

Alliance DAO : Quelles sont les opportunités et défis liés à la convergence de l'IA et de la Web3 ?
TechFlow SélectionTechFlow Sélection
Alliance DAO : Quelles sont les opportunités et défis liés à la convergence de l'IA et de la Web3 ?
Peu de technologies sont en mesure d'influencer de façon significative la trajectoire du développement de l'intelligence artificielle, et Web3 en fait partie.
Rédaction : Mohamed Fouda, Qiao Wang
*Cet article est publié en exclusivité par TechFlow sous autorisation de Alliance DAO.

Depuis le lancement de ChatGPT et GPT-4, un grand nombre d'analyses ont été consacrées à la manière dont l'intelligence artificielle (IA) pourrait transformer tout, y compris Web3. Les développeurs de nombreux secteurs utilisent désormais ChatGPT pour automatiser diverses tâches telles que la génération de code type, les tests unitaires, la documentation, le débogage ou encore la détection de vulnérabilités. Bien que cet article explore comment l’IA peut permettre de nouveaux cas d’utilisation intéressants dans Web3, son principal objectif est de mettre en lumière la relation mutuellement bénéfique entre Web3 et l’IA. Peu de technologies peuvent influencer significativement la trajectoire du développement de l’IA, mais Web3 fait partie de celles-ci.
Comment Web3 peut-il bénéficier à l’intelligence artificielle ?
Malgré son potentiel, les modèles actuels d’intelligence artificielle font face à plusieurs défis, notamment la confidentialité des données, l’équité dans l’exécution de modèles propriétaires, ainsi que la création et la diffusion de contenus falsifiés crédibles. Certaines technologies existantes de Web3 offrent des avantages uniques pour relever ces défis.
Ensembles de données propriétaires pour l’entraînement du machine learning
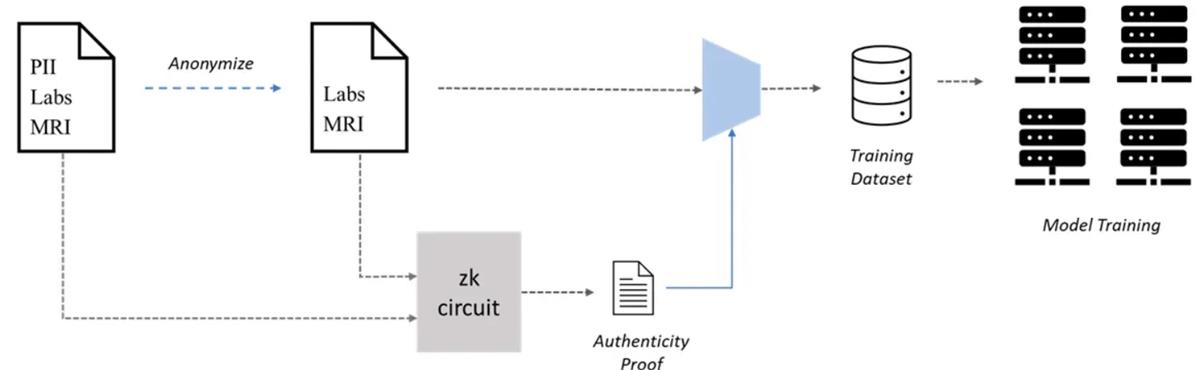
Un domaine où Web3 peut aider l’IA est la création collaborative d’ensembles de données propriétaires destinés au machine learning (ML), via des réseaux basés sur une preuve de travail humain (Proof of Personhood Work, PoPW). De vastes ensembles de données sont cruciaux pour obtenir des modèles ML précis, mais leur création peut constituer un goulot d’étranglement, notamment dans les applications médicales nécessitant des données sensibles. Par exemple, la protection de la vie privée des patients pose un problème majeur, alors même que l’accès aux dossiers médicaux est indispensable pour entraîner ces modèles. Toutefois, en raison de ces préoccupations, les patients peuvent hésiter à partager leurs informations médicales. Pour résoudre ce dilemme, les patients pourraient anonymiser leurs dossiers de manière vérifiable afin de préserver leur confidentialité tout en permettant leur utilisation pour l’entraînement des modèles ML.
La véracité des dossiers médicaux anonymisés reste néanmoins problématique, car des données falsifiées pourraient nuire à la performance du modèle. Pour pallier cela, on peut utiliser des preuves à connaissance nulle (Zero-Knowledge Proofs, ZKP) afin de valider l’authenticité des dossiers anonymisés. Un patient pourrait générer une ZKP attestant que le dossier anonymisé correspond bien à l’enregistrement d’origine, même après suppression des informations personnelles identifiables (PII). Ainsi, les patients peuvent soumettre leurs dossiers anonymisés accompagnés de la ZKP aux parties intéressées et être récompensés sans compromettre leur vie privée.
