

Un autre regard sur « IA + Blockchain » : comment l'IA révolutionne-t-elle Ethereum ?
TechFlow SélectionTechFlow Sélection
Un autre regard sur « IA + Blockchain » : comment l'IA révolutionne-t-elle Ethereum ?
À mesure que la puissance de calcul sur la chaîne augmentera progressivement, nous pouvons prévoir le développement de modèles de plus en plus complexes destinés à la gestion du réseau, à la surveillance des transactions, aux audits de sécurité, etc., ce qui améliorera l'efficacité et la sécurité du réseau Ethereum.
Rédaction : Mirror Tang, Salus ;
Yixin Ren, Hongshan Capital ;
Lingzhi Shi, Salus ;
Jiangyue Wang, Salus
Au cours de l'année écoulée, à mesure que l'intelligence artificielle générative (IA générative) a successivement dépassé les attentes du grand public, la vague de révolution de productivité de l'IA a balayé le secteur des cryptomonnaies. Nous avons constaté qu’un certain nombre de projets liés à l’IA ont créé un mythe de création de richesse sur le marché secondaire, tandis que de plus en plus de développeurs se mettent à créer leurs propres projets « IA + Crypto ».
Toutefois, une observation attentive révèle une forte homogénéisation parmi ces projets. La plupart d'entre eux se contentent d'améliorer les « rapports de production », par exemple en organisant la puissance de calcul via des réseaux décentralisés ou en créant une « Hugging Face décentralisée ». Peu de projets tentent une véritable fusion et innovation au niveau technologique fondamental. Selon nous, cette situation s'explique par un « biais sectoriel » entre les domaines de l’IA et de la blockchain. Bien que les deux champs présentent de nombreux points communs, rares sont ceux qui comprennent profondément chacun d’eux. Par exemple, les développeurs spécialisés en IA ont souvent du mal à saisir les spécificités techniques d’Ethereum ou son historique d’infrastructure, ce qui rend difficile la proposition de solutions d’optimisation approfondies.
Prenons comme exemple l’apprentissage automatique (machine learning, ML), une branche fondamentale de l’IA, qui permet aux machines de prendre des décisions à partir de données sans instructions de programmation explicites. L’apprentissage automatique montre un énorme potentiel dans l’analyse des données et la reconnaissance de motifs, et est déjà largement utilisé dans le web2. Toutefois, en raison des limites de son époque de création, même dans des bastions innovants comme Ethereum, l’architecture, le réseau et les mécanismes de gouvernance n’intègrent pas encore l’apprentissage automatique comme outil efficace pour résoudre des problèmes complexes.
« Les grandes innovations naissent souvent aux croisements des disciplines. » Notre objectif en rédigeant cet article est double : aider les développeurs d’IA à mieux comprendre le monde de la blockchain, tout en offrant aux développeurs de la communauté Ethereum de nouvelles perspectives. Nous commençons par présenter les aspects techniques d’Ethereum, puis proposons d’appliquer des algorithmes fondamentaux d’apprentissage automatique au réseau Ethereum afin d’améliorer sa sécurité, son efficacité et sa scalabilité. À travers ce cas d’étude, nous espérons susciter davantage d’innovations combinant « IA + Blockchain » au sein de l’écosystème développeur, en apportant un angle différent de celui du marché.
Implémentation technique d’Ethereum
-
Structure de données fondamentale
Une blockchain est essentiellement une chaîne de blocs reliés entre eux, dont la configuration distingue chaque chaîne. Cette configuration fait partie intégrante de la genèse de toute blockchain. Pour Ethereum, elle permet de différencier ses différentes chaînes, tout en identifiant des protocoles majeurs et événements marquants tels que DAOForkBlock (indiquant la hauteur du bloc du hard fork suite à l’attaque DAO) ou ConstantinopleBlock (marquant la mise à jour Constantinople). Pour les mises à jour importantes incluant de nombreuses propositions d’amélioration, des champs spéciaux indiquent la hauteur correspondante du bloc. En outre, Ethereum comporte divers réseaux de test ainsi que le réseau principal, tous identifiés de manière unique par un ChainID.
Le bloc de genèse, premier bloc de la chaîne, est référencé directement ou indirectement par tous les autres blocs. Dès le démarrage, chaque nœud doit charger correctement les informations du bloc de genèse, qui ne peuvent être modifiées arbitrairement. La configuration du bloc de genèse inclut non seulement la configuration de chaîne mentionnée ci-dessus, mais aussi des champs comme les récompenses minières, l’horodatage, la difficulté et les limites de gaz. Il convient de noter que le mécanisme de consensus d’Ethereum est passé du Proof-of-Work (PoW) au Proof-of-Stake (PoS).
Les comptes Ethereum sont divisés en comptes externes (EOA) et comptes contrats. Les comptes externes sont contrôlés exclusivement par une clé privée, tandis que les comptes contrats ne disposent pas de clé privée et ne peuvent être manipulés qu’en appelant le contrat via un compte externe. Chaque type possède une adresse unique. L’état global d’Ethereum forme un arbre de comptes, chaque compte correspondant à une feuille contenant son état (informations sur le solde, le code, etc.).
Transaction : Ethereum étant une plateforme décentralisée, son essence réside dans les transactions et les contrats. Un bloc Ethereum regroupe des transactions accompagnées d’autres informations. Chaque bloc se compose d’un en-tête et d’un corps. L’en-tête contient les preuves reliant tous les blocs en une chaîne — notamment le hachage du bloc précédent, la racine d’état attestant de l’état global d’Ethereum, la racine des transactions, la racine des reçus (receipts), ainsi que diverses données supplémentaires comme la difficulté, le nonce, etc. Le corps du bloc stocke la liste des transactions et celle des blocs oncles (terme désormais obsolète depuis le passage au PoS).
