

DeepSeek dévoile son nouveau modèle : pourquoi fait-il trembler le monde de l'IA ?
2025.01.26
Partager versPartager sur Twitter Dédié à des analyses Web3 approfondies
Dédié à des analyses Web3 approfondies
Partager sur WeChat
Partager sur WeiboPartager sur WeChat
Partager le lien de l’article
Partager l’affiche visuelle
TechFlow SélectionTechFlow Sélection
DeepSeek dévoile son nouveau modèle : pourquoi fait-il trembler le monde de l'IA ?
DeepSeek-R1 a réussi, grâce à une méthode d'apprentissage par renforcement pur, à atteindre des performances comparables à celles des meilleurs modèles tels que GPT-4o et Claude Sonnet 3.5.
2025.01.26 - 08:50:26
DeepSeek
DeepSeek-R1 a réussi, grâce à une méthode d'apprentissage par renforcement pur, à atteindre des performances comparables à celles des meilleurs modèles tels que GPT-4o et Claude Sonnet 3.5.
Auteur invité de « L'avenir de l'IA » par Tencent Tech : Hao Boyang
Moins d'un mois après sa dernière percée, DeepSeek a de nouveau ébranlé la communauté mondiale de l'IA.
En décembre dernier, le modèle DeepSeek-V3 avait déjà suscité une onde de choc majeure dans le domaine de l’IA en offrant des performances comparables à celles des meilleurs modèles comme GPT-4o ou Claude Sonnet 3.5, tout en affichant un coût d’entraînement extrêmement bas. Tencent Tech avait alors publié une analyse approfondie de ce modèle, expliquant de manière simple et claire les fondements technologiques qui lui permettaient d’allier faible coût et haute efficacité.
Mais cette fois-ci, c’est différent : le nouveau modèle lancé par DeepSeek, nommé DeepSeek-R1, ne se contente pas d’être économique — il marque aussi une avancée significative sur le plan technique, et surtout, il est entièrement open source.
Ce nouveau modèle poursuit la tradition d’un excellent rapport performance-prix, atteignant les performances de GPT-o1 avec seulement un dixième du coût.
De nombreux professionnels du secteur n’hésitent donc pas à proclamer que « DeepSeek succède à OpenAI », tandis qu’un nombre croissant d’observateurs s’intéresse particulièrement aux percées réalisées dans sa méthode d’entraînement.
Par exemple, Elvis, ancien chercheur chez Meta AI et auteur influent sur Twitter spécialisé dans les articles d’IA, a souligné que l’article scientifique sur DeepSeek-R1 était une véritable pépite, car il explore diverses méthodes pour améliorer le raisonnement des grands modèles linguistiques et révèle des phénomènes d’émergence nettement plus explicites.
 Yuchen Jin, une autre personnalité influente dans la communauté IA, considère quant à lui que la découverte décrite dans l’article — selon laquelle le modèle utilise une méthode pure de renforcement (RL) pour apprendre seul à raisonner et à s’auto-réfléchir — revêt une importance capitale.
Jim Fan, responsable du projet GEAR Lab chez NVIDIA, a également tweeté que DeepSeek-R1 utilisait des récompenses véridiques calculées par des règles codées en dur, évitant ainsi tout recours à des modèles d’apprentissage de récompense que la RL pourrait facilement truquer. Cette approche a permis l’émergence de comportements d’auto-réflexion et d’exploration autonome chez le modèle.
Et précisément parce que toutes ces découvertes essentielles ont été intégralement rendues publiques via l’open source de DeepSeek-R1, Jim Fan est allé jusqu’à dire que cela aurait dû être fait par OpenAI.
Yuchen Jin, une autre personnalité influente dans la communauté IA, considère quant à lui que la découverte décrite dans l’article — selon laquelle le modèle utilise une méthode pure de renforcement (RL) pour apprendre seul à raisonner et à s’auto-réfléchir — revêt une importance capitale.
Jim Fan, responsable du projet GEAR Lab chez NVIDIA, a également tweeté que DeepSeek-R1 utilisait des récompenses véridiques calculées par des règles codées en dur, évitant ainsi tout recours à des modèles d’apprentissage de récompense que la RL pourrait facilement truquer. Cette approche a permis l’émergence de comportements d’auto-réflexion et d’exploration autonome chez le modèle.
Et précisément parce que toutes ces découvertes essentielles ont été intégralement rendues publiques via l’open source de DeepSeek-R1, Jim Fan est allé jusqu’à dire que cela aurait dû être fait par OpenAI.
