
Sora fait son apparition, 2024 sera-t-il l'année zéro de la révolution AI+Web3 ?
TechFlow SélectionTechFlow Sélection
Sora fait son apparition, 2024 sera-t-il l'année zéro de la révolution AI+Web3 ?
Quelles étincelles peuvent jaillir de l'entrelacement entre Web3 et l'IA ?
Auteur : YBB Capital Zeke

Préambule
Le 16 février, OpenAI a dévoilé son dernier modèle de diffusion pour la génération vidéo contrôlée par texte, « Sora », qui marque une nouvelle étape majeure dans l'histoire de l'IA générative. Grâce à des vidéos de haute qualité générées à partir d'une grande variété de données visuelles, Sora illustre un progrès significatif. Contrairement aux outils comme Pika, qui génèrent encore quelques secondes de vidéo à partir d’images multiples, Sora s'entraîne dans un espace latent compressé combinant vidéos et images, en les décomposant en « patches » spatio-temporels, permettant ainsi une génération vidéo évolutive. De plus, ce modèle montre une capacité à simuler aussi bien le monde physique que le monde numérique. La démo de 60 secondes présentée peut légitimement être qualifiée de « simulateur universel du monde physique ».
Sur le plan technique, Sora suit la trajectoire déjà empruntée par les modèles GPT : « données brutes – Transformer – Diffusion – émergence ». Cela signifie que, comme auparavant, sa maturation repose sur la puissance de calcul. Or, puisque l'entraînement vidéo nécessite bien plus de données que l'entraînement textuel, la demande en puissance de calcul va encore croître. Dans un précédent article intitulé « Perspectives sur les secteurs prometteurs : marchés décentralisés de puissance de calcul », nous avions déjà souligné l'importance cruciale de la puissance de calcul à l'ère de l'IA. Avec la montée récente de l'engouement autour de l'IA, de nombreux projets liés au calcul ont vu le jour, tandis que d'autres projets Depin (stockage, calcul, etc.) en bénéficient indirectement et connaissent une forte hausse. Alors, au-delà des projets Depin, quelles autres synergies entre Web3 et IA peuvent émerger ? Quelles opportunités cette convergence recèle-t-elle ? L'objectif principal de cet article est de mettre à jour et compléter nos analyses précédentes, tout en explorant les possibilités qu'offre le Web3 à l'ère de l'IA.
Les trois grandes directions historiques du développement de l'IA
L'intelligence artificielle (IA) est une science technologique émergente visant à simuler, étendre et amplifier l'intelligence humaine. Depuis ses origines dans les années 1950-1960, après plus d'un demi-siècle d'évolution, elle est devenue une technologie clé transformant la société et tous les secteurs économiques. Au cours de ce parcours, les trois courants principaux — le symbolisme, le connexionnisme et le behaviorisme — se sont entrelacés, formant aujourd'hui la base du développement accéléré de l'IA.
Symbolisme (Symbolism)
Également appelé « logicisme » ou « approche par règles », il considère qu'il est possible de simuler l'intelligence humaine par le traitement de symboles. Cette méthode représente les objets, concepts et leurs relations au sein d'un domaine donné à l'aide de symboles, puis utilise le raisonnement logique pour résoudre des problèmes. Elle a obtenu des succès notables dans les systèmes experts et la représentation des connaissances. Le postulat central du symbolisme est que les comportements intelligents peuvent être réalisés par manipulation de symboles et inférence logique, où les symboles constituent une abstraction élevée du monde réel.
Connexionnisme (Connectionism)
Appelé aussi « méthode des réseaux neuronaux », il vise à reproduire l'intelligence en imitant la structure et le fonctionnement du cerveau humain. Cette approche construit des réseaux composés de nombreuses unités simples (analogues aux neurones), dont les connexions (similaires aux synapses) sont ajustées durant l'apprentissage. Le connexionnisme met particulièrement l'accent sur la capacité d'apprendre à partir des données et de généraliser, ce qui le rend très efficace pour la reconnaissance de formes, la classification ou encore les tâches de mappage entrée-sortie continue. L'apprentissage profond (deep learning), évolution du connexionnisme, a permis des percées décisives dans des domaines comme la reconnaissance d'image, la reconnaissance vocale ou le traitement du langage naturel.
