

L'énigme mathématique de la puissance de calcul de Sora
TechFlow SélectionTechFlow Sélection
L'énigme mathématique de la puissance de calcul de Sora
Sora ne représente pas seulement une avancée majeure en termes de qualité et de fonctionnalités de génération vidéo, mais annonce également une augmentation significative de la demande en GPU pour les phases de raisonnement à l'avenir.
Rédaction : Matthias Plappert
Traduction : Siqi, Lavida, Tianyi
Après avoir lancé son modèle de génération vidéo Sora le mois dernier, OpenAI a publié hier une série de créations réalisées par des artistes utilisant Sora, avec des résultats spectaculaires. Sans aucun doute, en termes de qualité générée, Sora est à ce jour le modèle de génération vidéo le plus puissant. Son apparition non seulement aura un impact direct sur les industries créatives, mais influencera également la résolution de certains problèmes clés dans des domaines comme la robotique ou la conduite autonome.
Bien qu'OpenAI ait publié un rapport technique sur Sora, celui-ci contient très peu de détails techniques. Ce texte est une traduction d'une analyse rédigée par Matthias Plappert du fonds Factorial. Matthias a travaillé chez OpenAI et participé au projet Codex. Dans cette étude, il examine les détails techniques clés de Sora, ses innovations majeures, leurs implications, ainsi que les besoins en puissance de calcul de modèles de génération vidéo comme Sora. Selon Matthias, à mesure que l'utilisation de la génération vidéo deviendra plus répandue, les besoins en calcul lors de l'inférence dépasseront rapidement ceux de l'entraînement, particulièrement pour des modèles basés sur la diffusion comme Sora.
D'après les estimations de Matthias, les besoins en puissance de calcul de Sora durant l'entraînement sont plusieurs fois supérieurs à ceux des grands modèles linguistiques (LLM), nécessitant environ 4200 à 10500 GPU Nvidia H100 entraînés pendant un mois. De plus, une fois que le modèle aura généré entre 15,3 et 38,1 millions de minutes de vidéos, le coût computationnel de l'inférence dépassera rapidement celui de l'entraînement. À titre de comparaison, les utilisateurs téléchargent actuellement environ 17 millions de minutes de vidéos chaque jour sur TikTok, et 43 millions sur YouTube. Le CTO d'OpenAI, Mira, a récemment indiqué dans un entretien que le coût élevé de la génération vidéo est l'une des raisons pour lesquelles Sora n'est pas encore accessible au public. OpenAI souhaite atteindre un coût comparable à celui de Dall·E pour la génération d'images avant d'envisager une ouverture.
La sortie récente de Sora par OpenAI a stupéfait le monde grâce à sa capacité extrêmement réaliste à générer des scènes vidéo. Dans cet article, nous examinerons en profondeur les détails techniques derrière Sora, les impacts potentiels de ces modèles vidéo, ainsi que certaines réflexions actuelles. Enfin, nous partagerons nos estimations concernant la puissance de calcul nécessaire pour entraîner un modèle tel que Sora, et analyserons la relation entre entraînement et inférence, ce qui revêt une importance cruciale pour anticiper la demande future en GPU.
Points clés
Les conclusions principales de ce rapport sont les suivantes :
-
Sora est un modèle de diffusion basé sur DiT et la diffusion latente, dont l'échelle a été augmentée tant en taille de modèle qu'en volume de données d'entraînement ;
-
Sora démontre l'importance cruciale du scaling-up pour les modèles vidéo, et une augmentation continue restera le principal moteur d'amélioration des capacités, tout comme pour les LLM ;
-
Des entreprises comme Runway, Genmo et Pika explorent actuellement la création d'interfaces intuitives et de flux de travail autour de modèles de génération vidéo basés sur la diffusion comme Sora, ce qui déterminera leur accessibilité et leur adoption ;
-
L'entraînement de Sora exige une puissance de calcul énorme : nous estimons qu'il nécessite entre 4200 et 10500 GPU Nvidia H100 pendant un mois ;
-
Pour l'inférence, nous estimons qu'un H100 peut produire au maximum environ 5 minutes de vidéo par heure. Les coûts d'inférence de modèles basés sur la diffusion comme Sora sont supérieurs de plusieurs ordres de grandeur à ceux des LLM ;
-
Avec l'adoption généralisée de modèles comme Sora, l'inférence surpassera l'entraînement comme composante dominante de la consommation computationnelle. Ce seuil critique est atteint après la production de 15,3 à 38,1 millions de minutes de vidéo, moment où le volume de calcul utilisé en inférence dépasse celui de l'entraînement initial. À titre de comparaison, les utilisateurs téléchargent quotidiennement 17 millions de minutes sur TikTok et 43 millions sur YouTube ;
-
En supposant une intégration massive de l'IA dans les plateformes vidéo — par exemple 50 % des vidéos sur TikTok et 15 % sur YouTube générées par IA — et en tenant compte de l'efficacité matérielle et des modes d'utilisation, nous estimons qu'en situation de pointe, environ 720 000 GPU Nvidia H100 seraient nécessaires pour l'inférence.