 Alors, quelle est exactement cette méthode RL pure dont ils parlent ? Et pourquoi le fameux « moment Aha » observé prouve-t-il que l’IA développe une capacité émergente ? Plus encore, que signifie cette innovation majeure de DeepSeek-R1 pour l’avenir du domaine de l’IA ?
Alors, quelle est exactement cette méthode RL pure dont ils parlent ? Et pourquoi le fameux « moment Aha » observé prouve-t-il que l’IA développe une capacité émergente ? Plus encore, que signifie cette innovation majeure de DeepSeek-R1 pour l’avenir du domaine de l’IA ?
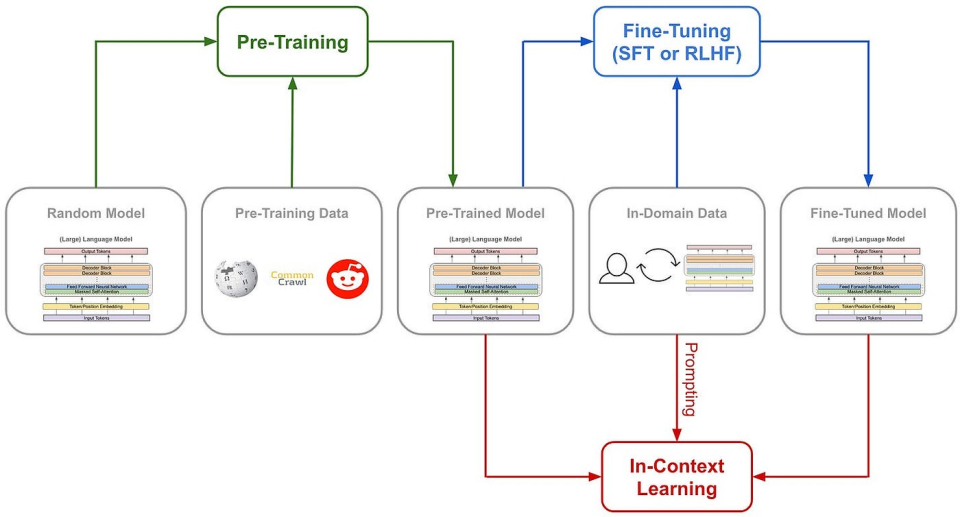 (Le cheminement traditionnel d’entraînement des modèles)
DeepSeek-R1 Zero choisit, quant à lui, une voie inédite : celle du renforcement « pur ». Il abandonne complètement les templates préétablis de chaîne de pensée (Chain of Thought) et le fine-tuning supervisé (SFT), s’appuyant uniquement sur des signaux simples de récompense/punition pour optimiser le comportement du modèle.
C’est comme enseigner à un enfant prodige à résoudre des problèmes sans lui donner aucun exemple ni aucune instruction, simplement en lui faisant essayer constamment et en lui fournissant un retour d’expérience.
DeepSeek-R1 Zero dispose d’un système de récompense extrêmement simple, conçu pour stimuler les capacités de raisonnement de l’IA.
Il repose sur deux règles :
1. **Récompense d’exactitude** : Un modèle d’évaluation vérifie si la réponse est correcte. Bonne réponse = points positifs ; mauvaise réponse = points négatifs. L’évaluation est simple : par exemple, pour un problème mathématique à résultat déterministe, le modèle doit fournir sa réponse finale entre balises spécifiées (comme <answer> et </answer>) ; pour un problème de programmation, un compilateur génère un feedback à partir de cas-tests prédéfinis.
2. **Récompense de format** : Un modèle de format exige que le raisonnement du modèle soit inscrit entre les balises <think> et </think>. Si le modèle ne respecte pas cette règle, il perd des points ; s’il la suit, il en gagne.
Afin d’observer précisément l’évolution naturelle du modèle durant l’apprentissage par renforcement (RL), DeepSeek a même volontairement limité les instructions système à cette seule contrainte de format, évitant ainsi tout biais lié au contenu — par exemple, forcer le modèle à adopter un raisonnement réflexif ou à généraliser une stratégie spécifique.
(Le cheminement traditionnel d’entraînement des modèles)
DeepSeek-R1 Zero choisit, quant à lui, une voie inédite : celle du renforcement « pur ». Il abandonne complètement les templates préétablis de chaîne de pensée (Chain of Thought) et le fine-tuning supervisé (SFT), s’appuyant uniquement sur des signaux simples de récompense/punition pour optimiser le comportement du modèle.
C’est comme enseigner à un enfant prodige à résoudre des problèmes sans lui donner aucun exemple ni aucune instruction, simplement en lui faisant essayer constamment et en lui fournissant un retour d’expérience.
