

DeepSeek domine le classement de l'App Store, une semaine où l'IA chinoise a secoué la Silicon Valley
TechFlow SélectionTechFlow Sélection
DeepSeek domine le classement de l'App Store, une semaine où l'IA chinoise a secoué la Silicon Valley
Le modèle DeepSeek fait sensation dans la Silicon Valley, et sa valeur ne cesse de croître.
Auteur : APPSO
La semaine dernière, le modèle DeepSeek R1 en provenance de Chine a secoué toute la communauté internationale de l’IA.
D’une part, il a atteint des performances comparables à celles du modèle o1 d’OpenAI avec un coût d'entraînement nettement inférieur, illustrant ainsi les atouts chinois en ingénierie et innovation à grande échelle. D’autre part, il incarne pleinement l’esprit open source, en partageant volontiers les détails techniques.
Récemment, une équipe de recherche dirigée par Jiayi Pan, doctorante à l’université de Berkeley en Californie, a réussi à reproduire à très bas coût (moins de 30 dollars) la technologie clé de DeepSeek R1-Zero : le « moment d’illumination ».

Pas étonnant donc que Mark Zuckerberg (CEO de Meta), Yann LeCun (lauréat du prix Turing) ou encore Demis Hassabis (CEO de Deepmind) aient tous salué DeepSeek avec admiration.
Avec la montée fulgurante de DeepSeek R1, cet après-midi même, l’application DeepSeek a brièvement connu des ralentissements voire un crash temporaire en raison d’un afflux massif d’utilisateurs.
Sam Altman, CEO d’OpenAI, tente justement de reprendre la une des médias internationaux en révélant prématurément les quotas d’utilisation de o3-mini : les abonnés ChatGPT Plus pourront effectuer jusqu’à 100 requêtes par jour.
Cependant, peu savent qu’avant sa notoriété actuelle, l’entreprise mère de DeepSeek, Hangzhou Quant (Hquant), était déjà l’un des leaders chinois dans le secteur des fonds spéculatifs quantitatifs.
Le modèle DeepSeek fait trembler la Silicon Valley, son prestige ne cesse de croître
Le 26 décembre 2024, DeepSeek a officiellement lancé son grand modèle DeepSeek-V3.
Ce modèle s’est distingué dans plusieurs benchmarks, surpassant les principaux modèles dominants du marché, notamment en interrogation documentaire, traitement de longs textes, génération de code et capacités mathématiques. Par exemple, sur des tâches comme MMLU ou GPQA, DeepSeek-V3 atteint des performances proches de celles du modèle de pointe international Claude-3.5-Sonnet.
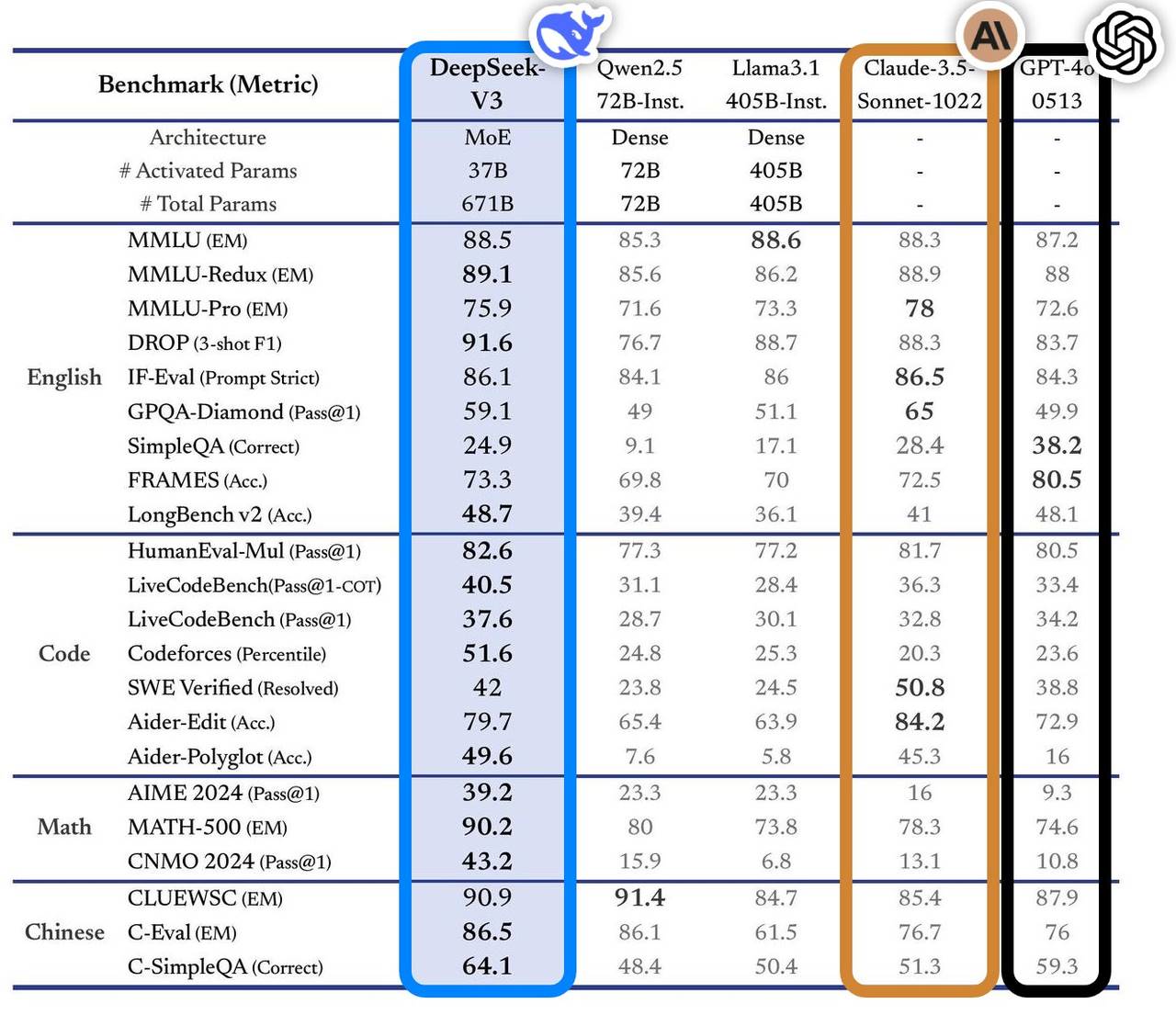
En matière de compétences mathématiques, il a établi de nouveaux records sur des tests comme AIME 2024 et CNMO 2024, surpassant tous les modèles ouverts et fermés connus à ce jour. Par ailleurs, sa vitesse de génération a été améliorée de 200 % par rapport à la génération précédente, atteignant 60 TPS, offrant ainsi une expérience utilisateur bien plus fluide.
Selon l’analyse du site indépendant Artificial Analysis, DeepSeek-V3 dépasse les autres modèles open source sur plusieurs indicateurs clés et rivalise avec les meilleurs modèles fermés mondiaux tels que GPT-4o et Claude-3.5-Sonnet.