Behaviorisme (Behaviorism)
Le behaviorisme est étroitement lié à la robotique biomimétique et aux systèmes autonomes intelligents. Il insiste sur l'idée qu'un agent intelligent peut apprendre par interaction avec son environnement. Contrairement aux deux approches précédentes, il ne cherche pas à modéliser les représentations internes ou les processus mentaux, mais favorise plutôt un cycle perpétuel de perception et d'action afin de produire des comportements adaptatifs. Selon cette vision, l'intelligence émerge du dialogue dynamique entre l'agent et son environnement. Cette approche s'avère particulièrement efficace pour les robots mobiles ou les systèmes de contrôle adaptatifs devant opérer dans des environnements complexes et imprévisibles.
Bien que ces trois courants diffèrent fondamentalement, ils interagissent et se combinent souvent dans la recherche et les applications pratiques de l'IA, contribuant ensemble à son avancement.
Principes généraux de l'AIGC
L'IA générative (Artificial Intelligence Generated Content, ou AIGC), en pleine expansion actuellement, constitue une évolution et une application du connexionnisme. L'AIGC est capable d'imiter la créativité humaine pour produire des contenus originaux. Ces modèles sont entraînés sur de vastes jeux de données à l’aide d’algorithmes d’apprentissage profond, leur permettant d’apprendre les structures sous-jacentes, relations et motifs présents dans les données. À partir d’une requête utilisateur, ils génèrent des sorties nouvelles et uniques, telles que des images, vidéos, code, musique, designs, traductions, réponses à des questions ou textes. Actuellement, l’AIGC repose essentiellement sur trois piliers : l’apprentissage profond (Deep Learning, DL), les mégadonnées et une puissance de calcul à grande échelle.
Apprentissage profond
L’apprentissage profond est un sous-domaine de l’apprentissage automatique (machine learning). Les algorithmes d’apprentissage profond s’inspirent du modèle du cerveau humain via des réseaux neuronaux. Tout comme le cerveau humain contient des millions de neurones interconnectés qui collaborent pour traiter l’information, les réseaux neuronaux profonds (ou réseaux neuronaux artificiels) sont constitués de plusieurs couches de neurones artificiels travaillant ensemble dans un ordinateur. Ces neurones artificiels, appelés nœuds, sont des modules logiciels utilisant des calculs mathématiques pour traiter les données. Les réseaux neuronaux artificiels sont donc des algorithmes d’apprentissage profond utilisant ces nœuds pour résoudre des problèmes complexes.