DeepSeek-R1 Zero dispose d’un système de récompense extrêmement simple, conçu pour stimuler les capacités de raisonnement de l’IA.
Il repose sur deux règles :
1. **Récompense d’exactitude** : Un modèle d’évaluation vérifie si la réponse est correcte. Bonne réponse = points positifs ; mauvaise réponse = points négatifs. L’évaluation est simple : par exemple, pour un problème mathématique à résultat déterministe, le modèle doit fournir sa réponse finale entre balises spécifiées (comme <answer> et </answer>) ; pour un problème de programmation, un compilateur génère un feedback à partir de cas-tests prédéfinis.
2. **Récompense de format** : Un modèle de format exige que le raisonnement du modèle soit inscrit entre les balises <think> et </think>. Si le modèle ne respecte pas cette règle, il perd des points ; s’il la suit, il en gagne.
Afin d’observer précisément l’évolution naturelle du modèle durant l’apprentissage par renforcement (RL), DeepSeek a même volontairement limité les instructions système à cette seule contrainte de format, évitant ainsi tout biais lié au contenu — par exemple, forcer le modèle à adopter un raisonnement réflexif ou à généraliser une stratégie spécifique.
 (Les instructions système de R1 Zero)
Grâce à ce système de règles minimaliste, l’IA s’améliore elle-même sous la règle GRPO (Group Relative Policy Optimization), par auto-échantillonnage et comparaison.
Le mode GRPO est relativement simple : il calcule le gradient de stratégie par comparaison relative entre échantillons d’un même groupe, réduisant efficacement l’instabilité de l’entraînement tout en accélérant l’apprentissage.
En termes simples, imaginez un professeur posant une question, puis demandant au modèle de répondre plusieurs fois. Chaque réponse est notée selon les règles ci-dessus, et le modèle est mis à jour selon la logique « maximiser les notes, éviter les mauvaises notes ».
Le processus ressemble à ceci :
Entrée de la question → Génération de plusieurs réponses par le modèle → Évaluation par le système de règles → Calcul de l’avantage relatif par GRPO → Mise à jour du modèle.
Cette méthode directe présente plusieurs avantages marqués. Premièrement, une meilleure efficacité d’entraînement, pouvant être accomplie en moins de temps. Deuxièmement, une réduction notable de la consommation de ressources, grâce à l’élimination du SFT et des modèles complexes de récompense, ce qui diminue fortement les besoins en puissance de calcul.
Plus important encore, cette méthode permet vraiment au modèle d’apprendre à penser — et même d’apprendre par « illumination soudaine ».
(Les instructions système de R1 Zero)
Grâce à ce système de règles minimaliste, l’IA s’améliore elle-même sous la règle GRPO (Group Relative Policy Optimization), par auto-échantillonnage et comparaison.
Le mode GRPO est relativement simple : il calcule le gradient de stratégie par comparaison relative entre échantillons d’un même groupe, réduisant efficacement l’instabilité de l’entraînement tout en accélérant l’apprentissage.
En termes simples, imaginez un professeur posant une question, puis demandant au modèle de répondre plusieurs fois. Chaque réponse est notée selon les règles ci-dessus, et le modèle est mis à jour selon la logique « maximiser les notes, éviter les mauvaises notes ».
Le processus ressemble à ceci :
Entrée de la question → Génération de plusieurs réponses par le modèle → Évaluation par le système de règles → Calcul de l’avantage relatif par GRPO → Mise à jour du modèle.
Cette méthode directe présente plusieurs avantages marqués. Premièrement, une meilleure efficacité d’entraînement, pouvant être accomplie en moins de temps. Deuxièmement, une réduction notable de la consommation de ressources, grâce à l’élimination du SFT et des modèles complexes de récompense, ce qui diminue fortement les besoins en puissance de calcul.
Plus important encore, cette méthode permet vraiment au modèle d’apprendre à penser — et même d’apprendre par « illumination soudaine ».