En résumé, Sora ne représente pas seulement une avancée majeure en matière de qualité et de fonctionnalités de génération vidéo, mais annonce aussi une augmentation significative de la demande en GPU liée à l'inférence à l'avenir.
01. Contexte
Sora est un modèle de diffusion. Ces modèles sont couramment utilisés dans la génération d'images, comme Dall-E d'OpenAI ou Stable Diffusion de Stability AI. De même, des sociétés récentes spécialisées dans la génération vidéo, telles que Runway, Genmo et Pika, utilisent très probablement des architectures basées sur la diffusion.
De manière générale, en tant que modèles génératifs, les modèles de diffusion apprennent progressivement à inverser un processus consistant à ajouter du bruit aléatoire aux données, afin de créer des données similaires à leurs données d'entraînement, comme des images ou des vidéos. Ils commencent à partir d'un bruit complet, puis retirent progressivement ce bruit et affinent les motifs jusqu'à obtenir une sortie cohérente et détaillée.

Schéma du processus de diffusion :
Le bruit est progressivement retiré jusqu'à la révélation d'un contenu vidéo détaillé
Source : Rapport technique de Sora
Ce processus diffère nettement de celui des modèles linguistiques (LLM) : les LLM génèrent itérativement les tokens un par un, méthode appelée échantillonnage auto-régressif. Une fois un token généré, il n'est plus modifié. On observe ce phénomène lors de l'utilisation d'outils comme Perplexity ou ChatGPT : la réponse apparaît lettre par lettre, comme si quelqu'un tapait en temps réel.
02. Détails techniques de Sora
Concomitamment à la sortie de Sora, OpenAI a publié un rapport technique, mais celui-ci contient peu de détails. Toutefois, la conception de Sora semble largement inspirée par l'article « Scalable Diffusion Models with Transformers ». Dans cet article, deux auteurs proposent DiT, une architecture basée sur les Transformers pour la génération d'images. Sora semble étendre ce travail au domaine vidéo. En combinant le rapport technique de Sora et l'article DiT, on peut reconstituer logiquement le fonctionnement de Sora.
Trois éléments clés concernant Sora :
1. Sora n'opère pas directement dans l'espace des pixels, mais utilise un espace latent (latent space), également appelé diffusion latente ;
2. Sora adopte une architecture Transformer ;
3. Sora semble utiliser un jeu de données extrêmement vaste.
Détail 1 : Diffusion latente
Pour comprendre la diffusion latente mentionnée ci-dessus, considérons d'abord comment une image est générée. On pourrait appliquer la diffusion à chaque pixel, mais ce serait très inefficace : par exemple, une image 512x512 contient 262 144 pixels. Une alternative consiste à compresser d'abord les pixels en une représentation latente, puis effectuer la diffusion dans cet espace latent réduit, avant de reconstruire l'image finale. Cette approche réduit drastiquement la complexité computationnelle : au lieu de manipuler 262 144 pixels, on traite seulement 64x64 = 4096 unités latentes. Cette percée, issue de l'article « High-Resolution Image Synthesis with Latent Diffusion Models », constitue la base de Stable Diffusion.

