

Du stockage du passé au calcul du futur : l'ordinateur hyperparallèle AO
TechFlow SélectionTechFlow Sélection
Du stockage du passé au calcul du futur : l'ordinateur hyperparallèle AO
Qu'est-ce qu'AO exactement ? Et quelle est la logique sous-jacente à ses performances ?
Auteur : Zeke, chercheur chez YBB Capital
Préambule
Les deux architectures principales de blockchain émergentes dans le Web3 actuel commencent à lasser. Que ce soit les blockchains modulaires en surabondance ou les nouveaux L1 qui vantent constamment leurs performances sans jamais réussir à les démontrer concrètement, leurs écosystèmes ne sont guère plus que des copies ou légères améliorations de celui d’Ethereum. Cette forte homogénéité a déjà privé les utilisateurs de tout sentiment de nouveauté. Cependant, le nouveau protocole AO récemment introduit par Arweave suscite un regain d’intérêt, permettant des calculs haute performance sur une blockchain de stockage et offrant même une expérience proche du Web2. Ce fonctionnement diffère radicalement des solutions d’évolutivité et architectures connues jusqu’à présent. Mais qu’est donc exactement AO ? Et quelle logique sous-tend ses performances ?
Comprendre AO
Le nom « AO » provient de « Actor-Oriented », une abstraction issue du modèle de programmation concurrente appelé « Actor Model ». Sa conception s'inspire de Smart Weave et suit fidèlement le principe central du modèle Actor selon lequel la communication se fait par passage de messages. En termes simples, on peut voir AO comme un « super-ordinateur massivement parallèle » fonctionnant sur le réseau Arweave via une architecture modulaire. D’un point de vue technique, AO n’est pas une couche d’exécution modulaire classique, mais plutôt un protocole de communication standardisant l’échange de messages et le traitement des données. Son objectif principal est de permettre la collaboration entre différents « rôles » au sein du réseau par échange de messages, afin de construire une couche de calcul dont la puissance s’additionne indéfiniment. Ainsi, Arweave, cette « unité de stockage géante », pourrait atteindre, dans un environnement de confiance décentralisée, la vitesse, la scalabilité et la capacité de calcul propres aux clouds centralisés.
