

Galaxy Digital : Comprendre la convergence entre les cryptomonnaies et l'intelligence artificielle
TechFlow SélectionTechFlow Sélection
Galaxy Digital : Comprendre la convergence entre les cryptomonnaies et l'intelligence artificielle
L'apparition des blockchains publiques est l'une des avancées les plus profondes de l'histoire de l'informatique, et le développement de l'intelligence artificielle aura, et a déjà, un impact profond sur notre monde.
Rédaction : Lucas Tcheyan
Traduction : Block unicorn
Introduction
L'émergence des blockchains publiques constitue l'une des avancées les plus profondes de l'histoire de l'informatique. Parallèlement, le développement de l'intelligence artificielle (IA) exerce et exercera une influence considérable sur notre monde. Si la technologie blockchain offre un nouveau modèle pour le règlement des transactions, le stockage des données et la conception de systèmes, l'IA quant à elle révolutionne le calcul, l'analyse et la diffusion de contenu. Les innovations dans ces deux secteurs libèrent de nouveaux cas d'utilisation qui pourraient accélérer leur adoption respective au cours des prochaines années. Ce rapport explore l'intégration croissante entre les cryptomonnaies et l'IA, en mettant l'accent sur les cas d'usage novateurs cherchant à combler l'écart entre ces deux domaines et tirer parti de leurs forces combinées. Plus précisément, il examine des projets axés sur les protocoles de calcul décentralisé, les infrastructures de machine learning à preuve de connaissance (zkML), ainsi que les agents d'IA.
Les cryptomonnaies offrent à l’IA une couche de règlement ouverte, sans autorisation préalable ni besoin de confiance, tout en étant hautement composable. Cela permet des cas d’utilisation tels que l’accès facilité au matériel via des systèmes de calcul décentralisés, la création d’agents d’IA capables d’exécuter des tâches complexes impliquant des échanges de valeur, ou encore le développement de solutions d’identité et de traçabilité destinées à contrer les attaques Sybil et les deepfakes. À l’inverse, l’IA apporte aux cryptomonnaies de nombreux avantages similaires à ceux observés dans le Web 2, notamment une amélioration significative de l’expérience utilisateur (UX) grâce à des grands modèles linguistiques (comme ChatGPT ou Copilot spécialement entraînés), ainsi qu’un renforcement du potentiel fonctionnel et automatisé des contrats intelligents. La blockchain fournit un environnement riche en données transparentes, exactement ce dont l’IA a besoin. Toutefois, sa capacité limitée en matière de calcul constitue un obstacle majeur à l’intégration directe de modèles d’IA.
Les expérimentations en cours et l’adoption future à la croisée des cryptomonnaies et de l’IA sont motivées par les mêmes facteurs qui soutiennent les cas d’usage les plus prometteurs des cryptomonnaies : l’accès à une couche de coordination ouverte, sans permission ni besoin de confiance, favorisant davantage le transfert de valeur. Étant donné leur potentiel immense, les acteurs de ce domaine doivent comprendre les modes fondamentaux selon lesquels ces deux technologies interagissent.
Points clés :
-
À court terme (entre 6 mois et 1 an), l’intégration entre cryptomonnaies et IA sera dominée par des applications d’IA visant à améliorer l’efficacité des développeurs, l’auditabilité et la sécurité des contrats intelligents, ainsi que l’accessibilité pour les utilisateurs. Ces intégrations ne sont pas exclusives aux cryptomonnaies, mais elles enrichissent néanmoins l’expérience des développeurs et des utilisateurs sur chaîne.
-
Face à la pénurie critique de GPU haute performance, les produits de calcul décentralisé développent des offres spécifiquement adaptées à l’IA, stimulant ainsi leur adoption.
-
L’expérience utilisateur et la réglementation restent des obstacles à l’attractivité des clients pour le calcul décentralisé. Toutefois, les derniers développements d’OpenAI et l’examen réglementaire en cours aux États-Unis soulignent la valeur proposition des réseaux d’IA décentralisés, résistants à la censure et ouverts à tous.
-
L’intégration de l’IA sur chaîne, notamment via des contrats intelligents capables d’utiliser des modèles d’IA, nécessite des avancées techniques en zkML et d’autres méthodes permettant de vérifier efficacement les calculs hors chaîne. Le manque d’outils complets, de talents développeurs et les coûts élevés constituent des freins majeurs.
-
Les agents d’IA s’adaptent naturellement aux cryptomonnaies, car les utilisateurs (ou les agents eux-mêmes) peuvent créer des portefeuilles afin d’interagir avec d’autres services, agents ou personnes. Cette possibilité est inenvisageable avec les circuits financiers traditionnels. Pour une adoption plus large, des intégrations supplémentaires avec des produits non liés aux cryptomonnaies seront nécessaires.