Le reçu de transaction fournit les résultats et informations supplémentaires après exécution de la transaction, qui ne peuvent être obtenus en examinant la transaction seule. Ces informations incluent : le contenu du consensus, les détails de la transaction et du bloc, le succès du traitement, les logs de contrat, la consommation de gaz, etc. L’analyse des reçus permet de déboguer les codes de contrats intelligents, d’optimiser la consommation de gaz, et offre une preuve que la transaction a été traitée par le réseau, avec visibilité sur ses effets.
Sur Ethereum, les frais de gaz peuvent être compris comme des frais de transaction. Lorsque vous envoyez un jeton, exécutez un contrat, transférez des ethers ou effectuez toute autre opération, chaque action consomme du gaz, car la machine Ethereum utilise des ressources pour le calcul. Vous devez donc payer des frais de gaz pour que la machine travaille pour vous. Ces frais sont versés aux validateurs (anciennement mineurs), selon la formule : Frais = Gaz Utilisé × Prix du Gaz. Le prix du gaz est fixé par l’expéditeur, influant directement sur la rapidité de traitement. Un prix trop bas peut entraîner un rejet de la transaction. Une limite de gaz (gas limit) doit également être définie pour éviter une consommation excessive due à une erreur dans le contrat.
-
Piscine de transactions (mempool)
Sur Ethereum, un grand volume de transactions circule. Comparé aux systèmes centralisés, la capacité de traitement par seconde des systèmes décentralisés reste limitée. En raison du flux massif de transactions entrant dans les nœuds, ceux-ci doivent gérer une mempool pour organiser efficacement ces transactions. La diffusion des transactions s’effectue en pair-à-pair (p2p) : un nœud diffuse une transaction exécutable à ses voisins, qui la relaient à leur tour, permettant ainsi à une transaction de se propager à tout le réseau Ethereum en environ 6 secondes.
Les transactions dans la mempool sont classées en exécutables et non exécutables. Les premières ont une priorité élevée et seront incluses dans un bloc, tandis que toutes les nouvelles transactions entrent initialement comme non exécutables. Les transactions exécutables et non exécutables sont respectivement stockées dans les conteneurs « pending » et « queue ».
La mempool maintient également une liste locale de transactions (local). Celles-ci bénéficient d’une priorité accrue, ne sont pas soumises aux limites de volume, et peuvent être rechargées immédiatement après un redémarrage grâce à un journal (journal), assurant ainsi qu’aucune transaction locale inachevée n’est perdue. Ce journal est régulièrement mis à jour.
Avant d’entrer dans la file d’attente, chaque transaction subit des vérifications de légitimité, incluant des contrôles anti-DOS, anti-valeurs négatives, et limites de gaz. La structure simplifiée de la mempool consiste en « queue + pending » (ensemble des transactions). Après vérification, d’autres contrôles sont effectués : vérification de la saturation de la file, comparaison des transactions distantes (non locales), remplacement de celles ayant le prix le plus bas. Pour remplacer une transaction exécutable, seul un relèvement de 10 % des frais est autorisé, la transaction remplacée devenant alors non exécutable. Pendant la maintenance, les transactions invalides ou excédant les limites sont supprimées, et certaines sont remplacées si elles remplissent les critères.
-
Mécanisme de consensus
Initialement, le consensus d’Ethereum reposait sur le calcul de hachages selon une difficulté cible (Proof-of-Work). Comme Ethereum a désormais adopté le Proof-of-Stake (PoS), nous ne développerons pas ici les détails du minage. En septembre 2022, Ethereum a finalisé la fusion avec la Beacon Chain, implémentant ainsi le PoS. Sous ce nouveau modèle, chaque bloc est produit toutes les 12 secondes. Les utilisateurs bloquent (stake) leurs ethers pour devenir validateurs. Un tirage aléatoire sélectionne des validateurs par cycle, chaque cycle comportant 32 créneaux (slots). À chaque créneau, un validateur est désigné comme proposeur (proposer) pour produire le bloc, tandis que les autres forment un comité chargé de valider la légitimité du bloc proposé et de certifier les blocs du cycle précédent. Le PoS améliore considérablement la stabilité et la vitesse de production des blocs, tout en réduisant drastiquement le gaspillage de ressources informatiques.
-
Algorithme de signature
Ethereum reprend le standard de signature de Bitcoin, utilisant la courbe elliptique secp256k1 et l’algorithme ECDSA (Elliptic Curve Digital Signature Algorithm). La signature est calculée à partir du hachage du message initial, composée simplement de R+S+V. Un nombre aléatoire est introduit à chaque calcul. R et S correspondent à la sortie brute de l’ECDSA. Le champ V, dit champ de récupération, indique combien d’essais sont nécessaires pour retrouver la clé publique à partir du message et de la signature, car plusieurs points candidats peuvent correspondre à une valeur R donnée sur la courbe elliptique.
Le processus complet peut être résumé ainsi : les données de transaction et les informations du signataire sont encodées via RLP, puis hachées. Cette empreinte est signée avec la clé privée via ECDSA, utilisant la courbe secp256k1. Enfin, les données de signature et de transaction sont combinées pour former une transaction signée, prête à être diffusée.
La structure de données d’Ethereum ne repose pas uniquement sur la technologie blockchain traditionnelle, mais intègre également l’arbre de Merkle Patricia (MPT), ou arbre de préfixes compressé de Merkle, permettant un stockage et une vérification efficaces de grandes quantités de données. Le MPT combine les fonctions de hachage cryptographique de l’arbre de Merkle et la compression des chemins de l’arbre de Patricia, offrant une solution garantissant à la fois l’intégrité des données et une recherche rapide.