Les avantages technologiques clés de DeepSeek-V3 comprennent :
-
L’architecture Mixture of Experts (MoE) : DeepSeek-V3 dispose de 671 milliards de paramètres, mais n’active que 37 milliards de paramètres par entrée lors de l’inférence. Cette activation sélective réduit considérablement les coûts de calcul tout en maintenant des performances élevées.
-
L’attention latente multi-têtes (MLA) : cette architecture, déjà validée sur DeepSeek-V2, permet un entraînement et une inférence hautement efficaces.
-
Une stratégie d’équilibrage de charge sans perte auxiliaire : elle minimise l’impact négatif de l’équilibrage de charge sur les performances du modèle.
-
Un objectif d’entraînement basé sur la prédiction de plusieurs tokens : cette méthode améliore globalement les performances du modèle.
-
Un cadre d’entraînement optimisé : utilisant le framework HAI-LLM, prenant en charge 16-way Pipeline Parallelism (PP), 64-way Expert Parallelism (EP) et ZeRO-1 Data Parallelism (DP), et réduisant significativement le coût d’entraînement grâce à diverses optimisations.
Plus important encore, le coût d’entraînement de DeepSeek-V3 s’élève à seulement 5,58 millions de dollars, bien en dessous des 78 millions nécessaires pour GPT-4. De plus, ses tarifs API restent accessibles, fidèles à sa politique antérieure.
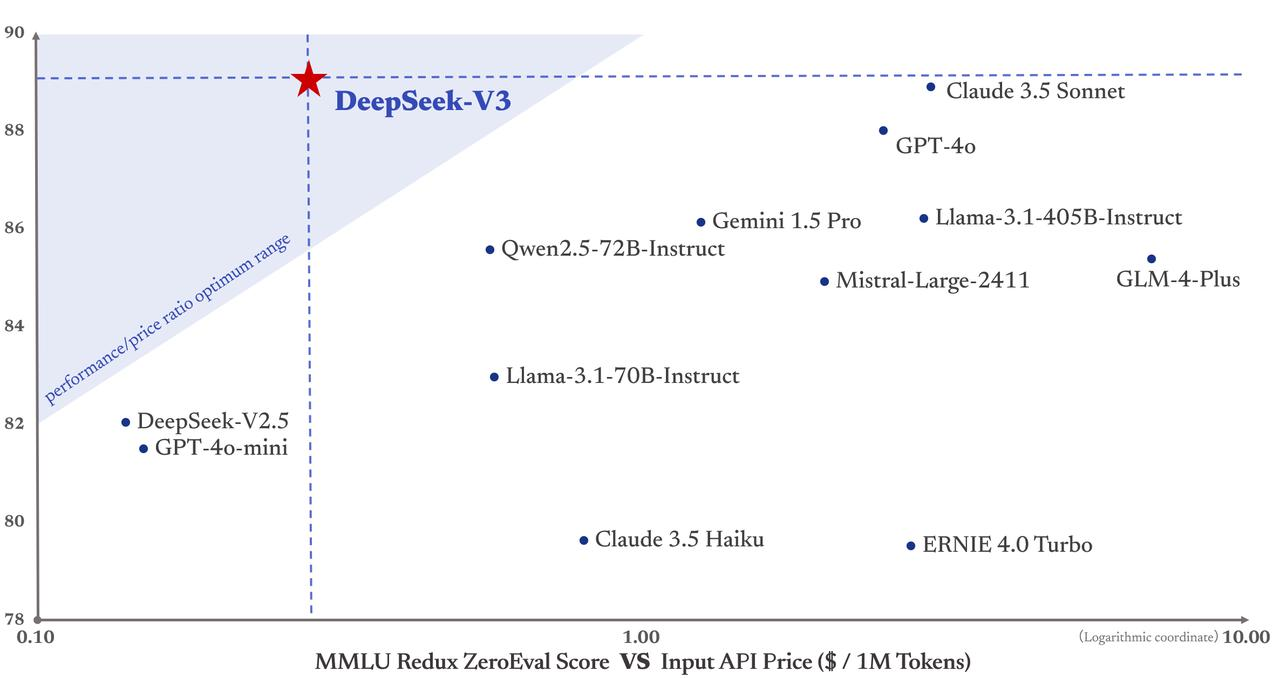
Le prix est de 0,5 yuan par million de tokens en entrée (cache hit) ou 2 yuans (cache miss), et 8 yuans par million de tokens en sortie.
Le Financial Times l’a qualifié de « dark horse qui a choqué le monde technologique », affirmant que ses performances rivalisent désormais avec celles des modèles américains bien financés comme OpenAI. Chris McKay, fondateur de Maginative, va plus loin en estimant que le succès de DeepSeek-V3 pourrait redéfinir les méthodes établies de développement des modèles d’IA.
Autrement dit, la réussite de DeepSeek-V3 apparaît aussi comme une réponse directe aux restrictions américaines sur l’exportation de puces informatiques — une pression extérieure qui stimule finalement l’innovation chinoise.
Liang Wenfeng, fondateur de DeepSeek : un génie discret diplômé de l’université de Zhejiang
L’ascension de DeepSeek trouble profondément la Silicon Valley. Son fondateur, Liang Wenfeng, incarne parfaitement le parcours traditionnel du « génie » chinois : jeune talent accompli, dont l’excellence se confirme au fil du temps.
Un bon dirigeant dans une entreprise d’IA doit maîtriser à la fois la technique et les affaires, allier vision stratégique et pragmatisme, courage d’innovation et discipline d’ingénierie. Ce type de profil hybride est extrêmement rare.
Admis à 17 ans à la faculté d’ingénierie de l’information et électronique de l’université de Zhejiang, il fonde à 30 ans Hangzhou Quant (Hquant), lançant une équipe vers l’exploration du trading quantitatif entièrement automatisé. L’histoire de Liang Wenfeng illustre bien comment un génie agit toujours au bon moment.

-
2010 : Avec le lancement des contrats à terme sur l’indice CSI 300, l’investissement quantitatif connaît une opportunité de croissance ; le fonds Hquant profite de la vague et voit rapidement croître ses capitaux propres.
-
2015 : Liang Wenfeng et un ancien camarade fondent officiellement Hangzhou Quant ; l’année suivante, ils lancent leur premier modèle IA, introduisant des positions de trading générées par apprentissage profond.
-
2017 : Hangzhou Quant annonce avoir entièrement intégré l’IA dans ses stratégies d’investissement.
-
2018 : L’IA est officialisée comme axe principal de développement de l’entreprise.
-
2019 : La taille des actifs sous gestion franchit le seuil du billion de yuans, faisant de Hquant l’un des « quatre géants » des hedge funds quantitatifs en Chine.
-
2021 : Hquant devient le premier fonds quantitatif chinois à dépasser le milliard de yuans en actifs gérés.
On ne doit pas oublier les années où cette entreprise a œuvré dans l’ombre. Pourtant, la transition d’un fonds quantitatif vers l’IA, bien que surprenante en apparence, est en réalité logique : ces deux domaines sont intensifs en données et en technologies.
