

Illia, cofondateur de NEAR : pourquoi l'IA a besoin du Web3 ?
TechFlow SélectionTechFlow Sélection
Illia, cofondateur de NEAR : pourquoi l'IA a besoin du Web3 ?
Nous sommes à un carrefour, d'un côté de la route se trouve un monde de l'IA fermé qui conduira à davantage de manipulation.

Récemment, Illia, cofondateur de NEAR, a participé à l'événement « Web3 Festival Hong Kong 2024 » et y a prononcé un discours important sur les sujets liés à l'IA et à la Web3. Voici une synthèse de son intervention, légèrement édité.
Bonjour à tous, je suis Illia, cofondateur de NEAR. Aujourd'hui, nous allons discuter de pourquoi l'IA a besoin de la Web3. En réalité, NEAR trouve ses origines dans l'IA. Avant de me lancer dans cette aventure entrepreneuriale, j'ai travaillé chez Google Research, spécialisé dans la compréhension du langage naturel, et j'étais l'un des principaux contributeurs au framework d'apprentissage profond TensorFlow de Google. Grâce aux efforts conjoints d'une équipe de collègues, nous avons créé le tout premier modèle « Transformers », qui a permis les grandes innovations que nous observons aujourd'hui dans le domaine de l'IA, et c'est précisément ce « T » dans GPT.
Par la suite, j'ai quitté Google pour fonder NEAR. En tant que startup spécialisée dans l'IA, notre objectif était d'apprendre aux machines la programmation. L'une de nos approches consistait à effectuer de nombreuses annotations de données, en faisant créer des données par des étudiants. Nous étions confrontés au problème de leur paiement, car ils venaient du monde entier, et certains n'avaient même pas de compte bancaire. Nous avons commencé à explorer la blockchain comme solution, mais nous avons réalisé qu'aucune technologie existante ne répondait à nos besoins : évolutivité, frais réduits, simplicité d'utilisation et accessibilité. C'est ainsi que nous avons créé le protocole NEAR.

Pour ceux qui ne sont pas familiers avec le sujet, les modèles linguistiques ne sont pas une nouveauté : ils existent depuis les années 1950. Des modèles statistiques généraux permettent de modéliser le langage et de l'utiliser dans diverses applications. Pour moi, la véritable innovation intéressante est survenue en 2013, avec l'introduction des plongements de mots (word embeddings). Cette idée permet de passer d'un symbole comme « New York » à un vecteur multidimensionnel, transformable en forme mathématique. Cela s'accorde parfaitement avec les modèles d'apprentissage profond, qui ne sont en fait que des multiplications matricielles massives et des fonctions d'activation.
Après 2013, j'ai rejoint Google. Au début de 2014, les modèles principalement utilisés en recherche étaient les RNN (réseaux neuronaux récurrents). Ceux-ci fonctionnent de manière similaire à la lecture humaine mot à mot, ce qui présente une limitation majeure : si vous souhaitez lire plusieurs documents pour répondre à une question, vous subissez un délai considérable, rendant leur utilisation en production impossible chez Google.