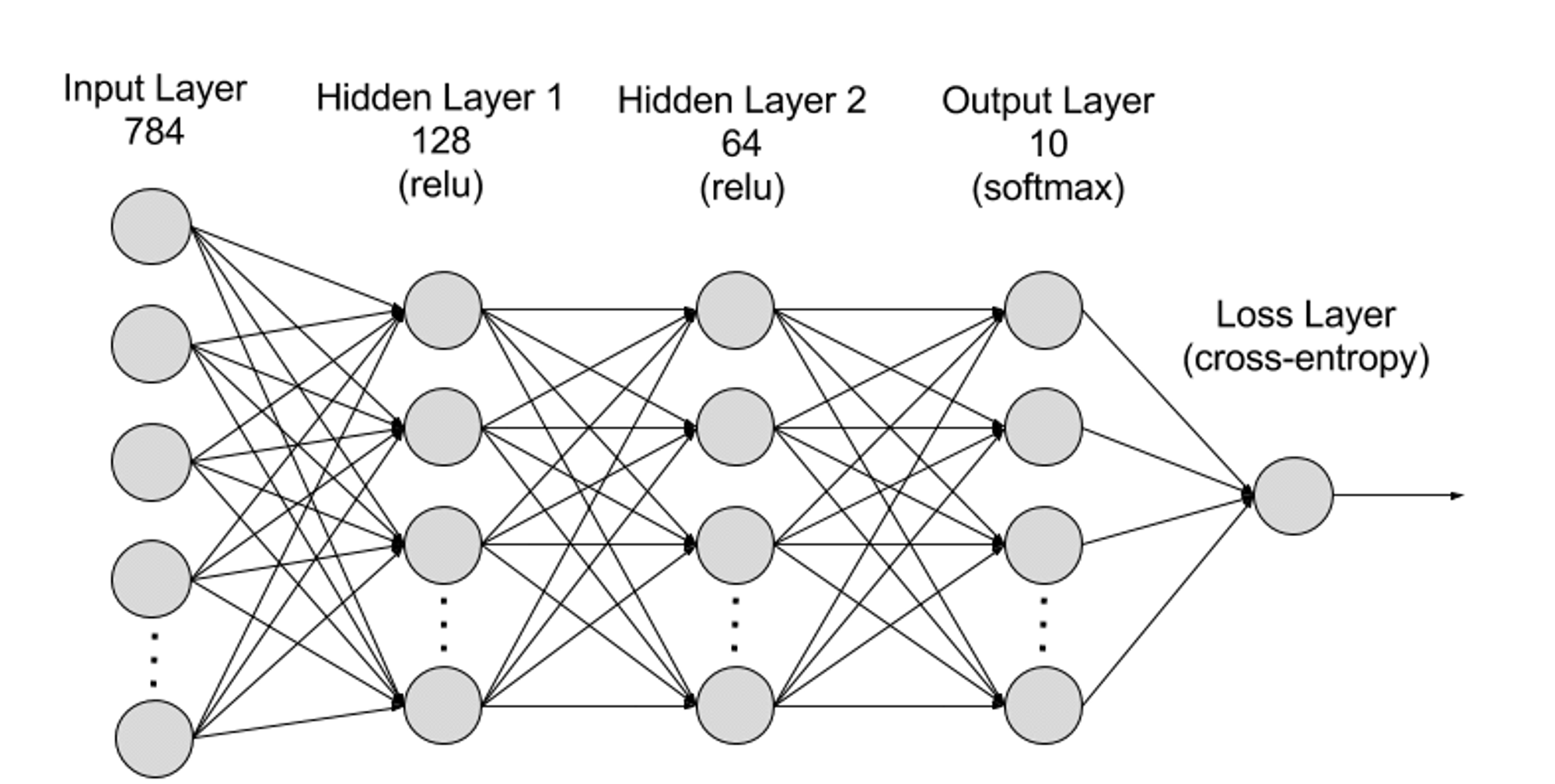
D’un point de vue structurel, un réseau neuronal comporte une couche d’entrée, une ou plusieurs couches cachées, et une couche de sortie. Les connexions entre ces couches sont définies par des paramètres.
● Couche d’entrée (Input Layer) : Première couche du réseau, elle reçoit les données externes. Chaque neurone correspond à une caractéristique des données d’entrée. Par exemple, dans le cas d’une image, chaque neurone pourrait représenter la valeur d’un pixel.
● Couche cachée (Hidden Layer) : Traite les données provenant de la couche d’entrée et les transmet aux couches suivantes. Ces couches analysent l’information à différents niveaux d’abstraction et ajustent leur comportement lorsqu’elles reçoivent de nouvelles données. Un réseau profond peut contenir des centaines de couches cachées, permettant d’analyser un problème sous divers angles. Par exemple, pour classifier une image d’un animal inconnu, on pourrait comparer la forme des oreilles, le nombre de pattes ou la taille des pupilles. De même, chaque couche cachée d’un réseau profond traite une caractéristique spécifique de l’image pour tenter une classification précise.
● Couche de sortie (Output Layer) : Dernière couche du réseau, elle produit le résultat final. Chaque neurone représente une classe ou une valeur de sortie possible. Par exemple, dans une tâche de classification, chaque neurone correspond à une catégorie ; dans une tâche de régression, il peut y avoir un seul neurone dont la valeur représente la prédiction.
● Paramètres : Les connexions entre les couches sont définies par des poids (weights) et des biais (biases). Pendant l’entraînement, ces paramètres sont optimisés afin que le réseau identifie correctement les motifs dans les données et effectue des prédictions précises. L’augmentation du nombre de paramètres augmente la capacité du modèle, c’est-à-dire sa capacité à apprendre et représenter des motifs complexes. En revanche, cela intensifie également la demande en puissance de calcul.
