

Comment calcule-t-on les coûts de DeepSeek et autres ?
TechFlow SélectionTechFlow Sélection
Comment calcule-t-on les coûts de DeepSeek et autres ?
Bagarre des grands modèles, d'un côté la compétition sur les capacités, de l'autre sur les « coûts ».
Auteur : Wang Lu, article original de Dingjiao One (dingjiaoone)
DeepSeek a profondément ébranlé le monde entier.
Hier, Musk est apparu en direct avec « l’IA la plus intelligente de la Terre » – Gork 3, affirmant que ses « capacités de raisonnement surpassent celles de tous les modèles connus à ce jour », obtenant de meilleurs scores que DeepSeek R1 et OpenAI o1 sur les tests de raisonnement-temporel. Récemment, WeChat, une application incontournable en Chine, a annoncé l’intégration de DeepSeek R1, actuellement en test progressif. Ce duo choc est perçu par l’extérieur comme un signe de bouleversement imminent dans le domaine de la recherche IA.
Aujourd’hui, de nombreuses grandes entreprises technologiques mondiales telles que Microsoft, NVIDIA, Huawei Cloud et Tencent Cloud ont déjà intégré DeepSeek. Les internautes ont également développé des usages originaux tels que la divination ou la prédiction de loteries. Cette popularité s’est directement transformée en revenus concrets, propulsant la valorisation de DeepSeek vers des sommets, atteignant désormais jusqu’à 100 milliards de dollars américains.
Le succès viral de DeepSeek s’explique non seulement par son accessibilité gratuite et sa facilité d’utilisation, mais aussi par le fait qu’il a réussi à entraîner le modèle DeepSeek R1, rivalisant avec OpenAI o1, pour seulement 5,576 millions de dollars de coût GPU. En effet, au cours des dernières années de la « bataille des cent modèles », les entreprises chinoises et étrangères spécialisées dans les grands modèles IA ont investi des dizaines, voire des centaines de milliards de dollars. Le prix à payer pour faire de Gork 3 « l’IA la plus intelligente du monde » est également élevé : Musk affirme que l’entraînement cumulé de Gork 3 a consommé 200 000 GPU NVIDIA (coût unitaire environ 30 000 dollars), tandis que selon les estimations des professionnels du secteur, DeepSeek n’en aurait utilisé qu’environ 10 000.
Cependant, certains challengent DeepSeek sur le plan des coûts. Récemment, l’équipe de Li Feifei a annoncé avoir entraîné un modèle de raisonnement nommé S1 pour moins de 50 dollars de frais de cloud computing, dont les performances en mathématiques et codage rivalisent avec celles d’o1 d’OpenAI et de R1 de DeepSeek. Toutefois, il convient de noter que S1 est un modèle de taille moyenne, loin derrière le niveau de plusieurs centaines de milliards de paramètres de DeepSeek R1.
Malgré cela, l’énorme différence entre 50 dollars et des centaines de milliards de dollars en coûts d’entraînement suscite la curiosité générale : d’un côté, on veut connaître la puissance réelle de DeepSeek et comprendre pourquoi toutes les entreprises cherchent à le rattraper, voire à le dépasser ; d’un autre côté, combien coûte exactement l’entraînement d’un grand modèle ? Quels sont les étapes impliquées ? À l’avenir, est-il possible de réduire encore davantage ces coûts ?
DeepSeek victime de généralisations abusives
Pour les professionnels du secteur, avant de répondre à ces questions, il faut clarifier certains concepts.
Tout d’abord, la perception de DeepSeek souffre de généralisations abusives. Ce qui impressionne le public est l’un de ses nombreux grands modèles : le modèle de raisonnement DeepSeek-R1. Pourtant, DeepSeek dispose d’autres grands modèles aux fonctionnalités différentes. Quant aux 5,576 millions de dollars mentionnés, ils correspondent aux dépenses GPU lors de l’entraînement du modèle généraliste DeepSeek-V3, qu’on peut considérer comme le coût pur de puissance de calcul.