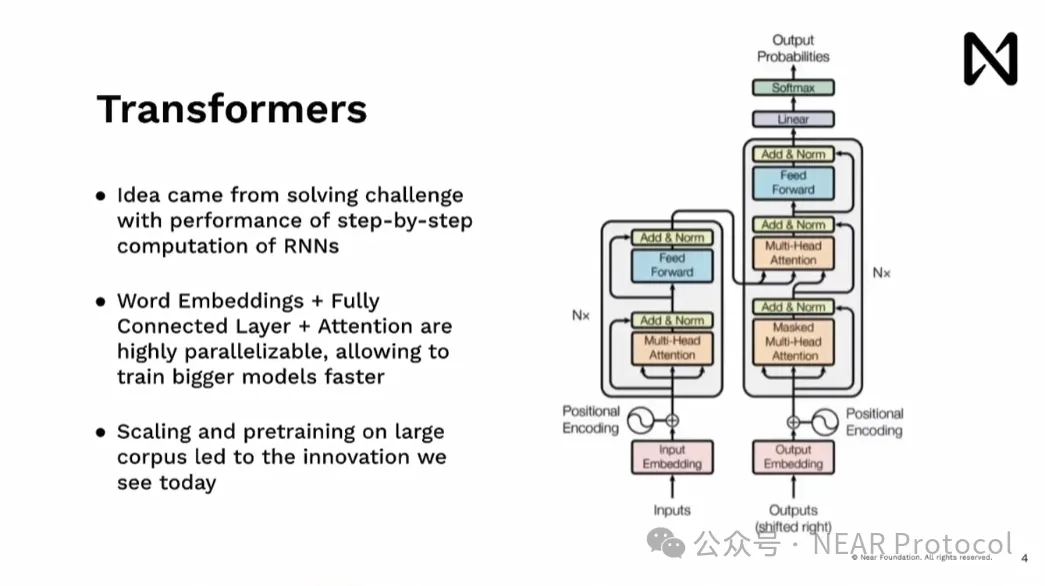
Le Transformer est né de nos tentatives pour résoudre les limites des RNN. Nous avons cherché à exploiter le parallélisme du calcul, particulièrement présent dans le matériel, notamment les GPU, afin de traiter presque intégralement un document simultanément, sans avoir à procéder étape par étape, éliminant ainsi ce goulot d'étranglement. Cela nous a permis d'introduire un modèle que l'équipe d'OpenAI a pu ensuite étendre massivement, en le pré-entraînant sur d'immenses corpus, donnant naissance aux grandes innovations actuelles telles que ChatGPT, Gemini et d'autres modèles.
Nous assistons désormais à des avancées majeures en IA, et ces innovations s'accélèrent. Ces modèles sont capables de raisonnement basique, ils possèdent un sens commun. Nous voyons les gens continuer à repousser leurs limites. À mon avis, il est essentiel que, dans les domaines de l'apprentissage automatique et de la science des données, des experts interprètent les résultats. Ce qui est intéressant maintenant, c'est que les grands modèles linguistiques peuvent interagir directement avec les humains et interagir avec d'autres applications et outils. Nous disposons donc désormais de moyens techniques pour contourner les intermédiaires dans l'interprétation des résultats.
Pour ceux qui ne sont pas familiers avec le sujet, lorsque nous parlons de ces modèles entraînés ou utilisés par des GPU, il ne s'agit pas de GPU de consoles de jeux ou de minage cryptographique. Il s'agit plutôt de supercalculateurs spécialisés, chaque machine comportant généralement huit GPU, dotés d'une puissance de calcul colossale. Ces machines sont empilées sur des baies, elles-mêmes majoritairement déployées dans des centres de données. Entraîner un grand modèle comme Groq prend trois mois avec 10 000 H100. Louer ce matériel coûterait 64 millions de dollars. Plus important encore, outre le calcul lui-même, il y a la connectivité.
Un élément clé ici est l'A100, surtout l'H100, relié à une vitesse de 900 gigaoctets par seconde. Pour comparaison, la connexion entre votre processeur et la RAM atteint environ 9 gigaoctets par seconde. Déplacer des données entre deux nœuds/deux GPU dans un rack de centre de données est en réalité plus rapide que de transférer des données du GPU vers le CPU. Et maintenant, nous continuons à améliorer Blackwell, dont la vitesse de connexion devrait doubler, atteignant 1 800 gigaoctets par seconde. Cette vitesse de connexion matérielle est folle, elle nous permet de ne plus voir ces dispositifs comme indépendants. Du point de vue du programmeur, ils semblent former une seule et même opération. Construire des systèmes à grande échelle implique de nombreux défis. L'idée est que ces appareils sont fortement interconnectés, alors que la connexion réseau locale normale est de 100 mégaoctets par seconde — soit environ dix mille fois moins rapide.