Mégadonnées
Pour un entraînement efficace, les réseaux neuronaux nécessitent généralement de grandes quantités de données variées, de haute qualité et provenant de sources multiples. Elles constituent la base de l’entraînement et de la validation des modèles d’apprentissage automatique. En analysant ces mégadonnées, les modèles peuvent découvrir les motifs et relations présents, permettant ainsi des prédictions ou classifications.
Puissance de calcul à grande échelle
La structure complexe et multicouche des réseaux neuronaux, le grand nombre de paramètres, les besoins massifs en traitement de données, la méthode itérative d’entraînement (où le modèle doit effectuer plusieurs passes avant et arrière, incluant le calcul des fonctions d’activation, de la fonction de perte, des gradients et la mise à jour des poids), les exigences de calcul en haute précision, les capacités de calcul parallèle, les techniques d’optimisation et de régularisation, ainsi que les phases d’évaluation et de validation du modèle — tout cela combine pour créer une forte dépendance à la puissance de calcul.

Sora
En tant que dernier modèle d’IA générative vidéo publié par OpenAI, Sora marque un progrès majeur dans la capacité de l’intelligence artificielle à traiter et comprendre des données visuelles variées. En utilisant un réseau de compression vidéo et une technique de « patches » spatio-temporels, Sora convertit en un format uniforme les masses de données visuelles provenant du monde entier et capturées par divers appareils, permettant ainsi un traitement et une compréhension efficaces de contenus visuels complexes. Basé sur un modèle de diffusion conditionné par texte, Sora génère des vidéos ou images parfaitement alignées avec les indications textuelles, démontrant une créativité et une adaptabilité remarquables.
Toutefois, malgré ses avancées dans la génération vidéo et la simulation d’interactions du monde réel, Sora présente encore certaines limites : précision de la simulation physique, cohérence dans la génération de longues vidéos, compréhension d’instructions textuelles complexes, ainsi que l’efficacité de l’entraînement et de la génération. En réalité, Sora repose toujours sur la puissance de calcul monopolistique et l’avantage du premier entrant d’OpenAI, prolongeant ainsi la « voie classique » de « mégadonnées – Transformer – Diffusion – émergence » sous une forme de « beauté violente ». D’autres entreprises d’IA conservent néanmoins la possibilité de rattraper ou de dépasser techniquement via des innovations de rupture.
Bien que Sora n’ait pas de lien direct avec la blockchain, je pense que, dans les un ou deux ans à venir, son impact poussera à l’émergence rapide d’autres outils de génération IA de haute qualité, influençant notamment les secteurs Web3 tels que GameFi, les réseaux sociaux, les plateformes de création et les projets Depin. Comprendre Sora est donc essentiel. Comment l’IA future pourra-t-elle s’intégrer efficacement au Web3 ? Voilà une question clé à méditer.
Quatre voies de convergence entre IA et Web3
Comme mentionné ci-dessus, les fondations nécessaires à l’IA générative se résument à trois éléments : algorithmes, données et puissance de calcul. D’autre part, l’IA, par sa polyvalence et son efficacité, constitue un outil révolutionnaire des modes de production. En revanche, les deux principales forces du blockchain sont la restructuration des rapports de production et la décentralisation. Le croisement de ces deux mondes peut selon moi emprunter quatre chemins principaux :
Calcul décentralisé
Étant donné que j’ai déjà écrit précédemment sur ce sujet, cette section vise surtout à faire un point sur l’état actuel du secteur du calcul. Lorsqu’on parle d’IA, la puissance de calcul reste un élément incontournable. Après l’arrivée de Sora, la demande en puissance de calcul devient presque inconcevable. Récemment, lors du Forum économique mondial de Davos 2024, Sam Altman, PDG d’OpenAI, a affirmé sans détour que la puissance de calcul et l’énergie sont actuellement les deux principaux freins, et que leur importance future sera équivalente à celle de la monnaie. Peu après, le 10 février, Sam Altman a annoncé sur Twitter un projet stupéfiant : lever 7 000 milliards de dollars (soit environ 40 % du PIB chinois en 2023) pour redessiner l’industrie mondiale des semi-conducteurs et fonder un empire des puces. Lorsque j’écrivais sur le sujet, mon imagination était limitée par les blocages nationaux et les monopoles des géants. Mais qu’une seule entreprise veuille désormais dominer toute l’industrie mondiale des semi-conducteurs semble véritablement fou.