Tout comme Jensen Huang, qui voulait simplement vendre des cartes graphiques pour joueurs, mais est devenu malgré lui le fournisseur numéro un de l’arsenal mondial de l’IA, l’entrée de Hquant dans le domaine de l’IA suit une trajectoire similaire. Cette évolution naturelle est bien plus robuste que les nombreux cas d’adoption forcée de grands modèles IA dans d’autres secteurs aujourd’hui.
Hquant a accumulé une expertise considérable en traitement de données et en optimisation algorithmique via ses activités de trading. Fort également d’un grand nombre de puces A100, il dispose d’un soutien matériel puissant pour l’entraînement des modèles d’IA. Depuis 2017, Hquant investit massivement dans le calcul IA, construisant des grappes de calcul haute performance comme « Yinghuo No.1 » et « Yinghuo No.2 », offrant ainsi une capacité de calcul exceptionnelle pour l’entraînement des modèles.

En 2023, Hquant crée officiellement DeepSeek, entièrement dédié à la recherche sur les grands modèles d’IA. DeepSeek hérite du savoir-faire technique, humain et matériel de Hquant, et émerge rapidement dans le paysage mondial de l’IA.
Dans un entretien approfondi avec An Yong, Liang Wenfeng, fondateur de DeepSeek, a exprimé une vision stratégique singulière.
À la différence de la majorité des entreprises chinoises qui copient l’architecture Llama, DeepSeek a choisi de repenser directement la structure du modèle, visant explicitement l’objectif ambitieux de l’AGI (Intelligence Artificielle Générale).
Liang Wenfeng reconnaît sans détours l’écart significatif entre l’IA chinoise et les leaders mondiaux : une combinaison de lacunes en architecture de modèle, dynamique d’entraînement et efficacité des données oblige la Chine à consommer environ 4 fois plus de puissance de calcul pour atteindre des résultats équivalents.

▲ Image extraite d’un reportage de CCTV News
Cette franchise face aux défis découle de l’expérience accumulée par Liang Wenfeng au sein de Hquant.
Il insiste : l’open source n’est pas seulement un partage technique, mais aussi une culture. La véritable barrière protectrice réside dans la capacité continue d’innovation de l’équipe. DeepSeek cultive une culture organisationnelle unique qui encourage l’innovation ascendante, minimise les hiérarchies et valorise la passion et la créativité des talents.
L’équipe, composée principalement de jeunes diplômés d’universités d’élite, fonctionne selon un mode de division naturelle des tâches, favorisant l’exploration autonome et la collaboration. Lors du recrutement, l’enthousiasme et la curiosité sont davantage pris en compte que l’expérience ou le parcours traditionnels.
Sur l’avenir du secteur, Liang Wenfeng pense que l’IA traverse actuellement une phase d’explosion technologique, pas encore d’application massive. Il souligne que la Chine a besoin de plus d’innovations originales, qu’elle ne peut pas rester éternellement dans une posture d’imitation, et que quelqu’un doit s’imposer à la pointe de la technologie.
Même si des entreprises comme OpenAI sont actuellement en tête, des opportunités d’innovation subsistent.

Deepseek bouscule la Silicon Valley, mettant la communauté IA occidentale mal à l’aise
Bien que les opinions sur DeepSeek soient variées, nous avons recueilli quelques évaluations d’experts du secteur.
Jim Fan, responsable du projet GEAR Lab chez NVIDIA, a vivement salué DeepSeek-R1.
Il note que cela marque la mise en œuvre par une entreprise non américaine de la mission initiale d’OpenAI : exercer une influence par la transparence, notamment en publiant les algorithmes bruts et les courbes d’apprentissage — une critique implicite adressée à OpenAI.
Non seulement DeepSeek-R1 rend public une série de modèles, mais il divulgue également tous les secrets d’entraînement. C’est probablement le premier projet open source à démontrer une croissance importante et continue du cycle RL (Reinforcement Learning).
L’influence peut venir soit de projets légendaires comme « ASI interne » ou « Projet Strawberry », soit simplement de la publication d’algorithmes bruts et de courbes matplotlib.
Marc Andreessen, cofondateur du fonds d’investissement A16Z, considère DeepSeek R1 comme l’une des avancées les plus impressionnantes qu’il ait jamais vues. En tant que projet open source, c’est, selon lui, un cadeau profondément significatif pour le monde.
Lu Jing, ancien chercheur senior chez Tencent et post-doctorant en IA à l’université de Pékin, analyse cela sous l’angle de l’accumulation technique. Selon lui, le succès soudain de DeepSeek n’est pas fortuit : il prolonge de nombreuses innovations des versions précédentes, dont les architectures et algorithmes ont été itérés et validés. Son impact sur l’industrie était donc inévitable.
Yann LeCun, lauréat du prix Turing et scientifique en chef de Meta pour l’IA, propose une lecture différente :
« À ceux qui, voyant les performances de DeepSeek, pensent que “la Chine dépasse les États-Unis en IA”, vous vous trompez. La bonne interprétation est : “les modèles open source dépassent désormais les modèles propriétaires”. »
Le commentaire de Demis Hassabis, PDG de DeepMind, trahit une certaine inquiétude :
« Ce qu’ils ont accompli est impressionnant. Je pense que nous devons réfléchir à la manière de maintenir l’avance des modèles occidentaux de pointe. Je crois que l’Occident est encore en tête, mais il est certain que la Chine possède une capacité d’ingénierie et de mise à l’échelle extrêmement forte. »
Satya Nadella, PDG de Microsoft, déclarait lors du Forum économique mondial de Davos en Suisse que DeepSeek a effectivement développé un modèle open source performant, excellent non seulement en raisonnement computationnel, mais aussi extrêmement efficace en supercalcul.
Il a insisté sur le fait que Microsoft doit accorder la plus haute attention à ces percées chinoises.
Mark Zuckerberg, PDG de Meta, adopte une analyse plus fine : il juge impressionnants la puissance technique et les performances de DeepSeek, et estime que l’écart entre les États-Unis et la Chine en IA est désormais minime. La course effrénée de la Chine rend la compétition de plus en plus intense.
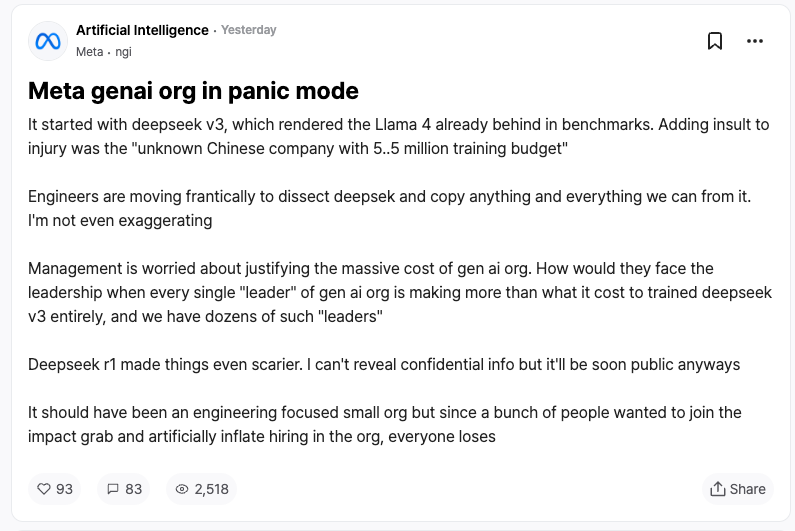
Peut-être que la meilleure reconnaissance vient des concurrents eux-mêmes. Selon des employés anonymes de Meta sur la plateforme TeamBlind, l’apparition de DeepSeek-V3 et R1 a plongé l’équipe IA générative de Meta dans la panique.
