Auteur principal de MoBA de Moonshot : les trois entrées d'un « nouveau formateur de grands modèles » sur la falaise de la pénitence
TechFlow SélectionTechFlow Sélection
Auteur principal de MoBA de Moonshot : les trois entrées d'un « nouveau formateur de grands modèles » sur la falaise de la pénitence
« À partir des articles scientifiques open source et du code open source, on est désormais passé à la chaîne de pensée open source ! »
Auteur : Andrew Lu, équipe LatePost

Image générée par Wujie AI
Le 18 février, Kimi et DeepSeek ont publié respectivement leurs nouvelles avancées MoBA et NSA le même jour, deux améliorations du mécanisme d'attention (Attention Mechanism).
Aujourd'hui, Andrew Lu, l'un des principaux chercheurs ayant développé MoBA, a publié un message sur Zhihu décrivant trois erreurs commises lors du processus de recherche, qu'il appelle « Trois visites à la vallée de la pénitence ». Sa signature sur Zhihu est « nouvel entraîneur LLM ».
Un commentaire sous cette réponse dit : « Partir des codes et articles open source, nous en sommes maintenant arrivés à partager aussi les chaînes de pensée. »
Le mécanisme d'attention est crucial car il constitue le cœur des grands modèles linguistiques (LLM) actuels. En remontant au mois de juin 2017, lorsque l'article fondateur Transformer, surnommé « les huit auteurs », a lancé la révolution LLM, son titre était : Attention Is All You Need (L'attention suffit). Cet article a depuis été cité 153 000 fois.
Le mécanisme d'attention permet aux modèles d'intelligence artificielle de savoir, comme les humains, sur quoi se concentrer et quoi ignorer lors du traitement de l'information, afin d'extraire les éléments clés.
Lors des phases d'entraînement et d'utilisation (inférence) des grands modèles, le mécanisme d'attention joue un rôle central. Son principe général est que, face à une entrée donnée, par exemple « j'aime manger des pommes », le modèle calcule les relations entre chaque mot (Token) et les autres mots pour comprendre la signification.
Mais quand les contextes traités par les grands modèles deviennent de plus en plus longs, l'utilisation initiale dans le standard Transformer de l'attention complète (Full Attention) devient intolérable en termes de ressources de calcul. En effet, la procédure initiale consiste à calculer les scores d'importance de tous les mots d'entrée, puis à appliquer un poids pour identifier les mots les plus importants. Cette complexité de calcul augmente quadratiquement (de façon non linéaire) avec la longueur du texte. Comme indiqué dans le résumé de l'article MoBA :
« L'augmentation quadratique inhérente à la complexité de calcul dans les mécanismes d'attention traditionnels entraîne des coûts computationnels dissuasifs. »
Parallèlement, les chercheurs souhaitent que les grands modèles puissent traiter des contextes toujours plus longs — dialogues multiround, raisonnement complexe, capacité de mémoire... Toutes ces caractéristiques attendues d'une IA générale (AGI) nécessitent une capacité de contexte extrêmement étendue.
Trouver une méthode d'optimisation du mécanisme d'attention qui soit peu gourmande en ressources de calcul et en mémoire, sans nuire aux performances du modèle, est donc devenu un sujet majeur de recherche.
C'est ce contexte technique qui explique pourquoi plusieurs entreprises concentrent leurs efforts sur l'amélioration de « l'attention ».
Au-delà de DeepSeek NSA et Kimi MoBA, début janvier de cette année, une autre startup chinoise spécialisée dans les grands modèles, MiniMax, a également mis en œuvre à grande échelle un nouveau mécanisme d'attention dans son premier modèle open source, MiniMax-01. Le fondateur de MiniMax, Yan Junjie, nous a alors indiqué que c'était l'une des principales innovations de MiniMax-01.
Le professeur Liu Zhiyuan, cofondateur de Bixin Intelligence et professeur adjoint au département d'informatique de l'Université Tsinghua, a également publié InfLLM en 2024, incluant une amélioration de l'attention creuse (sparse attention), article cité par celui de NSA.