Ainsi, l’importance du calcul décentralisé devient évidente. Les caractéristiques du blockchain peuvent effectivement résoudre les problèmes de monopole extrême de la puissance de calcul et du coût élevé des GPU spécialisés. Du point de vue des besoins de l’IA, l’utilisation du calcul se divise en deux axes : entraînement et inférence. Les projets axés sur l’entraînement restent très rares, car ils exigent une conception réseau décentralisée compatible avec les réseaux neuronaux et des ressources matérielles très élevées — une barrière d’entrée élevée et difficile à concrétiser. L’inférence, en revanche, est bien plus simple : la conception du réseau décentralisé est moins complexe, et les exigences matérielles et en bande passante sont moindres, ce qui en fait actuellement la voie dominante.
Le marché centralisé du calcul a un potentiel énorme, souvent associé au mot-clé « de l’ordre du trillion », et constitue l’un des sujets les plus spéculés à l’ère de l’IA. Pourtant, parmi les nombreux projets récents, la majorité semblent lancés à la hâte, surfant simplement sur la tendance. Ils brandissent fièrement le drapeau de la décentralisation, mais ignorent soigneusement les problèmes d’inefficacité inhérents aux réseaux décentralisés. De plus, leurs conceptions sont fortement homogènes — beaucoup adoptent un modèle standard (couche 2 + minage) — ce qui risque de mener à un gâchis généralisé. Dans ces conditions, espérer conquérir une part du marché traditionnel de l’IA semble difficile.
Systèmes collaboratifs d’algorithmes et de modèles
Les algorithmes d’apprentissage machine sont capables d’extraire des régularités et des motifs à partir des données pour ensuite effectuer des prédictions ou des décisions. Ce sont des technologies très exigeantes, car leur conception et optimisation nécessitent des compétences spécialisées et une innovation constante. Ils constituent le cœur de l’entraînement des modèles d’IA, définissant comment transformer les données en informations exploitables. Parmi les algorithmes d’IA générative courants, citons les réseaux antagonistes génératifs (GAN), les autoencodeurs variationnels (VAE) ou les Transformers. Chaque algorithme est conçu pour un domaine spécifique (dessin, reconnaissance vocale, traduction, génération vidéo) ou un objectif précis, puis utilisé pour entraîner des modèles spécialisés.
Avec autant d’algorithmes et de modèles aux forces différentes, pouvons-nous les intégrer en un modèle全能 capable de tout faire ? Bittensor, très en vogue récemment, est un leader dans cette direction. Grâce à un système d’incitation par minage, il encourage la collaboration et l’apprentissage mutuel entre différents modèles et algorithmes d’IA, visant à créer des modèles plus performants et universels. D’autres projets comme Commune AI (collaboration de code) suivent une logique similaire. Toutefois, pour les entreprises d’IA actuelles, les algorithmes et modèles sont des atouts stratégiques gardés jalousement, rarement prêtés ou partagés.
Ainsi, l’idée d’un écosystème collaboratif est fascinante : elle exploite les forces du blockchain pour surmonter l’isolement des algorithmes d’IA. Mais sa capacité à créer une valeur réelle reste incertaine. Les grands acteurs comme OpenAI, avec leurs algorithmes fermés, possèdent une capacité d’innovation, de mise à jour et d’intégration extrêmement rapide. En deux ans seulement, OpenAI est passé des modèles de génération textuelle à des modèles multi-domaines. Des projets comme Bittensor devront donc trouver des niches spécifiques ou adopter des stratégies alternatives.
Big data décentralisé
Du point de vue simple, utiliser des données privées pour nourrir l’IA ou les annoter constitue une direction très compatible avec la blockchain. Il suffit de veiller à éviter les données polluées ou malveillantes. Sur le plan du stockage, des projets Depin comme FIL ou AR peuvent également en bénéficier. Plus subtilement, l’utilisation des données blockchain pour l’apprentissage machine (ML) afin de résoudre leur accessibilité est une piste intéressante (l’un des axes explorés par Giza).
