

IA x Web3 : Explorer le paysage émergent et le potentiel futur
TechFlow SélectionTechFlow Sélection
IA x Web3 : Explorer le paysage émergent et le potentiel futur
L'IA et la Web3 semblent être des technologies indépendantes, reposant sur des principes fondamentalement différents et remplissant des fonctions distinctes. Toutefois, une analyse approfondie révèle que ces deux technologies pourraient compenser mutuellement leurs compromis, leurs avantages uniques pouvant se compléter et s'amplifier réciproquement.
Rédaction : IOSG Ventures
Première partie
À première vue, l'IA et la Web3 semblent être des technologies indépendantes, fondées sur des principes radicalement différents et servant des fonctions distinctes. Pourtant, une analyse approfondie révèle qu'elles ont la possibilité de compenser mutuellement leurs compromis, leurs avantages uniques pouvant se compléter et s'amplifier. Balaji Srinivasan a brillamment exposé ce concept de complémentarité lors du sommet SuperAI, suscitant une comparaison détaillée sur la manière dont ces deux technologies interagissent.
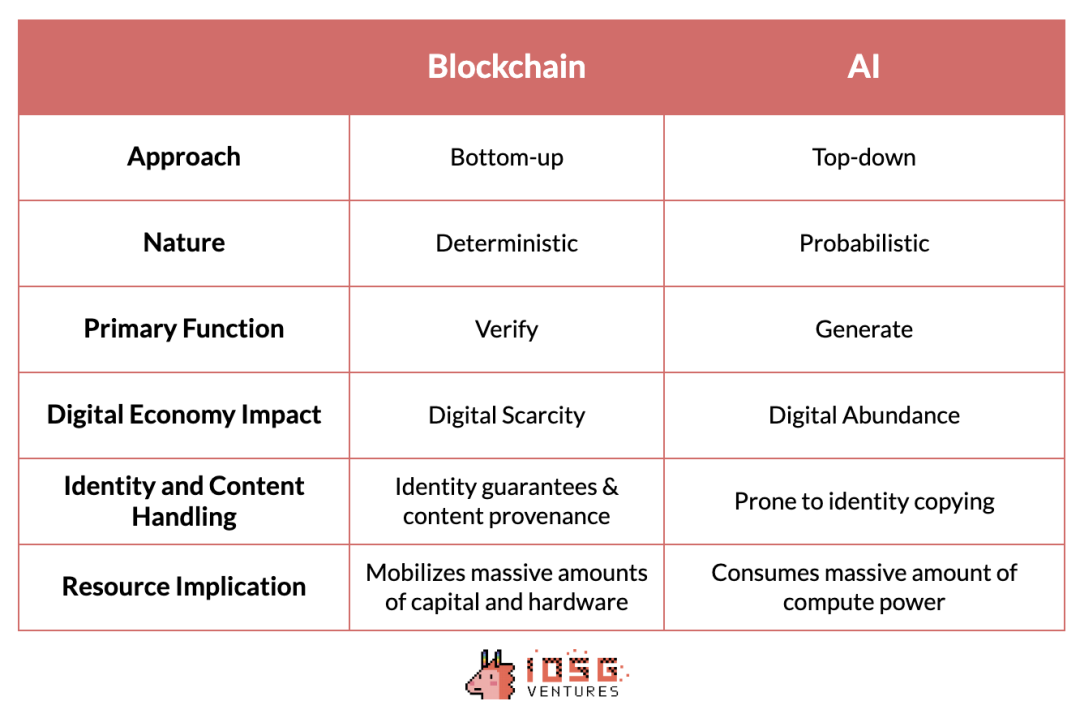
Les tokens reposent sur une approche ascendante, nés d'efforts décentralisés de cyberpunk anonymes, évoluant depuis plus de dix ans grâce à la collaboration de nombreux acteurs indépendants à travers le monde. En revanche, l'intelligence artificielle est développée selon une approche descendante, dominée par quelques géants technologiques qui dictent le rythme et les dynamiques du secteur, où les barrières à l'entrée sont davantage définies par l'intensité des ressources que par la complexité technique.