Pour une comparaison simple :
-
Modèle généraliste :
Reçoit des instructions précises, décompose les étapes ; l’utilisateur doit bien décrire la tâche, y compris l’ordre des réponses, par exemple indiquer s’il faut d’abord résumer puis proposer un titre, ou inversement.
Réponse rapide, basée sur la prédiction probabiliste (réaction rapide), prévoit la réponse à partir de grandes quantités de données.
-
Modèle de raisonnement :
Reçoit des tâches simples, claires et ciblées ; l’utilisateur exprime directement son besoin, le modèle pouvant alors planifier seul.
Réponse plus lente, basée sur la pensée en chaîne (réflexion lente), résout les problèmes étape par étape pour obtenir la réponse.
La principale différence technique réside dans les données d’entraînement : pour les modèles généralistes, ce sont question + réponse ; pour les modèles de raisonnement, ce sont question + processus de pensée + réponse.
Deuxièmement, en raison de l’attention accrue portée au modèle de raisonnement DeepSeek-R1, beaucoup pensent à tort que les modèles de raisonnement sont nécessairement supérieurs aux modèles généralistes.
Il faut reconnaître que les modèles de raisonnement appartiennent à une catégorie avancée, constituant un nouveau paradigme lancé par OpenAI après l’essoufflement du paradigme traditionnel d’entraînement préalable. Comparés aux modèles généralistes, les modèles de raisonnement sont plus coûteux et nécessitent un temps d’entraînement plus long.
Mais cela ne signifie pas qu’un modèle de raisonnement soit toujours plus efficace qu’un modèle généraliste, et même pour certaines tâches, il peut s’avérer peu pratique.
Liu Cong, expert renommé dans le domaine des grands modèles, explique à « DingjiaoOne » que pour des questions simples comme la capitale d’un pays ou la capitale provinciale d’une région, un modèle de raisonnement est moins performant qu’un modèle généraliste.

Surpensation de DeepSeek-R1 face à des questions simples
Il souligne que pour ce type de questions simples, le modèle de raisonnement n’est pas seulement moins efficace en termes de réponse, mais consomme aussi davantage de ressources informatiques, peut surréagir, et finalement donner une réponse erronée.
Il recommande d’utiliser les modèles de raisonnement pour des tâches complexes comme les problèmes mathématiques difficiles ou le codage exigeant, tandis que pour des tâches simples comme la synthèse, la traduction ou les réponses basiques, les modèles généralistes offrent de meilleurs résultats.
Troisièmement, quelle est réellement la puissance de DeepSeek ?
En se basant sur les classements officiels et les avis des professionnels, « DingjiaoOne » a établi un classement pour DeepSeek dans les domaines du modèle de raisonnement et du modèle généraliste.
Dans la première catégorie des modèles de raisonnement, quatre acteurs principaux : à l’étranger, la série o d’OpenAI (comme o3-mini) et Gemini 2.0 de Google ; en Chine, DeepSeek-R1 et QwQ d’Alibaba.
Plusieurs professionnels estiment que, bien que DeepSeek-R1 soit considéré comme un modèle de pointe national et que ses capacités soient perçues comme dépassant celles d’OpenAI, il subsiste toutefois un écart technologique par rapport au dernier o3 d’OpenAI.
Son importance majeure réside dans la réduction drastique de l’écart entre les niveaux nationaux et internationaux. « Si l’écart était auparavant de 2 à 3 générations, avec l’apparition de DeepSeek-R1, il est désormais réduit à 0,5 génération », indique Jiang Shu, professionnel expérimenté du secteur IA.
