

Vitalik Buterin : Les Community Notes de Twitter incarnent parfaitement l'esprit de la cryptographie, et j'attends avec impatience l'avenir des nouveaux réseaux sociaux expérimentaux
TechFlow SélectionTechFlow Sélection
Vitalik Buterin : Les Community Notes de Twitter incarnent parfaitement l'esprit de la cryptographie, et j'attends avec impatience l'avenir des nouveaux réseaux sociaux expérimentaux
Bien que Community Notes ne soit pas un « projet de cryptomonnaie », c'est peut-être l'exemple le plus proche des « valeurs crypto » que nous ayons vu dans le monde traditionnel.
Rédaction : vitalik
Traduction : TechFlow
Ces deux dernières années, Twitter (X) a été un véritable champ de bataille. L'année dernière, Elon Musk a racheté la plateforme pour 44 milliards de dollars, puis a procédé à une refonte totale de l'effectif, de la modération des contenus, du modèle économique et de la culture du site — des changements qui tiennent davantage de la puissance douce de Musk que de décisions politiques stricto sensu. Pourtant, au milieu de ces controverses, une nouvelle fonctionnalité s'est rapidement imposée sur Twitter, séduisant apparemment tous les camps politiques : Community Notes.
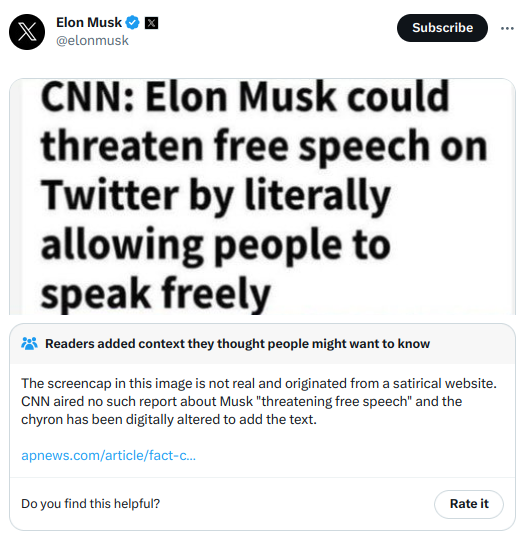
Community Notes est un outil de vérification des faits qui ajoute parfois des annotations contextuelles aux tweets, comme dans le cas ci-dessus du tweet d’Elon Musk, afin de combattre la désinformation. À l’origine appelé Birdwatch, ce système a été lancé en janvier 2021 sous forme de projet pilote. Il s’est progressivement étendu, notamment durant la période où Elon Musk a repris Twitter. Aujourd’hui, Community Notes apparaît fréquemment sur les tweets les plus populaires, y compris ceux portant sur des sujets politiques sensibles. D’après mon expérience personnelle et mes échanges avec des personnes de tous horizons politiques, ces notes sont généralement informatives et utiles lorsqu’elles sont affichées.
Mais ce qui m’intéresse surtout, c’est que bien que Community Notes ne soit pas un « projet crypto », il constitue peut-être l’exemple le plus proche des « valeurs crypto » que nous ayons vu émerger dans le monde réel. Les notes ne sont pas rédigées ou supervisées par un comité central d’experts ; tout le monde peut participer à leur écriture et à leur notation, et la décision d’afficher ou non une note repose entièrement sur un algorithme open source. Twitter met à disposition un guide détaillé expliquant le fonctionnement de cet algorithme. Vous pouvez télécharger les données publiées (notes et votes), exécuter localement l’algorithme et vérifier si ses résultats correspondent à ce qui est affiché sur le site. Malgré ses imperfections, le système s’approche de manière surprenante de l’idéal de neutralité fiable, tout en restant très utile.
Comment fonctionne l’algorithme de Community Notes ?
Tout utilisateur Twitter remplissant certains critères (principalement : compte actif depuis plus de six mois, sans infractions, numéro de téléphone vérifié) peut s’inscrire à Community Notes. Actuellement, les participants sont acceptés progressivement et aléatoirement, mais l’objectif final est d’ouvrir le système à toute personne éligible. Une fois accepté, vous commencez par noter des notes existantes. Si vos évaluations se révèlent cohérentes avec les résultats finaux, vous pouvez alors rédiger vos propres notes.
Lorsque vous soumettez une note, celle-ci reçoit un score basé sur les évaluations d’autres membres de Community Notes. Ces évaluations peuvent être considérées comme des votes à trois niveaux : « utile », « un peu utile » ou « inutile ». D'autres balises peuvent également être ajoutées et influencer l’algorithme. En fonction de ces retours, une note obtient un score. Si celui-ci dépasse 0,40, la note est affichée ; sinon, elle ne l’est pas.