Transformation des pixels de l’image gauche en une grille de représentation latente (à droite)
Source : Rapport technique de Sora
DiT et Sora utilisent tous deux la diffusion latente. Pour Sora, il faut en outre prendre en compte la dimension temporelle : une vidéo est une séquence temporelle d'images (appelées trames). Comme indiqué dans le rapport technique, la compression de l'espace pixel vers l'espace latent s'effectue à la fois spatialement (réduction de la hauteur et largeur de chaque trame) et temporellement (compression dans le temps).
Détail 2 : Architecture Transformer
Concernant le deuxième point, DiT et Sora remplacent l'architecture U-Net traditionnellement utilisée par une architecture Transformer standard. Ce choix est crucial car les auteurs de DiT ont constaté que l'utilisation de Transformers permet une évolution prévisible selon les lois d'échelle : en augmentant la taille du modèle, la durée d'entraînement, ou les deux, les performances du modèle s'améliorent systématiquement. Le rapport technique de Sora fait la même observation dans le contexte de la génération vidéo, illustrée par un graphique explicite.

Amélioration de la qualité du modèle avec l'augmentation du calcul d'entraînement : de gauche à droite, calcul de base, 4x, et 32x
Cette propriété d'échelle peut être quantifiée par les lois d'échelle (scaling laws), un aspect essentiel. Avant la génération vidéo, ces lois ont déjà été observées dans les LLM et autres modèles autorégressifs. La possibilité d'améliorer les modèles via l'échelle a été l'un des principaux moteurs du développement rapide des LLM. Étant donné que la génération d'images et de vidéos suit également cette loi, nous pouvons nous attendre à ce qu'elle s'applique pleinement dans ces domaines.
Détail 3 : Jeu de données
Pour entraîner un modèle comme Sora, un facteur clé est la disponibilité de données annotées. Nous pensons que le jeu de données contient une grande partie des secrets de Sora. Pour entraîner un modèle text2video comme Sora, il faut des paires constituées de vidéos et de leurs descriptions textuelles. OpenAI n'a guère discuté du jeu de données, mais a laissé entendre qu'il était très vaste. Dans le rapport technique, OpenAI explique s'être inspiré du fait que « l'entraînement sur des données à l'échelle internet confère aux LLM des capacités générales ».

Source : Rapport technique de Sora
OpenAI a également décrit une méthode d'annotation d'images par des légendes détaillées, utilisée pour construire le jeu de données DALL-E 3. En résumé, un modèle de légendage (captioner model) est entraîné sur un sous-ensemble annoté, puis utilisé automatiquement pour annoter le reste des données. Il est probable que Sora utilise une technologie similaire.
03. Impact de Sora
Application pratique des modèles vidéo
Sur le plan du réalisme et de la cohérence temporelle, la qualité des vidéos générées par Sora constitue indéniablement une percée majeure. Par exemple, Sora gère correctement les objets momentanément cachés, et reproduit fidèlement les reflets sur l'eau. Nous pensons que la qualité actuelle de Sora est déjà suffisante pour certains types de scènes, et peut être utilisée dans des applications concrètes, notamment en remplaçant partiellement les banques de vidéos existantes.
Cartographie du domaine de génération vidéo
Cependant, Sora fait face à des défis : nous ignorons encore sa précision de contrôle. Comme le modèle produit directement des pixels, modifier une vidéo générée est difficile et coûteux. Pour que le modèle soit utile, il est nécessaire de développer des interfaces utilisateur (UI) intuitives et des flux de travail adaptés. Comme le montre l'illustration ci-dessus, Runway, Genmo, Pika et d'autres entreprises du secteur travaillent déjà à ces solutions.
Grâce au scaling, nous pouvons accélérer nos attentes en génération vidéo
Comme discuté précédemment, une conclusion clé de l'étude DiT est que la qualité du modèle augmente directement avec la puissance de calcul. Cela rappelle fortement les lois d'échelle observées dans les LLM. Nous pouvons donc anticiper que, grâce à des ressources computationnelles accrues, la qualité des modèles de génération vidéo s'améliorera rapidement. Sora valide fortement cette hypothèse, et nous prévoyons qu'OpenAI et d'autres entreprises redoubleront d'efforts dans ce sens.