-
Arbre de Merkle Patricia (MPT)
Sur Ethereum, le MPT stocke tous les états et données de transaction, garantissant que tout changement de données se reflète dans le hachage de la racine de l’arbre. Ainsi, en vérifiant ce hachage, on peut attester de l’intégrité et de l’exactitude des données sans avoir à parcourir toute la base. Le MPT est composé de quatre types de nœuds : feuilles, extensions, branches et nœuds vides, formant un arbre adaptable aux modifications dynamiques. Lors d’une mise à jour, le MPT modifie, ajoute ou supprime des nœuds, mettant à jour simultanément le hachage de la racine. Comme chaque nœud est chiffré par une fonction de hachage, toute modification mineure provoque un changement radical du hachage racine, assurant sécurité et cohérence. De plus, la conception du MPT prend en charge la « vérification légère » : un client léger peut valider l’existence ou l’état d’une information en ne conservant que le hachage racine et les nœuds de chemin nécessaires, réduisant fortement les besoins de stockage et de traitement.
Grâce au MPT, Ethereum parvient non seulement à une gestion efficace et un accès rapide aux données, mais renforce aussi la sécurité et la décentralisation du réseau, soutenant ainsi son fonctionnement et son développement.
-
Machine à états
L’architecture centrale d’Ethereum s’inspire du concept de machine à états. La machine virtuelle Ethereum (EVM) est l’environnement d’exécution de tous les contrats intelligents, tandis qu’Ethereum lui-même peut être vu comme un système mondial partagé de transition d’états. Chaque bloc exécuté représente une transition d’un état global à un autre. Cette conception assure la cohérence et la décentralisation du réseau, tout en rendant les résultats d’exécution des contrats prévisibles et inviolables.
Dans Ethereum, l’état désigne l’information actuelle de tous les comptes, incluant soldes, données de stockage et code des contrats intelligents. À chaque transaction, l’EVM calcule et transforme l’état, un processus enregistré de manière sécurisée et efficace via le MPT. Chaque transition modifie les données des comptes et met à jour le MPT, reflétée par un changement du hachage racine.
La relation entre l’EVM et le MPT est cruciale, car le MPT garantit l’intégrité des données lors des transitions d’état. Quand l’EVM exécute une transaction et modifie l’état d’un compte, les nœuds correspondants du MPT sont mis à jour. Comme chaque nœud du MPT est lié par hachage, toute modification de l’état change le hachage racine, qui est ensuite inclus dans le nouveau bloc, assurant ainsi la cohérence et la sécurité globales du réseau Ethereum. Présentons maintenant l’EVM.
-
EVM
La machine virtuelle EVM est le fondement d’Ethereum pour l’exécution des contrats intelligents et les transitions d’état. Grâce à l’EVM, Ethereum peut véritablement être conçu comme un « ordinateur mondial ». L’EVM est Turing-complète, ce qui signifie que les contrats intelligents peuvent exécuter des calculs logiques arbitrairement complexes. L’introduction du mécanisme de gaz empêche efficacement les boucles infinies, assurant stabilité et sécurité du réseau. Sur le plan technique, l’EVM est une machine virtuelle à pile, exécutant des contrats compilés en bytecode spécifique à Ethereum. Les développeurs utilisent généralement des langages de haut niveau comme Solidity, qu’ils compilent en bytecode interprétable par l’EVM. L’EVM est au cœur de l’innovation d’Ethereum, supportant non seulement les contrats intelligents, mais aussi le développement d’applications décentralisées (dApps). Grâce à elle, Ethereum façonne un futur numérique décentralisé, sécurisé et ouvert.
Retour historique
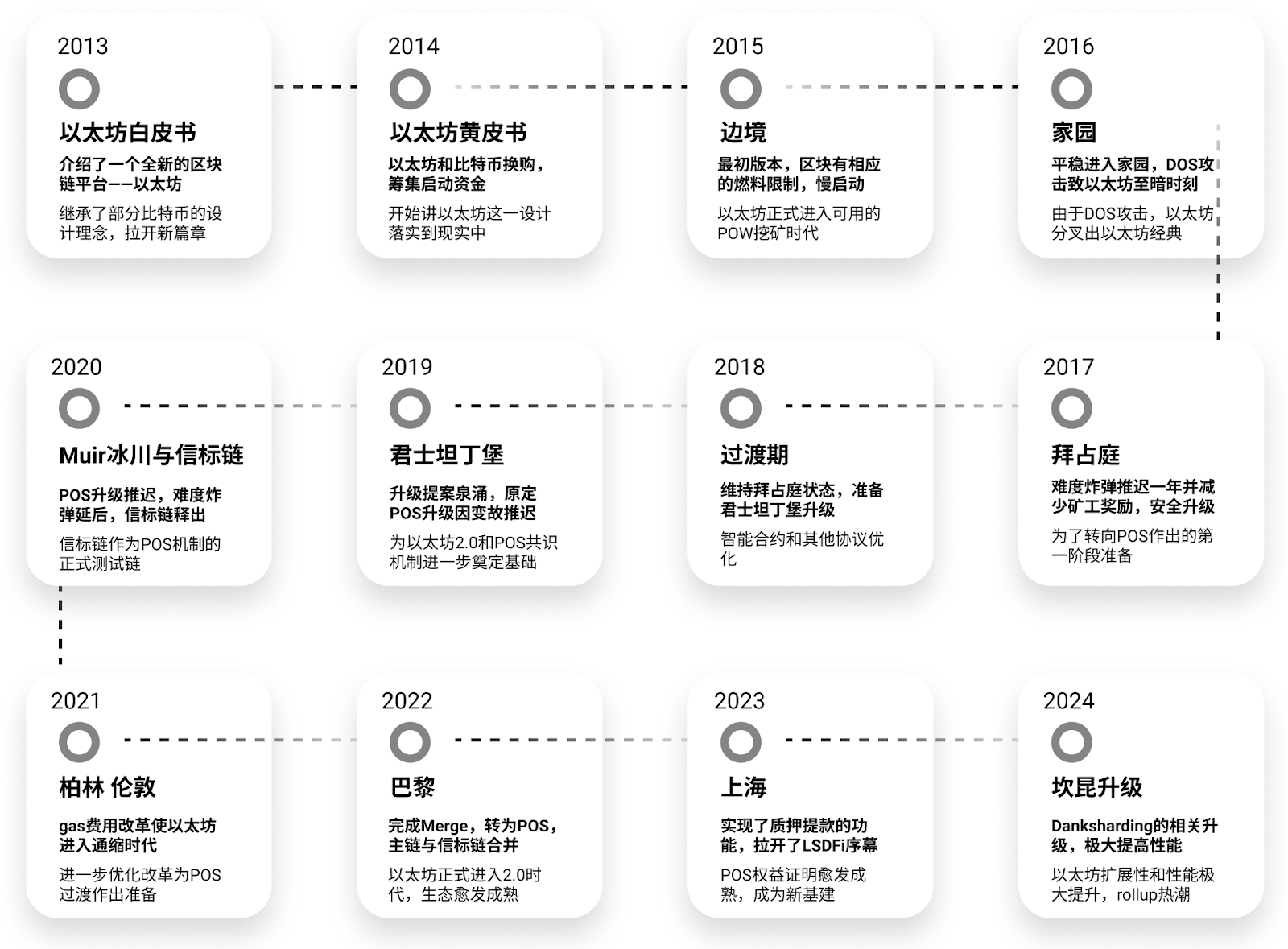
Figure 1 – Retour historique sur Ethereum
Défis auxquels Ethereum fait face
Sécurité
Les contrats intelligents sont des programmes informatiques exécutés sur la blockchain Ethereum. Ils permettent aux développeurs de créer et déployer diverses applications : prêts, échanges décentralisés, assurances, financements participatifs, réseaux sociaux, NFT, etc. La sécurité des contrats intelligents est primordiale pour ces applications, qui gèrent directement des cryptomonnaies. Toute vulnérabilité ou attaque malveillante peut menacer la sécurité des fonds et causer de lourdes pertes financières. Par exemple, le 26 février 2024, le protocole DeFi Blueberry Protocol a été attaqué à cause d’un défaut logique dans son contrat, entraînant une perte d’environ 1,4 million de dollars.