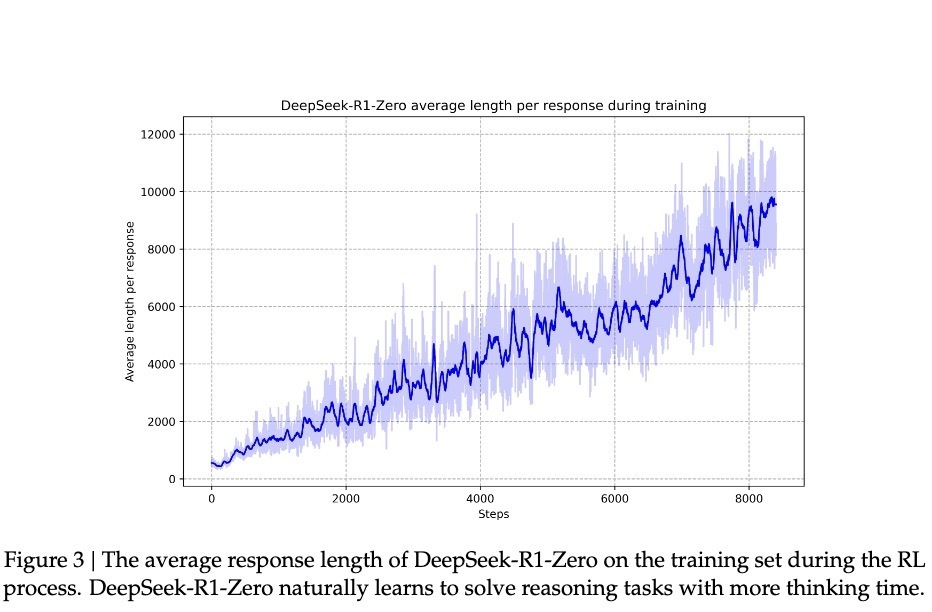 Grâce à cette montée en compétence associée à des « déclics », R1-Zero a vu son taux de réussite grimper de 15,6 % à 71,0 % dans la prestigieuse compétition mathématique AIME. Et lorsque le modèle tente plusieurs fois la même question, ce taux atteint même 86,7 %. Il ne s’agit pas ici d’un apprentissage mécanique — les problèmes d’AIME exigent une intuition mathématique profonde et une pensée créative, bien au-delà de l’application rigide de formules. Une telle progression suppose nécessairement une véritable capacité de raisonnement.
Grâce à cette montée en compétence associée à des « déclics », R1-Zero a vu son taux de réussite grimper de 15,6 % à 71,0 % dans la prestigieuse compétition mathématique AIME. Et lorsque le modèle tente plusieurs fois la même question, ce taux atteint même 86,7 %. Il ne s’agit pas ici d’un apprentissage mécanique — les problèmes d’AIME exigent une intuition mathématique profonde et une pensée créative, bien au-delà de l’application rigide de formules. Une telle progression suppose nécessairement une véritable capacité de raisonnement.
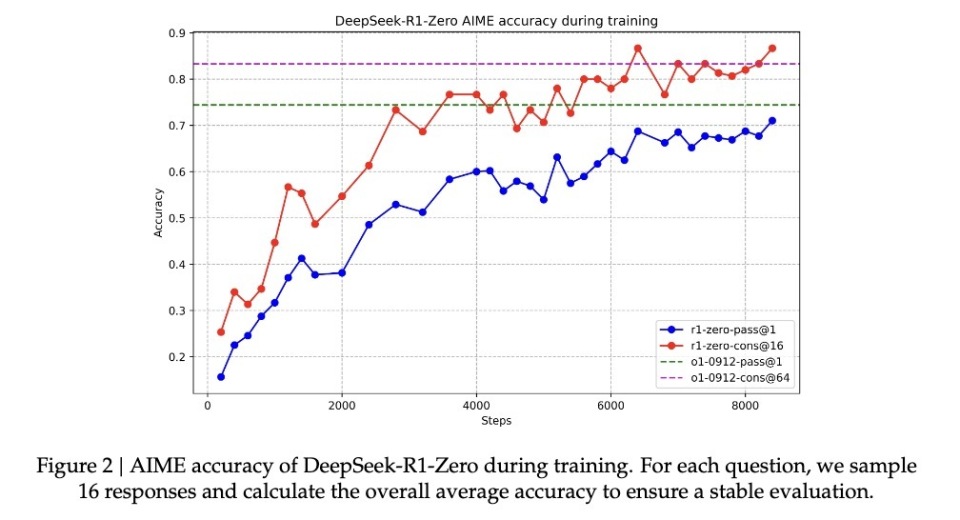 Une autre preuve solide que le modèle a effectivement acquis une capacité de raisonnement réside dans la régulation naturelle de la longueur de ses réponses selon la complexité du problème. Ce comportement adaptatif indique que le modèle n’applique pas un gabarit figé, mais comprend réellement la difficulté de la tâche, mobilisant proportionnellement plus de « temps de réflexion ». Tout comme un humain ajustera naturellement son effort entre une addition simple et une intégrale complexe, R1-Zero manifeste une intelligence analogue.