Terminologie
Intelligence artificielle (IA) : utilisation du calcul et des machines pour imiter les capacités humaines de raisonnement et de résolution de problèmes.
Réseaux de neurones : méthode d’entraînement des modèles d’IA. Ils traitent les entrées à travers plusieurs couches algorithmiques successives, en les affinant jusqu’à obtenir la sortie souhaitée. Constitués d’équations dotées de poids modifiables, ils nécessitent souvent d’importantes quantités de données et de puissance de calcul pour être formés avec précision. Il s’agit de l’une des approches les plus courantes pour développer des modèles d’IA (par exemple, ChatGPT repose sur un réseau de neurones utilisant l’architecture Transformer).
Entraînement : processus de développement des réseaux de neurones et autres modèles d’IA. Il requiert de grandes masses de données pour former correctement le modèle à interpréter les entrées et produire des sorties fiables. Pendant cette phase, les poids des équations du modèle sont ajustés continuellement jusqu’à atteindre un résultat satisfaisant. L’entraînement peut être extrêmement coûteux. Par exemple, ChatGPT utilise des dizaines de milliers de GPU propres pour traiter les données. Les équipes disposant de ressources limitées dépendent généralement de fournisseurs spécialisés comme Amazon Web Services, Azure ou Google Cloud.
Inference (inférence) : utilisation effective d’un modèle d’IA pour générer une sortie ou un résultat (par exemple, utiliser ChatGPT pour rédiger un plan sur l’intersection entre cryptomonnaies et IA). L’inférence intervient à la fois durant le processus d’entraînement et dans le produit final. Bien que moins intensive en calcul que l’entraînement, son coût reste élevé en raison des ressources nécessaires, même après la fin de l’entraînement.
Preuve de connaissance nulle (ZKP) : permet de vérifier une affirmation sans divulguer les informations sous-jacentes. Dans le domaine des cryptomonnaies, cela présente deux intérêts principaux : 1) la confidentialité, et 2) la mise à l’échelle. En matière de confidentialité, cela permet aux utilisateurs d’effectuer des transactions sans révéler d’informations sensibles (par exemple, le montant d’ETH détenu dans un portefeuille). Concernant la mise à l’échelle, cela permet de valider rapidement sur chaîne des calculs réalisés hors chaîne, évitant ainsi leur réexécution complète. Ainsi, les blockchains et applications peuvent effectuer des calculs économiquement hors chaîne puis les vérifier sur chaîne. Pour en savoir plus sur les ZKPs et leur rôle dans la machine virtuelle Ethereum, consulter le rapport de Christine Kim intitulé « zkEVMs : l’avenir de la scalabilité d’Ethereum ».
Cartographie du marché IA / cryptomonnaies

Les projets d’intégration entre IA et cryptomonnaies sont encore en phase de construction des infrastructures fondamentales nécessaires à des interactions massives d’IA sur chaîne.
Des marchés de calcul décentralisés émergent pour fournir le matériel physique intensif requis par l’entraînement et l’inférence des modèles d’IA, principalement sous forme d’unités de traitement graphique (GPU). Ces marchés bidirectionnels connectent les propriétaires de ressources informatiques et ceux qui cherchent à en louer, facilitant ainsi le transfert de valeur et la vérification des calculs. Au sein du calcul décentralisé, plusieurs sous-catégories apparaissent avec des fonctionnalités supplémentaires. Outre les marchés bilatéraux, ce rapport examinera également des fournisseurs spécialisés dans la formation vérifiable et l’affinement des modèles, ainsi que des projets visant à relier calcul et génération de modèles pour l’IA — souvent appelés réseaux d’incitation intelligente.
Le zkML constitue un domaine émergent pour les projets souhaitant fournir des sorties de modèles vérifiables sur chaîne, de manière économique et rapide. Ces projets permettent essentiellement à des applications de gérer des demandes de calcul lourdes hors chaîne, puis de publier sur chaîne des résultats vérifiables attestant que le travail hors chaîne a été effectué intégralement et avec précision. Actuellement, le zkML reste coûteux et lent, mais son utilisation croissante comme solution se confirme, notamment à travers le nombre croissant d’intégrations entre fournisseurs de zkML et applications DeFi ou jeux voulant exploiter des modèles d’IA.
Une offre suffisante de ressources de calcul et la capacité de vérifier les opérations sur chaîne ouvrent la voie aux agents d’IA sur chaîne. Un agent est un modèle entraîné capable d’agir au nom d’un utilisateur pour accomplir des tâches. Les agents offrent une opportunité majeure d’améliorer l’expérience sur chaîne, permettant aux utilisateurs d’effectuer des transactions complexes simplement via une conversation avec un chatbot. Pour l’instant toutefois, les projets d’agents restent centrés sur le développement d’infrastructures et d’outils facilitant leur déploiement rapide et simple.