Théoriquement, les données blockchain sont accessibles à tout moment et reflètent l’état complet du réseau. Pourtant, pour ceux extérieurs à l’écosystème, accéder à ces volumes massifs de données reste difficile. Le stockage complet d’une blockchain exige des connaissances pointues et des ressources matérielles importantes. Pour pallier cela, plusieurs solutions sont apparues : les fournisseurs RPC offrent un accès via des API, tandis que les services d’indexation permettent d’extraire les données via SQL ou GraphQL. Ces méthodes jouent un rôle clé, mais ont leurs limites. Les services RPC ne conviennent pas aux scénarios à forte densité de requêtes, souvent incapables de répondre à la demande. Quant aux services d’indexation, bien qu’ils proposent un accès structuré, la complexité des protocoles Web3 rend l’écriture de requêtes efficaces extrêmement ardue, parfois nécessitant des centaines, voire des milliers de lignes de code complexes. Cette barrière technique est un obstacle majeur pour les professionnels des données ou les passionnés peu familiers du Web3. Ces limitations cumulées montrent clairement le besoin d’une méthode plus accessible et utilisable des données blockchain, propice à une innovation plus large.
En combinant ZKML (preuve à connaissance nulle appliquée à l’apprentissage machine, réduisant la charge sur la chaîne) avec des données blockchain de haute qualité, on pourrait créer des jeux de données facilitant l’accessibilité blockchain. L’IA pourrait alors drastiquement abaisser cette barrière. Avec le temps, développeurs, chercheurs et amateurs de ML pourraient accéder à davantage de jeux de données pertinents et de qualité, permettant de concevoir des solutions innovantes et efficaces.
Applications DApp renforcées par l’IA
Depuis l’essor de ChatGPT-3 en 2023, l’intégration de l’IA dans les DApps est devenue une direction très courante. Grâce à leur grande polyvalence, les IA génératives peuvent être intégrées via API pour simplifier et rendre intelligents des plateformes d’analyse de données, des robots de trading, des encyclopédies blockchain, etc. Elles peuvent aussi jouer le rôle de chatbot (ex. Myshell), d’assistant IA (Sleepless AI), voire créer des PNJ dans des jeux blockchain. Toutefois, le seuil technologique étant faible, la plupart des projets se contentent d’intégrer une API puis d’ajuster légèrement, sans une intégration profonde au projet, ce qui explique qu’ils soient rarement mis en avant.
Mais avec l’arrivée de Sora, je pense que les directions IA + GameFi (y compris métavers) et IA + plateformes de création seront particulièrement stratégiques à l’avenir. En raison de la nature ascendante (bottom-up) du Web3, il était difficile d’imaginer la naissance de produits capables de rivaliser avec les jeux traditionnels ou les sociétés créatives. Sora pourrait justement briser cette impasse (peut-être en deux à trois ans). À en juger par sa démo, Sora possède déjà un potentiel concurrentiel face aux producteurs de mini-séries. La culture communautaire active du Web3 peut générer de nombreuses idées originales, et lorsque la seule limite devient l’imagination, la frontière entre les industries ascendantes et descendantes (top-down) s’effacera.
Conclusion
Avec les progrès continus des outils d’IA générative, nous vivrons encore de nombreux moments « iPhone » révolutionnaires. Bien que beaucoup regardent avec scepticisme la convergence entre IA et Web3, je pense personnellement que les orientations actuelles sont globalement pertinentes. Les véritables défis à résoudre se résument à trois points : la nécessité, l’efficacité et la complémentarité. Bien que cette fusion en soit encore à ses balbutiements, elle pourrait bien devenir le moteur principal du prochain marché haussier.
Conserver une curiosité et une ouverture d’esprit suffisantes face aux nouveautés est une attitude indispensable. Historiquement, le passage de la voiture aux chariots a été fulgurant. Tout comme les inscriptions ou les NFT par le passé, trop de préjugés ne font que nous priver d’opportunités.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News











