

Sora n'a pas encore été mis à disposition du public, alors pourquoi a-t-il déjà fait sensation sur Internet ?
TechFlow SélectionTechFlow Sélection
Sora n'a pas encore été mis à disposition du public, alors pourquoi a-t-il déjà fait sensation sur Internet ?
OpenAI l'appelle directement un « simulateur mondial », capable de modéliser les caractéristiques des personnes, des animaux et de l'environnement dans le monde physique.
Par : Mu Mu
Sans même ouvrir de test public, OpenAI a déjà stupéfait le monde technologique, internet et les réseaux sociaux grâce à une bande-annonce réalisée avec son modèle de génération vidéo à partir de texte, Sora.
Selon la vidéo officiellement publiée par OpenAI, Sora peut produire des « super-vidéos » complexes d'une durée allant jusqu'à une minute à partir d'informations textuelles fournies par l'utilisateur. Non seulement les détails visuels sont réalistes, mais ce modèle simule également le mouvement de caméra.
À en juger par les effets vidéo déjà diffusés, ce qui enthousiasme particulièrement le secteur est la capacité de Sora à comprendre le monde réel. Comparé aux autres grands modèles de texte vers vidéo, Sora affiche un avantage marqué en matière de compréhension sémantique, de rendu visuel, de cohérence temporelle et de durée.
OpenAI qualifie directement Sora de « simulateur du monde », affirmant qu’il est capable de reproduire les caractéristiques des êtres humains, des animaux et des environnements dans le monde physique. Toutefois, l’entreprise reconnaît que Sora n’est pas encore parfait, souffrant de lacunes dans sa compréhension et présentant des risques potentiels pour la sécurité.
Ainsi, Sora n’est actuellement accessible qu’à un très petit groupe sélectionné. OpenAI n’a pas encore annoncé quand Sora sera ouvert au grand public, mais l’impact qu’il a suscité suffit à faire prendre conscience aux entreprises concurrentes de leur retard.
La « bande-annonce » de Sora épate tout le monde
Dès la sortie du modèle de génération vidéo à partir de texte de OpenAI, Sora, les médias chinois ont repris leurs formules habituelles de sensationnalisme.
Les blogs et influenceurs s'exclament : « La réalité n’existe plus ». Les grandes figures du web louent aussi massivement les capacités de Sora. Zhou Hongyi, fondateur de 360, affirme que l’apparition de Sora pourrait ramener la réalisation de l’AGI (intelligence artificielle générale) de 10 ans à environ deux ans. En quelques jours seulement, l’indice de recherche Google sur Sora a grimpé en flèche, atteignant presque le niveau de popularité de ChatGPT.
Le succès fulgurant de Sora découle des 48 vidéos publiées par OpenAI, dont la plus longue dure une minute. Cela dépasse largement les limites précédentes de durée imposées par d'autres modèles tels que Gen2 ou Runway. En outre, la clarté des images est remarquable, et Sora maîtrise désormais le langage cinématographique.
Dans une vidéo d’une minute, une femme vêtue d’une robe rouge marche dans une rue illuminée de néons. Le style est réaliste, fluide. Ce qui impressionne le plus, c’est le gros plan sur la protagoniste : pores, taches pigmentaires, cicatrices d’acné sont fidèlement reproduits — l’effet est comparable à une diffusion en direct où l’on désactiverait les filtres de beauté. Même les rides du cou, révélatrices de l’âge, sont précisément représentées, en harmonie parfaite avec l’apparence du visage.
Outre la représentation réaliste des personnes, Sora peut aussi simuler les animaux et environnements réels. Une vidéo montre un pigeon couronné de Victoria sous plusieurs angles, restituant en ultra-haute définition les plumes bleues couvrant tout son corps jusqu’à la crête, sans oublier les moindres détails comme le mouvement de ses yeux rouges ou sa fréquence respiratoire, rendant difficile de distinguer si la scène a été filmée par un humain ou générée par IA.
Pour les animations créatives non-réalistes, Sora atteint un rendu visuel proche de celui des films d’animation Disney, suscitant des inquiétudes chez les animateurs quant à leur avenir professionnel.
Les améliorations apportées par Sora ne concernent pas uniquement la durée et la qualité des vidéos générées. Il peut aussi simuler les trajectoires de mouvement de caméra, y compris celles en vue subjective de jeu vidéo, en prise de vue aérienne ou même le fameux plan-séquence cinématographique.