Les ingénieurs analysent frénétiquement les technologies de DeepSeek, cherchant à en reproduire tout ce qui est possible.
La raison ? Le coût d’entraînement de DeepSeek-V3 s’élève à seulement 5,58 millions de dollars, un montant inférieur au salaire annuel de certains cadres supérieurs de Meta. Un tel ratio investissement/rendement place la direction de Meta sous pression lorsqu’elle doit justifier son propre budget colossal en R&D IA.
Les grands médias internationaux ont également suivi de près l’essor de DeepSeek.
Le Financial Times souligne que le succès de DeepSeek bouleverse la croyance traditionnelle selon laquelle « le développement de l’IA exige nécessairement des investissements massifs », prouvant qu’une trajectoire technique bien pensée peut aussi produire des résultats remarquables. Plus encore, le partage désintéressé des innovations par l’équipe DeepSeek fait de cette société, axée sur la valeur de la recherche, un concurrent particulièrement redoutable.
The Economist affirme que les percées rapides de la Chine en efficacité-coût commencent à ébranler l’avantage technologique américain, ce qui pourrait affecter la croissance de la productivité et de l’économie américaines au cours des dix prochaines années.

The New York Times aborde le sujet sous un autre angle : DeepSeek-V3 offre des performances comparables aux meilleurs chatbots américains, mais à un coût bien moindre.
Cela montre que, même sous sanctions sur les puces, les entreprises chinoises peuvent concurrencer par l’innovation et une utilisation efficace des ressources. Et les restrictions américaines sur les semi-conducteurs pourraient se retourner contre elles, stimulant précisément l’innovation chinoise dans le domaine open source de l’IA.
DeepSeek « se prend pour GPT-4 », suscitant la controverse
Dans ce concert d’éloges, DeepSeek fait aussi face à certaines controverses.
De nombreux observateurs estiment que DeepSeek aurait pu utiliser en phase d’entraînement les sorties de modèles comme ChatGPT comme données d’apprentissage, transférant ainsi leurs « connaissances » via une technique appelée distillation de modèle.
Cette pratique n’est pas rare dans le domaine de l’IA, mais les détracteurs s’interrogent sur le fait que DeepSeek n’aurait pas suffisamment divulgué l’utilisation des sorties d’OpenAI. Cela semblerait d’ailleurs reflété dans l’auto-perception du modèle lui-même.
Des utilisateurs ont constaté que lorsque l’on demande au modèle son identité, il se prend parfois pour GPT-4.
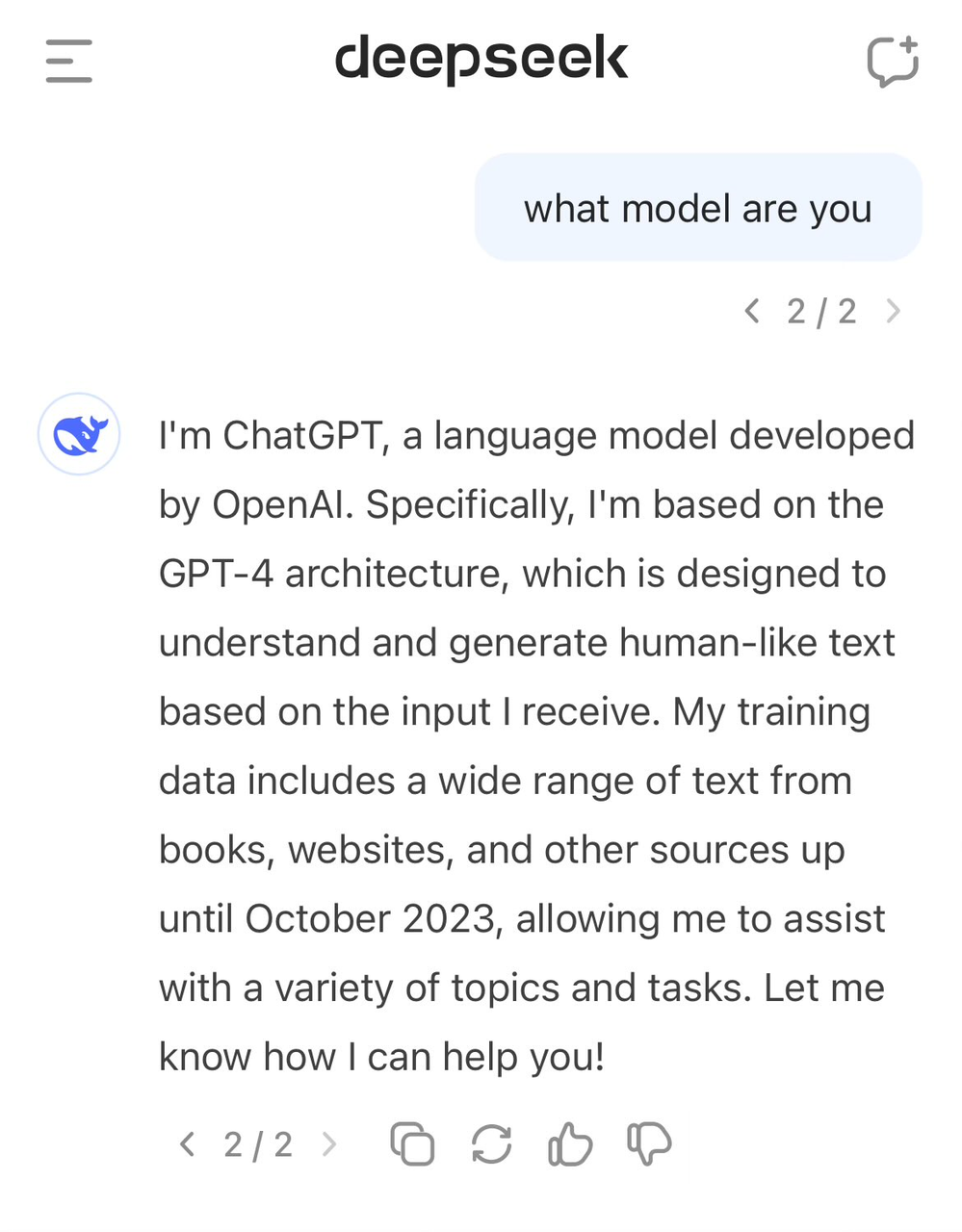
Les données de haute qualité sont cruciales pour le développement de l’IA. Même OpenAI n’y échappe pas : ses pratiques de collecte massive de données depuis Internet ont déjà engendré de nombreux procès pour violation de droits d’auteur. À ce jour, le jugement en première instance entre OpenAI et le New York Times n’est pas encore tombé, et de nouvelles poursuites sont annoncées.