Les vulnérabilités des contrats intelligents sont multiples : logique métier imparfaite, contrôle d’accès insuffisant, validation des données faible, attaques de réentrance, ou encore attaques par déni de service (DoS). Ces failles peuvent compromettre le bon fonctionnement du contrat. Prenons l’exemple d’une attaque DoS : l’attaquant envoie un grand nombre de transactions pour saturer les ressources du réseau. Les transactions normales ne sont alors plus traitées à temps, dégradant l’expérience utilisateur. De plus, cela fait grimper les frais de gaz, car les utilisateurs doivent payer plus cher pour que leurs transactions soient prioritaires lorsque les ressources sont tendues.
En outre, les utilisateurs d’Ethereum font face à des risques d’investissement et à des menaces contre la sécurité de leurs fonds. Par exemple, les « shitcoins » désignent des cryptomonnaies considérées comme presque sans valeur ni potentiel de croissance. Souvent utilisées comme outils de fraude ou pour manipuler les prix (stratégie pump-and-dump), elles présentent un risque élevé pouvant entraîner de lourdes pertes financières. En raison de leur faible prix et capitalisation, elles sont très sensibles à la manipulation et à la volatilité. Ces monnaies servent fréquemment à des escroqueries de type « honeypot » ou « rug pull ». Dans un « rug pull », les créateurs retirent soudainement toute la liquidité du projet, faisant chuter la valeur du jeton. Ces fraudes utilisent souvent de fausses partenariats ou recommandations pour attirer des investisseurs, puis disparaissent après avoir vendu leurs jetons, laissant aux victimes des actifs sans valeur. Investir dans des shitcoins détourne aussi l’attention et les ressources des cryptomonnaies légitimes dotées d’applications réelles et d’un potentiel de croissance.
Outre les shitcoins, les « aircoins » et les cryptomonnaies pyramidales constituent d'autres moyens rapides d’enrichissement. Pour les utilisateurs inexpérimentés, il est particulièrement difficile de les distinguer des cryptomonnaies légitimes.
Efficacité
Deux indicateurs directs de l’efficacité d’Ethereum sont la vitesse des transactions et les frais de gaz. La vitesse des transactions mesure le nombre de transactions que le réseau peut traiter par unité de temps. Elle reflète directement la capacité de traitement : plus elle est élevée, plus l’efficacité est grande. Chaque transaction sur Ethereum nécessite un paiement de gaz, compensant les validateurs pour la vérification. Moins les frais sont élevés, plus le réseau est efficace.
Une baisse de la vitesse des transactions entraîne une hausse des frais de gaz. En effet, lorsque le traitement ralentit, la compétition pour occuper l’espace limité des blocs augmente. Pour se démarquer, les utilisateurs augmentent leurs frais de gaz, car les validateurs privilégient les transactions les mieux rémunérées. Des frais plus élevés nuisent donc à l’expérience utilisateur.
Les transactions ne sont que l’activité de base sur Ethereum. Dans cet écosystème, les utilisateurs peuvent aussi emprunter, staker, investir ou souscrire à des assurances via des dApps spécifiques. Toutefois, en raison de la grande variété de dApps et de l’absence de services personnalisés comparables à ceux des secteurs traditionnels, les utilisateurs peinent à choisir les applications adaptées. Cela nuit à leur satisfaction et affecte l’efficacité globale de l’écosystème Ethereum.
Prenons l’exemple du prêt. Certains protocoles DeFi exigent un mécanisme de sur-collatéralisation pour assurer la sécurité de leur plateforme. Cela oblige les emprunteurs à bloquer plus d’actifs qu’ils n’en empruntent, actifs qui restent immobilisés pendant toute la durée du prêt. Cela diminue l’utilisation des fonds par l’emprunteur et réduit la liquidité du marché.
Applications de l’apprentissage automatique dans Ethereum
Des modèles d’apprentissage automatique tels que le modèle RFM, les réseaux antagonistes génératifs (GAN), les arbres de décision, l’algorithme des k-plus-proches voisins (KNN), ou encore l’algorithme de clustering DBSCAN jouent déjà un rôle important dans Ethereum. Ces modèles peuvent optimiser l’efficacité du traitement des transactions, renforcer la sécurité des contrats intelligents, segmenter les utilisateurs pour des services personnalisés, et contribuer à la stabilité du réseau.