Parmi ces réalisations, les mécanismes d'attention de NSA, MoBA et InfLLM relèvent tous de l'« attention creuse » (Sparse Attention) ; tandis que l'approche tentée par MiniMax-01 suit principalement une autre voie : l'« attention linéaire » (Linear Attention).
Cao Shijie, chercheur principal à Microsoft Research Asia et coauteur de SeerAttention, nous explique : globalement, l'attention linéaire modifie davantage et de façon plus radicale le mécanisme d'attention standard, cherchant à résoudre directement le problème d'explosion quadratique (donc non linéaire) du coût de calcul avec la longueur du texte. Un inconvénient potentiel serait une perte dans la capture des dépendances complexes sur de longs contextes. En revanche, l'attention creuse exploite la rareté naturelle de l'attention pour proposer une optimisation plus robuste.
Nous recommandons vivement la réponse très appréciée de Cao Shijie sur Zhihu concernant le mécanisme d'attention : https://www.zhihu.com/people/cao-shi-jie-67/answers
(Il répond à la question suivante : « Quelles informations retenir du nouveau papier DeepSeek NSA, co-signé par Liang Wenfeng ? Quelles en seront les conséquences ? »)
Fu Tianyu, doctorant au laboratoire NICS-EFC de l'Université Tsinghua et co-premier auteur de MoA (Mixture of Sparse Attention), précise que dans le cadre général de l'attention creuse : « NSA et MoBA introduisent tous deux une méthode d'attention dynamique, capable de sélectionner dynamiquement les blocs KV Cache nécessitant un calcul fin d'attention. Comparé à certaines méthodes statiques d'attention creuse, cela améliore les performances du modèle. Ces deux méthodes intègrent également l'attention creuse dès l'entraînement du modèle, et non seulement lors de l'inférence, ce qui renforce encore les performances. »
(Note : Les blocs KV Cache stockent les anciens calculs des étiquettes Key et des valeurs Value ; les étiquettes Key servent à identifier les caractéristiques ou positions des données dans les calculs d'attention, facilitant leur association avec d'autres données lors du calcul des poids d'attention. Les valeurs Value, associées aux étiquettes Key, contiennent généralement les données réelles à traiter, comme les vecteurs sémantiques de mots ou de phrases.)
En outre, Moonshot a non seulement publié un article technique détaillé sur MoBA, mais a également rendu public sur GitHub le code d'ingénierie de MoBA, utilisé en production dans son propre produit Kimi depuis plus d'un an.
* Ce qui suit est le témoignage d'Andrew Lu sur Zhihu, publié avec son autorisation. Plusieurs termes techniques d'IA apparaissent dans le texte original, les explications grises entre parenthèses sont des notes de la rédaction. Lien original : https://www.zhihu.com/people/deer-andrew
Récit de recherche d'Andrew Lu
Suite à l'invitation du professeur Zhang (Zhang Mingxing, professeur assistant à l'Université Tsinghua), je partage mon parcours mouvementé autour de MoBA, que j'appelle « Trois visites à la vallée de la pénitence ». (La question à laquelle répond Andrew Lu est : « Comment évaluer le cadre d'attention creuse MoBA, open-source par Kimi ? Quels sont les points forts respectifs comparés à NSA de DeepSeek ? »)
Début de MoBA
Le projet MoBA a commencé très tôt, fin mai 2023, juste après la création de Moonshot. Dès mon premier jour, Tim (Zhou Xinyu, cofondateur de Moonshot) m'a emmené dans une petite pièce avec Qiu Jiezhong (Zhejiang University / Zhejiang Laboratory, initiateur de l'idée MoBA) et Dylan (chercheur chez Moonshot) pour démarrer Long Context Training (entraînement sur long contexte). Je tiens à remercier Tim pour sa patience et ses conseils, ainsi que pour avoir fait confiance à un novice en LLM comme moi. Parmi les nombreux experts qui développent des modèles et technologies connexes, beaucoup, comme moi, ont commencé pratiquement à zéro avec les LLM.