Calcul décentralisé
Aperçu général
L’IA nécessite d’importantes ressources informatiques pour entraîner des modèles et effectuer des inférences. Durant la dernière décennie, la complexité croissante des modèles a fait exploser la demande en puissance de calcul. Par exemple, OpenAI a constaté que la demande en calcul pour ses modèles est passée d’un doublement tous les deux ans entre 2012 et 2018 à un doublement tous les trois mois et demi. Cela a provoqué une flambée de la demande pour les GPU, poussant certains mineurs de cryptomonnaies à réutiliser leurs GPU pour proposer des services de cloud computing. Face à l’intensification de la concurrence et à la hausse des prix, certains projets exploitent la technologie des cryptomonnaies pour proposer des solutions de calcul décentralisé. Ils offrent un accès à la demande à des ressources informatiques à des prix compétitifs, permettant aux équipes d’entraîner et d’exécuter des modèles à moindre coût. Toutefois, cela peut s’accompagner de compromis en termes de performances ou de sécurité.
La demande pour les GPU haut de gamme (notamment ceux fabriqués par Nvidia) est particulièrement forte. En septembre, Tether a acquis une participation dans le mineur allemand Northern Data, qui aurait dépensé 420 millions de dollars pour acheter 10 000 GPU H100 (l’un des GPU les plus avancés pour l’entraînement d’IA). Le délai d’attente pour obtenir du matériel de pointe peut atteindre six mois ou plus. Pire encore, les entreprises sont souvent contraintes de signer des contrats à long terme pour des volumes de calcul qu’elles n’utiliseront peut-être jamais. Cela crée des situations où des ressources sont disponibles mais inaccessibles sur le marché. Les systèmes de calcul décentralisés aident à corriger ces inefficiences en créant un marché secondaire, où les propriétaires de ressources peuvent revendre instantanément leur capacité excédentaire dès qu’elle est disponible, libérant ainsi une nouvelle offre.
Outre les prix compétitifs et l’accessibilité, la proposition de valeur clé du calcul décentralisé réside dans sa résistance à la censure. Le développement de l’IA de pointe est de plus en plus dominé par de grandes entreprises technologiques disposant d’un accès sans précédent aux données et à la puissance de calcul. Le premier thème mis en lumière par le rapport annuel 2023 sur l’indice de l’IA était la suprématie croissante du secteur industriel sur le monde académique dans le développement des modèles d’IA, concentrant le pouvoir entre les mains de quelques leaders technologiques. Cela suscite des inquiétudes quant à leur capacité à influencer fortement les normes et valeurs intégrées dans les modèles d’IA, surtout après que certaines entreprises aient cherché à imposer une réglementation limitant tout développement d’IA qu’elles ne pourraient contrôler.
Sous-secteurs du calcul décentralisé
Plusieurs modèles de calcul décentralisé ont émergé ces dernières années, chacun ayant ses priorités et compromis propres.

Calcul généraliste
Des projets comme Akash, io.net, iExec ou Cudos sont des applications de calcul décentralisé qui offrent ou vont bientôt offrir un accès à des ressources informatiques dédiées à l’entraînement et à l’inférence en IA, en plus de solutions générales de stockage et de calcul.
Akash est actuellement la seule plateforme « super-cloud » entièrement open source. Il s’agit d’un réseau basé sur la preuve d’enjeu utilisant le SDK Cosmos. AKT est le jeton natif d’Akash, servant à la fois de moyen de paiement, de protection de la sécurité du réseau et d’incitation à la participation. Lancé en 2020 avec son premier réseau principal, Akash s’est initialement concentré sur la création d’un marché de cloud computing sans permission, proposant d’abord du stockage et de la location de CPU. En juin 2023, Akash a lancé un nouveau testnet axé sur les GPU, suivi en septembre par le lancement du réseau principal GPU, permettant aux utilisateurs de louer des GPU pour l’entraînement et l’inférence en IA.
Deux types d’acteurs principaux composent l’écosystème Akash : les locataires et les fournisseurs. Les locataires sont les utilisateurs du réseau Akash souhaitant acquérir des ressources informatiques. Les fournisseurs sont les prestataires de ressources. Pour apparier locataires et fournisseurs, Akash s’appuie sur un processus d’enchères inversées. Le locataire soumet ses exigences de calcul, précisant éventuellement certaines conditions (localisation du serveur, type de matériel, etc.) et le montant qu’il est prêt à payer. Les fournisseurs soumettent ensuite leurs offres, et celui proposant le prix le plus bas remporte la tâche.