Génération de données synthétiques et augmentation de données
Dans des domaines comme la robotique ou la conduite autonome, les données restent une ressource rare : il n'existe pas d'équivalent internet où des robots accomplissent massivement des tâches ou conduisent. Généralement, ces problèmes sont abordés par des simulations ou la collecte massive de données dans le monde réel, ou les deux. Mais ces méthodes posent des difficultés : les données simulées manquent souvent de réalisme, tandis que la collecte dans le monde réel est coûteuse et insuffisante pour capturer des événements rares.

Comme illustré ci-dessus, on peut transformer des attributs vidéo pour les enrichir : ici, la vidéo originale (gauche) est rendue dans un environnement de jungle dense (droite)
Source : Rapport technique de Sora
Nous pensons que des modèles comme Sora peuvent jouer un rôle ici. Ils pourraient directement générer des données entièrement synthétiques. Sora peut aussi servir à l'augmentation de données, en transformant divers aspects des vidéos existantes.
L'augmentation mentionnée ici est déjà illustrée dans le rapport technique : initialement, une voiture rouge roule sur une route forestière ; après traitement par Sora, elle évolue dans une jungle tropicale. Avec la même technologie, on pourrait aisément modifier l'éclairage (jour/nuit) ou les conditions météorologiques.
Simulation et modèles du monde
« Les modèles du monde » (World Models) constituent une direction de recherche prometteuse. Si suffisamment précis, ces modèles permettraient d'entraîner directement des agents d'IA, ou serviraient à la planification et à la recherche.
Des modèles comme Sora apprennent implicitement (implicitement learning) à partir de vidéos un modèle fondamental du fonctionnement du monde réel. Bien imparfaite, cette « simulation émergente » (emergent simulation) est fascinante : elle suggère qu'on pourrait entraîner des modèles du monde à grande échelle à partir de données vidéo. De plus, Sora semble capable de simuler des scènes complexes — écoulement des liquides, reflets lumineux, mouvement des fibres ou des cheveux. OpenAI a même intitulé le rapport technique de Sora Video generation models as world simulators, indiquant clairement qu'ils considèrent cela comme l'impact le plus important du modèle.
Récemment, DeepMind a montré des effets similaires avec son modèle Genie : entraîné uniquement sur des vidéos de jeux, le modèle a appris à simuler ces jeux, voire à en créer de nouveaux. Dans ce cas, le modèle apprend même à adapter ses prédictions ou décisions à des comportements jamais directement observés. L'objectif d'entraînement de Genie reste d'apprendre dans ces environnements simulés.

Vidéo issue de Genie de Google DeepMind :
Introduction à Generative Interactive Environments
Dans l'ensemble, nous pensons que des modèles comme Sora et Genie seront essentiels pour entraîner à grande échelle des agents incarnés (embodied agents) sur des tâches du monde réel. Bien sûr, ces modèles ont des limites : entraînés dans l'espace des pixels, ils simulent chaque détail — y compris le vent dans les herbes — sans lien direct avec la tâche. Bien que l'espace latent soit compressé, il conserve encore beaucoup de ces informations pour garantir la reconstruction en pixels. Il n'est donc pas clair si la planification peut être efficace dans l'espace latent.
04. Estimation de la puissance de calcul
Nous portons un grand intérêt aux besoins en ressources computationnelles pendant l'entraînement et l'inférence, car ces données aident à prévoir la demande future. Toutefois, en raison du manque d'informations détaillées sur la taille du modèle Sora et son jeu de données, toute estimation reste incertaine. Les calculs présentés ici doivent donc être pris avec prudence.
Déduction de l'échelle de calcul de Sora à partir de DiT
Les détails sur Sora sont très limités, mais nous pouvons nous appuyer sur l'article DiT, qui constitue visiblement sa base. Le modèle DiT-XL, le plus grand de la série, compte 675 millions de paramètres et a requis environ 1021 FLOPS au total pour son entraînement. Pour mieux visualiser, cela correspond à 0,4 H100 Nvidia fonctionnant un mois, ou un seul H100 pendant 12 jours.
Actuellement, DiT est utilisé pour la génération d'images, mais Sora est un modèle vidéo. Sora peut générer jusqu'à 1 minute de vidéo. En supposant un taux d'encodage de 24 images par seconde (fps), une vidéo contient jusqu'à 1440 trames. La conversion de l'espace pixel vers l'espace latent compresse simultanément les dimensions spatiale et temporelle. En supposant un taux de compression identique à celui de DiT (facteur 8), il reste 180 trames dans l'espace latent. Une extrapolation linéaire simple impliquerait donc que le coût computationnel de Sora soit 180 fois supérieur à celui de DiT.