Après avoir visionné les superbes vidéos diffusées par OpenAI, on comprend aisément pourquoi le milieu technologique et l’opinion publique des réseaux sociaux sont sidérés par Sora. Et tout cela n’est encore que la bande-annonce.
OpenAI introduit le jeu de données des « patchs visuels »
Comment Sora parvient-il à cette capacité de simulation ?
Selon le rapport technique publié par OpenAI, ce modèle dépasse les limites des précédents modèles de génération d’images à partir de données visuelles.
Les recherches antérieures sur la génération d’images à partir de texte ont utilisé diverses méthodes, notamment les réseaux récurrents, les réseaux antagonistes génératifs (GAN), les transformeurs auto-régressifs et les modèles de diffusion. Mais elles avaient toutes en commun de se concentrer sur des catégories limitées de données visuelles, des vidéos courtes ou de dimensions fixes.
Sora adopte un modèle de diffusion basé sur les transformeurs. Le processus de génération d’image se divise en deux phases : un processus direct et un processus inverse, permettant ainsi à Sora d’étendre la vidéo dans le temps, vers l’avant comme vers l’arrière.
Durant la phase directe, le modèle simule la diffusion d’une image réelle vers une image entièrement bruitée. Concrètement, il ajoute progressivement du bruit à l’image jusqu’à ce qu’elle devienne purement aléatoire. La phase inverse est l’exact opposé : le modèle reconstitue progressivement l’image originale à partir de l’image bruitée. Par ces alternances entre réel et virtuel, OpenAI permet à Sora de comprendre la formation des images visuelles.
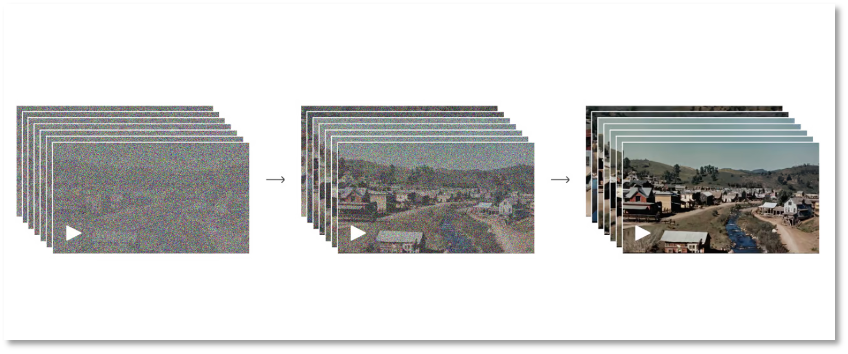 Du bruit total à l'image claire
Du bruit total à l'image claire
Bien entendu, ce processus nécessite un entraînement itératif intense. Le modèle apprend progressivement à éliminer le bruit et à restaurer les détails de l’image. Grâce à ces cycles répétés, le modèle de diffusion de Sora parvient à générer des images de haute qualité. Ce type de modèle s’est révélé performant dans la génération d’images, leur retouche ou encore la super-résolution.
Ce mécanisme explique pourquoi Sora produit des images si nettes et détaillées. Mais passer d’images statiques à des vidéos dynamiques exige du modèle une accumulation supplémentaire de données et un apprentissage approfondi.
Au-delà du modèle de diffusion, OpenAI convertit tous types de données visuelles – vidéos et images – en une représentation uniforme afin d’entraîner massivement Sora. Cette forme de représentation, appelée « patchs visuels (patches) » par OpenAI, consiste en un ensemble d’unités de données plus petites, semblables aux séquences de texte utilisées dans GPT.
Les chercheurs commencent par compresser la vidéo dans un espace latent de faible dimension, puis décomposent cette représentation en patches spatio-temporels. Cette structure hautement évolutive facilite la conversion vidéo-patch et convient particulièrement bien à l’entraînement de modèles capables de traiter divers formats d’images et de vidéos.