Les validateurs Akash assurent l’intégrité du réseau. Le nombre de validateurs est actuellement limité à 100, avec un plan d’augmentation progressive. N’importe qui peut devenir validateur en bloquant plus de jetons AKT que le validateur actuellement le moins bien enjoué. Les détenteurs d’AKT peuvent aussi déléguer leurs jetons à un validateur. Les frais de transaction et les récompenses de bloc sont distribués en AKT. En outre, pour chaque location, le réseau Akash perçoit une « taxe de service » définie par la communauté, redistribuée aux détenteurs d’AKT.
Marchés secondaires
Les marchés de calcul décentralisés visent à combler les inefficiences des marchés informatiques existants. La rareté de l’offre pousse les entreprises à accumuler des ressources excédant leurs besoins réels, tandis que la structure contractuelle des fournisseurs de cloud verrouille les clients dans des engagements à long terme, limitant encore davantage l’offre accessible. Les plateformes de calcul décentralisé libèrent une nouvelle offre, permettant à toute personne possédant des ressources informatiques de devenir fournisseur.
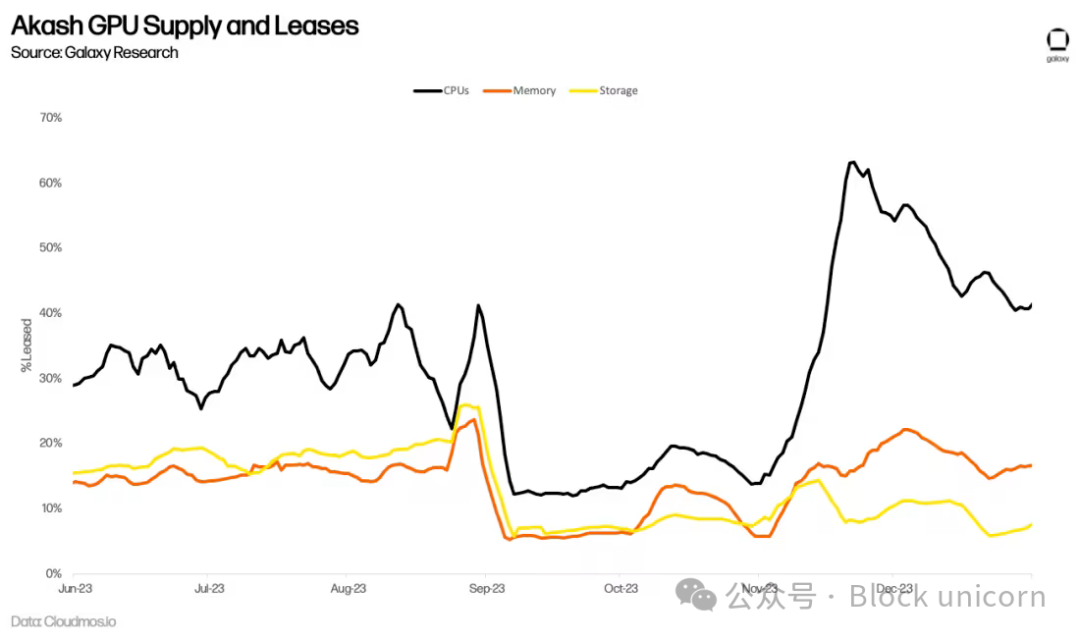
Il reste à voir si la demande croissante pour les GPU liée à l’entraînement en IA se traduira par une utilisation durable du réseau Akash. Par exemple, Akash propose depuis longtemps un marché de CPU offrant des services comparables aux alternatives centralisées avec des rabais de 70 à 80 %. Pourtant, ces prix réduits n’ont pas conduit à une adoption significative. Le nombre de locations actives a stagné, et au deuxième trimestre 2023, seulement 33 % du calcul, 16 % de la mémoire et 13 % du stockage étaient utilisés en moyenne. Bien que ces chiffres soient impressionnants en termes d’adoption sur chaîne (à titre de comparaison, Filecoin, le principal fournisseur de stockage, affichait un taux d’utilisation de 12,6 % au troisième trimestre 2023), ils indiquent que l’offre dépasse encore la demande.