Par ailleurs, nous pensons que le nombre de paramètres de Sora dépasse largement 675 millions. Une estimation de 20 milliards de paramètres semble plausible, ce qui suggère un facteur supplémentaire de 30 par rapport à DiT.
Enfin, nous estimons que le jeu de données d'entraînement de Sora est bien plus vaste que celui de DiT. DiT a été entraîné sur 3 millions d'étapes avec une taille de lot de 256, soit 768 millions d'images traitées. Notons que, étant donné qu'ImageNet contient seulement 14 millions d'images, les mêmes données ont été réutilisées. Sora semble entraîné sur un mélange d'images fixes et de vidéos, mais nous ignorons presque tout du jeu de données. Supposons simplement qu'il soit composé à 50 % d'images fixes et à 50 % de vidéos, et qu'il soit 10 à 100 fois plus volumineux que celui de DiT. Toutefois, comme DiT réutilise les mêmes données, cette pratique peut être sous-optimale si un jeu de données plus vaste est disponible. Un multiplicateur raisonnable pour l'augmentation du calcul serait donc plutôt de 4 à 10.
En combinant ces éléments, et en considérant différentes hypothèses sur la taille du jeu de données, nous obtenons :
Formule : Calcul de base de DiT × augmentation du modèle × augmentation du jeu de données × augmentation due aux 180 trames vidéo (uniquement pour 50 % du jeu de données)
-
Estimation conservatrice du jeu de données : 1021 FLOPS × 30 × 4 × (180 / 2) ≈ 1,1×10²⁵ FLOPS
-
Estimation optimiste du jeu de données : 1021 FLOPS × 30 × 10 × (180 / 2) ≈ 2,7×10²⁵ FLOPS
La puissance de calcul requise par Sora équivaut à celle de 4211 à 10528 GPU H100 fonctionnant pendant un mois.
Besoins en puissance de calcul : inférence vs entraînement
Un autre aspect crucial est la comparaison entre les coûts computationnels d'entraînement et d'inférence. Théoriquement, bien que l'entraînement soit coûteux, son coût est unique. En revanche, l'inférence, bien moins coûteuse par opération, se répète à chaque génération et croît avec le nombre d'utilisateurs. Ainsi, à mesure que l'usage s'étend, l'inférence devient de plus en plus importante.
Il est donc utile d'identifier le seuil critique au-delà duquel l'inférence dépasse l'entraînement.
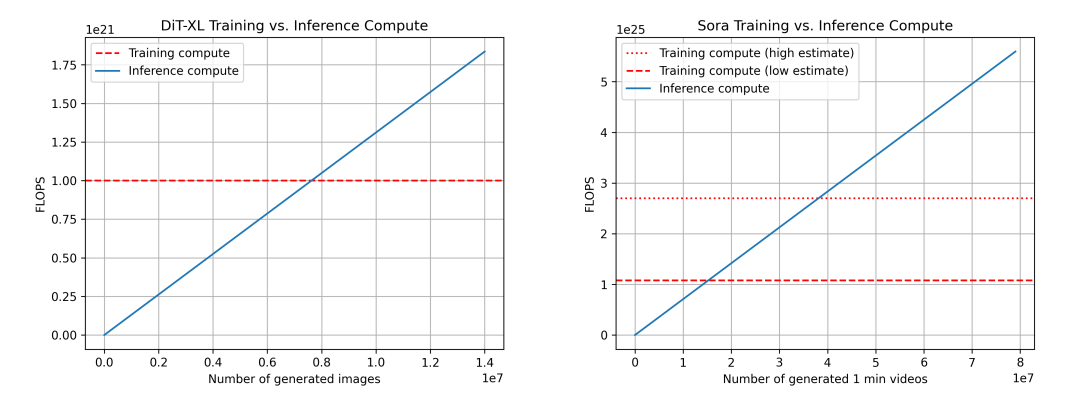
Nous comparons DiT (gauche) et Sora (droite). Pour Sora, les données reposent sur les estimations ci-dessus, donc approximatives. Deux estimations d'entraînement sont présentées : une basse (multiplicateur 4 pour la taille du jeu de données) et une haute (multiplicateur 10).