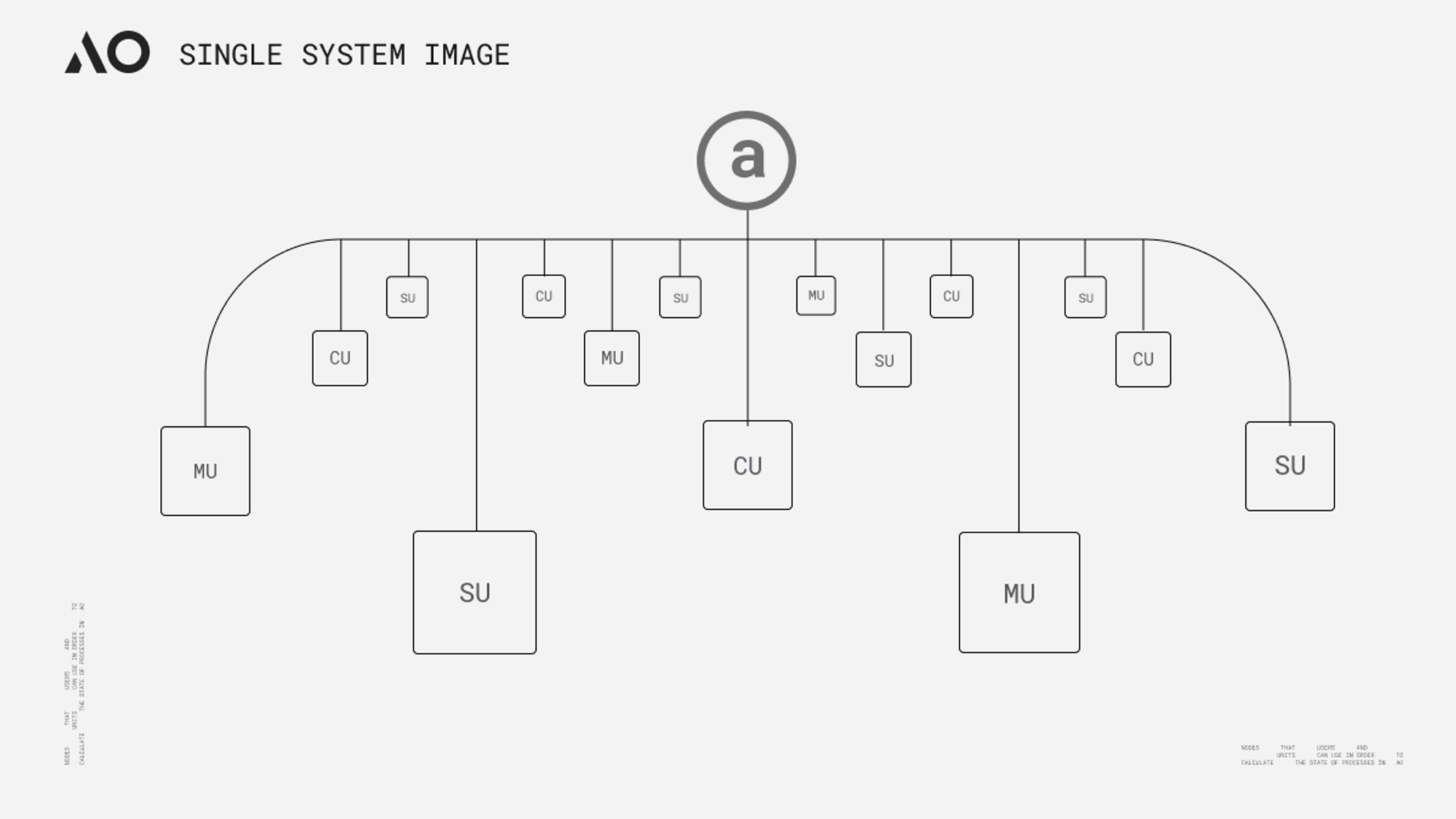
Architecture d’AO
L'idée derrière AO rappelle étrangement celle de « Core Time », proposée par Gavin Wood lors de la conférence Polkadot Decoded l'année dernière : toutes deux visent à découper puis recombiner des ressources computationnelles pour créer un prétendu « ordinateur mondial haute performance ». Pourtant, elles divergent fondamentalement. L'ordonnancement hétérogène (Exotic Scheduling) consiste à déconstruire et reconfigurer l'espace bloc de la chaîne relais, sans véritablement modifier l'architecture de Polkadot. Bien que cela dépasse les limites imposées par le modèle de slot unique d'une parachain, la performance reste bornée par le nombre maximal de cœurs inutilisés disponibles sur Polkadot. En revanche, AO théoriquement offre une capacité de calcul quasi illimitée — dans la pratique, elle dépendra du niveau d'incitation du réseau — ainsi qu'une liberté accrue. Du point de vue architectural, AO normalise le traitement des données et la représentation des messages, et repose sur trois sous-réseaux (unités réseau) pour assurer le tri, l'ordonnancement et le calcul. Selon les documents officiels, ces spécifications et fonctions peuvent être résumées comme suit :
● Processus (Process) : Un processus représente un ensemble d'instructions exécutées dans AO. Lors de son initialisation, il peut définir son environnement computationnel requis, incluant la machine virtuelle, le planificateur, les besoins en mémoire et extensions nécessaires. Ces processus conservent un état « holographique » (chaque donnée de processus pouvant être stockée indépendamment dans le journal de messages d’Arweave — notion précisée plus bas dans la