y accéder gratuitement ou à très bas coût, alors même que cela exige des investissements constants en matériel, stockage, bande passante et personnel opérationnel. En l’absence de modèle économique durable, une structure centralisée dominée par un seul acteur tend à émerger : dès qu’un fournisseur obtient un avantage précoce en vitesse ou en capital, les développeurs concentrent leurs requêtes vers ce service, recréant ainsi une dépendance ponctuelle. Des projets caritatifs comme Gitcoin ont répété à maintes reprises que « les infrastructures open source peuvent créer des milliards de valeur, mais leurs auteurs peinent souvent à payer leur loyer ».
Cela nous rappelle que le monde décentralisé a urgemment besoin d’enrichir la diversité de l’infrastructure Web3 via des financements de biens publics, des mécanismes de redistribution ou des initiatives communautaires. Nous appelons les développeurs de DApp à concevoir des produits privilégiant les solutions locales, et la communauté technique à intégrer dès la conception des DApp la possibilité de défaillance des services de recherche de données, afin que les utilisateurs puissent continuer à interagir avec les projets même sans infrastructure de récupération de données.
II. D'où proviennent les données que vous voyez sur un DApp ?
Pour comprendre pourquoi un incident comme celui de Goldsky peut arriver, il faut examiner de plus près le fonctionnement interne des DApp. Pour l’utilisateur moyen, un DApp se compose généralement de deux éléments : le contrat sur la chaîne et l’interface frontale. La plupart des utilisateurs sont habitués à utiliser des outils comme Etherscan pour consulter l’état des transactions sur la blockchain, et à obtenir des informations essentielles via l’interface, tout en lançant des transactions depuis celle-ci. Mais d’où viennent exactement les données affichées sur le front-end ?
Le service indispensable de recherche de données
Imaginons que vous développiez un protocole de prêt nécessitant d’afficher les positions des utilisateurs ainsi que les marges et dettes associées à chaque position. Une idée naïve serait que le front-end lise directement ces données depuis la chaîne. En pratique, cependant, le contrat du protocole de prêt n’autorise pas l’interrogation des positions par adresse utilisateur ; il propose seulement une fonction permettant d’obtenir les détails d’une position via son identifiant. Ainsi, pour afficher les positions d’un utilisateur, il faudrait extraire toutes les positions existantes puis filtrer celles appartenant à cet utilisateur. C’est comme demander à quelqu’un de parcourir manuellement des millions de pages de registres pour trouver une information spécifique — techniquement faisable, mais extrêmement lent et inefficace. En réalité, un front-end ne peut guère accomplir une telle tâche ; même sur un serveur, l’exécution d’une telle recherche par un nœud local peut prendre plusieurs heures pour les grands projets DeFi.
Il devient donc nécessaire d’introduire une infrastructure pour accélérer l’acquisition des données. Des entreprises comme Goldsky fournissent justement ce type de service d’indexation. L’image ci-dessous montre les types de données que peut fournir un tel service.

Certains lecteurs pourraient alors se demander : l’écosystème Ethereum dispose-t-il pas d’une plateforme décentralisée de recherche de données, TheGraph ? Quel lien existe-t-il entre TheGraph et Goldsky ? Et pourquoi tant de projets DeFi utilisent-ils Goldsky plutôt que TheGraph, pourtant plus décentralisé ?
Relations entre TheGraph / Goldsky et SubGraph
Pour répondre à ces questions, examinons quelques concepts techniques.
-
SubGraph est un cadre de développement permettant aux développeurs d’écrire du code pour lire et agréger des données blockchain, puis de les afficher sur le front-end selon certaines méthodes.
-
TheGraph est une plateforme précoce de recherche de données décentralisée. Elle a développé le cadre SubGraph écrit en AssemblyScript. Les développeurs peuvent utiliser ce cadre pour capturer les événements des contrats et les stocker dans une base de données, puis lire ces données via GraphQL ou directement via des requêtes SQL.
-
Nous appelons généralement « opérateurs SubGraph » les prestataires qui exécutent des SubGraph. TheGraph et Goldsky sont tous deux des hébergeurs de SubGraph. En effet, SubGraph n’est qu’un cadre de développement : les programmes qu’il génère doivent être exécutés sur des serveurs. Comme on peut le voir dans la documentation de Goldsky :
Certains lecteurs peuvent alors se demander pourquoi plusieurs opérateurs SubGraph existent-ils ?