Pour DiT, le modèle DiT-XL consomme 524×10⁹ FLOPS par étape d'inférence, et 250 étapes de diffusion par image, soit 131×10¹² FLOPS au total. Après la génération de 7,6 millions d'images, le seuil « inférence-entraînement » est atteint, au-delà duquel l'inférence domine. À titre de référence, les utilisateurs téléchargent environ 95 millions d'images par jour sur Instagram.
Pour Sora, nous estimons : 524×10⁹ FLOPS × 30 × 180 ≈ 2,8×10¹⁵ FLOPS. Avec toujours 250 étapes de diffusion, chaque vidéo consomme 708×10¹⁵ FLOPS. Cela correspond à environ 5 minutes de vidéo générées par heure par H100. Avec une estimation conservatrice du jeu de données, le seuil est atteint après 15,3 millions de minutes de vidéo générées ; avec une estimation optimiste, après 38,1 millions. À titre de comparaison, environ 43 millions de minutes sont téléchargées quotidiennement sur YouTube.
Quelques remarques complémentaires : pour l'inférence, les FLOPS ne sont pas le seul facteur. La bande passante mémoire est également critique. Des recherches activent visent à réduire le nombre d'étapes de diffusion, ce qui diminuerait le coût computationnel et accélérerait l'inférence. L'efficacité d'utilisation des FLOPS peut aussi varier entre entraînement et inférence.
Yang Song, Prafulla Dhariwal, Mark Chen et Ilya Sutskever ont publié en mars 2023 l'article Consistency Models, soulignant que bien que les modèles de diffusion aient fait des progrès majeurs dans la génération d'images, d'audio et de vidéo, ils souffrent de lenteur due à l'échantillonnage itératif. Leur proposition de modèles de cohérence permet d'échanger calcul contre qualité d'échantillonnage. https://arxiv.org/abs/2303.01469