Ce qui rend l’algorithme particulier, c’est la manière dont le score est calculé. Contrairement à un système simple qui additionnerait ou ferait la moyenne des votes, l’algorithme de Community Notes cherche activement à privilégier les notes qui reçoivent des évaluations positives de personnes aux opinions divergentes. Autrement dit, si des utilisateurs qui s’opposent habituellement parviennent à s’accorder sur une note particulière, cette dernière obtiendra un score élevé.
Plongeons dans les détails. Nous disposons d’un ensemble d’utilisateurs et d’un ensemble de notes. On peut construire une matrice M, où la cellule Mij indique comment le i-ème utilisateur a évalué la j-ème note.
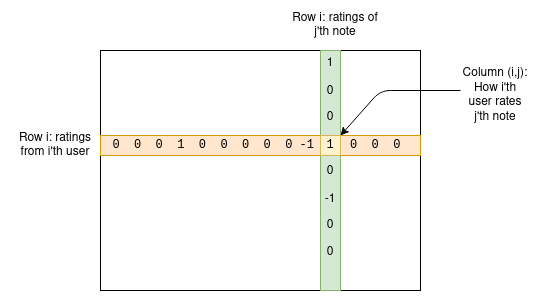
Pour une note donnée, la plupart des utilisateurs n’ont pas encore voté, donc la majorité des cellules de la matrice seront vides — ce qui ne pose aucun problème. L’objectif de l’algorithme est de créer un modèle à quatre dimensions pour les utilisateurs et les notes, attribuant à chaque utilisateur deux statistiques — que nous pouvons appeler « amabilité » et « polarité » — et à chaque note deux autres — « utilité » et « polarité ». Le modèle tente de prédire la matrice à partir de ces valeurs, selon la formule suivante :
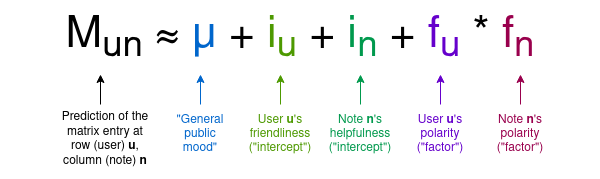
Notez que j'introduis ici les termes utilisés dans l'article Birdwatch, ainsi que mes propres appellations pour mieux comprendre intuitivement la signification des variables, sans recourir aux mathématiques :
-
μ est un paramètre de « sentiment public », mesurant à quel point les utilisateurs ont tendance à attribuer globalement des notes élevées.
-
iu est l’« amabilité » de l’utilisateur, c’est-à-dire sa propension à attribuer des notes élevées.
-
in est l’« utilité » de la note, c’est-à-dire sa probabilité d’obtenir des notes élevées. C’est la variable qui nous intéresse.
-
fu ou fn est la « polarité » de l’utilisateur ou de la note, autrement dit sa position sur l’axe dominant de l’extrême politique. En pratique, une polarité négative correspond approximativement à une orientation « de gauche », positive à une orientation « de droite ». Mais attention : cet axe extrême est déduit automatiquement par analyse des données, les concepts de gauche et droite n’étant pas codés en dur.
L’algorithme utilise un modèle classique d’apprentissage automatique (descente de gradient standard) pour trouver les meilleures valeurs des variables permettant de prédire les données de la matrice. L’« utilité » attribuée à une note devient son score final. Si ce score atteint au moins +0,4, la note est affichée.
L’astuce centrale réside ici : la « polarité » absorbe les caractéristiques d’une note qui plaisent à certains utilisateurs mais pas à d’autres, tandis que l’« utilité » mesure uniquement celles qui plaisent à tout le monde. Ainsi, en sélectionnant les notes hautement « utiles », on favorise celles reconnues transversalement, et on rejette celles acclamées par un groupe mais rejetées par un autre.
Ce qui précède décrit seulement la partie centrale de l’algorithme. En réalité, plusieurs mécanismes supplémentaires viennent s’y ajouter. Heureusement, ils sont documentés publiquement. Parmi eux :
-
L’algorithme est exécuté plusieurs fois, en ajoutant à chaque itération des votes fictifs extrêmes générés aléatoirement. Cela signifie que le résultat réel pour chaque note est une plage de valeurs, et que le résultat final dépend du « seuil de confiance inférieur » extrait de cette plage, comparé à un seuil de 0,32.