Ces deux technologies présentent également des natures fondamentalement différentes. Par essence, les tokens constituent des systèmes déterministes produisant des résultats inaltérables, tels que la prévisibilité des fonctions de hachage ou des preuves à connaissance nulle, en contraste marqué avec le caractère probabiliste et souvent imprévisible de l’intelligence artificielle.
De même, la cryptographie excelle dans la vérification, garantissant l’authenticité et la sécurité des transactions, et permettant de construire des processus et systèmes non fiables. L’IA, quant à elle, se concentre sur la génération, créant des contenus numériques riches. Toutefois, cette génération abondante pose des défis en matière de traçabilité des contenus et de prévention du vol d’identité.
Heureusement, les tokens proposent le concept opposé à la richesse numérique : la rareté numérique. Ils offrent des outils relativement matures pouvant être étendus à l’IA pour assurer la fiabilité de la provenance des contenus et éviter les usurpations d’identité.
Un avantage notable des tokens réside dans leur capacité à attirer massivement du matériel informatique et du capital vers des réseaux coordonnés au service d’un objectif spécifique. Cette capacité est particulièrement bénéfique pour l’IA, qui consomme d’énormes quantités de puissance de calcul. Mobiliser des ressources sous-utilisées afin d’offrir une puissance de calcul moins coûteuse peut considérablement améliorer l’efficacité de l’IA.
En comparant ces deux grandes technologies, nous ne pouvons qu’apprécier leurs contributions respectives, mais aussi percevoir comment elles peuvent ensemble ouvrir de nouvelles voies technologiques et économiques. Chaque technologie comble les lacunes de l’autre, créant ainsi un futur plus intégré et innovant. Dans cet article de blog, nous explorons le paysage émergent de l’industrie IA x Web3, en mettant l’accent sur certains nouveaux domaines verticaux naissants issus de leur croisement.
Source : IOSG Ventures
Deuxième partie
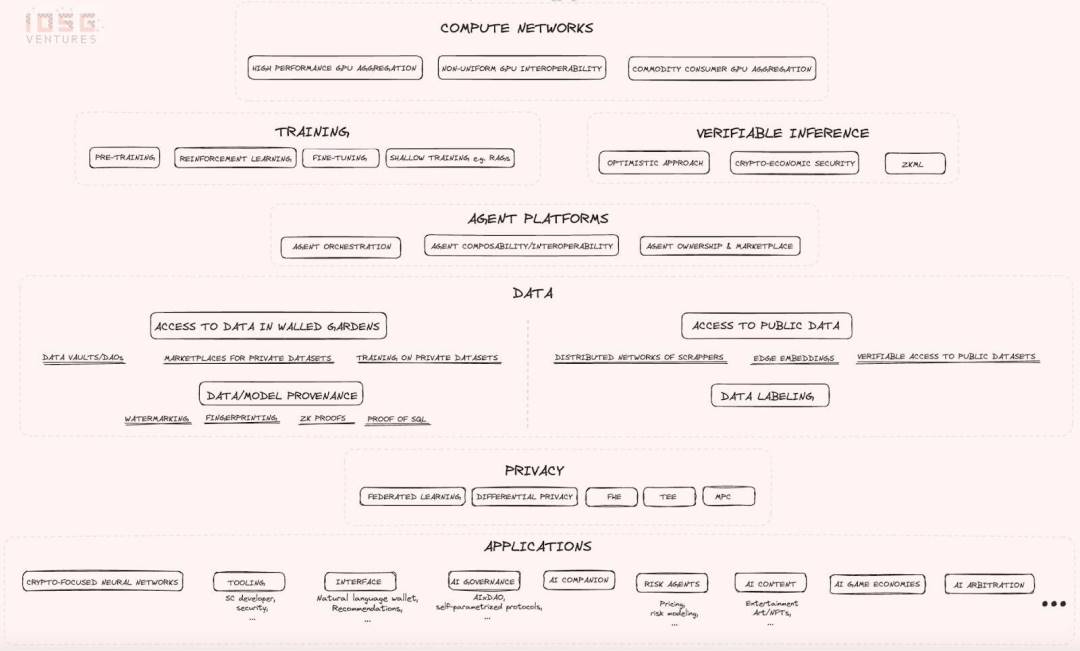
2.1 Réseaux de calcul
Le panorama sectoriel commence par les réseaux de calcul, qui cherchent à résoudre le problème de l’approvisionnement limité en GPU et tentent de réduire le coût du calcul selon diverses approches. Voici quelques éléments notables :
- Interopérabilité non uniforme des GPU : Une tentative très ambitieuse, comportant un risque technique élevé et une grande incertitude, mais dont le succès pourrait produire des résultats d’envergure et d’impact majeurs, rendant toutes les ressources de calcul interchangeables. L'idée consiste à construire des compilateurs et autres conditions préalables permettant d'insérer n'importe quelle ressource matérielle côté offre, tandis que, côté demande, les différences entre les GPU seraient entièrement abstraites, permettant à toute requête de calcul d'être routée vers n'importe quelle ressource disponible dans le réseau. Si cette vision se concrétise, cela réduirait fortement la dépendance actuelle des développeurs d'IA vis-à-vis du logiciel CUDA, dominant aujourd'hui totalement le secteur. Malgré les risques techniques élevés, de nombreux experts restent très sceptiques quant à la faisabilité de cette approche.