Parce que le cadre SubGraph ne spécifie que la manière dont les données sont extraites des blocs et insérées dans la base de données.
En revanche, la façon dont les données entrent dans le programme SubGraph ou dans quelle base de données elles sont finalement écrites n’est pas définie — ces aspects doivent être implémentés par chaque opérateur.
En général, les opérateurs SubGraph appliquent des optimisations comme la modification de nœuds pour améliorer la vitesse, et adoptent des stratégies et solutions techniques différentes (ex. : TheGraph, Goldsky).
TheGraph utilise désormais la solution technique Firehouse, qui lui permet d’offrir une recherche de données plus rapide qu’auparavant. Goldsky, quant à lui, ne publie pas le code source de son moteur central d’exécution SubGraph.
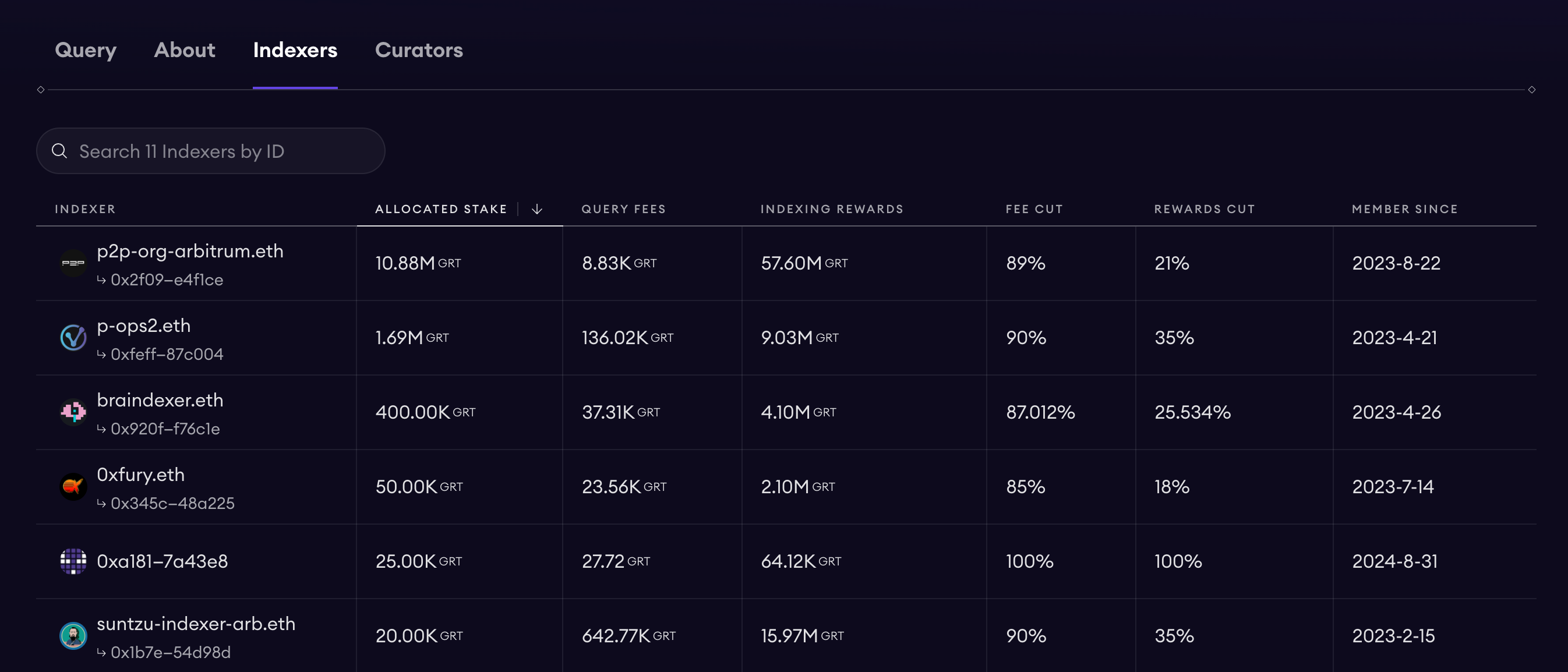
Comme mentionné précédemment, TheGraph est une plateforme décentralisée de recherche de données. Prenons par exemple le sous-graphe Uniswap v3 : on observe qu’un grand nombre d’opérateurs fournissent des services de recherche de données pour Uniswap v3. On peut donc considérer TheGraph comme une plateforme intégrant plusieurs opérateurs SubGraph. Un utilisateur peut envoyer son code SubGraph à TheGraph, puis différents opérateurs internes peuvent l’aider à indexer les données.