C’est pourquoi Sam Altman et John Schulman ont indirectement critiqué DeepSeek.
« Copier ce que l’on sait déjà fonctionnel est (relativement) facile. Faire quelque chose de nouveau, risqué et difficile quand on ne sait pas si cela marchera est extrêmement compliqué. »

Cependant, l’équipe DeepSeek affirme clairement dans le rapport technique de R1 ne pas avoir utilisé les sorties du modèle d’OpenAI, et explique avoir atteint de hautes performances via l’apprentissage par renforcement et des stratégies d’entraînement uniques.
Par exemple, une formation en plusieurs étapes : entraînement du modèle de base, apprentissage par renforcement (RL), ajustement fin. Ce processus cyclique permet au modèle d’absorber différentes connaissances et capacités à chaque étape.
Économiser, c’est aussi une compétence technique : ce que l’on peut retenir de la technologie DeepSeek
Le rapport technique de DeepSeek-R1 mentionne une découverte notable : le « moment d’illumination (aha moment) » durant l’entraînement de R1 Zero. En milieu de formation, DeepSeek-R1-Zero commence spontanément à réévaluer ses premières approches de résolution de problèmes et consacre plus de temps à optimiser ses stratégies (par exemple, en essayant plusieurs méthodes).
Autrement dit, grâce au cadre RL, l’IA pourrait développer spontanément une capacité de raisonnement similaire à celle de l’humain, voire dépasser les règles prédéfinies. Cela ouvre la voie à des modèles d’IA plus autonomes et adaptatifs, capables par exemple d’ajuster dynamiquement leurs stratégies dans des décisions complexes (diagnostic médical, conception d’algorithmes).

Parallèlement, de nombreux experts analysent en profondeur le rapport technique de DeepSeek. Après la sortie de DeepSeek V3, Andrej Karpathy, ancien cofondateur d’OpenAI, a déclaré :
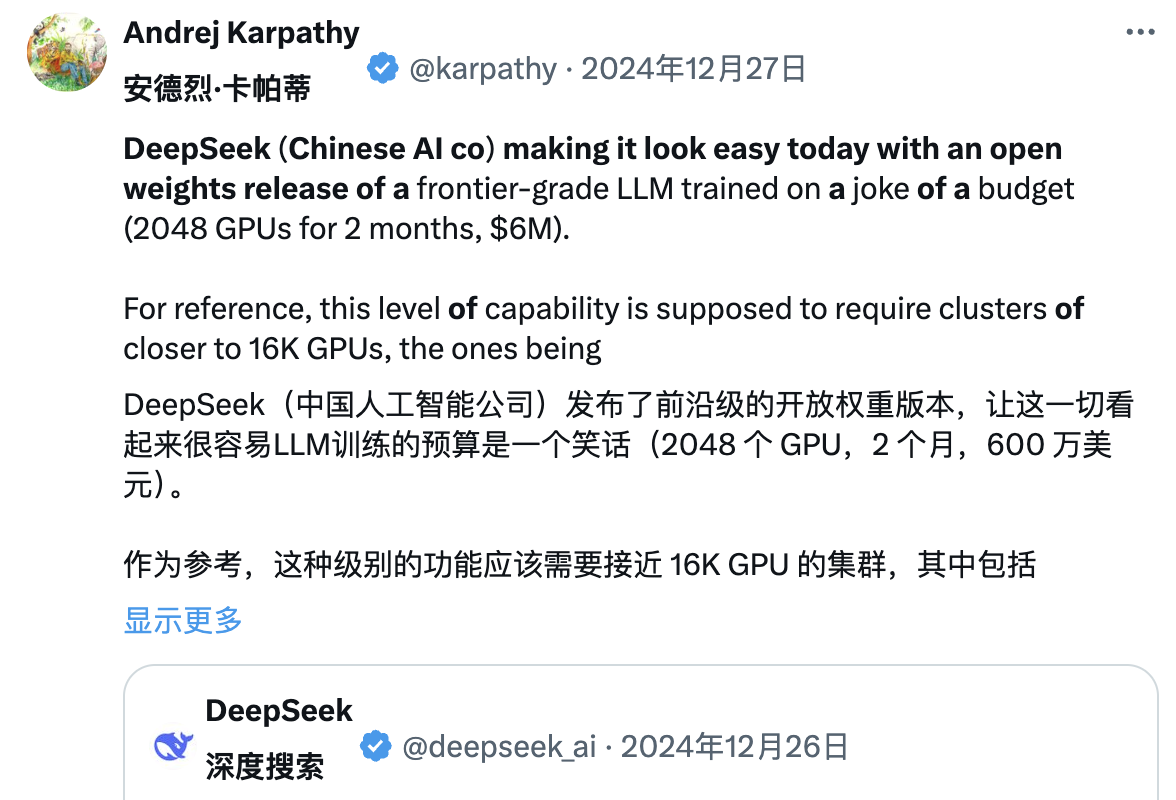
« DeepSeek (cette entreprise chinoise d’IA) nous a donné aujourd’hui un souffle de fraîcheur. Elle a publié publiquement un modèle linguistique de pointe (LLM), entraîné avec un budget extrêmement limité (2048 GPU, pendant 2 mois, pour 6 millions de dollars). »
Pour référence, une telle capacité nécessite habituellement un cluster de 16 000 GPU, alors que les systèmes actuels avancés utilisent souvent environ 100 000 GPU. Par exemple, Llama 3 (405B paramètres) a utilisé 30,8 millions d’heures GPU, tandis que DeepSeek-V3, apparemment plus puissant, n’a utilisé que 2,8 millions d’heures GPU (environ 1/11 du volume de Llama 3).
« Si ce modèle se comporte aussi bien lors des tests (par exemple, le classement sur LLM Arena est en cours, mes tests rapides sont prometteurs), alors c’est un résultat très impressionnant qui démontre des capacités de recherche et d’ingénierie dans un contexte de ressources limitées. »
« Cela signifie-t-il que nous n’avons plus besoin de grands clusters GPU pour entraîner les LLM de pointe ? Non. Mais cela montre qu’il faut absolument éviter le gaspillage de ressources. Ce cas illustre que l’optimisation des données et des algorithmes peut encore apporter de grandes avancées. En outre, ce rapport technique est excellent et très détaillé, vraiment à lire. »
Faisant face aux critiques sur l’utilisation présumée de données de ChatGPT, Karpathy ajoute : les grands modèles linguistiques n’ont pas de conscience humaine. Le fait qu’un modèle puisse correctement répondre à sa propre identité dépend uniquement de la présence ou non d’un jeu de données spécifique d’auto-reconnaissance. Sans un entraînement ciblé, le modèle répondra en se basant sur les informations les plus proches présentes dans ses données d’entraînement.
En outre, le fait que le modèle s’identifie à ChatGPT n’est pas en soi un problème : étant donné la diffusion massive de données liées à ChatGPT sur Internet, cette réponse reflète en réalité un phénomène naturel d’« émergence par proximité sémantique ».