- Agrégation de GPU haute performance : Intègre les GPU les plus populaires au monde au sein d'un réseau distribué et sans autorisation, sans se soucier des problèmes d'interopérabilité entre ressources GPU hétérogènes.
- Agrégation de GPU grand public bas de gamme : Cible l'agrégation de GPU grand public aux performances inférieures, potentiellement disponibles dans des appareils domestiques, représentant les ressources les plus sous-utilisées côté offre. Elle s'adresse à ceux prêts à sacrifier performance et rapidité pour bénéficier d'un entraînement plus long mais moins coûteux.
2.2 Entraînement et inférence
Les réseaux de calcul servent principalement deux fonctions : l'entraînement et l'inférence. La demande pour ces réseaux provient de projets Web 2.0 et Web 3.0. Dans l'écosystème Web 3.0, des projets comme Bittensor utilisent les ressources de calcul pour ajuster des modèles. Concernant l'inférence, les projets Web 3.0 insistent sur la vérifiabilité des processus. Cette priorité a donné naissance à un nouveau segment vertical : l'inférence vérifiable, où des projets explorent comment intégrer l'inférence IA dans des contrats intelligents tout en respectant les principes de décentralisation.
2.3 Plateformes d'agents intelligents
Viennent ensuite les plateformes d'agents intelligents. Le diagramme souligne les problématiques centrales que les startups de cette catégorie doivent résoudre :
- Interopérabilité, découverte et communication entre agents : Capacité des agents à se découvrir mutuellement et à communiquer.
- Capacité de formation et gestion de clusters d'agents : Possibilité pour les agents de former des groupes et de gérer d'autres agents.
- Propriété et marché des agents IA : Offrir une notion de propriété et un marché pour les agents IA.
Ces fonctionnalités mettent en lumière l'importance cruciale de systèmes flexibles et modulaires capables de s'intégrer parfaitement à diverses applications blockchain et d'intelligence artificielle. Les agents IA pourraient transformer radicalement notre interaction avec internet. Nous pensons que ces agents s'appuieront sur des infrastructures existantes pour opérer. Nous envisageons que les agents IA dépendront de l'infrastructure pour :
- Exploiter des réseaux de scraping distribués pour accéder à des données web en temps réel
- Utiliser des canaux DeFi pour les paiements entre agents
- Exiger des dépôts économiques non seulement pour sanctionner les comportements inappropriés, mais aussi pour améliorer la découvrabilité des agents (en utilisant le dépôt comme signal économique dans le processus de découverte)
- Utiliser le consensus pour décider quels événements doivent entraîner une pénalité
- Des normes d'interopérabilité ouvertes et des cadres pour agents soutenant la construction de collectifs composites
- Évaluer les performances passées selon un historique de données immuable et sélectionner en temps réel les collectifs d'agents appropriés

Source : IOSG Ventures
2.4 Couche des données
Dans la convergence IA x Web3, les données constituent un élément central. Elles sont un actif stratégique dans la compétition autour de l’IA, formant avec les ressources de calcul une ressource clé. Pourtant, cette catégorie est souvent négligée, car l’attention de l’industrie se concentre majoritairement sur la couche calcul. En réalité, les primitives offrent de nombreuses directions de valeur intéressantes dans l’acquisition de données, principalement selon deux axes majeurs :
- Accès aux données publiques d’internet
- Accès aux données protégées
Accès aux données publiques d’internet : Cette direction vise à construire un réseau de robots d’indexation distribué capable de parcourir l’intégralité d’internet en quelques jours, obtenant ainsi des jeux de données massifs, ou d’accéder en temps réel à des données très spécifiques. Toutefois, indexer d’immenses volumes de données exige des besoins réseau très élevés, nécessitant au minimum plusieurs centaines de nœuds pour réaliser un travail significatif. Heureusement, Grass, un réseau distribué de nœuds de scraping, compte déjà plus de 2 millions de nœuds activement partageant leur bande passante internet, avec pour objectif d’indexer l’intégralité d’internet. Cela illustre le potentiel immense des incitations économiques à mobiliser des ressources précieuses.