Le modèle tarifaire de Goldsky
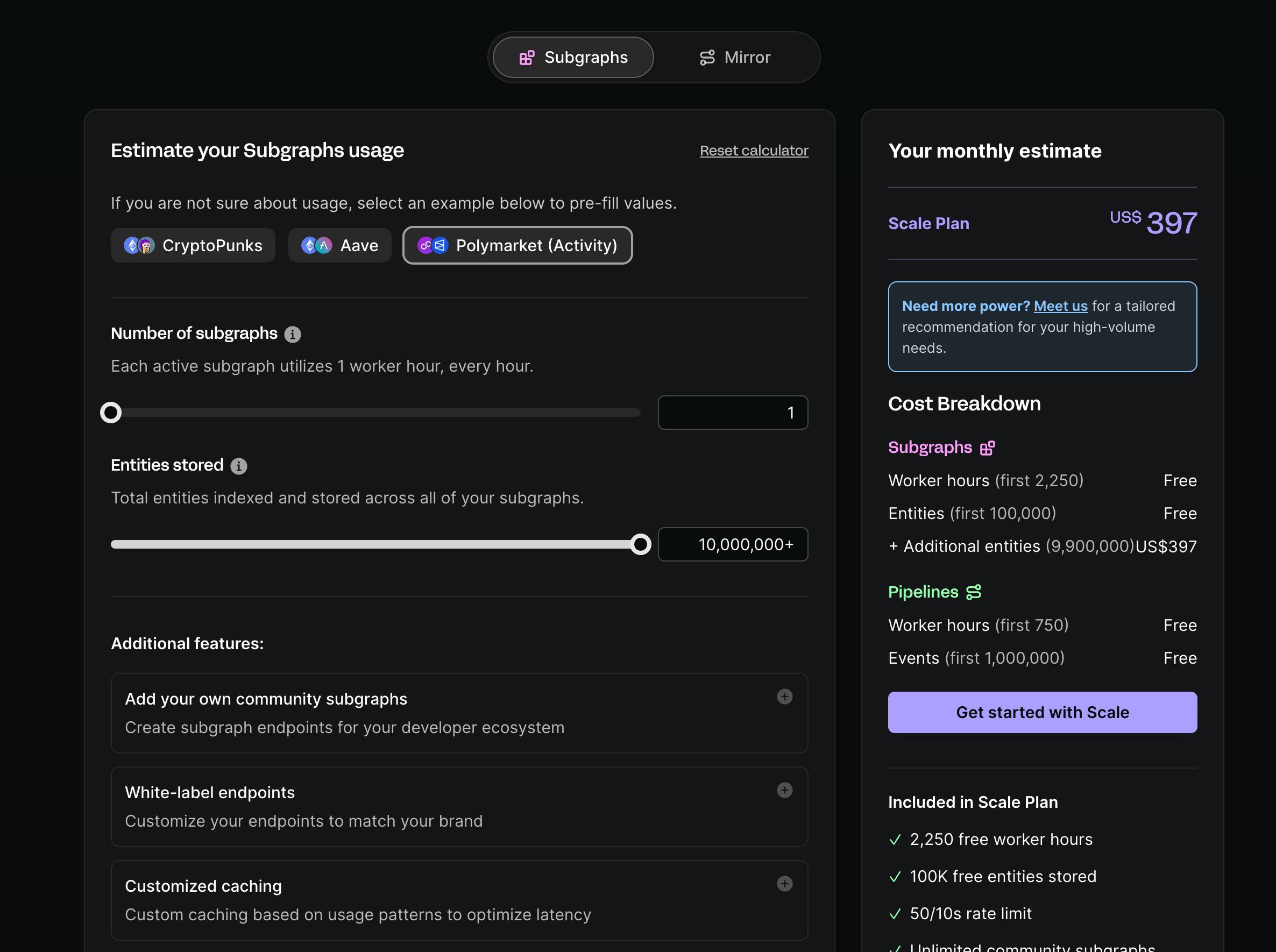
Pour une plateforme centralisée comme Goldsky, le modèle de facturation est simple : il repose sur l'utilisation des ressources, une méthode courante chez les plateformes SaaS du web. La majorité des professionnels techniques y sont familiers. L'image ci-dessous montre la calculatrice de prix de Goldsky :
Le modèle tarifaire de TheGraph
TheGraph, en revanche, adopte un système de frais complètement différent, lié