L'indexeur MUD est-il une conception médiocre ?
TechFlow SélectionTechFlow Sélection
L'indexeur MUD est-il une conception médiocre ?
L'indexeur du moteur MUD est la conception le moins mauvaise possible ; cet article explique en détail cette conclusion et tente d'explorer des solutions potentiellement meilleures.
Rédaction : ck, MetaCat
Préambule
Ce titre n’a pas pour but de provoquer une réaction spectaculaire, mais traduit sincèrement ce que j’ai ressenti récemment en utilisant le framework MUD (le terme « framework » étant plus approprié). La réponse préliminaire est la suivante : l’indexeur MUD constitue la solution la moins mauvaise. Cet article expliquera en détail cette conclusion et tentera d’explorer des solutions potentiellement meilleures, bien que ces réflexions restent très sommaires et qu’aucune réponse satisfaisante n’ait encore été trouvée. J’en profite pour noter ces idées, dans l’espoir de susciter d’autres contributions.

Source : https://mud.dev/
Approche centrée sur la base de données
Dans « 2048 entièrement sur chaîne : ce que nous avons appris en utilisant le moteur MUD », nous avons mentionné que la conception du framework MUD suit une logique « centrée sur la base de données ». Dans ce cadre, le déroulement de l’application tourne autour de la lecture et de l’écriture de données sur la blockchain. L’écriture des données est prise en charge par Store ; la lecture principalement par Indexer. L’emploi du mot « principalement » s’explique ainsi : la lecture des données directement sur la chaîne relève de Store, tandis que la lecture hors chaîne (ou côté client) est gérée par Indexer.
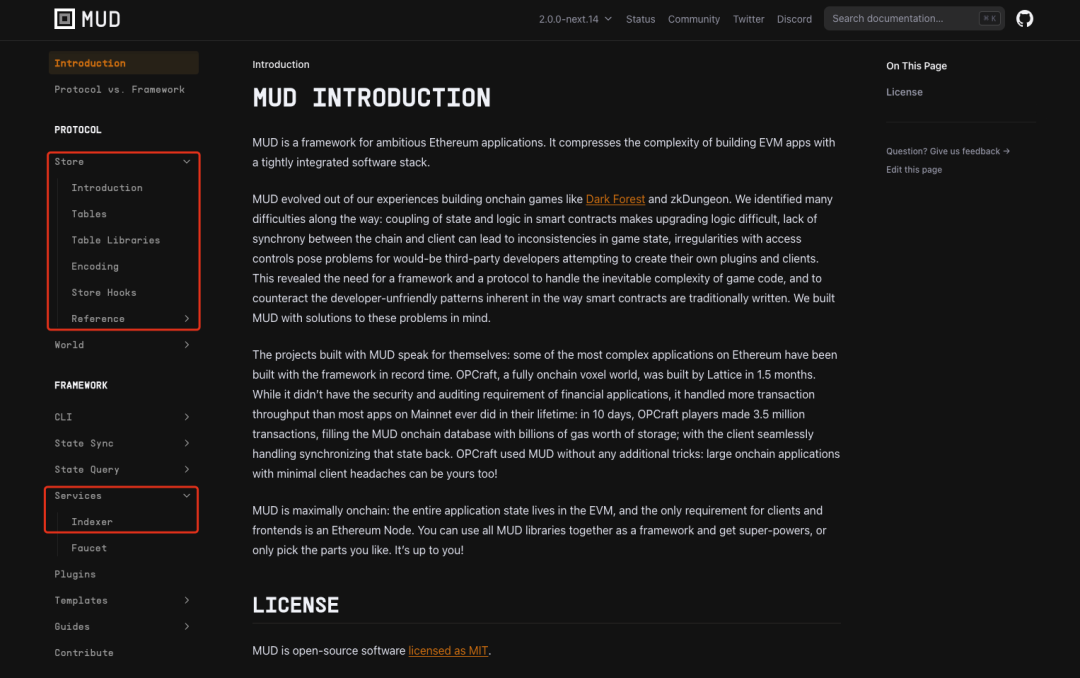
Source : https://mud.dev/introduction
Temps d’attente utilisateur
L’indexeur est essentiellement une copie locale (côté client) des données stockées sur la chaîne, organisées sous une forme similaire à celle d’une base de données relationnelle. Dans un scénario d’application DApp basée sur navigateur, cela signifie qu’à chaque rafraîchissement de page, il faut recréer intégralement cette copie locale. En raison du mode de stockage séquentiel des données sur la chaîne, le temps nécessaire pour reconstruire cette copie augmente au fil du temps, ce qui entraîne une augmentation du temps d’attente pour l’utilisateur et une détérioration concomitante de l’expérience utilisateur.