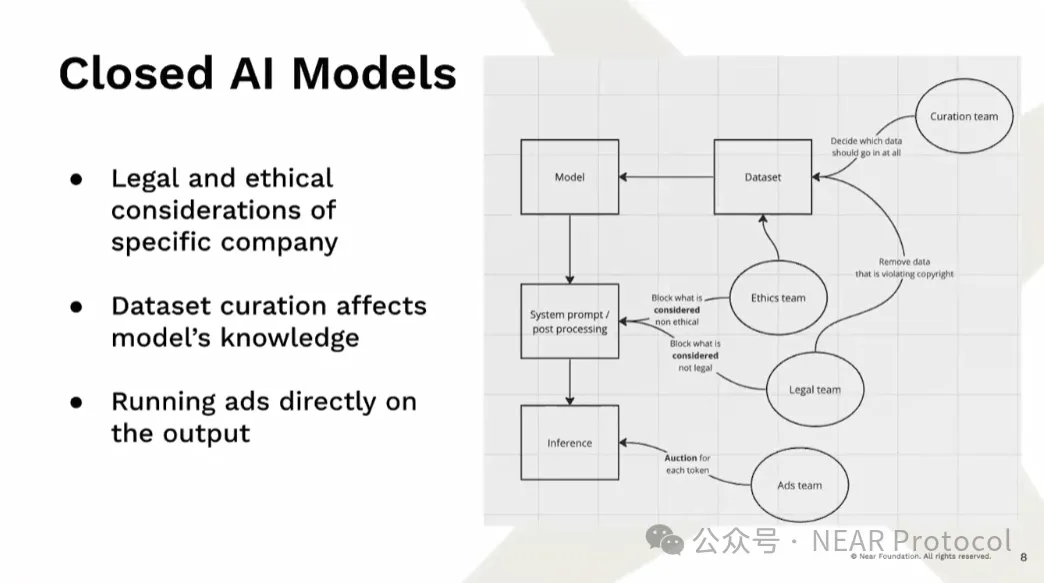
En raison de ces exigences élevées en matière d'entraînement, nous assistons aujourd'hui à la montée en puissance des modèles d'IA fermés. Même lorsque les poids du modèle sont open source, nous ne savons pas réellement ce qui a été intégré dedans. C'est crucial, car ces modèles apprennent en réalité des biais présents dans les données. Certains plaisantent en disant que les modèles ne sont que des poids et des biais — c'est ainsi qu'ils se manifestent. Actuellement, outre les ingénieurs, de nombreuses équipes influencent le contenu intégré dans les modèles en modifiant les jeux de données, excluant délibérément certaines informations pour diverses raisons. Ensuite, après la création du modèle, des traitements postérieurs et des modifications des prompts système déterminent ce que le modèle va inférer. Ce qui est particulièrement dangereux, c'est que nous ignorons totalement comment ces modèles ont été produits.
Nous assistons également à un accroissement massif des protestations et des poursuites judiciaires contre l'IA. Depuis l'utilisation des données jusqu'à la manière dont ces modèles produisent des résultats, en passant par le pouvoir exercé par ces entreprises sur les plateformes de distribution, tout cela suscite des controverses. Les modèles eux-mêmes deviennent des plateformes de diffusion, ce qui nous expose à d'énormes risques. De toute évidence, les régulateurs essaient de nous encadrer, mettant en place des mesures pour limiter l'accès des mauvais acteurs, rendant ainsi plus difficile l'existence des modèles ouverts et des approches décentralisées. L'open source manque de motivation économique suffisante, ce qui pousse certaines entreprises à initialement publier leurs modèles, puis à restreindre progressivement cet accès lorsqu'elles cherchent à gagner de l'argent, afin d'obtenir davantage de capitaux pour acheter de la puissance de calcul et entraîner des modèles encore plus grands.
L'IA générative devient un outil de manipulation de masse, et la situation économique des grandes entreprises conduit inévitablement à une distorsion des incitations. Une fois que vous avez atteint votre part de marché cible, vous devez continuer à afficher une croissance des revenus. Vous devez augmenter le revenu moyen par utilisateur, ce qui signifie extraire davantage de valeur des utilisateurs — voilà exactement ce qui se passe avec l'IA open source. Utiliser la Web3 comme outil pour inciter les gens peut créer des opportunités, tout en fournissant suffisamment de ressources computationnelles et de données pour permettre à chacun de construire des modèles compétitifs.

Nous devons permettre à un grand nombre d'outils d'IA de fonctionner efficacement dans l'univers Web3 pour les intégrer harmonieusement. Je vais aborder quelques composantes clés à partir des niveaux des données, de l'infrastructure et des applications. L'une des parties importantes est que ces modèles linguistiques peuvent désormais interagir directement avec la société, leur permettant de manipuler et de générer activement de la désinformation à grande échelle. Je tiens à préciser que l'IA n'est pas le problème ici, car ce genre de phénomène existait déjà auparavant. Ce qui importe, c'est que nous utilisions la cryptographie et la réputation sur chaîne pour résoudre ce problème. Peu importe que le contenu soit généré par une IA ou par un humain ; ce qui compte vraiment, c'est qui l'a publié, quelle en est la source, et quelle est l'opinion de la communauté.