à l’économie du token GRT. L’image ci-dessous illustre l’économie globale du token GRT :
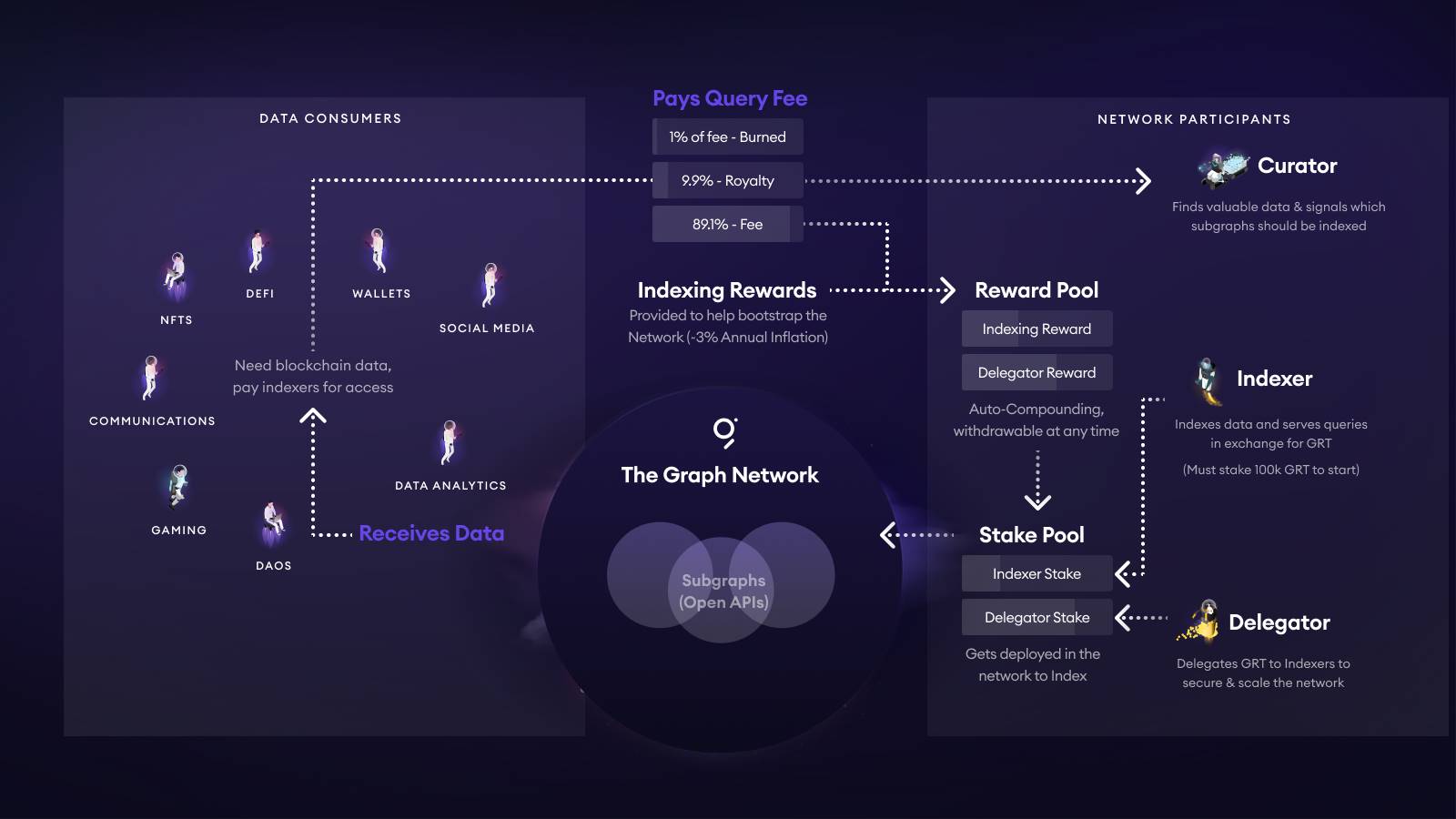
-
Chaque fois qu’une DApp ou un portefeuille effectue une requête vers un Subgraph, les frais de requête (Query Fee) sont automatiquement divisés : 1 % sont brûlés, environ 10 % vont au pool de curation (Curator / développeur) du Subgraph, et le reste (~89 %) est redistribué selon un mécanisme exponentiel aux Indexer et à leurs délégués (Delegator).