section « Problème de vérifiabilité »). Cet état holographique signifie que chaque processus peut fonctionner de manière autonome, avec une exécution dynamique réalisable par toute unité de calcul appropriée. Outre les messages provenant des portefeuilles utilisateurs, les processus peuvent aussi recevoir des messages relayés par d'autres processus via l'unité messagerie (MU) ;
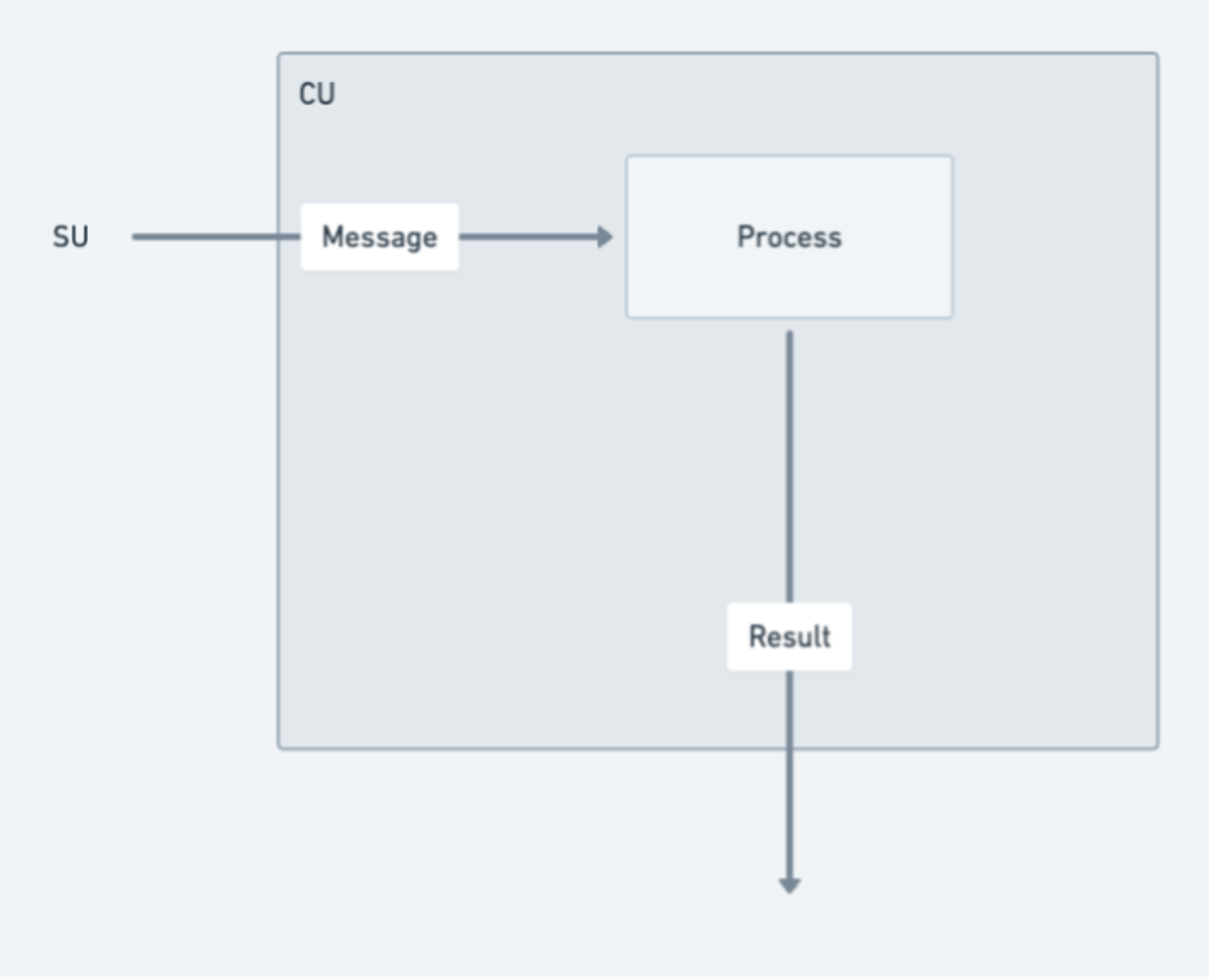
● Messages : Chaque interaction d’un utilisateur (ou d’un autre processus) avec un processus est représentée par un message. Celui-ci doit respecter le format natif ANS-104 d’Arweave, garantissant une structure homogène facilitant la sauvegarde par Arweave. De façon intuitive, on peut comparer un message à un identifiant de transaction (TX ID) dans une blockchain traditionnelle, bien que les deux ne soient pas strictement équivalents ;
● Unité Messagerie (MU - Messenger Unit) : La MU relaie les messages via un processus appelé « cranking », assurant la transmission des communications dans le système pour garantir des interactions transparentes. Une fois un message envoyé, la MU le route vers sa destination appropriée au sein du réseau (l’unité SU), coordonne l’interaction et traite récursivement tous les messages sortants générés. Ce processus se poursuit jusqu’à l’achèvement total du traitement. Outre le relais, la MU assure d’autres fonctions telles que la gestion des abonnements aux processus et le traitement des interactions programmées (cron) ;
● Unité Planification (SU - Scheduler Unit) : À réception d’un message, la SU lance plusieurs opérations clés pour maintenir la continuité et l’intégrité du processus. Elle attribue un nonce incrémental unique, garantissant l’ordre relatif par rapport aux autres messages du même processus. Ce processus d’attribution est formalisé par une signature cryptographique, assurant authenticité et intégrité séquentielle. Pour renforcer la fiabilité, la SU enregistre cette attribution signée ainsi que le message dans la couche de données d’Arweave. Cela garantit disponibilité, immuabilité des messages, et prévient toute altération ou perte de données ;