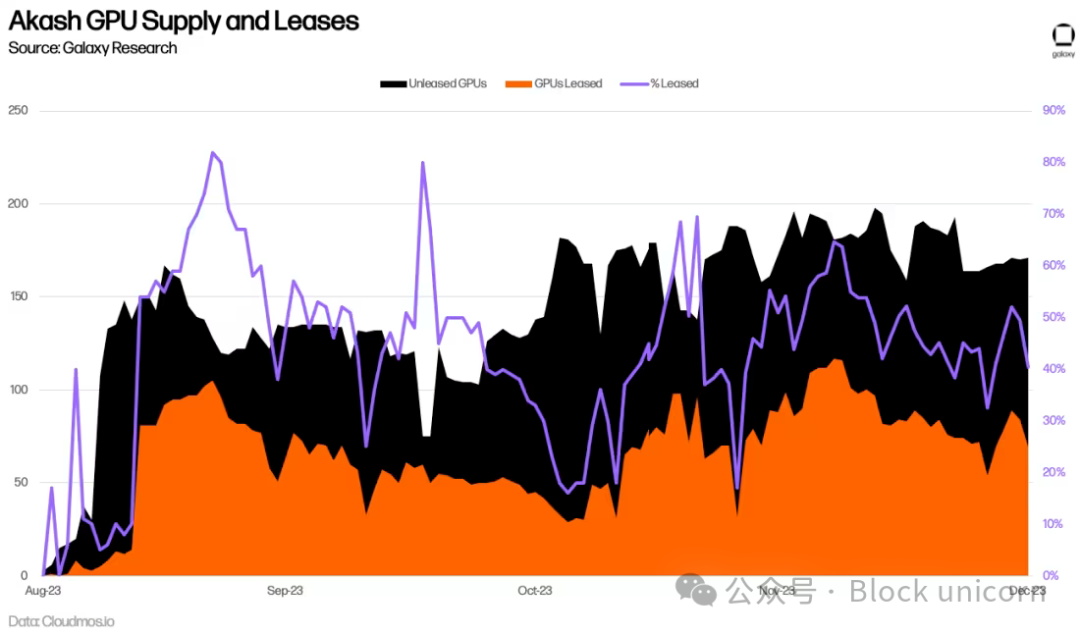
Plus de six mois se sont écoulés depuis le lancement du réseau GPU d’Akash, et il est donc encore trop tôt pour évaluer précisément son taux d’adoption à long terme. Jusqu’à présent, l’utilisation moyenne des GPU atteint 44 %, dépassant celle des CPU, de la mémoire et du stockage — un signe positif de demande. Cette utilisation est principalement portée par la forte demande pour les GPU de très haute qualité (comme les A100), dont plus de 90 % sont déjà loués.
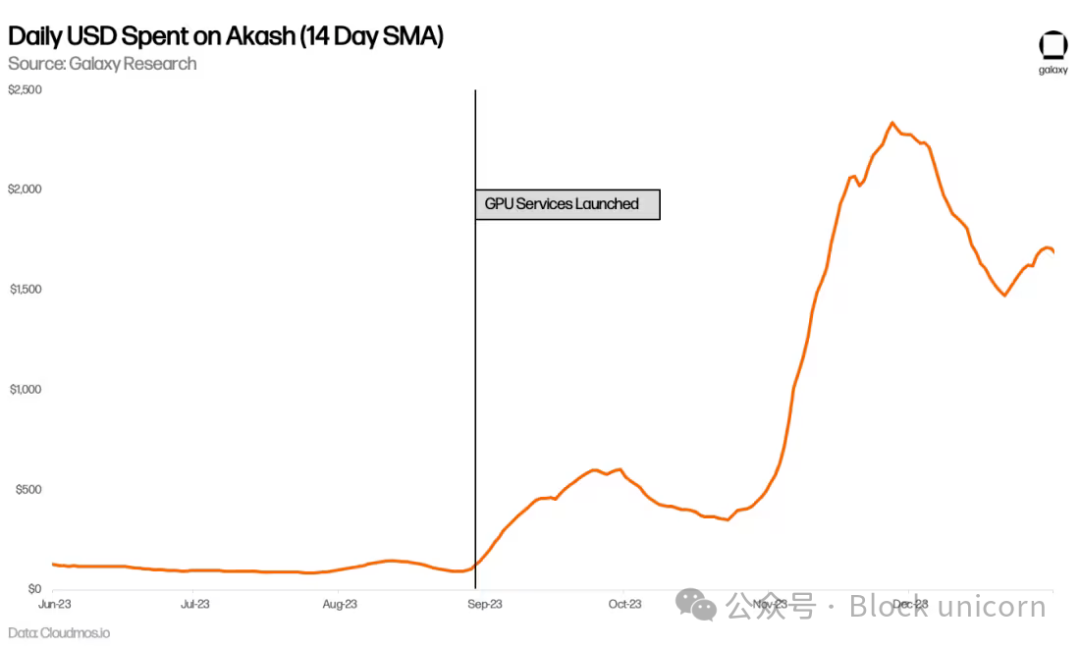
Les dépenses quotidiennes sur Akash ont également augmenté, presque doublant par rapport à la période précédant l’arrivée des GPU. Cela s’explique partiellement par une hausse de l’utilisation d’autres services, notamment les CPU, mais principalement par la nouvelle demande en GPU.