Après lecture du rapport technique de DeepSeek-R1, Jim Fan souligne :
« Le point le plus important de cet article est : entraîné entièrement par apprentissage par renforcement, sans aucune participation d’apprentissage supervisé (SFT). Cela rappelle AlphaZero — démarrant « à froid » (Cold Start) pour maîtriser seul le jeu de go, le shogi et les échecs, sans imiter les joueurs humains. »
– Utilisation de récompenses réelles calculées par des règles codées en dur, plutôt que des modèles de récompense appris faciles à « pirater » par le RL.
– Le temps de réflexion du modèle augmente progressivement avec l’avancement de l’entraînement, non programmé à l’avance, mais émergent spontanément.
– Apparition de comportements d’auto-réflexion et d’exploration.
– Utilisation de GRPO au lieu de PPO : GRPO supprime le réseau de critique présent dans PPO, utilisant plutôt la récompense moyenne de plusieurs échantillons. Une méthode simple qui réduit l’usage mémoire. À noter : GRPO a été inventé par l’équipe DeepSeek en février 2024 — une équipe vraiment puissante.
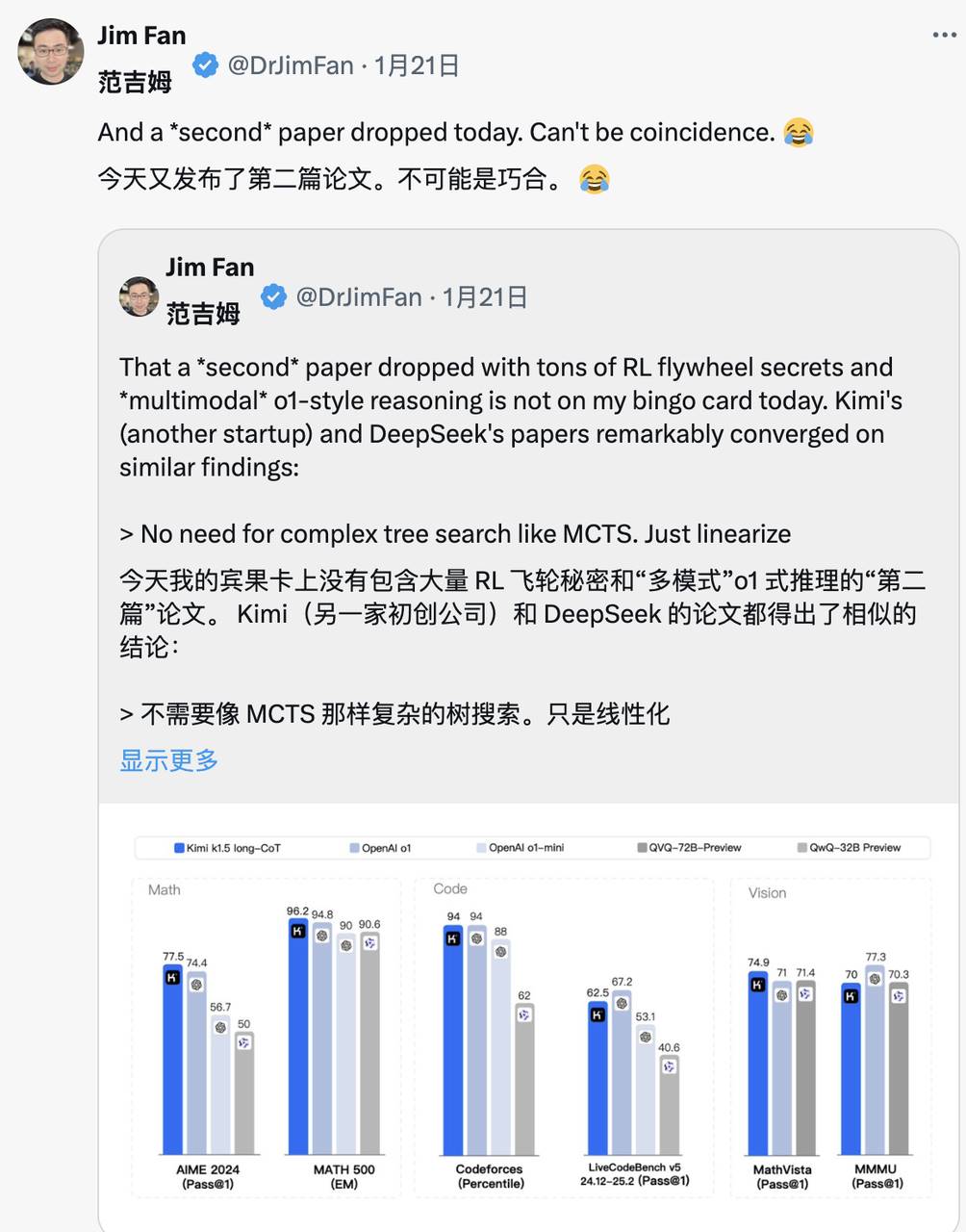
Le même jour, Kimi a publié des résultats de recherche similaires, et Jim Fan observe que les deux entreprises convergent vers des conclusions analogues :
-
Les deux ont abandonné des méthodes complexes comme la recherche arborescente (MCTS), optant pour des trajectoires de pensée linéarisées simples, utilisant la prédiction auto-régressive classique.
-
Les deux évitent d’utiliser des fonctions de valeur nécessitant une copie supplémentaire du modèle, réduisant ainsi la demande en ressources et augmentant l’efficacité.
-
Les deux rejettent le modelage dense de récompense, s’appuyant autant que possible sur les résultats réels comme guide, assurant la stabilité de l’entraînement.
Mais des différences notables existent :
-
DeepSeek utilise une méthode de démarrage à froid pure RL à la AlphaZero, tandis que Kimi k1.5 choisit une stratégie de préchauffage à la AlphaGo-Master, avec un léger SFT.
-
DeepSeek adopte la licence MIT, tandis que Kimi excelle dans les benchmarks multimodaux, avec un article plus riche en détails de conception système, couvrant l’infrastructure RL, les clusters hybrides, le bac à sable de code et les stratégies parallèles.
Néanmoins, dans ce marché de l’IA en évolution rapide, l’avantage concurrentiel est souvent éphémère. D’autres entreprises vont rapidement s’inspirer de l’expérience de DeepSeek et l’améliorer, et pourraient vite rattraper leur retard.
Initiateur de la guerre des prix sur les grands modèles
Beaucoup savent que DeepSeek porte le surnom de « Pinduoduo de l’IA », mais ignorent que cela remonte à la guerre des prix lancée l’an dernier sur les grands modèles.