Présentation des algorithmes
Un algorithme d’apprentissage automatique est un ensemble d’instructions permettant d’analyser des données, d’en extraire des motifs et d’en tirer des prédictions ou décisions. Ces algorithmes apprennent automatiquement à partir des données, sans nécessiter de programmation explicite. Des modèles comme RFM, GAN, arbres de décision, KNN ou DBSCAN sont déjà utilisés dans Ethereum. Leur application peut optimiser le traitement des transactions, renforcer la sécurité des contrats, segmenter les utilisateurs pour des services personnalisés, et stabiliser le réseau.
-
Classificateur bayésien
Le classificateur bayésien est une méthode statistique efficace visant à minimiser la probabilité d’erreur de classification ou le risque moyen dans un cadre de coûts donné. Son fondement repose sur le théorème de Bayes, qui permet d’estimer la probabilité qu’un objet appartienne à une classe donnée connaissant certaines caractéristiques. Le classificateur commence par considérer la probabilité a priori, puis applique la formule de Bayes en intégrant les données observées, mettant ainsi à jour la croyance sur la classe de l’objet. Parmi toutes les classes possibles, il choisit celle ayant la probabilité a posteriori maximale. Cette approche gère naturellement l’incertitude et les informations incomplètes, ce qui en fait un outil puissant et flexible applicable à de nombreux domaines.
Comme illustré à la figure 2, dans l’apprentissage supervisé, le modèle probabiliste basé sur le théorème de Bayes permet de décider de la classification. En combinant vraisemblance, probabilités a priori des classes et des caractéristiques, le classificateur calcule la probabilité a posteriori de chaque classe et assigne le point de données à celle ayant la plus forte probabilité. Dans le nuage de points à droite, le classificateur cherche à tracer une courbe séparant au mieux les points de couleurs différentes, minimisant ainsi les erreurs de classification.
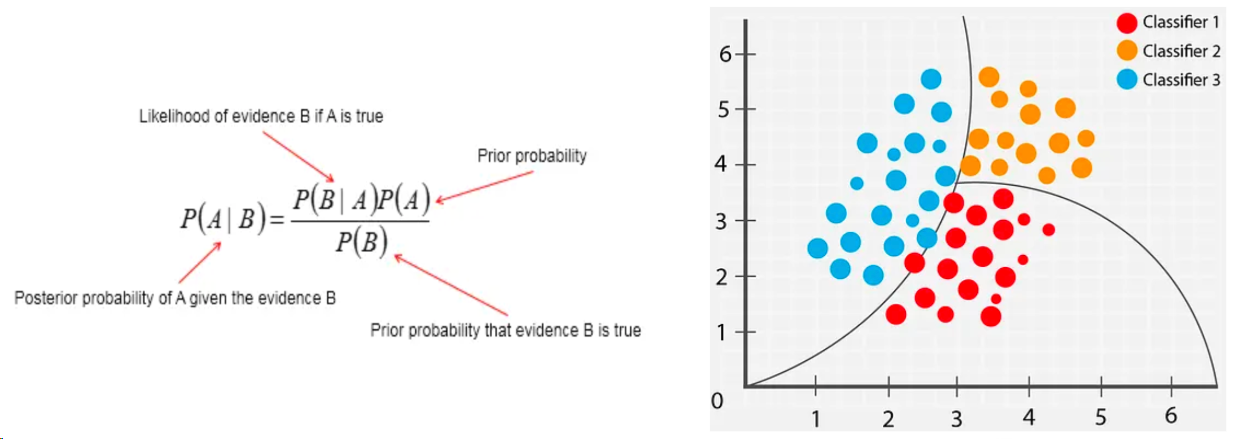
Figure 2 – Classificateur bayésien
-
Arbre de décision
L’algorithme d’arbre de décision est couramment utilisé pour les tâches de classification et de régression. Il suit une logique hiérarchique, divisant les données selon les caractéristiques offrant le plus grand gain d’information, afin de construire un arbre. En somme, l’algorithme apprend automatiquement des règles décisionnelles à partir des données, décomposant un processus complexe en plusieurs sous-décisions simples. Chaque décision simple découle d’un critère parent, formant une structure arborescente.
Comme visible à la figure 3, chaque nœud représente une décision basée sur un critère d’attribut, chaque branche un résultat possible. Chaque feuille représente le résultat final de prédiction ou de classification. Du point de vue algorithmique, le modèle d’arbre de décision est intuitif, facile à comprendre et fortement interprétable.