À l'époque, le niveau industriel général n'était pas élevé : tout le monde travaillait sur du 4K (longueur d'entrée-sortie environ 4000 tokens, quelques milliers de caractères chinois). Le projet a d'abord porté le nom de 16K on 16B, signifiant un pré-entraînement (pre-train) à 16K sur un modèle de 16 milliards de paramètres (16B). Très vite, en août, la demande est passée à un pré-entraînement supportant 128K. C'était la première exigence de conception de MoBA : pouvoir entraîner rapidement From Scratch (de zéro) un modèle supportant 128K, sans recourir à Continue Training (entraînement continu sur un modèle déjà formé).
Cela soulève une question intéressante : en mai-juin 2023, l'industrie pensait généralement qu'entraîner directement sur de longs textes (pré-entraînement end-to-end sur long contexte) était meilleur que d'entraîner d'abord sur du court puis d'étendre. Cette perception n'a changé qu'à l'arrivée de long Llama (grand modèle Meta supportant les longs textes) en deuxième moitié d'année. Nous avons effectué nos propres validations rigoureuses et constaté que l'entraînement sur du court + activation de longueur offrait une meilleure efficacité par token (chaque token apporte plus d'information utile, signifiant que le modèle accomplit des tâches de qualité supérieure avec moins de tokens). Ainsi, la première fonctionnalité conçue pour MoBA est devenue obsolète.
Pendant cette période, la conception de MoBA était aussi plus « radicale » : comparée à la version simplifiée actuelle, MoBA initialement proposée était une architecture en série à deux couches d'attention, incluant une cross attention (mécanisme d'attention entre deux séquences distinctes). La porte (gate, structure contrôlant la distribution des données entre différents réseaux experts) était sans paramètre (sans besoin d'entraînement), mais pour mieux apprendre les tokens historiques, nous avons ajouté à chaque couche Transformer une cross attention inter-machine et ses paramètres correspondants (permettant de mieux mémoriser l'information historique). Cette conception intégrait déjà l'idée désormais bien connue de Context Parallel (la séquence complète est distribuée sur différents nœuds, regroupée uniquement lors du calcul) : nous répartissions uniformément toute la séquence de contexte entre les nœuds de parallélisme de données, considérant chaque segment de contexte dans un nœud comme un expert (expert) dans un système MoE (Mixture of Experts), envoyant les tokens devant subir une attention vers l'expert correspondant pour une cross attention, puis récupérant le résultat. Nous avons intégré le framework fastmoe (un ancien cadre d'entraînement MoE) dans Megatron-LM (framework courant d'entraînement de grands modèles de Nvidia) pour supporter les communications entre experts.
Nous appelions cette approche MoBA v0.5.
(Note de la rédaction : L'inspiration de MoBA vient de l'architecture MoE dominante dans les grands modèles actuels. MoE signifie qu'à chaque étape, seul un sous-ensemble des paramètres experts est activé, économisant ainsi la puissance de calcul. L'idée centrale de MoBA est : « ne regarder que le contexte le plus pertinent, plutôt que tout le contexte, pour économiser le calcul et les coûts ».)
Vers le début août 2023, le modèle principal avait déjà été pré-entraîné sur un grand nombre de tokens, rendant un redémarrage coûteux. Avec une structure significativement modifiée et des paramètres supplémentaires, MoBA est entré pour la première fois dans la vallée de la pénitence.
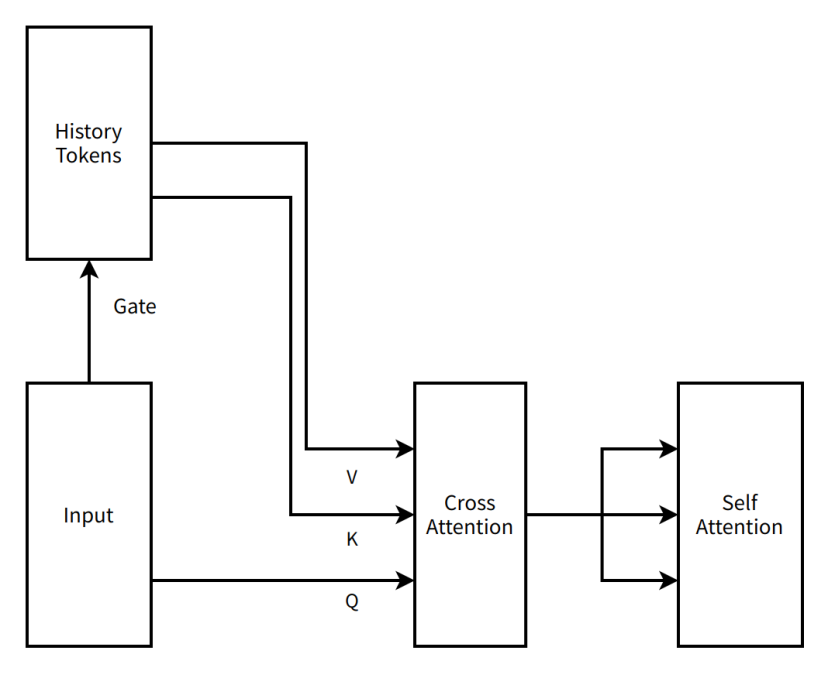
Schéma très simplifié de MoBA v0.5
Note de la rédaction :
History Tokens (tokens historiques) —— dans des scénarios comme le traitement du langage naturel, représente l'ensemble des unités textuelles précédemment traitées.