-
Si de nombreux utilisateurs (surtout ceux ayant une polarité similaire à celle de la note) jugent une note « inutile » et utilisent la même « balise » (ex. : « langage polémique ou biaisé », « sources non fiables »), alors le seuil d’utilité requis passe de 0,4 à 0,5 (une petite différence, mais cruciale en pratique).
-
Si une note est affichée, son utilité doit chuter de 0,01 point en dessous du seuil d’acceptation pour être retirée.
-
L’algorithme effectue plusieurs passes avec différents modèles, parfois en valorisant des notes dont le score initial d’utilité est compris entre 0,3 et 0,4.
Au total, on aboutit à un code Python complexe de 6 282 lignes réparties en 22 fichiers. Mais tout est ouvert : vous pouvez télécharger les données des notes et des votes, exécuter l’algorithme vous-même et comparer les résultats à ceux visibles sur Twitter.
À quoi cela ressemble-t-il concrètement ?
La principale différence entre cet algorithme et une simple moyenne des votes réside probablement dans le concept que j’appelle « valeur de polarité ». La documentation de l’algorithme les nomme fu et fn, avec f pour « facteur », car ces termes sont multipliés entre eux ; le terme plus général vient du fait qu’on espère un jour rendre fu et fn multidimensionnels.
Des valeurs de polarité sont attribuées aux utilisateurs et aux notes. Le lien entre l’identifiant utilisateur et le compte Twitter sous-jacent est intentionnellement confidentiel, mais les notes sont publiques. En pratique, du moins pour le jeu de données anglophone, les polarités générées par l’algorithme sont fortement corrélées à l’échiquier gauche-droite.
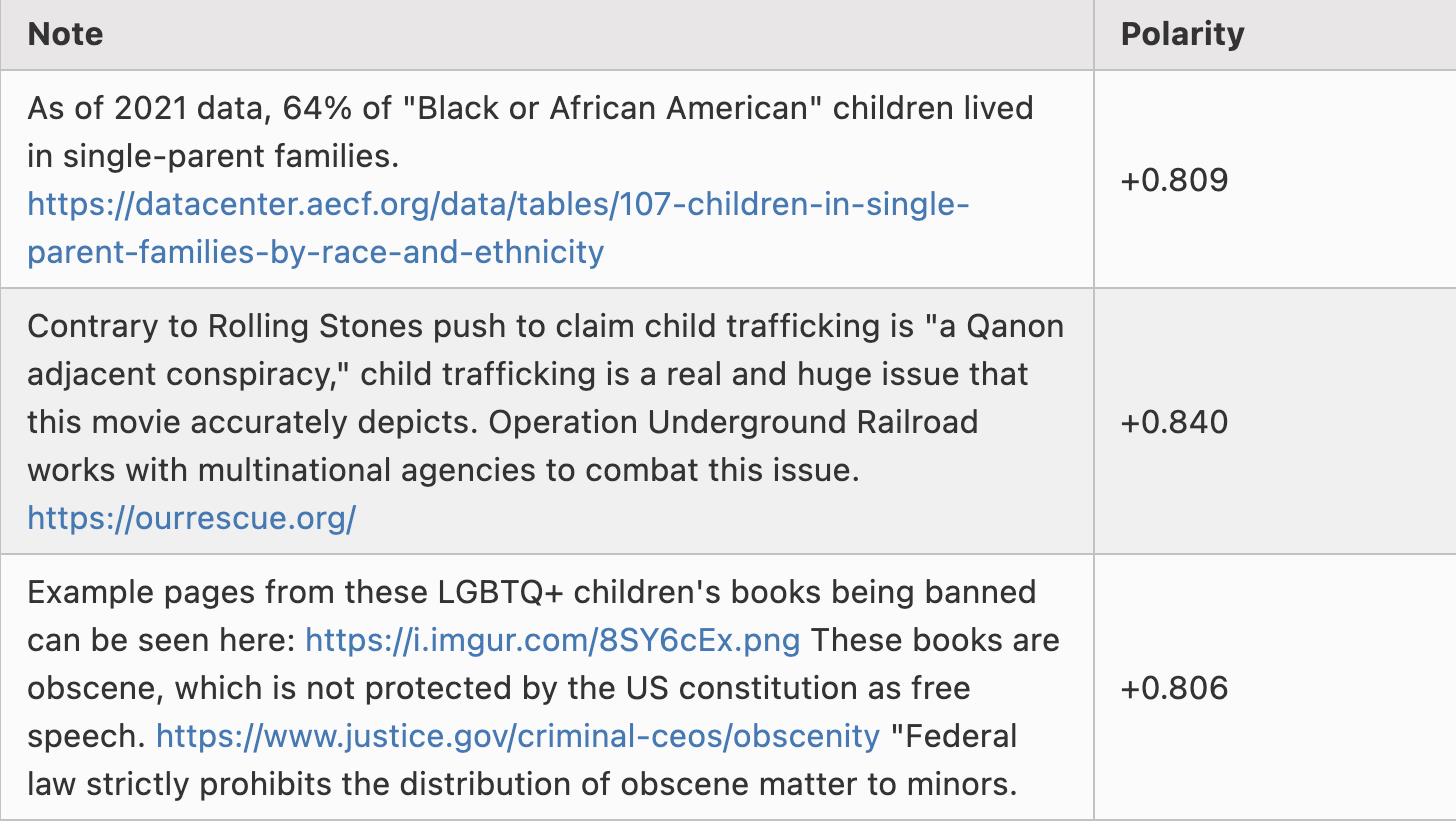
Voici quelques exemples de notes ayant une polarité d’environ -0,8 :
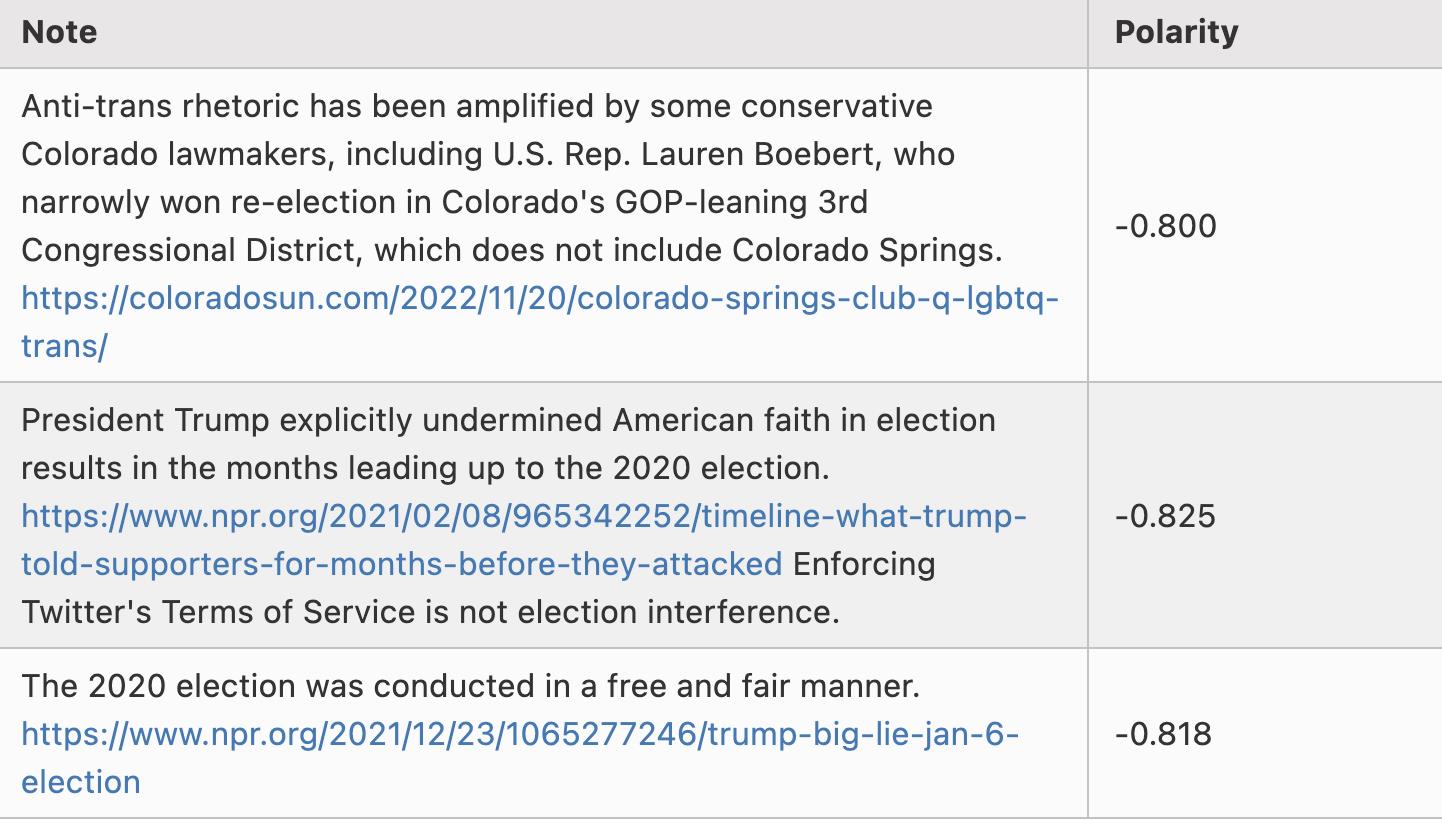
Je précise que je n’ai pas trié ces exemples : ce sont simplement les trois premières lignes du fichier scored_notes.tsv généré après exécution locale de l’algorithme, dont la polarité (appelée coreNoteFactor1 dans le tableau) est inférieure à -0,8.