-
Pour être opérationnel, un Indexer doit d’abord s’auto-staker au moins 100 k GRT. En cas de retour de données erronées, il subit une pénalité (slashing). Le Delegator délègue ses GRT à un Indexer et reçoit une part proportionnelle des ~89 %.
-
Le Curator (souvent le développeur) stakingue des GRT sur la courbe obligataire de son propre Subgraph via un Signal. Plus le Signal est élevé, plus il attire les Indexer pour allouer des ressources. L’expérience communautaire recommande de disposer de 5 k–10 k GRT pour garantir qu’au moins quelques Indexer acceptent la tâche. En outre, le curateur perçoit les 10 % de royalties.
Frais à l’utilisation sur TheGraph :
Après avoir enregistré une clé API dans le tableau de bord de TheGraph et utilisé celle-ci pour demander aux opérateurs de récupérer des données, chaque requête est facturée. Les développeurs doivent préalablement déposer une certaine quantité de tokens GRT sur la plateforme pour couvrir ces frais.
Frais de mise en gage (staking) Signal sur TheGraph :
Pour qu’un opérateur de TheGraph aide au déploiement d’un SubGraph, conformément au mécanisme de distribution décrit, le développeur doit signaler que son service de requête est attractif et rentable. Cela nécessite de staker des GRT, un peu comme faire de la publicité ou s’engager sur la rentabilité. Cela incite les autres à participer. Pendant les tests, les développeurs peuvent déployer gratuitement leur SubGraph sur TheGraph, où l’équipe officielle fournit un quota gratuit limité, insuffisant pour un usage en production. Si le développeur juge que son SubGraph fonctionne bien dans cet environnement de test, il peut le publier sur le réseau public et attendre que d’autres opérateurs participent. Le développeur ne peut pas payer directement un opérateur spécifique pour garantir la récupération des données, mais fait appel à une concurrence entre opérateurs, évitant ainsi une dépendance unique. Ce processus exige d’utiliser des tokens GRT pour « curatoriser » (ou « signaler ») son SubGraph, c’est-à-dire de staker une certaine quantité de GRT sur le SubGraph déployé. Seulement lorsque cette quantité atteint un seuil significatif (selon des données consultées auparavant, environ 10 000 GRT), les opérateurs commencent à indexer ce SubGraph.
Une mauvaise expérience tarifaire bloque les développeurs et les comptables traditionnels
Pour la plupart des développeurs de projets, utiliser TheGraph est relativement compliqué. Acheter des tokens GRT est encore faisable pour un projet Web3, mais le processus de curation d’un SubGraph déployé et l’attente que des opérateurs interviennent sont particulièrement inefficaces. Ce processus comporte au moins deux problèmes majeurs :
-
Incertain sur la quantité de GRT à staker et le temps d’attente avant intervention des opérateurs. Lorsque j’ai moi-même déployé un SubGraph, j’ai dû consulter un ambassadeur de la communauté TheGraph pour connaître la quantité requise, mais la plupart des développeurs n’ont pas accès à ces informations. Même après un staking suffisant, il faut encore du temps pour que les opérateurs interviennent.
-
Complexité de la comptabilité et du calcul des coûts. Le modèle économique basé sur les tokens rend difficile l’estimation des coûts pour la plupart des développeurs. Un problème concret supplémentaire est que si une entreprise doit comptabiliser ces dépenses, ses comptables auront du mal à comprendre cette structure de coût.
« Bon sang, la centralisation, c’est quand même mieux ? »
Il est clair que pour la plupart des développeurs, choisir directement Goldsky est beaucoup plus simple. Le modèle tarifaire est compréhensible par tous, et presque immédiatement opérationnel moyennant paiement, réduisant fortement l’incertitude. Cela conduit à une forte dépendance vis-à-vis d’un seul produit dans le domaine de l’indexation et de la recherche de données blockchain.