Gate (porte) —— dans les réseaux neuronaux, structure contrôlant le flux d'information
Input (entrée) —— données ou informations reçues par le modèle
V (Value) —— dans le mécanisme d'attention, contient les données réelles à traiter ou à observer, comme les vecteurs sémantiques
K (Key) —— dans le mécanisme d'attention, étiquette identifiant les caractéristiques ou la position des données, permettant leur association avec d'autres données
Q (Query) —— dans le mécanisme d'attention, vecteur utilisé pour extraire des informations pertinentes depuis les paires clé-valeur
Cross Attention (attention croisée) —— mécanisme d'attention se concentrant sur des sources différentes, comme associer l'entrée à l'historique
Self Attention (auto-attention) —— mécanisme d'attention où le modèle se concentre sur sa propre entrée, capturant les dépendances internes
Première visite à la vallée de la pénitence
Entrer dans la vallée est bien sûr une plaisanterie, signifiant simplement une pause pour trouver des améliorations, et un moment pour mieux comprendre la nouvelle structure. La première retraite fut courte. Tim, génial inventeur de Moonshot, proposa une nouvelle idée : remplacer l'architecture en série à deux couches d'attention par une architecture parallèle à une seule couche. MoBA n'ajoutait plus de paramètres supplémentaires, mais utilisait les paramètres existants du mécanisme d'attention pour apprendre simultanément toutes les informations d'une séquence, permettant ainsi un Continue Training avec une structure minimale.
Nous appelions cette approche MoBA v1.
MoBA v1 résulte en réalité de Sparse Attention combiné à Context Parallel. À l'époque où Context Parallel n'était pas encore dominant, MoBA v1 montrait une capacité d'accélération end-to-end très élevée. Après avoir validé son efficacité sur des modèles de 3B et 7B, nous avons rencontré un mur sur des modèles plus grands : apparition de pics de perte (loss spike) très importants pendant l'entraînement. Notre méthode initiale de fusion des sorties d'attention par blocs était trop simpliste (simple somme cumulative), rendant impossible le debuggage contre Full Attention. Sans ground truth (référence, ici le résultat de Full Attention), le debuggage était extrêmement difficile. Malgré l'usage de toutes les techniques de stabilité disponibles, le problème restait insoluble. À cause de ces problèmes sur grands modèles, MoBA entra pour la deuxième fois dans la vallée de la pénitence.