Voici maintenant quelques notes avec une polarité d’environ +0,8. Beaucoup concernent des discussions en portugais sur la politique brésilienne ou des fans de Tesla furieux contre des critiques de Tesla, donc je vais sélectionner quelques exemples hors de ces catégories :
Encore une fois, la division gauche/droite n’est encodée nulle part dans l’algorithme ; elle est découverte par calcul. Cela suggère que, appliqué à d’autres contextes culturels, l’algorithme pourrait détecter automatiquement leurs principales divisions politiques et tenter d’y bâtir des ponts.
En revanche, voici à quoi ressemblent les notes obtenant les scores d’« utilité » les plus élevés. Cette fois, comme elles sont effectivement affichées sur Twitter, je peux directement faire une capture d’écran :
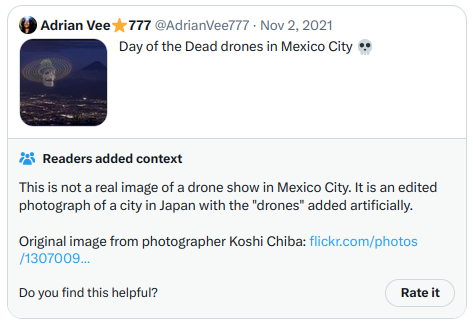
Et une autre :
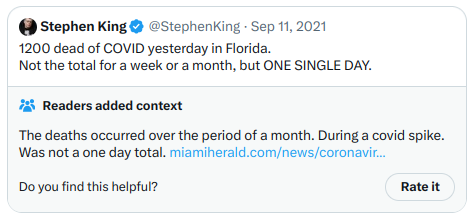
Concernant cette deuxième note, bien qu’elle traite d’un sujet politique très partisan, elle reste claire, de haute qualité et informative, ce qui lui vaut une bonne évaluation. Globalement, l’algorithme semble efficace, et il est possible de vérifier ses résultats en exécutant le code soi-même.
Quelle est ma perception de cet algorithme ?
Ce qui m’impressionne le plus en analysant cet algorithme, c’est sa complexité. Il existe une « version académique », qui utilise une descente de gradient pour trouver le meilleur ajustement d’équations matricielles à cinq vecteurs, puis une version réelle, beaucoup plus complexe, composée d’une série d’exécutions algorithmiques comportant de nombreuses passes différentes et divers coefficients arbitraires.
Même la version académique masque une complexité sous-jacente. L’équation optimisée est de degré quatre (car le terme fu*fn dans la formule de prédiction est quadratique, et la fonction de coût mesure le carré de l’erreur). Tandis que l’optimisation d’équations quadratiques à plusieurs variables admet presque toujours une solution unique, calculable via de l’algèbre linéaire basique, l’optimisation d’équations quartiques à plusieurs variables possède souvent de multiples solutions. Ainsi, des itérations successives de descente de gradient peuvent converger vers des minima locaux différents. De petites variations en entrée peuvent faire basculer l’algorithme d’un minimum local à un autre, changeant radicalement la sortie.
Cette différence avec les algorithmes auxquels j’ai contribué (comme le financement quadratique) me paraît illustrer celle entre un algorithme d’économiste et un algorithme d’ingénieur. Celui de l’économiste, dans des conditions idéales, mise sur la simplicité, est relativement facile à analyser, et possède des propriétés mathématiques claires qui montrent qu’il est optimal (ou le moins mauvais) pour la tâche donnée, idéalement accompagné d’une preuve limitant les dégâts en cas de manipulation. Celui de l’ingénieur, en revanche, résulte d’un processus itératif d’essais-erreurs, testant empiriquement ce qui fonctionne ou non dans un environnement opérationnel donné. L’algorithme d’ingénieur est pragmatique et fait le travail ; celui de l’économiste ne s’effondre pas face à des situations imprévues.