D'autre part, nous avons désormais des agents. Nous avons pris l'habitude d'appeler tout cela des agents. Mais en réalité, ils sont très variés : on peut avoir des agents outils ou des agents autonomes, centralisés ou décentralisés. Par exemple, ChatGPT est un outil centralisé, tandis que le modèle Llama est open source. Ils peuvent donc être utilisés de façon centralisée ou décentralisée, et il est possible d'exécuter des modèles décentralisés uniquement sur les appareils des utilisateurs, sans nécessiter de blockchain ou autre technologie similaire. Car si vous exécutez un modèle sur votre propre appareil, vous pouvez garantir qu'il fonctionne exactement selon vos attentes. Il existe aussi une gouvernance complètement autonome et décentralisée de l'IA, qui doit être validée, notamment lorsqu'elle attribue des fonds ou prend des décisions importantes.

Il existe également différents types de spécialisations. Par exemple, via les prompts, vous pouvez effectuer un « zero shot » pour enseigner à Llama de répondre d'une certaine manière, ou bien faire un fine-tuning sur des données spécifiques afin d'enrichir les connaissances du modèle. Vous pouvez aussi utiliser la récupération augmentée (retrieval augmentation) pour ajouter des informations contextuelles lors des requêtes des utilisateurs. La sortie n'a pas besoin d'être uniquement textuelle : elle peut être un composant d'interface riche, ou même une action directe effectuée sur la blockchain.
Vient ensuite l'autonomie. Un agent peut être un simple outil servant à accomplir une tâche souhaitée ; il peut aussi élaborer son propre plan et l'exécuter ; il peut réaliser un travail continu à partir d'un simple objectif donné ; il peut s'agir d'une optimisation par apprentissage par renforcement, où vous définissez simplement une métrique, un ensemble de critères et des limites, puis laissez le modèle explorer continuellement et trouver des méthodes pour progresser.

Enfin, l'infrastructure. Vous pouvez utiliser une infrastructure centralisée comme OpenAI ou Groq. Vous pouvez opter pour un modèle local distribué, ou encore une inférence décentralisée probabiliste. Il existe un cas d'utilisation particulièrement intéressant : le passage de la monnaie programmable aux actifs intelligents, où le comportement des actifs est défini par le langage naturel et peut interagir avec le monde réel ou d'autres utilisateurs. Par exemple, cela pourrait utiliser un oracle de traitement du langage naturel capable de lire l'actualité et d'optimiser automatiquement une stratégie selon les événements en cours. Le principal point de vigilance ici est que les modèles linguistiques actuels ne sont pas robustes face aux comportements hostiles, et peuvent facilement être manipulés sur divers sujets.
Nous sommes à un carrefour. D'un côté, un monde d'IA fermé qui conduira à davantage de manipulation. Les décisions réglementaires tendent souvent vers ce scénario, car les autorités exigent un contrôle toujours plus strict, davantage de KYC et plus de contraintes. Seules les grandes entreprises seront en mesure de respecter ces exigences. Les startups, en particulier celles qui tentent de rester open source, n'auront pas les ressources nécessaires pour concurrencer réellement, finiront par fermer ou être rachetées par de grandes entreprises. Nous commençons déjà à observer ce phénomène.
De l'autre côté se trouve le monde des modèles ouverts, où nous avons la promesse et la capacité d'agir avec une mentalité non lucrative et open source. Nous utilisons des incitations économiques cryptographiques pour créer des opportunités et des ressources, ce qui est indispensable pour développer des modèles d'IA open source compétitifs. NEAR s'efforce de concrétiser cela dans tout son écosystème. AI is NEAR. Dans les semaines à venir, nous partagerons davantage d'actualités. Suivez-moi sur Twitter et les réseaux sociaux de NEAR pour ne rien manquer. Merci !
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News