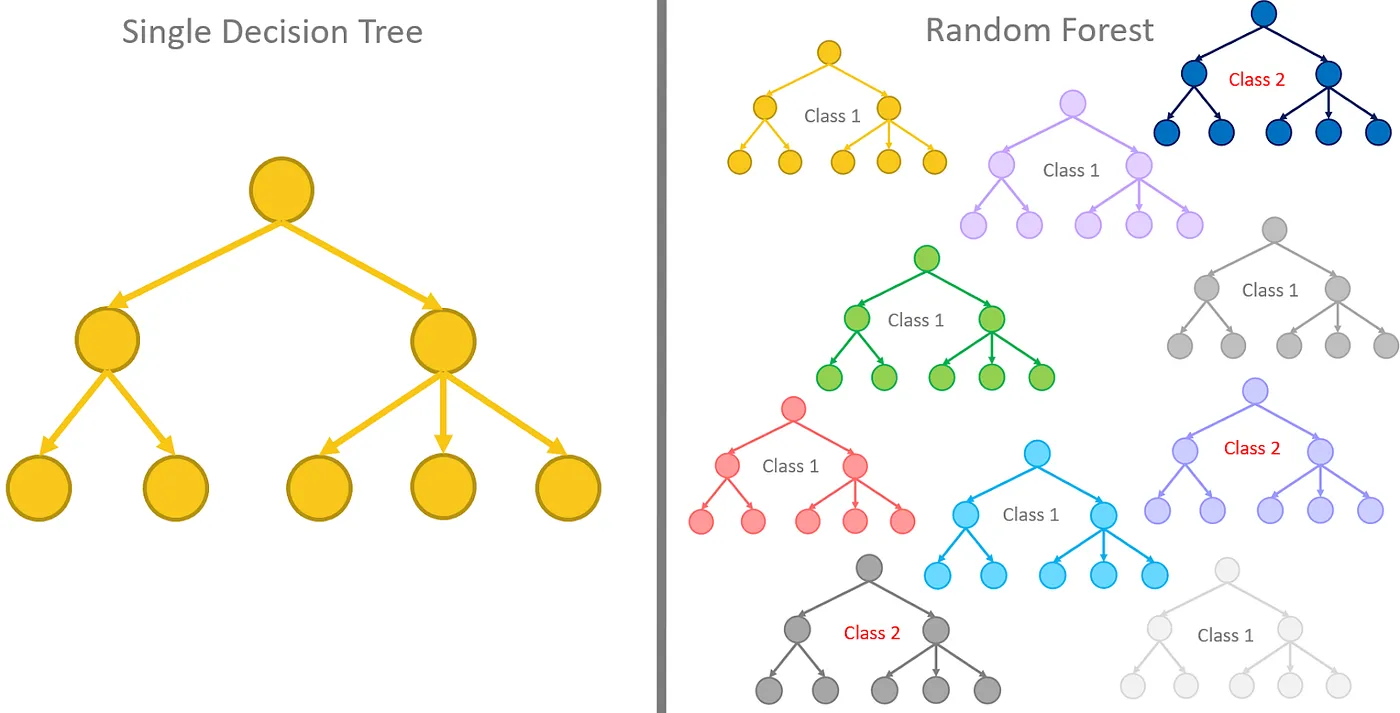
Figure 3 – Modèle d’arbre de décision
-
Algorithme DBSCAN
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) est un algorithme de clustering spatial basé sur la densité, particulièrement efficace sur des ensembles de données non connexes. Il peut découvrir des grappes de forme arbitraire sans connaître au préalable leur nombre, et présente une bonne robustesse aux valeurs aberrantes. DBSCAN identifie efficacement les points anormaux dans des données bruitées, définis comme des points situés dans des zones de faible densité, comme illustré à la figure 4.
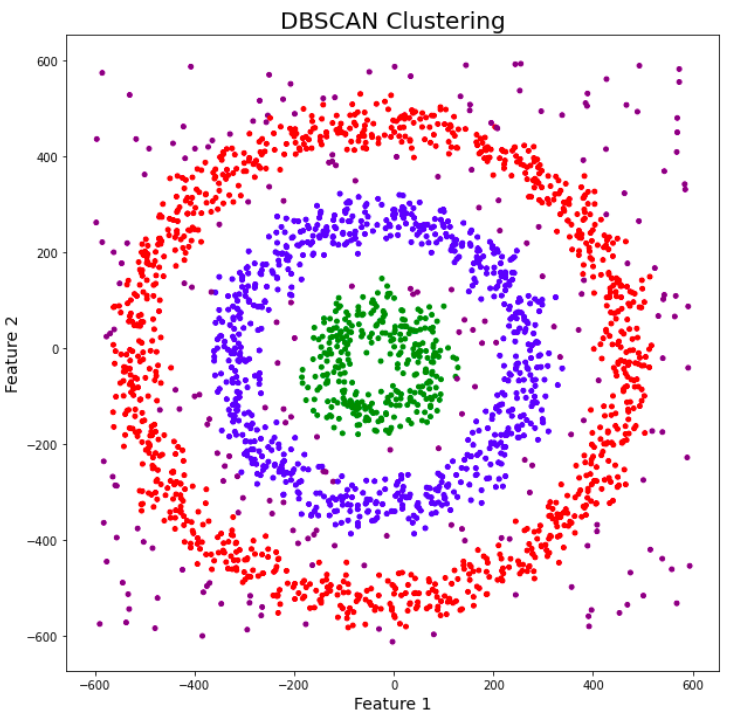
Figure 4 – DBSCAN détectant les bruits
-
Algorithme KNN
L’algorithme KNN (K-plus-proches voisins) sert à la fois à la classification et à la régression. En classification, il utilise un mécanisme de vote pour déterminer la catégorie d’un élément ; en régression, il calcule la moyenne ou moyenne pondérée des k voisins les plus proches.
Comme montré à la figure 5, le principe de KNN en classification consiste à trouver les k voisins les plus proches d’un nouveau point, puis à prédire sa catégorie selon celle de ces voisins. Si K=1, le point est attribué à la catégorie de son voisin le plus proche. Si K>1, une règle de vote majoritaire est appliquée : le point est assigné à la catégorie la plus représentée parmi ses voisins. En régression, le résultat est la moyenne des valeurs des k voisins.