● Unité Calcul (CU - Compute Unit) : Les CUs s'affrontent dans un marché pair-à-pair pour fournir aux utilisateurs et aux SUs le service de calcul d'état du processus. Une fois le calcul terminé, la CU renvoie une preuve signée contenant le résultat spécifique au demandeur. En outre, la CU peut générer et publier des preuves d’état signées que d’autres nœuds peuvent charger — moyennant une certaine rémunération proportionnelle.
Système d’exploitation AOS
AOS peut être vu comme le système d’exploitation ou l’outil terminal d’AO, permettant de télécharger, exécuter et gérer des fils (threads). Il fournit un environnement où les développeurs peuvent créer, déployer et exécuter des applications. Sur AOS, les développeurs exploitent le protocole AO pour développer leurs applications, les déployer et interagir avec le réseau AO.
Logique de fonctionnement
Le modèle Actor défend une philosophie dite de « tout est un acteur ». Tous les composants et entités au sein de ce modèle sont considérés comme des « acteurs », chacun possédant son propre état, comportement et boîte aux lettres. Ils collaborent par échange asynchrone de messages, permettant ainsi au système entier de fonctionner de manière distribuée et concurrente. Le réseau AO suit exactement cette logique : les composants, voire les utilisateurs eux-mêmes, sont abstraits en « acteurs », communiquant via une couche de messagerie, reliant ainsi les processus entre eux. Un système de travail distribué, parallèle et non partageant d’état est ainsi progressivement construit.
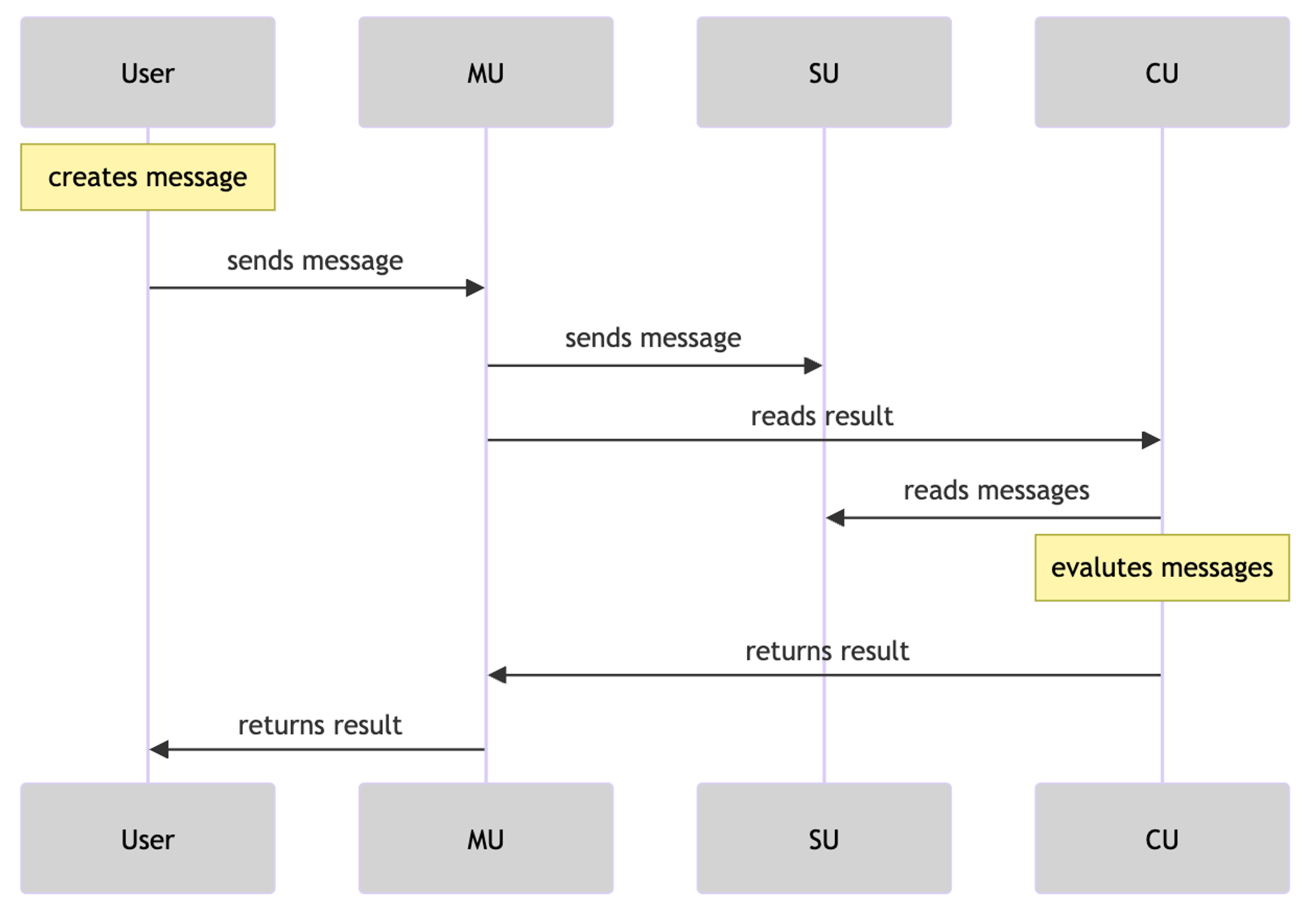
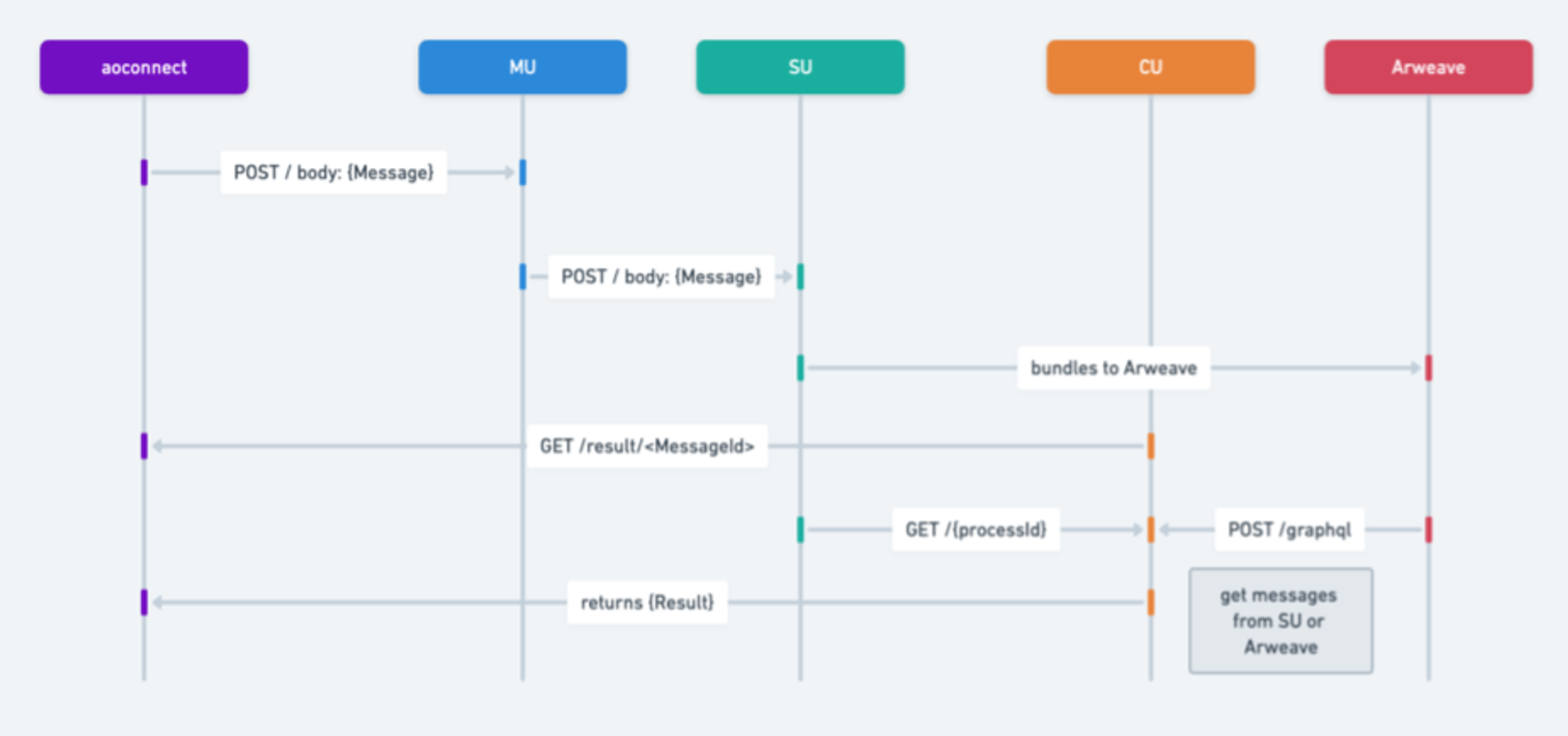
Voici un résumé des étapes du flux de transmission des messages :
1. Initiation du message :
○ Un utilisateur ou un processus crée un message pour envoyer une requête à un autre processus.