Ou, comme l’a dit roon (alias tszzl), un philosophe internet respecté, sur un sujet connexe :

Bien sûr, je dirais que l’aspect « esthétique théorique » des cryptomonnaies est nécessaire, car il permet de distinguer clairement les protocoles véritablement sans confiance de ceux qui semblent bons, fonctionnent bien en surface, mais reposent en réalité sur des acteurs centralisés, voire pire, sont de véritables escroqueries.
L’apprentissage profond fonctionne bien en conditions normales, mais présente des vulnérabilités inévitables face aux attaques adversariales. Quand c’est possible, des garde-fous techniques et des abstractions rigoureuses peuvent contrer ces attaques. D’où ma question : pouvons-nous transformer Community Notes lui-même en quelque chose de plus proche d’un algorithme d’économiste ?
Pour mieux comprendre ce que cela impliquerait, examinons un algorithme que j’ai conçu il y a quelques années pour un objectif similaire : le financement quadratique borné par paires (pairwise-bounded quadratic funding).
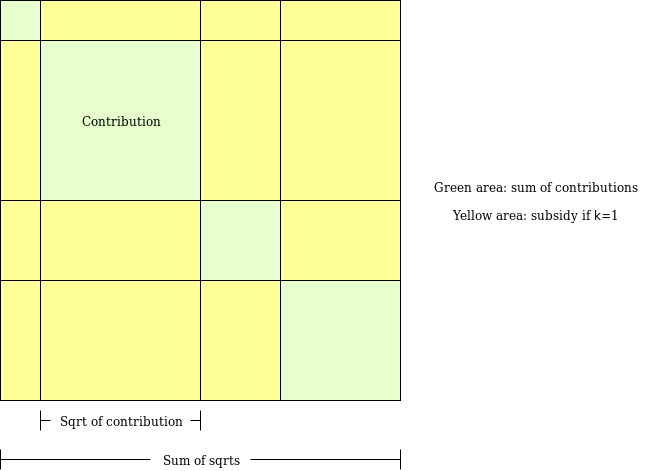
Le financement quadratique borné par paires vise à corriger une faille du financement quadratique « classique » : même deux participants complices peuvent subventionner massivement un faux projet, récupérer l’argent et vider tout le fonds. Dans cette variante, chaque paire de participants reçoit un budget limité M. L’algorithme parcourt toutes les paires possibles ; si un projet P reçoit une subvention parce que A et B y contribuent, cette subvention est prélevée sur le budget alloué au couple (A,B). Ainsi, même k participants complices ne peuvent voler au maximum que k*(k−1)*M.
Une telle approche ne convient pas directement à Community Notes, car chaque utilisateur vote rarement : en moyenne, le nombre de votes communs entre deux utilisateurs est nul, donc l’analyse par paires ne suffit pas à déterminer la polarité. Le modèle d’apprentissage automatique vise justement à « remplir » la matrice à partir de données très éparses, impossibles à analyser directement. Mais cela nécessite des efforts supplémentaires pour éviter une instabilité excessive face à quelques votes malveillants.
Community Notes résiste-t-il vraiment aux biais gauche/droite ?
Peut-on analyser si Community Notes parvient réellement à résister à la polarisation, c’est-à-dire s’il se comporte mieux qu’un algorithme de vote naïf ? Ce dernier offre déjà une certaine résistance : un post avec 200 mentions « utile » et 100 « inutile » performe moins bien qu’un post avec 200 « utile » seul. Mais Community Notes fait-il mieux ?
Du point de vue abstrait de l’algorithme, c’est difficile à dire. Pourquoi une note très populaire mais polarisante ne pourrait-elle pas avoir à la fois une forte polarité et une haute utilité ? L’idée est que si les votes sont conflictuels, la polarité devrait « absorber » les traits qui font varier les évaluations, mais le fait-il vraiment ?
Pour vérifier cela, j’ai exécuté 100 itérations de ma propre implémentation simplifiée. Résultat moyen :

Dans ce test, les « bonnes » notes reçoivent +2 des utilisateurs du même camp politique et +0 de l’autre camp. Les notes « bonnes mais plus polarisantes » reçoivent +4 du même camp, -2 de l’autre. Bien que la moyenne soit identique, la polarité diffère. Et en effet, les « bonnes » notes obtiennent une utilité moyenne supérieure aux « bonnes mais polarisantes ».
Un algorithme plus proche de celui de l’« économiste » aurait une explication plus claire de la manière dont il pénalise la polarisation.
Dans les cas à enjeux élevés, quelle est son utilité ?