Inférence sur des données privées
Une faiblesse majeure des grands modèles linguistiques (LLM) actuels réside dans leur capacité à traiter des données privées. Par exemple, lorsqu’un utilisateur interagit avec ChatGPT, OpenAI collecte ses données pour améliorer l’entraînement du modèle, ce qui peut entraîner des fuites d’informations sensibles — comme cela s’est produit chez Samsung. Les technologies à connaissance nulle (zk) peuvent aider à résoudre certains problèmes liés à l’exécution d’inférences sur des données privées. Ici, deux cas sont envisagés : les modèles open source et les modèles propriétaires.
-
Dans le cas des modèles open source, l’utilisateur peut télécharger le modèle et exécuter localement ses données sensibles. Par exemple, Worldcoin prévoit de mettre à jour son identifiant World ID. Ce système requiert le traitement des données biométriques privées de l’utilisateur, notamment le scan de l’iris, afin de créer un identifiant unique appelé IrisCode. Dans ce scénario, l’utilisateur peut garder ses données biométriques confidentielles sur son appareil, télécharger le modèle ML utilisé pour générer l’IrisCode, effectuer localement l’inférence, puis produire une ZKP prouvant qu’il a correctement généré l’IrisCode. La preuve fournie garantit l’exactitude de l’inférence tout en préservant la confidentialité des données. Des mécanismes efficaces de zk preuve pour les modèles ML (comme ceux développés par Modulus Labs) sont essentiels pour ce cas d’usage.
-
Pour les modèles propriétaires, les ZKP offrent deux approches possibles. Premièrement, utiliser une ZKP pour anonymiser les données utilisateur avant de les envoyer au modèle ML, comme discuté précédemment dans le cadre de la création de jeux de données. Deuxièmement, prétraiter localement les données sensibles avant d’envoyer les résultats au modèle. Dans ce cas, l’étape de prétraitement masque les données privées de façon irréversible. L’utilisateur génère ensuite une ZKP attestant du bon déroulement du prétraitement, puis le reste du modèle propriétaire peut être exécuté à distance sur le serveur du propriétaire. Ce cas d’usage s’applique notamment aux médecins IA capables d’analyser les dossiers médicaux pour un diagnostic potentiel, ou aux algorithmes d’évaluation des risques financiers analysant les informations personnelles des clients.
Authenticité du contenu et lutte contre les deepfakes
ChatGPT a peut-être éclipsé les modèles génératifs spécialisés dans la production d’images, d’audio ou de vidéos. Pourtant, ces derniers sont aujourd’hui capables de générer des contenus de type « deepfake » très réalistes. Récemment, une chanson attribuée à Drake, entièrement générée par IA, en est un exemple frappant. Ces techniques représentent une menace sérieuse, et bien que plusieurs start-ups tentent d’y remédier avec des solutions Web2, les technologies Web3 — comme les signatures numériques — semblent mieux adaptées.
Dans Web3, les interactions des utilisateurs (c’est-à-dire les transactions) sont signées à l’aide de clés privées pour en prouver la validité. De la même manière, tout contenu — texte, image, audio ou vidéo — peut être signé à l’aide de la clé privée du créateur afin d’en attester l’authenticité. N’importe qui peut vérifier cette signature à partir de l’adresse publique du créateur, disponible sur son site web ou ses comptes de médias sociaux. L’infrastructure nécessaire existe déjà sur les réseaux Web3. Fred Wilson a souligné comment associer un contenu à une clé publique pouvait efficacement combattre la désinformation. De nombreux investisseurs en capital-risque renommés ont déjà relié leurs profils de médias sociaux (comme Twitter) ou des plateformes décentralisées (comme Lens Protocol ou Mirror) à leurs adresses cryptographiques publiques, renforçant ainsi la crédibilité des signatures numériques comme méthode d’authentification du contenu.
Bien que ce concept soit simple, beaucoup reste à faire pour améliorer l’expérience utilisateur autour de cette authentification. Par exemple, il faut automatiser le processus de signature numérique des contenus afin d’offrir un flux transparent aux créateurs. Un autre défi consiste à générer des sous-ensembles de données signées (comme un extrait audio ou vidéo) sans avoir à signer à nouveau. De nombreuses technologies Web3 existantes apportent des solutions spécifiques à ces problèmes.