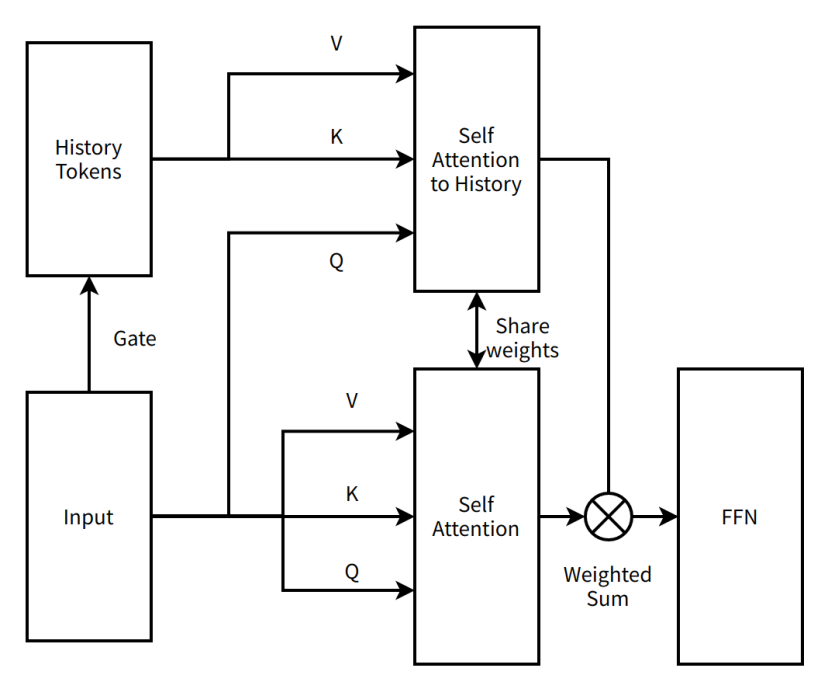
Schéma très simplifié de MoBA v1
Note de la rédaction :
Self Attention to History (auto-attention vers l'historique) —— mécanisme d'attention où le modèle se concentre sur les tokens historiques, capturant les dépendances entre l'entrée actuelle et l'historique
Share weights (partage de poids) —— parties différentes d'un réseau neuronal utilisant les mêmes paramètres pour réduire le nombre total de paramètres et améliorer la généralisation
FFN (Feed-Forward Neural Network, réseau feed-forward) —— structure de base de réseau neuronal où les données vont dans un sens unique de l'entrée à la sortie via les couches cachées
Weighted Sum (somme pondérée) —— opération consistant à additionner plusieurs valeurs selon leurs poids respectifs
Deuxième visite à la vallée de la pénitence
La deuxième retraite fut longue, débutant en septembre 2023 et ne prenant fin qu'au début 2024. Mais être en retraite ne signifiait pas être abandonné. J'ai pu découvrir un second aspect caractéristique du travail chez Moonshot : le secours saturé.
Outre Tim et le professeur Qiu, toujours très actifs, Su Shen (Su Jianlin, chercheur Moonshot), Yuan Ge (Jingyuan Liu, chercheur Moonshot) et d'autres experts ont participé à des discussions animées pour démonter et corriger MoBA. Le premier point corrigé fut cette simple somme pondérée. Après avoir essayé diverses méthodes combinant matrices de porte, Tim a sorti des archives Online Softmax (calcul possible sans voir toutes les données, traitement en continu), affirmant que cela devrait fonctionner. Le plus grand avantage est qu'avec Online Softmax, en réduisant la rareté à 0 (sélectionnant tous les blocs), nous pouvons comparer strictement avec un Full Attention mathématiquement équivalent, ce qui résout la plupart des difficultés d'implémentation. Toutefois, la division du contexte entre les nœuds de parallélisme de données causait toujours un problème d'inégalité : après répartition, les premiers tokens du premier nœud recevaient des demandes d'attention (attend) provenant de nombreux Q, créant un déséquilibre critique et ralentissant l'efficacité d'accélération. Ce phénomène porte un nom plus connu : Attention Sink (point de concentration d'attention).
Le professeur Zhang est alors arrivé, a écouté nos idées et proposé une nouvelle approche : séparer complètement les capacités Context Parallel et MoBA. Context Parallel reste Context Parallel, MoBA redevient une attention creuse pure, et non un cadre d'entraînement distribué. Tant que la mémoire GPU le permet, tout le contexte peut être traité sur une seule machine, MoBA servant à accélérer le calcul, tandis que Context Parallel organise et transmet les contextes entre machines. Nous avons donc réimplémenté MoBA v2, proche de la version actuelle connue de tous.