Source : https://www.mud2048.fun/
Prenons l’exemple de mud2048.fun : actuellement, il faut environ 10 à 20 secondes d’attente avant d’accéder à la page principale du jeu — une expérience franchement insupportable. C’est à partir de ce constat que cet article examine les forces et faiblesses de la conception de l’indexeur MUD, explore les pistes d’amélioration possibles, et aborde plus largement la question du modèle de lecture/écriture des données dans les frameworks de développement d’applications sur chaîne.
Dans le contexte anticipé d’une explosion des applications sur les Layer 2 d’Ethereum, cette discussion revêt une grande pertinence pratique. Elle touche même à une question fondamentale, peut-être décisive quant à savoir si les applications sur Layer 2 parviendront ou non à se développer massivement. Si cette problématique est résolue, les obstacles infrastructurels à l’essor des applications Ethereum Layer 2 seront levés, et il ne restera plus qu’à attendre l’émergence d’innovations modélaires pour déclencher une vague d’applications.
MUD Store : une meilleure solution pour l’écriture de données sur chaîne
La méthode d’écriture de données via Store est plus compacte que l’empaquetage natif des données Solidity, ce qui permet de réduire significativement les coûts de stockage. De plus, en « mappant » le stockage des données sur chaîne vers un modèle bien établi en ingénierie logicielle — la base de données relationnelle —, elle devient particulièrement intuitive pour les développeurs. Ainsi, comparée à la méthode native d’écriture de données Solidity, la solution proposée par Store est clairement supérieure. Toutefois, cela contribue également à créer des difficultés en matière d’efficacité de lecture des données. Comme disait Tagore : « Ce qui est meilleur ne vient jamais seul ; il arrive accompagné de tout le reste. »
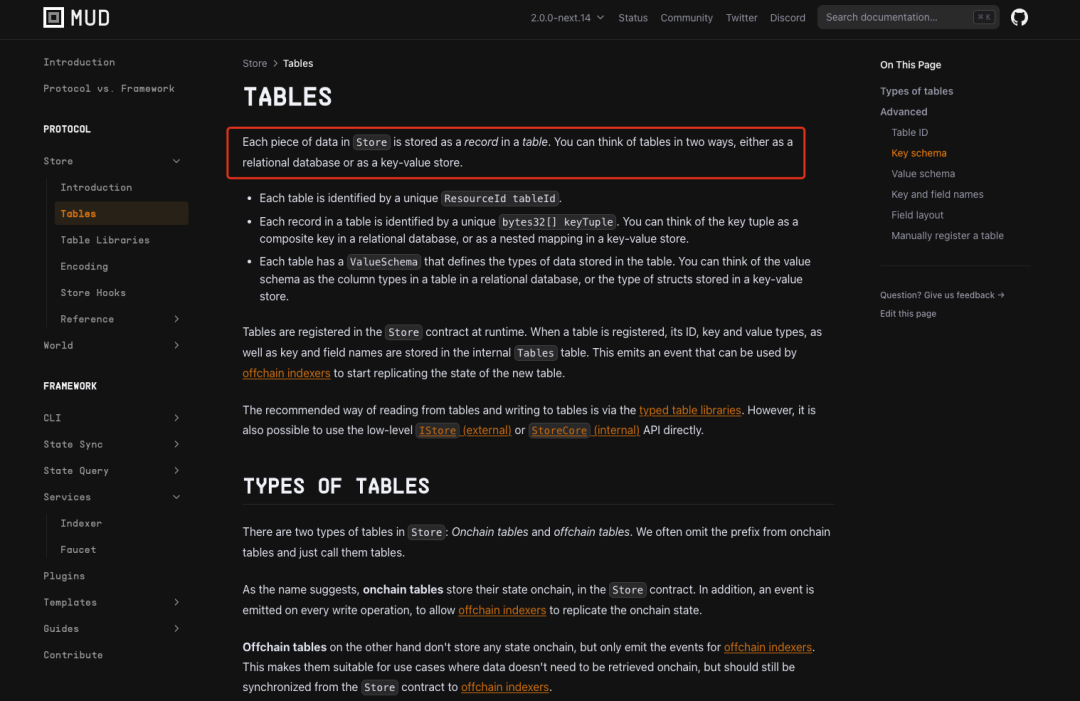
Source : https://mud.dev/store/tables
Cette méthode d’écriture, ou dit autrement, le fait d’écrire les données sur la blockchain, limite les options de lecture/requêtage à deux voies uniquement :
Première voie : lire directement depuis la chaîne. Inconvénient : faible efficacité, impossibilité de supporter des requêtes complexes.