Bien que Grass crée un terrain de jeu équitable pour les données publiques, le défi d’accéder aux données potentielles demeure — notamment l’accès aux jeux de données propriétaires. En effet, d’importantes quantités de données sensibles restent protégées par des mesures de confidentialité. De nombreuses startups exploitent désormais des outils cryptographiques permettant aux développeurs d’IA d’utiliser la structure fondamentale de données propriétaires pour concevoir et affiner des grands modèles linguistiques, tout en préservant la confidentialité des informations sensibles.
Les technologies telles que l’apprentissage fédéré, la confidentialité différentielle, les environnements d’exécution sécurisés (TEE), le chiffrement homomorphe complet et le calcul multipartite sécurisé offrent différents niveaux de protection de la vie privée, chacune impliquant des compromis spécifiques. L’article de recherche de Bagel fournit une excellente synthèse de ces technologies. Celles-ci permettent non seulement de protéger la confidentialité des données durant l’apprentissage machine, mais aussi de développer des solutions d’IA intégralement privées au niveau du calcul.
2.5 Provenance des données et des modèles
Les technologies de provenance des données et des modèles visent à garantir aux utilisateurs qu'ils interagissent bien avec le modèle et les données attendus. Elles assurent également l’authenticité et la traçabilité. Prenons l'exemple du tatouage numérique (watermarking) : une technique de provenance de modèle qui intègre une signature directement dans l'algorithme d'apprentissage automatique, plus précisément dans les poids du modèle, permettant ainsi de vérifier, lors de l'inférence, que celle-ci provient bien du modèle prévu.
2.6 Applications
En ce qui concerne les applications, les possibilités de conception sont infinies. Sur le diagramme ci-dessus, nous avons listé quelques cas d'utilisation particulièrement prometteurs émergents de l'application de l'IA dans le domaine Web3. Comme ces cas sont largement auto-explicatifs, nous n'y ajouterons pas de commentaire supplémentaire. Il convient toutefois de noter que la convergence entre l'IA et la Web3 pourrait redéfinir de nombreux domaines verticaux, car ces nouvelles primitives offrent aux développeurs une liberté accrue pour créer des cas d'usage innovants et optimiser les usages existants.
Troisième partie
Conclusion
La fusion IA x Web3 ouvre des perspectives pleines d’innovation et de potentiel. En exploitant les forces uniques de chaque technologie, nous pouvons relever divers défis et tracer de nouvelles voies technologiques. En explorant ce secteur émergent, la synergie entre IA et Web3 peut stimuler le progrès et redéfinir notre expérience numérique future ainsi que nos interactions en ligne.
La combinaison de rareté numérique et de richesse numérique, la mobilisation de ressources sous-utilisées pour améliorer l'efficacité du calcul, ainsi que la mise en place de pratiques sécurisées et respectueuses de la vie privée dans le traitement des données, définiront l'ère de l'évolution technologique à venir.
Toutefois, nous devons reconnaître que ce secteur en est encore à ses balbutiements, et que le paysage actuel pourrait rapidement devenir obsolète. Le rythme effréné de l’innovation signifie que les solutions de pointe d’aujourd’hui pourraient vite être remplacées par de nouvelles percées. Néanmoins, les concepts fondamentaux explorés — tels que les réseaux de calcul, les plateformes d’agents et les protocoles de données — soulignent les immenses possibilités offertes par la convergence de l’intelligence artificielle et de la Web3.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News