Peut-être la preuve la plus convaincante est-elle sa capacité de transfert (transfer learning). Sur la plateforme de compétition de programmation Codeforces, totalement différente, R1-Zero a atteint un niveau supérieur à 96,3 % des participants humains. Cette performance transversale montre que le modèle ne mémorise pas des astuces sectorielles, mais maîtrise une forme de raisonnement universel.
Une autre preuve solide que le modèle a effectivement acquis une capacité de raisonnement réside dans la régulation naturelle de la longueur de ses réponses selon la complexité du problème. Ce comportement adaptatif indique que le modèle n’applique pas un gabarit figé, mais comprend réellement la difficulté de la tâche, mobilisant proportionnellement plus de « temps de réflexion ». Tout comme un humain ajustera naturellement son effort entre une addition simple et une intégrale complexe, R1-Zero manifeste une intelligence analogue.
Peut-être la preuve la plus convaincante est-elle sa capacité de transfert (transfer learning). Sur la plateforme de compétition de programmation Codeforces, totalement différente, R1-Zero a atteint un niveau supérieur à 96,3 % des participants humains. Cette performance transversale montre que le modèle ne mémorise pas des astuces sectorielles, mais maîtrise une forme de raisonnement universel.
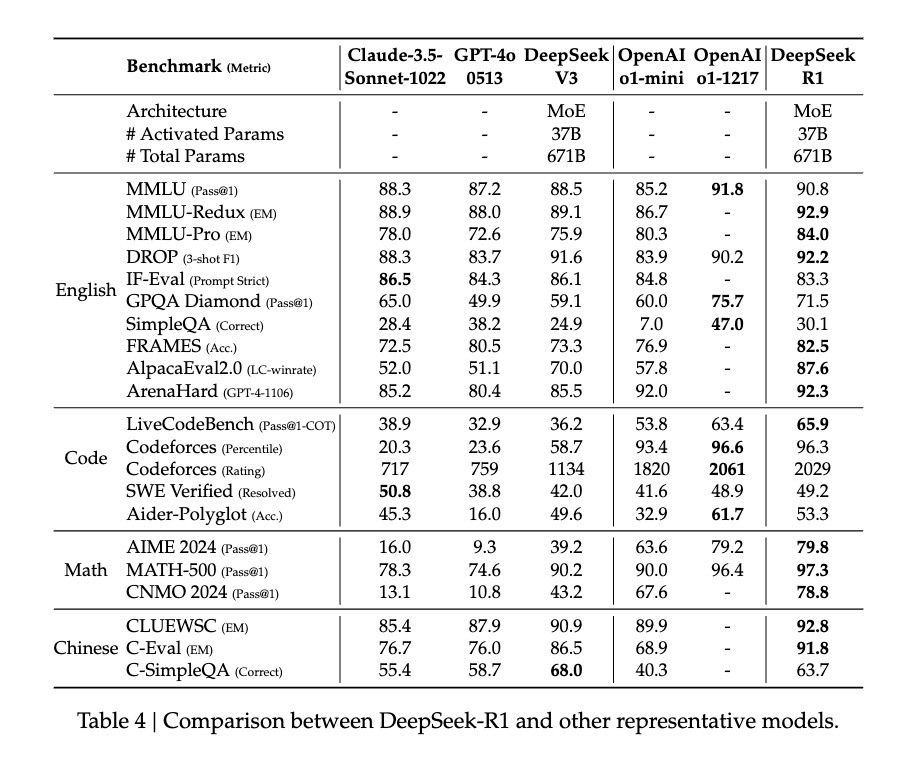 Pourtant, le potentiel de DeepSeek-R1 Zero semble encore plus grand. Lorsqu’on applique un mécanisme de vote majoritaire sur AIME 2024, son taux de précision atteint 86,7 % — une performance supérieure même à celle d’OpenAI o1-0912. Ce trait selon lequel « plusieurs tentatives améliorent la précision » suggère que R1-Zero maîtrise peut-être un cadre fondamental de raisonnement, plutôt que de simplement mémoriser des schémas de solution. Les données montrent une performance stable trans-domaine, de MATH-500 à AIME, puis à GSM8K, particulièrement sur les problèmes complexes nécessitant une pensée créative. Cette robustesse générale indique que R1-Zero a probablement développé une capacité de raisonnement de base, en contraste frappant avec les modèles optimisés pour des tâches spécifiques.
Ainsi, même s’il s’exprime mal, DeepSeek-R1 Zero serait peut-être le véritable « génie » qui comprend réellement le raisonnement.