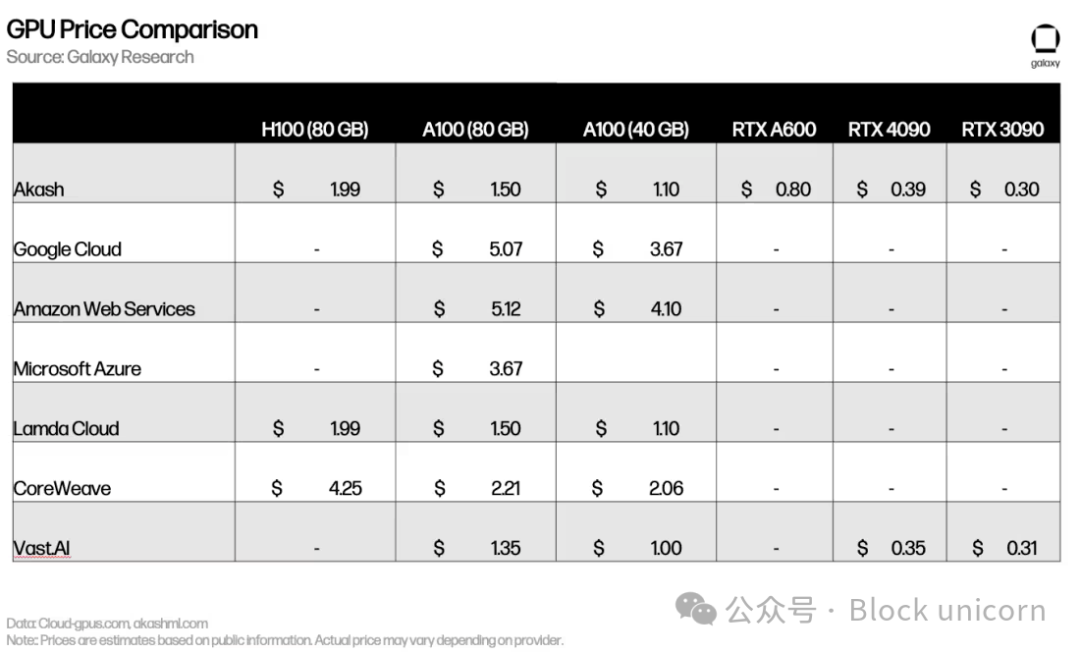
Les prix sont comparables (voire parfois supérieurs) à ceux des concurrents centralisés comme Lambda Cloud ou Vast.ai. La forte demande pour les GPU haut de gamme (H100, A100) signifie que la plupart de leurs propriétaires n’ont guère d’intérêt à les proposer sur un marché concurrentiel.
Bien que les premiers indicateurs soient encourageants, des obstacles subsistent (discutés plus bas). Les réseaux de calcul décentralisé doivent faire davantage pour générer à la fois demande et offre. Les équipes expérimentent différentes stratégies pour attirer de nouveaux utilisateurs. Par exemple, début 2024, Akash a adopté la proposition 240, augmentant l’émission de jetons AKT aux fournisseurs de GPU afin d’encourager davantage d’offre, notamment pour les GPU haut de gamme. L’équipe travaille également à déployer des modèles de preuve de concept pour montrer en temps réel les capacités de son réseau. Akash entraîne actuellement son propre modèle de base et a déjà lancé un chatbot et un outil de génération d’images utilisant les GPU Akash. De même, io.net a développé un modèle Stable Diffusion et lance de nouvelles fonctionnalités pour mieux refléter les performances et l’échelle du réseau.
Formation décentralisée en apprentissage machine
Outre les plateformes de calcul généralistes capables de répondre aux besoins en IA, un ensemble de fournisseurs spécialisés en GPU pour l’apprentissage machine émerge. Par exemple, Gensyn cherche à « coordonner l’énergie et le matériel pour construire une intelligence collective », selon le principe que « si quelqu’un souhaite entraîner quelque chose, et que quelqu’un d’autre est prêt à l’entraîner, alors cet entraînement devrait pouvoir avoir lieu ».
Le protocole compte quatre acteurs principaux : les soumissionnaires, les solveurs, les vérificateurs et les dénonciateurs. Les soumissionnaires envoient au réseau des tâches accompagnées d’une demande d’entraînement. Ces tâches incluent l’objectif d’entraînement, le modèle à entraîner et les données nécessaires. Lors de la soumission, les soumissionnaires doivent prépayer une estimation des ressources de calcul requises par les solveurs.