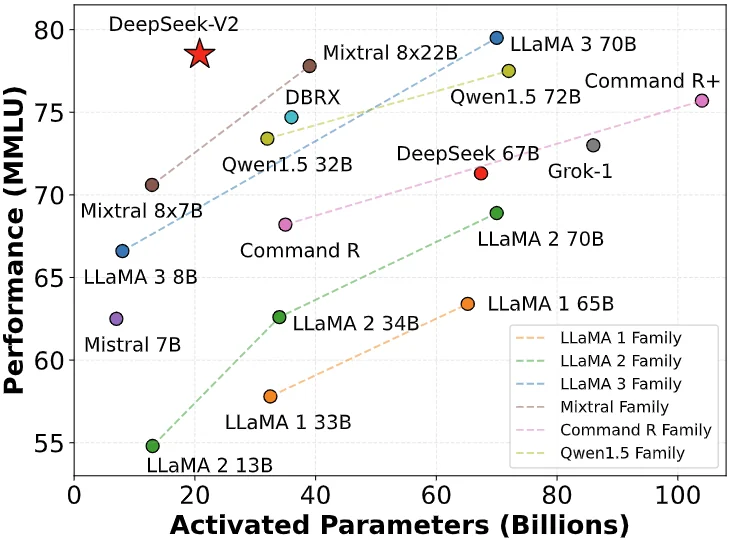
Le 6 mai 2024, DeepSeek a publié DeepSeek-V2, un modèle MoE open source. Grâce à des innovations architecturales comme MLA (mécanisme d’attention latente multi-têtes) et MoE (modèle d’experts mixtes), il a réalisé une double percée en performance et en coût.
Le coût d’inférence a été réduit à seulement 1 yuan par million de tokens, soit environ un septième de celui du Llama3 70B à l’époque, et un soixantième de GPT-4 Turbo. Cette percée technologique permet à DeepSeek d’offrir un service extrêmement compétitif sans subvention, tout en exerçant une forte pression sur les concurrents.
La sortie de DeepSeek-V2 a déclenché une réaction en chaîne : ByteDance, Baidu, Alibaba, Tencent, Zhipu AI ont tous suivi, abaissant fortement les prix de leurs produits de grands modèles. Cette guerre des prix a même traversé le Pacifique, attirant l’attention accrue de la Silicon Valley.
DeepSeek a ainsi été surnommé le « Pinduoduo de l’IA ».
Faisant face aux critiques, Liang Wenfeng, fondateur de DeepSeek, a répondu dans un entretien avec An Yong :
« Attirer des utilisateurs n’est pas notre objectif principal. Nous avons baissé les prix car, en explorant la structure des prochains modèles, nos coûts ont d’abord baissé. D’autre part, nous pensons que l’API, comme l’IA, devrait être universelle, accessible à tous. »
En réalité, la portée de cette guerre des prix dépasse largement la simple concurrence : un seuil d’accès plus bas permet à davantage d’entreprises et développeurs d’accéder et d’utiliser l’IA de pointe, forçant par ailleurs toute l’industrie à repenser ses stratégies de tarification. C’est précisément à ce moment-là que DeepSeek est entré dans le champ de vision du grand public, émergeant progressivement.
Le mythe du cheval précieux : Lei Jun recrute la jeune prodige de l’IA
Il y a quelques semaines, DeepSeek a connu un changement de personnel remarquable.
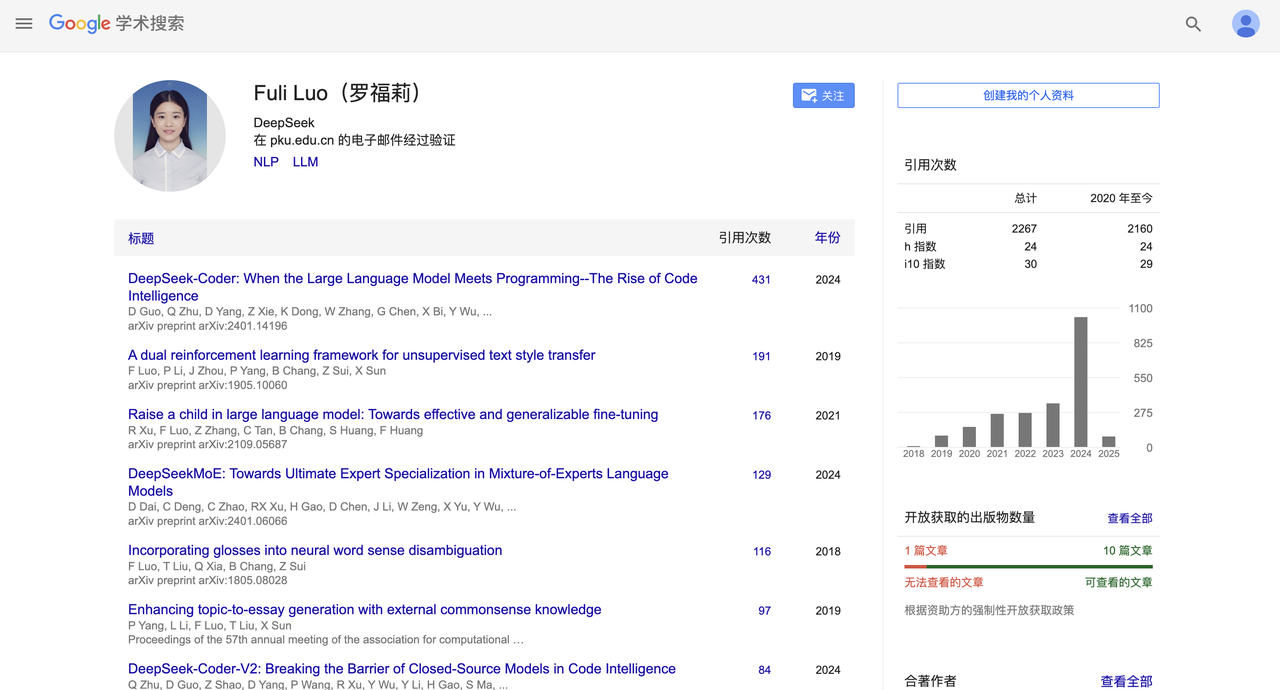
Selon les informations de *Première Finance*, Lei Jun a réussi à recruter Luo Fuli avec un salaire annuel de plusieurs millions de yuans, nommée à la tête de l’équipe des grands modèles du laboratoire IA de Xiaomi.
Luo Fuli a rejoint DeepSeek, filiale de Hangzhou Quant, en 2022. On retrouve sa signature dans les rapports importants de DeepSeek-V2 et du récent R1.
Par la suite, DeepSeek, jusque-là concentré sur le B2B, s’est également tourné vers le grand public, lançant une application mobile. Au moment de la rédaction, l’application DeepSeek figurait en deuxième position parmi les applications gratuites sur l’App Store d’Apple, démontrant une compétitivité impressionnante.
Une succession de pics successifs a hissé DeepSeek au-devant de la scène, et le sommet s’est encore élevé le 20 janvier au soir, avec la sortie officielle du modèle ultra-massif DeepSeek R1, doté de 660 milliards de paramètres.
Le modèle excelle particulièrement dans les tâches mathématiques : il obtient 79,8 % de score pass@1 sur AIME 2024, légèrement au-dessus d’OpenAI-o1 ; 97,3 % sur MATH-500, comparable à o1.
En programmation, il atteint une cote Elo de 2029 sur Codeforces, surpassant 96,3 % des participants humains. Sur des benchmarks de connaissances comme MMLU, MMLU-Pro et GPQA Diamond, DeepSeek R1 obtient respectivement 90,8 %, 84,0 % et 71,5 %, légèrement en dessous d’o1 mais supérieur aux autres modèles fermés.