On peut l’évaluer en observant un cas concret. Il y a environ un mois, Ian Bremmer s’est plaint qu’une note très critique ajoutée à un tweet d’un responsable chinois avait été supprimée.
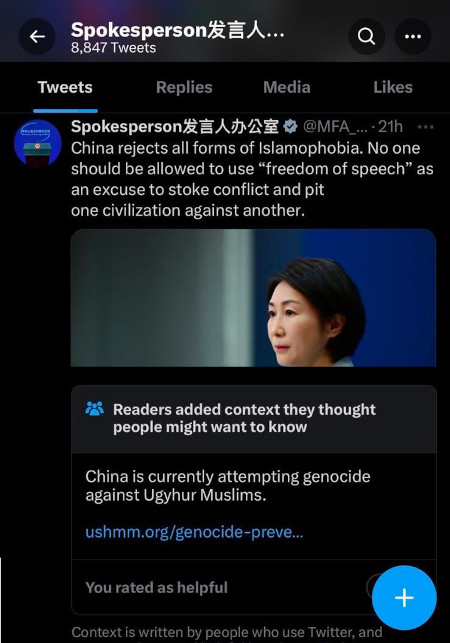
C’est un défi majeur. Concevoir un mécanisme dans une communauté Ethereum, où la pire conséquence serait qu’un influenceur extrême touche 20 000 dollars, est une chose. Être confronté à des questions politiques et géopolitiques affectant des millions de personnes, où chacun suppose systématiquement les pires intentions, est une tout autre affaire. Mais si les concepteurs de mécanismes veulent avoir un impact mondial, interagir avec ces environnements à haut risque est incontournable.
Sur Twitter, une raison évidente de soupçonner une manipulation centralisée est que Musk a de gros intérêts commerciaux en Chine, donc il aurait pu forcer l’équipe de Community Notes à interférer et supprimer cette note.
Heureusement, l’algorithme est open source et vérifiable ! Alors faisons-le. L’URL du tweet original est https://twitter.com/MFA_China/status/1676157337109946369. Le nombre final, 1676157337109946369, est l’ID du tweet. On peut chercher cet ID dans les données téléchargeables pour identifier la ligne correspondante dans le tableau :
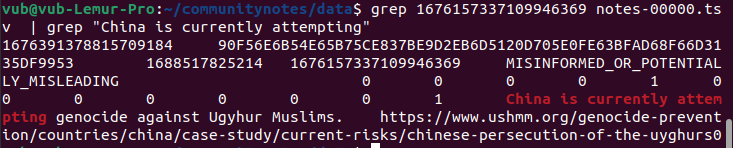
On obtient alors l’ID de la note elle-même : 1676391378815709184. On cherche ensuite cet ID dans les fichiers scored_notes.tsv et note_status_history.tsv générés par l’algorithme :
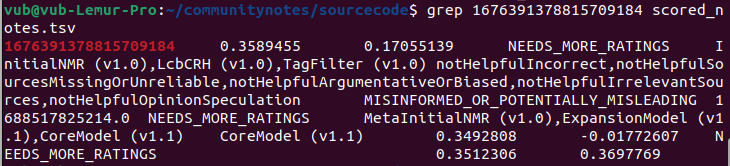

Dans la première sortie, la deuxième colonne donne le score actuel de la note. La seconde montre son historique : son statut actuel (colonne 7) est NEEDS_MORE_RATINGS, et son premier statut antérieur non-NEEDS_MORE_RATINGS était CURRENTLY_RATED_HELPFUL (colonne 5). On voit donc que l’algorithme a d’abord affiché la note, puis l’a retirée quand son score a légèrement baissé — aucune intervention centralisée n’est détectée.
On peut aussi examiner les votes eux-mêmes. En scannant le fichier ratings-00000.tsv, on isole tous les votes sur cette note et on compte les HELPFUL et NOT_HELPFUL :

Or, si on les trie par horodatage et qu’on examine les 50 premiers, on trouve 40 HELPFUL contre 9 NOT_HELPFUL. Conclusion identique : les premiers lecteurs ont apprécié la note, les suivants moins, donc son score a baissé progressivement.
Malheureusement, il est difficile d’expliquer précisément pourquoi l’état de la note a changé : ce n’est pas simplement « avant > 0,40, maintenant < 0,40, donc retirée ». En fait, un grand nombre de NOT_HELPFUL a déclenché une condition exceptionnelle, augmentant le seuil d’utilité requis pour rester affichée.
Autre leçon : pour qu’un algorithme de neutralité fiable le soit vraiment, il doit rester simple. Si une note passe de « acceptée » à « retirée », il devrait y avoir une explication claire et simple.