À partir de son expérience personnelle, il présente les forces et faiblesses des quatre modèles :
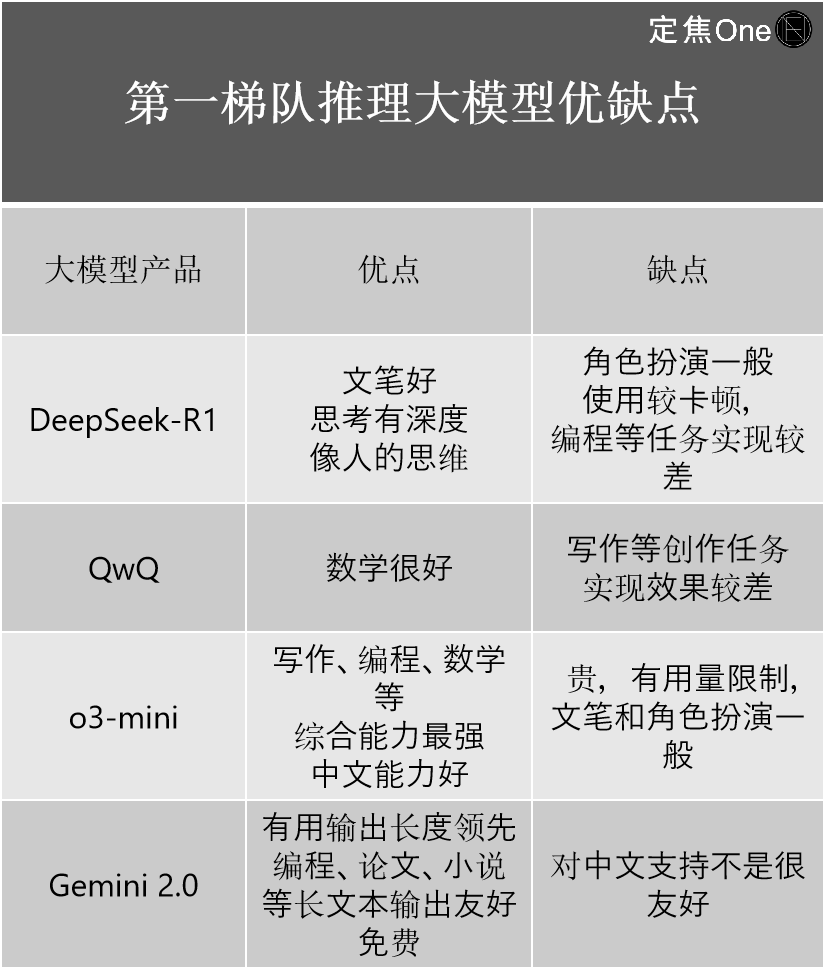
Dans le domaine des modèles généralistes, selon le classement LM Arena (plateforme open source évaluant les performances des grands modèles linguistiques LLM), cinq acteurs dominent le peloton de tête : à l’étranger, Gemini (fermé) de Google, ChatGPT d’OpenAI et Claude d’Anthropic ; en Chine, DeepSeek et Qwen d’Alibaba.
Jiang Shu partage également son retour d’expérience sur l’utilisation de ces modèles.
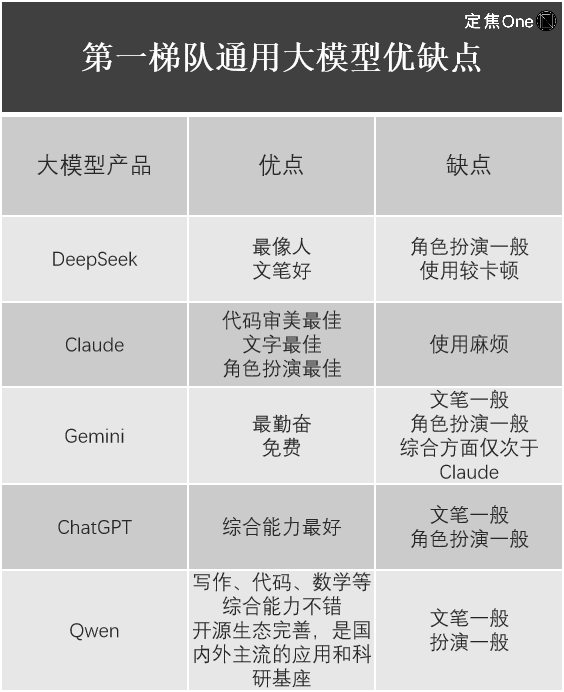
On constate aisément que, malgré l’impact mondial de DeepSeek-R1 et sa valeur indéniable, chaque grand modèle présente ses propres forces et faiblesses, et DeepSeek n’est pas exempt de défauts. Par exemple, Liu Cong remarque que Janus-Pro, le dernier modèle multimodal de DeepSeek spécialisé dans la compréhension et la génération d’images, offre des performances médiocres.