Comparaison des besoins computationnels d'inférence selon les modalités
Nous avons analysé l'évolution du coût computationnel d'inférence par unité de sortie selon les modalités. L'objectif est d'évaluer l'intensité computationnelle relative de l'inférence entre catégories de modèles, ce qui a un impact direct sur la planification. Chaque modèle ayant une unité de sortie différente : pour Sora, une vidéo d'une minute ; pour DiT, une image 512x512 pixels ; pour Llama 2 et GPT-4, un document de 1000 tokens (en référence, un article Wikipédia moyen contient environ 670 tokens).
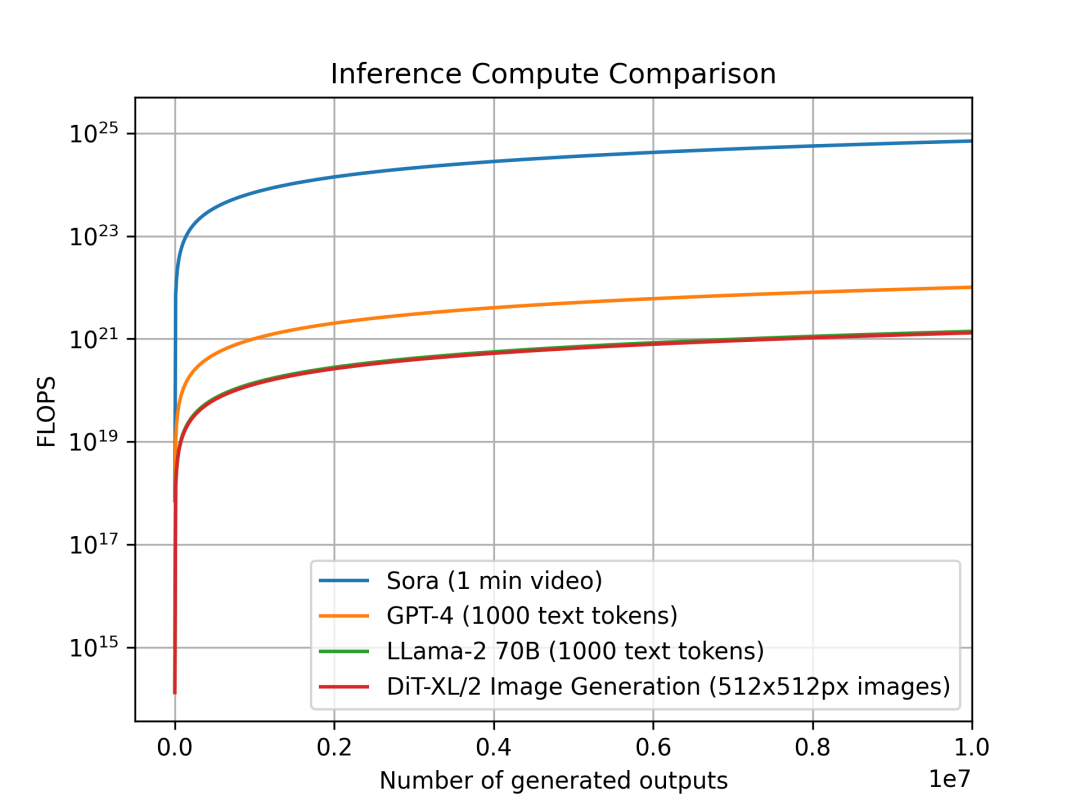
Comparaison du coût d'inférence par unité de sortie : Sora (1 minute vidéo), GPT-4 et LLama 2 (1000 tokens), DiT (une image 512x512px). Le graphique montre que Sora nécessite plusieurs ordres de grandeur de calcul en plus.
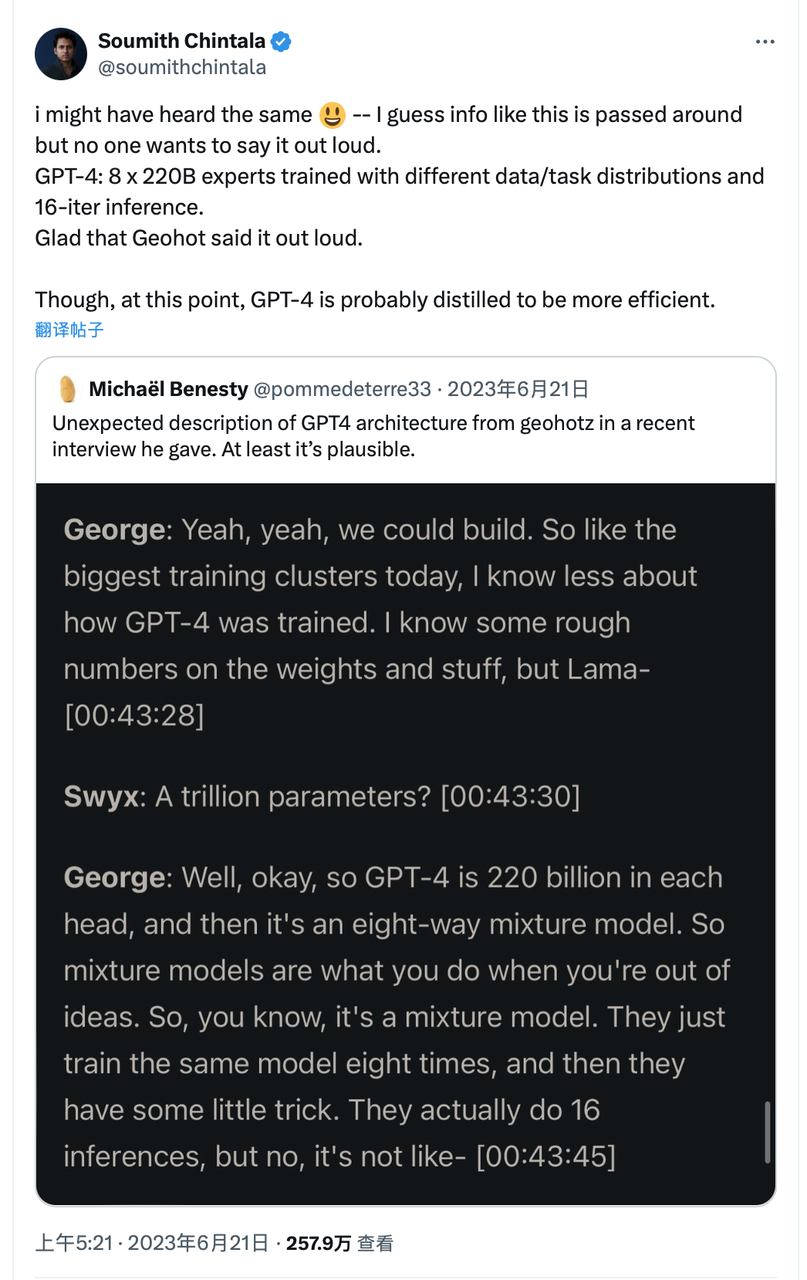
Nous comparons Sora, DiT-XL, LLama2-70B et GPT-4, en échelle logarithmique. Pour Sora et DiT, nous utilisons les estimations d'inférence précédentes. Pour Llama 2 et GPT-4, nous appliquons l'approximation « FLOPS = 2 × nombre de paramètres × nombre de tokens générés ». Pour GPT-4, nous supposons un modèle MoE avec 220 milliards de paramètres par expert, activant 2 experts par passage. Ces données sur GPT-4 ne sont pas officielles et sont fournies à titre indicatif.