Minimisation de la confiance pour les modèles propriétaires
Un autre domaine où Web3 peut bénéficier à l’IA est la minimisation de la confiance exigée vis-à-vis des fournisseurs lorsqu’un modèle ML propriétaire est proposé en tant que service. Les utilisateurs doivent pouvoir vérifier qu’ils reçoivent bien le service pour lequel ils paient, ou avoir la garantie qu’un modèle ML est exécuté de façon équitable — c’est-à-dire que tous les utilisateurs utilisent exactement le même modèle. Les ZKP peuvent fournir ces garanties. Dans cette architecture, le créateur du modèle ML génère un circuit zk représentant ce modèle. Ce circuit est ensuite utilisé à la demande pour produire une ZKP de l’inférence réalisée pour chaque utilisateur. Cette ZKP peut être envoyée directement à l’utilisateur pour vérification, ou publiée sur une blockchain publique chargée de gérer la validation. Si le modèle ML est privé, un tiers indépendant peut vérifier que le circuit zk utilisé représente effectivement ce modèle. La minimisation de la confiance dans l’exécution des modèles ML sera particulièrement utile lorsque les résultats ont des enjeux élevés. Exemples :
1. Diagnostic médical par ML
Dans ce cas d’usage, un patient soumet ses données médicales à un modèle ML pour un diagnostic potentiel. Il doit être assuré que le modèle ML cible a été correctement appliqué à ses données. Le processus d’inférence génère une ZKP attestant de l’exécution correcte du modèle.
2. Évaluation du crédit
Les ZKP peuvent garantir que les banques et institutions financières prennent bien en compte toutes les informations financières soumises par le demandeur lors de l’évaluation de son crédit. En outre, elles peuvent prouver l’équité du traitement en démontrant que tous les utilisateurs passent par le même modèle.
3. Traitement des sinistres d’assurance
Le traitement actuel des sinistres d’assurance est manuel et subjectif. Un modèle ML pourrait évaluer plus justement les polices et les détails des sinistres. Couplé aux ZKP, ce modèle pourrait prouver qu’il a pris en compte tous les éléments de la police et du sinistre, et garantir que le même modèle est utilisé pour traiter tous les sinistres relevant d’une même police.
Lutter contre la centralisation dans la création des modèles
La création et l’entraînement des grands modèles linguistiques (LLM) constituent un processus long et coûteux, nécessitant une expertise pointue, une infrastructure informatique spécialisée et des millions de dollars de ressources computationnelles. Ces contraintes favorisent l’émergence d’entités centralisées puissantes, comme OpenAI, qui peuvent acquérir un contrôle considérable en limitant l’accès à leurs modèles.
Face à ces risques de centralisation, la question de savoir comment Web3 peut promouvoir la décentralisation dans la création des LLM devient centrale. Certains partisans de Web3 proposent des solutions basées sur le calcul distribué pour concurrencer les acteurs centralisés. L’idée principale étant que le calcul distribué pourrait être une alternative moins coûteuse. Cependant, nous pensons que ce n’est pas nécessairement l’angle le plus pertinent. En effet, le calcul distribué souffre d’un inconvénient majeur : le coût de communication entre différents dispositifs hétérogènes peut ralentir l’entraînement ML de 10 à 100 fois.
Au contraire, les projets Web3 pourraient se concentrer sur la création de modèles ML uniques et compétitifs selon un modèle similaire à PoPW. Ces réseaux PoPW pourraient également collecter des données afin de construire des jeux de données exclusifs pour entraîner ces modèles. Des projets comme Together et Bittensor vont déjà dans ce sens.
Infrastructure de paiement et d’exécution pour les agents IA
Ces dernières semaines ont vu l’émergence d’agents IA capables d’utiliser des LLM pour raisonner sur les tâches nécessaires à la réalisation d’un objectif, voire pour les exécuter directement. Cette vague a commencé avec BabyAGI et s’est rapidement étendue à des versions plus avancées comme AutoGPT. Une prédiction importante ici est que ces agents IA deviendront de plus en plus spécialisés pour exceller dans des tâches précises. S’il existait un marché spécialisé d’agents IA, ceux-ci pourraient rechercher, embaucher et payer d’autres agents IA pour accomplir des tâches spécifiques, contribuant ainsi à un projet global. Dans ce contexte, les réseaux Web3 offrent un environnement idéal. Pour les paiements, les agents IA pourraient être équipés de portefeuilles cryptographiques leur permettant de recevoir des fonds et de payer d’autres agents. En outre, ils pourraient accéder à des ressources sur des réseaux cryptographiques sans permission. Par exemple, si un agent IA a besoin de stocker des données, il pourrait créer un portefeuille Filecoin et payer pour du stockage décentralisé sur IPFS. Il pourrait aussi déléguer des ressources de calcul provenant de réseaux décentralisés comme Akash pour exécuter certaines tâches, voire étendre sa propre capacité d’exécution.