Il existe aussi une autre forme de manipulation : le brigading. Quelqu’un voyant une note qu’il désapprouve peut mobiliser une communauté très active (ou pire, un réseau de faux comptes) pour voter NOT_HELPFUL. Peu de votes suffisent alors pour passer d’« utile » à « trop polémique ». Réduire cette vulnérabilité demande plus d’analyse. Une piste : ne pas permettre à tout utilisateur de voter sur toute note, mais assigner aléatoirement des notes à des évaluateurs via un algorithme de recommandation, et ne leur autoriser que l’évaluation des notes qui leur sont attribuées.
Community Notes n’est-il pas trop « prudent » ?
La principale critique que j’entends contre Community Notes est qu’il n’en fait pas assez. Deux articles récents le soulignent. Extrait de l’un d’eux :
Le programme est gravement limité par le fait que pour qu'une note soit publiquement affichée, elle doit bénéficier d'un consensus général entre personnes de tous bords politiques.
« Il faut un consensus idéologique », dit-il. « Cela signifie que les gens de gauche et de droite doivent s'accorder pour que la note soit attachée au tweet. »
Il ajoute qu’en substance, cela exige « un accord trans-ideologique sur la vérité », ce qui est presque impossible dans un climat de polarisation croissante.
C’est un dilemme délicat, mais personnellement, je préfère que dix tweets mensongers circulent librement plutôt qu’un tweet honnête soit injustement annoté. Nous avons connu des années de vérification des faits courageuse, partant du principe que « nous savons la vérité, et qu’un camp ment bien plus souvent que l’autre ». Quel en a été le résultat ?

Honnêtement, la vérification des faits suscite aujourd’hui une méfiance assez généralisée. Une stratégie serait d’ignorer ces critiques, de rappeler que les experts connaissent mieux la vérité que tout système de vote, et de persévérer. Mais insister sur cette voie semble risqué. Il est précieux de construire des institutions transverses respectées, au moins dans une certaine mesure, par tous. Comme la maxime de William Blackstone appliquée aux tribunaux, je pense que pour préserver ce respect, il faut un système dont les erreurs soient des omissions, non des actions injustes. Ainsi, il me semble salutaire qu’une organisation majeure adopte cette approche différente, traitant son rare respect transversal comme une ressource précieuse.
Un autre motif à ma tolérance pour la prudence de Community Notes : je ne pense pas que chaque tweet erroné, ni même la majorité, doive recevoir une correction. Même si moins de 1 % des tweets erronés bénéficient d’une annotation informative, Community Notes reste un outil éducatif extrêmement précieux. L’objectif n’est pas de tout corriger, mais de rappeler qu’il existe plusieurs points de vue, que certains messages, séduisants en apparence, sont profondément trompeurs, et que vous, oui vous, pouvez effectuer une recherche Internet basique pour vérifier leur fausseté.
Community Notes n’est pas, et ne prétend pas être, une panacée pour tous les problèmes de la connaissance publique. Pour tout ce qu’il ne résout pas, il reste ample place à d’autres mécanismes : gadgets innovants comme les marchés prédictifs, ou organisations traditionnelles embauchant des spécialistes à plein temps, peuvent tenter de combler ces lacunes.
Conclusion
Community Notes n’est pas seulement une expérience fascinante de média social, mais aussi un exemple émergent d’un type de conception de mécanismes : des systèmes qui cherchent activement à identifier les polarisations et à favoriser les ponts entre groupes plutôt que d’accentuer les divisions.
Parmi les autres exemples que je connaisse dans cette catégorie figurent : (i) le mécanisme de financement quadratique par paires utilisé par Gitcoin Grants, et (ii) Polis, un outil de discussion qui utilise un algorithme de regroupement pour aider les communautés à identifier des déclarations largement soutenues par-delà les clivages habituels. Ce domaine de conception mécanique est précieux, et j’espère y voir davantage de travaux académiques.
La transparence algorithmique offerte par Community Notes n’est pas totalement un média social décentralisé — si vous n’aimez pas la manière dont il fonctionne, vous ne pouvez pas choisir un autre algorithme pour voir les mêmes contenus différemment. Mais c’est la réalisation la plus proche qu’on puisse observer aujourd’hui dans une application à très grande échelle, et elle apporte déjà une immense valeur, tant pour prévenir la manipulation centralisée que pour reconnaître les plateformes qui s’en abstiennent.
J’attends avec impatience les développements de Community Notes et de nombreux algorithmes similaires au cours des dix prochaines années.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News














