

Pantera 2024 : l'IA reste en tête d'agenda, la Web3 apportera un élan dans l'inférence, la confidentialité des données et les incitations
TechFlow SélectionTechFlow Sélection
Pantera 2024 : l'IA reste en tête d'agenda, la Web3 apportera un élan dans l'inférence, la confidentialité des données et les incitations
La vitesse à laquelle l'innovation se produit dans l'écosystème technologique de la blockchain génère de nouveaux marchés et secteurs verticaux à chaque cycle.
Rédaction : Chia Jeng Yang & Caroline Cahilly, Pantera Capital
Traduction : TechFlow
Pantera Capital a récemment publié un long article détaillant de manière approfondie ses perspectives sur les tendances du marché de la cryptomonnaie en 2024, ses stratégies d'investissement, les domaines surveillés et les prévisions.
Étant donné la longueur de l'article, nous l'avons divisé en plusieurs sections selon les thèmes abordés pour la traduction.
Il s'agit ici de la quatrième partie de l'article complet, rédigée par Chia Jeng Yang, directeur exécutif de Pantera, et l'interne Caroline.
On peut y voir leur intérêt marqué pour la convergence entre l'IA et le Web3, ainsi qu'une analyse fine de l'intégration entre intelligence artificielle et cryptographie. Ils considèrent que le Web3 peut jouer un rôle clé dans le raisonnement des systèmes d'IA, la confidentialité des données et les mécanismes incitatifs, ouvrant ainsi des opportunités dans ces domaines.
TechFlow a traduit cette section. Voici le texte intégral.
Le rythme d'innovation au sein de l'écosystème des technologies blockchain génère à chaque cycle de nouveaux marchés et domaines verticaux. Nos recherches élargissent notre argumentaire, nous permettant de rester en avance et d'optimiser la couverture dans la recherche et l'investissement. Dans les lignes qui suivent, nous partageons les domaines que nous surveillons activement.
IA x WEB3
IA : fusionner l'intelligence humaine et celle des machines
La sortie des modèles d’intelligence artificielle, comme les grands modèles linguistiques (LLM), devrait être le résultat optimal d’une interaction entre cerveaux humains et informatiques, données et systèmes d’incitation.
Ce qui rend les LLM si prometteurs, c’est leur capacité à communiquer en langage naturel, permettant aux humains et aux IA d’utiliser un même langage pour décrire des processus complexes. C’est une étape cruciale vers un futur de systèmes coordonnés intégrant les êtres humains. Pour améliorer cette collaboration, nous devons encore développer des cadres robustes, des mécanismes et des outils homme-machine capables d’encourager les systèmes d’IA à mieux raisonner, produire des réponses plus utiles et atteindre des résultats optimaux.
Comment le Web3 favorise cette interaction
Les cadres d'incitation nativement numériques des blockchains détermineront comment les humains interagiront avec l'IA, grâce à la motivation de la foule (crowdsourcing), la responsabilité, etc. Nous souhaitons explorer les produits capables d'optimiser les interactions entre les intelligences informatiques/IA et humaines — notamment celles impliquant les détenteurs de jetons et les développeurs — en privilégiant les cas d'utilisation à moyen et long terme.
Dans ce qui suit, nous examinerons trois aspects clés de l'interaction homme-machine à l'ère de l'IA :
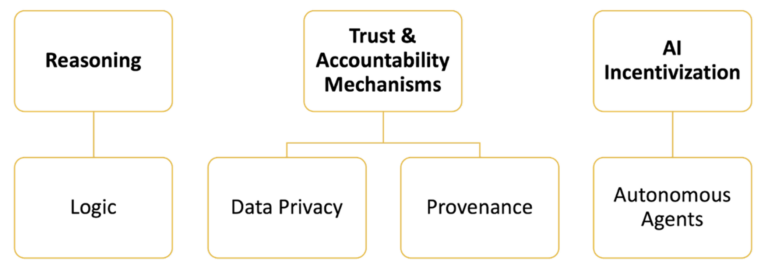
Voici quelques points forts par lesquels la cryptographie peut apporter une valeur ajoutée à l'IA, développés tout au long de cet article :
-
Paiement : Les paiements financiers traditionnels ont des limites bien définies. En revanche, les cryptomonnaies ne nécessitent que quelques lignes de code. La programmabilité facilite l'intégration de produits logiciels : les développeurs n'ont qu'à intégrer une adresse de portefeuille dans leur code. Elle permet aussi des paiements flexibles basés sur le calcul, là où les infrastructures existantes imposent des coûts élevés d'audit. En contournant l'infrastructure financière mondiale obsolète, elle réduit les barrières à l'entrée pour les produits destinés à un public international. De plus, les transactions cryptographiques offrent généralement des frais inférieurs aux paiements traditionnels. Une intégration simple et peu coûteuse est particulièrement bénéfique pour les projets open source, souvent limités en ressources, tandis que la simplicité reste essentielle à la collaboration et à l'adoption.