Évidemment, la complexité du modèle économique GRT nuit à l’adoption généralisée de TheGraph. Bien qu’un modèle économique puisse être complexe, cette complexité ne devrait pas être exposée à l’utilisateur. Par exemple, le mécanisme de staking curatorial de GRT ne devrait pas être visible par l’utilisateur final. TheGraph ferait mieux d’offrir une interface de paiement simplifiée.
Cette critique de TheGraph n’est pas uniquement mon avis personnel. Paul Razvan Berg, ingénieur de contrats intelligents renommé et fondateur du projet Sablier, a exprimé une opinion similaire dans un tweet, affirmant que l’expérience utilisateur liée au déploiement de SubGraph et à la facturation en GRT est extrêmement mauvaise.
III. Quelques solutions existantes
Pour résoudre le problème du point de défaillance unique dans la recherche de données, nous avons déjà mentionné une piste : les développeurs peuvent envisager d’utiliser TheGraph, même si le processus est complexe (achat de GRT, staking curatorial, paiement des frais API).
Actuellement, l’écosystème EVM compte de nombreux logiciels de recherche de données. Voir par exemple The State of EVM Indexing par Dune ou Récapitulatif des outils d’indexation EVM par rindexer. Une discussion plus récente est disponible dans ce tweet.
Cet article n’analysera pas en détail les causes de la panne de Goldsky, car selon le rapport de Goldsky, l’entreprise connaît la cause exacte mais ne la divulgue qu’aux clients enterprise. Ainsi, aucun tiers ne peut actuellement savoir précisément ce qui s’est passé. D’après le rapport, il semble que le problème soit survenu lors de l’écriture des données indexées dans la base. Dans ce rapport succinct, Goldsky indique que la base de données était inaccessible, et qu’un accès n’a été retrouvé qu’en coopérant avec AWS.
Dans cette section, nous présentons d'autres approches alternatives :
-
ponder est un logiciel de recherche de données simple, offrant une bonne expérience de développement et facile à déployer, que les développeurs peuvent installer sur leurs propres serveurs.
-
local-first est un concept de développement intéressant, prônant une expérience utilisateur fluide même en l’absence de connexion réseau. Dans le contexte blockchain, on peut assouplir légèrement cette exigence, en garantissant une bonne expérience dès que l’utilisateur peut se connecter à la blockchain.
ponder
Pourquoi recommander ponder plutôt qu’un autre outil ? Plusieurs raisons :
-