Une fois soumise, la tâche est attribuée à un solveur chargé d’entraîner réellement le modèle. Le solveur renvoie ensuite le travail terminé à un vérificateur, dont le rôle est de s’assurer que l’entraînement a été correctement réalisé. Les dénonciateurs ont pour mission de garantir que les vérificateurs agissent honnêtement. Pour inciter les dénonciateurs à participer, Gensyn prévoit de diffuser régulièrement des preuves intentionnellement fausses, récompensant ceux qui les détectent.
Au-delà de la fourniture de ressources informatiques pour des tâches liées à l’IA, la proposition de valeur clé de Gensyn réside dans son système de vérification, encore en développement. Pour s’assurer que les calculs externes des fournisseurs de GPU sont correctement exécutés (c’est-à-dire que le modèle est bien entraîné comme souhaité), une vérification est indispensable. Gensyn adopte une approche innovante, utilisant une méthode de vérification originale appelée « preuve probabiliste d’apprentissage, protocole basé sur des graphes et jeu d’incitations à la Truebit ». Il s’agit d’un modèle optimiste, permettant aux vérificateurs de confirmer que les solveurs ont correctement exécuté le modèle sans avoir à le relancer entièrement eux-mêmes — un processus coûteux et inefficace.
Outre sa méthode de vérification innovante, Gensyn affirme offrir un meilleur rapport coût-efficacité par rapport aux alternatives centralisées et aux concurrents cryptographiques : ses tarifs d’entraînement en ML seraient jusqu’à 80 % moins chers qu’AWS, tout en surpassant des projets similaires comme Truebit lors de tests.

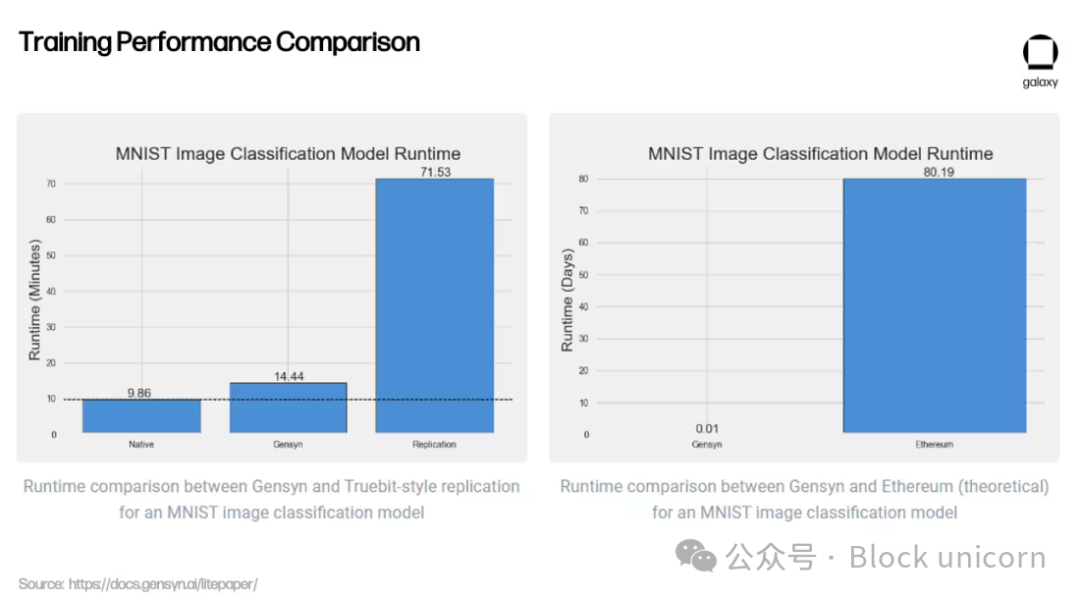
Il reste à voir si ces résultats préliminaires pourront être reproduits à grande échelle sur un réseau décentralisé. Gensyn espère exploiter l’excédent de puissance de calcul provenant de petits centres de données, d’utilisateurs individuels, voire à terme de téléphones mobiles. Toutefois, comme l’admet l’équipe de Gensyn, la dépendance à des fournisseurs hétérogènes pose de nouveaux défis.
Pour des fournisseurs centralisés comme Google Cloud ou Coreweave, le calcul est coûteux, mais la communication entre unités de calcul (bande passante et latence) est bon marché. Ces systèmes sont conçus pour maximiser la rapidité de communication entre les matériels. Gensyn inverse cette logique : en permettant à n’importe qui dans le monde de fournir des GPU, il réduit le coût du calcul, mais augmente celui de la communication, car le réseau doit désormais coordonner des tâches de calcul sur des matériels hétérogènes distants. Gensyn n’a pas encore été lancé, mais il illustre ce qui pourrait être possible dans le cadre d’un protocole décentralisé d’apprentissage machine.