-
Crowdsourcing : Alors que le retour humain sur les modèles LLM devient crucial, les incitations du Web3 permettent un crowdsourcing de données à une vitesse et une échelle inégalées. Des systèmes structurés de récompenses (et de pénalités) devraient aussi favoriser des informations de haute qualité, attirant un grand nombre de contributeurs aux profils variés.
-
Contrôle des données : Le contrôle personnel des données (avec traçabilité et confidentialité) devient de plus en plus important, car :
-
a. Si les utilisateurs peuvent facilement être rémunérés ou bénéficier d'une meilleure expérience, ils seront davantage enclins à contrôler leurs propres données (ce qui semble désormais possible). Avec la montée des agents autonomes, les utilisateurs pourront être rémunérés pour leurs données sans intervention active. De plus, ceux qui maîtrisent leurs données devraient obtenir une expérience supérieure aux algorithmes personnalisés actuels, souvent médiocres. Contrairement aux précédentes tentatives de portefeuilles de données, les LLM peuvent aujourd'hui automatiser collecte manuelle massive de données multiplateformes, et contextualiser efficacement les données non structurées en langage naturel.
-
b. Les entreprises pourraient prendre l'initiative de contrôler les données afin de protéger les informations confidentielles. De nouvelles normes émergeront ensuite pour les individus.
Trois idées nous enthousiasment particulièrement :
-
Raisonnement fondé sur le retour humain : Inférer logiquement via des graphes de connaissances mis en commun (zk)
-
Suivi ML des redevances pour contenu généré par l’IA (AIGC) : Utiliser le machine learning pour calculer les redevances dues aux contenus d’origine ayant alimenté l’AIGC
-
Jumeaux numériques publicitaires : À mesure que les LLM remplacent les moteurs de recherche comme principaux moyens de récupération d'information, les préférences des utilisateurs seront captées par interaction avec les LLM plutôt que par navigation web. La publicité dans ce monde IA aura besoin d'infrastructures permettant aux systèmes AdTech d'extraire automatiquement les préférences personnelles à partir de jumeaux numériques.
Raisonnement
Malgré l'effervescence autour des LLM, ceux-ci peinent encore dans des tâches comme la planification, le raisonnement, la compréhension du monde physique — des compétences où les humains excellent. Ces erreurs proviennent probablement du fait que les LLM imitent massivement des motifs dans les données sans comprendre les principes logiques ou physiques sous-jacents, ce qui les rend insuffisants selon les critères humains.
La valeur du raisonnement systématique réside dans sa capacité à traiter des problèmes inconnus, d’autant plus que les preuves montrent fortement que les transformeurs (transformers) ne peuvent pas aller au-delà des données d’entraînement. Nous recherchons donc des solutions aux problèmes de raisonnement, applicables autant aux modèles de base qu’aux systèmes intégrant des LLM aujourd’hui, en mettant l’accent sur les mécanismes de retour humain pour améliorer le raisonnement.
Logique
Les graphes de connaissances (méthode utilisant des bases de données structurées pour capturer les relations entre entités, événements et concepts) offrent une manière intéressante d’intégrer le raisonnement logique aux LLM.
Voici quelques exemples de leur intégration possible :
-
Récupération dynamique de connaissances : Pendant le raisonnement, extraire dynamiquement des informations pertinentes depuis le graphe selon un mécanisme d’attention.
-
Boucle de rétroaction : Si la sortie s’écarte nettement de la compréhension du graphe, utiliser cette rétroaction pour un nouvel ajustement.
Graphes de connaissances en crowdsourcing : Le crowdsourcing redéfinira la collecte et la validation de l'information, contribuant à créer un « dépôt de toute la connaissance et culture humaines ».
Les graphes de connaissances en mode crowdsourcing inciteront les utilisateurs à fournir des données et leurs connexions logiques, rémunérés automatiquement dès qu’un modèle accède à leur contribution. Pour garantir l’exactitude, les contributions incorrectes seront pénalisées, selon un ensemble de critères validés par un groupe de vérificateurs. Définir ces critères (spécifiques à chaque graphe) sera l’un des facteurs clés du succès.
Le Web3 offre un moyen d’inciter à grande échelle la création de tels graphes. De plus, les lacunes du raisonnement LLM sont une cible mouvante, et le Web3 permet d’inciter ponctuellement à combler ces manques au fur et à mesure qu’ils apparaissent.