Pourtant, le potentiel de DeepSeek-R1 Zero semble encore plus grand. Lorsqu’on applique un mécanisme de vote majoritaire sur AIME 2024, son taux de précision atteint 86,7 % — une performance supérieure même à celle d’OpenAI o1-0912. Ce trait selon lequel « plusieurs tentatives améliorent la précision » suggère que R1-Zero maîtrise peut-être un cadre fondamental de raisonnement, plutôt que de simplement mémoriser des schémas de solution. Les données montrent une performance stable trans-domaine, de MATH-500 à AIME, puis à GSM8K, particulièrement sur les problèmes complexes nécessitant une pensée créative. Cette robustesse générale indique que R1-Zero a probablement développé une capacité de raisonnement de base, en contraste frappant avec les modèles optimisés pour des tâches spécifiques.
Ainsi, même s’il s’exprime mal, DeepSeek-R1 Zero serait peut-être le véritable « génie » qui comprend réellement le raisonnement.
Yuchen Jin, une autre personnalité influente dans la communauté IA, considère quant à lui que la découverte décrite dans l’article — selon laquelle le modèle utilise une méthode pure de renforcement (RL) pour apprendre seul à raisonner et à s’auto-réfléchir — revêt une importance capitale.
Jim Fan, responsable du projet GEAR Lab chez NVIDIA, a également tweeté que DeepSeek-R1 utilisait des récompenses véridiques calculées par des règles codées en dur, évitant ainsi tout recours à des modèles d’apprentissage de récompense que la RL pourrait facilement truquer. Cette approche a permis l’émergence de comportements d’auto-réflexion et d’exploration autonome chez le modèle.
Et précisément parce que toutes ces découvertes essentielles ont été intégralement rendues publiques via l’open source de DeepSeek-R1, Jim Fan est allé jusqu’à dire que cela aurait dû être fait par OpenAI.
Alors, quelle est exactement cette méthode RL pure dont ils parlent ? Et pourquoi le fameux « moment Aha » observé prouve-t-il que l’IA développe une capacité émergente ? Plus encore, que signifie cette innovation majeure de DeepSeek-R1 pour l’avenir du domaine de l’IA ?
La formule la plus simple, retour au renforcement pur
Après la sortie d’o1, le renforcement du raisonnement est devenu la méthode la plus surveillée du secteur. Généralement, lors de l’entraînement d’un modèle, on applique une méthode fixe pour améliorer ses capacités de raisonnement. Mais l’équipe DeepSeek a expérimenté simultanément trois voies technologiques radicalement différentes pendant l’entraînement de R1 : l’apprentissage par renforcement direct (R1-Zero), un entraînement progressif en plusieurs étapes (R1), et la distillation de modèle — et les trois ont réussi. Les deux dernières méthodes contiennent des éléments hautement innovants, ayant un impact profond sur l’industrie. Cependant, ce qui enthousiasme le plus, c’est sans conteste la voie du renforcement direct. En effet, DeepSeek-R1 est le premier modèle à démontrer l’efficacité de cette approche. Commençons par rappeler la méthode traditionnelle d’entraînement des capacités de raisonnement : elle consiste généralement à injecter un grand nombre d’exemples de chaîne de pensée (Chain of Thought, COT) dans l’étape de SFT (fine-tuning supervisé), accompagnés de modèles complexes de récompense tels que les modèles de récompense de processus (PRM), afin d’inciter le modèle à raisonner étape par étape. On peut même intégrer des algorithmes comme la recherche arborescente Monte Carlo (MCTS) pour guider le modèle à explorer les meilleures solutions possibles parmi de nombreuses options.
(Le cheminement traditionnel d’entraînement des modèles)
DeepSeek-R1 Zero choisit, quant à lui, une voie inédite : celle du renforcement « pur ». Il abandonne complètement les templates préétablis de chaîne de pensée (Chain of Thought) et le fine-tuning supervisé (SFT), s’appuyant uniquement sur des signaux simples de récompense/punition pour optimiser le comportement du modèle.
C’est comme enseigner à un enfant prodige à résoudre des problèmes sans lui donner aucun exemple ni aucune instruction, simplement en lui faisant essayer constamment et en lui fournissant un retour d’expérience.
DeepSeek-R1 Zero dispose d’un système de récompense extrêmement simple, conçu pour stimuler les capacités de raisonnement de l’IA.
Il repose sur deux règles :
1. **Récompense d’exactitude** : Un modèle d’évaluation vérifie si la réponse est correcte. Bonne réponse = points positifs ; mauvaise réponse = points négatifs. L’évaluation est simple : par exemple, pour un problème mathématique à résultat déterministe, le modèle doit fournir sa réponse finale entre balises spécifiées (comme <answer> et </answer>) ; pour un problème de programmation, un compilateur génère un feedback à partir de cas-tests prédéfinis.