Deuxième voie : copier les données de la chaîne vers un environnement hors chaîne, puis effectuer les requêtes complexes hors chaîne (c’est la solution adoptée par MUD). Mais cela pose deux problèmes :
1> Au fil du temps, la synchronisation et la copie des données prennent de plus en plus de temps, ce qui dégrade progressivement l’expérience utilisateur ;
2> Chaque copie cliente doit exécuter localement des opérations globales (par exemple, calculer un classement), ce qui entraîne un gaspillage notable de ressources.
Durant le développement de mud2048.fun, nous avons eu un échange simple avec l’équipe MUD concernant le premier problème, aboutissant à quelques solutions temporaires, mais qui ne réglaient pas la racine du problème. La zone encadrée en rouge ci-dessous illustre le processus intégré à MUD consistant à copier les données depuis la chaîne.
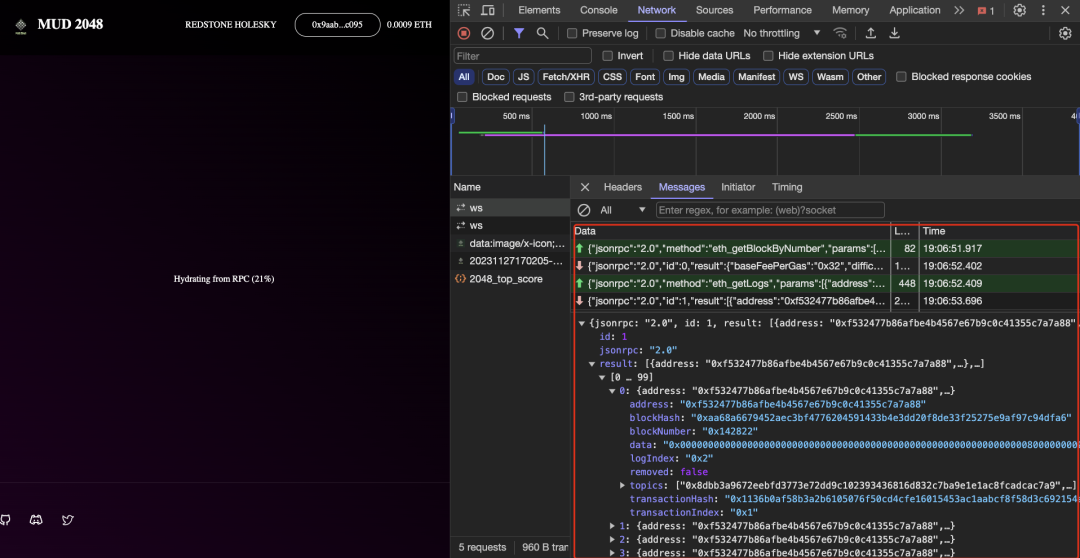
Source : https://www.mud2048.fun/
La question ultime : comment assurer une lecture efficace des données pour les applications entièrement sur chaîne ?
À partir de l’évolution des produits Internet, on sait que dans la majorité des cas, plus de 90 % du temps est consacré à la lecture des données, contre moins de 10 % pour leur écriture. Par conséquent, une solution efficace pour la lecture des données détermine directement la qualité de l’expérience utilisateur.
Dans le domaine de la blockchain, un concept similaire existe : celui de « couche de disponibilité des données » (Data Availability Layer). Bien que ce concept ne traite pas exactement du même niveau de problème, il pourrait néanmoins nous aider à penser des solutions, alors empruntons-le temporairement.