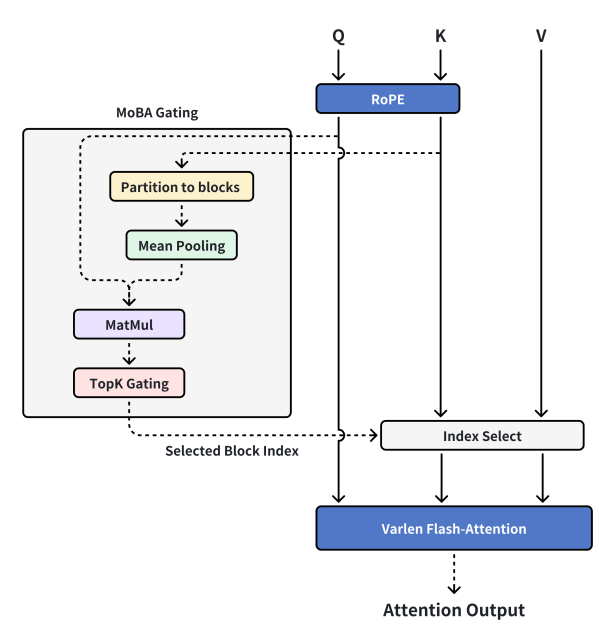
Conception actuelle de MoBA
Note de la rédaction :
MoBA Gating (contrôle MoBA) —— mécanisme de contrôle spécifique à MoBA
RoPE (Rotary Position Embedding, intégration de position rotative) —— technique ajoutant des informations de position aux séquences
Partition to blocks (partition en blocs) —— diviser les données en blocs distincts
Mean Pooling (moyenne par groupe) —— opération de réduction dans l'apprentissage profond, calculant la moyenne des données dans une zone
MatMul (Matrix-Multiply, multiplication matricielle) —— opération mathématique calculant le produit de deux matrices
TopK Gating (contrôle Top-K) —— mécanisme de contrôle sélectionnant les K éléments les plus importants
Selected Block Index (index du bloc sélectionné) —— numéro du bloc retenu
Index Select (sélection par index) —— extraction d'éléments selon leur index
Varlen Flash-Attention (attention rapide à longueur variable) —— mécanisme d'attention efficace adapté aux séquences de longueur variable
Attention Output (sortie d'attention) —— résultat produit par le mécanisme d'attention
MoBA v2 est stable et entraînable, parfaitement aligné avec Full Attention sur du court texte, avec une loi d'échelle fiable et une transition fluide vers les modèles en production. Nous y avons ajouté davantage de ressources. Après une série de debugs et plusieurs cheveux perdus par l'équipe infra, nous avons réussi à atteindre des résultats parfaits aux tests « recherche de l'aiguille dans la botte de foin » (test de performance sur longs textes), ce que nous jugions excellent. Le déploiement a alors commencé.
Mais bien sûr, seul l'imprévu était inattendu. Pendant la phase SFT (fine-tuning supervisé, entraînement complémentaire sur tâche spécifique après pré-entraînement), certains jeux de données comportaient un masque de perte (loss mask) très creux (seulement 1 % ou moins des tokens générant un gradient d'entraînement). Cela faisait que MoBA performait bien sur la plupart des tâches SFT, mais que plus la tâche impliquait des résumés longs, plus le loss mask devenait creux, et plus l'efficacité d'apprentissage baissait. MoBA fut alors suspendu juste avant le déploiement, entamant sa troisième visite à la vallée de la pénitence.
Troisième visite à la vallée de la pénitence
La troisième retraite fut la plus tendue : le projet avait déjà accumulé un coût irrécupérable important, l'entreprise ayant investi massivement en ressources de calcul et humaines. Si, finalement, les applications sur longs textes échouaient, toute la recherche précédente serait perdue. Heureusement, grâce aux excellentes propriétés mathématiques de MoBA, lors d'expériences d'ablation intensives (suppression partielle du modèle pour analyser l'impact), nous avons constaté que sans loss mask, les performances étaient excellentes, mais qu'avec loss mask, elles étaient mauvaises. Nous avons compris que les tokens avec gradient étaient trop rares pendant SFT, causant une faible efficacité d'apprentissage. En modifiant les dernières couches pour utiliser Full Attention, nous avons augmenté la densité des tokens avec gradient lors de la rétropropagation, améliorant ainsi l'efficacité d'apprentissage sur certaines tâches. D'autres tests ultérieurs ont prouvé que ce basculement n'affectait pas significativement l'efficacité de l'attention creuse après retour. Sur 1 million de tokens, les performances restaient équivalentes à celles d'un Full Attention de même structure. MoBA est ainsi revenu de la vallée et a été déployé avec succès pour servir les utilisateurs.