Ponder n’a aucune dépendance vis-à-vis d’un fournisseur. À l’origine projet individuel, ponder ne demande à l’utilisateur que de fournir une URL RPC Ethereum et un lien vers une base PostgreSQL, contrairement aux logiciels proposés par des entreprises.
-
Ponder offre une excellente expérience de développement. Ayant utilisé ponder à plusieurs reprises, je constate que, écrit en TypeScript et reposant principalement sur viem, son utilisation est très agréable.
-
Ponder présente de meilleures performances.
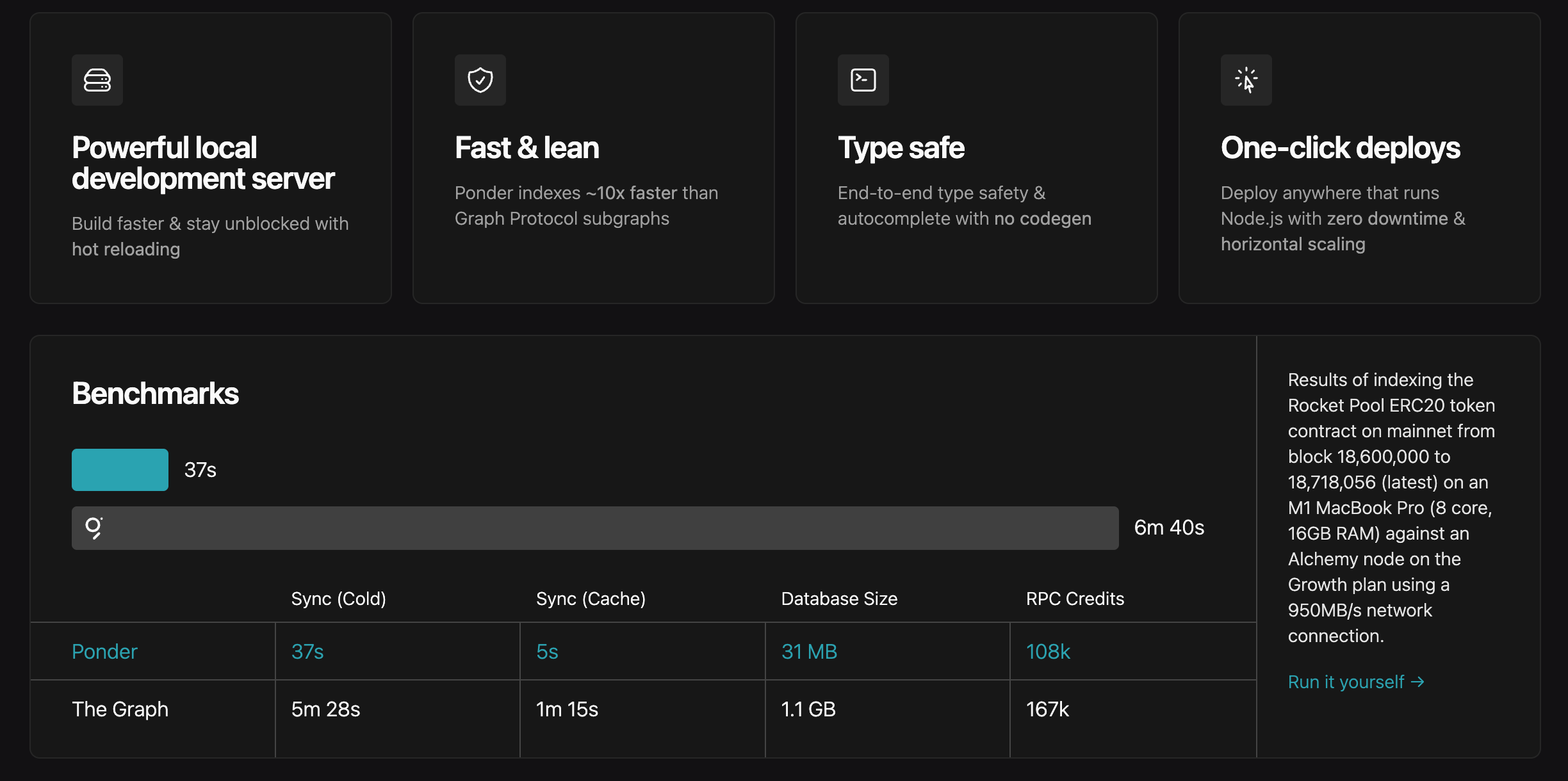
Bien sûr, certains problèmes subsistent. Ponder est encore en phase de développement rapide, et les mises à jour peuvent entraîner des ruptures de compatibilité rendant les anciens projets inopérants. Cet article n’étant pas un tutoriel technique, nous n’entrerons pas davantage dans les détails de développement avec ponder. Les lecteurs ayant des compétences techniques peuvent consulter eux-mêmes la documentation.
Un aspect intéressant de ponder est sa démarche commerciale actuelle, qui illustre bien la « théorie de l’isolement » abordée dans un précédent article.
Expliquons brièvement cette « théorie de l’isolement ». Les biens publics, par nature accessibles à tous, subissent une perte d’utilité sociale s’ils sont payants, car certains utilisateurs cessent alors de les utiliser (en termes économiques : « perte de l’optimalité de Pareto »). Théoriquement, on pourrait pratiquer une tarification différenciée, mais le coût de mise en œuvre excède souvent les gains. Ainsi, les biens publics restent gratuits non par principe, mais parce que toute tarification fixe nuit à l’intérêt général, et qu’aucune méthode peu coûteuse de tarification différenciée n’existe. La théorie de l’isolement propose une solution : isoler un groupe homogène d’utilisateurs et leur appliquer un tarif. Cela permet de préserver l’accès gratuit pour tous, tout en générant des revenus auprès d’un segment spécifique.
Ponder applique précisément cette théorie :
-
Pour déployer ponder, certaines compétences sont requises : fournir un RPC, une base de données, etc.
-
Après déploiement, le développeur doit assurer la maintenance continue (ex. : système proxy pour équilibrer la charge et éviter que les requêtes de données interfèrent avec l’indexation en arrière-plan). Ce niveau de complexité peut rebuter certains développeurs.
-
Actuellement, ponder teste un service de déploiement entièrement automatisé via marble : l’utilisateur envoie simplement son code pour un déploiement automatique.