2. **Récompense de format** : Un modèle de format exige que le raisonnement du modèle soit inscrit entre les balises <think> et </think>. Si le modèle ne respecte pas cette règle, il perd des points ; s’il la suit, il en gagne.
Afin d’observer précisément l’évolution naturelle du modèle durant l’apprentissage par renforcement (RL), DeepSeek a même volontairement limité les instructions système à cette seule contrainte de format, évitant ainsi tout biais lié au contenu — par exemple, forcer le modèle à adopter un raisonnement réflexif ou à généraliser une stratégie spécifique.
(Les instructions système de R1 Zero)
Grâce à ce système de règles minimaliste, l’IA s’améliore elle-même sous la règle GRPO (Group Relative Policy Optimization), par auto-échantillonnage et comparaison.
Le mode GRPO est relativement simple : il calcule le gradient de stratégie par comparaison relative entre échantillons d’un même groupe, réduisant efficacement l’instabilité de l’entraînement tout en accélérant l’apprentissage.
En termes simples, imaginez un professeur posant une question, puis demandant au modèle de répondre plusieurs fois. Chaque réponse est notée selon les règles ci-dessus, et le modèle est mis à jour selon la logique « maximiser les notes, éviter les mauvaises notes ».
Le processus ressemble à ceci :
Entrée de la question → Génération de plusieurs réponses par le modèle → Évaluation par le système de règles → Calcul de l’avantage relatif par GRPO → Mise à jour du modèle.
Cette méthode directe présente plusieurs avantages marqués. Premièrement, une meilleure efficacité d’entraînement, pouvant être accomplie en moins de temps. Deuxièmement, une réduction notable de la consommation de ressources, grâce à l’élimination du SFT et des modèles complexes de récompense, ce qui diminue fortement les besoins en puissance de calcul.
Plus important encore, cette méthode permet vraiment au modèle d’apprendre à penser — et même d’apprendre par « illumination soudaine ».
Apprendre par soi-même, dans le « déclic » du raisonnement
Comment savoir que le modèle a réellement appris à « penser » selon cette méthode extrêmement « primitive » ? Un cas fascinant est documenté dans l’article : lorsqu’il traitait une expression mathématique complexe √a - √(a + x) = x, le modèle s’est soudain interrompu en disant : « Wait, wait. Wait. That’s an aha moment I can flag here » (« Attends, attends… c’est un moment “aha” que je peux signaler ici »), puis a repris toute sa démarche de résolution. Ce comportement similaire à une illumination humaine est entièrement spontané, non prédéfini. Ces moments de déclic marquent souvent un bond qualitatif dans les capacités cognitives du modèle. Selon les recherches de DeepSeek, les progrès du modèle ne sont pas uniformes. Pendant l’apprentissage par renforcement, la longueur des réponses connaît des augmentations soudaines et significatives, appelées « points de saut », qui coïncident souvent avec un changement radical dans la stratégie de résolution. Ce schéma rappelle fortement l’illumination soudaine après une longue réflexion humaine, suggérant une rupture cognitive profonde.
Grâce à cette montée en compétence associée à des « déclics », R1-Zero a vu son taux de réussite grimper de 15,6 % à 71,0 % dans la prestigieuse compétition mathématique AIME. Et lorsque le modèle tente plusieurs fois la même question, ce taux atteint même 86,7 %. Il ne s’agit pas ici d’un apprentissage mécanique — les problèmes d’AIME exigent une intuition mathématique profonde et une pensée créative, bien au-delà de l’application rigide de formules. Une telle progression suppose nécessairement une véritable capacité de raisonnement.
Une autre preuve solide que le modèle a effectivement acquis une capacité de raisonnement réside dans la régulation naturelle de la longueur de ses réponses selon la complexité du problème. Ce comportement adaptatif indique que le modèle n’applique pas un gabarit figé, mais comprend réellement la difficulté de la tâche, mobilisant proportionnellement plus de « temps de réflexion ». Tout comme un humain ajustera naturellement son effort entre une addition simple et une intégrale complexe, R1-Zero manifeste une intelligence analogue.
Peut-être la preuve la plus convaincante est-elle sa capacité de transfert (transfer learning). Sur la plateforme de compétition de programmation Codeforces, totalement différente, R1-Zero a atteint un niveau supérieur à 96,3 % des participants humains. Cette performance transversale montre que le modèle ne mémorise pas des astuces sectorielles, mais maîtrise une forme de raisonnement universel.