Combien coûte l’entraînement d’un grand modèle ?
Revenons à la question du coût d’entraînement des grands modèles : comment naît un grand modèle ?
Liu Cong explique que la création d’un grand modèle se déroule principalement en deux phases : pré-entraînement et post-entraînement. Si l’on compare un grand modèle à un enfant, le pré-entraînement et le post-entraînement consistent à faire passer l’enfant du stade où il ne sait que pleurer à celui où il comprend ce que disent les adultes, puis à celui où il leur parle activement.
Le pré-entraînement concerne principalement les corpus d’apprentissage. Par exemple, injecter de vastes volumes de texte au modèle permet à l’enfant d’acquérir des connaissances, mais à ce stade, il ne fait que les absorber sans savoir encore les utiliser.
Le post-entraînement consiste à enseigner à l’enfant comment utiliser ces connaissances acquises, via deux méthodes : l’ajustement fin du modèle (SFT) et l’apprentissage par renforcement (RLHF).
Liu Cong précise que, qu’il s’agisse de modèles généralistes ou de raisonnement, nationaux ou internationaux, tous suivent ce processus. Jiang Shu confirme également à « DingjiaoOne » que tous utilisent l’architecture Transformer, donc au niveau fondamental de la structure du modèle et des étapes d’entraînement, il n’y a aucune différence essentielle.
Plusieurs professionnels indiquent que les coûts d’entraînement varient fortement selon les entreprises, principalement concentrés sur trois aspects : matériel, données et main-d’œuvre, chacun pouvant adopter des approches différentes, entraînant des coûts variables.
Liu Cong donne des exemples : acheter ou louer du matériel implique des écarts de prix importants. L’achat représente un investissement initial élevé, mais réduit fortement les coûts futurs (principalement l’électricité), tandis que la location limite l’investissement initial mais maintient un coût permanent. Concernant les données d’entraînement, acheter des données existantes ou les extraire soi-même fait également une grande différence. Le coût de chaque entraînement varie aussi : le premier cycle nécessite l’écriture de robots d’extraction et le filtrage des données, tandis que les versions suivantes peuvent réutiliser des opérations antérieures, réduisant ainsi les coûts. En outre, le nombre d’itérations intermédiaires avant la version finale influence également le coût total, mais les entreprises de grands modèles restent très discrètes à ce sujet.
En résumé, chaque étape implique de nombreux coûts cachés élevés.
Des estimations externes basées sur les GPU indiquent que, parmi les modèles leaders, l’entraînement de GPT-4 coûterait environ 78 millions de dollars, Llama3.1 plus de 60 millions, et Claude3.5 environ 100 millions. Cependant, étant donné que ces grands modèles leaders sont fermés, et que l’on ignore si certaines entreprises gaspillent des ressources computationnelles, il est difficile d’obtenir des chiffres précis. Jusqu’à l’apparition de DeepSeek, dans la même catégorie, avec un coût de 5,576 millions de dollars.

Source image / Unsplash
Il convient de noter que les 5,576 millions de dollars correspondent au coût d’entraînement du modèle de base DeepSeek-V3 mentionné dans le rapport technique de DeepSeek. « Ce coût pour la version V3 ne reflète que le coût du dernier entraînement réussi ; les coûts initiaux liés à la recherche, à l’architecture et aux erreurs d’algorithmes ne sont pas inclus. Quant au coût spécifique d’entraînement de R1, il n’est pas mentionné dans l’article scientifique », précise Liu Cong. Autrement dit, les 5,576 millions ne représentent qu’une petite partie du coût total du modèle.
La société d’analyse et de prévision du marché des semi-conducteurs SemiAnalysis indique que, en tenant compte des dépenses en capital serveur et des coûts opérationnels, le coût total de DeepSeek pourrait atteindre 2,573 milliards de dollars sur quatre ans.