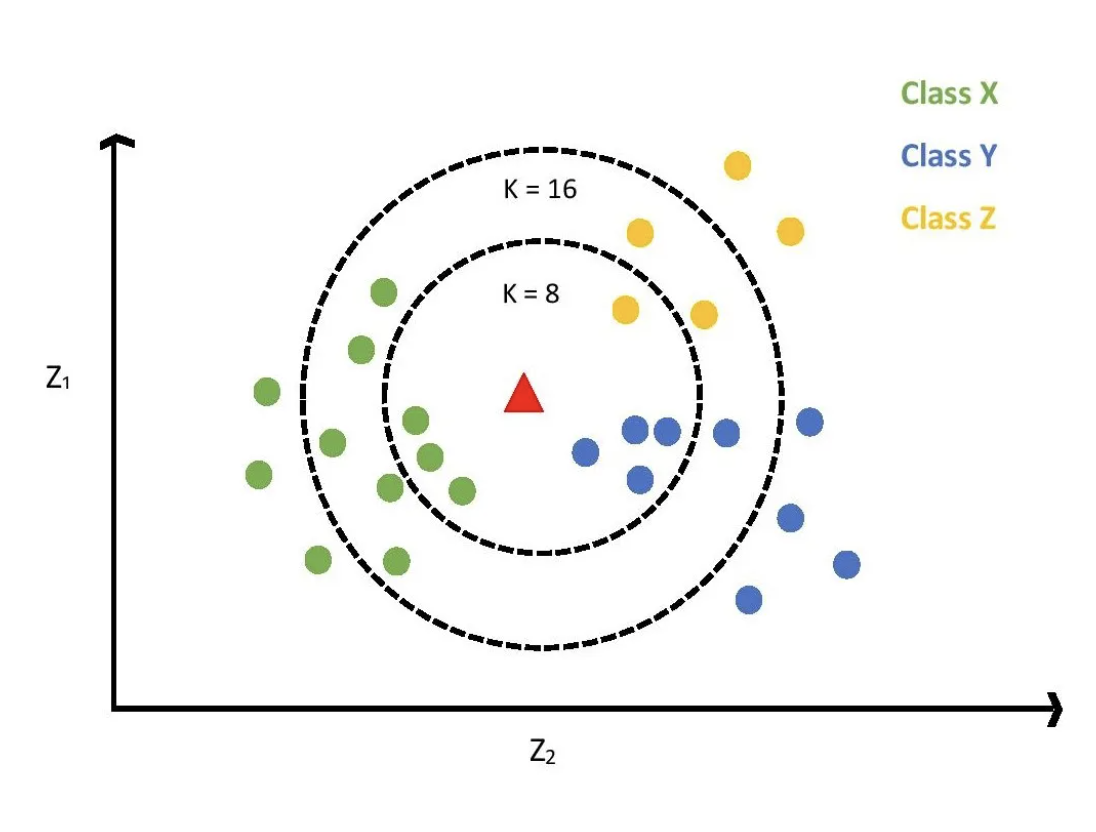
Figure 5 – KNN appliqué à la classification
-
Intelligence artificielle générative
L’intelligence artificielle générative est une technologie d’IA capable de produire de nouveaux contenus (textes, images, musique, etc.) à partir d’entrées spécifiées. Fondée sur les progrès de l’apprentissage automatique et du deep learning, notamment en traitement du langage naturel et reconnaissance d’images, elle apprend des motifs et corrélations dans de vastes jeux de données pour générer de nouveaux contenus originaux. La clé réside dans l’entraînement du modèle, qui nécessite des données de qualité. Au fil de l’analyse de la structure, des motifs et des relations dans les données, le modèle affine progressivement sa capacité à générer du contenu nouveau.
-
Transformer
Le Transformer, pilier de l’IA générative, a introduit de façon novatrice le mécanisme d’attention, permettant à la fois de se concentrer sur les éléments clés et de considérer le contexte global. Cette capacité unique a fait briller les Transformers dans la génération de texte. En utilisant les derniers modèles de traitement du langage naturel, comme GPT (Generative Pre-trained Transformer), il devient possible de comprendre les besoins exprimés en langage naturel par les utilisateurs et de les convertir automatiquement en code exécutable, réduisant ainsi la difficulté du développement et augmentant fortement l’efficacité.
Comme illustré à la figure 6, l’introduction du mécanisme d’attention multi-têtes et auto-attention, combiné aux connexions résiduelles et aux réseaux neuronaux entièrement connectés, ainsi qu’aux techniques antérieures d’embedding de mots, a permis un bond spectaculaire des performances des modèles génératifs liés au traitement du langage.
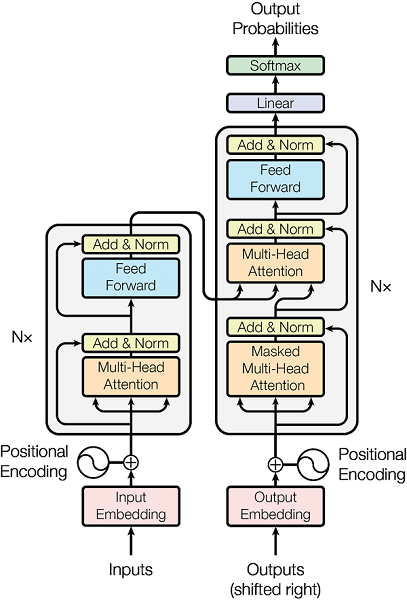
Figure 6 – Modèle Transformer
-
Modèle RFM
Le modèle RFM est un outil d’analyse basé sur le comportement d’achat des utilisateurs, permettant d’identifier différents groupes de valeur. Il segmente les utilisateurs selon trois critères : la date de la dernière transaction (Recency), la fréquence des achats (Frequency), et le montant total dépensé (Monetary value).
Comme illustré à la figure 7, ces trois indicateurs forment le cœur du modèle RFM. Chaque utilisateur reçoit une note selon ces dimensions, puis est classé par ordre décroissant pour identifier les segments les plus précieux. Ce modèle permet une segmentation efficace des clients.