En outre, des systèmes structurés de récompenses (et de sanctions) favoriseront des informations de haute qualité et attireront un grand nombre de contributeurs aux horizons variés. Soulignons que les utilisateurs créent de la valeur en partageant leurs données de façon productive et non nulle — contrairement aux marchés prédictifs zéro-somme ou aux oracles décentralisés.
Enfin, dans les limites actuelles de l’IA, le crowdsourcing de ces graphes aidera à maintenir une précision pertinente (sans simplement reproduire les capacités de raisonnement des LLM existants).
Mécanismes de confiance et de responsabilité
1. Confidentialité des données
Les contrôles sur les données utilisateur en IA, actuellement en développement, rivaliseront bientôt avec l’écosystème matériel d’Apple. Nous devons prendre en compte la confidentialité des données car :
-
À mesure que l’IA s’immisce sans heurt dans tous les aspects de nos vies — des objets connectés aux applications de santé — la quantité de données collectées croît exponentiellement.
-
Nous approchons un point de basculement concernant la capacité de l’IA à créer du contenu personnalisé (par exemple via des LLM) et la perception qu’en ont les utilisateurs. À mesure que les utilisateurs chercheront de plus en plus fréquemment et massivement l’IA pour des expériences et produits véritablement personnalisés, le taux de partage de données avec l’IA augmentera fortement.
Par conséquent, la confidentialité des données est essentielle pour instaurer la confiance des utilisateurs dans les systèmes d’IA et aider les développeurs à éviter les abus (accès non autorisé, vol d’identité, manipulation).
Des technologies Web3 telles que les preuves à divulgation nulle (zk-SNARK) et le chiffrement homomorphe complet (FHE) permettront des interactions sécurisées, garantissant que les informations sensibles restent sous le contrôle de l’utilisateur.
Le récent décret américain sur l’IA souligne l’importance de « renforcer la recherche et les technologies de protection de la vie privée, telles que les outils cryptographiques préservant la confidentialité individuelle », et introduit des obligations de déclaration pour les grands modèles. Cela indique une ouverture accrue des régulateurs aux méthodes de provenance et de confidentialité du Web3, voire leur adoption future comme standard de conformité.
Graphes de connaissances ZK en crowdsourcing : Grâce à des graphes de connaissances ZK générés en mode collaboratif, l’IA peut tirer parti de données privées. Plus précisément, ils comporteront des nœuds « publics » (contenant des données publiques) et des nœuds « privés » (contenant des données chiffrées). Le modèle peut exploiter les connexions logiques entre nœuds pour parvenir à une réponse, sans révéler les données elles-mêmes — les nœuds cités dans la réponse finale seront publics, mais ceux utilisés pour y parvenir n’ont pas besoin de l’être.
Ces graphes facilitent aussi la suppression des données utilisateur, car leur accès en temps réel (via récupération dynamique) évite de stocker implicitement les données dans les modèles entraînés.
2. Provenance
Sans traçabilité de provenance, l’IA pourrait générer des deepfakes et exploiter librement des données personnelles, privées ou propriétaires. Grâce au Web3, nous pouvons tracer l’origine des NFT, autres actifs médias et données utilisées par les modèles, offrant ainsi de nombreuses solutions prometteuses.
Suivi ML des redevances pour contenu généré par l’IA : Outre les deepfakes, l’essor de l’AIGC dans l’art soulève des défis uniques en matière de propriété intellectuelle et de redevances. Par exemple, si un système AIGC compose un mashup de deux artistes célèbres, comment répartir le crédit et la récompense économique entre eux ? Étant donné la complexité et la variabilité de l’AIGC, les modèles traditionnels de répartition deviennent de moins en moins adaptés.
Le suivi par apprentissage automatique (ML) propose une méthode pour identifier les composants d’origine d’une œuvre AIGC. Contrôler la provenance dès la génération de l’AIGC est crucial pour permettre un tel suivi.
En l’absence d’une infrastructure de paiement mondiale solide pour l’AIGC, des plateformes comme YouTube, déjà dotées de mécanismes de paiement de redevances, prendront de l’avance et pourraient encore concentrer leur pouvoir.
Pour démocratiser la création AIGC et garantir une juste rémunération aux artistes, un nouveau système de paiement est nécessaire. Un réseau de paiement blockchain intégré nativement aux modèles AIGC pourrait permettre des paiements instantanés mondiaux dès le premier jour. Puis, le suivi ML et la blockchain pourraient être intégrés à diverses plateformes, réduisant l’avantage actuel de géants comme YouTube.
Investir dans cette technologie permettrait non seulement une répartition équitable des redevances, mais aussi stimulerait l’innovation AIGC en ouvrant des opportunités à davantage de créateurs.