○ La MU (unité messagerie) reçoit ce message et l’envoie via une requête POST vers d'autres services.
2. Traitement et relais du message :
○ La MU traite la requête POST et transmet le message à l’unité SU (planification).
○ La SU interagit avec la couche de stockage ou de données d’Arweave pour archiver le message.
3. Récupération du résultat via l’ID du message :
○ La CU (calcul) reçoit une requête GET, récupère le résultat selon l’ID du message, puis évalue l’état du message dans le processus. Elle peut retourner le résultat à partir d’un seul identifiant de message.
4. Récupération des informations :
○ La SU reçoit une requête GET pour extraire les informations de messages selon une plage temporelle donnée et un ID de processus.
5. Envoi des messages sortants :
○ La dernière étape consiste à envoyer tous les messages sortants.
○ Cette étape implique d’examiner les messages et générations présents dans l’objet résultat.
○ En fonction de ce contrôle, les étapes 2, 3 et 4 peuvent être répétées pour chaque message ou génération pertinent.
Que change AO ? « 1 »
Différences avec les réseaux classiques :
1. Capacité de traitement parallèle : Contrairement aux réseaux comme Ethereum, dont la couche de base et chaque Rollup fonctionnent essentiellement comme un seul processus, AO supporte un nombre arbitraire de processus exécutés en parallèle, tout en maintenant intacte la vérifiabilité des calculs. En outre, ces réseaux fonctionnent dans un état synchronisé global, tandis que les processus AO conservent leur propre état indépendant. Cette indépendance permet aux processus AO de traiter un volume beaucoup plus élevé d’interactions, offrant une extensibilité supérieure, idéale pour les applications exigeantes en performance et fiabilité ;
2. Reproductibilité vérifiable : Bien que certains réseaux décentralisés, tels qu’Akash ou les systèmes pair-à-pair comme Urbit, offrent une grande puissance de calcul, ils ne fournissent pas, contrairement à AO, une reproductibilité vérifiable des interactions, ou reposent sur des solutions de stockage non permanentes pour conserver leurs journaux d’interaction.
Différences entre le réseau de nœuds AO et les environnements de calcul traditionnels :
● Compatibilité : AO supporte divers types de threads, qu'ils soient basés sur WASM ou EVM, pouvant être connectés à AO via des méthodes techniques adaptées.
● Projets de création collaborative : AO prend en charge les projets de création collaborative, permettant de publier des NFT atomiques sur AO ou de combiner des données avec UDL pour construire des NFT sur AO.
● Composabilité des données : Les NFT sur AR et AO bénéficient d’une forte composabilité, permettant à un article ou contenu d’être partagé et affiché sur plusieurs plateformes tout en conservant la cohérence de la source et les attributs d’origine. Lorsqu’un contenu est mis à jour, le réseau AO diffuse cet état mis à jour à toutes les plateformes concernées, assurant synchronisation et diffusion de la version la plus récente.
● Rémunération et propriété : Les créateurs peuvent vendre leurs œuvres sous forme de NFT et transmettre via le réseau AO les informations de propriété, assurant ainsi une rémunération juste du contenu.
Soutien aux projets :
1. Basé sur Arweave : AO exploite les caractéristiques d’Arweave pour éliminer les vulnérabilités liées aux fournisseurs centralisés, telles que les points de défaillance uniques, les fuites de données ou la censure. Les calculs sur AO sont transparents et vérifiables grâce aux journaux de messages reproductibles stockés sur Arweave et aux propriétés de confiance minimale décentralisées ;
2. Fondation décentralisée : La base décentralisée d’AO permet de surmonter les limites d’évolutivité imposées par les infrastructures physiques. N’importe qui peut facilement créer un processus AO depuis son terminal, sans connaissances, outils ou infrastructure spécialisés, garantissant ainsi que même les individus ou petites entités puissent avoir une influence globale et participer activement.
Problème de vérifiabilité d’AO
Après avoir compris le cadre et la logique d’AO, une question courante surgit : AO semble ne pas présenter les caractéristiques globales typiques d’un protocole ou d’une blockchain décentralisée. Peut-on vraiment obtenir vérifiabilité et décentralisation simplement en uploadant des données sur Arweave ? C’est précisément ici que réside l’ingéniosité du design d’AO. AO fonctionne hors chaîne, ne résout pas la vérifiabilité, ni ne modifie le consensus. L’équipe d’Arweave a choisi de séparer clairement les responsabilités : AO gère la communication et le calcul, Arweave assure uniquement le stockage et la vérification. Leur relation est presque une projection. AO doit simplement garantir que les journaux d’interaction soient stockés sur Arweave, permettant ainsi un « état holographique » projeté sur Arweave. Cette projection assure cohérence, fiabilité et déterminisme dans les résultats de calcul. En outre, les journaux de messages sur Arweave peuvent également déclencher inversement l’exécution de processus AO (capables de s’activer automatiquement selon des conditions ou calendriers prédéfinis pour exécuter des opérations dynamiques).