Les professionnels jugent que, comparé aux investissements de centaines de milliards de dollars des autres entreprises de grands modèles, même à 2,573 milliards, le coût de DeepSeek reste faible.
En outre, l’entraînement de DeepSeek-V3 nécessite seulement 2 048 GPU NVIDIA, avec seulement 2,788 millions d’heures-GPU utilisées. En comparaison, OpenAI a utilisé des dizaines de milliers de GPU, et Meta a consommé 30,84 millions d’heures-GPU pour entraîner son modèle Llama-3.1-405B.
DeepSeek est non seulement plus efficace durant la phase d’entraînement, mais aussi plus performant et moins coûteux lors de la phase d’inférence.
Les tarifs API publiés par DeepSeek pour divers grands modèles (les développeurs peuvent appeler des grands modèles via API pour générer du texte, dialoguer ou produire du code) montrent que ses coûts sont inférieurs à ceux des « OpenAI et autres ». En général, un API à coût élevé nécessite un prix élevé pour amortir ses dépenses.
Le tarif API de DeepSeek-R1 est de 1 yuan par million de tokens d’entrée (cache hit), et 16 yuans par million de tokens de sortie. En revanche, pour o3-mini d’OpenAI, les tarifs par million de tokens d’entrée (cache hit) et de sortie sont respectivement de 0,55 dollar (4 yuans) et 4,4 dollars (31 yuans).
Le cache hit signifie lire les données depuis le cache plutôt que de recalculer ou regénérer le résultat via le modèle, ce qui réduit le temps de traitement et diminue les coûts. Le secteur distingue cache hit et cache miss pour améliorer la compétitivité des tarifs API, et les prix bas facilitent l’accès des petites et moyennes entreprises.
Récemment, après la fin de la période promotionnelle, DeepSeek-V3 a augmenté ses tarifs, passant de 0,1 yuan par million de tokens d’entrée (cache hit) et 2 yuans par million de tokens de sortie à 0,5 yuan et 8 yuans respectivement, mais reste tout de même inférieur aux autres modèles principaux.
Bien que le coût total d’entraînement d’un grand modèle soit difficile à estimer, les professionnels s’accordent à dire que DeepSeek pourrait représenter le coût minimum actuel parmi les grands modèles de pointe, et que les autres entreprises devraient à l’avenir s’aligner sur DeepSeek pour réduire leurs coûts.
Les enseignements de DeepSeek sur la réduction des coûts
Où DeepSeek a-t-il économisé ? D’après les professionnels, des optimisations ont été réalisées à chaque étape : architecture du modèle, pré-entraînement, post-entraînement.
Par exemple, pour garantir la qualité des réponses, de nombreuses entreprises utilisent le modèle MoE (Mixture of Experts), qui consiste, face à un problème complexe, à le décomposer en sous-tâches attribuées à différents experts. Bien que plusieurs entreprises aient mentionné ce modèle, DeepSeek a atteint un niveau ultime de spécialisation des experts.
Le secret réside dans la segmentation fine des experts (sous-décomposition des tâches au sein d’une même catégorie) et l’isolement des experts partagés (isoler certains experts pour réduire la redondance des connaissances). Ces mesures permettent d’améliorer considérablement l’efficacité et les performances des paramètres MoE, fournissant des réponses plus rapides et précises.
Un professionnel estime que DeepSeekMoE atteint avec environ 40 % de puissance de calcul seulement des résultats comparables à ceux de LLaMA2-7B.
Le traitement des données est également un obstacle majeur dans l’entraînement des grands modèles. Toutes les entreprises cherchent à améliorer l’efficacité du calcul tout en réduisant les besoins matériels en mémoire et bande passante. La solution trouvée par DeepSeek consiste à utiliser l’entraînement en basse précision FP8 (accélère l’entraînement en apprentissage profond). « Cette démarche est relativement en avance parmi les modèles open source connus, car la plupart des grands modèles utilisent l’entraînement en précision mixte FP16 ou BF16, alors que FP8 est beaucoup plus rapide », explique Liu Cong.