Il s’agit clairement d’une application de la « théorie de l’isolement » : les développeurs réticents à maintenir eux-mêmes ponder sont isolés et peuvent opter pour un service simplifié moyennant paiement. Naturellement, l’apparition de marble ne prive pas les autres développeurs de l’utilisation gratuite et auto-hébergée du framework ponder.
Public cible de ponder et Goldsky ?
-
Ponder, totalement indépendant de fournisseur, est plus populaire que les services d’indexation dépendants de tiers lors du développement de petits projets.
-
Certains développeurs de grands projets n’optent pas nécessairement pour ponder, car ces projets exigent des performances élevées. Des fournisseurs comme Goldsky offrent alors des garanties de disponibilité supérieures.
Les deux solutions comportent des risques. À la lumière de l’incident Goldsky, il est conseillé aux développeurs de maintenir leur propre instance ponder pour faire face à une éventuelle panne d’un service tiers. De plus, l’utilisation de ponder impose de vérifier la validité des données retournées par le RPC. Récemment, Safe a signalé un cas de plantage d’indexeur dû à des données incorrectes retournées par un RPC (ici). Bien qu’aucune preuve directe ne lie cet incident à Goldsky, je soupçonne que Goldsky ait pu rencontrer un problème similaire.

La philosophie de développement local-first
Local-first est un sujet discuté depuis plusieurs années. En résumé, un logiciel local-first doit posséder deux caractéristiques :
-
Fonctionner hors ligne
-
Permettre la collaboration entre clients
Les discussions techniques autour de local-first font souvent référence à la technologie CRDT (Conflict-free Replicated Data Type). Un CRDT est un format de données sans conflit, permettant une fusion automatique des modifications sur plusieurs appareils tout en préservant l’intégrité des données. On peut voir un CRDT comme un type de données doté d’un protocole de consensus simple, garantissant intégrité et cohérence dans un environnement distribué.
Toutefois, dans le développement blockchain, on peut assouplir certaines exigences de local-first. Il suffit que, même sans les données d’indexation fournies par le développeur du projet, l’utilisateur conserve une disponibilité minimale sur le front-end. Par ailleurs, la nécessité de synchronisation entre clients est déjà résolue par la blockchain elle-même.
Dans un scénario DApp, la philosophie local-first peut s’appliquer ainsi :
-
Mise en cache des données critiques : le front-end doit conserver en cache des données importantes comme les soldes ou positions, afin que l’utilisateur voie l’état connu le plus récent même si le service d’indexation est indisponible.
-
Conception de fonctionnalités dégradées : lorsque le service d’indexation est hors service, la DApp peut offrir des fonctions de base. Par exemple, certaines données peuvent être lues directement depuis la chaîne via RPC, permettant à l’utilisateur de consulter au moins une partie des informations actualisées.
Cette approche augmente considérablement la résilience de l’application, évitant qu’elle devienne totalement inutilisable lors d’une panne du service de recherche. Sans tenir compte de la convivialité, la meilleure application local-first consisterait à exiger que l’utilisateur exécute un nœud local, puis utilise un outil comme trueblocks pour indexer localement les données. Pour approfondir la question de l’indexation décentralisée ou locale, voir le tweet Literally no one cares about decentralized frontends and indexers.
IV. Conclusion
La panne de six heures de Goldsky a sonné l’alerte pour tout l’écosystème. Bien que la blockchain elle-même soit décentralisée et résistante aux pannes ponctuelles, l’écosystème d’applications construit dessus reste fortement dépendant de services d’infrastructure centralisés. Cette dépendance introduit un risque systémique.
Cet article a présenté brièvement pourquoi TheGraph, pourtant célèbre, n’est pas largement utilisé aujourd’hui, en particulier en raison des complexités liées à l’économie du token GRT. Ensuite, nous avons exploré des pistes pour construire une infrastructure d’indexation plus robuste : nous encourageons les développeurs à adopter ponder comme solution d’urgence, tout en saluant sa stratégie commerciale prometteuse. Enfin, nous avons discuté de la philosophie local-first, invitant les développeurs à concevoir des applications fonctionnelles même sans service d’indexation.
Actuellement, de nombreux développeurs Web3 prennent conscience du risque de point de défaillance unique dans les services d’indexation. GCC espère que davantage de développeurs s’intéresseront à cette infrastructure, en créant des services d’indexation décentralisés ou en concevant des cadres permettant aux DApp de fonctionner même sans service d’indexation.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News