Intelligence générale décentralisée
Les plateformes de calcul décentralisé ouvrent également la voie à de nouvelles approches de conception de l’IA. Bittensor est un protocole de calcul décentralisé basé sur Substrate qui cherche à répondre à la question : « Comment transformer l’IA en une méthode collaborative ? » Son objectif est de décentraliser et de rendre commune la génération d’intelligence artificielle. Lancé en 2021, Bittensor entend exploiter la puissance de modèles collaboratifs d’apprentissage machine pour itérer continuellement et produire une IA de meilleure qualité.
Bittensor s’inspire de Bitcoin : sa monnaie native, TAO, a une offre maximale de 21 millions d’unités, avec un halving tous les quatre ans (le premier aura lieu en 2025). Plutôt que d’utiliser la preuve de travail pour trouver un nombre aléatoire correct et obtenir une récompense de bloc, Bittensor repose sur une « preuve d’intelligence », exigeant des mineurs qu’ils exécutent des modèles pour générer des réponses à des requêtes d’inférence.
Incentivisation de l’intelligence
Initialement, Bittensor s’appuyait sur un modèle dit « Mixte d’experts » (MoE) pour générer des sorties. Plutôt que de recourir à un seul modèle généraliste, le MoE redirige chaque requête d’inférence vers le modèle le plus précis pour ce type d’entrée. Imaginez la construction d’une maison : vous engagez différents experts pour chaque aspect du chantier (architecte, ingénieur, peintre, maçon, etc.). Le MoE applique cette logique aux modèles d’apprentissage machine, sélectionnant selon l’entrée le modèle le plus adapté. Comme l’explique Ala Shaabana, fondateur de Bittensor, c’est comme « parler à une pièce pleine de personnes intelligentes pour obtenir la meilleure réponse, plutôt qu’à une seule ». Cette approche a été temporairement suspendue en raison de difficultés liées au routage correct, à la synchronisation des messages vers les bons modèles, et aux incitations, en attendant un développement plus poussé du projet.
Le réseau Bittensor compte deux acteurs principaux : les validateurs et les mineurs. Les validateurs envoient aux mineurs des requêtes d’inférence, évaluent leurs réponses et les classent selon la qualité de celles-ci. Pour assurer la fiabilité de leurs classements, les validateurs reçoivent un score « vtrust » proportionnel à la cohérence de leurs classements avec ceux des autres validateurs. Plus un validateur a un score vtrust élevé, plus il reçoit de jetons TAO. Cela incite les validateurs à converger progressivement vers un consensus sur les classements, car plus ils s’accordent, plus leur score personnel augmente.
Les mineurs, aussi appelés serveurs, sont les participants du réseau qui exécutent réellement les modèles d’apprentissage machine. Ils rivalisent entre eux pour fournir au validateur la réponse la plus précise à une requête donnée : plus la réponse est exacte, plus ils gagnent de jetons TAO. Les mineurs peuvent produire ces sorties comme ils le souhaitent. Par exemple, un mineur Bittensor pourrait, dans le futur, avoir auparavant entraîné un modèle sur Gensyn et l’utiliser pour gagner des récompenses TAO.
Actuellement, la majorité des interactions se déroulent directement entre validateurs et mineurs. Un validateur soumet une entrée à un mineur et demande une sortie (par exemple, un modèle entraîné). Une fois qu’il a interrogé les mineurs du réseau et reçu leurs réponses, il les classe et soumet ce classement au réseau.
Cette interaction entre validateurs (basés sur la preuve d’enjeu) et mineurs (basés sur une preuve de modèle, une variante de la preuve de travail) est appelée consensus Yuma. Elle vise à inciter les mineurs à produire les meilleures sorties pour gagner des jetons TAO, et les validateurs à classer fidèlement les sorties des mineurs afin d’obtenir un score vtrust plus élevé et augmenter leurs récompenses, formant ainsi le mécanisme de consensus du réseau.
Sous-réseaux et applications
Les interactions sur Bittensor consistent principalement en des requêtes envoyées par les validateurs aux mineurs et l’évaluation des réponses. Cependant, à mesure que la qualité des mineurs contributifs s’améliore et que l’intelligence globale du réseau croît, Bittensor créera une couche applicative au-dessus de sa pile existante, permettant aux développeurs de construire des applications interrogeant le réseau Bittensor.
En octobre 2023, Bittensor a franchi une étape importante vers cet objectif avec la mise à jour Revolution, introduisant les sous-réseaux. Les sous-réseaux sont des réseaux distincts sur Bittensor incitant
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News