Selon les partages de Hill et Outprog, si l’on simplifie davantage la logique de vérification, on peut imaginer AO comme un cadre de calcul d’inscriptions basé sur un indexeur massivement parallèle. Tout comme l’indexeur d’inscriptions Bitcoin extrait les informations JSON des inscriptions et enregistre les soldes dans une base de données hors chaîne, suivant des règles d’indexation pour valider. Bien que l’indexeur fonctionne hors chaîne, les utilisateurs peuvent vérifier l’inscription en changeant d’indexeur ou en exécutant leur propre instance, évitant ainsi les risques de malveillance. Comme mentionné précédemment, l’ordre des messages et l’état holographique des processus sont tous uploadés sur Arweave. En appliquant alors le paradigme SCP (Storage Consensus Paradigm — que l’on peut comprendre comme un indexeur sur chaîne utilisant des règles d’indexation, notons que SCP est apparu bien avant les indexeurs classiques), n’importe qui peut restaurer AO ou n’importe quel thread AO à partir des données holographiques sur Arweave. Les utilisateurs n’ont pas besoin d’exécuter un nœud complet pour vérifier un état de confiance : comme pour le changement d’indexeur, il suffit d’envoyer une requête de consultation à un ou plusieurs nœuds CU via la SU. Étant donné que le stockage sur Arweave est à la fois hautement performant et peu coûteux, les développeurs AO peuvent ainsi construire une couche de calcul bien supérieure aux capacités des inscriptions Bitcoin.
AO vs ICP
Résumons brièvement les caractéristiques d’AO avec quelques mots-clés : disque dur natif géant, parallélisme illimité, calcul illimité, architecture modulaire globale et processus à état holographique. Tout cela paraît idéal. Toutefois, ceux familiers avec les projets blockchain reconnaîtront une forte similarité avec un projet autrefois qualifié de « mastodonte » : l’« Internet Computer » (ICP), célèbre à une époque.
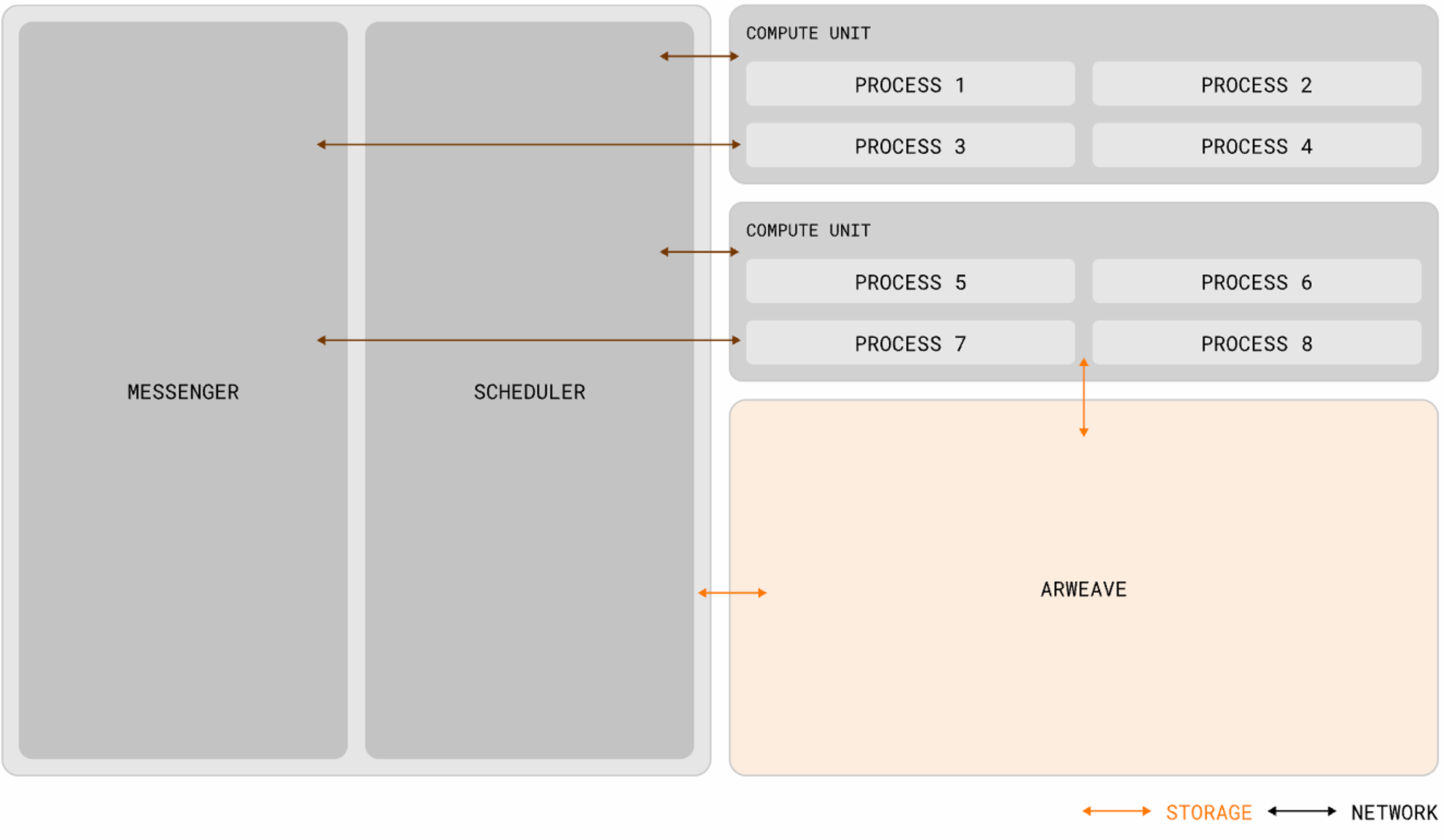
ICP fut salué comme le dernier grand projet du monde blockchain, largement soutenu par les institutions d’élite, atteignant une FDV de 200 milliards USD lors du pic haussier de 2021. Mais avec le reflux du marché, la valeur du jeton ICP a chuté vertigineusement. À la fin du marché baissier de 2023, sa valeur était environ 260 fois inférieure à son sommet historique. Pourtant, indépendamment du prix du jeton, une réévaluation objective d’ICP aujourd’hui montre que ses aspects techniques restent remarquables. Beaucoup des avantages impressionnants d’AO aujourd’hui étaient déjà présents chez ICP. AO va-t-il subir le même sort qu’ICP ? Commençons par comprendre pourquoi ils se ressemblent tant : ICP et AO sont tous deux conçus selon le modèle Actor, centrés sur une exécution locale, d’où leurs nombreuses similitudes. Les blockchains de sous-réseaux ICP sont formées par des équipements matériels haute performance indépendants (nœuds), exécutant le protocole Internet Computer (ICP). Ce protocole est implémenté par de nombreux composants logiciels regroupés en une « réplique », car ils dupliquent état et calculs sur tous les nœuds d’un sous-réseau.