Incitations IA
Alors que les modèles d’IA deviennent de plus en plus autonomes, nous souhaitons concevoir des systèmes capables de les inciter à agir conformément aux souhaits humains.
Agents autonomes
Un agent autonome est un modèle capable d’interagir intelligemment avec son environnement (par exemple, en utilisant des outils ou en lançant des appels API pour accéder à des données en temps réel), d’interagir avec des algorithmes pour raisonner et décider, et d’agir sans contrôle humain direct. Il manifeste un comportement orienté vers un but et peut apprendre de l’expérience, mais seulement dans des contextes très restreints (comme la conduite autonome). À mesure que les modèles d’IA passeront de la simple récupération d’information à l’exécution d’actions pour les utilisateurs, l’adoption d’agents autonomes, authentifiés par les utilisateurs et utilisant une monnaie numérique native, pourrait croître.
Positionnement par jumeau numérique : La publicité classique basée sur la recherche décline, car des modèles conversationnels comme ChatGPT deviennent la principale source de récupération d’information. Cela pose un défi au secteur AdTech, dont la publicité traditionnelle par moteurs de recherche et cookies connaît des rendements décroissants.
Quand le marché réalisera que ce sont ces modèles personnels, et non les cookies, qui constituent l’unité fondamentale pour comprendre les préférences utilisateur, les modèles permettant aux annonceurs d’extraire ces préférences d’autres modèles pourraient dominer. Grâce à cela, les annonceurs pourraient atteindre un niveau de personnalisation auparavant impossible, tout en préservant la vie privée via des méthodes cryptographiques.
Une nouvelle plateforme facilitant ces interactions pourrait contourner les géants logiciels et matériels actuels comme Google ou Apple.
Plus précisément, quand un utilisateur décide de créer un jumeau numérique, il lui accorde l’accès à son historique de recherche, ses comptes actuels (Google, ChatGPT, Amazon), son disque dur, etc. Ce jumeau élabore un résumé initial de ses données — entreprises avec lesquelles il interagit, centres d’intérêt, etc. — et se met à jour continuellement.
L’utilisateur peut alors définir les permissions concernant la vente de ses données par le jumeau, et à qui. Par exemple, imaginons un bouton intitulé « Autoriser mon robot publicitaire à dialoguer avec GPT-4, Meta AI, etc. ». Le jumeau interagit alors de façon autonome avec les modèles IA des annonceurs. Ces derniers déterminent s’il vaut la peine de cibler ce profil, sans même connaître l’identité de l’utilisateur. S’il est ciblé, l’utilisateur reçoit des publicités (via texte, discussion avec un LLM, etc.) et est rémunéré en échange.
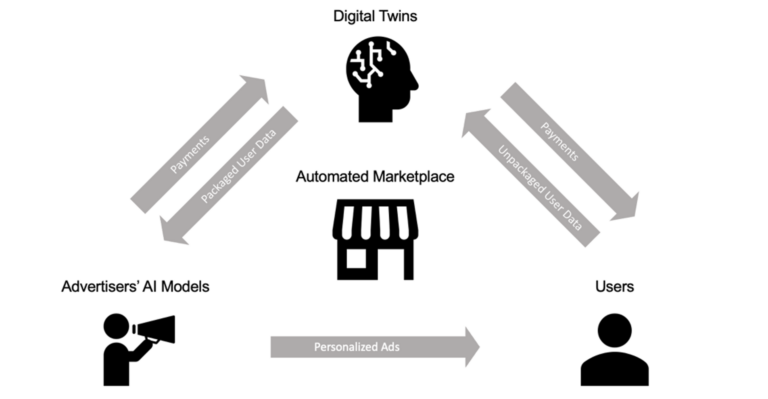
Dans ce marché des jumeaux numériques, les réseaux de paiement cryptographiques pourraient être le moyen le plus simple de rémunérer les interactions entre modèles, puisque les transactions ne nécessitent que quelques lignes de code. En outre, la conception des incitations doit garantir que les jumeaux ciblés offrent une valeur maximale aux annonceurs. Ainsi, ces derniers devraient uniquement viser les jumeaux dotés de données propres et précises reflétant fidèlement les préférences des utilisateurs.
Conclusion
La convergence des technologies d’IA et de Web3 a le potentiel de révolutionner le raisonnement des systèmes d’IA, la confidentialité des données et les mécanismes d’incitation. Les solutions basées sur la blockchain devraient favoriser des transactions et un traitement des données sûrs et efficaces, tout en incitant des contributions variées pour enrichir le développement et l’application de l’IA. Cette symbiose entre IA et cryptographie pourrait aboutir à des systèmes d’intelligence artificielle plus puissants, efficaces et centrés sur l’utilisateur, répondant ainsi aux défis clés du domaine de l’IA.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News