Prévenir les atteintes à la vie privée par l’IA
Compte tenu de la quantité massive de données requise pour entraîner des modèles ML performants, on peut s’attendre à ce que toute donnée publique soit intégrée aux modèles afin de prédire le comportement individuel. De plus, les banques et institutions financières pourraient former leurs propres modèles ML à partir des informations financières des utilisateurs, capables de prédire leurs comportements futurs. Cela représenterait une grave violation de la vie privée. La seule solution pour atténuer cette menace est que la confidentialité des transactions financières soit protégée par défaut. Dans Web3, cette confidentialité peut être assurée grâce à des blockchains de paiement privées (comme zCash ou Aztec) et à des protocoles DeFi privés (comme Penumbra et Aleo).
Cas d’usage Web3 activés par l’IA
Jeux sur chaîne
1. Génération de bots pour joueurs non programmeurs
Des jeux comme Dark Forest ont créé un paradigme unique où les joueurs tirent avantage en développant et déployant des bots capables d’accomplir des tâches de jeu. Ce changement de paradigme risque d’exclure les joueurs sans compétences en programmation. Cependant, les LLM peuvent changer cela. Entraînés spécifiquement, les LLM peuvent comprendre la logique des jeux sur chaîne et permettre aux joueurs de créer des bots reflétant leur stratégie sans avoir à écrire de code. Des projets comme Primodium et AI Arena travaillent à intégrer à la fois des joueurs humains et des joueurs IA dans leurs jeux.
2. Combats de bots, paris et jeux d’argent
Une autre possibilité dans les jeux sur chaîne est celle de joueurs IA entièrement autonomes. Dans ce cas, le joueur est un agent IA, comme AutoGPT, utilisant un LLM comme moteur arrière et ayant accès à des ressources externes — internet, et potentiellement un capital initial en crypto-monnaie. Ces joueurs IA pourraient participer à des combats de bots avec mise. Cela pourrait ouvrir un marché spéculatif sur les résultats de ces paris.
3. Création de PNJ réalistes pour les jeux sur chaîne
Actuellement, les personnages non-joueurs (PNJ) sont peu exploités. Leurs actions sont limitées et leur impact sur le déroulement du jeu est minime. En tirant parti de la synergie entre IA et Web3, on peut concevoir des PNJ contrôlés par IA plus immersifs, rompant avec la prévisibilité et rendant le jeu plus intéressant. Un défi possible serait d’introduire des PNJ pertinents tout en minimisant le TPS (transactions par seconde) lié à leurs activités. Un TPS excessif risquerait de congestionner le réseau et d’altérer l’expérience des joueurs réels.
Réseaux sociaux décentralisés
L’un des défis des plateformes sociales décentralisées actuelles est qu’elles n’offrent pas d’expérience utilisateur vraiment distinctive par rapport aux plateformes centralisées. Une intégration fluide avec l’IA pourrait offrir des expériences uniques absentes des alternatives Web2. Par exemple, des comptes gérés par IA pourraient aider à attirer de nouveaux utilisateurs en partageant du contenu pertinent, en commentant des publications et en participant à des discussions. Ces comptes IA pourraient aussi servir d’agrégateurs d’actualités, en résumant les tendances récentes correspondant aux intérêts de l’utilisateur.
Tests de sécurité et de viabilité économique pour les protocoles décentralisés
Les agents IA basés sur des LLM, capables de définir des objectifs, de générer du code et de l’exécuter, offrent une opportunité de tester concrètement la sécurité et la viabilité économique des réseaux décentralisés. Dans ce scénario, un agent IA est chargé d’analyser l’équilibre sécuritaire ou économique d’un protocole. Il peut examiner la documentation du protocole et les contrats intelligents pour identifier des failles, puis exécuter indépendamment des mécanismes d’attaque afin de maximiser ses gains. Cette approche simule l’environnement réel auquel le protocole pourrait être confronté après son lancement. À partir de ces tests, les concepteurs peuvent revoir leur conception et corriger les vulnérabilités. Jusqu’à présent, seules des entreprises spécialisées comme Gauntlet disposaient des compétences techniques nécessaires. Toutefois, pour des LLM formés sur Solidity, les mécanismes DeFi et les précédents développements, nous espérons qu’ils pourront fournir des fonctionnalités similaires.