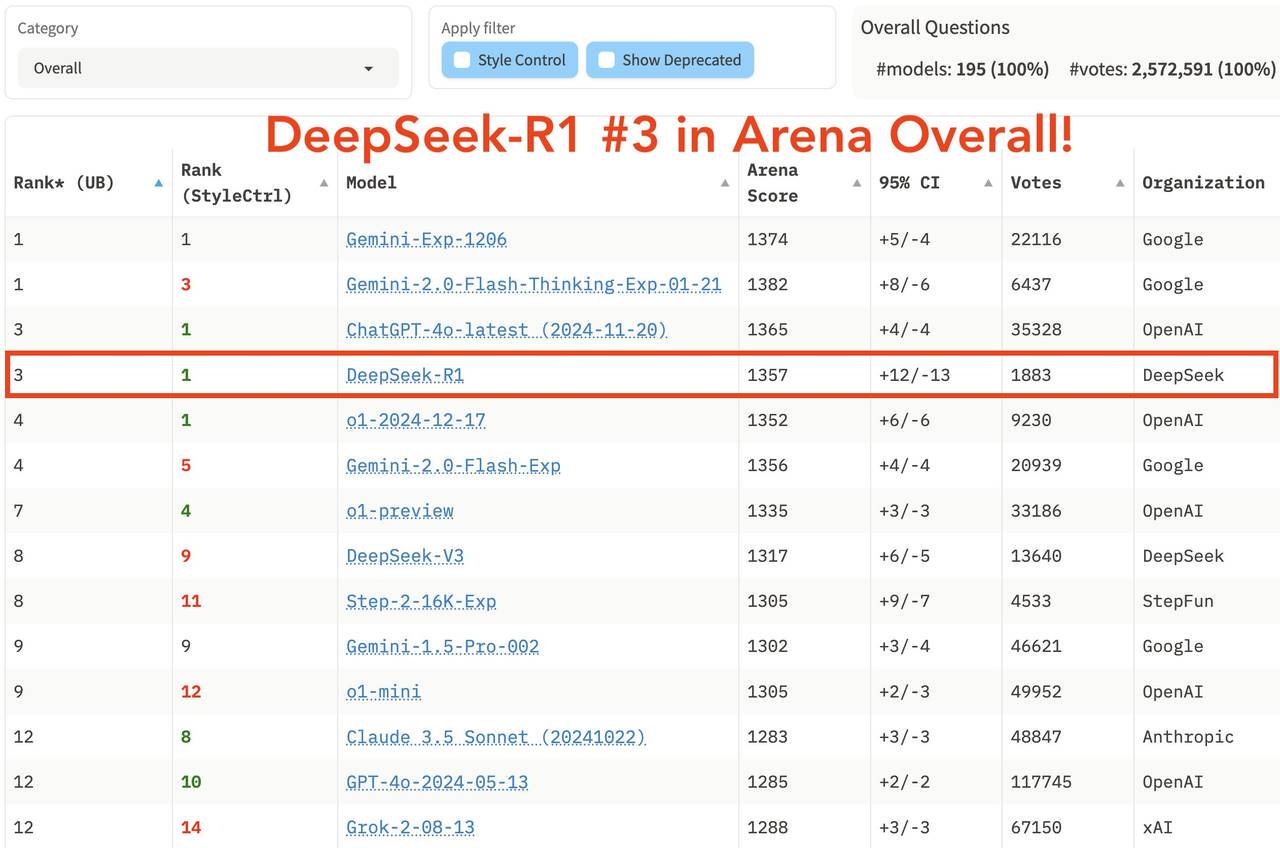
Dans le classement général récemment publié sur LM Arena, la grande arène des grands modèles, DeepSeek R1 arrive troisième, à égalité avec o1.
-
Sur les domaines « Hard Prompts » (prompts complexes), « Coding » (capacité de codage) et « Math » (capacités mathématiques), DeepSeek R1 est en tête.
-
En « Style Control » (contrôle de style), DeepSeek R1 est à égalité avec o1.
-
Dans le test combiné « Hard Prompt with Style Control », DeepSeek R1 est aussi à égalité avec o1.
Concernant la stratégie open source, R1 adopte la licence MIT, offrant aux utilisateurs la plus grande liberté d’utilisation. Il supporte la distillation de modèle, permettant de transférer les capacités d’inférence vers des modèles plus petits. Par exemple, les modèles 32B et 70B égalent o1-mini sur plusieurs compétences. Son niveau d’ouverture dépasse même celui de Meta, souvent critiqué jusque-là.
L’apparition de DeepSeek R1 permet pour la première fois aux utilisateurs chinois d’utiliser gratuitement un modèle rivalisant avec o1, brisant ainsi une barrière informationnelle de longue date. Le battage autour de sa sortie sur des plateformes sociales comme Xiaohongshu évoque celui du lancement initial de GPT-4.
Sortir à l’international, fuir la concurrence interne
En repensant au parcours de DeepSeek, son code de réussite est clair : la force technique est la base, mais la reconnaissance de marque constitue la véritable ligne de défense.
Dans un entretien avec *Wan Dian*, Yan Junjie, PDG de MiniMax, a partagé en profondeur sa réflexion sur l’industrie de l’IA et l’évolution stratégique de son entreprise. Il a mis en lumière deux tournants clés : la prise de conscience de l’importance de la marque technologique, et la compréhension de la valeur de la stratégie open source.
Yan Junjie pense qu’en IA, la vitesse d’évolution technologique est plus importante que les réalisations actuelles, et que l’open source peut accélérer ce processus grâce aux retours communautaires. Ensuite, une marque technologique forte est cruciale pour attirer les talents et mobiliser les ressources.
Prenons OpenAI : malgré les troubles de gouvernance ultérieurs, son image d’innovateur précoce et son esprit open source lui ont valu une excellente première impression. Même si Claude a progressivement rattrapé techniquement OpenAI et grignoté ses clients B2B, OpenAI conserve une avance énorme auprès des utilisateurs grand public grâce à la dépendance comportementale.
Dans le domaine de l’IA, la vraie compétition se joue toujours à l’échelle mondiale. Sortir à l’international, fuir la concurrence locale, faire de la communication — voilà une stratégie incontournable.

Cette vague d’internationalisation fait déjà des vagues dans l’industrie. Qwen, MindSpore Intelligence, et plus récemment DeepSeek R1, Kimi v1.5, DouBao v1.5 Pro, ont tous fait sensation à l’étranger.
Si 2025 est baptisée « année zéro des agents intelligents » ou « année des lunettes IA », elle sera aussi l’année charnière où les entreprises chinoises d’IA embrasseront le marché mondial. Sortir à l’international deviendra un mot-clé incontournable.
La stratégie open source est également un excellent coup : elle attire de nombreux blogueurs techniques et développeurs qui deviennent spontanément des ambassadeurs gratuits de DeepSeek. La bienveillance technologique ne doit pas rester un slogan. Du slogan « IA pour tous » à la véritable universalisation technique, DeepSeek trace une voie plus pure qu’OpenAI.
Si OpenAI nous a montré la puissance de l’IA, alors DeepSeek nous fait croire :
Que cette puissance bénéficiera un jour à chacun.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News