Source : X
On observe que les modèles basés sur la diffusion comme DiT et Sora consomment bien plus de puissance de calcul en inférence : DiT-XL (675 millions de paramètres) consomme autant que LLama 2 (70 milliards de paramètres). Plus encore, Sora dépasse GPT-4 de plusieurs ordres de grandeur.
Il convient de rappeler que ces chiffres reposent sur des hypothèses simplificatrices et des estimations. Ils ne tiennent pas compte de l'efficacité réelle d'utilisation des FLOPS, ni des limites de mémoire ou de bande passante, ni de techniques avancées comme le décodage spéculatif (speculative decoding).
Prévision de la demande d'inférence si Sora est largement adopté :
À partir des besoins de Sora, nous estimons combien de GPU Nvidia H100 seraient nécessaires si la génération vidéo par IA était massivement adoptée sur des plateformes comme TikTok et YouTube.
• Comme ci-dessus, supposons qu'un H100 produise 5 minutes de vidéo par heure, soit 120 minutes par jour.
• Sur TikTok : actuellement, 17 millions de minutes de vidéos sont téléchargées quotidiennement (34 millions de vidéos × durée moyenne de 30 secondes), avec une pénétration IA hypothétique de 50 % ;
• Sur YouTube : 43 millions de minutes téléchargées quotidiennement, avec une pénétration IA de 15 % (principalement vidéos de moins de 2 minutes) ;
• Volume quotidien de vidéos générées par IA : 8,5 + 6,5 = 15 millions de minutes.
• Nombre total de GPU Nvidia H100 nécessaires pour soutenir les créateurs sur TikTok et YouTube : 15 millions / 120 ≈ 89 000.
Mais ce chiffre de 89 000 pourrait être sous-estimé, car plusieurs facteurs doivent être pris en compte :
• Nous supposons une utilisation des FLOPS à 100 %, sans tenir compte des goulets d'étranglement mémoire ou de communication. Une utilisation réelle de 50 % est plus réaliste, doublant donc la demande en GPU ;
• La demande d'inférence n'est pas uniforme dans le temps, mais présente des pics. Pour assurer le service, davantage de GPU sont nécessaires. En tenant compte des pics, multiplions la demande par 2 ;
• Les créateurs peuvent générer plusieurs vidéos avant d'en choisir une à publier. En supposant en moyenne 2 générations par vidéo publiée, la demande double encore ;
Au total, en situation de pointe, environ 720 000 H100 seraient nécessaires pour répondre à la demande d'inférence.
Cela confirme notre conviction : à mesure que les modèles d'IA générative deviennent populaires et omniprésents, la demande computationnelle d'inférence dominera, particulièrement pour des modèles basés sur la diffusion comme Sora.
Il convient aussi de noter que le scaling continu des modèles amplifiera encore davantage cette demande. Toutefois, des optimisations techniques, notamment en inférence et dans la pile logicielle, pourront compenser en partie cette hausse.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News