Source : https://www.alchemy.com/overviews/data-availability-layer
Les solutions courantes de disponibilité des données (DA) en blockchain peuvent être grossièrement divisées en deux catégories : DA sur chaîne et DA hors chaîne. Les inscriptions sur Bitcoin relèvent de la première catégorie (les données sont stockées sur la blockchain Bitcoin, mais interprétées hors chaîne), tandis que les Layer 2 d’Ethereum relèvent de la seconde (ZK Rollup et OP Rollup stockent leurs données sous forme de CALLDATA sur Ethereum Layer 1). Ces deux approches sont encore en compétition, aucune n’ayant clairement pris le dessus à ce jour — ce qui nous fournit justement des exemples contrastés utiles pour réfléchir à notre propre problème.
Impossible de reprendre directement les solutions Web2
Dans le monde Web2, lorsque les performances de lecture d’une base de données sont insuffisantes, on ajoute généralement une couche de cache devant la base de données, ou bien on multiplie les bases de données esclaves pour améliorer la capacité de lecture.
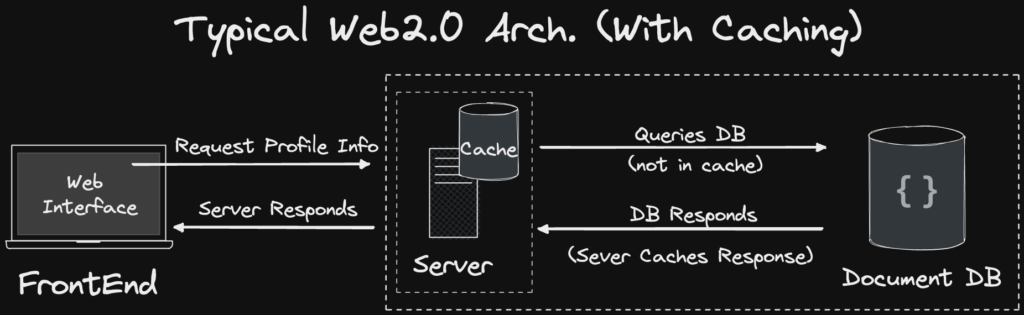
Architecture typique d’un service Web2. Source : https://smartbuilds.io/scaling-web3-social-media-blockchain-cache-layer/
Toutefois, dans le domaine de la blockchain, ces solutions semblent aujourd’hui inapplicables. D’une part, le modèle de prestation de services passe du centralisé au décentralisé ; d’autre part, le stockage des données évolue du stockage structuré vers un stockage chaîné. Ces changements fondamentaux impliquent que les solutions doivent aussi évoluer en conséquence. Pour l’instant, aucune solution équivalente à un « cache » ou à une « base esclave » adaptée à la blockchain n’a encore été trouvée.
Il existe certes des cas de DApps s’inspirant du système de cache Web2, mais ils manquent clairement de caractère universel. Du point de vue du framework MUD, intégrer une telle solution introduirait davantage de facteurs centralisés, ce qui n’est donc pas idéal.
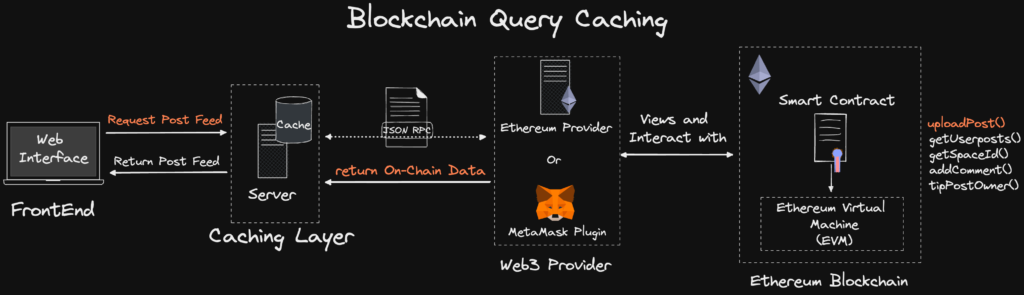
Architecture de DApp intégrant un cache. Source : https://smartbuilds.io/scaling-web3-social-media-blockchain-cache-layer/
Indexer : la solution la moins mauvaise
En soi, MUD représente déjà un progrès majeur dans le domaine des blockchains dédiées aux applications, car il résout simultanément trois problèmes importants :
1> Le couplage entre données et logique dans les contrats intelligents, qui rend difficile la mise à jour de la logique ;
2> L’absence de mécanisme de synchronisation entre la chaîne et le client, conduisant à des incohérences d’état ;
3> Le manque d’un mécanisme d’accès unifié sur la blockchain, entraînant redondances et obstacles à l’interopérabilité.