L’architecture en réplication d’ICP se divise en quatre couches :
Couche réseau pair-à-pair (P2P) : Collecte et diffuse les messages provenant des utilisateurs, d’autres nœuds du même sous-réseau ou d’autres sous-réseaux. Les messages reçus sont répliqués sur tous les nœuds du sous-réseau, assurant sécurité, fiabilité et résilience ;
Couche de consensus : Sélectionne et ordonne les messages provenant des utilisateurs et des différents sous-réseaux pour former des blocs de blockchain, finalisés et certifiés via un consensus byzantin tolérant aux pannes. Ces blocs finalisés sont ensuite transmis à la couche de routage ;
Couche de routage des messages : Achemine les messages générés par les utilisateurs ou le système entre les sous-réseaux, gère les files d’entrée/sortie des DApp, et planifie l’exécution des messages ;
Couche d’environnement d’exécution : Calcule les opérations déterministes liées aux contrats intelligents en traitant les messages reçus de la couche de routage.
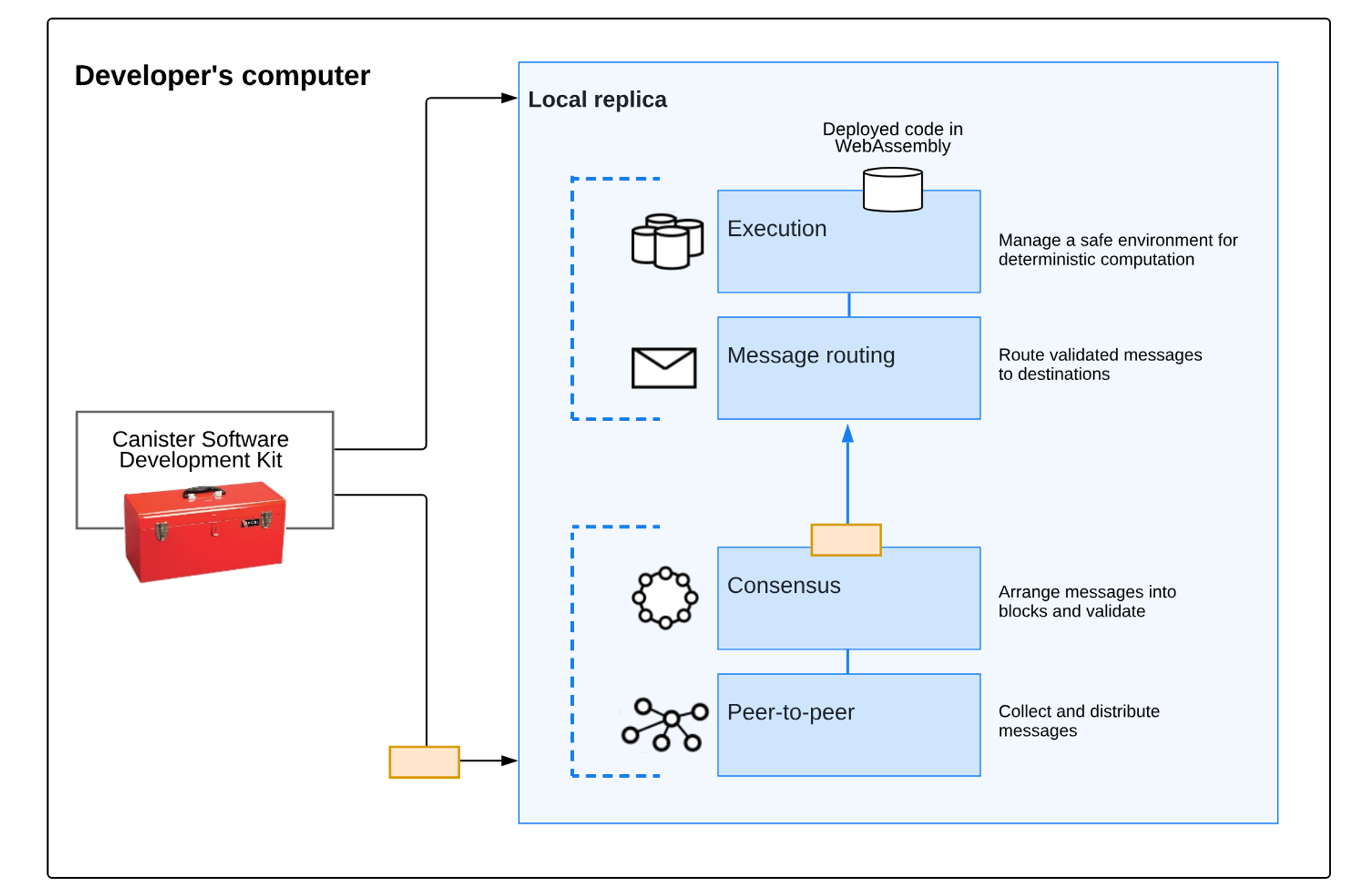
Blockchain de sous-réseau
Un « sous-réseau » désigne un ensemble de répliques interconnectées, exécutant chacune une instance distincte du mécanisme de consensus, créant ainsi sa propre blockchain sur laquelle un groupe de « canisters » peut s’exécuter. Chaque sous-réseau peut communiquer avec d'autres et est contrôlé par un sous-réseau racine, qui délègue ses permissions via la technologie de clé blockchain. ICP utilise les sous-réseaux pour permettre une extension illimitée. Le problème des blockchains traditionnelles (et des sous-réseaux individuels) est qu’elles sont limitées par la puissance de calcul d’un seul nœud, car chaque nœud doit exécuter toutes les opérations pour participer au consensus. En exécutant plusieurs sous-réseaux indépendants en parallèle, ICP franchit cet obstacle monoprocesseur.