Enfin, merci aux nombreux experts pour leur aide précieuse, à l'entreprise pour son soutien indéfectible et pour ses innombrables cartes graphiques. Le code que nous publions aujourd'hui est celui utilisé en production, validé sur le long terme, simplifié en retirant diverses conceptions superflues selon les besoins réels, gardant une structure minimaliste tout en restant efficace. Nous espérons que MoBA, ainsi que sa chaîne de pensée (CoT, Chain of Thought) ayant mené à sa création, puisse apporter aide et valeur à tous.
FAQ
J'en profite pour répondre à quelques questions fréquentes des derniers jours. J'ai surtout ennuyé le professeur Zhang et Su Shen en leur demandant de jouer les agents d'assistance. Voici quelques questions courantes regroupées ici.
1. MoBA est-il inefficace pour le Decoding (processus de génération de texte durant l'inférence du modèle) ?
MoBA est efficace pour le Decoding, très efficace pour MHA (Multi-Head Attention), moins pour GQA (Grouped Query Attention), et le moins efficace pour MQA (Multi-Query Attention). Le principe est simple : dans le cas MHA, chaque Q possède son propre cache KV, donc la porte MoBA peut, idéalement, pré-calculer et stocker pendant la phase prefill (calcul initial à l'entrée) le token représentatif de chaque bloc, qui ne changera plus par la suite. Ainsi, presque toutes les opérations IO (entrées-sorties) proviennent uniquement du cache KV après Index Select, ce qui signifie que le degré de rareté de MoBA détermine directement la réduction des IO.
Mais pour GQA et MQA, un groupe de têtes Q partage le même cache KV. Si chaque tête Q peut librement choisir son bloc d'intérêt, cela risque d'annuler l'optimisation IO apportée par la rareté. Prenons un exemple : 16 têtes Q en MQA, MoBA divise exactement la séquence en 16 blocs. Dans le pire cas, chaque tête Q s'intéresse à un bloc différent numéroté de 1 à 16, annulant ainsi tout gain d'IO. Plus il y a de têtes Q pouvant librement choisir leur bloc KV, moins l'effet est bon.
Face à ce phénomène de « têtes Q choisissant librement leur bloc KV », une amélioration naturelle serait de les forcer à converger : si tous choisissent le même bloc, l'optimisation IO serait maximisée. Oui, mais lors de nos tests, notamment sur des modèles pré-entraînés ayant coûté cher, chaque tête Q a son propre « goût » unique, et une fusion forcée est moins efficace qu'un ré-entraînement complet.
2. MoBA sélectionne obligatoirement self attention (mécanisme d'auto-attention) , mais le voisin du self est-il aussi obligatoirement sélectionné ?
Non, ce point peut prêter à confusion, mais nous avons choisi de faire confiance à SGD (Stochastic Gradient Descent). L'implémentation actuelle de la porte MoBA est très directe. Les étudiants intéressés peuvent facilement modifier la porte pour forcer la sélection du bloc précédent, mais nos tests montrent que le gain est marginal.
3. MoBA dispose-t-il d'une implémentation Triton (framework pour écrire du code GPU haute performance, développé par OpenAI) ?
Nous en avons implémenté une version, apportant un gain de performance end-to-end supérieur à 10 %. Toutefois, maintenir une implémentation Triton synchronisée avec la branche principale s'avère coûteux. Après plusieurs itérations, nous avons donc différé toute optimisation supplémentaire.
* Liens vers les projets mentionnés en début d'article (les pages GitHub contiennent tous les liens vers les articles techniques ; la page GitHub de DeepSeek NSA n'est pas encore publiée) :
Page GitHub MoBA : https://github.com/MoonshotAI/MoBA
Article technique NSA : https://arxiv.org/abs/2502.11089
Page GitHub MiniMax-01 : https://github.com/MiniMax-AI/MiniMax-01
Page GitHub InfLLM : https://github.com/thunlp/InfLLM?tab=readme-ov-file
Page GitHub SeerAttention : https://github.com/microsoft/SeerAttention
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News