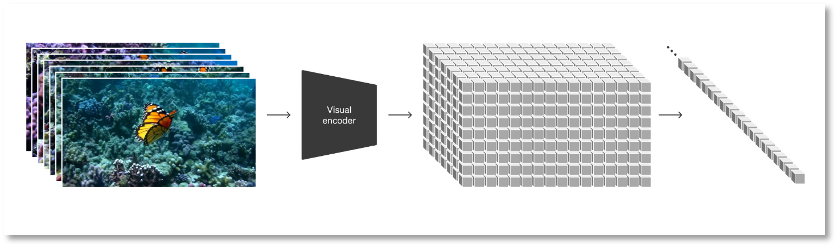 Transformation des données visuelles en patches
Transformation des données visuelles en patches
Afin de réduire la charge informatique et la quantité d’information nécessaire à l’entraînement de Sora, OpenAI a développé un réseau de compression vidéo. Celui-ci réduit d’abord la vidéo en un espace latent de faible dimension au niveau pixel, puis extrait des patches à partir de ces données compressées. Cela diminue le volume d’entrée et allège considérablement la charge de calcul. Parallèlement, OpenAI a entraîné un modèle décodeur capable de remapper les informations compressées vers l’espace des pixels.
Grâce à cette représentation par patchs visuels, les chercheurs peuvent entraîner Sora sur des vidéos ou images de différentes résolutions, durées et proportions. Lors de la phase d’inférence, Sora peut déterminer la logique vidéo et contrôler la taille de la vidéo générée en organisant des patches initialisés aléatoirement dans une grille adaptée.
Selon OpenAI, lors de l’entraînement à grande échelle, le modèle vidéo manifeste des fonctionnalités prometteuses : il simule fidèlement les personnes, animaux et environnements du monde réel, génère des vidéos haute fidélité, assure une cohérence 3D et temporelle, et parvient ainsi à simuler authentiquement le monde physique.
Altman joue l’intermédiaire pour les tests des internautes
Des résultats à la méthode de développement, Sora démontre des capacités impressionnantes. Pourtant, les utilisateurs ordinaires n’ont toujours aucun accès. Actuellement, ils doivent simplement rédiger une consigne descriptive et mentionner Sam Altman, cofondateur d’OpenAI, sur X (anciennement Twitter). Ce dernier agit alors comme intermédiaire, générant la vidéo via Sora et la publiant pour que le public en voie les résultats.
Cela alimente inévitablement des doutes quant à la véritable puissance de Sora comparée aux démonstrations officielles d’OpenAI.
À ce sujet, OpenAI admet franchement que le modèle présente encore certaines lacunes. Comme les premières versions de GPT, Sora souffre actuellement d’« hallucinations ». Ces erreurs, dans un contexte principalement visuel, apparaissent de manière particulièrement concrète.
Par exemple, il ne parvient pas à simuler correctement certains phénomènes physiques fondamentaux, comme la relation entre le tapis roulant d’un treadmill et le mouvement d’une personne, ou encore la chronologie entre la rupture d’un verre et l’écoulement du liquide à l’intérieur.
Dans la séquence montrant des archéologues découvrant une chaise en plastique, celle-ci semble littéralement « flotter » hors du sable.
Il y a aussi des petits loups qui apparaissent soudainement, surnommés par les internautes « la mitose du loup ».
Il confond parfois aussi les directions gauche-droite, avant-arrière.
Ces imperfections dans les scènes animées semblent indiquer que Sora doit encore approfondir sa compréhension et son apprentissage de la logique du mouvement dans le monde physique. En outre, comparé aux risques de ChatGPT, Sora, qui offre une expérience visuelle immédiate, soulève des préoccupations morales et sécuritaires encore plus graves.
Déjà, le modèle de génération d’images à partir de texte Midjourney a montré que « voir ne signifie pas croire » : les images générées par IA, quasi indiscernables des vraies, sont devenues un vecteur de désinformation. Le Dr Newell, scientifique en chef chez iProov, spécialisée dans l’authentification d’identité, déclare que Sora permettra « aux acteurs malveillants de produire facilement des vidéos factices de très haute qualité ».
On imagine aisément que si les vidéos générées par Sora étaient utilisées à mauvais escient — fraude, diffamation, diffusion de contenus violents ou pornographiques — les conséquences seraient incalculables. Voilà pourquoi Sora inspire autant de crainte que de stupéfaction.
OpenAI est conscient des risques liés à Sora, ce qui explique probablement pourquoi seuls quelques rares privilégiés peuvent y accéder, sur invitation uniquement. Quand sera-t-il ouvert au grand public ? Aucun calendrier n’a été donné. Mais à la vue des vidéos publiées par OpenAI, les autres entreprises n’ont plus beaucoup de temps pour rattraper Sora.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News