Pourquoi a-t-il échoué ?
Comme expliqué ci-dessus, l’objectif d’ICP était simple : créer un serveur cloud décentralisé. Ce concept, tout comme AO aujourd’hui, semblait révolutionnaire il y a quelques années. Alors pourquoi a-t-il échoué ? En bref : trop ambitieux pour le Web3, pas assez pratique face au cloud centralisé. Trois raisons principales. Premièrement, le système de programmes d’ICP, appelé Canister (le « conteneur » mentionné plus haut), est similaire aux processus ou AOS d’AO, mais pas identique. Les programmes ICP sont encapsulés dans des Canisters, invisibles de l’extérieur, et nécessitent des interfaces spécifiques pour accéder aux données. Cette architecture asynchrone nuit gravement aux appels de contrats DeFi, empêchant ICP de capter de la valeur financière pendant le « DeFi Summer ».
Deuxièmement, les exigences matérielles sont extrêmement élevées, rendant le projet peu décentralisé. L’image ci-dessous montre les configurations matérielles minimales exigées par ICP à l’époque — encore aujourd’hui exagérées, dépassant largement celles de Solana, voire surpassant en stockage les blockchains dédiées au stockage.

Troisièmement, l’écosystème est pauvre. Même aujourd’hui, ICP reste l’une des blockchains les plus performantes. Si aucune application DeFi n’a émergé, qu’en est-il des autres ? Malheureusement, ICP n’a jamais réussi à faire émerger une seule application phare depuis sa création, ni attirant les utilisateurs Web2 ni captant ceux du Web3. Avec un degré de décentralisation aussi faible, pourquoi ne pas utiliser directement des applications centralisées riches et matures ? Cependant, on ne peut nier que la technologie ICP reste de très haut niveau. Ses avantages — gas inversé, compatibilité élevée, extensibilité infinie — restent des atouts précieux pour attirer les prochains milliards d’utilisateurs. Dans la vague actuelle de l’IA, si ICP sait tirer parti de son architecture, une renaissance reste possible.
Revenons à la question posée plus haut : AO échouera-t-il comme ICP ? Personnellement, je pense que non. Les deux principaux facteurs ayant causé l’échec d’ICP ne sont pas problématiques pour AO : Arweave dispose déjà d’un solide écosystème, l’état holographique règle le problème de centralisation, et AO offre une flexibilité supérieure en termes de compatibilité. Les véritables défis d’AO résident plutôt dans la conception de son modèle économique, son soutien au DeFi, et surtout dans une question centenaire : dans les domaines non financiers et non liés au stockage, sous quelle forme le Web3 doit-il se manifester ?
Le Web3 ne doit pas se limiter à la narration
Dans le monde du Web3, le mot le plus fréquemment utilisé est sans doute « narration ». Nous avons même pris l’habitude d’évaluer la valeur de la plupart des jetons à travers cette lentille. Cela découle naturellement du fait que la majorité des projets Web3 ont de grandes ambitions, mais offrent une expérience souvent décevante. En comparaison, Arweave compte déjà de nombreuses applications pleinement opérationnelles, rivalisant avec l’expérience utilisateur du Web2. Par exemple, Mirror ou ArDrive : si vous les avez utilisés, vous aurez difficilement perçu une différence avec les applications traditionnelles. Pourtant, la capture de valeur d’Arweave en tant que blockchain de stockage reste fortement limitée. Le calcul pourrait bien être la voie incontournable. Surtout dans le contexte actuel, où l’IA domine les tendances, le Web3 rencontre encore de nombreux obstacles naturels dans leur convergence — sujet déjà abordé dans nos précédents articles. Aujourd’hui, AO d’Arweave, avec son architecture non modulaire type Ethereum, propose une excellente nouvelle infrastructure pour le Web3 × IA. De la bibliothèque d’Alexandrie au super-ordinateur massivement parallèle, Arweave trace son propre paradigme.
Articles de référence
1. Introduction rapide à AO : Présentation du super-ordinateur massivement parallèle
4. AOCookBook
5. AO — Le super-ordinateur massivement parallèle que vous n’imaginez pas
6. Analyse multicritère de la chute d’ICP : technologie singulière et écosystème froid
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News





![Analyse approfondie de Trade[XYZ] : comment 92 marchés et 98 % du volume de trading HIP-3 ont-ils été établis ?](https://upload.techflowpost.com/upload/images/20260716/20260716061117965147.jpeg?x-oss-process=image/resize,p_50/quality,q_80)