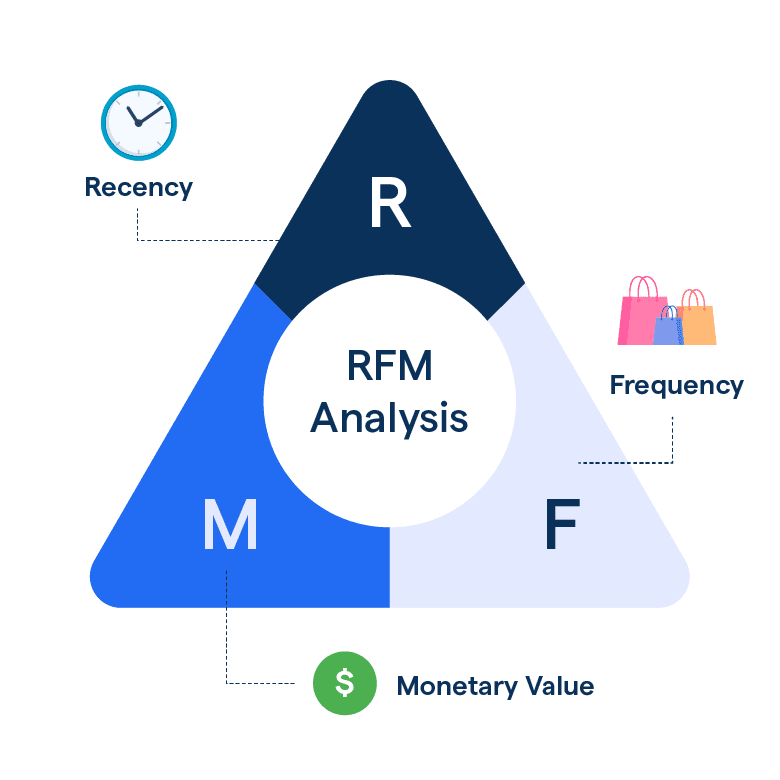
Figure 7 – Modèle de segmentation RFM
Applications possibles
Dans notre recherche sur l’utilisation de l’apprentissage automatique pour relever les défis de sécurité d’Ethereum, nous avons exploré quatre axes principaux :
-
Identification et filtrage des transactions malveillantes via un classificateur bayésien
En construisant un classificateur bayésien, il est possible d’identifier et de filtrer les transactions suspectes, notamment les transactions massives, fréquentes et à petit montant susceptibles de provoquer des attaques DoS. Cette méthode, en analysant des caractéristiques telles que le prix du gaz ou la fréquence des transactions, contribue efficacement à maintenir la santé du réseau et à assurer la stabilité d’Ethereum.
-
Générer du code de contrat intelligent sécurisé répondant à des exigences spécifiques
Les réseaux antagonistes génératifs (GAN) et les réseaux génératifs basés sur Transformer peuvent tous deux générer du code de contrat intelligent conforme à des exigences précises, tout en maximisant la sécurité. Toutefois, ils diffèrent par le type de données utilisées pour l’entraînement : les GAN s’appuient principalement sur des exemples de code non sécurisés, tandis que les modèles basés sur Transformer utilisent des exemples de code sécurisé.
En entraînant un GAN à reconnaître des modèles de contrats sûrs et en construisant un modèle auto-antagoniste générant des codes potentiellement dangereux, on peut ensuite entraîner le modèle à détecter ces vulnérabilités, aboutissant à une génération automatique de contrats intelligents de haute qualité et plus sûrs. Quant aux modèles génératifs basés sur Transformer, ils apprennent à partir de grands volumes de contrats sécurisés pour générer du code adapté à des besoins précis, optimisé en consommation de gaz, ce qui améliore encore l’efficacité et la sécurité du développement.
-
Analyse des risques des contrats intelligents via un arbre de décision
L’analyse des caractéristiques d’un contrat intelligent — comme la fréquence d’appel des fonctions, la valeur des transactions ou la complexité du code source — via un arbre de décision permet d’identifier efficacement son niveau de risque potentiel. En étudiant les modes d’exécution et la structure du code, on peut anticiper les vulnérabilités et points critiques, fournissant ainsi une évaluation utile aux développeurs et utilisateurs. Cette approche pourrait significativement renforcer la sécurité des contrats intelligents dans l’écosystème Ethereum, réduisant les pertes dues à des failles ou du code malveillant.
-
Construction d’un modèle d’évaluation des cryptomonnaies pour réduire les risques d’investissement
En exploitant des algorithmes d’apprentissage automatique pour analyser des données multidimensionnelles — transactions, activités sur les réseaux sociaux, performance sur le marché — on peut construire un modèle prédictif estimant la probabilité qu’une cryptomonnaie soit une « shitcoin ». Ce modèle fournirait une aide précieuse aux investisseurs pour éviter les pièges, favorisant ainsi un développement sain du marché des cryptomonnaies.
Par ailleurs, l’apprentissage automatique peut aussi améliorer l’efficacité d’Ethereum. Nous pouvons explorer trois dimensions clés :
-
Optimisation du modèle de file d’attente dans la mempool via un arbre de décision
Un arbre de décision peut efficacement optimiser la file d’attente des transactions dans la mempool d’Ethereum. En analysant des caractéristiques comme le prix du gaz ou la taille de la transaction, l’arbre peut optimiser le choix et l’ordre des transactions. Cette méthode améliore nettement l’efficacité du traitement, réduit la congestion du réseau et diminue le temps d’attente pour les utilisateurs.
-
Segmentation des utilisateurs et services personnalisés
Le modèle RFM (Récent, Fréquence, Valeur monétaire), outil bien établi en gestion relation client, permet de segmenter les utilisateurs selon trois critères : date de la dernière transaction (Recency), fréquence des transactions (Frequency) et montant total (Monetary value). Appliqué à Ethereum, ce modèle permettrait d’identifier les utilisateurs à forte valeur, d’optimiser l’allocation des ressources et d’offrir des services plus personnalisés, améliorant ainsi la satisfaction utilisateur et l’efficacité globale de la plateforme.
L’algorithme DBSCAN peut aussi analyser le comportement transactionnel des utilisateurs pour identifier différents groupes, permettant ainsi d’offrir des services financiers plus adaptés. Cette stratégie de segmentation optimise les campagnes marketing, la satisfaction client et l’efficacité du service.
-
Évaluation de crédit basée sur l’algorithme KNN
L’algorithme des k-plus-proches voisins (KNN) peut analyser l’historique et les comportements transactionnels des utilisateurs d’Ethereum pour leur attribuer un score de crédit, crucial dans les activités financières comme le prêt. Ce score aide les institutions financières et plateformes de prêt à évaluer la capacité de remboursement et le risque de crédit des emprunteurs, permettant des décisions de prêt plus précises. Cela limite les prêts excessifs et am
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News