Dans le post-entraînement, l’optimisation de stratégie par apprentissage par renforcement est un point critique, assimilable à l’amélioration de la prise de décision du grand modèle. Par exemple, AlphaGo a appris par optimisation de stratégie à choisir les meilleurs coups au jeu de go.
DeepSeek adopte l’algorithme GRPO (Group Relative Policy Optimization) plutôt que PPO (Proximal Policy Optimization). La différence principale réside dans l’utilisation ou non d’un modèle de valeur pendant l’optimisation algorithmique : GRPO estime la fonction d’avantage via une récompense relative au sein d’un groupe, tandis que PPO utilise un modèle de valeur distinct. Moins de modèles impliquent naturellement une moindre demande en puissance de calcul, donc des économies.
Enfin, au niveau de l’inférence, l’utilisation du mécanisme d’attention latente multi-têtes (MLA) au lieu de l’attention multi-têtes traditionnelle (MHA) réduit nettement l’occupation de la mémoire vidéo et la complexité du calcul, ce qui se traduit directement par une baisse des frais d’API.
Cependant, la plus grande révélation pour Liu Cong vient de DeepSeek : il est possible d’améliorer les capacités de raisonnement d’un grand modèle sous différents angles, et de bons modèles de raisonnement peuvent être obtenus uniquement par micro-ajustement (SFT) ou uniquement par apprentissage par renforcement (RLHF).
Source image / Pexels
Autrement dit, il existe désormais quatre façons de créer un modèle de raisonnement :
Première méthode : apprentissage par renforcement pur (DeepSeek-R1-zero)
Deuxième méthode : SFT + apprentissage par renforcement (DeepSeek-R1)
Troisième méthode : SFT pur (modèle distillé DeepSeek)
Quatrième méthode : prompts uniquement (petit modèle à faible coût)
« Avant, tout le monde dans le milieu marquait SFT + RLHF. Personne n’imaginait que SFT pur ou RLHF pur pouvaient donner de si bons résultats », note Liu Cong.
La réduction des coûts par DeepSeek apporte non seulement des inspirations techniques, mais influence aussi les trajectoires des entreprises IA.
Wang Sheng, associé chez INNO Angel Fund, explique que dans la course vers l’AGI, deux choix stratégiques s’offrent souvent aux entreprises IA : l’un suit le paradigme de l’« armement en puissance de calcul », accumulant technologies, argent et ressources computationnelles pour pousser les performances du grand modèle à un haut niveau avant de songer à son application industrielle ; l’autre suit le paradigme de « l’efficacité algorithmique », visant dès le départ l’application industrielle, et lançant des modèles à faible coût et haute performance grâce à l’innovation architecturale et aux capacités d’ingénierie.
« La série de modèles de DeepSeek prouve qu’en l’absence de croissance du plafond, le paradigme axé sur l’optimisation de l’efficacité plutôt que sur l’augmentation des capacités est viable », affirme Wang Sheng.
Les professionnels croient que, avec l’évolution des algorithmes, les coûts d’entraînement des grands modèles continueront à diminuer.
« Woodie » Cathie Wood, fondatrice et PDG d’ARK Invest, a souligné qu’avant DeepSeek, le coût d’entraînement en IA baissait de 75 % par an, et le coût d’inférence même de 85 à 90 %. Wang Sheng a également indiqué que publier un modèle identique à celui sorti en début d’année à la fin de l’année entraînerait une chute massive des coûts, pouvant atteindre 1/10.
L’institut de recherche indépendant SemiAnalysis indique dans un récent rapport d’analyse que la baisse du coût d’inférence est l’un des signes du progrès continu de l’intelligence artificielle. Des performances équivalentes à celles du grand modèle GPT-3, qui nécessitaient auparavant un supercalculateur et plusieurs GPU, peuvent désormais être reproduites par de petits modèles installés sur un ordinateur portable. Et les coûts ont fortement baissé : le PDG d’Anthropic, Dario Amodei, estime que le coût des algorithmes tendant vers la qualité de GPT-3 a déjà chuté de 1 200 fois.
À l’avenir, la vitesse de réduction des coûts des grands modèles ne fera que s’accélérer.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News