Un génie brillant mais mal articulé
Bien que R1-Zero démontre des capacités de raisonnement stupéfiantes, les chercheurs ont vite identifié un problème sérieux : ses processus de pensée sont souvent incompréhensibles pour les humains. L’article reconnaît honnêtement que ce modèle, entraîné uniquement par renforcement, souffre de « poor readability » (mauvaise lisibilité) et de « language mixing » (mélange de langues). Ce phénomène est compréhensible : R1-Zero optimise son comportement uniquement via des signaux de récompense, sans jamais avoir vu d’exemple humain servant de « réponse type ». C’est comme un enfant prodige qui invente sa propre méthode de résolution : efficace, mais incapable de l’expliquer clairement. Durant sa résolution, il peut alterner plusieurs langues ou développer un langage singulier, rendant son raisonnement difficile à suivre. Pour corriger ce défaut, l’équipe a développé une version améliorée, DeepSeek-R1. En introduisant des données de « cold-start » (démarrage à froid) plus traditionnelles et un processus d’entraînement en plusieurs étapes, R1 conserve une forte capacité de raisonnement tout en apprenant à exprimer sa pensée de façon compréhensible pour les humains. C’est comme associer à l’enfant prodige un coach en communication, qui lui apprend à exprimer clairement ses idées. Après cette mise au point, DeepSeek-R1 atteint des performances comparables, voire supérieures à OpenAI o1 dans certains domaines. Sur le benchmark MATH, R1 obtient 77,5 % de précision contre 77,3 % pour o1 ; sur le test plus exigeant AIME 2024, R1 atteint 71,3 %, surpassant o1 (71,0 %). En programmation, il atteint 2441 points sur Codeforces, dépassant 96,3 % des participants humains.
Pourtant, le potentiel de DeepSeek-R1 Zero semble encore plus grand. Lorsqu’on applique un mécanisme de vote majoritaire sur AIME 2024, son taux de précision atteint 86,7 % — une performance supérieure même à celle d’OpenAI o1-0912. Ce trait selon lequel « plusieurs tentatives améliorent la précision » suggère que R1-Zero maîtrise peut-être un cadre fondamental de raisonnement, plutôt que de simplement mémoriser des schémas de solution. Les données montrent une performance stable trans-domaine, de MATH-500 à AIME, puis à GSM8K, particulièrement sur les problèmes complexes nécessitant une pensée créative. Cette robustesse générale indique que R1-Zero a probablement développé une capacité de raisonnement de base, en contraste frappant avec les modèles optimisés pour des tâches spécifiques.
Ainsi, même s’il s’exprime mal, DeepSeek-R1 Zero serait peut-être le véritable « génie » qui comprend réellement le raisonnement.
Le renforcement pur, une raccourci inattendu vers l’AGI ?
La sortie de DeepSeek-R1 attire tant l’attention sur la méthode de renforcement pur car elle ouvre littéralement une nouvelle voie d’évolution pour l’IA. R1-Zero — un modèle entièrement entraîné par renforcement — dévoile des capacités de raisonnement généralisées impressionnantes. Il excelle non seulement aux concours de mathématiques. Plus encore, R1-Zero ne fait pas semblant de penser : il développe véritablement une forme de raisonnement autonome. Cette découverte pourrait bouleverser notre compréhension de l’apprentissage automatique : les méthodes traditionnelles d’entraînement auraient pu commettre une erreur fondamentale — vouloir à tout prix faire imiter aux IA la pensée humaine. L’industrie doit reconsidérer le rôle du learning supervisé dans le développement de l’IA. Grâce au renforcement pur, les systèmes d’IA semblent capables de développer des capacités natives de résolution de problèmes, sans être enfermés dans des cadres de solutions prédéfinis. Certes, R1-Zero souffre d’un manque criant de lisibilité dans ses sorties. Mais ce « défaut » même pourrait justement attester de l’originalité de sa cognition. Comme un enfant prodige qui invente sa propre méthode sans pouvoir l’expliquer en langage courant. Cela nous rappelle que l’intelligence artificielle générale (AGI) pourrait exiger des modes de pensée radicalement différents de ceux des humains. Voilà ce qu’est le véritable apprentissage par renforcement. Comme le théorisait le célèbre pédagogue Piaget : la vraie compréhension naît d’une construction active, non d’une réception passive.Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News
Ajouter aux favoris
Partager sur les réseaux sociaux
Auteur
腾讯科技