Utilisation des LLM pour l’indexation des données et l’extraction d’indicateurs
Bien que les données blockchain soient publiques, indexer ces données et en extraire des informations utiles reste un défi persistant. Certains acteurs comme CoinMetrics se concentrent sur l’indexation des données et la construction d’indicateurs complexes à vendre, tandis que d’autres comme Dune indexent les composants principaux des transactions brutes et s’appuient sur la communauté pour créer des indicateurs. Avec les récents progrès des LLM, on voit clairement émerger une disruption potentielle dans ce domaine. Dune a d’ailleurs perçu cette menace et a publié une feuille de route LLM incluant des composants comme l’interprétation de requêtes SQL ou la génération de requêtes en langage naturel. Cependant, nous prédisons que l’impact des LLM ira plus loin. Il deviendra possible, par exemple, qu’un LLM indexe automatiquement des données pour un indicateur spécifique et interagisse directement avec les nœuds blockchain. Des startups comme Dune Ninja explorent déjà des applications innovantes des LLM pour l’indexation des données.
Accompagner les développeurs vers de nouveaux écosystèmes
Différentes blockchains se font concurrence pour attirer des développeurs à construire des applications sur leurs écosystèmes. L’activité des développeurs Web3 est un indicateur clé du succès d’un écosystème donné. Pour les développeurs, un point douloureux majeur est le manque de soutien et de guidance lorsqu’ils apprennent et construisent sur un nouvel écosystème. Certains écosystèmes ont déjà investi des millions de dollars pour créer des équipes DevRel dédiées. Dans ce domaine, les LLM émergents ont déjà montré des résultats impressionnants : expliquer du code complexe, détecter des erreurs, ou encore créer de la documentation. Des LLM finement ajustés pourraient compléter l’expertise humaine et augmenter considérablement l’efficacité des équipes DevRel. Par exemple, les LLM pourraient créer de la documentation, des tutoriels, répondre aux questions fréquentes, ou encore aider les développeurs lors de hackathons en fournissant du code type ou en créant des tests unitaires.
Amélioration des protocoles DeFi
L’intégration de l’IA dans la logique des protocoles DeFi peut considérablement améliorer leurs performances. Jusqu’ici, le principal obstacle à cette intégration était le coût prohibitif de l’implémentation de l’IA sur chaîne. Bien que les modèles IA puissent être exécutés hors chaîne, il n’existait auparavant aucun moyen de vérifier l’exécution du modèle. Toutefois, grâce à des projets comme Modulus et ChainML, la vérification de l’exécution hors chaîne devient possible. Ces projets permettent d’exécuter les modèles ML hors chaîne tout en maîtrisant les coûts sur chaîne. Pour Modulus, les frais sur chaîne se limitent à la vérification de la ZKP du modèle ; pour ChainML, il s’agit des frais d’oracle payés au réseau décentralisé d’exécution IA.
Quelques cas d’usage DeFi pouvant bénéficier de l’intégration de l’IA :
-
Fourniture de liquidités AMM, par exemple mise à jour des plages de liquidité dans Uniswap V3.
-
Protection contre les liquidations de positions de dette, en utilisant des données sur chaîne et hors chaîne.
-
Produits structurés DeFi complexes, où le mécanisme de la vault est défini par un modèle financier IA plutôt qu’une stratégie fixe. Ces stratégies pourraient inclure du trading, du prêt ou des options gérés par IA.
-
Mécanisme de score de crédit sur chaîne prenant en compte différentes blockchains et différents portefeuilles.
Conclusion
Nous sommes convaincus que Web3 et l’IA sont compatibles tant sur le plan culturel que technique. Contrairement au Web2, souvent méfiant envers les robots, Web3 permet à l’IA de s’épanouir grâce à ses caractéristiques de programmabilité sans permission.
Plus largement, si l’on considère la blockchain comme un réseau, nous anticipons que l’IA dominera les bords du réseau (note du traducteur : les points d’entrée et d’interaction avec le réseau). Cela s’applique à diverses applications grand public, des réseaux sociaux aux jeux.
Jusqu’à présent, les bords des réseaux Web3 étaient majoritairement occupés par des humains. Ce sont eux qui initiaient et signaient les transactions, ou mettaient en œuvre des bots dotés de stratégies fixes pour agir en leur nom.
Avec le temps, nous verrons de plus en plus d’agents IA aux bords du réseau. Ces agents interagiront avec les humains et entre eux via des contrats intelligents. Ces interactions donneront naissance à de nouvelles expériences consommateurs.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News