Pour résoudre le problème de lecture des données, MUD place sur le client un « nœud complet » qui ne s’intéresse qu’aux données du contrat concerné. Officiellement appelé « Namespaced Full-node », c’est ce que nous désignons comme Indexer.
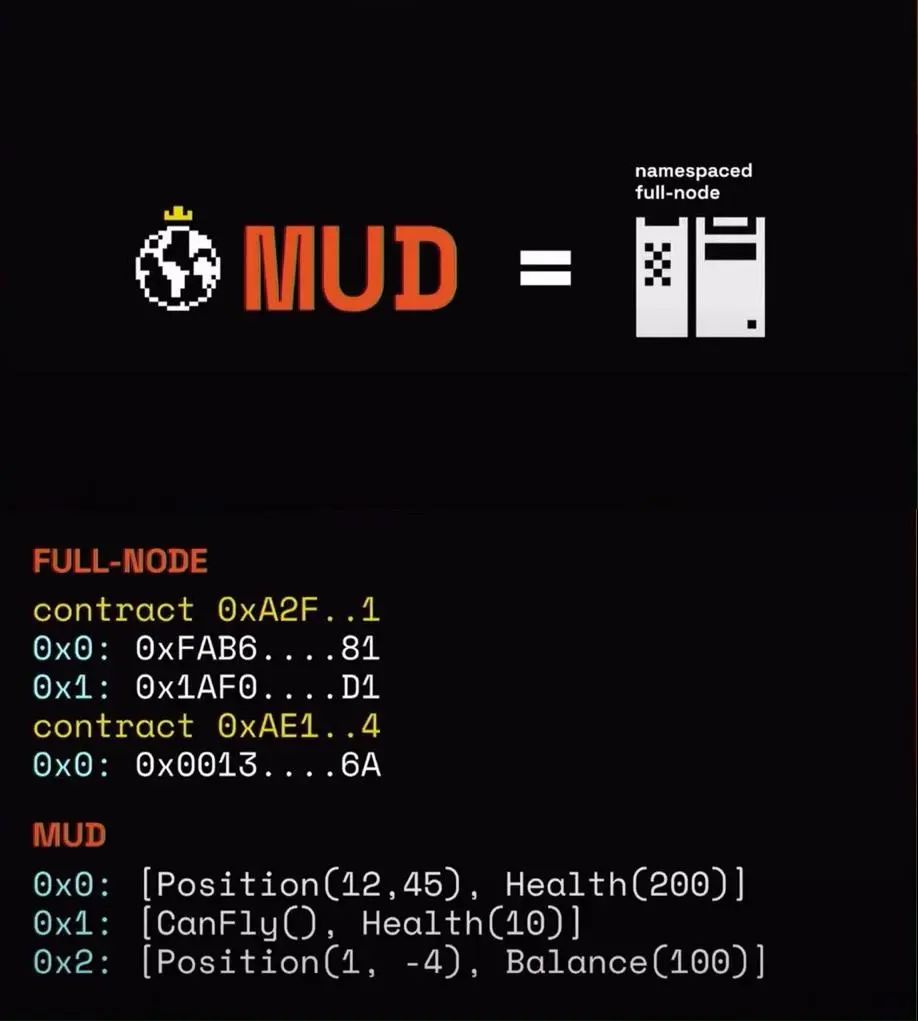
Source : https://youtu.be/tLGdup5wmck?si=ykgQ4qwut4VLgimF
Dans le domaine des blockchains d’applications, cette solution marque une avancée significative, passant du rien à quelque chose. Bien qu’elle ne soit pas parfaite, elle constitue indéniablement un excellent point de départ. Les générations futures pourront s’appuyer sur cette base pour explorer des solutions encore meilleures. En résumé, l’indexeur MUD est la solution la moins mauvaise, mais nous devons continuer à chercher mieux.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News